
动态融合社交信息的社会化推荐
2021-11-05 01:28任柯舟彭甫镕张晓静
计算机应用 2021年10期
任柯舟,彭甫镕,郭 鑫,王 喆,张晓静
(山西大学大数据科学与产业研究院,太原 030006)
0 引言
随着互联网的发展和电子商务的蓬勃发展,信息数据呈现爆炸式增长,导致人们面临的选择也越来越多,推荐系统逐渐成为一种普遍应用的技术。传统的推荐系统大多是基于协同过滤或基于内容推荐[1],这类方法主要基于集体智慧,核心思想是给用户推荐他们喜欢物品的相似物品,或者向用户推荐与他们有相似行为的用户喜欢的物品[2]。虽然这些传统的方法有不错的效果,但都忽视了用户交互物品之间的结构关系,例如用户的行为习惯、用户偏好的发展及商品的流行时间等[3]。序列推荐系统能有效利用用户与物品的交互序列来很好地包含这些结构信息,从而进行更加准确和动态的推荐[4]。序列推荐将用户的交互物品按照时间顺序来构建一个序列模型,通过捕获物品之间的依赖关系获得用户的动态兴趣特征,很好地解决了用户的兴趣迁移问题。受处理长度的影响,序列模型通常得到的是用户的短期兴趣特征。为了使用户特征更加完整,研究人员通常使用矩阵分解模型来获取用户长期养成的喜好,即用户的长期兴趣。
每位用户的交互物品相较于物品总量来说是很稀疏的,因此大多数的用户-物品矩阵是稀疏矩阵,而数据的稀疏会导致推荐的效果下降[5];同时随着各大社交网站的发展,越来越多的科研人员将社交数据作为缓解数据稀疏的辅助数据[6]。大多数社会化推荐都基于同质性和社交影响理论,即在社交网路中有联系的用户有相似的兴趣爱好,同时具有相似爱好的人更容易建立联系。由于矩阵分解良好的扩展性,研究人员在矩阵分解的基础上提出了两种融合方式[7]:1)用户特征向量的共享表示,在原矩阵分解的基础上通过共享用户特征,使用户-项目矩阵分解得到的用户特征向量也可以应用在用户社交矩阵中;2)用户特征重表示,在用户兴趣与社交兴趣相似的基础上,增加社交约束项,保证用户特征与社交特征尽可能相似。
用户与项目交互是一个动态序列,用户的兴趣动态变化[3]在序列推荐算法中已被大量地关注,而在一般的社会化推荐算法忽略了用户的短期兴趣。除了用户兴趣的动态特性外,社会化推荐算法也忽略了社交影响的动态特性,将不同时刻的朋友行为同等对待。例如,表1展示了用户u和其两个朋友a、b在t-1到t+1的交互列表,图1展示朋友a、b对用户u可能的影响力。在t-1时刻用户u和朋友a有相同的交互物品,因此朋友a的影响力要大于朋友b;在t时刻用户u和朋友b有相同的交互物品,因此朋友b的影响力要大于朋友a;在t+1 时刻,虽然朋友a,b都交互过物品3,但朋友a的交互时刻要比朋友b更接近于用户u,因此朋友a的影响力要大于朋友b。

