
深度学习方法在水稻氮素营养诊断中的应用初探
2021-12-09 00:54姚强粟超李波易婧敬廷桃吕斌
南方农业·上旬 2021年11期
姚强 粟超 李波 易婧 敬廷桃 吕斌


摘 要 为解决传统水稻氮素营养诊断方法需要采集水稻植株叶片,损伤水稻植株,需到指定实验室测定,耗时费力,手持叶绿素仪不稳定、误差大等问题,对使用深度学习方法开展水稻氮素营养诊断开展了初步探索。简介了深度学习模型的建立和训练,对模型识别效果的验证。参与模型训练的水稻样本图片共10 173张,通过调整训练参数,得到多个模型,保留准确率达到80%以上的模型9个,其中返青期3个、分蘖期3个、拔节孕穗期2个、灌浆期1个;对精度最高的返青期模型开展了模型识别效果验证。初步结果显示,使用深度学习方法开展水稻氮素营养诊断有效可行。
关键词 深度学习;数字图像;水稻叶片;氮;营养诊断
中图分类号:S126 文献标志码:A DOI:10.19415/j.cnki.1673-890x.2021.31.029
水稻是我国最主要的粮食作物,全国60%以上人口以稻米为主食。水稻生产在我国农业生产上和粮食安全方面具有举足轻重的地位。氮素是作物生长发育周期中需要量最多的营养元素之一,也是对作物生长、产量和品质影响最为显著的营养元素之一[1]。在种植水稻的过程中,错误地施用氮肥或是施氮经验不足,会使水稻氮素营养失调,从而导致水稻产量和品质的降低[2]。传统的氮素营养诊断以田间采集植株样品、实验室化学分析为主,这种方法在样品的采集、测试及数据处理等方面需耗费大量的人力、物力和财力,时效性差,不利于推广应用[3]。近年来,随着互联网+、大数据、人工智能等新技术的发展和应用,数字农业、智慧农业应运而生,运用数字技术、人工智能技术开展作物氮素营养诊断的研究取得了很多成果。如:李岚涛等应用数字图像技术进行了水稻氮素营养诊断方面的研究[3];吴刚等采用一种基于卷积神经网络的方法对采集的多光谱玉米植株图像进行氮素含量、水分含量等分析识别[4];魏全全等运用数字图像技术对马铃薯氮素营养开展估测及验证[5];魏雪等开展了智能手机图像参数与玉米氮素营养状况关联解析[6];李红军等利用数码相机对小麦冠层进行拍照,分析色彩参数与作物氮素营养状况之间的关系[7]。本文探索采用深度学习的方法开展水稻氮素营养诊断。
1 试验方案及数据采集
1.1 试验方案
试验在重庆市农业科学院高科技园区(九龙坡区白市驿镇高峰寺村)开展。水稻品种为重庆市当前栽培面积较大的主栽品种渝香203。为了产生不同含氮量的水稻植株和群体,为水稻叶片与冠层图像采集和植株氮素含量分析提供样本,共设置7个处理、3次重复。7个处理分别是空白对照、低氮、低中氮、中氮、中高氮、高氮和超高氮,3次重复按设定顺序排列试验区组。试验前对3个重复田块的土壤养分基本情况进行了化验分析(结果见表1)。
试验田小区间设立隔离肥水田埂。各处理施氮量(均为纯N量)分别为:空白对照(0 kg·hm-2)、低氮(70 kg·hm-2)、低中氮(105 kg·hm-2)、中氮(140 kg·hm-2)、中高氮(210 kg·hm-2)、高氮(280 kg·hm-2)和超高氮(420 kg·hm-2)。试验田的水分管理、磷肥和钾肥施用量各个处理保持一致。磷肥施用量(P2O5)为50 kg·hm-2,钾肥施用量(K2O)为100 kg·hm-2。
施肥方式:氮肥按照7∶3的重量比例分2次施入,分别为基肥(7)和分蘖肥(3);磷肥、钾肥作基肥1次性施入,在扬花后期叶面喷施0.5%磷酸二氢钾1次。
1.2 数据采集
试验数据包括水稻图像数据和氮营养含量数据。图像数据作为深度学习算法的输入,氮營养含量数据用于数据集的标定。在水稻的返青期、分蘖期、拔节孕穗期及灌浆期开展图像数据采集,利用国产安卓智能手机获取水稻叶片和冠层图像,每个处理采集100~200幅图像,拍摄角度包含与地面成60°和90°。照片长宽比设置为4∶3,测光方式设置为矩阵测光,ISO模式设置为自动,对焦方式设置为自动对焦(AF-C),图像保存格式为JPG格式。
采集图像数据的同时,对水稻植株叶片进行同步取样,选择长势适中的水稻植株第三完全展开叶作为样本叶片,每个处理采集40~50个叶片(鲜重约200 g)放入提前编号的专用样品袋中,送回实验室进行氮素含量化学测定。
2 深度学习建模、训练
2.1 准备数据集
数据集是深度学习模型的输入,模型的训练和测试围绕数据集开展。好的数据集是丰富的高质量数据的集合。
2.1.1 图像数据归类
