
基于混淆因子隐压缩表示模型的因果推断方法
2021-11-05 01:28蔡瑞初白一鸣郝志峰
计算机应用 2021年10期
蔡瑞初,白一鸣,乔 杰,郝志峰
(1.广东工业大学计算机学院,广州 510006;2.佛山科学技术学院数学与大数据学院,广东佛山 528000)
0 引言
近年来,科学研究、工业生产等各领域积累的数据量迅速增长,其中蕴含的研究价值和实用价值也得到了充分的重视和验证,因此,如何深度发掘这些海量数据中蕴含的有价值的信息成为了一个研究热点[1]。越来越多领域中的研究人员致力于从数据中获得此前常规方法无法直接得到的新知识,以推动科学研究进步或帮助决策者在工作中做出合理的判断,其中,因果关系是研究人员最希望获得的一类知识。一方面,因果关系表明了事物间如何相互影响的潜在作用机制,可以帮助研究事物的特性;另一方面,对于研究或工作中关心的事件,在了解了相关的因果关系知识后,就可以通过对原因进行干预行动来推动结果向期望的方向发展[2]。
如何在数据中发掘因果关系,以及如何排除各种其他因素对发掘过程的干扰是一个困难的问题。一种最常用的传统因果关系发现方法是随机控制实验(Randomized Controlled Trial,RCT),通过复杂的实验设计来对各个变量进行干预,根据干预造成的影响分析得到因果关系,同时尽可能地排除其他因素的干扰[2],但它的有效性相当依赖于实验设计的合理性,更关键的是,RCT中必需的干预行动在因果关系未知时并不总是可行的[3],在经济学等领域中干预的花费是不可接受甚至不可能的,在医学等领域中干预可能引发伦理问题。在观察数据上,尤其是非时序的观察数据上进行的因果关系发现方法避免了以上问题[4]。这些方法通常基于对变量进行独立性检测或利用数据产生机制的具体特性来进行因果推断。然而,对于同时受混淆因子影响的两个变量,即使它们之间并不存在直接的因果连接,由于混淆因子引入的相关性很难与这两个变量直接相连时的相关性区分开,也会被独立性检测方法判定为相关变量,并最终得到带有错误边的因果网络。如何检测到混淆因子、消除这类错误边并最终得到正确的因果结构是研究人员最关心的问题之一。
为解决含隐变量的因果关系发现问题,现有方法利用最大祖先图[5]、量子信息不等式[6]等进行隐变量检测,但这些方法提出时在连续数据上使用,并不保证能够适用于离散数据。针对含混淆因子的离散数据的因果关系发现问题,本文提出了一种基于混淆因子隐压缩表示(Confounder Hidden Compact Representation,CHCR)模型[7]的因果推断方法。首先,利用数据集构建备选模型,为备选模型中的原因变量指定一种确定性映射,确保原因变量映射到一个具有更少可能取值数的中间隐状态,也就是对原因变量进行隐压缩表示;然后,根据数据和备选模型用贝叶斯信息准则(Bayesian Information Criterion,BIC)计算其模型评分,不断改动模型并根据模型评分更新最佳模型直到收敛;最后,查看最佳模型中的压缩情况,由于受混淆因子影响的两个变量间不存在直接的因果连接,因此最佳模型中的压缩情况将表明两个变量间不存在隐压缩表示,根据最佳模型中是否存在隐压缩表示,可以分辨出正确的因果结构。
1 相关工作
