
人口普查微观记录样本代表性研究
2021-11-26 06:52胡桂华迟璐婕
工程数学学报 2021年5期
胡桂华, 迟璐婕
(重庆工商大学数学与统计学院,重庆 400067)
1 引言
从事人口统计研究的国内外学者,很想获得人口普查微观记录.可是,各国政府统计部门出于普查工作条例规定的微观数据保密及采集微观记录的成本考虑,并不愿意提供研究人员普查微观记录.无论哪个国家,能够获得普查微观记录学者的工作单位通常在该国拥有很高的知名度.明尼苏达大学获得了美国和其他许多国家的人口普查微观数据,清华大学得到了中国2010 年人口普查住户及个人记录.
明尼苏达大学人口中心的IPUMS 数据库,免费为科研工作者提供普查微观记录用于科学与教育研究[1-4].这些微观记录包括姓名、性别、年龄、文化程度、生育、婚姻、出生、死亡、迁移、劳动力参与、职业结构、教育和种族.IPUMS 数据库的数据一般占所在国或地区全部普查微观记录的1%.除美国100%提供普查微观记录给IPUMS 数据库外,其他愿意向IPUMS 数据库提供数据的国家只会提供1%,99%的微观记录不会提供.中国在1982 年、1990 年和2000 年,以住户(含家庭户和集体户)为抽样单位,采取等距抽样方法,按照1%比例向IPUMS 数据库提供普查微观记录.中国国家统计局迄今尚未向IPUMS 数据库提供2010 年1%普查微观记录.
IPUMS 从一些国家的政府统计部门的普查微观记录中抽取1%作为样本,因此存在样本代表性问题[5],需要对这个1%样本进行评估.如果100%普查微观记录进入IPUMS 数据库,就不存在样本代表性评估问题,因为它只可能存在非抽样误差,而不可能存在抽样误差.如果明尼苏达大学人口中心评估这个样本的代表性,就只需要采取一重抽样评估抽取的1%样本的代表性.如果明尼苏达大学人口中心将1%样本微观数据全部给予某个或某些研究人员使用,研究人员也只需要采取一重抽样评估抽取的1%样本的代表性.然而明尼苏达大学人口中心只会给予研究人员1%样本中的很少一部分.如果研究人员要评估他们得到的这部分样本数据的代表性,自然是要采取二重抽样来评估样本的代表性.我们站在使用部分1%样本微观数据的研究人员的角度评估样本代表性,根据第二重样本构造的男女人数估计量及抽样方差估计量做这项工作.
研究人员在决定使用IPUMS 样本普查微观记录之前,很想知悉其对总体的人口普查微观记录的代表性.只有当IPUMS 样本代表性大的时候,才可以用来进行各种统计分析.抽样理论指出[6],代表性大的样本,其内部结构与总体结构一致,能够对总体进行有效的估计,对总体特征做出合乎逻辑的评估.代表性小的样本,其结构偏离总体结构,无法代表总体,所描述的总体特征或推断的总体参数难以反映总体的实际状况[7,8].抽样调查的所有工作都是围绕如何通过设计合理的,适合于目标总体的抽样方式或方法来抽取代表性大的样本来展开的.抽样专家把代表性大的样本称为“好样本”,代表性小的样本称为“坏样本”.抽样调查成功的关键在于抽到代表性大的“好样本”.样本代表性与样本规模是两回事情.