
基于联合损失胶囊网络的换衣行人重识别
2022-01-05 02:32王洪元孙博言
计算机应用 2021年12期
刘 乾,王洪元*,曹 亮,孙博言,肖 宇,张 继
(1.常州大学计算机与人工智能学院、阿里云大数据学院,江苏常州 213164;2.常州工程职业技术学院设计艺术学院,江苏常州 213164)
(∗通信作者电子邮箱hywang@cczu.edu.cn)
0 引言
行人重识别(Person Re-Identification,Re-ID)是一个经典的计算机视觉问题,其目标是将不同摄像机拍摄人物的照片图像关联起来。它是一个重要的研究课题,在跨摄像机目标跟踪、目标再捕获等方面有着广泛的应用[1]。在过去几年里,已经提出了几个对社区有重要贡献的数据集,例如Viper[2]、CUHK03[3]、Market1501[4]、DukeMTMC-reID[5]等。
目前大部分公开数据集都是基于这样的假设,即每个人出现在一个摄像机下集中在短时间情况(例如,不到30 min)。在这种假设下,行人的衣服不太可能发生改变。然而,现实中摄像头捕获的行人照片图像,极大可能是一个人在相隔很长一段时间后再次出现。这种情况下,行人更换衣服或者携带不同物品的几率将会变大。因此,换衣行人重识别是行人重识别在大规模视频安防监控中常见的、更具有挑战性的案例。
在目前公开的行人重识别数据集研究中,人们主要研究穿着相同衣服的人在短时间内的重新识别,面临的主要挑战是分辨率低、光照条件、季节、背景和遮挡[6-7]。目前为止,这一领域的研究已经趋于成熟,基于特征提取的方法已经可以在Market1501 数据集上的Rank-1 准确率达到95.7%[8],超过了人眼的识别能力。现有的行人重识别模型的设计大多数基于深度神经网络(Deep Neural Network,DNN),这些网络提取不会变化的信息作为特征表示,一般来说这些特征表示由衣服外观主导,因此,目前的行人重识别模型并不适用研究换衣行人重识别问题。Huang 等[9]提出的基于胶囊神经网络的换衣行人重识别网络ReIDCaps 使用矢量胶囊代替标量神经元,其长度代表行人的身份信息,方向表示行人的衣着信息。虽然该模型在换衣行人重识别问题上取得了一些较好的指标,但是该模型的泛化性和鲁棒性仍需要提高。
本文在ReIDCaps[9]的基础上进行改进,将网络的损失函数由普通的交叉熵损失改进为标签平滑正则化交叉熵[10]与Circle Loss[11]的联合损失。联合损失在单一交叉熵损失的基础上可以提高模型训练时的泛化能力和鲁棒性,从而提升模型的性能指标。改进后的模型在Celeb-reID[9]、Celeb-reIDlight[9]和NKUP[12]数据集上的大量实验验证了本文方法的有效性。
1 相关工作
1.1 换衣行人重识别数据集
随着近几年行人重识别领域研究的发展,已经有多个行人重识别数据集中在衣服的变化上,这些数据集分为两类:基于视频的和基于图片的。现有的基于视频的换衣行人重识别数据集有DPI-T[13]、IAS-Lab[14]、BIWI[15]和PAVIS[16],这些数据集目标是在RGB-D 视频中识别出一个行人。由于大多数安装在公共区域的监视设备不能捕捉深度信息,这些数据集是专门为特定的室内监视场景而设计和收集的。现有的基于图像的换衣行人重识别数据集有Celeb-reID[9]、PRCC[17],COCAS[18]、LTCC[19]和NKUP[12],这些数据集的目标是在RGB图像中识别出一个行人,这些图像是为一般公共区域监控场景而设计和收集的。尽管应用场景不同,但这些基于视频和基于图像的数据集都有利于促进换衣行人重识别研究的进一步发展。
1.2 换衣行人重识别研究方法