在因果关系发现的研究工作中,一般用概率图模型(Probability Graph Model,PGM)来表示变量间的因果关系,图模型中的节点表示数据集中的变量,边表示变量间的因果连接,这种图模型又被称为贝叶斯因果网络[2]。通常假设数据中潜在的因果机制可以用一个有向无环图表示,且各变量之间的条件独立性可以根据是否d-分离判断[2,4]。面向非时序观察数据的因果关系发现方法由于实用性和避免了RCT 存在的问题成为了近年来的研究热点,大量方法被提出以从数据中学习贝叶斯因果网络,其中,发展最快的大致可以分为基于约束(Constraint-based)的方法和基于因果函数(Causalfunction-based)的方法两类。经典的基于约束的方法有PC(Peter-Clark)算法[8]和IC(Inductive Causation)算法[9],主要将变量间的条件独立性作为约束,根据约束确认部分特殊结构并删除错误的边[2],但基于约束的方法不可避免地受到马尔可夫等价类问题的影响,多种不同结构可能具有完全相同的条件独立性[4],这些等价结构不具有可分辨性。基于因果函数的方法通常基于结构方程模型和对产生数据的因果机制特性的假设进行因果网络的学习。经典的基于因果函数的方法包括基于独立成分分析算法和剪枝算法的线性非高斯无环模型(Linear Non-Gaussian Acyclic Model,LiNGAM)[10],基于原因变量与噪声独立的假设进行因果方向判断的加性噪声模型(Additive Noise Model,ANM)[11]和基于信息熵的信息几何因果推断(Information-Geometric Causal Inference,IGCI)[12]。这些方法在符合各自假设的场景中能够较好地学习因果网络,但难以拓展到其他场景下。文献[13-14]将两类方法结合起来,将因果网络分解为局部子网络,并使用因果函数模型学习局部网络。文献[15]提出了最大最小爬山(Max-Min Hill-Climbing,MMHC)算法,使用改进后的PC 算法得到无向图,再使用优化后的爬山算法确定最终结构。
以上经典方法都是在连续数据中使用的,对离散数据通常并不适用,其主要原因是连续数据的许多性质在离散数据中截然不同甚至不存在。文献[16]将ANM 扩展到了离散情况下,该模型假设变量的各个可能取值间存在序关系,但很多情况中并不存在有意义的序关系,也就是说,离散ANM 仅仅适用于定序(Ordinal)数据而不适用于定类(Nominal)数据。此外,离散ANM 并没有定义一种较为通用和有意义的加法来描述离散情况下噪声对数据的影响。针对这些问题,文献[7]提出了适用于分类数据的隐压缩表示(Hidden Compact Representation,HCR)模型,由于分类数据中变量的可能取值常常不是按照因果机制划分的,因此不同取值对于当前因果关系来说可能是等价的,可以按照因果机制对这些可能取值进行划分,HCR 模型将这种划分抽象为一个隐藏的确定性映射阶段,并证明了当使用BIC 作为评分标准时,由于压缩映射后模型参数更少,正确的因果模型将具有更高的模型评分。因此,可以使用HCR模型来分辨离散变量间的因果方向。
