
基于可解释学习的物联网安全通用入侵检测系统
2021-11-24 06:49魏明锐
绵阳师范学院学报 2021年11期
魏明锐
(安徽农业大学经济技术学院,安徽合肥 230011)
0 引言
物联网是一个由互联设备组成的生态系统,每个设备都嵌入了计算工具,如传感器或处理单元,以通过互联网收集、存储和交换数据[1].然而,保护物联网网络安全已经成为实施此类网络的主要挑战之一[2].网络入侵检测系统(NIDS)旨在保护数字物联网网络免受网络威胁[3].传统NIDS旨在分析传入的流量特征,并将它们与已知的攻击特征之一进行匹配.这种方法对已知的攻击具有很高的检测精度,但是它无法检测到物联网网络中看不见的威胁,即零日攻击.因此,研究人员应用新兴的机器学习技术来学习和检测网络流量的有害模式,以检测入侵[4].在这一领域已经进行了大量的学术研究,开发了许多基于机器学习的NIDS算法,当应用于某些数据集时,大多达到了较高的检测精度.然而,这种系统在网络中的实际部署数量非常少[5].主要原因是缺乏对基于机器学习的内部NIDS操作的理解[6]和不可靠的评估方法[7].目前,基于机器学习的网络入侵检测系统是作为一个复杂的“黑盒”提供的,它在某些数据集上取得了很好的检测结果.机器学习模型的复杂性使得它们很难解释所做预测背后的基本原理.因此,在入侵检测等高度敏感的领域,组织不愿意相信机器学习决策[6].因此,可解释的人工智能方法被应用于现代系统,以解释和解释机器学习模型所做的决定.通过理解和修改影响模型决策的因素,可解释的模型输出可以帮助维护和排除基于模型的NIDS部署的故障.此外,在此类系统的评估阶段使用的数据集通常是用一组独特的数据特征生成的.提出一个标准特征集,该标准特征集允许使用一个公共特征集跨多个数据集评估所提出的系统.然而,在提出的基于网络流的特征集上,机器学习模型的性能从未与跨多个数据集的另一组特征进行过比较.因此,本文旨在通过三个数据集比较由CICFlowMeter[8]设计的特征集和的NetFlow特征集.这将允许使用跨多个数据集的NetFlow(网络流量)和CICFlowMeter特征集对建议的机器学习模型进行可靠评估.此外,通过使用SHAP解释方法计算每个特征的Shapley值,已经解释了由机器学习分类器获得的分类结果.这将有助于识别模型预测中使用的关键特征.
1 可解释的网络入侵检测系统
在基于机器学习的NIDS的设计已经涌现出了大量工作,并且达到很高的准确度.然而,与其他领域相比,该方法的错误成本要高得多.因为NIDS的运作要求在任何时候都是最佳的,以避免出现安全隐患.机器学习通常被认为是一种“黑箱”技术,在这种技术中,人们不清楚学到了什么模式,也不清楚为什么要做出预测.在基于机器学习的NIDS环境中,模型训练、预测和将网络流量分类为攻击类别的方式通常很神奇.因此,很多机构不愿意实现基于语言模型的工具.有多种原因,如数据源、数据特征、类不平衡和不准确的数据集,会对机器学习模型做出的预测产生巨大影响.这使得理解和深入了解机器学习内部运营和决策变得至关重要.
上述动机导致了可解释学习该研究领域的出现,其目标是分析和解释机器学习模型的内部操作.因此,将可解释学习的技术应用于基于机器学习的NIDS,对于通过增加对机器学习的信任来缩小广泛的学术研究和操作部署之间的偏见就显得尤为重要.解释机器学习模型检测结果的一种方法是确定哪些网络数据特征有助于分类器的决策,这就意味着确定分类器使用数据集的哪些特征来区分良性样本和攻击样本至关重要.首先,它有助于识别哪些包含安全事件的特征应该在模型设计层面考虑.另一方面,定位出那些仅包含有限数量安全事件的特征,且从数据集中省略.此外,模型的分类决策将基于这些特征的值来加以证明.这有助于排除模型预测错误导致的不良影响.因为它允许安全专家分析导致误分类的特征值.在获得这些信息后,可以进一步调整模型参数和所利用的特征.