图1 朋友对用户的影响Fig.1 Influence of friends on a user

表1 用户和朋友的交互列表Tab.1 Interactive list of a user and his friends
针对用户的兴趣动态变化和社交影响的动态特性,本文提出了一种社交信息动态融合的社会化推荐模型。首先,利用自注意力机制构建用户交互物品的序列模型,捕获用户短期兴趣;然后,利用具有时间遗忘的注意力机制构建社交短期影响,利用具有协同特性的注意力机制构建社交长期影响;最后,结合社交的长短期影响与用户的短期兴趣获得用户的最终兴趣并产生下一项推荐。本文的主要贡献如下:
1)在社交短期兴趣建模过程中,提出具有遗忘机制的注意力融合方法,降低朋友在较远时刻的行为的社交影响力;
2)在社交长期兴趣建模过程中,提出具有协同特性的注意力融合方法,加强行为相似的朋友的社交影响力;
3)提出将用户短期兴趣、社交短期兴趣与社交长期兴趣进行融合,得到一种社交信息动态融合的推荐模型;
4)在两个公开数据集上分别与最新的序列模型和社会化模型进行对比验证提出模型的性能。
1 相关工作
与基于协同过滤的推荐系统的集体智慧相比,序列推荐将重点放在用户交互序列之间的依赖关系上,考虑物品之间的顺序结构关系,通过对用户交互物品进行序列建模,获取用户的兴趣迁移。传统的序列推荐方法主要基于马尔可夫链,例如Feng 等[8]在下一项兴趣点推荐(Point Of Interest,POI)推荐问题上,提出了一种个性化排序度量嵌入方法(Personalized Ranking Metric Embedding,PRME)来建模个性化嵌入序列,首先将POI嵌入到高维空间中,然后用欧拉距离表示两个POI之间的转换概率,同时加入用户的兴趣偏好,最后利用马尔可夫链来预测下一项新的POI,并在两个真实数据集上验证了该模型的优越性。随着深度学习的发展,越来越多的学者将眼光放在了深度学习上。深度学习中的循环神经网络(Recurrent Neural Network,RNN)和卷积神经网络(Convolutional Neural Network,CNN)模型都可以用来处理序列数据。Tang等[9]将在时间和潜在空间中最近一组项目嵌入到“图像”中,并使用卷积滤波器学习顺序模式作为图像的局部特征。针对用户的长短期兴趣,Li 等[10]提出了区分长短期兴趣的用户动态推荐模型。Ma 等[11]利用矩阵分解的思想得到用户的长期兴趣,然后利用分层门控网络(Hierarchical Gated Network,HGN)获取用户短期兴趣,最后在预测层聚合用户的长短期兴趣。
然而不管是传统的马尔可夫链还是基于深度学习的RNN 或者CNN 模型都无法很好地处理长距离依赖问题。文献[12]发现在机器翻译中注意力机制因其可处理长距离依赖关系和可并行化处理的优势,被广泛应用在各类自然语言处理(Nature Language Processing,NLP)问题中。Kang 等[13]利用自注意机制来构建序列模型,通过实验验证了该模型的有效性。Liu 等[14]提出了一种基于会话推荐的短期注意/记忆优先级模型,通过注意力机制来获取用户最后一次交互产生的短期记忆,并从用户的上下文中捕获用户的长期兴趣,在3 个基准数据集上验证了模型的有效性。
因评分矩阵的稀疏性,人们引入社交信息作为额外信息来缓解数据稀疏的问题。Yang 等[15]在矩阵分解的基础上,提出了一种基于用户共享表示的特征融合方式。将用户与物品交互矩阵分解为用户特征和物品特征,并将用户社交矩阵分解为用户信任特征和被信任特征,通过共享用户特征和用户信任特征来融合社交信息。Jamali 等[16]认为用户的个性化特征与其朋友的个性化特征类似,在矩阵分解的基础上增加约束项使用户朋友的个性化特征与用户的个性特征类似。Sun等[17]提出了一种基于递归网络的时间社会推荐方法,利用上一时刻的长短期记忆(Long Short-Term Memory,LSTM)神经网络输出,通过注意力机制捕获用户朋友的长期兴趣,然后将当前时刻的输入和得到的社交信息输入到LSTM 中得到用户的动态兴趣,同时利用用户的长期兴趣通过注意力机制来再次聚合用户朋友的长期兴趣,最后通过加权聚合用户的长短期兴趣。