在水稻的返青期、分蘖期、拔节孕穗期及灌浆期采集了约10 000幅图像数据,取得处理样本叶片氮营养含量测定结果84个。对3个重复的氮营养含量测定结果取平均值,分别得到各生长期空白对照、低氮、低中氮、中氮、中高氮、高氮、超高氮的氮营养含量值。将同一生长期3个重复采集的图像归为一类,以计算得到的氮营养含量值标定分类,最终将每个生长期的图像划分为7类,每个分类约有图像350幅。
2.1.2 图像处理
在图像采集过程中,会有一些图像因拍摄位置导致水稻图像在整个画面中占比较小,这部分图像会降低模型识别的准确率,因此需要对这部分数据进行裁剪,使水稻图像在整个画面中的占比大于50%。另外,拔节孕穗期及灌浆期的图像会存在部分过度曝光,这部分图像会影响模型的有效性,因此需将这部分图像剔除。
2.1.3 划分训练集和测试集
按水稻生长期将所有图像数据分为4个数据集,每个数据集7个分类,由训练集和测试集组成,训练集用来训练神经网络中的参数,测试集用于客观评价神经网络的性能。从每个分类中随机选取20%的图像数据作为测试集,剩余图像数据作为训练集。
2.2 建立模型
2.2.1 模型设计
基于卷积神经网络构建深度学习模型,模型设计如图1所示。
卷积层和池化层分别设置3层,输入层神经元7个(对应7个分类),神经元激活函数用Relu,分类器使用Softmax。
2.2.2 模型创建
目前流行的深度学习工具有:Keras、TensorFlow、Torch等,其中Keras是使用最为广泛的深度学习工具之一。Keras是一个高层神经网络API,由纯Python编写,将TensorFlow、theano、CNTK等作为底层库进行封装。为了快速搭建实验环境,减少因程序包与包之间的依赖关系造成的大量错误,使用Anaconda结合PyCharm进行搭建,Anaconda版本用Anaconda3-5.3.1,Python版本用3.7.0,TensorFlow版本用2.3.0。
使用Keras创建卷积神经网络模型有3种方法,分别是:使用Sequential API创建、使用Functional API创建、模型子类化。本研究使用Sequential API创建图1所示模型,部分代码如下:
model.add(Conv2D(20,(3, 3), padding="same", input_ shape=shape, name='filter1'))
model.add(Activation("relu"))
model.add(MaxPooling2D(strides=(2,2),name="max1"))
model.add(Dropout(0.5))
# 以上是添加卷积层1和池化层1激活函数是relu
model.add(Conv2D(30, (3, 3), padding="same", name='filter2'))
model.add(Activation("relu"))
model.add(MaxPooling2D(strides=(2,2),name="max2"))
#以上是添加卷积层2和池化层2
model.add(Conv2D(50, (5, 5), padding="same", name='filter3'))
model.add(Activation("relu"))
model.add(MaxPooling2D(strides=(2,2),name="max3"))
model.add(Dropout(0.5))
#以上是添加卷积层3和池化层3
model.add(Flatten())
model.add(Dense(250))
model.add(Dropout(0.5))
model.add(Activation("relu"))
model.add(Dense(classes))
#以上是添加全连接层
model.add(Activation("softmax"))
#以上是添加分类器
2.3 模型训练
分别对4个数据集中的图像开展模型训练,生成模型参数,用于分生长期水稻氮营养诊断。模型训练过程如下。
1)将一个生长期的数据集放入Python项目中。
2)设置训练所需的参数,如图像大小、分类数、batchsize和epoch等。参数设定没有确切的最优值,只能在实验中不断调整以得到更好的模型参数。
3)指定模型优化器、参数名称、训练集扩充方法等。因采集的图像数量有限,为了提高模型的泛化能力,需通过图像旋转、水平平移、上下平移和图像翻转等方法扩充训练集。
4)将图像数据矩阵化。将缩放后的图像数据转化为矩阵形式的数据,便于计算机运算。
5)调用keras.model的fit_generator函数开始执行模型训练,训练过程由计算机自行完成。
