
基于BERT的因果关系抽取
2021-11-26 08:47左万利
吉林大学学报(理学版) 2021年6期
姜 博, 左万利,2, 王 英,2
(1. 吉林大学 计算机科学与技术学院, 长春 130012; 2. 吉林大学 符号计算与知识工程教育部重点实验室, 长春 130012)
自然语言处理(natural language processing, NLP)中的关系抽取是人工智能相关领域中的重要研究方向. 其中, 因果关系抽取作为自然语言和人工智能领域中的重要问题目前已得到广泛关注. 因果关系, 即表示“原因”与“结果”之间的对应关系. 实际应用中存在大量的因果关系, 如新闻报道: 截至2020年9月18日16时01分, 全球〈e1〉新冠肺炎〈/e1〉确诊超3 000万例, 导致943 433人〈e2〉死亡〈/e2〉. 标签〈e1〉和标签〈e2〉间的实体存在因果关系.
传统因果关系抽取方法通常基于模式匹配[1]、机器学习[2]等方法, 文献[3]提出了一种新型朴素Bayes模型, 可从文本中提取显式因果关系. 传统模式下因果关系抽取方法的特征选择繁琐复杂、抽取模式较固定, 从文本中抽取的因果关系精确度较低. 近年, 人们开始使用深度学习的方法研究因果关系抽取, 一般从以下3个角度研究: 给定实体对判断是否包含因果关系, 给定文本判断是否包含因果关系分类和识别并标记包含因果关系的文本. 文献[4]通过卷积神经网络(convolutional neural network, CNN)识别文本中的因果关系并进行了分类; 文献[5]通过融合对抗对学习对文本中的因果关系对进行抽取; 文献[6]通过双向长短期记忆网络(bidirectional long short-term memory, BiLSTM)标记出文本中的原因、结果, BiLSTM模型能获取跨度较大的数据特征, 标注数据更准确. 现有的序列标注方法有隐Markov模型(hidden Markov model, HMM)[7]、条件随机场 (conditional random field, CRF)[8]等. 文献[9]将BiLSTM+CRF 模型应用到序列标注任务中, 目前已成为序列标注任务中的主流模型; 谷歌基于自然语言的特点, 提出了一个基于注意力机制的Transformer网络框架[10]; 文献[11]使用深度学习网络与self-ATT机制相结合的方式进行序列标注, 取得了比模型BiLSTM+CRF更好的实验效果; 谷歌基于Transformer框架, 又推出了BERT[12](bidirectional encoder representations from transformers)模型, 将BERT应用到下游任务中, 可得到表征能力更强的预训练字向量, 使得同一单词在不同的文本中可具有不同的特征表示. 通过这种方式, 可在一定程度上弥补因果关系领域数据数量不足的缺陷, 使模型训练的更充分.
本文针对因果关系抽取领域缺少公开数据集, 并且没有统一标注规则的问题, 从SemEval系列数据集选取5 485条一因一果关系相关数据并制定规则重新标注; 并将BERT应用到因果关系抽取领域. 本文采用BERT+BiLSTM+CRF模型, 以序列标注的方式进行因果关系抽取, 挖掘事件之间引起和被引起的关系, BERT的加入在一定程度上解决了因果关系数据集样本特征信息不足和语义特征表示不充分的问题.
1 BERT+BiLSTM+CRF模型结构
1.1 BERT
BERT[12]即Transformers[10]的双向编码表示, 其模型特点是利用大规模、无标注的语料训练, 获得包含文本丰富语义信息的表示. 本文采用BERT作为本文模型的核心部分, 挖掘因果关系特征信息.
1.1.1 Embedding表示

图1 BERT预训练语言模型Fig.1 BERT pre-trained language model
由于计算机只能处理由数字0,1组成的序列, 无法直接读懂文字, 所以需将文字转化成数字, 这种表达方式称为词向量. 传统的词向量word2vec[13-14],glove[15]模型不能解决一词多义的现象, 一个词语只有一种词向量表示方式, 如“苹果公司于今年推出了iphone12”和“烟台苹果今年产量大增”中的“苹果”含义不同, 前者表示公司名称, 后者表示水果, 但由于传统词向量只能表示其中一个意思, 因此使模型准确率下降. BERT[12]模型解决了该问题, 其通过使用三层Embedding表示使得一个词语可用多个向量形式表示.
BERT结构如图1所示, 其中E1,E2,……,EN为模型的输入部分, 通常为单词. 输入部分传入到双向全连接Transformer层生成词向量. BERT的Embedding由Token Embedding,Segment Embedding,Position Embedding三部分构成: Token Embeddings表示词向量; Segment Embeddings对句子进行编码, 用于刻画文本的全局语义信息; Position Embeddings 对位置信息进行编码, 记录单词顺序这一重要特征, 实现对不同位置的同一个字或词的区分. 3个向量相加为每个Token的最终向量, 如图2所示.

