
RDF 图模型支持下的知识图谱数据索引与压缩存储算法
2021-12-27 07:59鲁富宇冷泳林
渤海大学学报(自然科学版) 2021年3期
鲁富宇,冷泳林
(渤海大学 信息科学与技术学院,辽宁 锦州 121013)
0 引言
随着领域知识图谱的不断完善、规模的不断扩大,其数据管理问题愈加重要[1]. RDF作为人工智能领域存储和管理知识图谱的通用框架,采用三元组形式描述知识,大量知识构成三元组库. 三元组库以实体、属性和值为基本构件,通过属性和值描述知识之间的关系. 同时一条三元组也可以看做是实体指向属性值的有向边,这些有向边连接到一起构成有向图,图顶点表示实体和值,有向边表示属性. 知识图谱中包含了丰富的语义知识,这些语义知识构成领域知识图谱[2]. 根据链接开放数据发布的信息显示,很多领域知识图谱的规模在10亿条以上,如维基百科和地理信息知识图谱的三元组达到30亿条,蛋白质知识图谱超过130亿条. 如此大规模的领域知识图谱数据给数据高效存储和检索都提出巨大挑战[3].
基于关系的RDF数据存储是一种常见的存储方式,三元组表[4-5]、垂直分割[6]以及属性表[7]都是采用替代的关系存储方式存储RDF三元组,来加速数据检索,但这种基于元组的存储方式忽略了数据间知识的联系,并且在处理大规模数据时的空值、自连接等问题严重影响了数据的检索效率. 一些存储索引系统如RDF-3X[8],Hexastore[9]和SPOVC[10]通过构建三元组不同组合方式的索引存储多个索引副本,并辅助相应的查询优化技术,提高了查询效率. 当面临大规模数据时,这些索引都是以空间来换取时间效率的. 另外,gStore[11]采用树状索引和邻接表的方式对RDF数据进行索引,TripleBit[12]依据RDF谓语对元组进行索引并进行压缩存储. 这两种索引在执行查询过程中过滤大量不相关数据,提高查询效率. 但它们都是基于元组的检索,需要利用查询优化技术降低查询中间结果. 为降低查询中间结果,RP-index(RDF Path in⁃dex)[13]和RG-index(RDF graph index)[14]两种基于路径和图的过滤索引用来实现数据的有效过滤. 其中RP-index索引RDF图中入边路径信息,RG-index将路径索引扩展至图结构索引实现元组的有效过滤,这两种索引的规模会随着图规模的不断扩大而迅速增加. 基于以上分析,自连接、副本和压缩方法是影响SPARQL查询效率的主要因素.
本文通过分析RDF数据发现,链式结构做为一种常见数据结构,有效的反映出知识之间的关联,在数据检索和知识推理中都具有非常重要的作用. 基于此,提出一种基于路径的索引树(Path tree,P-tree)及建立在该索引结构上的三元组压缩和检索算法(Compressed and retrieval triples,CRK2-triples),来实现RDF数据模型下知识图谱数据的快速检索.
1 路径索引树(P-tree)构建
RDF有向图的每条边链接知识主体(主语)和知识主体所对应的属性值(宾语),边代表着主体的特征. 通过对SPARQL查询图特征进行分析得出星型、链式、环型、树型是SPARQL查询图的基本结构. 其中链式结构是指主语又同时作为宾语的结构,本文针对链式这种常见的结构,构建P-tree索引.
给定一个RDF有向图G,如果G中存在一个顶点v满足链接它的所有边中只有出边,没有入边,则称顶点v为源点. 相反,如果v满足只有入边没有出边,称之为汇点. 对于一个RDF有向图,从源点出发,沿有向边的方向进行深度优先遍历,直到遇到第一个汇点结束,所得到的路径,称之为一条由源点到汇点的完整路径. 将一个RDF知识图谱按从源点到汇点进行分解,会得到多条完整路径. 文献[15]已经证明,RDF图中的任意一个实体或属性及它们之间的有向边都至少属于一条完整路径,由此可以保证一个RDF有向图可以由一个完整路径集合表示.
对于一个给定的SPARQL查询,同样也以源点到汇点的完整路径分解方式将其分解为完整查询路径集合,文献[15]同样给出了如果SPARQL查询是RDF子图,那么一定至少存在一条完整路径,满足查询路径是完整路径的子路径.
由于RDF图中顶点及边都是采用统一资源标识符(URI)进行表示,直接的字符串匹配查询在查询效率上有一定影响,而基于二进制的位串利用逻辑运算所进行的匹配查询效率要明显优于字符串的匹配.因此本文对完整路径及查询路径利用布鲁姆过滤器进行编码,生成能够快速配的二进制位串.
将RDF图分解成一个全路径集合,集合中每一条全路径上的边信息构成一条概要路径,对于每条概要路径将路径上每条边的属性信息通过k个Hash函数h1,h2,…,hk映射到长度为m的向量V中,生成一个布鲁姆编码. 则所有的n条完整路径对应生成n个布鲁姆编码V1,V2,…,Vk. 接下来通过计算这n个编码之间的汉明距离,得到任意一对完整路径之间的相似性,然后利用AP聚类,对生成的n条完整路径进行聚类.
AP聚类在聚类时不需要指定聚类中心,将所有数据作为潜在的聚类中心,然后通过迭代的方式在数据点间传递吸引度和归属度消息,通过迭代不段更新吸引度和归属度矩阵,直到产生k个高质量的exem⁃plar为止. 通过聚类产生的每一个聚类集合中包含若干条路径,这些路径在边的信息上相似性最大. 因此接下来对这些相似路径的布鲁姆编码执行按位“与”操作,得到一个复合布鲁姆编码,此编码代表一个完整路径集合,这个集合中的完整路径具有相似的路径边信息. P-tree就是将每一个聚类集合对应的布鲁姆编码作为叶子节点,然后采用自底向上的过程构建的,一层一层构建,直到只有一个根节点为止,图1展示了P-tree构建过程.