深度学习在解决行人重识别任务上取得了很大的成功,但目前基于卷积神经网络(Convolutional Neural Network,CNN)的行人重识别方法主要针对的是非换衣的行人重识别问题。之前由于缺乏大规模的换衣行人数据集,关于换衣行人重识别的研究较少,但随着越来越多的换衣行人数据集的公开,相关研究也丰富起来。目前的研究主要是从体型、轮廓等提取与衣着无关的特征。文献[17]中基于人体图像的轮廓草图来研究换衣行人重识别问题,在深度神经网络中引入基于学习空间极坐标变换(Spatial Polar Transformation,SPT)层来变换轮廓草图图像,以在极坐标空间中提取可靠且有判别性的卷积神经网络特征。文献[18]中提出了一种将生物特征和服装特征结合起来进行身份识别的生物特征服装网络(Biometric-Clothes Network,BC-Net)。文献[19]中引入了形状嵌入模块和衣物形状提取模块,目的在于消除目前不可靠的服装外观特征,并将重点放在身体形状信息上,因为在换衣情况下,身体形状等软生物特征会更可靠。然而,目前的换衣行人重识别研究主要是从人体姿态或轮廓中用已有的预测模型提取身体特征信息,这些特征提取会因为模型预测的误差而导致提取的特征所包含的正确形态信息非常有限,泛化能力弱,鲁棒性不强;此外,这些额外的姿态或轮廓估计增加了这些方法的计算成本。
1.3 胶囊网络
2017 年,采用动态路由机制的胶囊网络被提出用于解决手写数字识别问题[20]。目前胶囊网络已经被成功地用于许多计算机视觉任务中,如图像分割[21]、数据生成[22]、图像分类[20]等。用一组矢量神经元表示胶囊,其长度表示实体的存在性,方向表示实体的其他属性。文献[20]中提出的DigitCaps 模型证实对训练数据进行小仿射变换可以适度提高其鲁棒性。2018 年,文献[23]中引入了另一个基于胶囊的网络,该网络使用期望最大化算法执行动态路由机制[23]。与前人的工作不同,胶囊网络由姿态矩阵表示,网络中的胶囊层专门用于定义视点更改对象的旋转和平移。Huang 等[9]提出的Celeb-ReID数据集主要受到行人衣着变化的影响,与姿态矩阵胶囊相比,文献[20]中提出的基于矢量的胶囊更适合换衣行人重识别的情况,因为它能够感知每个实体的属性线索。ReIDCaps[9]模型主要是由DigitCaps[20]推动的。除了DigitCaps,ReIDCaps 还集成了经过ImageNet 训练的CNN 来提取底层的视觉信息,因为在ImageNet 上预先训练过的CNN 在许多重识别任务中的表现都很出色。这是第一个将胶囊与经过ImageNet 训练的CNN 在复杂数据集上进行集成的工作,特别是关于行人重识别的数据。
ReIDCaps[9]不用提取额外的姿态或轮廓信息,计算成本相较低。相较于一般的行人重识别模型,矢量胶囊拥有更多的信息,其长度表示行人身份信息,其方向表示行人衣着信息;但该模型依然存在泛化能力差、鲁棒性不强的问题。本文在ReIDCaps 模型的基础上增加了标签平滑正则化交叉熵损失和Circle Loss 的联合损失,通过减少真实样本标签的类别在计算损失函数时的权重和将类间和类内的相似性嵌入到相似对中进行优化的方法,抑制过拟合,收敛目标明确,从而提高模型的泛化性和鲁棒性。
2 本文方法
本文方法整体框架如图1,分为三个主要模块:1)视觉特征提取模块,采用ImageNet 预训练的CNN 模型提取每幅图像的底层视觉特征,然后将这些特征送入胶囊网络以感知行人身份信息和衣着信息;2)行人身份信息和着装感知模块,采用胶囊层来感知图像的行人身份信息和着装信息,行人身份信息通过每个矢量胶囊的长度来感知,行人的着装信息通过每个矢量胶囊的方向来感知;3)辅助模块,用于进一步提高从ReIDCaps 模块中学习到的特征的区分度,提高模型的鲁棒性。
