
基于FPGA的极化码译码实现*
2021-12-14 08:38方家鑫刘纯武黄芝平
移动通信 2021年6期
方家鑫,刘纯武,黄芝平
(国防科技大学智能科学学院,湖南 长沙 410000)
0 引言
极化码作为一种新型的编码方式,被Arika[1]提出并证明在二进制对称无记忆信道中,极化码相较于turbo 码和LDPC 码更能达到香农极限,理论上是“最优编码”。近年更是被新兴的5G 纳入其中作为控制信道编码方式,从而吸引了很多学者的关注研究,获得了快速发展。
当前,极化码的译码方式主要有软件和硬件两种途径,但是在软件上由于CPU 是采用串行方式工作的,从而对快速译码带来了极大的制约,而FPGA 由于其具有高速并行计算的特点刚好适用于此。此外,极化码译码本身是采用递归方式进行的,因此在FPGA 里能够实现资源共享,易于实现。
目前,极化码的译码算法主要可以分为两大类。第一类是SC 译码算法以及基于SC 译码算法的改进算法[2-7],主要代表是SCL(Successive Cancellation List,列表连续抵消算法)译码算法,SCL 算法中保留了串行译码的特性,在译码每个信息比特时允许同时保留多个候选路径,通过降低正确路径丢失的概率来改善译码性能。第二类是信息传播算法,将编码领域中的经典算法,如MPA(Message Propagation Algorithm,消息传播算法)应用于polar 码译码。但是在这些常见算法中,许多算法如BP 和ML 译码算法由于运算过程中涉及大量的乘除运算,不利于硬件实现。相较之下,SC 译码器和基于SC 的SCL 译码器当中的“蝶形运算”单元存在非常简单的实现方式,简化后的运算只涉及取符号运算,取最小值运算和加法运算,不含任何乘除法运算,非常适合芯片实现。最后,由于SC 译码算法固有的误差传播现象,前序信息比特的错误会严重影响后序信息比特的译码,这将严重影响译码的性能表现,因此采用基于SC 算法的新型译码方式——SCL,该算法旨在通过引入路径度量值,获得L个译码序列来进行选择,避免SC 那样局限于单一序列的估计,从而提高译码性能。但是由于SCL 译码器本质上可以认为由L个SC 译码器组成,使得其在存储空间、功耗、译码复杂度、时延方面都大大增加。
基于极化码在FPGA 中易于实现的优点和SCL 算法的优越性,本文的主要工作为运用SCL 译码算法,在FPGA 中实现极化码译码器并在运行效率和占用资源等方面有所提升。
1 极化码的SCL译码算法
极化码的基本思想是通过信道极化,使用“好”的信道传输信息比特,而在“差”的信道上放置编译码双方都已知的固定比特即冻结比特,通常设置为0。对于一个(N,K)极化码,N代表码长,K代表信息比特数,其编码方式为:


图1 N=4、L=2时的SCL译码路径示意图

其中,α,β代表上一层的对数似然比值,u代表与当前译码位相关的已译码比特,sgn为符号函数。
2 FPGA中实现算法的优化
采用树形流水线结构后[8-9],PE(Processing Element,处理单元)电路成为译码器的重要组成部分[10],对PE 的改进优化将对整个硬件电路产生极大的影响。常规的PE单元主要包含f节点模块和g节点模块。在f节点模块中包含一个异或单元、一个绝对值比较单元与一个选择器单元。而g模块则较之更加复杂,首先将输入的对数似然比值转换成补码形式,再将转换成的补码输入加法器和减法器,生成带符号位的数值,g模块的输出值由已译码的部分和作为控制选择输出,最后通过一个2 输入选择器决定是输出f模块的结果还是g模块的结果。由此可见,f节点和g节点计算相对独立,整体计算效率较低。为改善此问题,将f节点和g节点关联起来进行计算。对g节点中加法器和减法器运算进行分析,发现sgn(α+β)⊕sgn(β-α)与sgn(β2-α2) 符号一致,而sgn(β2-α2) 正 好对应判断α,β的绝对值相对大小。故可以将g节点中加法器和减法器的结果取符号位进行异或操作,作为f节点绝对值输出的控制端。则此时f节点中2 输入数据选择器的输出m为:

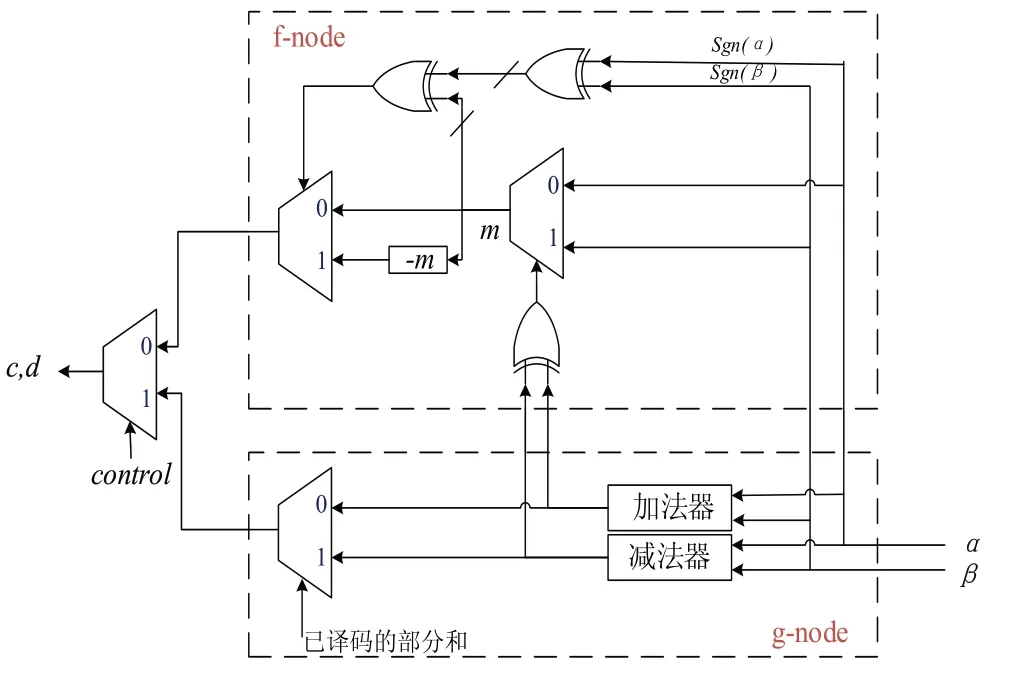
图2 改进后的PE单元结构
此外,由于在对译码器进行译码时,每层的f与g节点的相关计算数值都需要保存下来参与到下一层的计算,因此,这些数据的大小将会影响存储空间资源,故在整个译码器的计算过程中,对存储的似然比值进行量化,缩小数值大小,进而降低硬件资源消耗。这样虽然PE 中涉及的加减运算可能会影响存储所需宽度,但经过量化缩小即可不引入更多消耗,且由于与译码判决相关的是判决层的数值符号,并不受绝对大小影响,因此并不会影响判决结果。
3 译码硬件平台与译码测试结果
在本文的SCL 译码器实现过程中,采用的FPGA 芯片是Xilinx 公司Virtex-7 系列的xc7vx485tffg1157-2。在硬件验证过程中,考虑到FPGA 开发板存储资源有限,在PC 端完成了极化码的编码与信道加扰,然后将接收端得到的信道LLR 量化后传送给FPGA,FPGA 接收到译码信息后开始进行译码工作。
3.1 译码的仿真与测试
首先,为了综合考虑译码误码性能与译码复杂度,需要选取合适的路径数即列表宽度L,在MATLAB 中进行了仿真,结果如图3 所示:
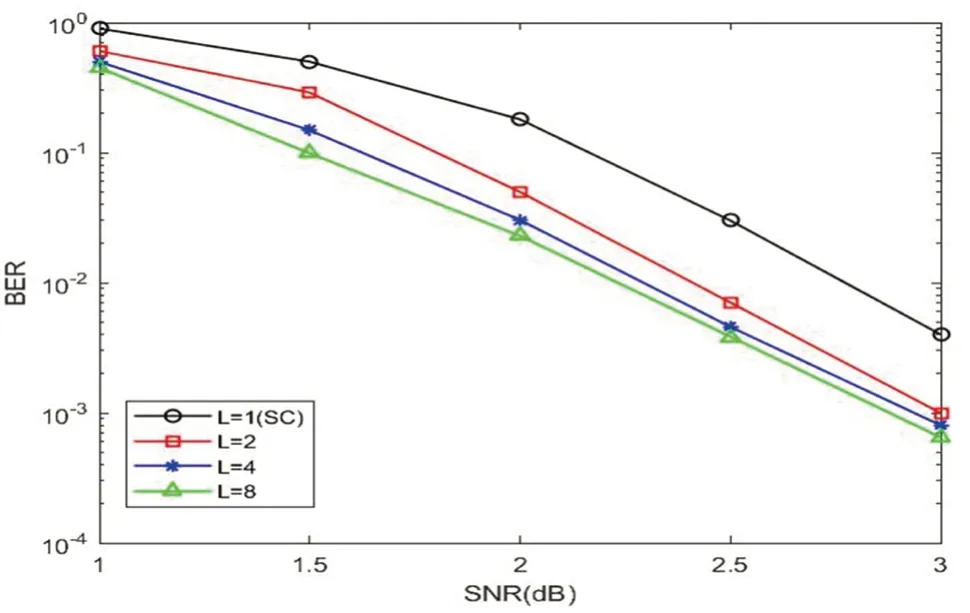
图3 SCL算法L取值不同的误比特率
从图3 可以明显看到,列表宽度L为1 时性能较差,随着列表宽度的增加,误码性能越来越好,但是从图中可以看到L为4 与L为8 的结果相差很小,考虑到实现的复杂度,选择列表宽度为4。接着验证译码器的正确性进行,码字经过polar 编码器进行编码,经过调制,信道传输后,在接收端收到对应的LLR 值,按照译码器设计对这些LLR 值进行处理,通过VIVADO 自带仿真软件modelsim 对译码器进行硬件仿真,然后使用在线逻辑分析仪去抓取在FPGA 上的译码结果。
如图4 所示,上面的图为码长1 024,码率0.5 的极化码采用SCL 译码在modelsim 中的部分仿真结果,data表示译码输出结果。下面的图为在开发板上用逻辑分析仪抓取的FPGA 运行结果波形图,对应实际译码结果,跟源码比较,得出本次译码结果正确。
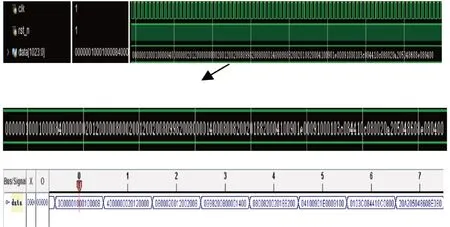
图4 N=1 024时的运行结果
3.2 译码性能分析
使用Vivado 2017 进行综合,在综合报告里可以查看所消耗的资源,如表1 所示:

表1 编码长度为1 024的综合资源结果
对于译码器的硬件设计来说,译码器的纠错能力和吞吐率是评价其性能的两大重要指标。其中吞吐率的定义为:

其中,N代表码长,fmax表示译码的最高时钟频率,tc表示译码所需的时钟周期数,吞吐率计算结果为39.5 Mbit/s。对不同码长的polar 码在FPGA 上进行测试,优化后的SCL译码器和常规的SCL 译码器相比,占用的硬件资源减少了30%以上,译码的最高频率提高了20%左右。对于译码器的纠错能力,将回传的译码结果与原码进行比对,得到经过量化操作后硬件译码的误码率,如图5 所示:

图5 量化操作后的硬件译码误码率
可以看到,译码器在保证译码高效的情况下,译码的误码水平与仿真结果接近,译码性能良好。
4 结束语
如今极化码的相关理论研究日益增多,但是在硬件平台中实现的较少,还有很大的提升空间。基于此本文采用极化码的SCL 译码算法,对其FPGA 硬件实现进行一定改进优化,最后在开发板上进行实现。测试结果表明改进之后的译码器在资源消耗、吞吐率方面有了一定提升,具有很强的工程实用性。
猜你喜欢
现代计算机(2021年36期)2021-03-14
成都信息工程大学学报(2018年4期)2019-01-23
海峡姐妹(2017年10期)2017-12-19
时代英语·高一(2017年5期)2017-11-14
三联生活周刊(2017年33期)2017-08-11
银行家(2017年1期)2017-02-15
新闻传播(2016年3期)2016-07-12
遥测遥控(2015年2期)2015-04-23
电视技术(2014年17期)2014-09-18
电测与仪表(2014年20期)2014-04-04
