
融合显/隐式反馈的社会化协同排序推荐算法
2022-01-05 02:31张佳强
计算机应用 2021年12期
李 改,李 磊,张佳强
(1.顺德职业技术学院智能制造学院,广东佛山 528333;2.中山大学计算机学院,广州 510006)
(∗通信作者电子邮箱ligai999@126.com)
0 引言
随着人类进入信息化社会,特别是移动互联网和社交网络的出现,互联网上的信息量呈指数级爆炸式增长,人们越来越难以从互联网上迅速找到所需要的信息。传统的检索系统对每个用户的关键词检索都返回相同的结果,而推荐系统可根据用户的个人偏好来更准确地推荐相关信息,因此在互联网工业界得到了广泛应用。
信息推荐系统中协同过滤推荐算法是目前应用最成功且最广泛的信息推荐算法。随着社交网络的兴起,出现了社会化协同过滤推荐算法。根据所采用的机器学习方法的不同,社会化协同过滤推荐算法分为两种[1]:一种是基于评分预测的社会化协同过滤推荐算法,一种是基于排序预测的社会化协同排序推荐算法。相关研究表明:基于排序学习的社会化推荐算法没有基于评分预测的社会化协同过滤推荐算法所具有的预测值与真实排序不匹配的固有缺陷;同时,由于不以预测评分作中介,而是直接通过排序学习对推荐对象进行排序推荐,因此具有更直接的实际应用价值[1-3]。
在处理显式评分的社会化协同排序推荐算法中,代表性的有Yao 等[5]在国际顶级会议WWW2014 上提出的SoRank 模型。此外,随着深度学习的应用与发展,也出现了一些学者采用深度学习来研究处理显式评分的社会化协同排序推荐算法,均显著提高了该类推荐算法的性能[6-7]。在基于隐式反馈的社会化协同排序推荐算法研究领域,Du 等[8]在国际会议ADMA2011 上提出了UGPMF(User Graph regularized Pairwise Matrix Factorization)模型,Krohn-Grimberghe 等[9]在国际会议WSDM2012 上 提 出 了 MR-BPR(Multi-Relational matrix factorization using Bayesian Personalized Ranking)模型,Zhao等[10]在国际会议ICKM2014 上提出了SBPR(Social Bayesian Personalized Ranking)模型。此类算法的最新模型是Guo等[11]在国际权威期刊《Journal of Computer Science and Technology》上提出的SocialBPR 模型。上述基于隐式反馈的社会化协同排序模型均是基于矩阵分解的贝叶斯个性化排序(Bayesian Personalized Ranking based on Matrix Factorization,BPR-MF)模型的改进版本,其目标函数均是优化排序学习的评价指标受试者工作特性曲线下面积(Area Under Receiver Operating Characteristic curve,AUC)。
