
基于斜回归树及其集成算法的静态电压稳定规则提取
2022-01-11 08:13贾宏阳侯庆春刘羽霄
电力系统自动化 2022年1期
贾宏阳,侯庆春,刘羽霄,张 宁,范 越
(1. 电力系统及大型发电设备安全控制和仿真国家重点实验室,清华大学,北京市 100084;2. 清华大学电机工程与应用电子技术系,北京市 100084;3. 国网青海省电力有限公司,青海省西宁市 810008)
0 引言
高比例可再生能源并网对电力系统安全稳定运行产生巨大挑战[1-3]。可再生能源的随机性和低惯性导致电力系统运行模式增多,各种模式下的电力系统运行点越来越分散,部分运行点接近于安全稳定临界点,连锁故障[4]、电压失稳[5]、功角失稳[6]和频率崩溃[7]等安全稳定事故发生的概率增加[8-10]。风光等间歇性可再生能源并网后,电力系统安全稳定机理日趋复杂,传统基于同步机的安全稳定分析方法出现局限性。电力系统安全稳定问题通常需要表达为高阶微分方程或无法直接解析表达,例如静态电压稳定裕度往往通过连续潮流算法多次求解潮流方程得到,难以快速、直接辨识系统稳定裕度,难以给出线性安全稳定规则指导系统优化运行。
近年来,随着人工智能技术的飞速发展,在传统解析分析法与时域仿真法的基础上,基于机器学习的电力系统安全稳定辨识及规则提取方法,有望辅助解决上述难题。已有研究主要利用强化学习、神经网络、支持向量机和单变量决策树等算法进行电力系统安全稳定辨识。文献[11]利用强化学习进行电压稳定裕度辨识。文献[12-14]使用各类神经网络对系统电压稳定与暂态稳定进行辨识。文献[15-16]使用支持向量进行系统暂态稳定评估。文献[17-18]使用决策树对系统暂态稳定性进行分析。而面向规则提取的研究则主要基于结构简单的机器学习模型。文献[15]基于支持向量机构造能够实时求取的稳定裕度指标,然后利用灵敏度方法获取切机灵敏度与切负荷灵敏度,进而构建紧急控制决策模型中的稳定约束。文献[19]将支持向量机的训练结果转化为单变量决策树C4.5,文献[18]直接通过单变量决策树提取稳定规则,但单变量决策树提取的规则是一维的,不能精准刻画电力系统的复杂安全边界。文献[20-21]尝试对神经网络的训练结果进行解释,但这些方法需要引入专家知识。
目前,基于机器学习的电力系统安全稳定裕度辨识与规则提取算法有很多,但是缺少一种兼顾可解释性与表示性的算法,能够直接而快速地获取稳定裕度与系统状态变量之间的显式关系。传统单变量决策树模型学习容量有限,难以表示大型电力系统的复杂安全稳定规则。传统神经网络或集成学习等黑箱模型提取的规则过于复杂,难以解释并可靠地应用于电力系统在线安全稳定辨识。同时,非线性模型的拟合结果难以直接应用于紧急控制决策或考虑安全约束的日前优化调度[22-23]。
针对这一难题,本文提出了内嵌安全稳定约束的电力系统优化运行框架和用于电力系统安全稳定规则提取的斜回归树及其集成算法,以静态电压稳定问题为例验证了算法的有效性。本文工作的创新性主要体现在以下3 个方面。
1)提出了内嵌安全稳定约束的电力系统优化运行框架,通过数据生成、决策树学习、规则提取与内嵌,实现在电力系统优化运行中考虑安全稳定约束。
2)针对静态电压稳定问题,提出斜回归树算法对稳定裕度进行精准预测,该算法的表示能力与泛化性能相对于单变量回归树有了大幅提升,便于提取可靠的安全稳定规则。
3)提出了斜回归树的集成方法,进一步提升算法的学习能力,引入Lasso 和Ridge 正则化项,保证安全稳定规则简单而有效。
1 内嵌安全稳定约束的电力系统优化运行框架
本章针对电力系统小干扰稳定、电压稳定、频率稳定与连锁故障等安全问题给出内嵌安全稳定约束的电力系统优化运行一般方法,选用决策树提取规则并将其转化为安全稳定约束。为了保证方法的可行性与有效性,决策树提取规则应满足以下要求[24]。
1)准确:算法从系统中提取的规则应与实际安全边界形成精准映射。为此,决策树必须具有强大的泛化性能,必要时能够通过集成提高其学习能力。
2)可解释:算法提取的每条规则必须易于电力系统调度人员理解。为此,决策树的深度取值不宜太大,每次划分既要保证刻画安全边界的准确性,又要保证划分系数向量的稀疏性。
3)可嵌入优化运行:应保证内嵌安全稳定约束的优化问题能够快速求解。为此,决策树的每次划分必须为线性划分,划分系数向量应尽可能稀疏。
为了满足上述要求,本文给出内嵌安全稳定约束的电力系统优化运行框架,如图1 所示。