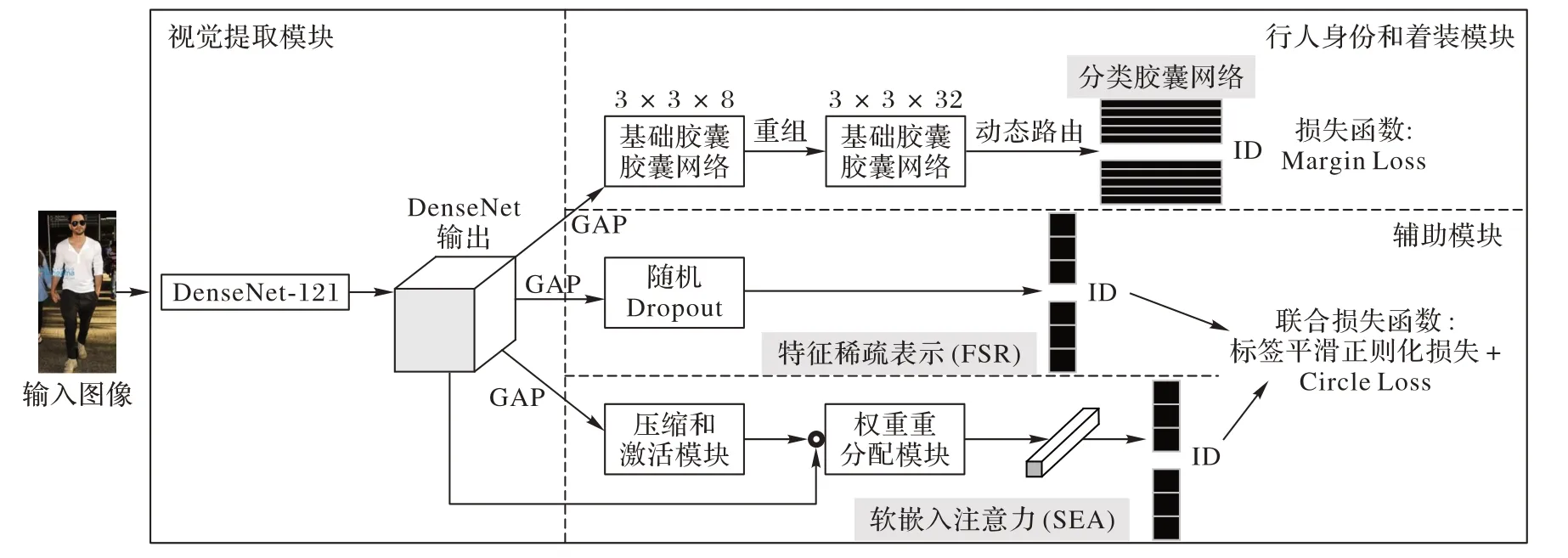
图1 本文方法的整体框架Fig.1 Overall framework of the proposed method
2.1 视觉特征提取模块

其中:γ用于平衡胶囊层和辅助模块的贡献权重。文献[20]中提出γ=0.5时效果最佳,所以本文实验也取γ=0.5。
2.2 行人身份和着装感知模块
ReIDCaps 中使用矢量胶囊来了解服装变化的特性。在训练中,胶囊的长度CL反映行人的身份信息存在的可能性,胶囊的方向CO代表同一个行人身份的不同类型的衣服。为了实现这一点,本文方法在之后采用了两个不同的胶囊层,分别是基础胶囊层(Primary Capsules,P-Caps)和分类胶囊层(Classification Capsules,C-Caps)[20]。这两层都在文献[20]中提出,用于手写数字识别。但在ReIDCaps 网络设计中,更改了两层上的参数设置,以适应ReID 任务和经过ImageNet训练的CNN 骨干网络。具体地说,给定O(Ixn),8 个32 通道卷积运算(卷积核大小2×2,步长为2)用于构造P-Caps。使用重构操作来级联P-Caps中的每个块(总共8个块)的对应信道。之后,在P-Caps层中得到288(3×3×32)个8维矢量胶囊。最后使用非线性挤压函数来确保每个矢量胶囊的长度归一化:

C-Caps 层之后是P-Caps 层。在C-Caps 层中有N个行人身份胶囊,N表示训练集中行人身份数量。C-Caps 中每个行人身份胶囊是P-Caps层中所有矢量胶囊的组合。给定P-Caps中的8 维矢量v8Dk,本文方法将其维度映射到24 维。然后,C-Caps层中的行人身份胶囊可以通过以下公式计算:

其中:n∈[1,N];代表耦合系数,该耦合系数由P-Caps 和CCaps 层之间的动态路由过程确定。这里24 维的使用挤压函数归一化(参考式(2))。动态路由是建立P-Caps 层和C-Caps 层之间关系的关键技术,本文采用的动态路由与文献[20]中的描述相似。
输入一个给定图像,使用边际损失(Margin Loss)作为该模块的损失函数:

其中:yn表示输入图像的行人身份是否存在,存在的话yn=1,否则yn=0。使用λ=0.5 来平衡两部分之间的权重,用m+和m-来控制的长度。由于刚刚的假设,如果行人身份存在的话,那么C24Dn的长度应该是长的,否则应该是短的,所以设。
2.3 辅助模块
辅助模块主要包含FSR和SEA模块。在将经过骨干网络的输出采用全局平均池化,以获得输入图像Ixn的CNN 表示:

其中:H和W分别代表的高度和宽度;在全局平均池化层之后,将FSR和SEA的输入分别表示为。
FSR 目的是提高基于CNN 输出的泛化能力。Dropout 层已经证明了其在网络训练中可以通过随机将部分神经元置为零来防止CNN 过拟合[25],使用Dropout 可以使成为稀疏表示,在反向传播时转移到,潜在地提高了整个网络的鲁棒性。

原ReIDCaps 里使用交叉熵损失在FSR 和SEA 分支对训练集中行人身份进行分类,本文中使用交叉熵损失,采用标签平滑正则化交叉熵损失[10]与Circle Loss[11]的联合损失作为最终的损失函数。
2.4 标签平滑正则化交叉熵