以上方法忽视用户的短期兴趣和社交影响的动态特性,本文针对这两点提出了一种社交信息动态融合的社会化推荐模型。
2 社交信息动态融合的推荐方法
2.1 符号定义
假设有M个用户组成的用户集合U,N个物品组成的物品集合R。对于每一个用户u交互过的物品集合,按时间顺序进行重新排序,构建用户的交互列表Ru=。用户通常含蓄的表达喜好,而不是给予准确的评分值。因此本文考虑隐式反馈的问题:如果用户u在t时刻交互(点击或收藏、购买)了物品i,则=1;否则=0。为了统一表示,本文使用i,j表示物品,u表示用户,a,b表示朋友。使用F∈RM×M表示用户之间的有向社交矩阵:如果用户u收藏或关注了用户b,则Fu,b=1;否则Fu,b=0。因为是有向社交关系,因此Fu,b≠Fb,u,Fu表示用户u的朋友集合。
下一项推荐问题是在给定用户的交互物品序列Ru=和用户之间的社交关系Fu前提下,预测用户在t+1时刻的交互行为。
2.2 模型框架
针对序列推荐中的数据稀疏问题,提出了一种社交信息动态融合的社会化推荐,其整体框架如图2所示。整体分为3层,从下到上分别为处理用户序列信息的短期兴趣层、融合社交信息的社交融合层和预测用户评分的预测层。
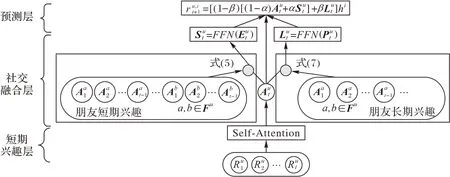
图2 模型框架Fig.2 Framework of the model
为了实现对用户兴趣的动态描述在短期兴趣层,使用自注意机制针对用户的历史交互行为构建序列模型,得到用户的短期兴趣。
如果用户u在t时刻对物品i有兴趣,一般近期交互过物品i的朋友和长期接触物品i的朋友可能对用户当前兴趣产生更大的影响,因此将社交融合层,分为左侧的社交短期兴趣和右侧的社交长期兴趣,并使用具有时间遗忘的注意力机制对社交短期兴趣进行建模,使用具有协同特性的注意力机制对社交长期兴趣进行建模。
在社交短期兴趣部分,利用用户t时刻的短期兴趣通过注意力机制融合朋友的短期兴趣,得到用户动态兴趣特征,并将朋友行为的遗忘曲线加入到注意力权重中。在社交长期兴趣部分,利用用户t时刻的短期兴趣Aut通过注意力机制融合朋友的长期兴趣Va,得到用户静态兴趣特征,并将用户与朋友的杰卡德相似度系数加入注意力权重中。最后在预测层通过权重参数α和β融合社交的长短期兴趣与用户的短期兴趣获得用户在t+1时刻的最终兴趣:
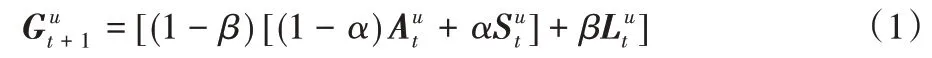
其中:表示用户u在t+1 时预测的用户兴趣,α和β为自学习的权重参数。
下面分别从短期兴趣层、社交融合层和预测层三部分详细介绍本文的模型。
2.3 短期兴趣层
因为自注意力机制在处理序列关系中可并行和处理长期依赖的优点,使用自注意力机制搭建用户与物品的交互序列模型,通过短期兴趣得到用户u在t时刻的短期兴趣特征。短期兴趣层的整体结构如图3 所示,分为特征嵌入层、位置嵌入层和自注意力层。
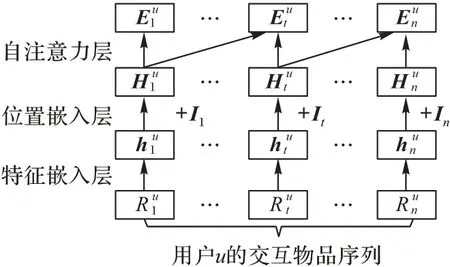
图3 短期兴趣层Fig.3 Short-term interest layer
隐式反馈只包含用户id和物品id并不包含其它上下文及额外信息,为了丰富用户表示,参照Word Embedding[18]思想,使用嵌入层将用户和物品id 转换为固定长度的向量,并通过神经网络来学习潜在空间参数。
为了便于训练,固定用户交互物品的序列大小。取用户交互物品序列中的最后n项物品作为模型的输入,如果用户交互个数小于n,则在序列的前端填充0。将用户u的交互物品序列映射到d维的物品潜在空间得到固定长度的用户交互物品嵌入特征,用户id 映射到d维的用户潜在空间得到用户的长期兴趣特征Vu。
因为自注意力机制平等的对待t时刻之前的每个交互物品,并不包含具体的位置信息,本文使用Vaswani 等[12]的固定位置嵌入方法:

其中I=[I1,I2,…,In]表示位置信息嵌入矩阵。
注意力机制模仿人类眼睛的观察行为,在机器翻译任务等各类自然语言处理任务中证明自注意力机制的有效性,本文采用自注意力机制来构建序列模型[7],对于用户t时刻的短期兴趣具体定义如下:

通过对t时刻之前用户交互物品的聚合,得到用户在t时刻的短期兴趣特征。为了赋予模型非线性并考虑不同潜在维度之间的相互作用,参照文献[7]添加全连接层和多头操作,并对自注意力和全连接层进行叠加,得到用户的短期兴趣Aut。全连接层定义如下:

2.4 社交融合层
2.4.1 社交短期兴趣
当用户u在t时刻对物品i感兴趣时,若他的朋友a最近收藏或购买过类似于i的物品,那么朋友a可能对用户u产生比其他未交互物品i的朋友更大的影响,并且朋友a的很久以前的行为与近期行为对用户u的影响不同。基于以上考虑,提出了具有时间遗忘的注意力机制来对社交短期兴趣进行建模。首先,利用2.3 节中的自注意层得到用户朋友的短期兴趣;然后,利用用户的短期兴趣在朋友的短期兴趣中搜索那些与用户当前兴趣相似的朋友,并根据相似度赋予相应的权重,同时为了使不同时刻的朋友兴趣对用户的影响不同,在相似度权重中加入时间遗忘值,最后根据得到的权重聚合朋友的短期兴趣。具体定义如下:

为了保持物品的有序性,将用户朋友在t时刻之后交互的物品屏蔽掉;并且加入时间因素,当朋友短期兴趣的时间ta距离当前时刻t越远时对当前时刻的用户影响越小。在注意力权重部分加入时间遗忘值,来减少距离当前时刻较远的朋友兴趣的影响,具体定义如下:
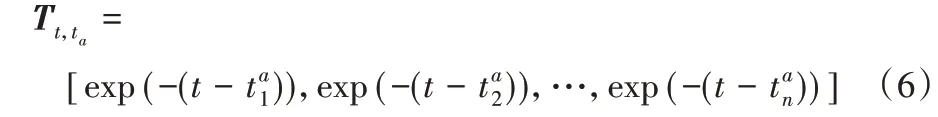
其中:时间t和ta的基本时间单位是周,为朋友a的行为对应的时间。
2.4.2 社交长期兴趣
一般情况下,如果用户u在t时刻喜欢物品i,那么长期与物品i交互的朋友能给用户u提供更好的建议。在此基础上提出了具有协同特性的注意力机制对社交长期兴趣进行建模。利用用户的短期兴趣,通过注意力机制在朋友的长期兴趣中查找与用户当前兴趣相似的用户。同时通过杰卡德(Jaccard)相似度系数[19]进一步利用序列信息计算用户与朋友的相似度,并将该相似度加入注意力权重中。具体定义如下:
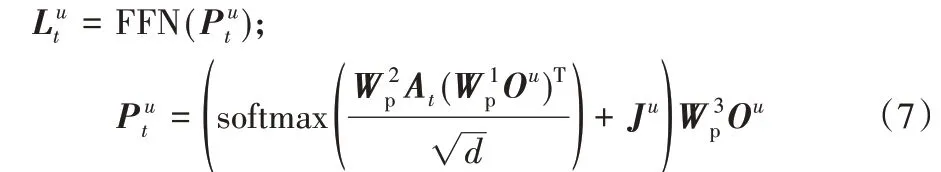
同时考虑用户与朋友之间的总体相似度,加入用户与朋友之间的杰卡德相似度系数来加强那些与用户相似度更近的朋友,杰卡德相似度系数定义如下:

其中:Ru表示用户u交互物品的集合,∩和∪分别表示交和并操作。
为了稳定训练过程并防止过拟合,加入layer Normalization 和dropout 操作[7]。针对2.3 和2.4 节中的任意网络层(注意力层和全连接层),网络层定义为z=y(x),增加层归一化(layer Normalization)和dropout操作后的定义如下:

2.5 预测层
利用式(1)得到用户的下一项推荐Gu t+1根据矩阵分解[20]的思想预测用户在t+1时刻对物品i的喜好程度:

其中hi表示物品i在物品潜在空间的嵌入特征。
2.6 模型训练
将t时刻之前的用户交互物品作为模型输入得到用户在t+1 时刻下一项推荐,用二元交叉熵损失函数[7]作为目标函数,并将用户的t+1 时刻的交互物品作为正样本,用户从未交互过的物品j作为负样本:

其中θ(x)=1/(1+e-x),将预测的喜好程度调整至(0,1)区间。
使用2014 年提出的Adam[21]优化算法,继承了AdaGrad(Adaptive Gradient Algorithm)和RMSProp(Root Mean Square Prop)的优点,具有计算高效、方便实现和较好处理系数梯度等优点。整体算法流程如算法1所示。


