
TopPixelLoss:类别不均衡的遥感影像语义分割损失函数
2021-12-21 09:19袁伟许文波周甜
中国空间科学技术 2021年6期
袁伟,许文波,周甜
1. 成都大学 建筑与土木工程学院,成都 610106 2. 电子科技大学 资源与环境学院,成都 610097
1 引言
分割遥感影像获取地理信息数据现已成为主流的地理信息数据获取途径,在诸多项目中得到使用,特别是在大区域的地籍调查、生态监测、地理国情监测等项目中,其优势尤为明显。传统的遥感图像分割主要是依靠像素值的特点函数关系进行计算,将差异较小的像元归属为同一类别,如分水岭算法[1]、主动轮廓模型[2]、统计区域融合[3]、联合多种空间特征的高光谱图像空谱分类方法[4]、基于多特征的遥感图像分割算法[5]等。由于地物存在同物异谱或异物同谱的现象,传统方法的分类效果十分有限。
随着深度学习技术的出现和发展,不少学者将深度学习技术应用到遥感影像分割上,取得了较好的效果,如对房屋的提取[6]、对道路的提取[7]。但是多数都集中在对房屋、植被等的提取上,这类地物的特点是在图幅中的占比较大。而在遥感解译中,小目标的检测、分割也是实际生产的需求之一,如对于大海中舰船的检测或分割,路面汽车的检测或分割,输电塔的检测或分割等。
小目标分割时,由于背景与前景存在明显的不均衡,背景往往大大多于前景,致使损失函数由背景主导,分割效果不佳。针对这个问题,文献[8-10]通过对数据集进行重采样的方式达到样本类别相对平衡,但是会破坏数据的分布和丢失信息;文献[11-12]通过修改交叉熵损失函数的形式来增强网络识别小类别的能力;文献[13]通过先目标检测再将检测到的区域单独用网络进行分割后修改原图。
现有的方法均考虑所有的像素来计算交叉熵损失值,这样会导致前景较少时被背景所淹没。本文提出一种仅考虑部份交叉熵较大的像素来计算损失值,有效避免了上述问题,提高了占比较少的前景分割精度。
2 TopPixelLoss的计算方法
交叉熵是用来衡量两幅图像的相似程度的,现有的损失函数是对所有像素的交叉熵求加权平均,做为最终的损失函数值。对于类别占比较为均衡的情况,只需对所有像素求平均,得到最终的损失函数值,就能得到较好的分类效果,即

(1)
式中:y'为预测为前景的概率值;y为标签值;LCrossEntropy为每个像素的交叉熵;Loss为最终的损失值。对于类别不均衡的数据,采用对所有像素交叉熵求平均的形式,会导致占比较少的类别被占比大的类别所淹没。例如一个二分类图像有100像素,汽车所占像素只有2个,那么即使这2像素分类全错,所有像素均预测为背景,那么准确率仍然可达98%。因此文献[12]提出了FocalLoss损失函数,对每个像素按前景和背景赋予不同的权重,然后再求所有像素交叉熵的均值作为最终的损失函数值。每个像素的交叉熵计算方法如下:
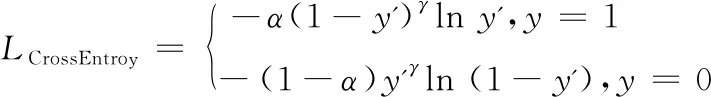
(2)

(3)
随着训练的进行,这些差异大的像素交叉熵将逐渐变小,差异小的像素交叉熵自然更小,因此这部份交叉熵较大的像素可以覆盖交叉熵较小的像素。
如表1所示,从混淆矩阵可以看出,像素的分类情况为4类,第1类是实为前景预测为前景的TP,第2类是实为前景预测为背景的FN,第3类是实为背景预测为前景的FP,第4类是实为背景预测为背景的TN。其中,FP和FN是分类错误的情况,TP和TN为分类正确的情况。对于损失函数来说,应该着重关注分类不正确的情况,也就是FP和FN。从交叉熵大小来说,FP和FN的交叉熵必然大于TP和TN。因此,筛选出交叉熵大的像素,也就是分类错误的像素来求取损失函数值,可以避免错误分类的小目标被大量分类正确的像素淹没的情况。