图1 电力系统安全规则提取与内嵌的算法框架Fig.1 Algorithm framework for extraction and embedding of power system security rules
1)通过仿真为算法生成大容量数据集:仿真能够获取实际电力系统运行过程中较少达到的运行状态,使得决策树算法能够从数据集中获取更准确的安全边界。电力系统安全稳定仿真数据集的生成过程为:给定系统的边界条件;抽样得到可再生能源机组出力与负荷大小;通过最优潮流求解运行状态数据;通过时域仿真或稳定性计算判断系统是否稳定。静态电压稳定仿真数据集的生成过程将在第2章中详述。
2)训练集成稀疏斜决策树:充分利用稀疏斜决策树及其集成算法的可解释性,提取稀疏且线性的安全稳定规则[24]。本文将以静态电压稳定问题为例,介绍斜回归树及其集成算法,具体将在第3 章与第4 章中详述。
3)规则提取与内嵌优化:利用递归算法提取斜决策树各叶节点的稀疏划分矩阵,通过大M 法将其转化为安全稳定约束[24]。内嵌后的运行优化问题变为混合整数线性规划(MILP)问题,可通过多种商业软件求解。
2 斜回归树及其集成算法框架:以静态电压稳定问题为例
由于高比例可再生能源电力系统的随机性和低惯性,利用斜回归树及其集成算法提取静态电压稳定规则时,需要解决以下2 个问题。
1)如何通过简单而有效的抽样方法在高比例可再生能源电力系统广阔的运行状态空间中进行采样生成数据集?
2)如何将斜回归树进行高效集成并防止过拟合,以提取尽可能简单而可靠的安全稳定规则?
为了解决上述问题,图2 给出了斜回归树用于提取静态电压稳定规则的算法框架。
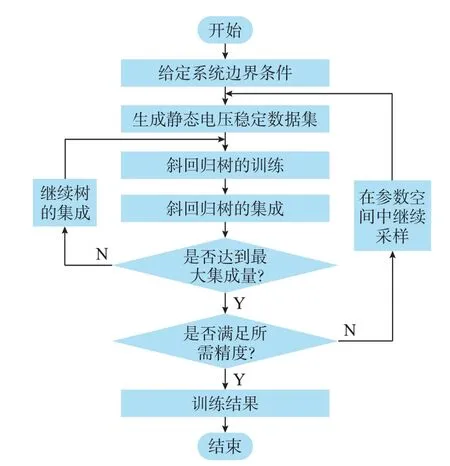
图2 斜回归树用于提取静态电压稳定规则的算法框架Fig.2 Algorithm framework for extracting static voltage stability rules using oblique regression tree
1)给出系统边界条件:包括节点类型信息、负荷参数、接地导纳、电压幅值及其变化范围、线路参数、机组所在节点和有功、无功出力的上下限等。
2)生成静态电压稳定数据集:首先,采用改进拉丁超立方抽样(LHS)对负荷大小与可再生能源机组的出力上限进行采样,得到在高比例可再生能源电力系统运行状态空间中分布均匀的样本[25]。接着,通过最优潮流计算得到运行状态样本的详细信息,记为p,然后通过连续潮流计算得到运行状态的电压稳定裕度值,记为y。电力系统最优潮流和连续潮流算法较为成熟[26-27],目前已有PSASP、BPA 等商业软件[28],以及MATPOWER、PSAT 等开源软件能够进行相关计算[29-30],因此具体方法不再赘述。为了体现电力系统运行状态的关键信息,本文将p定义为:

式中:Pg(1×ng)和Qg(1×ng)分别为各个机组有功和无功出力;Pd(1×nd)和Qd(1×nd)分别为各个节点有功和无功负荷;Vm(1×nn)和Va(1×nn)分别为各个节点的电压幅值和相角;常数1 为预留项,用于学习线性划分的常数项;ng、nd、nn分别为发电机组数、负荷节点数与系统节点数。
最后,将电力系统运行状态{p}及其电压稳定裕度值{y}整合为静态电压稳定数据集D:

式中:pi为编号为i的运行状态;yi为pi的电压稳定裕度值。
3)斜回归树的训练:将静态电压稳定数据集D输入斜回归树算法中进行训练,按照最大深度等终止条件训练出斜回归树各个非叶节点的划分系数向量θ与各个叶节点的代表值y~。斜回归树的训练方法详见第3 章。
4)斜回归树的集成:本文利用boosting 的思想集成斜回归树[31]。用新增斜回归树拟合已有集成斜回归树的拟合误差。为了减小过拟合的风险,引入Lasso 和Ridge 正则化项[32-33],提高集成斜回归树泛化性能的同时,增强其可解释性。斜回归树的集成方法详见第4 章。
5)反馈:如果当前训练结果达不到预期要求,一方面可以继续进行树的集成,返回步骤3);另一方面也可以判断算法在电力系统运行状态空间中泛化性能较差的位置,于该位置附近进一步采样扩充训练集,返回步骤2)。
3 斜回归树算法
本文提出的斜回归树算法具有两方面的优势,一方面是较强的表示能力,另一方面是其提取的安全稳定规则具有良好的可解释性。
斜回归树的表示能力源于采用了线性斜划分代替传统的单变量划分,不难理解,每次划分考虑运行方式向量p的全部特征显然要比仅考虑单个特征承载更多信息。斜回归树通过线性划分预测电压稳定裕度的机理为:如果电力系统运行状态pi满足线性划分θTpi<0,pi被划分到左侧子节点,斜回归树就认为pi具有左侧子节点代表值的稳定裕度,反之亦然。实现线性斜划分的关键在于如何克服指示函数I(θTpi<0)的不连续性[24],使得最优斜划分的寻找从离散优化问题转化为连续优化问题。本文将sigmoid 函数σ(z)引入斜回归树训练[34],引入σ(z)后斜划分的指示函数变为pi落在左右两侧子节点的概率值,本文将其命名为权重和,计算式为[34]:

斜回归树的可解释性表现在其预测依据明确、易于调度人员理解。提取静态电压稳定规则利用了斜回归树的可解释性:从树的根节点到叶节点t中间会经过若干线性划分判断{θTp<0?},各线性划分的划分系数列向量逐列排列成该叶节点的划分矩阵Θ,此时存在一条样本pi满足这些线性划分判断,也即满足ΘTpi<0,斜回归树就会将该叶节点的代表值作为该样本的标签预测值,各叶节点的划分矩阵整合起来就是斜回归树得到的规则。
斜回归树的训练目标是为了得到叶节点的代表值y~t与非叶节点的最优划分系数向量θ,分别对应斜回归树损失函数的构建与单次划分得分的构建。
斜决策树在训练集D={(pi,yi)}上的加权平方损失函数为:

忽略仅与训练集有关的常数项,不难发现目标函数对各个叶节点解耦。因此,对于一个叶节点而言,整棵树达到最小损失的代表值即为该叶节点达到最小损失的代表值。根据式(4),y~t可表示为:

式中:Lmin(f)|t为落在t号叶节点上的样本所能达到的最小损失,整棵树的最小损失即为各个叶节点最小损失之和。
斜回归树单次划分的得分Sscore如下:

最大化Sscore就能够得到单次划分中父节点的最优划分系数θ。根据式(6),算法将单次划分后L(f)的减小量作为单次划分的得分,即单次划分中父节点的最小损失减去2 个子节点的最小损失之和的差。构建单次划分的得分是为了简化问题规模,依次优化各节点的划分系数。式(7)中ωi0为pi在父节点的初始权重,因为采用各节点依次优化的方法,所以从根节点到该节点经过的划分也已知,从而有ωi0已知。
基于上述推导,斜回归树的训练方法可以总结为通过递归不断在当前节点上进行划分,直到达到最大深度。首先,根据输入数据集D建立当前节点。然后,通过最大化Sscore得到最优划分系数θ,如果Sscore≤0 说明本次划分并不能减小拟合误差,当前节点可以作为叶节点通过式(5)给出其代表值;如果Sscore>0 说明本次划分仍有价值,当前节点可由最优划分系数θ分成2 个子节点。最后,通过硬划分获取分入左右2 个子节点的数据集DL与DR,分别将左右2 个子节点作为当前节点继续划分,直到得到一颗完整的树。
4 集成斜回归树
斜回归树应用于大型电力系统稳定裕度分析时存在两方面的不足。一方面,运行方式向量pi的维度往往很高,划分系数向量θ往往比较稠密,不利于挖掘影响安全稳定状态的关键因素,不利于调度人员理解并应用斜回归树提取的规则;另一方面,需要进一步提升斜回归树的学习能力,确保算法能够精准辨识大型电力系统更加复杂的安全稳定边界。
为了解决上述问题,本文提出斜回归树的稀疏技术与集成方法:在Sscore中引入Lasso 和Ridge 正则化项,一方面避免过拟合保证规则的有效性,另一方面保证划分系数向量θ尽可能稀疏,使得提取规则既可靠又仅与少量关键特征强相关;然后,利用boosting 思想对稀疏斜回归树进行集成,得到集成斜回归树算法。
稀疏斜回归树的核心在于:在Sscore中同时加入Lasso 和Ridge 正则化项,每次划分的优化目标变为:

式中:α‖θ‖1和β分别为对单次划分的Lasso 和Ridge 回归惩罚项,α与β为惩罚系数;M为参与当前节点划分系数训练的数据集大小。加入Lasso 回归惩罚项的作用是使得θ稀疏,降低算法提取规则的稠密性,提升算法的可解释性;加入Ridge 回归惩罚项的作用是增加目标函数的凸性,防止因Lasso 回归惩罚项的加入导致单次划分仅与单个特征相关;而M的作用为使得惩罚系数α与β不必随M的改变做出调整。
加入Lasso 回归惩罚项之后目标函数的一阶梯度并不连续,因而不能直接通过牛顿法或拟牛顿法求解其最优值。但其一阶梯度在每一个象限内却是连续的,利用这一特性能够通过文献[24]提出的改进OWL-QN 算法优化求解其最优值。该算法只需利用Sscore的一阶梯度就可以求解得到当前节点最优且稀疏的划分系数θ。令Sscore前两项为lL(θ) 和lR(θ),则Sscore的一阶梯度函数可以表示为:

而lL(θ)的一阶梯度函数如下:

lR(θ)的一阶梯度函数与lL(θ)类似,不再赘述。
目标函数经改进OWL-QN 算法优化求解的具体过程参见文献[24],结合第3 章的训练方法即可得到稀疏斜回归树。
本文利用梯度提升的思想对稀疏斜回归树进行集成得到集成斜回归树算法。设已有集成斜回归树φ(p)集成了K棵稀疏斜回归树,则φ(p)对pi的安全稳定裕度预测值可表示为:

如果此时φ(p)的预测精度已达到所需要求,则不需要继续添加稀疏斜回归树。反之则需要将训练集中各条数据的拟合误差yi-y^i作为新增斜回归树训练数据的新标签值,然后训练稀疏斜回归树添加到集成斜回归树模型中,直到获得满足所需精度的预测模型。值得一提的是,集成斜回归树的训练过程也可以引入学习率或者特征抽样(列采样)等方法。
5 算例分析
本文选取2 个高比例可再生能源电力系统(记为IEEE-30 和RTS-GMLC)测试本算法的性能,所选系统的部分关键参数见附录A 表A1。IEEE-30系统改自IEEE-30 节点标准算例系统,在节点10、24、28 分别添加一座50 MW 的风电场和一座50 MW的光伏发电站,可再生能源装机容量渗透率为47%,关注可再生能源机组出力和负荷变化时节点8 的电压稳定情况;RTS-GMLC 系统是美国国家可再生能源实验室(NREL)提出的73 节点稳定测试系统,可再生能源装机容量渗透率为43%,关注节点3 的电压稳定情况。本节通过仿真计算在2 个系统上分别生成了22 000 和55 000 条数据,用于训练和测试数据比例为10∶1。为了展示集成斜回归树算法(简称EWORT)的各方面性能,本文将该方法与已有方法中性能表现最佳的XGBoost 算法(简称XGB)进行对比。
图3 展示了集成斜回归树算法训练误差和测试误差随树集成量的变化情况。