3 结果与分析
参与模型训练的水稻样本图片共10 173张,其中:返青期训练样本1 981张,测试样本496张;分蘖期训练样本2 146张,测试样本536张;拔节孕穗期训练样本1 888张,测试样本472张;灌浆期训练样本2 123张,测试样本531张。
3.1 模型精准度分析
模型的精准度受多种因素影响,当测试集图像数据不变的情况下,同一模型在不同训练参数下,模型精准度会有很大的差别。影响训练结果精度的参数包括:batch_size、epoch、learning_rate及圖像缩放比例。
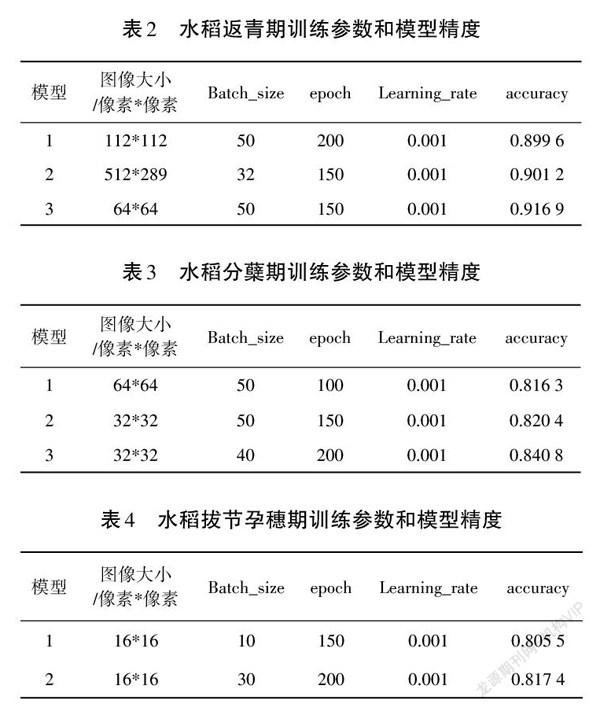
通过调整训练参数,得到了多个模型,保留准确率达到80%以上的模型9个,其中返青期3个、分蘖期3个、拔节孕穗期2个、灌浆期1个。返青期训练参数和模型精度见表2,分蘖期训练参数和模型精度见表3,拔节孕穗期训练参数和模型精度见表4,灌浆期训练参数和模型精度见表5。4个生长期精度最高模型训练时的epoch、loss、accuracy关系分别见图2、图3、图4、图5。
3.2 模型识别效果验证
从每个生长期的图像数据中各随机选取70张图像分别组成各生长期最佳模型的验证集,开展模型识别效果验证,以精度最高的返青期模型为例,验证结果列于表6。
可以看出,低中氮的准确率最低,10张验证图片有7张被识别为低氮。结合叶片样本氮营养含量测定值发现,低氮为33.78 g·kg-1,低中氮为33.71 g·kg-1,两个等次的氮营养含量非常接近,因此导致分类出错,如果根据氮营养含量来划分等次,则低中氮的准确率为90%。高氮准确率不高的原因与低中氮相似。
4 讨论与小结
本研究使用智能手机自带的照相机在可见光下采集水稻各生长期图像数据,应用深度学习的方法探索水稻氮营养诊断的新途径。初步结果显示,该方法有效可行,与采用多光谱图像数据的方法对比,在保证较高准确率的情况下,大大降低了诊断成本;与传统采集植株样本进行实验室测定的方法相比,优势在于对水稻植株的无损诊断;与使用手持叶绿素仪进行诊断的方法相比,优势在于結果稳定、误差小。该方法的难点和不足在于需要针对不同的水稻品种建立各个生长期的图像数据集和深度学习模型。
后续可开发出基于Web的水稻氮营养诊断系统,对水稻图像开展批量诊断。也可将深度学习模型迁移到移动端,开发用于水稻氮营养诊断的手机APP,让用户可以通过手机随时随处开展诊断。
参考文献:
[1] 孙棋.基于数字图像处理技术的水稻氮素营养诊断研究[D].杭州:浙江大学,2008.
[2] 杨红云,罗建军,万颖,等.计算机视觉技术在水稻氮素营养诊断中应用的研究进展[J].中国农学通报,2020,36(16):149-155.
[3] 李岚涛,张萌,任涛,等.应用数字图像技术进行水稻氮素营养诊断[J].植物营养与肥料学报,2015,21(1):259-268.
[4] 吴刚,彭要奇,周广奇,等.基于多光谱成像和卷积神经网络的玉米作物营养状况识别方法研究[J].智慧农业(中英文),2020,2(1):111-120.
[5] 魏全全,李飞,张萌,等.基于数字图像技术的马铃薯氮素营养估测及验证[J].生态学杂志,2021,40(9):3017-3024.
[6] 魏雪,贾彪,兰宇,等.智能手机图像参数与玉米氮素营养状况关联解析[J].生态学杂志,2021,40(8):2656-2664.
[7] 李红军,张立周,陈曦鸣,等.应用数字图像进行小麦氮素营养诊断中图像分析方法的研究[J].中国生态农业学报,2011,19(1):155-159.
(责任编辑:丁志祥)
收稿日期:2021-09-16
基金项目:重庆市农业发展资金项目“手机+图像识别构建水稻氮素营养诊断系统研究”(NKY-2021AB009)。
作者简介:姚强(1981—),男,河南南阳人,硕士,高级工程师,从事农业信息技术、物联网集成开发研究。E-mail:94388062@qq.com。
为通信作者,E-mail:479996341@qq.com。
猜你喜欢
科技资讯(2016年27期)2017-03-01
科技资讯(2016年26期)2017-02-28
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
美与时代·美术学刊(2016年8期)2016-11-09
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
科教导刊·电子版(2016年1期)2016-03-14
