
使用关联检索缓和推荐系统中的稀疏性问题
2021-11-17 12:38高艳华郭晓坤
计算机仿真 2021年9期
张 洋,高艳华,郭晓坤
(1.中国航天科工二院,北京 100039;2.北京控制与电子技术研究所软件研发中心,北京 100038)
1 引言
随着互联网的快速发展,连接到互联网的服务器数量和WWW上的Web数量呈指数级增长趋势。同时互联网的快速发展为人们提供了大量信息,例如,Netflix拥有成千上万部电影,亚马逊拥有数百万本书,Del.icio.us拥有超过100亿个页面集,因此很多信息不可能一次全部给出。传统的搜索算法仅向所有用户提供相同的有序结果,不能根据用户的不同兴趣向不同的用户提供不同的服务,信息爆炸降低了信息的使用率,这种现象称为信息过载。个性化推荐(包括个性化搜索)被认为是解决信息过载问题的最有效工具之一。从根本上说,推荐系统是替代用户来评估各种产品,包括书籍,电影,CD,Web等,这是一个从已知到未知的过程[1]。
推荐作为一种社会过程,在消费者的许多应用中起着重要作用,因为对于每个消费者而言,独立地了解所有可能的替代方案的成本过高。根据特定的应用程序设置,消费者可能是买家,信息搜索者或正在搜索某些专业知识的组织[2]。
目前,推荐算法主要包括协同过滤算法、基于内容的算法、基于用户产品的二元关系图推荐算法[3]和混合推荐算法[4],在对于稀疏性方面的研究还处于起步阶段。本文着眼于稀疏性和精度问题,通过用户评分之间的相对距离来计算相似矩阵,并创造性地使用关联检索技术,来实现一种新的协同过滤算法,此算法对缓和数据集的稀疏性方面有很明显的效果。
2 协同过滤和稀疏性问题
2.1 协同过滤
协同过滤又称社会过滤,它通过分析用户的兴趣,在用户群中找到特定用户的相似用户,综合这些相似用户对某一信息的评价来形成对指定用户对此信息的喜好程度的预测。
迄今为止,协同过滤是最成功的推荐系统方法,并且已广泛应用于各种应用程序中。其中,Grundy被认为是第一个协同过滤系统[5]。Grundy系统可以建立用户的偏好模型,以向每个用户推荐相关的书籍。 Tapestry邮件处理系统,处理用户之间的相似性。用户越多,精度越低[6]。 GroupLens建立用户的信息组,用户组内的用户可以发布自己的信息,并与其他用户进行协同推荐[7]。 Ringo利用相同的社交信息过滤方法向用户推荐音乐[8]。还有其它一些典型的协同过滤推荐系统,例如Amazon.Com[9],Jester[10],Phoaks[11]等。
协同过滤的推荐系统主要可分成三个步骤:①输入资料表示:将用户过去的行为及兴趣用一个m×n的矩阵R来表示,亦即n个用户层利用m项产品的历史资料,矩阵元素rij则表示第i个用户购买第j个产品。②相似度的建立:是协同过滤推荐系统中最重要的一个步骤,可以计算出用户间的相似程度,以作为将来推荐的依据。③产生推荐:从社群成员中衍生出对目标用户的前n项推荐产品。
大多数协同过滤算法可以分为两类[12]:基于内容的协同过滤算法和基于模型的协同过滤算法。基于内容的协同过滤算法首先从训练集数据库中找到与当前测试用户最相似的用户,然后将这些相似用户给出的评分进行组合以获得对测试用户的预测。两种最常用的方法是Pearson相关和角度余弦。Pearson相关和角度余弦已经应用于许多实例中,例如,缺席投票,案例扩展,加权优势预测等。基于模型的算法首先收集评分数据以进行研究,以此推断用户的行为模型以及对产品进行评分。
但是协同过滤方法也具有几个主要限制,包括稀疏性、可伸缩性和同义词问题。当事务或反馈数据稀疏且不足以标识邻居时,就会出现稀疏性问题,这是一个主要问题,通常会限制建议的质量和协同过滤的适用性。研究重点是即使没有足够的数据,也要开发一种有效的方法来提供高质量的建议。
2.2 稀疏性
在协同过滤系统中,用户或消费者通常由他们购买或评价的物品代表。例如,在电影院中有300万部电影,则每个使用者都由300万个元素的布尔特征向量表示。每个元素的值取决于该消费者过去是否观看过相应的电影。通常,值1到5表示发生了事件,值0表示没有发生这种事件。当涉及多个消费者时,可以使用由代表这些消费者的所有向量组成的矩阵来捕获过去的观看事件。称此矩阵为消费者与产品的交互矩阵。在本文中,用C表示消费者集合,用I表示项目集合。用矩阵R=|C|×|I|=(rij)代表消费者-产品交互矩阵,其中

