
基于LSTM-FCN的并发查询执行计划选择
2022-01-25 18:54章彬慧宋春花牛保宁柳浩楠陶温霞程永强
计算机工程与应用 2022年2期
章彬慧,宋春花,牛保宁,柳浩楠,陶温霞,程永强
太原理工大学 信息与计算机学院,山西 晋中 030600
查询是数据库系统的主要负载,查询执行的效率决定数据库系统的性能。为查询选择合适的执行计划是提高数据库系统的性能、最终提升应用系统性能的关键。目前数据库系统在选择执行计划时由于:(1)代价模型(cost model)[1]对执行计划的代价估计不准确;(2)很少考虑查询之间的相互影响——查询交互(query interaction)[2],孤立地为查询选择执行计划,导致选择的执行计划很难在不同场景下都是合适的。这里的“合适的”是指查询的执行不仅是高效的,同时它的执行不会显著降低系统的效率。
一方面,代价估计不准、估算复杂查询的成本太高导致查询优化器无法为查询选择最优的执行计划。执行计划是数据库系统执行查询语句的操作组合,查询优化器通常将其表示为一棵二叉树。一般地,一个查询有多种执行计划,这些执行计划返回相同的结果集[3],但是它们的执行代价差别很大。查询优化器基于左深树(left-deep tree),按照一定的搜索策略,如System-R[4]算法、基因算法[5]等,为查询选择候选执行计划(candidate execution plan),其原则是在不坏的执行计划(左深树)中,根据表和索引的统计信息,估计各个执行计划的代价,从中选出较优的执行方案。
另一方面,多个查询并发运行是数据库系统运行的常态,选择执行计划时应该考虑查询间的相互作用。并发运行的一组查询被称作查询组合(query mix)。在查询组合中,查询之间会相互影响,产生查询交互。查询交互的本质是并发查询对系统资源的争用或共享,通常引起查询使用资源量或时间的改变,也就是执行计划代价的改变,从而导致查询执行性能的降低或提高[6-7]。例如:一个查询读入缓冲池的数据,被另一个查询利用,减少对I/O资源的使用;多个查询同时进行多个外排序与逐一进行排序相比,由于用于排序的内存不同,前者需要更多的I/O。由于查询交互极其复杂,一个查询在不同查询组合中经受的查询交互千差万别,执行计划代价改变程度也不同。查询优化器基于代价模型选择的执行计划在一个查询组合中是合适的,在另外一个查询组合中很可能不是合适的。因此,执行计划的选择需全面考虑当前查询组合下的查询交互因素,才能找到合适的执行计划。在实践中,查询优化器在选择执行计划时,把一些系统配置参数,如并行度(multi programming level,MPL)、缓冲池的大小、排序堆的大小等作为选择执行计划的因素。这样做,或多或少能够考虑一些查询交互因素,但是,这种参数是静态的,选择的执行计划也是静态的[7],覆盖的查询交互因素不足以全面反映查询交互的动态变化。
综上所述,为了能够选择适合实际场景的执行计划,需要综合考虑查询本身的代价及查询交互因素。这是一项复杂的任务,很难用一个简单的数学模型来描述。深度学习的出现和其在数据管理中的应用,为解决上述问题提供了新的思路:构建深度学习网络,融合反映查询执行代价的查询组合执行计划特征(features of plans,FoP)和反映查询交互的查询组合交互特征(features of query interaction,FQI),组成查询组合特征(query mix features,QMF),作为网络的输入,为查询动态选择执行计划。
本文针对周期性地运行一批固定查询的联机分析处理(on-line analytical processing,OLAP)场景,提出用深度学习实现并发查询执行计划的选择。
问题描述:一个数据库系统D={M,R,T},其中M={qi|i=1,2,…,m}表示正在运行的查询组合,R表示查询组合中查询间的查询交互,T表示数据库系统中关系的集合。当查询qj到来时,从查询优化器为其筛选的候选执行计划集合Q={qj_c|c=1,2,…}中,选择一个合适的执行计划,使得新查询组合的执行效率最高。