当数据对应的因果结构中存在混淆因子时,可能因不满足因果充分性假设[4]而学习到带有错误边的因果网络。近年来,许多经典方法的改进版本被提出以检测隐变量并消除错误边。针对基于约束的方法,结合PC 算法和最大祖先图,文献[5]提出了快速因果推断(Fast Causal Inference,FCI)算法;文献[17]在FCI算法的基础上改进得到极快因果推断(Really Fast Causal Inference,RFCI)算法;文献[18-19]利用工具不等式检测是否存在隐变量。针对基于因果函数的方法,文献[20]在LiNGAM 的基础上提出了根据外生变量间是否独立来检测隐变量的ParceLiNGAM;文献[21]提出了适用于线性非高斯情况下的lvLiNGAM(latent variable LiNGAM)。文献[6,22]利用量子信息不等式,通过计算贝叶斯网络的条件熵检测隐变量。上述隐变量检测方法在各自适用情况下都有较好性能,为在离散数据上的隐变量检测方法提供了参考。
2 问题定义及方法
首先描述使用的变量,定义本文专注于解决的问题并提出基于CHCR 模型的混淆因子隐压缩表示因果推断(Confounder Hidden Compact Representation Causal Inference,CHCRCI)方法。
2.1 问题定义
在本文中,用Z表示混淆因子,X、Y表示数据集中包含的变量,|Z|表示变量的可能取值数,G表示因果网络对应的图模型,G:∅表示该因果网络图中不存在因果连接,G:X←Z→Y中Z到X、Y的箭头表示Z是X、Y的原因,在图1中,实线包围表示该变量存在于数据集中,虚线包围表示该变量是不存在于数据集中的隐变量。
本文专注解决的因果推断问题如图1所示,变量X和Y之间无直接的因果连接,且受混淆因子Z影响,根据d-分离[2],给定Z时X和Y是条件独立的,不给定Z时X和Y是相关的。如果在符合这个结构的数据上使用基于约束的方法,由于Z是不存在于数据集中的隐变量,给定数据集中的任何其他变量都无法使X和Y相互独立,这意味着结果中将包含一条X和Y之间直接相连的错误边。
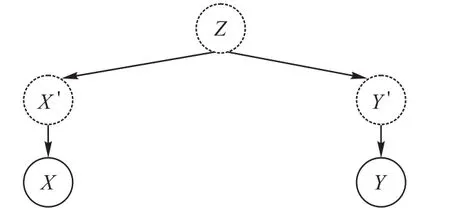
图1 混淆因子隐压缩表示模型示意图Fig.1 Schematic diagram of confounder hidden compact representation model
在图1 中,Z对X施加影响时,首先确定性映射到中间隐状态X'=f(Z),再由X'对X施加影响,其中f表示将Z的值与X'的值对应起来的方式,如=f(Z1)=f(Z2)表示Z1和Z2将被映射到。由于Z中的一个值只能映射到X'里的至多一个值,因此|Z|≥|X'|。当|Z|=|X'|时,可以视为经历了映射X'=Z的特殊情况;当|Z|>|X'|>1 时,称Z到X'的映射为压缩映射,此时式(1)成立:
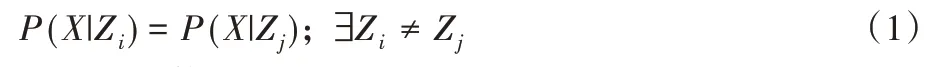
