
基于社交网络分析的区间二元语义群决策方法研究
2022-01-21 01:54宗梦婷宗梦环
管理学报 2022年1期
宗梦婷 宗梦环 陈 曦
(1. 南京大学商学院; 2.南京财经大学营销与物流管理学院)
1 研究背景
随着政治、经济、社会等不同领域中涉及的决策问题的复杂性日益增强,相关参与者越来越多地依赖群体智慧,多属性群决策在多个领域被广泛应用[1,2]。语言信息多属性群决策问题的研究,主要关注专家评价信息的量化和聚合方式、专家权重的确定等问题。
语言信息的量化和集结一直是群决策问题的研究重点[3]。关于专家判断信息集成的方法,通常使用加权几何平均(WGA)算子[4]、有序加权平均(OWA) 算子[5]、有序加权几何平均(OWGA)算子[6]、基于诱导有序加权平均(IOWA)信息聚合算子[7]等。但是,通过这些方法得到的专家群体信息可能是整体平均的,忽略了偏离平均水平的一些信息。由此,需要选择更优的方法对专家判断信息进行量化和集结,以减少信息的丢失,改进现有的集结方法。
在群决策过程中,确定专家权重是非常关键的环节。专家权重可分为客观权重和主观权重。客观权重一般通过定量判断每个专家偏好信息的质量,专家客观权重的获取方法大多依赖于各专家与群体的一致性程度,专家的判断信息越接近群体的一致性,相应的专家权重越大[8]。还有一些研究同时考虑主观权重和客观权重,将两者结合以确定综合权重[9]。主观权重一般指已知的信息,如参与专家的名声、地位、职业、社会关系、对当前问题的熟悉程度和自信程度等[10]。专家在社交网络中的位置是专家地位和影响力的一个重要特征,也是确定专家权重时应该考虑的重要因素[11],社交网络分析是常用于研究个人、团体、组织甚至整个社会之间关系的一种理论结构[12]。已有众多学者在社交网络分析的框架内对群决策问题进行了研究[7]。BRUNELLI等[13]通过内生性计算决策者在社交网络中影响力的重要性,解决了感知评价的问题。WU等[11]提出一种基于社交网络分析的信任共识的群体决策模型,该模型具有区间值模糊互惠偏好关系,是将信任程度和共识程度结合到群决策问题领域的最早尝试之一。PÉREZ等[7]提出新的基于诱导有序加权平均的社交网络分析算子,在社交网络决策框架内聚合社会群体偏好。WU等[11]利用信任关系计算聚集过程中专家的权重。同时,真实的群决策问题不仅涉及到评价信息的量化和集结,还涉及人的心理因素[14,15]。由于时间限制、专家在相关领域的知识或经验有限,专家在决策过程中针对不同方案的不同属性时,可能会带有不同程度的自信[16]。自信偏好关系可以反映一个人在群决策过程中的知识、经验或态度[17],为研究决策科学中的多重自信提供了更为普遍的理论依据。例如,DONG等[18]验证了大多数情况下自信偏好关系可以提高最终决策的质量。LIU等[19]提出一种新的基于自信多重偏好关系的群体决策共识方法。LIU等[20]提出一种新的SC-FPRS加性一致性度量和改进方法,并引入一种新的SCI-IOWA算子用于群体决策。由此可见,专家的自信偏好关系同样应该被看作是决定其权重的重要因素。
然而,群决策过程中考虑专家之间社交网络关系兼顾专家自信偏好的研究较少。鉴于此,本研究旨在探索一种新的社交网络分析框架下同时考虑到专家自信偏好关系的群决策方法。社交网络关系可以表示联接关系、跟随关系、合作关系、沟通关系等,本研究主要考虑专家之间的信任关系。本研究需要进行以下工作:①设计基于Steiner点的区间二元语义的集结方法,考虑相同粒度语言信息和不同粒度语言信息,减少初始语言信息的丢失和失真,简化集结过程;②在决策过程中,考虑专家之间的社交网络关系和专家的自信偏好关系,提出一种基于社交网络分析和自我评价的区间语义群决策的新方法;③定义专家的相对重要程度和群体相似度,以获取专家客观权重,更客观地评估专家的整体能力。