图1 P-tree构建过程
2 元组压缩与检索算法
P-tree索引树的每个叶子节点都会对应一组相似的完整路径,这些完整路径拥有相似的路径边信息.当将SPARQL分解为完整查询路径后,通过对P-tree执行自顶向下的逻辑“与”运算找到匹配的叶子节点时,相当于在众多的完整路径中找到了与之匹配的路径信息. 为了得到最终的查询结果,还需要将叶子节点所对应的全路径集合与查询路径进行精确匹配. 本部分将依据相似完整路径具有的相同边信息设计一个元组压缩和检索算法CRK2-triples,该算法利用k2-tree压缩存储每一个路径边所对应的元组集合.
由于每一个叶子节点都包含一组相似的完整路径集合,这些完整路径包含的路径边有很大的相似性. 因此每一个谓语都会对应着一个元组集合. 当将RDF图分解为完整路径时,一个元组有可能出现在多条完整路径中,因此就会产生很多元组副本. 为降低副本冗余,通过聚类完整相似路径已经将具有相同边的元组聚类到一起,在对元组进行存储时,利用k2-triples进一步将具有相同边的元组进行统一的压缩存储,可以进一步降低元组的副本率. 其中每一条边所对应的元组集合采取的是二级压缩模式,一级压缩是建立在k2-triples基础上实现的,二级压缩采取RLE(Run-length encoding)方式.
k2-triples是一种专门针对共享属性的元组设计的元组压缩存储方式,其基本思想是建立在k2-tree基础上的. k2-triples利用一个位矩阵存储具有相同属性元组,其中位矩阵的行和列分别对应元组的主语和宾语. 当位矩阵中任意位所对应的主语和宾语存在时,将其设置为1,否则设为0. 对于生成的位矩阵,存在大量主语和宾语的不关联关系,所以位矩阵中会有大量0出现. 如果直接采用位矩阵进行存储,非常浪费存储空间. 为此,k2-triples将位矩阵转换成一个k2-tree进行压缩存储,图2描述了位矩阵采用k2-tree的存储方式。
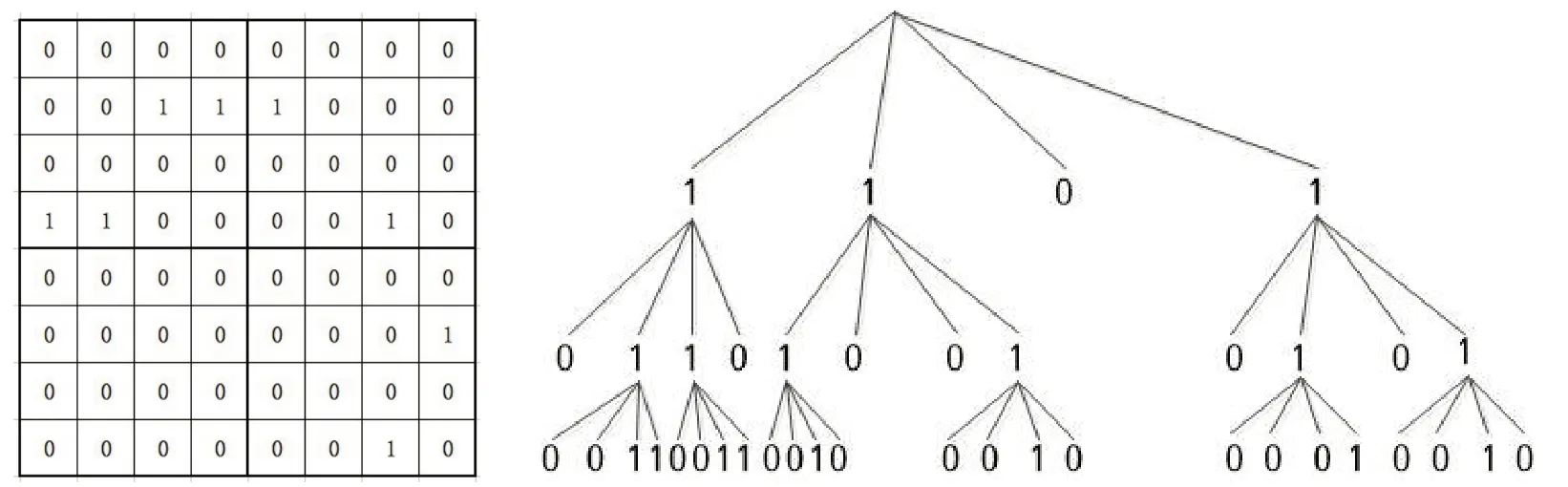
图2 k2-triples压缩方案