图3 斜回归树算法的集成效果Fig.3 Ensemble effect of oblique regression tree algorithm
图3 中,平均相对误差定义为算法在单个数据集上预测相对误差的平均值,横坐标是算法的集成量,1 表示只有单棵树。当树集成量较少时,EWORT 的误差就远低于XGB 的误差,随着树集成量的增大,EWORT 收敛到更小的泛化误差,说明它对电力系统电压稳定信息有更强的识别和表示能力。从趋势上看,虽然XGB 误差下降的幅度很大,误差下降速度比EWORT 更快,但这是因为其初始精度较差,给集成留下了相当多的学习空间。以IEEE-30 算例结果为例,EWORT 不仅能在单棵树时给出比XGB 集成20 棵树更高的预测精度,还能在集成第2 棵树时得到比XGB 集成第20 棵树时更大的误差下降幅度。
图4 展示了EWORT、XGB 与人工神经网络(ANN)在测试误差和训练时间方面的差别,左侧纵坐标轴表示测试误差,意义与图3 中平均相对误差相同,右侧纵坐标轴为训练时间,采用对数刻度。
图4(a)为IEEE-30 算例的结果,EWORT 和XGB1 的最大深度为5,集成20 棵树,XGB2 和XGB3 的最大深度为3,分别集成20 棵树和200 棵树,ANN 取三层神经网络,隐层取200 个神经元。图4(b)为RTS-GMLC 算例的结果,EWORT 和XGB1 的最大深度为5,集成4 棵树,XGB2 和XGB3的最大深度为4,分别集成4 棵树和200 棵树,ANN取三层神经网络,隐层取200 个神经元。在测试误差方面,EWORT 的泛化误差比集成度相同的XGB1 和XGB2 降低约30%;同时EWORT 能够达到与XGB3 和ANN 接近的预测精度。在训练时间方面,EWORT 短于ANN 而长于XGB。这是因为EWORT 引入Lasso 惩罚项导致目标函数的一阶梯度不连续,训练时间比XGB 更长;而ANN 需要经过多次反向传播才能达到最优的拟合效果,所以在2 个算例中,ANN 的训练时间都超过EWORT 的3 倍。这说明:在具有强可解释性的算法中,EWORT 的学习能力超越了原本表现最优的XGB,EWORT 只需少量集成就能达到XGB 大量集成的泛化性能,且在更大的系统中,这种效果更加显著;在具有强学习能力的算法中,EWORT 的泛化性能与ANN 相当的同时,训练时间更有优势。此外,ANN 的训练结果是一个黑箱,调度人员难以从中获取稳定裕度的预测依据,其预测结果出现大幅偏差的情况也将无从预知。

图4 模型测试误差和训练时间对比Fig.4 Comparison of model test error and training time
连续潮流与机器学习算法计算静态电压稳定裕度所需时间的对比结果见附录A 表A2。为了避免单次计算的随机性,表中给出的时间数据是算法完成1 000 次静态电压稳定裕度计算所需的总时间。从IEEE-30 与RTS-GMLC 的算例结果可以看出,相比于连续潮流算法,EWORT 等机器学习算法计算稳定裕度所需时间几乎可以忽略不计;相比于其他机器学习算法,EWORT 虽不具备优势,但是因单次平均计算时间过短,在实际应用时各种机器学习算法的裕度计算时间对调度人员而言相差不大。
电压稳定裕度预测值与真实值之间的对比如图5 所示。图5 中蓝点代表数据集中的一个实例,其横坐标是电压稳定裕度的真实值,纵坐标是模型对电压稳定裕度的预测值,中间橙色的线是理想中的预测结果:预测值恰为真实值。实例点越靠近橙线,模型预测效果越好。观察IEEE-30 的结果,容易发现EWORT 的预测结果更加集中到橙线附近,而XGB 存在多个远离橙线的点。观察RTS-GMLC 的结果,上述对比则更加明显,且XGB 的样本点也更加分散。由此可见,EWORT 具有比XGB 更小的预测不确定性,随着系统的增大对比更加明显。