2 问题描述和基础知识
2.1 区间二元语义群决策问题
本研究探讨的是基于社交网络分析和专家自我偏好关系的区间二元语义群决策问题,西班牙学者HERRERA等[21]首次提出了二元语义分析方法,采用二元语义形式表示指标或属性的语言判断信息,并用二元语义相关运算规则进行处理,可有效避免之前提出的在群决策过程中信息的丢失和失真问题,使语言信息的集结结果更具真实性和可信度。基于社交网络分析和专家自我偏好关系的区间二元语义群决策问题的定义如下:
定义1基于社交网络分析,考虑专家自我偏好关系的区间二元语义群决策问题包含以下几个基本要素:提供的备选方案集X={x1,x2,…,xm},m≥2;备选方案的属性集Y={y1,y2,…,yn},n≥2;参与的专家群体E={e1,e2,…,ep},p>3;参与专家的社交网络结构矩阵F;参与专家的初始权重IW={v1,v2,…,vp}。假设S={s1,s2,…,sg}是粒度为g+1的有限语言短语集,决策专家根据语言短语集对备选方案各个属性给出自我偏好信息。设专家给出的属性判断矩阵为ξ,自我偏好信息矩阵为C,专家ek(k=1,2,…,p)提供的初始信息矩阵表示为
Ak=[(ξ(k)ij)m×n,(C(k)ij)m×n] ,
(1)
式中,i=1,2,…,m;j=1,2,…,n;k=1,2,…,p;属性评价信息ξ(k)ij和自我评价信息C(k)ij采用区间二元语义信息的表达形式,两者属于并列信息,不存在逻辑上的比较和计算关系。
2.1.1二元语义表示模型
二元语义是指采用一个二元组(si,αi)表示语言形式判断信息的方法。其中,si表示事先定义和选择的语言判断信息集中存在的语言短语;αi表示由专家给出的语言信息与事先定义和选择的评价集中最贴近语言短语之间的差别值,αi∈[-0.5,0.5)。所以,二元语义可以理解为一种以符号平移为基础的概念。下面对二元语义给予具体介绍[22]。定义2~定义5给出二元语义的相关运算规则。
定义2设si∈S为语言信息,则可根据以下的转换函数θ得到相应的二元语义形式的语言短语:
θ:S→S×[-0.5,0.5) ,
θ(si)=(si,0),si∈S。
(2)
定义3假设语言信息评价集S={s0,s1,…,sg},β∈[0,g]是一个数值,表示语言符号集结运算的结果,则可根据以下公式将β转化为相应的二元语义函数:
Δ:[0,T]→S×[-0.5,0.5) ,
(3)
式中,Round表示“四舍五入”取整运算。
定义4假设语言信息评价集S={s0,s1,…,sg},(si,αi)是一个二元语义,则可根据以下逆函数Δ-1将二元语义转换成相应的数值β∈[0,g]:
Δ-1:S×[-0.5,0.5)→[0,g] ,
Δ-1:(si,αi)=i+αi=β。
(4)
定义5假设(si,αi),(sj,αj)为任意两个二元语义,其具有以下性质:①二元语义的比较规则:若si>sj,则(si,αi)≻(sj,αj);若si=sj,αi>αj,则(si,αi)≻(sj,αj);若si=sj,αi=αj,则(si,αi)=(sj,αj)。②二元语义的逆运算转换规则表示为
Neg{(si,αi)}=Δ{T-[Δ-1:(si,αi)]}。
(5)
2.1.2区间二元语义
下面定义6给出区间二元语义信息的定义;定义7给出区间二元语义信息的期望和方差,并定义区间二元语义的比较模型。
定义6[23]假设S={s0,s1,…,sg}是一个语言短语集,其中两个语言短语构成一个区间语义信息[si,sj],i≤j;si,sj∈S,si和sj表示下限和上限。则[(si,αi),(sj,αj)]表示区间二元语义信息;(si,αi)和(sj,αj)表示下限和上限。其中,i≤j;si,sj∈S;αi,αj∈[-0.5,0.5),表示由计算得到的语言信息与初始语言评价集中最贴近语言短语之间的差别。