当k为2时,将位矩阵分成k2个子矩阵,k2-tree的根节点包含k2个子节点,对k2子矩阵按自上而下,自左向右顺序依次判断每个矩阵,如果子矩阵中的各个位都为0,则k2-tree的子节点对应为0,否则为1. 如图2所示,左侧矩阵分解为4个子矩阵时,第3个子矩阵中全部为0,因此对应k2-tree节点即为0. 当第一层节点生成后,对应值为1的节点继续重复上述步骤,直到节点值为0或者分割矩阵元素个数为k2为止.
生成的k2-tree,按照从根节点到叶节点,从左到右的顺序将所有节点值连接成一个二进制的压缩位串. 同样,压缩位串中仍然有很多连续的1或0,为了缩小存储空间,继续对这个位串利用RLE进行压缩.如图2,经过一级压缩后形成的位串为1101011010010101001100110010001000010010,二级压缩后为“[1]2 1 1 1 2 1 1 2 1 1 1 1 1 2 2 2 2 2 1 3 1 4 1 2 1 1”.
当已知检索谓语时,需要在上述的压缩串中根据已知主语查找对应宾语,或者已知宾语查找对应主语. 以检索主语为例,压缩串检索算法步骤如下:
步骤1:判断检索主语与矩阵中哪些子矩阵相关,同时记录关联子矩阵对应列的起始位置;
步骤2:在压缩串中获取子矩阵压缩串,同时寻找主语对应的子矩阵;
步骤3:重复上述方法,当搜索到叶子节点为1,并且满足与主语关联,则此列对应宾语即为与主语关联的元组的宾语.
3 实验
本文将P-tree索引和CRK2-triples压缩和检索算法同RDF-3X(v0.3.8),Bitmat[16]和TripleBit在合成和真实数据集上进行了实验.
3.1 数据集及环境设置
本部分选择LUBM、SP2Bench合成数据集和Uniprot真实数据集,同时这三种数据集又对应设计了相应的标准查询测试语句,表1 给出了每个数据集的详细信息. 本文利用C++程序设计语言编写索引生成代码,用G++编译,选择O2优化等级进行优化. 运行环境PC机配置:Intel Xeon 2.00 GHz处理器,20 GB内存.考虑到缓存,本文每个查询都执行三次,取平均结果以避免OS的影响.