本文的创新点如下:
(1)使用LSTM与FCN构成的LSTM-FCN实现并发查询执行计划的选择。用LSTM学习时域特征、FCN实现特征融合及分类,为查询动态选择适合当前执行场景的执行计划。
(2)同时考虑执行计划与查询交互两方面的因素为查询选择执行计划。设计充分体现查询组合中所有查询特征的编码方式,将查询组合执行计划与查询组合交互度量值QueryRating[6]共同作为神经网络输入特征来源。
1 相关工作
本章首先介绍当前查询优化器选择执行计划的方法,然后讨论考虑查询交互因素、选择执行计划的方法,最后讨论深度学习在选择执行计划上的应用。
1.1 查询优化器选择执行计划的方法
一条查询语句经过解析器转换为查询树,查询优化器以查询树作为输入,根据关系访问方式、连接方式及连接顺序生成可能的执行计划,然后依据代价模型[1]选择代价最小的方案,作为该查询的较优执行计划,并制定一个完整的规划树传递给执行器[4]。主流数据库管理系统的查询优化器都是基于代价策略选择执行计划。改善代价估计不准确的主要途径是通过修正统计信息[8-9]。优化器为并发查询选择执行计划时,通过一些静态的参数[10-12],如并行度、缓冲池的大小、排序堆的大小等,体现查询交互的影响。参数固定时,选择的执行计划也固定不变,参数配置不能准确描述查询交互。
1.2 考虑查询交互因素选择执行计划的方法
TRating[7]模型只考虑查询交互因素,为并发查询选择执行计划,取得了较好的效果,显示查询交互是影响执行计划选择的主要因素。
BAL(buffer access latency)[13]、QueryRating[6]通过度量查询交互来预测查询响应时间,提出了度量查询交互的方法。BAL方法主要考虑逻辑读/写代价,以查询并发与单独运行的时间差衡量查询交互。QueryRating方法综合考虑逻辑读/写、查询计算的代价等,以查询两两运行与单独运行时响应时间的比值,量化两个查询之间的查询交互。TRating提出的QIs方法[7]认为,查询单独运行的响应时长会影响其加入查询组合后受到查询交互的持续时长。
上述模型和方法揭示了查询交互是影响查询执行的主要因素。其他一些研究虽然没有提出查询交互的概念,但是实质上利用查询交互中的查询合作来优化查询的执行,包括查询结果集的共享访问[14]、查询间数据的共享扫描[15]及操作符的共享[16]等并发查询优化方法。并发查询执行过程中,查询间不仅存在查询合作,更多的应该是查询竞争。查询交互反映了查询间的合作和竞争关系。
本文采用QueryRating度量查询两两之间的交互,构造查询组合交互特征FQI,把查询交互作为主要因素为并发查询选择执行计划。
1.3 深度学习在选择执行计划上的应用
随着人工智能的发展,近几年研究人员将深度学习与数据库性能优化问题相结合取得了较好的成果[8-9,17],这些研究主要侧重于改进查询优化器代价模型或提高基数估计准确率。使用LSTM,将执行计划作为模型输入,为特定查询预测响应时间[18]达到了较高的准确率。基于强化学习的Neo(neural optimizer)[19],利用神经网络调整搜索策略,为查询生成较优的执行计划。使用图嵌入对并发查询进行查询性能预测[20],图模型的每个顶点是执行计划中的一个操作,两个顶点之间的边表示它们之间的相关性,例如,共享相同的表、索引或竞争的资源。
基于现有代价模型很难准确估计执行计划的代价、复杂多变的查询交互使得简单的数学模型无法作为选择执行计划的依据。本文提出用LSTM-FCN,同时考虑执行计划与查询交互,为查询动态选择适合当前查询组合的执行计划。
2 方法
用深度学习神经网络解决问题的关键是:获取样本数据,构造合适的输入特征,选择适合描述问题的网络模型。按照这一思路,2.1节对问题进行分析,讨论解决问题的思路。对于样本数据的获取,2.2节介绍查询组合交互信息的获取及预测标签的设计与编码,2.3节讨论输入特征QMF的设计。2.4节,给出LSTM-FCN模型的网络结构及网络参数设计。