(1)
通过计算每个特征的贡献程度来解释模型的决策将有助于揭示机器学习的“黑箱”.本文利用Shapley值来解释网络数据特征在网络攻击检测中的重要性.Shapley值是由Lloyd Shapley在1953年发明的,这是一种根据玩家对游戏总支出的贡献来分配玩家支出的方法.Shapley值背后的理论已经在机器学习领域中采用,其中“游戏”代表数据集中单个样本的预测任务.“支出”是一个样本的实际预测减去所有样本的平均预测.“玩家”是合作获得“支出”的样本的特征值.总的来说,Shapley值是特征值各自贡献的加权平均值.Shapley值(Øj)通过等式1定义,其中S是模型使用的特征的子集.x表示数据集样本的特征值向量,p是总特征数.每个xj是j = 1的特征值,...,.p和valx(S)是子集S中特征值的预测.
SHAP解释是由Lundberg和Lee开发的一种常见的可解释人工智能技术.它基于一种计算Shapley值的附加特征重要性方法,称为核SHAP和树SHAP.与其他可解释学习方法相比,SHAP方法具有很强的理论基础,可以用来解释任何机器学习模型的输出.SHAP提出的新方法显示出比其他方法更高的性能.KernelSHAP是一种基于核的Shapley值计算方法,受用于解释任何机器学习模型的局部代理模型的启发.树形图用于解释基于树的机器学习模型,如决策树、随机森林和额外的树,通过利用它们内部的“树”结构来加速解释过程.当实现时,SHAP通过基于每个特征对预测过程的贡献计算每个特征的重要性来解释每个数据样本x的预测.等式2定义了由SHAP指定的解释,其中g是机器学习模型.z'∈{0,1}M是所用特征的联合向量,M代表最大联合大小,Øj∈R是特征j的Shapley值.当使用SHAP来确定特征重要性时,具有较大Shapley值的特征更重要.SHAP计算数据集内每个要素的平均重要性.
(2)
2 数据集
控制数据集信息的网络数据特征对机器学习模型的最终质量有很大的影响[10].需要这些特征来表示足够数量的安全事件,以帮助模型的分类任务.为了可靠地评估基于机器学习的NIDS性能,需要使用相同的特征集在多个数据集上对模型进行评估.多个数据集将有助于评估模型对不同攻击类型和网络环境的检测的泛化能力.目前,NIDS数据集具有不同的特征集,这些特征集通常彼此完全不同.然而,当模型部署在实际网络上时,提取这些信息是不可行的.因此,跨多个数据集使用单个特征集在模型设计中至关重要,这增加了评估的可靠性和潜在部署的机会.NIDS数据集需要在表示的信息方面相似,以促进可靠的实验.数据集表示的信息由组成数据集的网络要素的选择决定.由于数据集作者在选择网络要素时已经应用了他们的领域知识,因此大多数可用的数据集都由一组几乎唯一的要素组成.
通用特征集支持跨不同数据集和攻击类型的机器学习模型的可靠实验评估.目前,共有四个NIDS数据集共享一个基于网络流的公共要素集.这些特征被提议作为在未来的NIDS数据集上使用的标准集.因此,在本文中,由CICFlowMeter工具[8]设计的特征与三个数据集的标准NetFlow特征集进行了比较.作为实验的一部分,CICFlowMeter工具已被用于从ToN-IoT和BoT-IoT数据集提取特征.从数据包捕获文件生成的数据流已经使用标注的真实事件以二进制和多类方式进行了标记.生成的数据集分别被命名为CIC-ToN-IoT和CIC-BoT-IoT提供用于研究目的.所选数据集包括:NFC-CSE-CIC-IDS2018-v2、NFC-ToN-IoT-v2、NFC-BoT-IoT-v2、CSE-CIC-IDS 2018、CIC-ToN-IoT和CIC-BoT-IoT将允许对跨多个网络环境和攻击类型的两个常见特征集的机器学习实验进行评估.它还将综合评估这两个特征集,并比较启用机器学习模型进行入侵检测的性能.数据集介绍如下:
(1)CSE-CIC-IDS2018[11].一个著名的NIDS数据集,于2018年在一个涉及通信安全机构和加拿大网络安全研究所的项目中发布.用于模拟网络流量的试验台是以涉及多个部门的组织网络方式建立的.暴力、机器人、DoS、DDoS、渗透和网络攻击等攻击类型都是从外部发起的.数据集包含75个使用CIC FlowMeter-v3工具提取的特征[8].总共有16,232,943个数据流,其中13,484,708(83.07%)是良性的,2,8,235(16.93%)是攻击样本.CIC-ToN-IoT.,其中CICFLowMeter的特征集是从ToN-IoT数据集的pcap文件中提取的[12].CICFlowMeter-v4[8]用于提取83个特征.有5,351,760个数据样本,其中2,836,524(53.00%)是攻击样本,2,515,236(47.00%)是良性样本.