图2 BERT的Embedding表示Fig.2 Embedding representation of BERT
1.1.2 Transformer Encoder
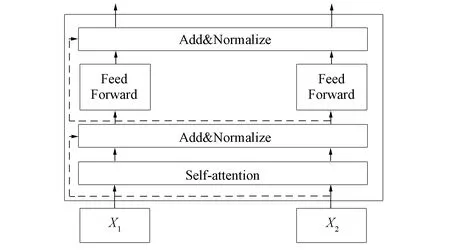
图3 Transformer结构Fig.3 Structure of Transformer
Transformer是组成BERT的核心模块, 每个Transformer单元主要由Self-attention组成, 其结构如图3所示. Transformer使用Self-attention代替了传统的循环神经网络(RNN), 将输入句子中的每个词和整个句子的全部词语做Attention, 获得词语间的相互关系, 记录不同词语间的关联程度, Attention计算方法为
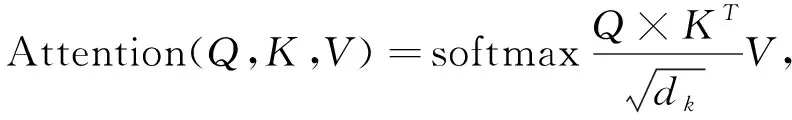
(1)
其中Q表示索引,K表示键,V表示值.
输入句子经过Self-attention计算后, Transformer增加后续3次操作, 使得任意两个单词距离为1. 1) 残差连接: 将模型输入输出相加, 其结果作为最后输出; 2) 归一化: 将指定层神经网络节点进行均值为[0,1]的标准化方差; 3) 线性转换: 将每个字的增强语义向量进行两次线性变换, 用于增强整个模型的表达能力. 其中, 变换后的向量和原向量长度相同, 从而解决了传统神经网络的长期依赖问题.
1.2 BiLSTM
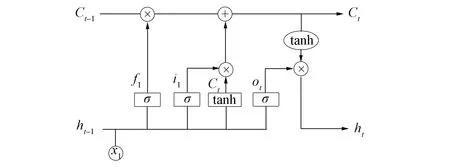
图4 LSTM结构Fig.4 Structure of LSTM
在序列标注和命名实体识别任务中, 通常使用循环神经网络解决标注问题. 但由于神经元之间参数共享, 因此当序列较长时会出现梯度消失等情况. 而长短期记忆网络(long short-time memory, LSTM)通过引入门结构和记忆单元, 将RNN中反向传播过程中连乘的求导形式转换为求和, 最终可以捕捉到长距离的依赖信息, 并避免了梯度弥散等情况. 其整体结构如图4所示.
1) 在遗忘门的帮助下决定细胞状态丢弃信息, 用公式表示为
ft=σ(Wf·[ht-1,xt]+bf);
(2)
2) 更新细胞状态为
3) 确定输出内容, 输出为
Ot=σ(Wo·[ht-1,xt]+bo),
(6)
其中:σ表示Sigmoid函数, 输出[0,1]内的数值; ×符号表示数据间的点乘;ht-1表示上一时刻的输出;xt表示当前时刻的输出;Ct-1表示上一时刻的细胞状态.
1.3 条件随机场
条件随机场[8](conditional random field, CRF)是在给定一组随机输入变量s的条件下, 输出一组随机变量l的条件概率分部模型. CRF通过记录相邻单词的约束关系, 对输入数据进行预测, 用公式表示为

(7)
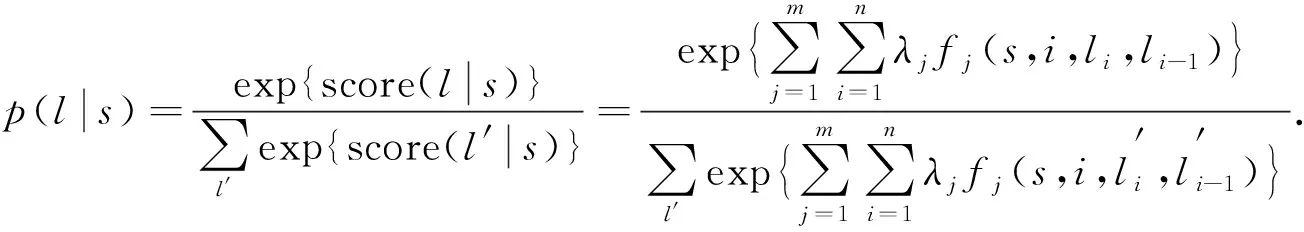
(8)
通过上述过程可建立一个条件随机场. 首先, 通过预先定义特征函数集, 每个函数的参数是整个句子s、当前位置i、i对应的标签以及i-1对应的标签; 其次, 为每个函数对应一个权重λi; 最后, 对于每个标注序列l, 先将全部特征函数进行加权求和, 再将其转化为概率值, 概率值最高的标签确定为预测结果. 经过上述计算, 即完成了对数据标注因果标签的预测.