2.1 问题分析与解决思路
解决引言中所提问题的关键一点是,如何判断执行效率最高。查询qj的到来,对M产生了新的查询交互,引发其本身及M中各查询执行状态的改变。可以通过度量这种改变来判断查询的执行效率。这种改变具体表现为两个方面:查询等待资源时间的改变和查询获得资源量的改变(代价的改变)。查询响应时间是等待时间与执行时间之和,反映了查询交互的后果,它的变化程度表征了查询交互的程度。QueryRating[6]用查询响应时间的变化程度度量两个查询之间查询交互的大小。

其中,tji表示查询qj与查询qi并发时qj的响应时间,tj表示查询qj单独运行时的响应时间。若Rji小于1,表示查询qi对查询qj的执行有促进作用。Rji越小,表示查询qi对查询qj的促进作用越强。反之,Rji大于1,表示查询qi对查询qj的执行有抑制作用。Rji越大,表示查询qi对查询qj的抑制作用越强。Rji等于1,表示两查询并发时不存在相互作用。
查询单独执行时不需要等待资源,它的响应时间是执行计划代价的体现。并发查询的QueryRating值越小,消极查询交互越小,查询的执行效率越高。假设查询qj有执行计划qj_1、qj_2,它们到来之后受到M的查询交互作用,QueryRating值前者小于后者。但是M中各查询与qj_1并发时,QueryRating值大于它们与qj_2并发时的QueryRating值,那么qj_1、M的QueryRating之和可能大于qj_2、M的QueryRating之和,即qj执行效率较高的执行计划可能降低新查询组合的执行效率。受到QueryRating的启发,将查询qj与M的查询交互作用之和,作为描述新查询组合执行效率高低的标准。查询交互作用之和用QueryRating之和表示。其中qj受到M的QueryRating值越小,表示查询qj受到M的消极查询交互越小,qj的执行效率越高。M受到qj的QueryRating值,用M中各查询受到qj的QueryRating值之和表示,该值越小,表示M的执行效率越高。qj执行效率与M执行效率之和表示qj到来之后,新查询组合的查询效率。
需要注意的是,qj到来之后,可能会造成M中各查询之间查询交互的调整,本文认为这个影响较小,暂时不予考虑。基于以上分析,将新查询组合中的QueryRating之和作为判断其执行效率高低的标准,并以此为目标函数,选择合适的执行计划:

其中,RjM和RMj分别表示qj与M并发运行时,qj和M受到对方的查询交互作用,tjM和tic分别表示qj以候选执行计划qj_c与M并发运行时,qj和M中的查询qi的响应时间。
公式(2)中,tjM/tj和tic/ti分别表示在qj以候选执行计划qj_c与M并发运行的情况下,qj和M中的查询qi相对于它们单独运行时响应时间的变化程度。tjM/tj小于1,表示查询qj以候选执行计划qj_c加入到M之后,qj_c响应时间变短,M与它的积极查询交互提升了qj_c的执行效率;反之,降低了qj_c的执行效率。表示查询qj以候选执行计划qj_c与M并发运行情况下,M中各查询响应时间总体的变化程度。该值越小,表示qj_c与M的查询交互提升了M的执行效率,反之,降低了M的执行效率。表示qj_c到来之后,新查询组合的响应时间的改变程度。该值越小,表示查询qj的候选执行计划qj_c对查询组合的执行效率提升程度越大,该执行计划越适合与M并发运行。
在网络输入方面,执行计划表征了查询执行的代价,从执行计划中可以提取代价信息,构造FoP。查询交互往往造成查询等待资源和执行代价的改变,体现在查询响应时间中,因此,可以从查询响应时间的改变中获取查询交互信息,构造FQI,进而得到模型输入特征QMF。
在深度学习网络的选择方面,考虑到查询执行过程中,各操作之间存在一定的时序关系,而LSTM模拟时间关系,持续保留层间关系,可以描述查询内部的时域特征。FCN融合特征,实现分类。因此,本文使用LSTMFCN实现并发查询执行计划的选择。
2.2 查询组合交互信息的获取及预测标签的设计与编码