表1 二分类混淆矩阵
TopPixelLoss损失函数的具体计算步骤为:
1)将预测图像与真实标签图像进行逐像素的比较,计算出每个像素的交叉熵。
2)将所有像素的交叉熵按从大到小进行排序。
3)确定一个K,按此阈值筛选出前K个交叉熵最大的像素。
4)对于筛选出的K个像素交叉熵取平均,作为最后的损失值。
由于采用以折代曲过渡的方案,因此,每块玻璃的外形尺寸都不相同,需设定一套完整的标识系统,该标识系统应能充分体现玻璃的安装位置、方向及正反面等信息内容。标识系统制定原则如下:(1)将玻璃骨架编号,然后玻璃分块跟着骨架进行编号,以明确安装位置;(2)玻璃统一在左上角做标识,以明确安装方向;(3)编号及安装方向标识均标记在玻璃正面,以明确玻璃安装方向。
3 试验数据预处理及评价指标
3.1 数据集
试验数据采用ISPRS 提供的Vaihingen 数据集(http:∥www.isprs.org/commissions/comm3/wg4/tests.html)。该数据集包含33幅不同大小的数字正射影像,其地面分辨率均为9 cm,正射影像由近红外、红、绿3个波段组成,包含车辆、建筑物、低矮植被、树木、不透水地面、河流及其他共6个类别。因车辆在每幅图幅中所占像素较少,本次试验选择车辆作为分类目标。
由于计算机处理能力的限制,将每幅影像裁剪为512×512像素大小,不足的部分以0补充,最后保存为24位的jpg图片。标注影像按相同的方法裁剪,并转换为8位的灰度图像。共得到742幅图像,随机选取702幅作为训练图像,40幅作为测试图像。
3.2 评价指标
为了验证本文方法的优势,采用MIoU(平均交并比)、ACC(准确度)、F1-score三个评价指标进行对比分析。
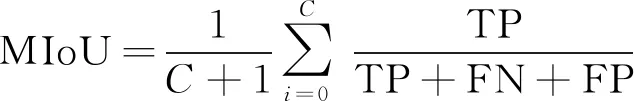
(4)

(5)

(6)
其中

(7)
式中:C为前景分类数量,加上背景总共为C+1类,本文C取1。TP为真正,表示正确分为汽车的像素个数。FP为假正,表示背景被分为汽车的像素个数。TN为真负,表示正确分为背景的像素个数。FN为假负,表示汽车被误分为背景的像素个数。式(4)先将背景和汽车分别作为正样本求出评价指标后,再取平均值便可得到所有类的平均评价指标。式(5)~(7)中正样本为汽车。
4 试验和结果分析
本文试验的硬件环境为:CPU Intel I5-9400F,显卡NVIDIA GeForce RTX 2060 Super 8G,GPU加速库CUDA10.0。程序采用Python语言基于TensorFlow深度学习框架编写。
深度学习模型使用PSPNet[14],采用AdamOptimizer 算法[15]寻找最优解,学习率为0.000 1。此外,对权重采用L2正则化[16],以防止过拟合,提高泛化能力。本次试验的K值1×104~1.4×105,每隔1×104取一次值。训练周期epoch最大值为100,每个epoch之后在测试集上进行评估,若连续10个epoch的评价指标MIoU都不再升高,则采用提前终止模型训练的策略(early stopping)[17]结束模型训练,以防止过拟合。
不同的K值得到的评估指标结果如表2所示。可以看出,从1×104开始,评估指标先是上升,到5×104左右最好,然后又下降。因为本文试验所用的图片为512×512像素,一幅图共有22.6×105像素,而从图中可以看出汽车的像素数在一幅图中不会超过一半,所以如果K取值超过1.3×105,前景像素所占比例必定越来越小,直到与普通交叉熵一致,预测效果也会下降到与普通交叉熵一致。
从测试集的预测结果图来看,使用普通交叉熵的PSPNet输出结果,存在一些误将背景错分为车辆的情况,而使用了FocalLoss的PSPNet网络的输出结果有所好转,但是效果最好的还是使用TopPixelLoss的输出结果,如图1第1、2行所示。在车辆被误分为背景的这一类错误中,使用TopPixelLoss的输出结果效果也是最好的,如图1第3、4行所示。
3种损失函数的所有测试图像计算出的平均指标值,如表3所示。从评价指标上来看,使用TopPixelLoss损失函数相对于普通交叉熵损失函数来说,MIoU提升了3.6%,F1-score提升了6.0%,ACC也提升了0.2%。用TopPixelLoss损失函数相对于使用FocalLoss损失函数的输出结果来说,MIoU提升了3.0%,F1-score提升了5.0%,ACC也提高了0.1%。

表2 不同K值的评价指标值

图1 使用不同损失函数的PSPNet预测结果对比Fig.1 Comparison of PSPNet prediction results with different loss functions

表3 使用不同损失函数的PSPNet评价指标对比
5 结论
本文针对遥感影像中的小目标分割问题,提出一种名为TopPixelLoss的损失函数。在ISPRS 提供的 Vaihingen 数据集上,使用PSPNet网络与普通交叉熵、FocalLoss、TopPixelLoss三种损失函数分别对车辆进行二分类分割。结果表明,不论从测试集上的预测图形来说,还是从评价指标上来说,使用TopPixelLoss损失函数的输出结果效果都更好。相对于FocalLoss来说,MIoU提升了3.0%,F1-score提升了5.0%,ACC也提高了0.1%。因此,本文提出的TopPixelLoss损失函数在遥感影像小目标语义分割方面,是比FocalLoss损失函数更优的损失函数。
本文的TopPixelLoss计算时涉及超参数K,K值是否能自动确定是下一步的研究重点。
猜你喜欢
安徽农业科学(2022年6期)2022-04-11
国际太空(2022年1期)2022-03-09
建材发展导向(2021年24期)2021-02-12
少儿画王(3-6岁)(2020年4期)2020-09-13
初中生世界·八年级(2019年6期)2019-08-13
海峡姐妹(2019年1期)2019-03-23
东方教育(2018年20期)2018-08-22
小学生导刊(低年级)(2016年9期)2016-10-13
小学生导刊(低年级)(2016年6期)2016-07-02
小学生导刊(低年级)(2016年4期)2016-04-12