压缩映射体现了离散变量取值的划分方式与真实因果机制间的差距,因此仅仅在原因指向结果的正向模型中存在,从结果指向原因的反向模型中并不存在压缩映射[7]。给定包含m条关于X和Y数据的数据集D=,本文提出的因果推断方法的目标是分辨出正确的因果结构。也就是说,当真实结构含有混淆因子,如G:X←Z→Y时,即使X和Y是相关的,在本文方法的输出结果中,X和Y之间也没有直接连接的边。需要注意的是,由于无论是否压缩,映射均可视为存在确定性映射,为表述简便,本文在不需要强调中间映射的地方将其省略,如G:X→Y与G:X→Y'→Y同义。此外,本文方法并不假设混淆因子必须存在,理论分析和实验结果表明,本文方法同样适用于不含混淆因子的因果结构。
2.2 方法描述
CHCR 模型适用于原因变量经过压缩映射影响结果变量时。对于因果结构G:X←X'←Z→Y'→Y,此时|Z|>|X'|、|Z|>|Y'|成立。由于X、Y之间并不存在直接的因果关系,通常情况下,它们之间并不存在压缩映射,为排除极端情况,在CHCR模型中假设式(2)成立:
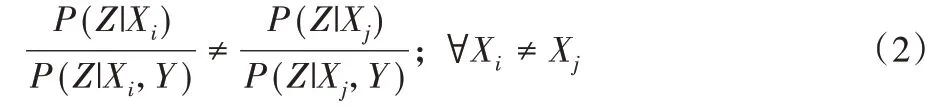
对Y也做类似假设后,可以得到用于分辨正确因果结构的定理1。需要注意的是,即使在实验中并未去除极端情况,本文方法仍具有最高的准确率,可见实际上该假设对本文方法有效性的影响可以忽略不计。
定理1给定数据集D=,学习得到最佳模型G:X→Y'→Y,其中Y'为压缩映射,若|Y'|=1,则真实因果结构为G:∅;若|Y'|=|X|,则真实因果结构为G:X←Z→Y;若1<|Y'|<|X|,则真实因果结构为G:X→Y。
证明 当|Y'|=1时,根据d-分离,给定Y'时X和Y相互独立,如果Y'只有一个取值,那么X和Y自然就是相互独立的。从另一个角度来说,此时无论X取何值,由于X的所有可能取值映射到了同一个值上,对应的Y分布不变,也就是说X和Y相互独立。
当|Y'|=|X|时,若真实因果结构为G:X→Y,根据压缩映射的定义,1<|Y'|<|X|成立,与|Y'|=|X|矛盾,因此X和Y之间不存在直接的因果连接。若真实结构为G:∅,则|Y'|=1。且当真实因果结构为G:X←Z→Y时,对于X的任意两个不同取值Xi≠Xj,有:
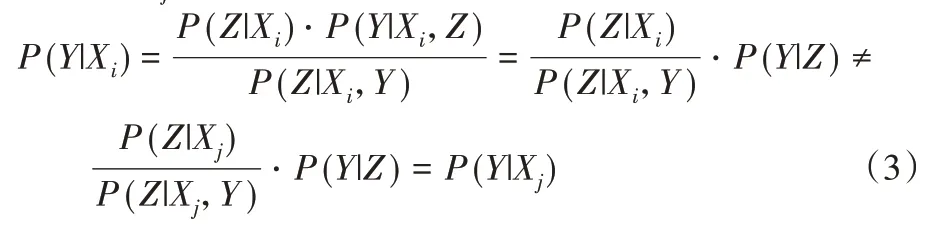
式(3)的推导基于条件概率公式,给定Z时,X与Y相互独立,且式(2)成立,从式(3)中可以看出X到Y间不存在压缩映射,即|Y'|=|X|,因此,此时真实结构只可能是G:X←Z→Y。
当1<|Y'|<|X|时,由于|Y'|≠1,真实结构不是G:∅,由于|Y'|≠|X|,若真实因果结构为G:X←Z→Y,则与式(3)不符。因此,真实结构为G:X→Y。
根据定理1 可以提出混淆因子因果推断算法CHCRCI。首先,在数据集上搜索得到评分最高的因果结构,如G:X→Y'→Y。通过检查压缩映射的情况,即|Y'|,可以分辨出正确的因果结构。完整算法如算法1所示。

在算法1 中,为得到最佳模型,对当前备选模型中的原因变量,尝试各种将其映射到中间状态的方式,更新模型直至无法取得更高的模型评分。在数据集上计算模型评分S=BIC(D,f,G)的公式如下:
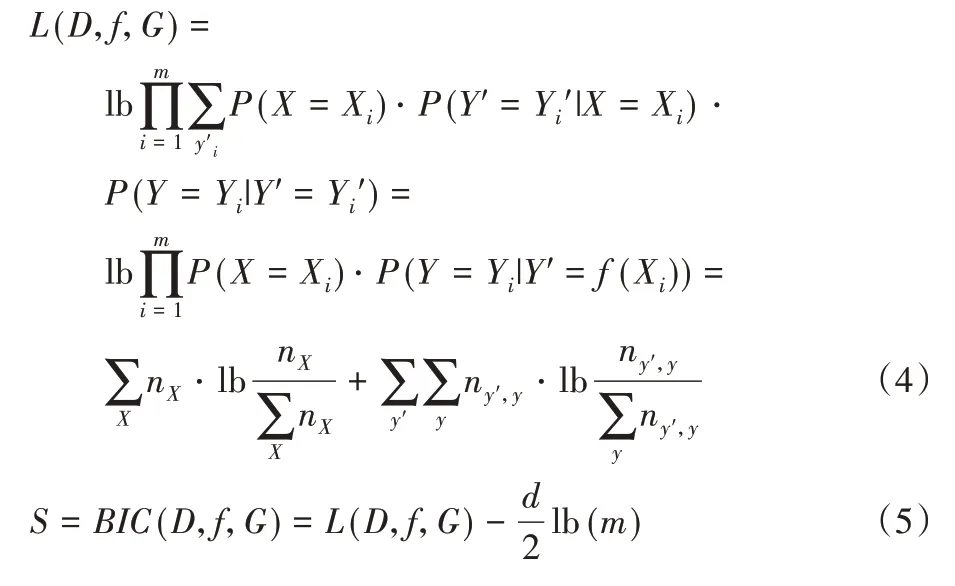