3 实验与结果分析
3.1 数据集
使用同时满足序列信息和社交信息的两个公开的隐式反馈数据集brightkite 和Last.FM,将两个数据集的用户交互物品序列按照时间戳进行排序来保证序列性。
brightkite 是一个基于位置的社交网络数据集,用户通过签到来实时共享他们的位置。它包含了从2008年3月21日至2010年10月18日的用户交互记录及用户之间的社交关系。Last.FM 是一个音乐数据集,记录了从2005年8月1日到2011 年5 月9 日用户对歌曲的评价及用户之间的社交记录,详细的数据信息见表2。

表2 数据集详细信息Tab.2 Dataset detailed information
模型主要参数有:batch_lr表示每次训练的用户个数和学习率,maxlen 表示用户的最大交互个数,dropout 表示丢失率,maxfriend表示最大的用户朋友个数。两个数据集的具体参数见表3。

表3 两个数据集的参数Tab.3 Parameters of two datasets
3.2 评价指标
本文使用leave-one-out[7]来对数据集进行分类,将用户的最后一个交互物品作为测试集来评估模型的最终性能,将剩余的交互物品作为训练集。在评估推荐性能时,将测试集作为正样本i,从未交互的物品集合中随机抽取100 个物品作为负样本,将正负样本结合组成包含101 个物品的推荐物品列表,然后利用Top-N指标来评估模型性能。
本文使用的Top-N评价指标为HR@10[22]和NDCG@10[23]。
命中率(HR@10)评估在推荐列表的相似度排名中正样本是否能排在前10,若排在前10则认为命中:

其中:U表示所有用户的集合;lu,i表示正样本i预测评分值在推荐列表中的排序位置;为指示函数表示正样本i的排序位置是否在前10,是为1,不是为0。
NDCG@10 在HR 的基础上加入了位置因素,当正样本的排名越靠前时,推荐效果更好:

3.3 对比方法
为了验证本文的模型,与使用了序列信息的序列推荐模型(BERT4Rec、SASRec)和使用了社交信息的社交推荐模型(DiffNet)进行对比验证。
使用python 对数据进行预处理,利用tensorflow 实现SLSRec 模型,在高性能服务器(CPU 主频2.20 GHz*24,内存126 GB,4 块NVIDIA P100 的显卡及2.7 TB 磁盘)上进行实验。采用早停机制进行实验,一次迭代200 次左右能达到最优推荐结果,训练及评估运行时间在2 h左右。
SASRec[7]2018 年Kang 等提出的一种捕获长期语义的自注意力序列推荐模型。
BERT4Rec[24]2019年Sun等提出的一种序列推荐模型,该模型首次将深度双向顺序模型和完形目标引入推荐系统领域,通过完形任务用双向自注意网络来建模用户行为序列。
DiffNet[25]2019 年Wu 等提出的一种基于社会化推荐的深度影响传播模型,设计了一个分层影响传播结构,以模拟用户的潜在嵌入是如何随着社会扩散过程的继续而演变的,以此来表示用户如何受到递归社会扩散过程的影响。
3.4 实验结果
3.4.1 SLSRec的性能测试
通过在两个数据集上与所有的对比模型的比较来验证本文模型的性能。3.3节中的对比模型都是用tensorflow 来实现的,并且针对两个数据集对各个模型的参数进行了微调。针对DiffNet和BERT4Rec按照模型要求对数据集进行进一步处理,剔除了那些交互个数小于2 的用户,并对剔除后的数据集进行了新的id 映射。因为BERT4Rec 对内存的要求很高,在数据量较大的brightkite 数据集上难以进行验证。各模型在两个数据集上的NDCG@10 和HR@10 的结果如表4 所示,其中最优的结果用加粗表示,次优的结果使用下划线来表示,并在最后一行给出了SLSRec相较于次优结果的提升比率。