根据2.1节的讨论,查询响应时间的变化程度反映了查询交互的后果。在OLAP场景中,一批查询周期性运行,查询qj单独执行的响应时间及其与查询组合M并发运行时的响应时间容易获得。M中各查询对查询qj造成的响应时间的改变程度可以表示为:Rj1,Rj2,…,Rji,…,Rjm。基于以上分析,用查询交互值QueryRating[6]的改变程度反映查询交互导致的查询执行代价的改变,进而构造查询qj受到M的查询组合交互特征FQI。
公式(2)是评价执行计划是否合适的指标,因此,将预测标签定义为与候选执行计划一一对应c位向量L,L=(lj_1,lj_2,…,lj_c)。L中,与查询组合M并发执行时,qj合适的执行计划对应位为1,其余位为0。
2.3 输入特征QMF
根据上面的分析,执行计划体现查询的执行代价,不同执行计划代价不同,执行计划本身的信息应作为网络输入特征来源之一。查询交互反映查询组合中查询间的相互作用,表征查询执行代价的改变程度,影响执行计划的选择,查询交互也应作为模型输入特征来源之一。因此,LSTM-FCN的输入特征应包括两部分:FoP、FQI。通过向量拼接的方法,得到模型的输入特征QMF,QMF={FoP,FQI}。其中,FoP从查询的执行计划中获取,FQI从查询响应时间的变化程度中获取。下面,使用独热编码(one-hot encoding)对输入数据进行预处理,把输入数据变成长度相同的特征,便于神经网络处理。
2.3.1 FoP的提取与编码
一个查询的执行计划有多个,查询复杂时,执行计划数量增多,考虑全部的执行计划相对困难。因此,本文从查询优化器得到的候选执行计划中选择若干个响应时间不同的计划作为实验执行计划。这些执行计划反映了查询的执行代价。
假如有查询:select r_name,n_name from nation,region where n_regionkey=r_regionkey;对应的查询执行计划树如图1所示。

图1 查询执行计划树Fig.1 Query execution plan tree
后续遍历该执行计划树,得到一个操作序列{nation,Hash,region,nation⊳⊲region},其中,符号⊳⊲表示关系之间的连接操作,将操作序列中的每一个操作编码成二进制序列。对查询组合中所有查询的执行计划按照相同的方式进行编码,生成查询组合执行计划特征FoP。
由于操作类型是每个操作的属性,操作的表是每个操作的作用对象,操作的列是每个操作作用对象的一个准确定位,操作结果行的宽度反映了每个操作的规模,即该操作的复杂度或代价。同时考虑以上四个方面对查询的每个操作进行编码,得到的编码序列可以充分体现查询的执行代价。将操作列表按照{操作种类,操作的表,操作涉及的表的列,结果行宽度}的格式编码,可以把执行计划转换成二进制串。以执行计划qj_c为例,具体编码方式如下:
后续遍历执行计划qj_c的计划树,得到对应于qj_c的操作序列si_c={pj|j=1,2,…,n},n表示此执行计划树中操作个数。对序列中的每个操作提取关键特征进行编码,得到向量pj={ak|k=1,2,3,4}。向量pj具体编码方式如下:
(1)a1代表操作pj的类型,例如Merge Join、Neated Loop等操作。假设数据库有d种操作类型,a1则为d位的向量。pj对应位为1,其他位设为0。
(2)a2代表pj在数据库中操作的关系。假设数据库有e个关系,a2则为e位的向量。a2中pj操作的关系对应位为1,其他位设为0。
(3)a3代表关系的列。假设关系共有f列,则a3则为f位的向量。关系a2涉及到的列对应位为1,其他位设为0。
(4)a4代表pj操作结果行的平均宽度及每行所占的字节数。将结果行平均宽度划分成g个区间,所得宽度对应的区间位为1,其他位设为0。
向量pj中向量a1、a2、a3表征查询操作的特点,a4表征查询结果的复杂程度。对于查询组合M,查询的不同执行计划看作不同的查询,则qj到来之后,查询组合执行计划特征:
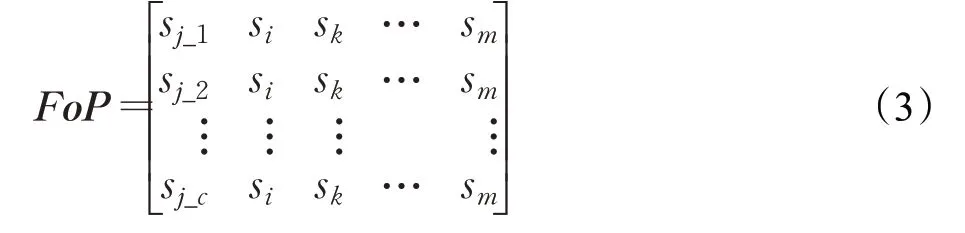