(6)
(7)
(8)

2.2 社交网络分析
社交网络分析是一种基于图模型的系统中社会实体间关系抽象的有效策略。通过对群体与社交网络的关系建模,社交网络是指一组节点根据它们之间的关系通过链接进行连接的图。社交网络可以被看作是一个平台,在这个平台上,用户可以分享信息,互相交流;同时,用户之间的关系可以通过社交网络分析得到。一般来说,在一个社交网络中,有3个主要元素:参与者、参与者之间的关系、参与者的属性。社交网络结构具有3种不同的表示方案[24](见表1)。也可以使用统一的方式详细地表示社交网络概念,见定义8。

表1 社交网络分析的不同表现形式
定义8[11]社交网络是一个有向图G(E,L),其中E表示专家集,E={e1,e2,…,ep},p>3,L是节点之间的有向直线或弧的集合,L={l1,l2,…,lq},边(ek,eh)∈L表示专家eh直接影响专家ek(k,h∈P),P表示专家个数集。一个社会计量的F=(fkh)m×m(fkh∈{0,1})被用来表示G(E,L):
(9)
式中,fkh=1表示专家fh直接影响fk(k,h∈P)。
显然,定义8仅描述的是社交网络中专家之间的二元关系:完全影响或完全不影响。然而,在大多数情况下,很难明确描述专家之间的影响关系,因为在描述社交网络结构时,专家之间的关系常常存在不确定性。由此,引入以下模糊社会计量:
定义9[15]区间值模糊社会矩阵FL是E×E与关系函数UFL:E×E→[0,1]的关系,UFL(ek,eh)=fkh,其中fkh表示fk分配给fh的信任度(k,h∈P)。在不失一般性的前提下,采用模糊社会计量的方法描述专家之间的信任关系。
下面给出示例说明,以便进一步解释。示例:矩阵F=(fkh)5×5(k,h=1,2,…,5;k≠h)表示它们之间的信任关系:

定义10假设F=(fkh)p×p(k,h=1,2,…,p;k≠h)为社会计量矩阵,那么ek的社交网络信任权重系数NW(ek)为
(10)
3 基于社交网络分析的区间二元语义群决策框架
本研究针对的群决策问题已在定义1中详细描述。本节介绍一种基于社交网络分析的区间二元语义群决策框架,主要框架分为以下几部分:①初始信息处理。本研究设计了基于Steiner点的区间二元语义量化和集结方法,将专家初始语言信息映射为二维空间的点集,对专家的判断信息和自我评价信息进行处理,便于语言信息的量化。②专家判断信息之间的偏差距离。此部分的核心是用映射点之间的欧式距离代表语言信息之间的偏差。计算专家判断信息之间的距离,继而获取相对重要程度;计算专家判断信息与理想集结信息之间的距离,继而获取专家与群体的相似度;计算专家自我评价的与最高评价之间的距离,继而获取自信程度系数。③权重的获取。获取自信程度系数和社交网络影响力系数,根据专家的相对重要系数、群体的相似度指数,获取专家的综合权重。④信息的集成。根据综合权重对初始信息进行集成,对方案排序和择优。这些阶段将在后文进一步详细描述。
3.1 专家初始语言信息的处理
3.1.1将区间二元语义信息映射为平面点集
在二维空间中,任意两点之间的实际距离,即欧氏距离,可用来表示任意两个专家之间的偏差。下面主要描述将区间二元语义信息映射为平面点集的转化规则,定义11给出将相同粒度区间二元语义信息映射到二维空间点的转化规则,定义12给出将不同粒度区间二元语义信息映射到二维空间点的转化规则。