样本量大,并不意味着样本代表性一定大,反之亦然.决定样本代表性的因素除了样本规模外,还与总体内部单位变异性、抽样方法、抽样方式和分层变量的选择等等有关.有学者把样本规模当作是制约样本代表性的唯一因素,寄希望于通过扩大样本规模而达到增大样本代表性的目的,把样本当作总体,把样本指标当作总体指标,忽视或从未计算抽样方差.样本代表性与抽样的随机性也不一致.完全按照随机原则抽取的样本的代表性不一定大.相较于简单随机抽样,等距抽样的随机性主要是体现在第一个单位的选择上,因而随机性较差.但由于它在抽样之前对总体单位按照某个标志排列,又每间隔相等距离抽取一个单位,因而其样本覆盖总体,样本代表性大.由于这个原因,抽样专家倾向于使用等距抽样.在实际抽样工作中,美国普查局和其他一些国家的政府统计部门抽取样本时使用等距抽样,计算抽样方差时使用简单随机抽样的抽样方差公式.
目前评估样本代表性的方法主要有三种.一是如果样本严格按照抽样程序抽出,抽到的是概率样本,就认为样本代表性大.二是如果能够找到与总体参数(如人数)很接近的指标(如普查人数),就把依据样本资料估计的结果与总体参数接近的指标进行比较.如果两者之间差异小,就认为样本代表性较大.三是计算抽样误差.抽样误差越大,样本代表性越小.抽样误差公式含有总体未知参数,例如,抽样平均方差中的总体方差未知.在这种情况下,用抽取的样本资料计算的样本方差替代总体未知方差.在抽样调查中,总体参数永远是未知的,无法得到的.如果得到了总体参数,就没有必要进行抽样调查.抽样调查目的就是估计总体参数.较为理想的做法是,把这两种方法结合起来使用,即先确保抽到的是概率样本,再根据估计值与总体参数差异或抽样误差大小判断样本代表性.在评估IPUMS 样本代表性之前,构造总体参数估计量及其抽样方差估计量.要提高样本代表性,必须控制抽样误差.
控制抽样误差的方法有四种.一是增大样本规模.样本规模大,意味着样本接近总体,依据样本估计的总体参数接近总体参数.但是,样本规模大、调查经费、调查时间和调查数据误差也会相应增加.因此,靠增大样本规模提高样本代表性并不是一个好方法.二是在既定样本规模下,选择适合的抽样方式和分层变量,也能减少抽样误差.分层抽样估计精度优于简单随机抽样和整群抽样.分层二重抽样,通过对第一重样本的现场调查确定第二重抽样的分层变量,能提高第二重样本的代表性,进而降低抽样误差.三是选择适当的总体参数估计量.例如,三系统估计量的抽样方差小于双系统估计量的抽样方差.四是尽可能利用与主要变量高度相关且质量高的辅助变量,以提高总体参数估计精度.
从实际使用IPUMS 数据库的人员来看,主要是国内外人口学者,统计学者使用这一数据库的很少.人口学者直接利用该数据库的普查微观记录进行人口统计分析.在分析之前,他们并未考虑样本代表性问题,从未进行样本代表性评估或检验,也未交代样本的获取过程和计算抽样标准误差.我们的研究有望改变这一状况,引起人口学者对IPUMS 样本代表性问题的关注,从而得出合理的分析结论.