传统的基于排序预测的社会化协同排序推荐算法要么仅关注显式反馈数据[5-7],要么仅关注隐式反馈数据[8-11],没有充分挖掘这些数据的潜在价值。事实上,在真实的社会化信息推荐系统中,评分矩阵和社交网络矩阵中的显式反馈数据和隐式反馈数据是同时存在的。为了同时挖掘用户评分矩阵和社交网络矩阵中的显/隐式信息,Guo 等[12]提出了TrustSVD 模型,该模型通过改进SVD++模型来同时挖掘用户评分矩阵和社交网络矩阵中的显/隐式信息。由于该模型仍然是评分预测算法,因此同样存在预测值与真实排序不匹配的固有缺陷[4]。为了克服固有缺陷,同时进一步提高社会化推荐算法的推荐性能,本文在TrustSVD 模型和xCLiMF 模型[13]基础上,提出一种新的优化排序学习评价指标预期倒数排名(Expected Reciprocal Rank,ERR)的融合显/隐式反馈的社会化协同排序推荐算法SPR_SVD++,以同时挖掘用户评分矩阵和社交网络矩阵中的显/隐式反馈信息。实验结果表明,SPR_SVD++算法的归一化折损累计增益(Normalized Discounted Cumulative Gain,NDCG)和ERR 指标[1-2]均优于对比的最新的融合显/隐式反馈信息的推荐算法,且适合处理大数据,可广泛应用于互联网服务中的个性化信息推荐。
1 预备知识
本文用斜体加粗的大写字母(如:X)表示矩阵,用小写字母(如:i,j)表示标量。给定矩阵X,Xij表示它的一个元素,X.j和Xi.分别表示X的第j列、第i行,XT表示X的转置。如X表示显式评分矩阵,则Xij∈{0,1,2,3,4,5},该矩阵具有m个用户、n个对象;表示X的逼近/预测矩阵,V∈Cd×n,一般d≪r,r表示X的秩,r≤min(m,n),U和V分别表示用户和推荐对象的显式特征矩阵,d表示特征个数。Pui表示用户u的推荐对象i的排序得分。如X表示隐式评分矩阵,则,U和Y分别表示用户和推荐对象的隐式特征矩阵。
T=(Tuv)m×m表示有m个用户的社交网络矩阵,Tuv∈{0,1},“1”表示用户u信任用户v,“0”表示不信任。u信任v并不意味着v信任u,也就是说T是不对称的。表示T的逼近/预测矩阵,,U∈Cd×m,W∈Cd×m,U和W分别表示信任者特征矩阵和被信任者特征矩阵。为了在本模型中统一优化用户评分矩阵和社交网络矩阵,假定用户特征矩阵和信任者特征矩阵共享相同的特征空间,均用U表示,U∈Cd×m,因此。信任者的特征矩阵U和被信任者的特征矩阵W可以通过最小化以下目标函数[1]得到:

其中:T(u)表示用户u直接信任的用户的集合。
2 TrustSVD算法
TrustSVD 算法是一种融合显/隐式反馈的基于评分预测的社会化协同过滤推荐算法,其核心思想是在SVD++模型[14]基础上融入用户的社交网络信息,从而使TrustSVD 算法成为同时融合社交网络和评分矩阵的显/隐式信息的基于评分预测的协同过滤推荐算法。文献[12]中的实验结果显示:TrustSVD 算法的性能优于其他已知的融合显/隐式反馈的协同过滤推荐算法。在TrustSVD 算法中,逼近/预测矩阵中评分项的预测公式如下:
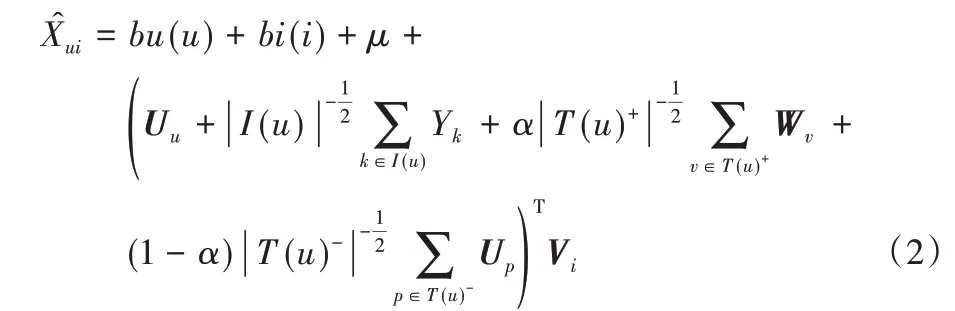
有关TrustSVD算法的详细描述见文献[12]。
3 SPR_SVD++算法
本章首先对SPR_SVD++算法进行详细描述,接着给出该算法完整的求解过程和伪代码,最后对新算法的时间复杂度进行全面分析。
3.1 算法介绍
在实际的应用中,人们更关注的是推荐对象之间的偏序关系,因此在基于排序预测的协同排序推荐算法能够更好地满足用户的实际需要。xCLiMF 模型是一种处理显式评分数据的基于排序预测的协同排序推荐算法[13],其核心思想是在目标函数中优化排序学习的评价指标ERR。文献[13]中的实验结果显示:xCLiMF 模型的性能优于目前已知的优化其他评价指标的基于排序预测的协同排序推荐算法。由于xCLiMF模型优化的是评价指标ERR,使得求解过程易于并行化,计算复杂度与评分矩阵中评分点的总数成正比,非常适合处理大规模数据(详见文献[13]和本文3.3 节的算法复杂度分析),因此本文提出的SPR_SVD++算法的核心思想是把TrustSVD算法融入xCLiMF模型,进而形成一种新的优化排序学习指标ERR的基于排序预测的社会化协同排序推荐算法。
在xCLiMF 模型中,用于评价对用户u所产生的推荐序列的ERRu公式如下所示:
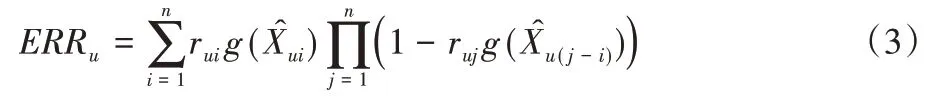
鉴于对数函数的单调性,最大化式(3)所得到的模型参数和最大化一致。因此,可得到如下公式:

和文献[13]中一样,运用Jensen 不等式和对数函数的凹性,得到的下限如下:
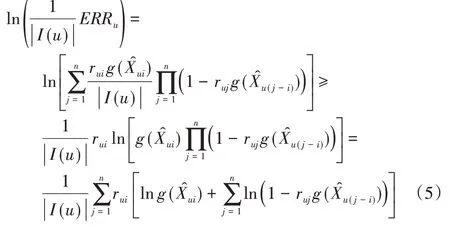

考虑全部m个推荐对象,SPR_SVD++算法的目标函数变形为:
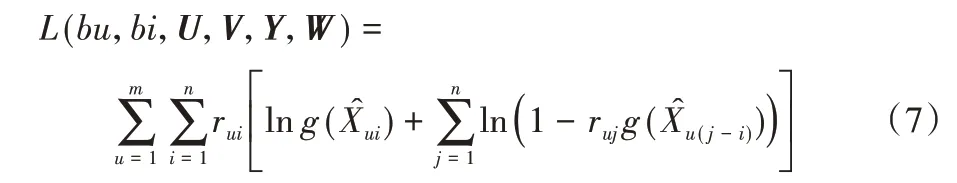
最大化目标函数(7)等价于最小化公式(8):
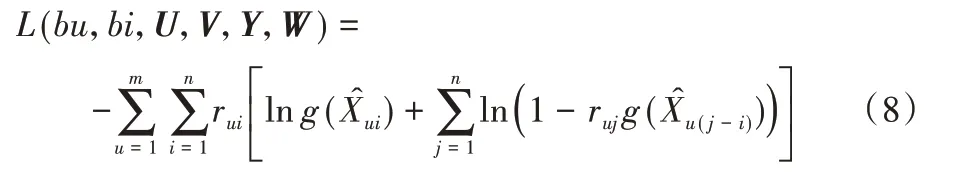
至此,相比目标函数(3),目标函数(8)简化了很多,可以运用传统的梯度下降法求解参数bu,bi,U,V,Y和W。