βk=[βa(k)ij,βb(k)ij]m×n∈R2。
(11)

(12)


(13)
3.1.2区间二元语义信息的集结
(1)相同粒度区间二元语义信息的集结

(2)不同粒度区间二元语义信息的集结
假设不同专家根据不同粒度的语言短语集给出区间二元语义信息为[(sa(1)ij,αa(1)ij),(sb(1)ij,αb(1)ij)],…, [(sa(p)ij,αa(p)ij),(sb(p)ij,αb(p)ij)],Ap=a(p)ij+αa(p)ij,Bp=b(p)ij+αb(p)ij,粒度分别是g1,g2,…,gp,根据定义12可得到评价信息的分解区间矩阵为
(14)

(3)Steiner点概念
接下来,定义13描述Steiner点的定义,根据Steiner点的定义可知,要找的最优集结点即对应点集的Steiner点。


3.1.3运用PGSA获取最优集结点
初等几何方法并不能找到最优综合集结点,当然随着专家群体的扩大,即已知二维坐标点数的增加,找到最优综合集结点的难度会随之增大。为了寻找到最优综合集结点,本研究采用模拟植物生长算法[26]来加以解决。由于PGSA具有参数设置简单、限制少,各方向性的随机搜索能力强、稳定性高的特点,因此,在求解全局最优解方面具有很大的优越性,近年来已被国内外学者广泛地应用于诸多研究领域[27,28]。
考虑p个已知点e1,e2,…,ep(p>3),每个点相应的权重是w1,w2,…,wp(p>3),应用PGSA求解Steiner点,即最优集结点E的具体方法如下:
步骤1确定初始生长点ah∈X,X为Rn中的有界闭箱,有界闭箱的长度为l,H为生成初始点的个数,这些初始生长点ah为有界闭箱内随机均匀的点;
步骤2求解各生长点的生长概率
(15)
步骤3根据步骤2的结果建立各生长点在[0,1]区间上的内概率空间,以随机数来选择本次迭代生长点am;
步骤4确定步长λ(一般取l/1 000),生长点ah按照∂=90°的L系统进行生长,用新的生长点中集结点替换ah;
步骤5若不再产生新的生长点且达到预设定的迭代次数,分别得到全局最优解和局部最优解,则停止计算,否则转步骤2。
3.2 专家初始语言信息之间距离的计算
3.2.1专家判断信息之间的距离
根据定义11和定义12,将决策矩阵中的区间数映射到二维坐标中。在二维空间中,任意两点之间的欧氏距离可用来表示任意两个专家之间的差异。定义14描述了个体专家的相对重要系数的确定。
定义14专家ek的判断信息与专家eh相对距离表示为θkh,通过式(16)确定。
θkh=1-
(16)
式中,k=1,2,…,p;h=1,2,…,p;k≠h。因为有p位专家,所以相对重要系数RW(ek)表示为
(17)
3.2.2专家判断信息与专家群体最优集结信息之间的距离


(18)
SW(ek)=1-
(19)
3.2.3专家自我评价信息与最大自我评价信息之间的距离
专家ek给出的初始信息矩阵为Ak=[(ξ(k)ij),(C(k)ij)]m×n,i=1,2,…,m;j=1,2,…,n;k=1,2,…,p。其中,ξ(k)ij代表方案属性判断信息;C(k)ij代表专家自我评价信息,两者都是采用区间二元语义形式表示,根据定义11的描述,可以将自我评价信息映射为平面点集γk=[γa(k)ij,γb(k)ij]m×n∈R2,i=1,2,…,m;j=1,2,…,n;k=1,2,…,p。定义16主要描述专家自信程度系数的计算。