(2)CIC-BoT-IoT.CICFlowMeter-v4[8]用于从BoT-IoT数据集[13]pcap文件中提取83个特征.数据集总共包含13,428,602条记录,其中包含13,339,356条(99.34%)攻击样本和89,246条(0.66%)良性样本.攻击样本由继承自父数据集的四种攻击场景组成,即.DDoS、DoS、侦察和盗窃.
(3)NFC-CSE-CIC-IDS 2018-v2[7].CSE-CIC-IDS 2018数据集[11]已使用nProbe[14]转换为43个基于NetFlow的要素,以生成NFC-CSE-CIC-IDS 2018-v2.流量总数为18,893,708,其中2,258,141(11.95%)为攻击样本,16,635,567(88.05%)为良性样本.有六种攻击类别,如暴力、机器人、DoS、DDoS、过滤和网络攻击.
(4)NF-ToN-IoT-v2[7].基于2021年发布的43个NetFlow特性生成的物联网数据集.这些特征是使用nProbe[14]从原始母(ToN-IoT)数据集[12]的pcaps文件提取的,该数据集由澳大利亚网络安全中心(ACCS)在Cyber Range实验室生成的.攻击数据流总数10,841,027(63.99%)和6,099,469(36.01%)是良性数据流,总计16,940,496个样本.有九种攻击类别,分别是后门、拒绝服务、拒绝服务、注入、MITM、密码、软件、扫描和XSS.
(5)NF-BoT-IoT-v2[7].2021年发布了一个新生成的基于43个NetFlow特性的物联网数据集.这些特征是使用nProbe[14]从原始数据集的pcaps中提取的,原始数据集被称为BoT-IoT,由ACCS的网络实验室生成[13].它包含37,763,497个标记的网络数据流,其中大多数是攻击样本;37,628,460(99.64%)和135,037(0.36%)为良性.数据集中有四种攻击类别,即.DDoS、DoS、侦察和盗窃.
3 评价
在实验过程中,深度前馈和随机森林分类器被用来对数据集中存在的网络数据流进行分类.目的是评估CICFlowMeter格式(CSE-CIC-IDS2018、CIC-BoT-IoT和CIC-ToNIoT的三个数据集以及它们各自的NetFlow格式(NF-CSE-CIC-IDS2018-v2、NF-BoT-IoT-v2和NF-ToN-IoT-v2)的数据集.此外,将利用SHAP方法对结果进行分析和解释,以确定有助于模型最终预测的关键特征.为了避免对攻击设备和受害设备的学习偏见,丢弃了源/目标入侵防御系统和端口.此外,也删除了时间戳和流标识特征,因为它们对于每个数据样本是唯一的.最小-最大定标器用于归一化0和1之间的所有值.使用几个二进制分类指标来对结果进行量化评估,例如准确度、F1分数、检测率(DR)、误报率(FAR)、曲线下面积(AUC)和预测单个数据样本所需的预测时间(以微秒计).为了公平评估,进行了五次交叉验证,并测量了平均结果.
为了评估,深度前馈和随机森林分类器被设计为将数据集样本分类为攻击和良性两种类别.表1和表2分别列出了使用随机森林和深度前馈分类器的六个数据集的攻击检测结果.两种分类器通过增加容积率和降低容积率,在NF-CSE-CICID 2018-v2数据集上获得了比CSE-CIC-IDS2018数据集更高的检测精度.导致分别使用随机森林和深度前馈分类器的F1分数从0.93增加到0.98和从0.90增加到0.97.这证实了的.随机森林分类器在ToN-IoT和BoT-IoT数据集的NetFlow和CICFlowMeter特征集上获得了非常相似的检测结果.在这两个数据集中,F1分数从0.99增加到1.00.FAR从CIC-ToN-IoT的1.22%降至NF-ToN-IoT-v2的0.58%,从CIC-BoT-IoT的1.53%降至NF-BoT-IoT-v2的0.25%.在这两个数据集中,NetFlow特性比CICFlowMeter特性需要更少的预测时间.深度前馈模型在NF-ToN-IoT-v2数据集上的检测率(DR)显著提高,达到95.37%,而在CIC-ToN-IoT数据集上的检测率为92.29%,这导致F1评分从0.94提高到0.96.这也是NFC-BoT-IoT-v2数据集的NetFlow功能中的场景,与CIC-BoT-IoT仅95.99%的检测率相比,该数据集实现了99.54%的高检测率.