表4 不同模型在两个数据集上的结果对比Tab.4 Comparison of results of various models on two datasets
从3.1 节数据集的分析中可以看出,brightkite 数据集中评分数据密度是远远小于Last.FM的,因此从表4可以看出在brightkite 数据集的所有模型的结果要小于在Last.FM 数据集上的结果。本文提出的SLSRec 在序列推荐的基础上加入用户的社交信息,来缓解数据稀疏问题。从表3 可以看出,针对数据密度较大的Last.FM 数据集,SLSRec 在HR 指标上有1.3%的提升,在NDCG 指标上有2.1%的提升,说明SLSRec的推荐结果的命中程度提升不大,但是命中物品的排名更高。相反,SLSRec 模型在数据密度较小的brightkite 数据集中HR指标有8.5%的提升,NDCG 指标有8.9%的提升,说明本文提出的SLSRec能有效缓解数据稀疏问题。
3.4.2 消融实验
从图2 中可以看出,社交融合层分为社交短期兴趣和社交长期兴趣两个部分。同时分别在社交短期兴趣部分加入时间遗忘值,在社交长期兴趣部分加入杰卡德相似度系数。本文通过消融研究分析它们的影响,表5 显示了SLSRec 的默认方法及其4 种结构在两个数据集上的性能。下面分别介绍了变体并分析了它们的效果:
1)Short 结构:表示社交短期兴趣部分,在序列推荐的基础上仅仅加入用户朋友的短期兴趣,可以看出相对纯粹的序列推荐模型该变体的推荐效果还是有所提升。
2)Short+time 结构:相对Short 结构加入了时间遗忘值Tt,ta,通过时间遗忘值来弱化那些相对当前时刻较远物品的影响,从表4可以看出加入时间遗忘值之后推荐效果有所提升。
3)Long 结构:表示社交长期兴趣部分,在序列推荐的基础上仅仅加入用户社交的长期兴趣,相对于纯粹的序列推荐模型有所提升并且提升幅度要大于加入社交的短期兴趣。
4)Long+sim 结构:在Long结构的基础上加入杰卡德相似度系数,在注意力权重的基础上加强那些与用户行为相似的朋友信息,相较于long结构效果有所提升。
5)SLSRec(Short+time+Long+sim)结构:利用α和β来融合Short+time结构和Long+sim 结构,从表5中看出总体效果有所提升。
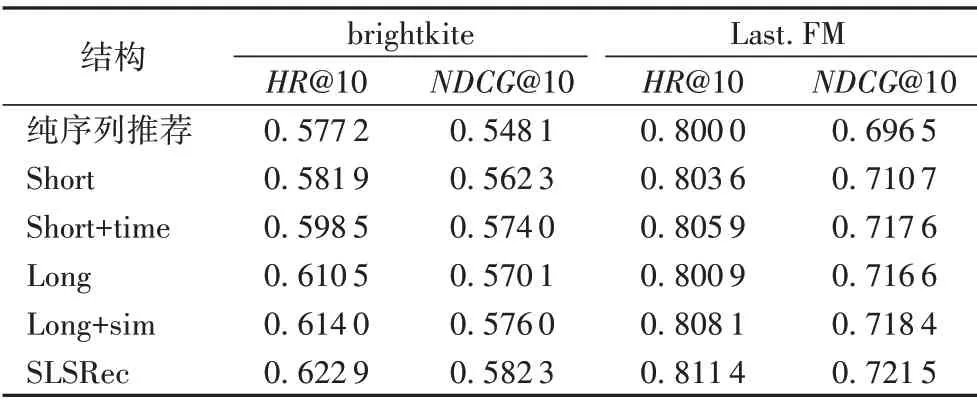
表5 两个数据集上的消融实验分析Tab.5 Ablation experiment analysis on two datasets
3.4.3 社交影响力分析
式(1)中的α和β通过自学习的方式来融合模型中各个因素的比例关系:α值可以反映模型中的用户短期兴趣和社交短期兴趣的权重大小,如果α值越大则社交短期兴趣的权重越大,否则用户短期兴趣的权重越大;β值表示社交长期兴趣的的权重,越小则社交长期兴趣的权重越小。
从图4 可以看出,在数据较为密集的Last.FM 数据集中α都比较低,而在数据较为稀疏的brightkite 数据集中,α的值要远大于Last.FM 数据集中的值,即:用户行为数据越少,社交短期兴趣对用户最终兴趣重构贡献越大。β值在两个数据集基本保持不变,说明社交长期兴趣比较稳定,受到数据稀疏性的影响较弱。