(20)
CW(ek)=1-
(21)
3.3 专家综合权重的获取
针对区间语言信息群决策问题,本研究提出一种考虑社交网络分析和专家自我评价的专家综合权重的确定方法。主要包括调整主观权重、获取客观权重、获取专家的综合权重3个部分。
(1)调整主观权重通过定义10可获取专家ek社交网络信任权重系数NW(ek)(k=1,2,…,p),根据定义16可获取自信程度系数CW(ek)(k=1,2,…,p),结合专家初始权重IW(ek)(k=1,2,…,p),并运用式(22)调整给定的初始主观权重。
(22)
(2)获取客观权重根据定义14和定义15可以得专家ek的相对重要系数RW(ek)(k=1,2,…,p)和专家ek相似度权值系数SW(ek)(k=1,2,…,p),使用RW(ek)和SW(ek),并运用式(23)获取客观权重。
(23)

(24)

3.4 根据综合权重对初始判断信息进行集成
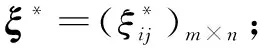
3.5 基于社交网络的区间二元语义信息的群决策步骤
综上所述,基于社交网络的区间二元语义群决策的步骤可总结如下:
步骤1处理专家的初始属性评价信息和自我评价信息;
步骤2计算专家的相对重要系数RW(ek)、专家与群体的相似度系数SW(ek)、专家的自信程度系数CW(ek);
步骤3调整专家的主观权重,获取专家的客观权重,进而确定专家的综合权重;
步骤4结合专家的综合权重对方案的判断信息进行集成,获取方案最终的综合判断信息,对方案进行排序并选出最优方案;
步骤5结束。
4 算例与对比分析
4.1 算例
本节将基于社交网络分析的区间二元语义群决策方法,应用于考虑专家社交网络分析和自我评价信息的区间二元语义群决策问题中,以详细地展示其实施过程。问题描述如下:随着社交媒体、移动、分析、云计算、物联网等技术的发展和运用,数字化带来企业战略、过程、文化、产品和服务等方面的变化。对企业来说,理解和衡量其数字能力有助于分析数字技术带来的机遇和挑战[29]。本研究将企业的数字化能力总结为数字技术资源、数字化互补资源、数字化战略、数字化运营、数字化文化、数字化生态6个维度[30],表示为属性集Y={y1,y2,y3,y4,y5,y6},并构建企业数字能力水平的评价模型;选择4个数字化转型中的企业作为备选决策集,表示为X={x1,x2,x3,x4};参与的4位专家群体表示为E={e1,e2,e3,e4};专家初始权重为v1=0.10,v2=0.30,v3=0.20,v4=0.40。参与专家的社交网络信任结构关系用有向图表示(见图1):

其区间值模糊矩阵F如下:

S={s1,s2,s3,s4,s5,s6,s7}是粒度为7的有限语言短语集,专家根据语言短语集对备选方案各个属性给出判断信息和自我评价信息。4位专家给出的属性判断信息见表2,自我评价信息见表3。如果专家根据不同粒度的语言短语集给出备选方案的判断信息和自我评价信息,则根据前文描述的不同粒度的区间二元语义信息处理规则进行映射和集结,其他决策过程与相同粒度语言短语集一样。

表2 专家e1,e1,e1,e1给出的企业数字化能力水平属性判断信息矩阵

表3 专家e1,e2,e3,e4的自我评价信息矩阵
根据专家给出的属性评价信息和自我评价信息,本算例的决策步骤如下:
步骤1对初始信息进行处理。
根据定义4描述的二元语义转换规则和定义11中描述的映射规则,对专家e1的属性判断矩阵进行处理,得到属性信息对应的二维空间点集(见表4)。同理可知,专家e2,e3,e4处理得到的区间数矩阵和专家的自我评价的区间数矩阵,因篇幅有限这里就不全部列出。考虑专家权重:v1=0.10,v2=0.30,v3=0.20,v4=0.40,根据定义15计算可以得到专家的最优集结矩阵(见表5)。