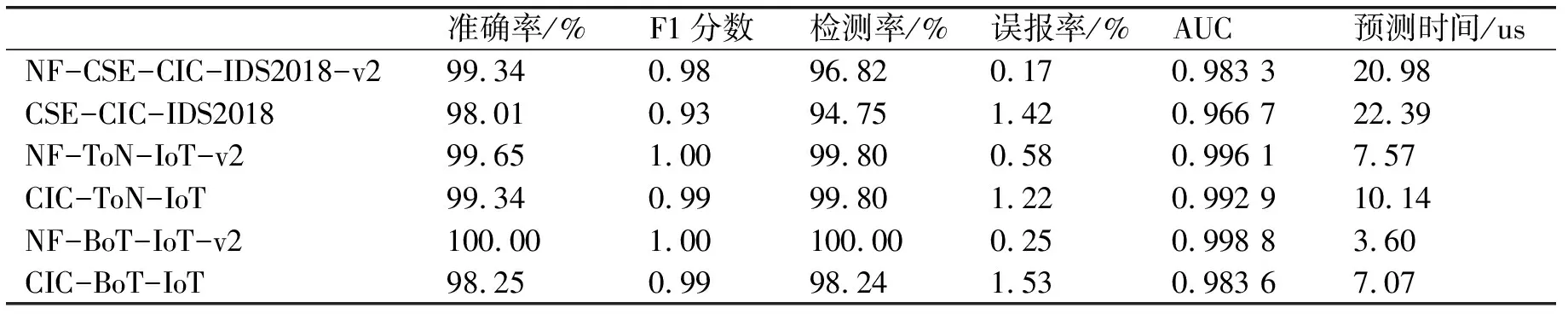
表1 随机森林的分类结果
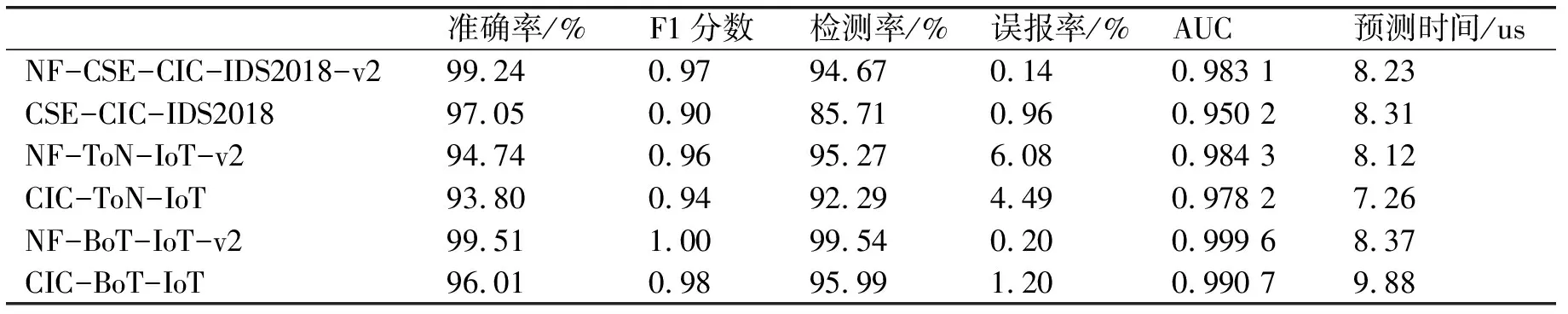
表2 深度前馈网络的分类结果
与CICFlowMeter特征相比,NetFlow特征所需的预测时间更短,这可以用组成数据集的特征总数更少来解释.较高的攻击检测率和较低的误报率表明基于网络流的特征包含更多或更高质量的安全事件,有助于机器学习模型进行有效的网络入侵检测.总的来说,不断提高的检测精度表明提出的网络流特征集能够更好地帮助机器学习模型识别所有三个数据集中存在的攻击.图1直观地展示了在攻击检测场景中使用NetFlow特性集与CICFlowMeter特征集相比的优势.图1a和1b分别基于随机森林和深度前馈分类器对结果进行了分组.图中显示,与CICFlowMeter特征相比,NetFlow特征在三个数据集上始终获得更高的F1分数.