式(4)中首先基于CHCR 模型得到似然度L(D,f,G)的表达式,其中,并说明了给定数据集时如何用最大似然估计计算该表达式,nX为X=x时的频数。式(5)利用BIC 评分的定义式得到最终的模型评分,其中d是整个模型的参数数,m是数据集中的样本数。选出模型评分最高的作为最佳模型后,在最佳模型上应用定理1即可得到作为输出结果的网络结构。需要注意的是,当|f*|=|X|时,这种无法压缩可能由两种不同情况导致:一种是最佳模型与真实模型方向相反,反向是不存在压缩映射的;另一种是真实结构为G:X←Z→Y,此时两个方向都不存在压缩映射;因此需要进一步验证才能确定属于哪一种情况。
算法1 使用BIC 作为备选模型的评分函数,BIC 是具有一致性的评分准则,即更符合数据分布且具有更少参数的模型将得到最高分数[23],因此能够帮助找到最佳结构。在某些情况下,如X、Y之间的互信息很小时,认为二者间没有边的备选模型因为参数更少,可能会得到更高的BIC 评分。此时,对于G1:X→Y'→Y和G2:∅,以下计算式成立:
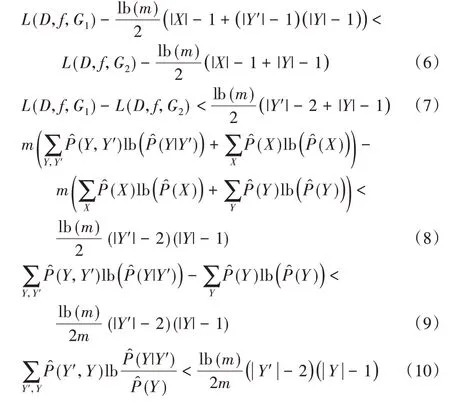
式(6)中不等号两边是BIC 评分的定义式,即似然度减去随参数和数据量增加而增大的惩罚项,m表示数据集的记录数。式(7)到式(8)的变形与式(4)中类似,即消去经验频率。在式(8)中,似然度写成由记录数m与经验频率组成的形式。式(10)成立时,使用BIC评分将输出G:∅,需要注意的是,本文提出的方法的目的并非恢复或消去隐变量,而仅仅是去除错误的因果连接,得到可见变量间正确的因果结构。从这个角度来说,G:∅也应被视为正确结果。因此,即使当式(10)描述的特殊情况发生时,本文方法所得到的因果结构仍然是不存在错误因果连接的正确结果。
3 实验与结果分析
首先使用生成的模拟数据,以准确率(Accuracy),即学习到正确因果结构的次数占实验次数的比率,衡量所提出的因果推断方法CHCRCI 的性能。选取了若干具有代表性且性能较好的方法作为对比,包括独立性检测方法希尔伯特-施密特独立性准则(Hilbert-Schmidt Independence Criterion,HSIC)[24]、混合型因果发现方法MMHC 和含有隐变量检测的RFCI。在多组实验中分别测试了各方法在单一因果结构或混合因果结构上,随样本数、可能取值数或混合程度变化时的准确率,并分析各组实验结果。其次,在真实数据集Abalone上使用本文方法进行实验并分析实验结果。本文的模拟数据实验中,生成数据及运用各方法的过程重复了1 000 次,以各方法得到正确结构的次数占总次数的比率作为准确率。
模拟数据的生成过程大致可以分为两个阶段:首先,在[5,15]内等概率随机选定X、Y、Z等各变量的可能取值数,在[2,5]内等概率随机选定压缩映射的可能取值数,以标准正态分布采样并经过取绝对值、分别除以其总和的操作得到原因变量的概率分布,采样得到原因变量的数据并压缩映射到中间隐状态;其次,以与生成变量分布类似的方式随机生成中间隐状态到结果变量的转移概率矩阵,并根据数据和转移概率矩阵采样得到结果变量的数据。不特别指出时,以上参数为数据生成时的默认参数。
为测试本文中所提方法在各种不同情况下的性能,设计并进行了4组对比实验。
第1组实验测试在数据量变化时,CHCRCI能否正确识别出存在混淆因子的因果结构,真实因果结构均为G:X←Z→Y。在第1 组实验中,样本数的变化范围为[1000,1500,2 000,2 500,3 000],用于对比的方法包括HSIC和RFCI。