图5 电压稳定裕度预测值分布图Fig.5 Distribution of predicted voltage stability margin
图6 展示了Lasso 和Ridge 惩罚系数的大小对树稀疏度和训练时间的影响。
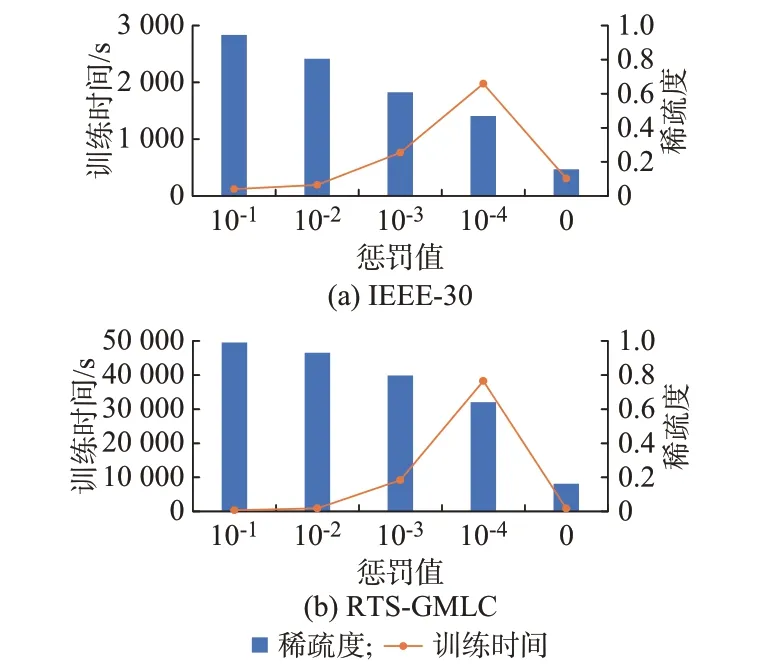
图6 惩罚值对回归树稀疏度和训练时间的影响Fig.6 Effect of penalty value on sparsity and training time of regression tree
斜决策树的稀疏度定义为划分系数向量中零元素个数的平均占比。因为树稀疏度只跟Lasso 惩罚系数有关,这里令Ridge 惩罚系数等于Lasso 惩罚系数,作为横坐标,即α值的大小,从大到小排列。图6中橙色折线的纵坐标轴在左侧表示训练时间,蓝色柱的纵坐标轴在右侧表示树的稀疏度。从图6 中可以看出,随着惩罚系数的减小,训练时间先增大后减小,树的稀疏度不断减小,说明通过增大α能够大幅增加树的稀疏度,减小训练时间;α接近零时训练时间大幅增加;α为零时并不能有效限制树的稀疏度,但是训练时间却有所减小。由此可见,适当增大α能够使划分系数向量变得稀疏,从而使提取规则更加简单可解释。
单棵斜回归树提取IEEE-30 系统的静态电压稳定规则示例见附录A 图A1。该树精度达99.14%,在训练时选取了较大的α,得出了极度稀疏的斜回归树。即便如此,该树仍比同参数的XGB 泛化误差降低约17%。算法可解释性在电压稳定的场景下表现为调度人员对稳定裕度预测依据的了解程度,斜回归树的预测依据在图中表现为非叶节点中的不等式判断。从图A1 中可以看到,前两层的不等式判断同单变量回归树一样都只与节点8 的电压有关,斜回归树认为首先要根据节点8 的电压判断节点8 的电压稳定裕度。整棵树与单变量回归树最大的差别在第3 层最左侧的节点,其预测依据同时与多个特征量有关:距离节点8 较近的节点27 的电压在划分中占主导地位,节点2 的电压和此处发电厂的有功出力起辅助作用。在这个中间节点分裂出2 个电压稳定裕度代表值较小的叶节点,说明斜回归树通过斜划分处理好了低稳定裕度情况下数据集的划分,从而得到了超过XGB 的预测性能。此外,如果没有引入正则化项,尤其是Lasso 惩罚项,非叶节点的划分将与所有输入特征相关,算法提取的规则不会如附录A 图A1 那样简单、易于理解。
6 结语
本文提出了内嵌安全稳定约束的电力系统优化运行框架和用于电力系统安全稳定规则提取的斜回归树及其集成算法。该算法具有较强的表示能力与良好的可解释性。算例分析结果表明集成斜回归树具有超过同类算法XGBoost 的学习能力与集成效率。
斜回归树及其集成算法能够用于电力系统安全稳定规则提取,有望成为在电力系统优化运行中考虑安全稳定约束的突破性技术。后续将研究所提出的框架如何应用于考虑暂态电压等稳定问题的电力系统优化运行以及所提出的线性规则如何内嵌电力系统优化运行模型。
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
猜你喜欢
电气电子教学学报(2022年3期)2022-07-30
中国舰船研究(2022年1期)2022-03-19
世界科学技术-中医药现代化(2021年8期)2021-12-21
有色设备(2021年4期)2021-03-16
科学导报·科学工程与电力(2019年22期)2019-10-21
宇航总体技术(2018年5期)2018-10-15
电子制作(2018年16期)2018-09-26
北京汽车(2018年2期)2018-05-02
中国交通信息化(2017年11期)2017-06-06
电子制作(2017年24期)2017-02-02