在讨论样本代表性问题时,需要特别注意的一个问题是,一个样本是否可用,要由(而且只能由)估计量的精度(用估计量的方差或置信区间来描述)来判断.如果样本的使用者觉得估计量的精度是可以接受的,那么这个样本对他来说就是可用的.换句话说,一个样本是否可用,不能一概而论.其一,不同的使用者对精度有不同的要求,此使用者认为可用,彼使用者可能会认为不可用.那么,该样本对此使用者是可用的,对彼使用者却是不可用的.其二,估计不同的指标,各自会有精度要求,此指标估计量的精度可以接受,彼指标估计量的精度可能会不可以接受.那么,该样本对此指标是可用的,对彼指标却是不可用的.
研究有三个显著特点.第一,迄今尚未发现国内外其他学者关注和研究人口普查微观数据样本代表性问题.中国国家统计局每次人口普查后均未发布样本代表性招标课题,课题中标者也未意识到他们得到的普查微观记录样本是否对总体普查微观记录有代表性.因此,本研究不是对已有研究的重复,而是具有独创性.第二,采用分层二重抽样方式抽取样本,并且每重抽样的分层变量并不相同,这确保了样本代表性.第三,在比率估计量构造中,使用第一重样本资料估计作为辅助变量的总体住户人数,而不是像通常的比率估计量那样利用已知的住户人数指标,从而保证了估计量各项指标统计上的一致性,即均为估计量,并且比率估计量的分子和分母均是双重扩张估计量[9-12].
从以上讨论或论证可以看出:本文依据统计抽样理论及美国明尼苏达大学人口研究中心IPUMS 数据库提供的人口普查微观数据撰写而成,采用随机原则抽取样本.如果样本有意识抽取,则难以计算抽样方差和判断样本代表性.对抽取的样本,利用样本人数和抽样权数,使用双重扩张估计量构造总体男女人数线性估计量;为提高总体男女人数估计精度,构造总体男女人数比率估计量;针对男女人数估计量较为复杂的问题,采用Binder 抽样方差估计量近似计算其抽样方差.构造总体男女人数估计的置信区间;为便于读者理解.利用微观数据演示计算公式的使用方法和给出估计结果.所做的这一切工作,表明我们的研究有充足的抽样理论依据及数据基础.
2 抽样设计
抽样设计包括抽样方式、抽样单位确定、样本量测算、总体参数估计量及其抽样方差估计量构造.
2.1 抽样方式
采取分层二重抽样抽取样本[13-15],每重抽样的抽样单位均为住户.第一重抽样层用h表示,第二重抽样层用g表示.在第一重抽样中,首先获得每一层以住户为单位的抽样框,然后以住户为抽样单位,从层h的住户抽样框中,采取简单随机或等距抽样抽取住户样本,样本量为nh.第h层的住户总数记为Nh,总体的住户总数记为N,第一重抽样层的总层数记为H.在第二重抽样中,对抽取的第一重样本住户进一步分层.例如,按照住户性质(集体户和家庭户)共分为G层,任意层记为g.从每一hg层,编制第一重样本住户抽样框,从抽样框中以住户为抽样单位采取简单随机或等距抽样方式抽取第二重住户样本.美国、中国等为便于组织抽样和提高样本代表性,通常采取等距抽样.在后面的实证分析中,我们采取等距抽样抽取住户样本.
2.2 估计总体男性和女性人数的估计量
首先构造估计总体住户的男性和女性人数的线性估计量和比率估计量,然后构造它们的抽样方差及其估计量.