多分类任务中,神经网络会输出一个当前数据对应于各个类别的置信度分数,将这些分数通过Softmax 进行归一化处理,最终会得到当前数据属于每个类别的概率,然后会计算交叉熵损失函数。随后训练神经网络,最小化预测概率和标签真实概率之间的交叉熵,从而得到最优的预测分布。神经网络会促使自身往正确标签和错误标签差值最大的方向学习,在训练数据较少,不足以表征所有样本特征的情况下,会导致网络过拟合。标签平滑正则化的交叉熵可以解决上述问题,这是一种正则化策略,主要是通过soft one-hot来加入噪声,减少了真实样本标签的类别在计算损失函数时的权重,最终起到抑制过拟合的效果。
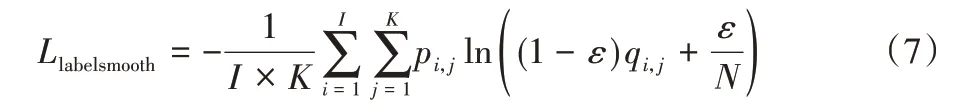
其中:I为行人身份数;K为图片数量;N为行人类别数;pi,j为预测概率,qi,j为真实概率;ε为平滑因子。
2.5 Circle Loss
Circle Loss[11]对于深度特征学习的优化过程提出了两点见解。首先,大部分损失函数,包括三元组损失和分类损失,都是通过将类间和类内的相似性嵌入到相似对中进行优化;其次,在监督下的相似对中,每一个相似性分数根据其到最优效果的距离而赋予不同的惩罚强度。由此得到了Circle Loss,使得每一个相似度分数可以以不同的梯度学习。Circle Loss优化灵活性高,收敛目标明确,有利于深度特征学习,而且它将两种基本的学习方法(即基于类别标签和基于样本对的学习)统一到一个公式中。文献[11]的实验结果也表明Circle Loss在行人重识别任务中有比较好的表现。

其中:sp为类内相似性,sn为类间相似性;K为类内相似性分数个数,L为类间相似性分数个数;γ是尺度参数;m是优化的严格程度。
2.6 联合损失
改进后的FSR 和SEA 模块的损失使用交叉熵损失、标签平滑正则化损失和Circle Loss 三个损失的联合损失作为最终的损失。

相较于单一的交叉熵损失函数,标签平滑正则化交叉熵损失可以防止模型过拟合;而Circle Loss 将度量损失与分类损失进行了统一化,相较于单一的交叉熵损失,这两种损失联合对于模型的训练能够更加鲁棒,从而提升整个模型的性能指标。
3 实验与结果
3.1 数据集和评价指标
本文在Celeb-reID、Celeb-reID-light 和NKUP 三个不同的换衣行人重识别数据集进行了大量实验,以验证本文方法的有效性。
Celeb-reID 数据集分为三个子集,包括训练集、图库集和查询集。该数据集中同一个行人的衣着发生了很大的变化,但其中也存在一个行人可能会穿着同一件衣服两次的情况。具体地说,总体上每个行人70%以上的图片都展示了不同的衣着。该数据集中有1 052 个行人身份,共计34 186 张图片;训练使用632 个行人身份,图片20 208 张;测试使用420 个行人身份,图片13 978 张。在测试集中,2 972 张图片被用作查询集,11 006张被用作图库集。此外,一般的数据集中只包含前视图和侧视图,而该数据集中包含一些后视图。
Celeb-reID-light 数据集是Celeb-reID 数据集的轻量级版本。与Celeb-reID 不同的是,在Celeb-reID-light中的行人不会两次穿同一件衣服[27]。该数据集中有590 个行人身份,训练使用490 个行人身份,图片9 021 张;测试使用100 个行人身份,图片1 821张。在测试集中,887张图片被用作查询集,934张图片被用作图库集。虽然Celeb-reID-light 的尺度比CelebreID 的小,但当一个人穿着完全不同的衣服时,它可以用来证明Re-ID方法的鲁棒性。
NKUP 是从现实生活中提取的可公开的换衣行人重识别数据集,有很长的时间间隔和多个镜头。NKUP 数据集包含107 个行人,总共9 738 张行人图片,其中总共79 个穿着不同衣服的行人,其余穿着单一衣服的行人用作测试对象。