(1)
在许多大型应用中,物品的数量和消费者的数量都很大。在这种情况下,即使记录了许多事件,消费者与产品的交互矩阵仍然可以非常稀疏,即R中的非0元素很少。此问题通常称为稀疏性问题,对协同过滤方法的有效性产生很大负面影响。由于稀疏性,两个给定用户之间的相似性(或相关性)极有可能为零,从而使协同过滤失效[13]。即使对于正相关的用户对,此类相关度量也可能不可靠。而冷启动问题进一步说明了解决稀疏性问题的重要性。冷启动问题是指新用户或新项目刚刚进入系统的情况[14]。由于缺乏足够的先前评级或购买,协同过滤无法为新用户生成有用的推荐。同样,当有新商品进入系统时,协同过滤系统不太可能将其推荐给大多数用户,因为很少有用户对该商品进行评分或购买。从概念上讲,冷启动问题可以看作是稀疏性问题的一个特殊实例,即消费者与产品交互矩阵A的某些行或列中的大多数元素为0[2]。许多研究人员已尝试缓解稀疏性问题。在文献[14]中,作者提出了一种基于项目的方法来解决可伸缩性和稀疏性问题。另一种缓解稀疏性的方法是降维,旨在直接降低消费者-产品交互矩阵的维。减少维度的一种简单策略是形成项目或用户的集群,然后将这些集群用作预测中的基本单位。也可以应用更先进的技术来实现降维,包括统计技术(例如主成分分析(PCA)[10])和信息检索技术(例如潜在语义索引(LSI))。本质上,降维方法通过生成更密集的用户-项目交互矩阵来处理稀疏性问题,然后使用此精简矩阵进行预测。实验研究表明,降维可以在某些应用程序中显著提高推荐质量,但在有些应用程序中却表现不佳,在此缩减过程中可能会丢失潜在有用的信息[15]。
研究人员还尝试将协同过滤与基于内容的推荐方法相结合以缓解稀疏性问题[16][17]。除了用户项目交互之外,此类技术还考虑了从其内容派生的项目之间的相似性,这使他们可以做出更准确的预测。但是,混合方法需要有关产品的附加信息以及用于计算产品之间有意义的相似度的度量。在实践中,这种产品信息和相关的相似性度量可能很难获得。另一类方法是将数据视为二部图,其中节点代表用户和项目,如果用户i评价过项目j,则在用户i和项目j之间存在一条边(i,j)。此外,边(i,j)的权重对应于i到j的等级。然后使用图形理论测度得出用户或项目之间的全局相似性。例如,将两个用户之间的相似度计算为在图的随机游走中其各自节点之间的平均通勤时间。还研究了其它图形理论量度,例如图形节点之间的最小跳跃距离,以及图形中节点的扩展激活。这些方法的主要缺点是:在预测问题的背景下,通常对相似性度量没有很好的解释[18]。
研究的重点是开发一种计算方法,以探索用户之间的关联来解决稀疏性问题,并在协同过滤的前提下提高准确性。
3 基于关联检索的协同过滤
3.1 关联检索
在文本分析中,关联检索将词语和文档之间的关联关系进行统计和研究。关联检索背后的基本思想是:建立文档、索引项、查询的图模型或网络模型,然后使用该模型探索词语与文档之间的传递关联性,以提高信息检索的质量。这种关系也反映在人们的日常生活中,例如,UA是UB的朋友,UC是UA的朋友,则UB可以向UC推荐电影A,因此,UC和UB之间存在关联关系。发现推荐系统可以利用用户之间的这种关系来解决稀疏性问题。
3.2 通过关联检索找到用户之间的关系
首先假设一个用户集C={c1,c2,c3}包含了三个用户,和一个电影集I={i1,i2,i3,i4}包括了四部电影。R=|C|×|I|代表用户的评分矩阵,包含了3×4=12个元素。

其中行代表用户,列代表电影。例如,第一行代表用户c1观看了电影i2和i4,等级分别为3和4.