式(3)的估计量为

式(2)和(4)中的DE 是双重扩张估计量(Double Estimator)的缩写.
如果能够得到主要变量y的辅助变量(如某个住户的所有成员)xi的人数,那么总体辅助变量总人数的估计量^XDE为

使用第一重样本,估计的辅助变量总人数的估计量^X(1)为

使用式(2)和(4),式(5)和(6),构造估计总体男性和女性人数的比率估计量(Ratio Estimator)

式(2)、(4)、(7)和(8)统一写成下面公式

对式(2)或(4),li1=0, li2=yi;对式(7)或(8),

事实上,当li1=0, li2=yi时,式(9)变为
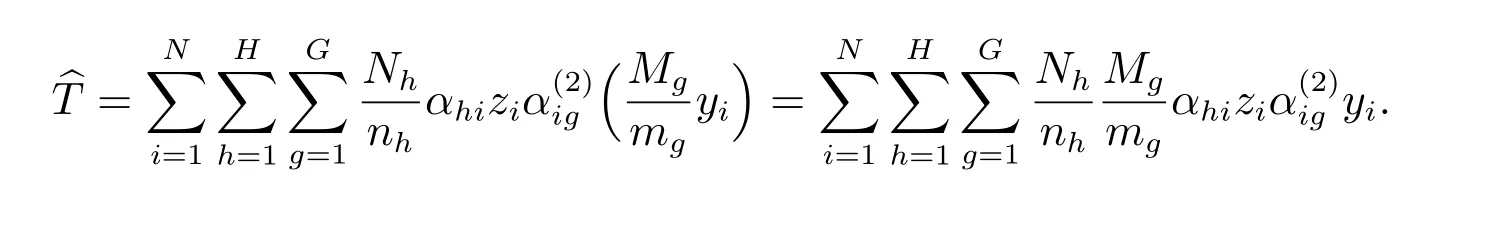

这即为式(7).
可以证明,式(9)中的线性估计量,即式(2)或(4)是下式的一个无偏估计量.
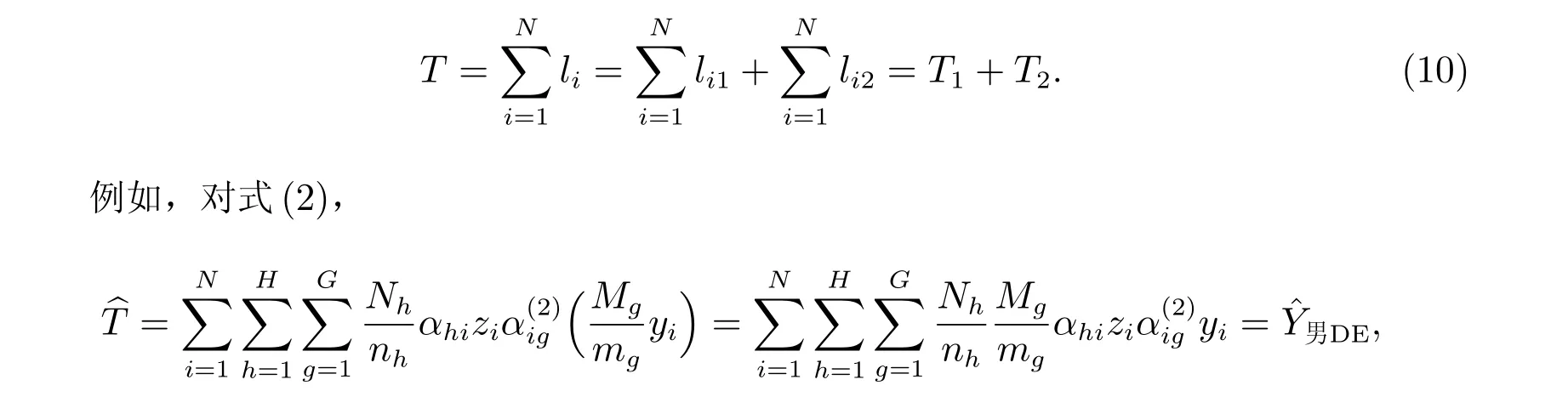

2.3 总体男性和女性人数估计量的抽样方差



从式(20)可以看出,总体男性或女性人数估计量的抽样方差由三项构成(从右向左).第一项表示所有g层的总体总量的抽样方差估计量.第二项表示所有h层的总体总量的抽样方差的估计量.第三项表示所有交叉层hg的总体总量的抽样方差估计量.这三项的总和表示总体的总体总量的抽样方差估计量.
式(2)、(4)、(7)和(8)的抽样方差,除了可以使用Binder 方法外,还可以使用分层刀切法近似计算[19,20]