HSIC 是一种基于Hilbert-Schmidt范数的非参数独立性度量准则,通过在再生核希尔伯特空间上定义互协方差,计算得到度量独立性的统计量,是一种高效准确、被广泛使用的独立性检测方法。由于本实验中可观测变量只有两个,因此基于约束的方法基本可以等同为独立性检测方法,HSIC 的表现可以代表较为先进的基于约束的方法。
RFCI 是一种可以在存在隐变量或选择偏差时使用的因果推断方法,RFCI 为基于FCI的改进,与FCI具有接近的效果且复杂度更低。RFCI在判断因果结构时更为谨慎,能够较好地分辨出隐变量和选择偏差带来的影响,因此RFCI的表现可以代表含有隐变量检测的因果发现方法。本实验中RFCI 的实现使用了R语言程序包pcalg[25]。
从图2 中可以看出,由于混淆因子的影响导致可见变量间存在相关性,HSIC 始终不能很好地学习到正确的因果结构,事实上,随着样本量的增长,HSIC 的准确率愈发接近于随机猜测;由于RFCI在存疑时更倾向于输出不确定状态而非认为存在因果连接,因此在样本数较少时也能够输出正确结果,但随着样本量增长,其准确率同样接近于随机猜测;如式(10)所示,CHCRCI 在样本数较少时表现更好,但无论样本数多少,CHCRCI 始终能够较好地学习到正确的因果结构,且其准确率明显地高于对比方法。
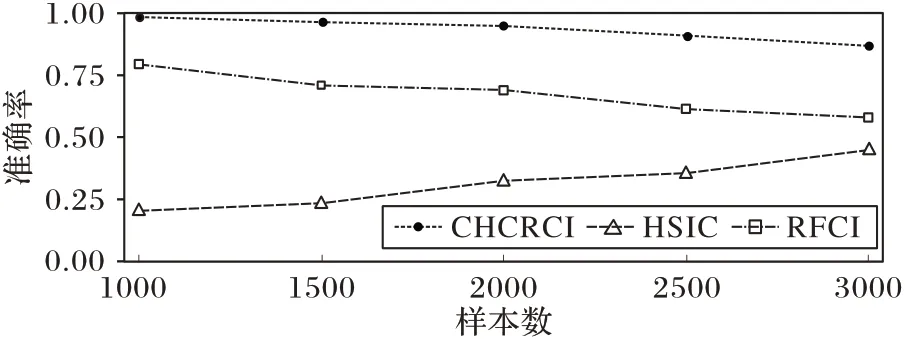
图2 三种方法在样本数变化时的正确率比较Fig.2 Accuracy comparison of three methods when the number of sample changes
第2组实验是测试在变量可能取值数不同时,CHCRCI的表现是否受到影响。在不同的领域中或分类方式不同时,离散变量可能取值数可以有较大的差别,因此有必要测试本文方法是否能够适应这种差别。在生成数据的过程中,调整可能取值数随机选择范围的上限,如从[5,8]中选定可能取值数,以整体地改变可能取值数。在第2 组实验中,因果结构均为G:X←Z→Y,样本数固定为1 000,压缩映射的可能取值数的随机选择范围仍为[2,5]。选择HSIC、RFCI 与本文方法进行性能对比。
从图3 中可以看出,可能取值数变化时,RFCI 和HSIC 学习因果结构的准确率仅有小幅波动,CHCRCI 的准确率则仅在可能取值数为5 时有极少下降,这是由于可能取值数过少导致压缩的性质不明显。但整体来说,CHCRCI 仍然几乎在每次实验中都正确分辨了因果结构。实验结果中准确率曲线的稳定一方面表明了CHCRCI 的有效性,另一方面表明了其他各组实验的结论也适用于不同可能取值数的情况。
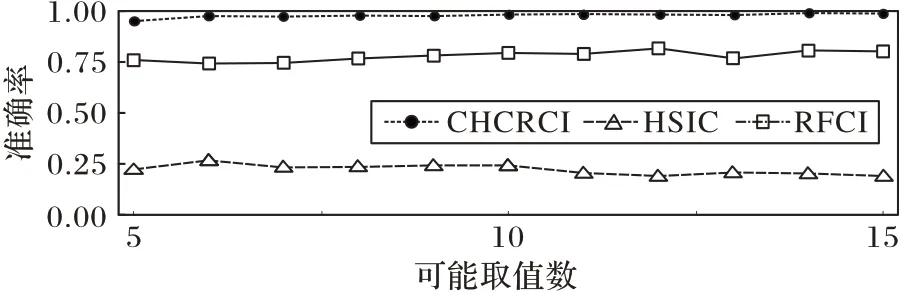
图3 三种方法在变量可能取值数不同时的正确率比较Fig.3 Accuracy comparison of three methods when the number of variable possible values changes