从矩阵B的第二行可以发现用户c2观看了电影i2,i3和i4,从矩阵R和矩阵B中很容易发现用户c1和c2都观看了电影i2和i4。根据相似性理论,可以确定用户c1与用户c2相似,因此可以通过用户c2将电影i3推荐给用户c1,但不能将电影i1推荐给c1。以上示例仅包含4部电影,然而当前在线电影提供商超过百万部电影,如果仅通过直接相似度进行用户推荐,就会出现“暗信息”,某些电影将无法推荐给某些用户,无法满足用户的需求。
根据关联检索理论,以用户为一组节点,产品为一组节点,使用二部图表示矩阵B,如图1所示。

图1 协同过滤中的传递关联
根据图1,关联路径的长度假定为3,这里有c1-i2-c2-i3和c1-i4-c2-i3两条路径,电影i3应该推荐给用户c1,但在i1和c1之间没有一个长度为3的路径,所以i1不会推荐给c1。如果路径长度拓展到5,发现电影i1可以通过路径c1-i2-c2-i3-c3-i1和c1-i4-c2-i3-c3-i1推荐给用户c1。
针对以上分析,本文作了一些定义如下:
定义1:直接推荐路径表示某用户直接推荐给目标用户项目。
定义2:间接推荐路径表示某用户通过一个或多个用户推荐给目标用户项目。
定义3:用户直接相似度表示直接推荐路径中用户之间的相似度。
定义4:用户间接相似度表示间接推荐路径中推荐用户与目标用户之间的相似度。
通过以上分析可知,关联检索方法可以探索用户之间的传递,以获得一组路径以及直接或间接的相似度。通过式(2)计算稀疏矩阵中rij的值以解决稀疏性问题。
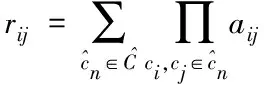
(2)

3.3 计算直接相似矩阵
在用户直接相似度矩阵的计算中,没有使用Pearson相关系数和余弦相似度。通过研究,发现用户观看电影后,无论用户的评分高低,在一定程度上都可以表达用户之间在个人偏好和评分偏好上的相似之处。例如,在矩阵R中,用户c1和c2分别为i2和i4打分,c1的等级为3和4,c2的等级为2和5,可以使用式(3)计算c1和c2对同一电影的相似度等级sim_2(12)=0.8,sim_4(12)=0.8.

(3)
其中max是最大值函数,abs是绝对值函数,R代表评级的集合,例如R={0,1,2,3,4,5},rik代表用户i对产品k的评价值。获得相似度等级后,使用式(4)计算i和j之间的用户相似度

(4)
注意到,m为产品数量。以评分矩阵R为例,用户相似度aij=(0.8+0.8)÷4=0.4,根据此方式,可以得到用户相似度矩阵Asim如下
接下来,结合关联检索和直接相似度矩阵进行计算,以便在获得用户相似度矩阵后获得推荐矩阵。
3.4 计算推荐矩阵
使用3.2节提供的数据推荐给用户c1。当M=3时,从数据中可以发现c1有两个推荐路径c1-i2-c2-i3和c1-i4-c2-i3。根据3.3节的相似度矩阵,c1和c2之间的相似度为0.4,路径权重为0.4;因此得到i3的相关度是0.4×2=0.8; 由于c1和c2具有最高的相似性,因此c2对i3的评分值为3,因此推荐值为0.8。当M=5时,有两个推荐路径c1-i2-c2-i3-c3-i1和c1-i4-c2-i3-c3-i1,权重为a12×a23=0.4×0.25=0.1,相关度的值为0.1×2=0.2,用户c3对i1的评分为4,所以推荐值是0.2×4=0.8。
推荐矩阵Martix_R定义为
其中R是评分矩阵,Asim是相似度矩阵,B是标记矩阵。利用3.2节的数据,通过式(4),在M=3和M=5时,可以分别得到推荐矩阵Matrix_R3和Matrix_R5
3.5 算法介绍
基于关联检索的协同过滤算法:
输入:用户评分矩阵R,路径长度M
输出:推荐矩阵
步骤1、B=R, 如果rij≠0,那么bij=1
步骤2、设置迭代次数N=1
步骤3、原始推荐矩阵Matrix_RN=R
步骤4、根据式(3)和(4)计算直接相似矩阵Asim
步骤5、将矩阵B转置BT
步骤6、根据式(5)计算矩阵Matrix_RM
步骤7、如果N+2
4 实验与分析
4.1 实验数据集
使用推荐系统的标配实验数据Movielens数据集。数据集包含了943位用户对1682部电影的100,000个评分,评分区间为1-5,每个用户至少评价了20部电影,稀疏度为99.937%。
4.2 实验过程
对于每个目标消费者,检索了之前查看过的全部商品,并按查看日期将它们分类。这些项目的前90%作为训练数据集输入,通过不同的方法产生建议。为了进行比较,这些项目的后10%作为客户的预测数据集,并被隐藏在推荐系统中。
在实验中,比较了基于Pearson相关系数推荐、基于余弦相似度推荐和本文所提出的方法。使用准确率(Precision)、召回率(Recall)、覆盖率(Coverage)和F值(F-Measure)来衡量给定推荐方法的有效性,这些方法在信息检索和推荐系统研究中被广泛接受。
● 皮尔逊相关系数(Pearson Correlation Coefficient简称PCC)
皮尔逊相关系数方法预测用户x对项目i的评分为:

(5)


(6)
● 余弦相似度(Vector Similarity简称VS)
该方法与PCC非常相似,不同之处在于相关系数sim(x,y)的计算公式为:

(7)
准确率(Precision)、召回率(Recall)、覆盖率(Coverage)和F值(F-Measure)的定义如下:

(8)

(9)

(10)

(11)
4.3 实验结果
在实验中,将提出的方法称为AR-CF(基于关联检索的协同过滤)。根据Movielens数据集对于AR-CF,PC和COS算法分别计算准确率,召回率和F值。在AR-CF中,M的值为3。表1、图2至图5是上述三个算法在准确率、召回率、F值和覆盖率上的综合比较。
在准确率方面,AR-CF与PC相比增长了18.40%,比COS增长了33.48%;在召回率方面,AR-CF与PC相比增长了17.55%,与COS相比增长了66.78%。在F值方面,AR-CF与PC相比增长了18.29%,与COS相比增长了34.23%;在覆盖率方面,AR-CF与PC相比增长了4.66%,与COS相比增长了24.78%。综上所述,AR-CF在准确率、召回率、F值和覆盖率方面都有了很大的提高。还发现,在稀疏情况下,COS的表现最差。在覆盖率方面,AR-CF仅比PC增长4.66%。还进行了另一个实验,结果表明,当M=5时,覆盖率可以增加10%以上,计算的开销大大增加,但是推荐精度的增加却很小。本文认为覆盖率降低的原因有两个,一方面是因为M的值为3,另一方面,实验数据集的稀疏程度可能还不够。

表1 综合比较

图2 预测准确率的比较

图3 F值的比较

图4 召回率的比较

图5 覆盖率的比较
5 结论
本文旨在缓解稀疏性问题来提高协同过滤系统中的推荐精度。使用关联检索技术缓解稀疏性问题,并提出了一种新的协同过滤算法以提高推荐精度;使用Movielens数据集中的数据通过第4章实验,得到AR-CF算法在推荐过程中是可以正常运行的,论证了该方法的有效性;通过实验表明,与标准协同过滤方法相比AR-CF算法的准确率、F-值、召回率和覆盖率都有了明显提升,该方法缓解了稀疏性问题,并获得了更好的推荐质量。同时,本文提出的方法也存在问题。这些系统利用的数据量将随着时间的推移继续增加。在这种情况下,此方法将导致数据过载问题。最终,它将对协同过滤推荐器的可伸缩性提出重大挑战。因此,在接下来的研究中,将考虑协同过滤推荐器的可伸缩性问题。
猜你喜欢
技术与创新管理(2020年5期)2020-10-09
商情(2020年24期)2020-06-30
科学与财富(2019年27期)2019-10-25
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
读与写·教育教学版(2017年10期)2017-11-10
科学与财富(2017年28期)2017-10-14
读者(2017年5期)2017-02-15
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