采用TrustSVD 算法中一样的方法,假定用户特征矩阵和信任者特征矩阵共享相同的特征空间,均用U表示,因此可以应用信任者的特征向量和被信任者的特征向量来约束用户的特征向量。得到新目标函数如下:
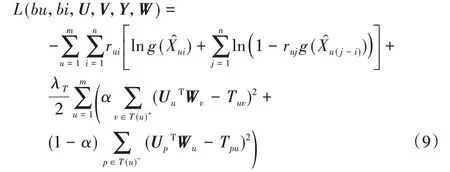
其中:UuTWv是用户u对用户v的预测信任值,UpTWu是用户p对用户u的预测信任值;α∈[0,1],用于控制信任者对最终评分的影响。
采用和参考文献[12]一致的策略,并引入加权的λ规范化。目标函数(9)变形为:
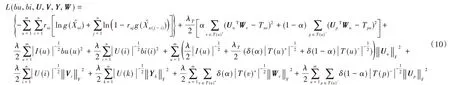
其中:λ是正则化系数,为了降低模型复杂度,在这里对所有参数bu、bi、U、V、Y和W采用一样的正则化系数;δ(x)是一个指示函数,当x>0 时值为1,否则值为0;‖Uu‖F表示Uu的Frobenius 范数;U(i)表示给推荐对象i评分过的用户集合;在这里采用|I(u)|、T(u)+和T(u)-同时约束用户的特征向量Uu。
3.2 新算法优化求解与伪代码描述
采用和参考文献[1-3]一样的策略,得到bu、bi、U、V、Y和W的求偏导公式如下:


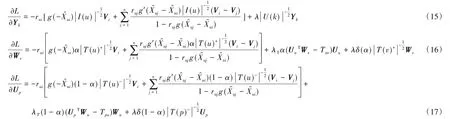
SPR_SVD++算法的伪代码描述详见算法1。
算法1 SPR_SVD++算法。
输入 评分矩阵X,社交矩阵T,学习率β,正则化参数λ,信任规范化参数λT,折中控制参数α,特征数d,最大迭代轮数itermax;
输出 评分偏差bu和bi,特征矩阵U、V、Y和W。

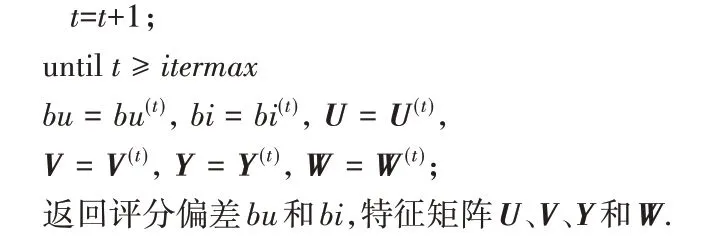
3.3 算法计算复杂度分析
4 实验结果及分析
4.1 实验数据集
在本实验中,一共使用3 个数据集:Epinions 数据集、Flixster 数据集和Ciao 数据集。数据集的具体说明详见参考文献[1,12]。
4.2 实验的评价标准
本文采用NDGG 和ERR 作为实验评价指标,具体定义详见参考文献[1-2]。
4.3 实验设置
采用和文献[1-2]类似的策略,针对3 个数据集,对每个用户给出条件:“Given 20”“Given 40”“Given 60”作为训练集,剩下的用作测试。
所有模型的最优参数值均分别确定。对每个数据集的不同条件数据子集,对实验中的所有模型均用训练数据集和五折交叉确认来确定模型参数。对于SPR_SVD++算法,和参考文献[15]一样,λT和α的最优值通过交叉确认确定。学习率β∈{χ|χ=0.000 1× 2c,χ≤0.5,c>0,c是一个正整数},通过实验找出最优值。其他参数的设置均参照参考文献[1]中的设置。对比算法的参数设置详见相应的参考文献。