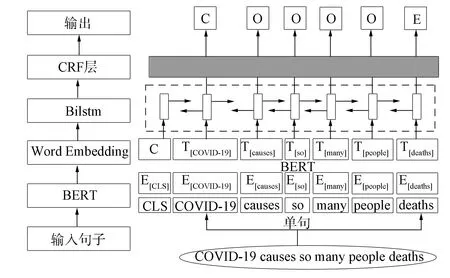
图5 BERT+BiLSTM+CRF的因果关系抽取模型Fig.5 Causality extraction model of BERT+BiLSTM+CRF
1.4 BERT+BiLSTM+CRF模型
本文提出的BERT+BiLSTM+CRF的因果关系抽取模型结构如图5所示. 由图5可见, 模型主要由BERT预训练层、BiLSTM神经网络层、CRF分类层三部分构成. 首先, 将BERT置于模型最底层, 输入包含因果关系的句子, 转换成单词序列, 通过BERT将单词转换成动态词向量, 达到一词多义的效果, 提升词向量的表示能力; 其次, 通过BiLSTM层记录文本序列上的依赖关系; 最后, 传递到CRF层完成对文本中因果关系的抽取, 为句子中的每个单词预测因果标签.
2 数据集
2.1 数据来源
本文实验数据集为SemEval 2007 Task4,SemEval 2010 Task8和SemEval 2020 Task5, 共选取了SemEval 2007和SemEval 2010中的1 368个句子, SemEval 2020中的2 485个句子, 维基百科中1 632 个句子进行人工标注, 最终得到5 485个一因一果的句子. 本文以5∶1∶1的比例将数据分为训练集、验证集和测试集.
2.2 数据标注规则
1) 将原因标注为C, 结果标注为E, 非因果词和标点符号标记为O;
2) 对于由多个单词联合构成的原因或结果, 只选择一个因果核心词进行标注.
以句子COVID-19 causes so many people deaths为例, 其对应的标注标签如表1所示.

表1 标注示例
3 实 验
3.1 参数设定
实验优化器选为Adam; 学习率为2×10-5; 迭代次数为100; 词向量维度为768维.
3.2 实验评估标准
本文用粗粒度抽取3种标签“原因”(C)、“结果”(E)、“其他”(O)的精确率P、召回率R和F1值评定模型性能. 以标签为单位, 实验判断单词属于“原因”(C)、“结果”(E)还是“其他”(O). 本文重点关注标签“C”(原因)和“E”(结果)的3种指标得分.
3.3 对比模型
为验证本文BERT+BiLSTM+CRF模型抽取因果关系的性能, 选择8个模型做对比实验, 其中包括4个基准模型: CRF,LSTM,LSTM+CRF,BiLSTM和4个主流模型: BiLSTM+CRF,BiLSTM+self-ATT,BiLSTM+CRF+self-ATT,L-BL. 将每个模型的标签修改为C,E,O, 与本文提出的模型标注方式保持一致. 采用粗粒度下的P,R,F1值对模型识别3种标签的效果进行评估.
3.4 实验结果与分析
粗粒度抽取“C”,“E”,“O”标签的P,R,F1值列于表2.