第3 组实验是测试CHCRCI 是否仅适用于混淆因子存在的结构,即本文方法是否具有泛用性。在生成数据时,设定存在混淆因子的概率并随机选择结构类型,该概率的选择范围为{0.2,0.4,0.6,0.8}。存在混淆因子时,真实因果结构为G:X←Z→Y;不存在混淆因子时,真实因果结构为G:X→Y。样本数固定为1 000。由于HSIC 不能直接用于判断因果方向,对比方法改为RFCI和MMHC。
MMHC是一种结合了基于约束的方法和基于评分的方法的因果发现方法,首先使用启发式方法得到父子节点表,第二阶段在父子节点表的基础上使用加入模拟退火等优化手段的爬山算法得到最终结果,由于第一阶段极大减小了搜索空间,能够较好地分辨出正确的因果结构。本实验中MMHC 方法的实现使用了R语言程序包bnlearn[26]。
从图4中可以看出,随着存在混淆因子的概率增长,RFCI准确率有一定提升,但始终接近于随机猜测,这是由于RFCI本质上仍然属于基于约束的方法,而基于约束的方法由于马尔可夫等价类问题,很多时候是无法分辨因果方向的,自然导致了无法正确分辨因果结构;MMHC 方法在存在混淆因子的概率较高时,一定程度上能够学习到正确因果结构,但随着该概率的降低,准确率也急剧降低,如在两种结构的出现概率接近时,准确率也接近于随机猜测;CHCRCI 则在存在混淆因子概率取各值时,均能够较好地分辨出正确的因果结构,且准确率明显优于对比方法,表明CHCRCI 适用于更为一般的情况,具有泛用性。
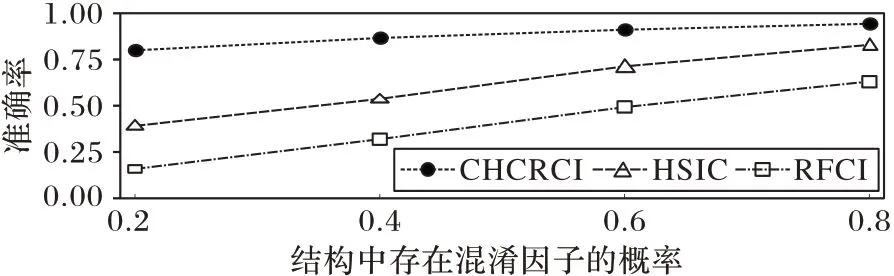
图4 三种方法在不同类型结构混合时的正确率比较Fig.4 Accuracy comparison of three methods when mixing different types of structure
第4 组实验是在混合因果结构上,测试样本数不同时CHCRCI 的表现。为避免类别不平衡(Class-imbalance)问题,真实因果结构在G:X←Z→Y和G:X→Y中等概率地随机选取,生成数据的数据量的变化范围为[1000,1500,2 000,2 500,3 000],其他实验参数均为默认值,对比方法为MMHC和RFCI。
从图5 中可以看出,随着样本数的增长,CHCRCI、MMHC和RFCI三种方法的准确率变化不大,MMHC 的准确率有小幅上升,RFCI的准确率有小幅下降,CHCRCI则始终能够取得实验中最高的准确率,且明显高于其他两个方法,表明了类别平衡时CHCRCI方法的有效性。
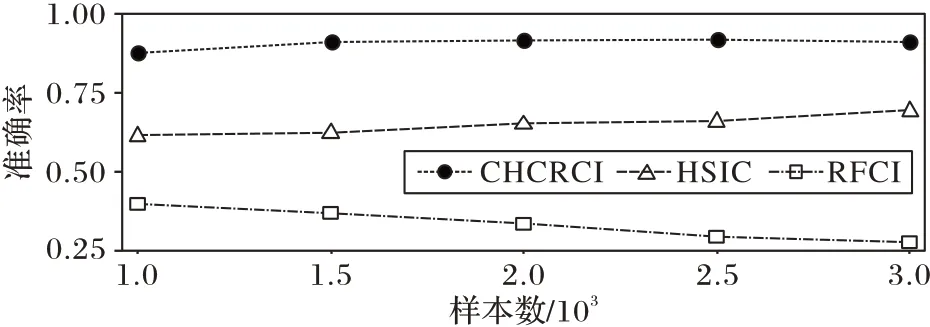
图5 混合结构中三种方法在样本数不同时的正确率比较Fig.5 Accuracy comparison of three methods in mixed structure with different numbers of samples
总的来说,通过设计并测试CHCRCI 在样本数、混淆因子出现概率、变量可能取值数等各种条件变化时的准确率指标的实验,并与HSIC、RFCI、MMHC这三种具有代表性的经典方法进行对比可以看出,CHCRCI 在四组实验中分别设定的各种情况均能够较好地分辨出正确的因果结构,本文方法的有效性和泛用性得到了验证。