4.4 实验结果及分析
4.4.1 信任规范化参数λT对SPR_SVD++算法性能的影响
除了参数λ以外,SPR_SVD++算法还有两个重要参数λT和α。为了确定算法中这两个算法的最优值,采取的策略是固定其中一个参数,寻找另一个的最优值。找到最优值后把该最优值固定,以寻找下一个参数的最优值。图1 给出了信任规范化参数λT对SPR_SVD++算法性能的影响,此时:固定α=0.5,同时λT∈{0.01,0.1,1,2,5,10},其中纵轴表示评价指标NDCG@10 的值,横轴表示信任规范化参数λT的值。采用Epinions 的子数据集“Given 40”作为实验数据集。从图1可以看出:SPR_SVD++算法的性能随着信任规范化参数λT值的变化而变化;当SPR_SVD++算法的性能最佳时,λT=0.1;在SPR_SVD++算法中引入用户的信任网络信息,有助于提高该类推荐算法的性能。
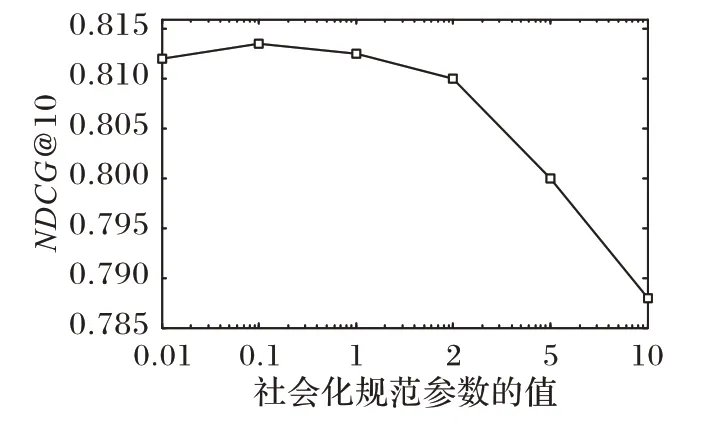
图1 λT对SPR_SVD++算法性能的影响Fig.1 Influence of λT on performance of SPR_SVD++algorithm
4.4.2 折中控制参数α对SPR_SVD++算法性能的影响
图2给出了折中控制参数α对SPR_SVD++算法性能的影响,其中纵轴表示评价指标NDCG@10 的值,横轴表示折中控制参数α的值。本实验仍然选择Epinions 数据集的子数据集“Given 40”作为实验数据集。根据图1显示的实验结果,此时固 定λT=0.1。α取值范围为:α∈{χ|χ=0.1×c,0 ≤c≤10,c是一个整数}。α=1 表示仅仅考虑被用户u信任的用户们对的影响,忽略信任u的用户对的影响;α=0则正好相反,表示仅仅考虑信任u的用户对的影响,忽略被用户u信任的用户们对的影响;取α∈(0,1)正是为了平衡这两种极端情况。从图2可观察到:当α=0时SPR_SVD++算法的性能优于当α=1 时的性能,这说明在SPR_SVD++算法中,信任者对算法性能的影响高于被信任者;当α=0 和α=1 时的算法性能均逊于α∈(0,1)时,这说明折中考虑信任者和被信任者对算法性能的影响,能够进一步提高SPR_SVD++算法的性能。
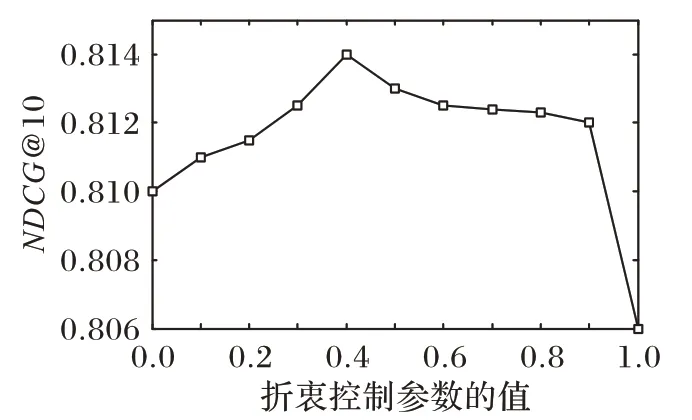
图2 α对SPR_SVD++算法性能的影响Fig.2 Influence of α on performance of SPR_SVD++algorithm
4.4.3 SPR_SVD++算法和经典协同过滤推荐算法的比较
考虑公平性,在3 个数据集上对比了本文的SPR_SVD++算法与3个经典的同时融入用户评分矩阵的显/隐式反馈的推荐算法,结果如图3。对比算法为:
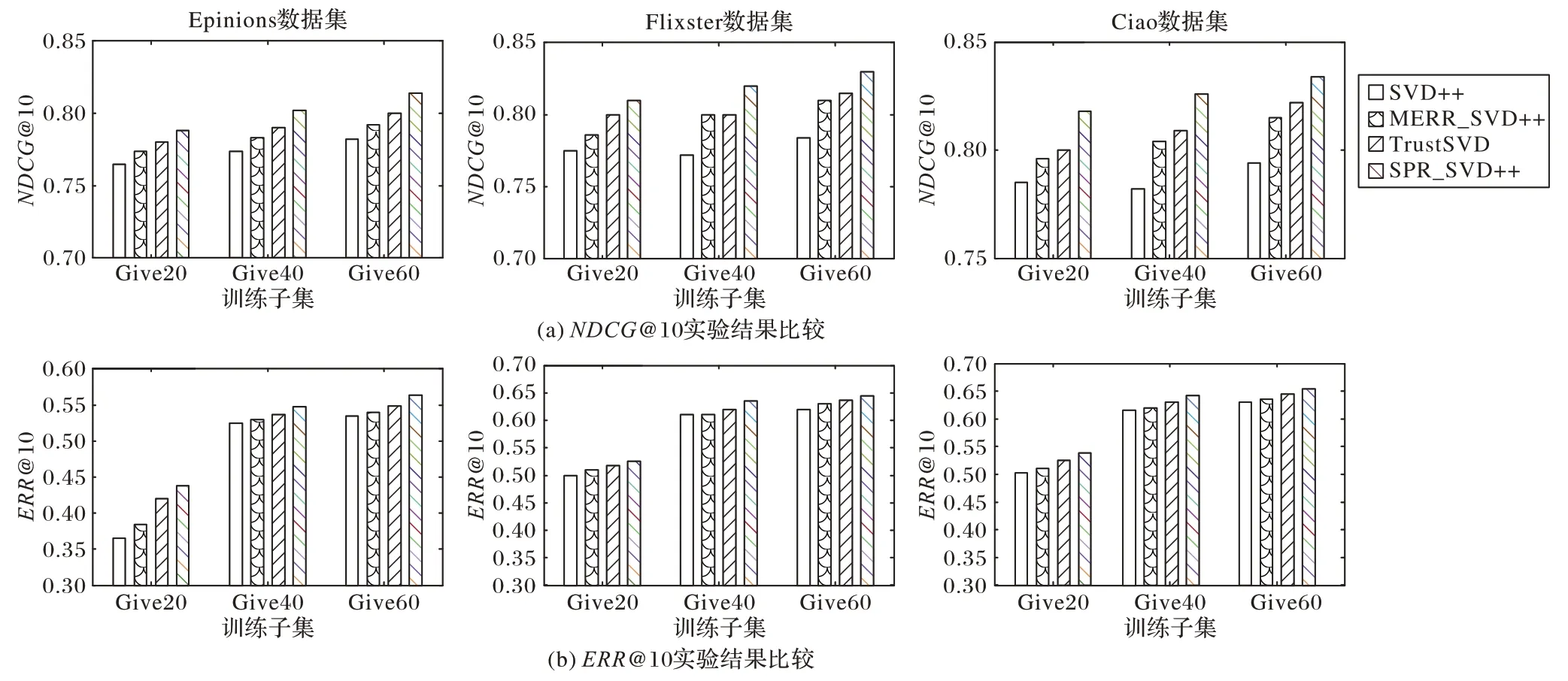
图3 SPR_SVD++算法与其他经典协同过滤推荐算法的性能比较Fig.3 Performance comparison of SPR_SVD++algorithm and other classic collaborative filtering algorithms
TrustSVD[12]:这是目前最新的基于评分预测的融合显/隐式反馈的社会化推荐算法,其核心思想是扩展SVD++算法,以融入用户的社交网络信息。
MERR_SVD++[3]:这是目前最新的基于排序预测的融合显/隐式反馈的协同排序推荐算法,其核心思想是在改进xCLiMF 算法的基础上同时融入用户评分矩阵的显/隐式反馈信息,优化排序学习的评价指标ERR。
SVD++[14]:该算法是最基础的融合用户显/隐式反馈信息的推荐算法,其核心思想是扩展SVD 模型以融入用户的显/隐式反馈信息。
从图3 可以看出,在3 个社会化数据集的各种条件子集下,SPR_SVD++算法的性能均远优于TrustSVD、MERR_SVD++和SVD++算法,且随着用户评分数据量的增长,算法性能提高越显著;SPR_SVD++算法的性能优于TrustSVD,说明优化排序学习的评价指标ERR 能够有效克服TrustSVD 的固有缺陷,进一步提高融入用户评分矩阵的显/隐式反馈的推荐算法的性能;且两个评价指标NDCG@10和ERR@10的性能走势图趋于一致,这说明SPR_SVD++算法优化排序学习的评价指标ERR 并不影响采用NDCG@10 作为评价指标的算法性能;随着特征数的增加,SPR_SVD++算法的性能也线性提高,这说明在本算法中训练数据的增加能够训练出更高精度的预测模型。
5 结语
本文在xCLiMF 模型和TrustSVD 模型的基础上,提出了一种新的优化排序学习评价指标ERR 的融合显/隐式反馈的社会化协同排序推荐算法SPR_SVD++。在真实的数据集上的实验结果表明,SPR_SVD++算法的性能优于对比的最新的该类推荐算法,且具有很好的可扩展性,因此,在面向海量数据处理的互联网工业界具有广泛的应用前景。
猜你喜欢
名家名作(2021年4期)2021-05-12
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
读与写·教育教学版(2017年10期)2017-11-10
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
现代情报(2014年8期)2014-11-06
教育(2014年4期)2014-02-25
浙江社会科学(2004年2期)2004-04-21