本文使用Rank-k和平均精度均值(mean Average Precision,mAP)评估方法的性能,Rank-k表示在排名前k个列表中正确匹配的概率,反映的是检索精度;mAP 反映的是召回率。
3.2 实验参数设置
本文采用经过ImageNet 预训练的DenseNet121[24]作为特征提取的骨干网络,输出的特征向量为1 024维。将特征向量分别输入视觉特征提取模块和辅助模块。因为实验训练与测试的数据集为换衣行人重识别数据集,所以使用与训练一般行人重识别网络不同的策略,因为考虑换衣行人重识别,模型需要产生更多可学习的参数,以适应有关服装变化的附加信息。该网络训练过程中,每个批次包含20 张图像。设置经ImageNet 训练的DenseNet121 中的初始学习率为1E-4,并且在DenseNet 输出之后的新的网络中的初始学习率设置为1E-3。所输入的图像的大小都调整为224×224,并且在训练前随机翻转和随机擦除(概率设为0.5)。使用Adam 随机优化[28],参数β1=0.9,β2=0.999。80个训练周期后学习率下降到原来的1/10,100 个周期后停止训练。Celeb-reID、CelebreID-light 和NKUP 的训练行人身份数N=632,490,102,标签平滑正则化交叉熵损失的参数ε=0.1,Circle Loss 的参数设置为γ=128,m=0.25。
整个实验基于Ubuntu 16.04、Cuda10 和Cudnn7.6 的环境和Python 3.8、Pytorch 1.7.0 和torchvision 0.8.1 深度学习框架实现,实验的硬件配置包括:4 块GPU:GTX 2080Ti(显存:11 GB)。
3.3 实验评估
本文在三个换衣行人重识别的数据集上进行了ReIDCaps基线(Baseline)方法(本文比对的实验数据基于以上的实验环境复现原文代码所得)、仅带有标签平滑正则化交叉熵损失(Label Smooth Regularization)的ReIDCaps 方法、仅带有Circle Loss 的ReIDCaps 方法和标签平滑正则化交叉熵和Circle Loss联合损失的ReIDCaps方法的实验,实验结果如表1所示。在Celeb-reID、Celeb-reID-light和NKUP 三个数据集上,在基线方法上加入标签平滑正则化损失之后,mAP 分别提高了0.7、0.2、1 个百分点;Rank-1 提高了2、-0.3、1 个百分点,因为该损失可以防止模型过拟合。在基线方法上进加入Circle Loss 损失之后,mAP 分别提高了0.8、0.7、1.5 个百分点;Rank-1 提高了1、0.2、-0.9 个百分点,因为该损失将类内距离与类间距离统一化,提高了模型的泛化性。绝大多数实验结果表明这两种方法单独对模型的性能都有所提升。采用标签平滑正则化交叉熵损失和Circle Loss 的联合损失之后,mAP 分别提高了1.1、0.9、2.2 个百分点;Rank-1 分别提高了0.5、0.9、1.8 个百分点。绝大多数性能指标较单独加入一个损失函数相比都有所提升,且达到了最优值。由此可见两种损失的组合可以共同提高整个模型的鲁棒性,提升换衣行人重识别的匹配精度。

表1 仅标签平滑正则化、仅Circle Loss和标签平滑正则化和Circle Loss联合损失在三个数据集上的性能比较 单位:%Tab.1 Performance comparison of only smooth regularization loss,only Circle Loss and joint loss of label smooth regularization loss and Circle Loss on three datasets unit:%