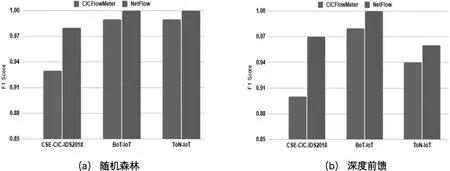
图1 在三个NIDS数据集中两种特征集的分类性能
当使用NetFlow特征集对机器学习模型的检测精度进行训练和评估时,机器学习模型的检测精度的不断提高证明了在NIDS方向对其进行标准化的优势.NetFlow特征集支持两种机器学习模型:深度前馈网络和随机森林,遵循深层次和浅层次的学习结构,在针对不同网络环境设计的三个数据集上实现可靠的性能,并包含大量不同的攻击类型.在BoT-IoT和ToN-IoT数据集上,CICFlowMeter的结果稍差,在CSE-CIC-IDS2018数据集上,检测攻击的效率在一定程度上较低.此外,NetFlow特征集的另一个优点是,与包含83个特征的CICFlowMeter相比,它包含的特征较少,只有43个.较少数量的特征将有助于增强网络的特征提取、分析和存储操作.最后,NetFlow特征自然存在于网络数据包的报头中,不需要额外的任务来收集,不像CICFlowMeter特征包括基于总和、最大值、最小值、标准偏差和平均值计算的统计测量特性,这在实时高速网络中是不可行的.
4 结果分析
在本节中,将利用SHAP技术对上述结果进行解释和分析.SHAP用于筛选出有助于最终预测的特征,并因此确定机器学习模型的分类性能.Shapley值定义了每个数据样本的特征值对最终结果的贡献程度.平均Shapley值是所有测试样本的Shapley值的平均值.Shapley平均值越高,表示该特征值对模型最终预测结果的影响越大.因此,Shapley值越大的特征越值得我们去分析和研究.前20个特征的平均Shapley值如图23所示(本文仅列出CSE-CIC-IDS2018和NF-CSE-CIC-IDS2018-v2两个数据集上的可视化结果).Y轴特征基于它们在用于评估机器学习模型的整个测试数据样本中的平均Shapley值(X轴)结果进行排序.每个图都显示了分别由随机森林和深度前馈模型的KernelSHAP和TreeSHAP方法确定的平均Shapley值.为了直观且有效的进行比较,平均Shapley值已被标准化为从0到1的取值范围.由于相似的特征集和攻击类型,本节将对每个数据集的结果分别进行分析.

图2 CSE-CIC-IDS2018数据集中前20个特征的Shapley值分布图
在图2中,CSE-CIC-IDS2018数据集的特征已经通过它们各自的平均Shapley值进行了排序.图2a和2b分别解释了随机森林和深度前馈分类器的结果.使用随机森林分类器时,包含与流前进方向相关的安全事件的特征构成了影响模型决策的前四个特征.特别是“Fwd Seg Size Min”(前向分段大小最小值)特征对结果的影响几乎是其他任何特征的两倍.随机森林分类器似乎给特征分配了相对分布的权重,导致Shapley值逐渐减小.然而,深度前馈分类器通过常规操作,根据特征的重要性程度为不同特征分配不同的权重,因此Shapley值急剧下降.导致前十个特征对模型的决策有几乎占据了大部分的影响.前两个特征分别表示每秒前向和后向数据包的数量,随后是“Fwd Seg Size Min”(前向分段大小最小值)特征,这是影响随机森林分类器的主要特征.