图4 参数α和β的值Fig.4 Values of parameters α and β
3.4.4 最大朋友和最大交互物品的参数分析
图5 展示了最大序列长度maxlen 和最大朋友个数maxfriend 对模型推荐性能的影响,maxlen 主要影响的是序列推荐的结果,maxfriend 主要影响的是社交融合的结果。因服务器内存的大小限制,无法运行maxlen 超过200 和maxfriend超过15的实验。
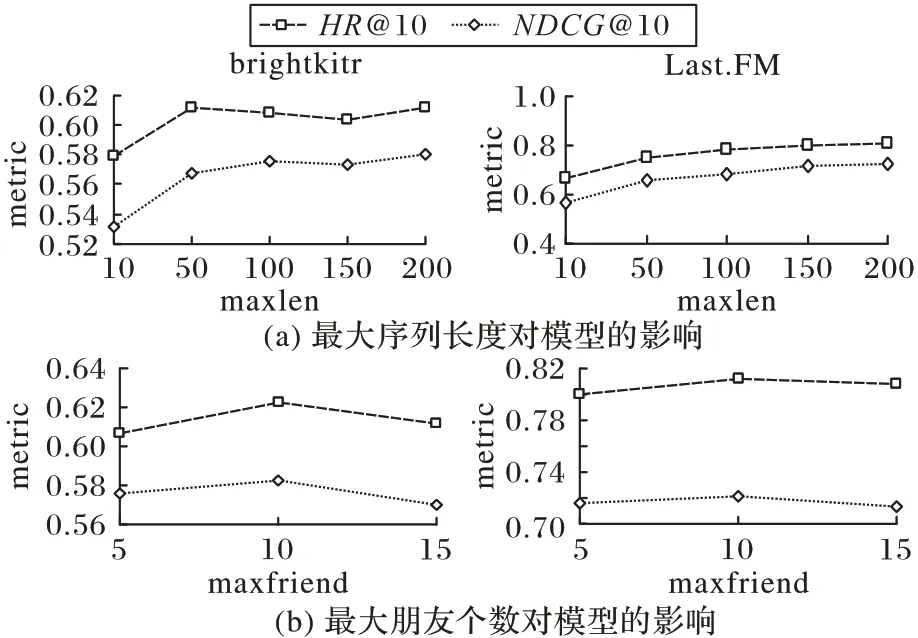
图5 maxlen和maxfriend参数的影响Fig.5 Influence of maxlen and maxfriend parameters
从图5 可以观察到,maxlen 和maxfriend 对推荐结果的影响与数据的密度有关。对于数据密度较大的Last.FM 数据集,maxlen 影响较大,性能曲线呈现整体上升的趋势;maxfriend 影响较小,性能曲线整体比较平稳。在数据较为稀疏的brightkite数据集中,maxlen影响较小,性能曲线整体比较平稳;maxfriend影响较大,性能曲线整体比较平稳。从两个数据集的对比可以看出,本文提出的SLSRec模型在稀疏数据上能更有效地利用朋友兴趣恢复用户兴趣进而提升推荐效果。
4 结语
针对社会化推荐模型忽视用户动态兴趣和朋友对用户影响的动态变化的情况,提出一种社交信息动态融合的社会化推荐算法。首先,利用自注意力机制构建用户短期兴趣;然后,利用具有时间遗忘的注意力机制构建社交短期兴趣,利用具有协同特性的注意力机制构建社交长期兴趣;最后,融合社交的长短期兴趣与用户的短期兴趣获得用户的最终兴趣并产生下一项推荐。在实验部分利用HR@10和NDCG@10指标对模型性能进行评估,结果表明SLSRec 算法在Last.FM 和brightkite数据集上相较于最新的推荐模型推荐效果都有所提升。本文主要利用朋友的一阶关系,没有进一步考虑社交网络中的影响扩散,在下一步工作中将利用GCN 等网络模型来捕获不同时刻朋友兴趣在社交网络中的影响扩散。
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31
小雪花·成长指南(2022年1期)2022-04-09
环球人物(2022年4期)2022-02-22
小资CHIC!ELEGANCE(2021年32期)2021-09-18
小天使·二年级语数英综合(2017年3期)2017-04-01
第二课堂(课外活动版)(2016年2期)2016-10-21
小天使·一年级语数英综合(2015年8期)2015-07-06
读者·校园版(2015年13期)2015-07-01
小学阅读指南·高年级版(2014年2期)2014-05-27
中学英语之友·高一版(2008年10期)2008-12-11