UCI 数据集Abalone[27]常被用于检验离散变量上的因果发现方法的性能,该数据集中包含4 177 条关于鲍鱼的性别(Sex)、长度(Length)、直径(Diameter)、高度(Height)等属性的数据,通常认为其性别是长度、直径、高度的原因[7,16,28],然而由于幼年鲍鱼无法识别性别,其性别属性中除雄性(Male,M)与雌性(Female,F)外还包括了无法识别性别的幼年(Infant,I)。为研究其性别属性与其他3 个属性间的关系,去除性别属性为I的无意义数据后,在新数据集上使用CHCRCI方法得到的结果如表1所示。
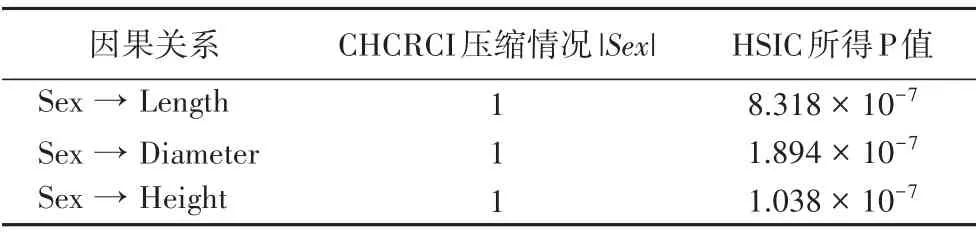
表1 使用CHCRCI与HSIC所得不同变量间因果关系结果的对比Tab.1 Comparison of results obtained by CHCRCI and HSIC between different variables
表1给出了对三组变量分别使用CHCRCI和HSIC方法所得到结果的对比,其中,压缩情况|Sex|是使用CHCRCI 方法所得结果中中间映射的可能取值数,使用HSIC方法所得结果中的P值表示该组变量是否相互独立。从表1中可以看出,不同性别可以压缩至唯一中间状态,根据定理1 和式(10),这意味着性别和其他变量间并不存在直接的因果连接,但可能存在混淆因子,对于这些可见变量间的因果关系来说,这两种情况并没有区别。性别属性与其他属性间不存在直接的因果关系这一结论看似与现有研究结果冲突,但这些研究中并未去除性别无法分辨的幼年鲍鱼的数据,不难推断出存在混淆因子年龄,即年龄决定了是否可以分辨性别,也决定了长度、直径、高度等属性。因此,本文方法所得结论与现有研究结果是可以相容的。作为对比,HSIC 所得结果表明各组变量是相关的,在许多方法中,这意味着将引入性别变量到其他变量的错误的因果连接。
4 结语
本文深入探究了存在混淆因子时的因果推断方法的研究现状,对含混淆因子的离散数据上的因果推断进行了理论分析,提出了一种基于混淆因子隐压缩表示(CHCR)模型的因果发现方法。根据学习到的最佳模型中中间映射的可能取值数,可以判断数据集中的变量间是否存在直接的因果连接,避免了因混淆因子影响而导致出现的错误连接。实验结果表明,在各种样本数或不同类型结构混合等多种情况下,本文所提的方法都能够较好地学习到正确的因果结构,在准确率指标上明显优于对比方法,且在真实数据集Abalone上使用本文方法得到了变量间更为合理的因果关系。在未来的工作中,本文方法有待扩展到节点数更多、结构更复杂的因果结构学习问题中,或进一步弱化当前模型中存在的对于潜在因果机制的假设。
猜你喜欢
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
高中生·天天向上(2018年7期)2018-07-23
法制博览(2018年12期)2018-03-08
新高考·高二数学(2014年7期)2014-09-18
江淮论坛(2013年6期)2013-11-16
福建中学数学(2011年9期)2011-11-03
法制与社会(2009年3期)2009-07-05