其中θ为总体参数,未知,其估计量为ˆθ,s为被剔除的普查小区t所在的层,ˆθ(st)为剔除t后重新算得的总体参数估计量,剔除的次数为第一重样本小区的总数目.对式(2)、(4)、(7)和式(8),ˆθ分别为ˆY男DE,ˆY女DE,ˆY男RE,ˆY女DE.
3 估计量的性质
估计男女人数的式(7)和(8)为比率估计量,其比率的分子和分母使用再加权扩张估计量构造.关于比率估计量的性质,抽样估计理论已给出若干成熟结论.比率估计量不是无偏的,但当样本量n很大时,是近似无偏的,或者说这个偏差是可以忽略的.当主变量和辅助变量的相关系数大于0.5 时,比率估计量比简单估计量的精度要高.抽样理论和有关文献研究成果指出,在大样本情况下,比率估计量具有相合性或一致性,在样本量足够大(大于30)使目标变量与辅助变量的变异系数都小于0.1 时,由中心极限定理可知,比率估计量的极限分布近似正态,可按照正态分布总体特征的区间估计,构造比率估计量置信区间.
我们反复查阅国内外抽样调查专著或教材,尚未发现式(2)和(4)这样的分层二重抽样技术条件下的线性估计量是否服从正态分布的结论.因此,我们只能根据已有结论和自己的理解对式(2)和(4)是否服从正态分布做出判断.
估计男女人数的式(2)和(4)为线性无偏估计量,具有一致性和服从正态分布.当样本规模足够大时,比率估计量接近于线性估计量.这表明,线性估计量是比率估计量的一种特殊形式.既然比率估计量近似正态分布,因此,我们推测线性估计量也可能服从或近似服从正态分布.
其实,判断一个估计量是否服从正态分布的较好办法是,从总体中抽取若干个样本,使用估计量计算每一个样本的估计值,将这些估计值与估计值的个数显示在坐标系下,就可以根据点的分布情况,判断估计量是否服从正态分布.在统计学中,均值服从正态分布就是采用这种原始方法判断或显示出来的.
4 实证分析
4.1 资料来源
实证目标是,判断美国明尼苏达大学人口中心IPUMS 提供的1%人口普查微观记录样本是否具有代表性.数据来源于IPUMS 数据库的重庆市2000 年11 月1 日1%的样本普查微观记录.采用分层二重抽样抽取样本.
在第一重抽样中,将重庆市所有住户划分在三个抽样层,即城市层、镇层和乡村层.在每个抽样层,以住户为抽样单位,按照既定抽样程序,等距抽取1%住户样本.第一重样本为重庆市2000 年1%人口普查住户资料,样本量为93181 个住户,来源于美国明尼苏达大学人口中心.该中心从中国国家统计局获取数据.
在第二重抽样中,对第一重样本,按照住户性质进一步分为家庭户层和集体户层.在每一个这样的新层,仍然以住户为抽样单位,在既定抽样程序下,等距抽取住户样本.其中,来源于城市第一重样本的家庭户层和集体户层的样本量分别为200 个和50 个住户;来源于镇第一重样本的家庭户层和集体户层的样本量分别为110 个和15 个住户;来源于乡村第一重样本的家庭户层和集体户层的样本量分别为600 个和10 个住户.为了提高第二重样本住户的代表性,在具体确定第二重住户样本量时,考虑了下述因素:各层住户总数目、样本抽取的随机性、各层住户人数之间的差异、样本中是否包含集体户和家庭户.
对进入第二重样本的每一个住户,未发现单位无答复及内容无答复,也就是应答率为100%,另外明尼苏达大学人口中心对可疑的或错误的普查微观记录做了修正,因而不存在非抽样误差.
从IPUMS 数据库及中国国家统计局公布的2000 年人口普查资料中,我们获得了有关总体及样本资料,见表1 至表3.

表1 重庆市2000 年人口普查汇总数据

表2 样本形成过程

表3 样本住户人数(人)
4.2 实证结果与分析
利用表1 至表3 数据,使用式(2)和(4)估计的重庆市家庭户和集体户的男性和女性人数,见表4.

表4 基于式(2)和(4)的重庆市家庭户及集体户男或女人数估计值(人)
从表1 和表4 可以看出,估计的重庆市家庭户男性人数和女性人数分别为15183516 人和14346299 人,而相应的普查人数分别为15169064 人和14314587 人;估计的重庆市集体户男性人数和女性人数分别为686939 人和372770 人,而相应的普查人数分别为672365 人和356747 人.可见,无论是家庭户,还是集体户,估计的重庆市男性人数和女性人数的估计值均接近于男女普查人口数.可见,样本代表性大.
为了使用式(7)和(8)估计重庆市家庭户及集体户男性人数和女性人数,首先使用式(5)得到重庆市家庭户和集体户人数估计值,见表5.然后利用第一重样本住户抽样权数,使用式(6)得到住户的人口数估计值,见表6.