3.4 与现有方法对比
除了以上对比实验,本文方法也和一些先进的非换衣行人重识别方法做了比较。在Celeb-reID、Celeb-reID-light 和NKUP 三个换衣行人重识别数据集上进行了比较,选取了四种不同的粗粒度行人重识别方法包括IDE+(DenseNet-121)、ResNet-Mid[29]、Two-Stream[30]、Multi-Level Factorisation Net(MLFN)[31]和一种细粒度行人重识别方法PCB(Part-based Convolutional Baseline)[32],以及本文改进前的换衣行人重识别网络ReIDCaps[9]。粗粒度方法使用整个图像作为输入,而细粒度方法同时考虑全身和身体局部的特征。这些方法都在非换衣行人重识别场景下取得很好的表现,如表2 所示。在Celeb-reID 换衣行人重识别数据集上,本文方法Rank-1 达到10.8%,mAP 达到51.6%;在Celeb-reID-light 小型换衣行人重识别数据集上Rank-1 达到11.1%,mAP 达到21.5%。在这两个数据集上和对比的方法相比均取得了最优的性能指标。在NKUP 数据集上,本文方法的Rank-1 达到了7.5%,mAP 达到8.3%,mAP 为最优指标,Rank-1指标略低于PCB,优于其他方法。由此可见,本文提出的基于联合损失的胶囊换衣行人重识别网络在综合性能上优于对比的绝大部分先进非换衣行人重识别方法,在三个换衣行人重识别数据集上验证结果几乎都一致,增加标签平滑正则化交叉熵损失和Circle Loss 联合损失后,提高了模型的泛化能力和鲁棒性,在三个换衣行人重识别数据集的实验结果也验证了该方法的有效性。

表2 本文方法与现有方法比较 单位:%Tab.2 Comparison of the proposed method with the existing methods unit:%
4 结语
本文提出了一个基于标签平滑正则化交叉熵损失和Circle Loss 联合损失的胶囊换衣行人重识别网络。首先使用ImageNet 预训练DenseNet121 骨干网络,提取底层视觉特征,然后使用胶囊网络作为行人身份和衣着感知模块。为了提高整个模型的鲁棒性,还加入了辅助模块,并且对于辅助模块的损失函数进行改进,使用标签平滑正则化交叉熵损失与Circle Loss 联合损失。在三个换衣行人重识别数据集CelebreID、Celeb-reID-light 和NKUP 上的实验表明,本文方法具有一定的优越性。本文方法虽然提高了一些性能指标,但和其他方法一样,对于换衣行人重识别整体性能不高,可见换衣行人重识别确实是一个非常困难的任务,如何能够更好地提高换衣行人重识别的模型性能,使其可以达到与非换衣行人重识别数据集上相当的性能,是进一步需要研究的目标。
猜你喜欢
现代装饰(2021年2期)2021-07-21
意林(2021年5期)2021-04-18
扬子江(2019年1期)2019-03-08
上海师范大学学报·自然科学版(2018年3期)2018-05-14
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
神州·上旬刊(2017年9期)2017-10-15
小天使·一年级语数英综合(2017年6期)2017-06-07
计算技术与自动化(2014年1期)2014-12-12
小学阅读指南·高年级版(2009年3期)2009-03-27
家庭医药(2009年1期)2009-02-05