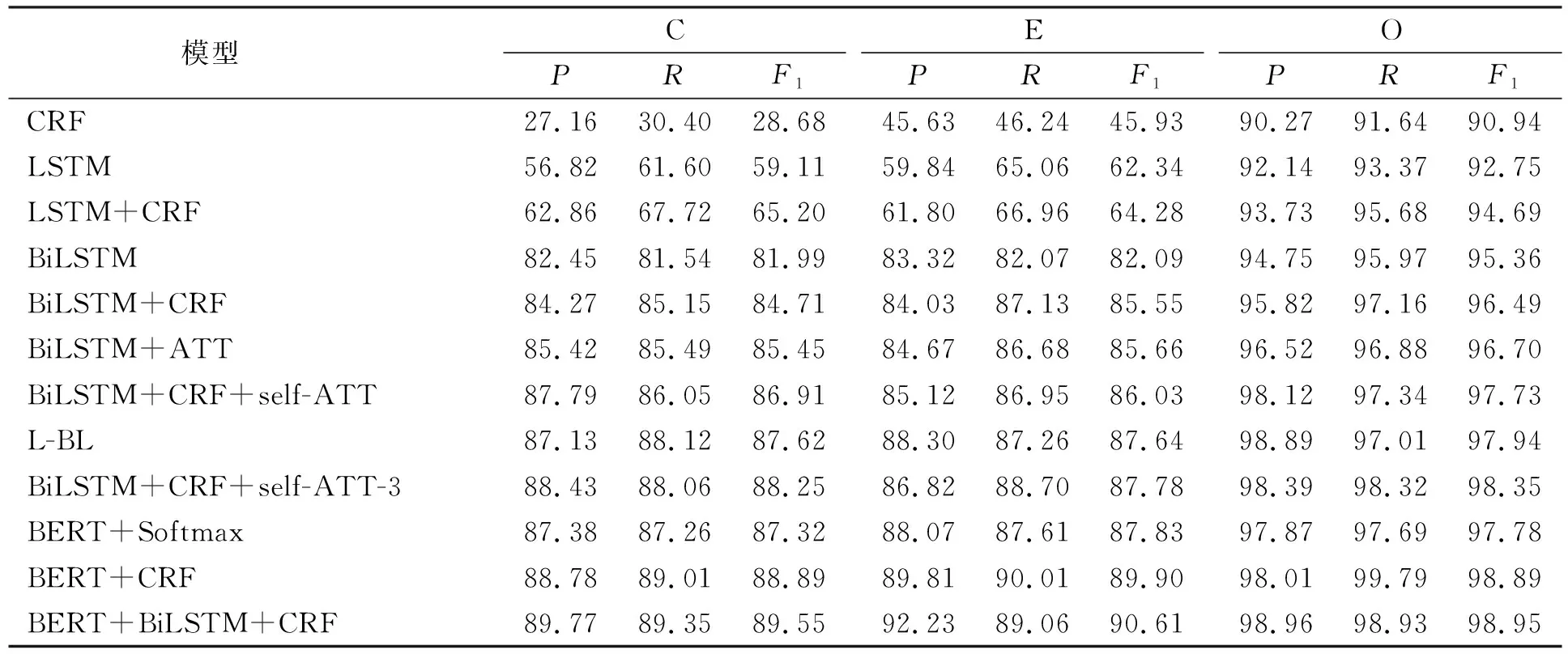
表2 不同模型3种标签的准确率(P)、召回率(R)和F1值评分实验结果(%)
由于本文重点关注了文本中因果关系的研究, 故分析指标时, 重点关注C(原因)和E(结果)的各项粗粒度指标, 分析本文提出的模型对使用本文定义标注句子中的C(原因)和E(结果)性能的影响. 由表2可见: 本文提出的模型BERT+BiLSTM+CRF在自建的因果关系领域数据集(Semeval-CE)上有较好的识别效果, C(原因)的粗粒度P值达89.77%,R值达89.35%,F1值达89.55%; E(结果)的粗粒度P值达92.23%,R值达89.06%,F1值达到90.61%; 在Semeval-CE数据集上, 对比实验模型中, BiLSTM+CRF+self-ATT-3模型粗粒度下C,E,O的指标分别取得了最高的分数. 本文在BiLSTM+CRF模型的底层加入BERT预训练模型, 3项评价指标均较主流模型(BiLSTM+CRF+self-ATT-3)有不同程度的提高, 取得了更优的评分, 实验结果提高0.054 1, 并且实验结果远好于其他对比模型. 表明BERT的加入使模型有更强的表征词语能力, 更好地学习到了文本中的因果关系特征信息, 证明BERT的加入为标注文本中包含因果关系的实体提供了帮助, 从而有效地提高了对文本中原因和结果的标注性能.
综上所述, 本文针对现有的大规模公开数据集普遍用于研究所有类型的实体关系, 因果关系标注数量较少且不易识别, 不能很好地研究实体间的因果关系的问题, 以SemEval数据集为基础, 自建了一个较大规模的因果关系数据集SemEval-CE并重新标注. 基于BERT可以使同一单词在不同文本中表现为动态变化词向量的特点, 本文提出了BERT+BiLSTM+CRF的因果序列标注方法, 并在SemEval-CE数据集上进行实验. 实验结果表明, BERT的加入使该模型充分学习了因果的特征信息, 使得粗粒度P,R,F1值3项评价指标均有了不同程度的提高, 实验结果优于主流模型, 从而可以有效抽取文本中的因果关系.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
南大法学(2021年6期)2021-04-19
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
车迷(2018年11期)2018-08-30
高中生·天天向上(2018年7期)2018-07-23
海峡姐妹(2018年3期)2018-05-09
湘江法律评论(2016年0期)2016-06-15
公民与法治(2016年10期)2016-05-17
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