表1 数据集
3.2 查询性能
表2和表3显示了几种索引存储方案在LUBM数据集上执行SPARQL查询反应时间. 从表中可以看出,本文的编码索引树P-tree与CRK2-triples的查询反应时间,尤其是在执行复杂查询时的时间效率比其它三种索引结构更有优势. 分析原因:(i)本文基于完整路径构建的P-tree索引是一种路径边的组合索引,通过它可以过滤大量不相关元组,缩小检索范围;(ii)本文提出的压缩存储及其对应存储模式下的直接检索,使相同内存情况下CRK2-triples加载更多的查询数据,降低了I/O代价;另外,基于完整路径的检索,使大多数连接仅发生在很小一部分元组中间,也降低了最终结果连接的数量,同时提高了查询效率.
在表2和表3数据显示P-tree检索大规模数据集时更有效. 如LUBM50和LUBM2000数据集执行结果中,采用RDF-3X索引查询时间跳跃性很大,尤其是复杂查询Q1和Q3. 但CRK2-triples的最大变化却很平稳. 原因是RDF-3X需要解压加载多种索引,当数据增加时,时间代价变大. 而基于元组的Bitmat和TripleBit,产生的中间结果要高于CRK2-triples,因此查询性能也就低于CRK2-triples.

表2 LUBM50查询反应时间(秒)

表3 LUBM2000查询反应时间(秒)
Unirpot数据集的元组规模达到7亿条. Bitmat使用本文提供的硬件环境得不到查询结果. 因此表4只对比了RDF-3X、TripleBit和STLIS三种方法的查询时间. 由于很多元组之间的连接操作是在执行P-tree检索后的路径集合中完成的,导致参与连接的中间结果集很小,所以同基于元组的过滤相比,CRK2-triples在路径模板树的过滤效果要好于其它两种.

表4 Uniprot查询效率(秒)
我们同样在数据集SP2Bench上执行查询,表5列出了各个查询的执行时间. 由于SP2Bench数据集规模很小,大多数查询的中间结果都能一次性加载入内存,因此STLIS执行查询的优势没有在LUBM数据集上明显,由此也验证了STLIS对大规模数据集的有效性.

表5 SP2B-100M查询效率(秒)
3.3 存储空间对比
本文比较了四种索引的存储空间,本文存储空间包含存储数据集和索引所消耗的存储空间. 除了Bitmat,其它的三个索引方案中均包含节点的字典工具. 表6列出了各存储方案在不同数据集上所消耗的存储空间. 其中在所有数据集上,CRK2-triples所耗费的存储空间都低于RDF-3X. 原因是RDF-3X包含6个聚类索引和9个聚集索引,因此,RDF-3X是一种以空间换时间的索引. 另外,随着数据规模的增加,RDF-3X和Bit⁃mat存储空间较CRK2-triples增加迅速. 因而CRK2-triples更加合适大规模数据. LUBM和SP2Bench的谓语数量较小导致分解后的完整路径相似性较大,降低了元组副本量,所以CRK2-tree和TripleBit在这两个数据集上的存储空间相差不大.

表6 存储空间(GB)
4 结 论
本文针对基于元组模式索引知识图谱时产生的频繁连接和数据冗余问题,提出一种基于路径检索的索引树P-tree. P-tree通过分解RDF有向图,得到从源点到汇点的完整路径,然后利用完整路径边信息结合布鲁姆过滤器生成路径编码,再针对路径编码相似性实现相似完整路径的聚类. 对每一个聚类集合,结合位运算生成索引树叶子节点,采用自底向上方式构建而成. 对于索引树叶节点对应的相似完整路径集合,本文利用k2-tree实现元组的压缩存储,并给出基于CRK2-trriples索引的元组精确匹配.
在实验中,将所提出的P-tree索引树及CRK2-triples同现有基于元组的索引存储方案在时间和空间性能上进行对比. 实验结果表明本文提出的索引方案在处理大规模复杂查询时更有效. 同时,CRK2-triples的压缩存储方式极大的降低了数据存储空间.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
南京理工大学学报(2022年1期)2022-03-17
汽车实用技术(2022年4期)2022-03-07
智能计算机与应用(2021年6期)2021-12-17
综艺报(2020年21期)2020-11-30
技术与创新管理(2020年5期)2020-10-09
商情(2020年24期)2020-06-30
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
电脑爱好者(2019年17期)2019-10-30
科学与财富(2019年27期)2019-10-25