图3a和3b分别解释对比了使用随机森林和深度前馈分类器在NF-CSE-CIC-IDS2018-v2数据集上的攻击检测性能.两个分类器的前20个影响特征中有13个共同特征.这表明它们包含关键的安全事件,可用于检测NFC-CSE-CIC-IDS 2018-v2数据集中存在的攻击.常见特征主要包括基于传输控制协议(TCP)和生存时间(TTL)的特征.“TCP_WIN_MAX _OUT”分别是深度前馈和随机森林分类器中影响最大的第一个和第二个特征,它表示从目的主机到源主机的最大TCP窗口.总的来说,深度前馈分类器为特征分配权重的特性可以从Shapley值的急剧下降现象中看出,前10个特征对分类器的决策结果占据了绝大部分的影响.
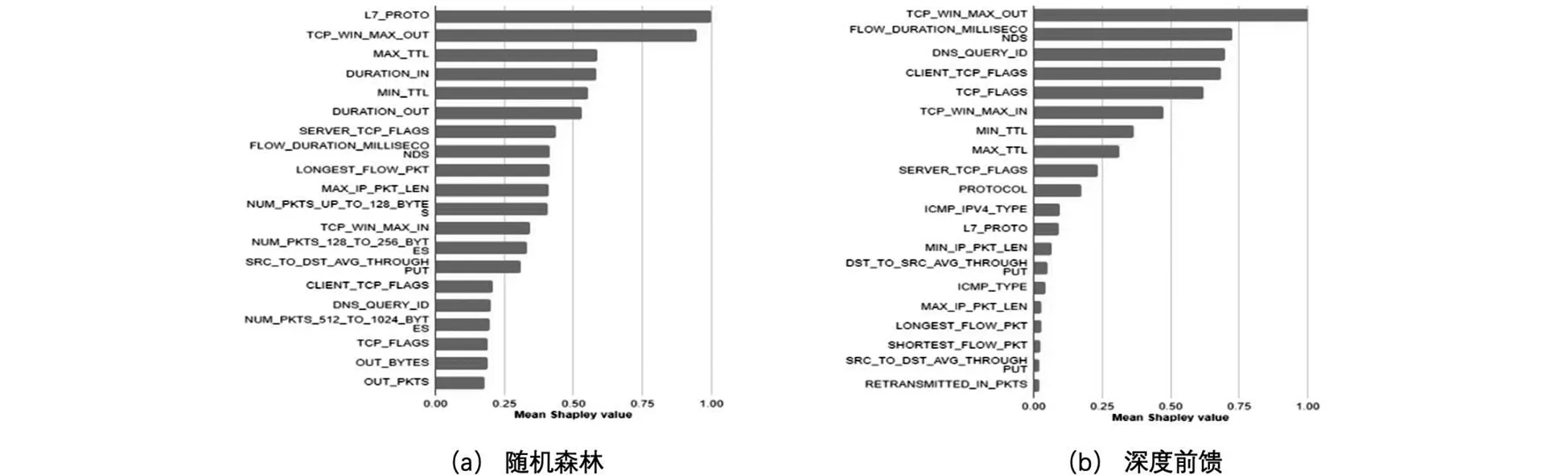
图3 NF-CSE-CIC-IDS2018-v2数据集中前20个特征的Shapley值分布图
5 结论
基于机器学习的网络入侵检测系统在研究界取得了卓越的攻击检测性能.然而,应用在实际部署的规模一直不足.对跨多个数据集的公共特征集的有限评估以及对分类结果的解释行不足均导致了将研究结果转化为产品的失败局面.本文对所提出的基于网络流的特征集进行了评估,并与CICFlowMeter设计的特征集进行了比较.在三个数据集上使用两种机器学习分类器分别进行了评估.通过这种评估方式表明了在NIDS数据集上拥有通用特征集的重要性和必要性.由机器学习模型生成的分类结果表明网络流特征在三个数据集上的一致性影响.其中深度前馈和随机森林分类器在更短的预测时间内实现了更高的攻击检测精度.此外,SHAP方法通过测量特征重要性来解释机器学习模型的预测结果.已经为每个数据集确定了影响模型预测的关键特征.
猜你喜欢
环球时报(2022-07-13)2022-07-13
电子产品世界(2022年4期)2022-04-21
环球时报(2022-03-14)2022-03-14
计算机研究与发展(2022年1期)2022-01-19
计算机系统应用(2021年2期)2021-02-23
计算机应用(2020年12期)2020-12-31
计算机应用与软件(2020年1期)2020-01-14
计算机测量与控制(2019年4期)2019-05-08
电影(2018年8期)2018-09-21
文苑(2015年9期)2015-09-10