表5 基于式(5)的重庆市家庭户和集体户的人数估计值(人)

表6 基于式(6)的重庆市家庭户和集体户的人数估计值(人)
表5 和表6 数据来源于辅助信息得到的男女人口数估计值.利用表4 至表6 数据,使用式(7)和(8)计算重庆市家庭户及集体户男女人数比率估计值,见表7.

表7 基于式(7)和(8)的重庆市家庭户及集体户男或女人数比率估计值(人)
表7 表明,利用辅助信息构造的人口数估计量估计的重庆市家庭户男性人数和女性人数分别为15182757 人和14345558 人,估计的重庆市集体户男性人数和女性人数分别为666508 人和361665 人.与表1 比较可以看出,它们均接近于普查人数.因此,样本代表性大.
进一步,比较表4 和表7 发现,利用辅助信息构造的人口数估计量比未利用辅助信息构造的人口数估计量精度高,所估计的人数更加接近于相应的普查人口数,结果见表8.

表8 基于不同公式估计的重庆市男性和女性人数与其普查人数差异(人)
利用式(20)计算重庆市男女人数估计值的抽样标准误差.在95.45%概率把握程度下得到其置信区间,见表9.

表9 基于式(20)的重庆市男女人数置信区间
如果把重庆市2000 年普查人口数作为总体参数(真值),比较表1 和表9 可以看出,表9 的所有置信区间均包括了相应的真值.这表明估计结果接近真值,样本代表性大,估计精度较高.另外,在95.45%的概率保证程度下,依据式(7)和(8)计算的置信区间,比依据式(2)和(4)算得的置信区间都要窄,表明男女人数比率估计量的估计精度更高.
我们使用式(21)抽样方差近似计算公式得到估计的重庆市男女人数置信区间,见表10.

表10 基于式(21)的重庆市男女人数置信区间
比较表9 和表10,以及比较使用分层刀切法和Binder 方法计算抽样方差的过程,我们可以看出两点.一是使用分层刀切法和本文的Binder 方法算得的置信区间存在差异.对同一估计量和同样的样本数据资料,采用不同的抽样方差计算方法算得的结果有差异是正常的.二是Binder 方法的计算量明显小于分层刀切法,这是本文使用Binder 方法原因之一.
5 结论
为估计总体男性和女性人数,构造线性估计量和比率估计量.这两个估计量可以统一写在一个估计量中,采用Binder 方法计算其抽样方差.
作为科研人员,在得到人口普查住户及个人微观记录样本后,所要做的第一项工作是检验其代表性.只有样本代表性足够,才可以使用该样本进行科学研究工作.例如,利用样本资料估计人口普查覆盖误差和内容误差.
即便是国内外知名单位,也难以获得政府统计部门100%的人口普查微观记录,所能得到的是样本普查微观记录.为了使得分析结果反映总体的普查状况,要检验样本的代表性.只有代表性大的样本才能对总体得出可靠的分析结论.分层二重抽样技术适合于检验IPUMS 样本普查微观记录的代表性.
本文利用来源于IPUMS 数据库的重庆市2000 年人口普查微观记录样本,采用相关公式估计的人数与其普查人数的差异很小,抽样误差也小.由于本样本严格按照抽样程序抽出,并且不存在无答复和非抽样误差,样本规模也适中,因此由IPUMS 数据库提供的重庆市2000 年普查微观记录样本对同期全部普查微观记录具有很好的代表性,可以用于各种人口统计分析,为相应政策或计划的制订提供科学依据.
猜你喜欢
河北科技大学学报(社会科学版)(2022年4期)2023-01-06
闽南风(2020年6期)2020-06-23
中国现代中药(2020年2期)2020-04-29
中国建筑防水·悦居(2018年1期)2018-11-08
读书文摘·经典(2018年7期)2018-07-11
青海政报(2017年12期)2017-10-16
——勉冲·罗布斯达
文化遗产(2017年2期)2017-04-22
现代营销·学苑版(2016年12期)2017-01-23
电测与仪表(2015年6期)2015-04-09
数学物理学报(2014年3期)2014-03-11