表4 专家e1的属性判断矩阵对应二维空间点的坐标集

表5 企业数字能力水平属性判断信息的最优集结矩阵
步骤2计算专家的相对重要系数RW(ek)、专家与群体的相似度系数SW(ek)、专家的自信程度系数CW(ek)。①根据定义14中式(16)计算可得相对距离(1)为提升最终计算结果的精确性,在计算专家评价信息之间相对距离θ时保留6位小数,文中其他计算结果保留一位或两位小数。:θ12=0.615 343,θ13=0.868 103,θ14=0.628 415,θ21=0.588 525,θ23=0.591 484,θ24=0.864 069,θ31=0.837 830,θ32=0.530 458,θ34=0.507 516,θ41=0.573 646,θ42=0.854 199,θ43=0.540 413;根据定义15中式(17)计算可得:RW(e1)=0.70,RW(e2)=0.68,RW(e3)=0.63,RW(e4)=0.66。②根据定义15计算可得专家与群体的相似度指数:SW(e1)=0.27,SW(e2)=0.24,SW(e3)=0.26,SW(e4)=0.23。③因本研究专家选择的有限语言集为S={s1,s2,s3,s4,s5,s6,s7},可知专家自我评价的最大值为[(s7,0),(s7,0)],根据定义16计算可得专家的自信程度系数:CW(e1)=0.75,CW(e2)=0.80,CW(e3)=0.69,CW(e4)=0.76。

步骤4结合专家的综合权重对方案的判断信息进行集成,获取方案最终的综合判断信息,对方案进行择优和排序。


表6 考虑专家综合权重获取的最优集结矩阵
4.2 与其他集结方法的比较
利用表5中给出的专家属性评价信息,得到基于PGSA的最优区间数;然后分别使用几何平均、DT-OWA两种集结算法对信息进行聚合;最后计算不同方法得到的集合点与其他点距离之和。比较结果见表7。由表7可知,PGSA得到的集合点与其他点的距离之和最短,这说明PGSA得到的集结信息最能代表专家的综合评价。

表7 不同集结方法获取的集结信息对比
5 结语
本研究设计了基于Steiner点的区间二元语义集结方法对评价信息进行量化和集结,将每个专家的评价矩阵映射为二维空间点集,并获取最优集结矩阵,达到帕累托最优;在调整专家主观权重时,定义了专家的自信程度系数,并考虑专家在社交网络结构中的影响力;在调整专家客观权重时,考虑各决策矩阵的相似度系数,并结合主观权重和客观权重评估了专家的整体影响力。
本研究提出的方法丰富了区间语言多属性群决策问题中,语言信息的量化、集结以及专家综合权重的获取两个关键环节的研究。管理者在决策时,不仅需要考虑专家之间的社交网络关系(外部地位)和专家自我评价信息(内部自信),还需考虑专家与专家、专家与群体的差异对其权重的影响,从而进一步保证专家权重度量的真实性和客观性。
但本研究提出的决策方法只考虑了专家社交网络结构的中心度特征;给出的算例缺乏管理理论基础。在未来的研究中,可以探索具有更大专家群体、更多方案属性、更多专家社交网络结构特征、更多专家主观情绪的群决策问题的量化、集结和优化,开发和丰富此方法在不同实践和管理领域的应用。此外,未来的决策理论和方法可以与数字科学、计算实验、战略管理等不同学科交叉融合,实现客观、科学的决策。
猜你喜欢
中学生数理化·八年级物理人教版(2022年9期)2022-10-24
中国水运(2022年4期)2022-04-27
建材发展导向(2022年4期)2022-03-16
卫星应用(2022年1期)2022-03-09
开放教育研究(2020年2期)2020-03-31
中国外汇(2019年13期)2019-10-10
铁道通信信号(2018年3期)2018-04-19
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
长江学术(2016年4期)2016-03-11