2.3.2 FQI的提取与编码
构建查询组合交互特征FQI首要一点是获取查询交互信息。查询qj加入到查询组合M中之后,其响应时间的变化程度可以表征其受到组合中各查询的查询交互。为了更准确地分析qj受到M的查询交互,本文计算M中每个查询对qj的查询交互值,将其作为qj受到的查询组合交互信息。根据2.2节中的分析,用qj单独运行及其与M并发时响应时间的改变,反映其代价的变化,进而构造查询qj受到M的查询组合交互特征FQI。具体方案如下:
分别计算M中各查询对qj响应时间的改变程度:Rj1,Rj2,…,Rji,…,Rjm。将它们编码,作为查询qj受到M的查询组合交互特征FQI。编码方案如下:统计实验数据中查询交互值范围,将查询交互值编码为定长h位向量r={(0,1],(1,2],(2,3],…,(h-1,h]},其中h=。为了方便实现查询交互值的特征化,本文对临界值“1”的编码做如下规定:1是查询间促进或抑制作用的分界线,故将向量r每位设为步长为1的左开右闭区间,当查询交互值小于或等于1时,视为两查询之间的相互作用为积极查询交互,反之,视为消极查询交互。查询组合交互特征如下:
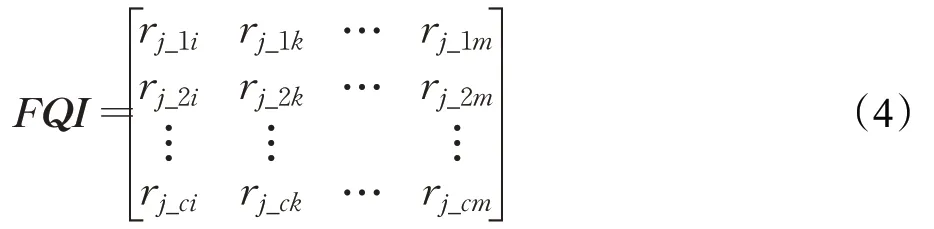
故模型的输入特征——查询组合特征为:
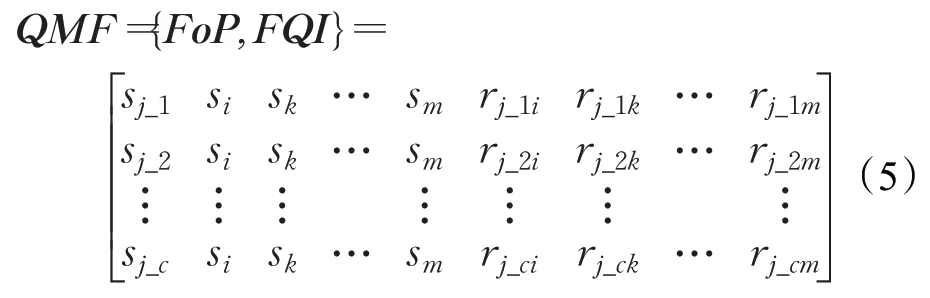
一般地,FoP列向量数等于MPL,FQI列向量数等于MPL-1。FoP、FQI行向量数等于待测查询的候选执行计划个数。
QMF的编码及生成过程也称为查询组合特征化,特征向量QMF反映了查询组合的执行代价和运行时执行代价的改变程度。本文从查询级别提取有效特征QMF,以此作为深度学习神经网络的输入,为查询动态选择适合其运行环境的执行计划。
2.4 LSTM-FCN模型的构造
本文LSTM-FCN构建的主要思想是从查询级的优化入手,首先通过查询组合的特征化设计表征查询的属性,并将其作为模型的输入特征,其次是选择合适的深度学习模型,选择执行计划。模型的改进上,采用网络组合的方式将LSTM和FCN结合在一起,用LSTM描述查询各操作间的相关性,具体表现为操作间的时序关系,在LSTM输出层后添加FCN层,实现特征的高度融合。输出层采用全连接层,实现分类。
使用LSTM与FCN的组合LSTM-FCN模型选择执行计划,其中将LSTM作为模型的一部分,原因有两方面:(1)LSTM的输入门、遗忘门、输出门描述了特征之间的时序关系,使得模型可以通过记住上一时刻的状态来动态地调整自身学习过程;(2)查询组合特征序列较长,LSTM学习长序列的能力较强,避免了传播过程中可能发生的特征丢失问题。将FCN作为模型的一部分原因是:FCN可以简单高效地对LSTM层输出的特征进行融合,同时将特征长度转换成合适的维度,便于模型的输出层计算损失。
LSTM层的自我调整保证了执行计划选择的动态性,FCN层保证了LSTM-FCN模型的高效性和稳定性。经过特征化后的查询组合作为模型的输入,使得LSTM-FCN在保证动态性及高效性的同时,描述查询的静态属性——查询的操作类型及规模,动态属性——查询组合内查询间的相互作用,从而实现并发查询执行计划的动态选择。第3章中设计相关实验验证了本文模型的性能。LSTM-FCN的网络结构如图2所示。

图2 LSTM-FCN的网络结构Fig.2 Network structure of LSTM-FCN model
其中输入特征向量是QMF,QMF作为LSTM层初始状态的输入向量。LSTM单元的物理结构与内部逻辑关系分别如图3、4所示。
图4展示一个LSTM单元内部的运算关系,它将当前时刻的输入、上一时刻的输出、状态三个向量进行运算,得到当前时刻的输出和状态。图4和图3相对应,图4中的x(t)就是样本向量QMF。图中两条线相交时,如果有运算关系,则用实心表示,否则用空心表示。其中实心点表示上一时刻的输出h(t)与当前时刻的输入通过向量拼接的方式构成一个新的向量。长方形框表示借助一层具有对应激活函数神经单元来实现。
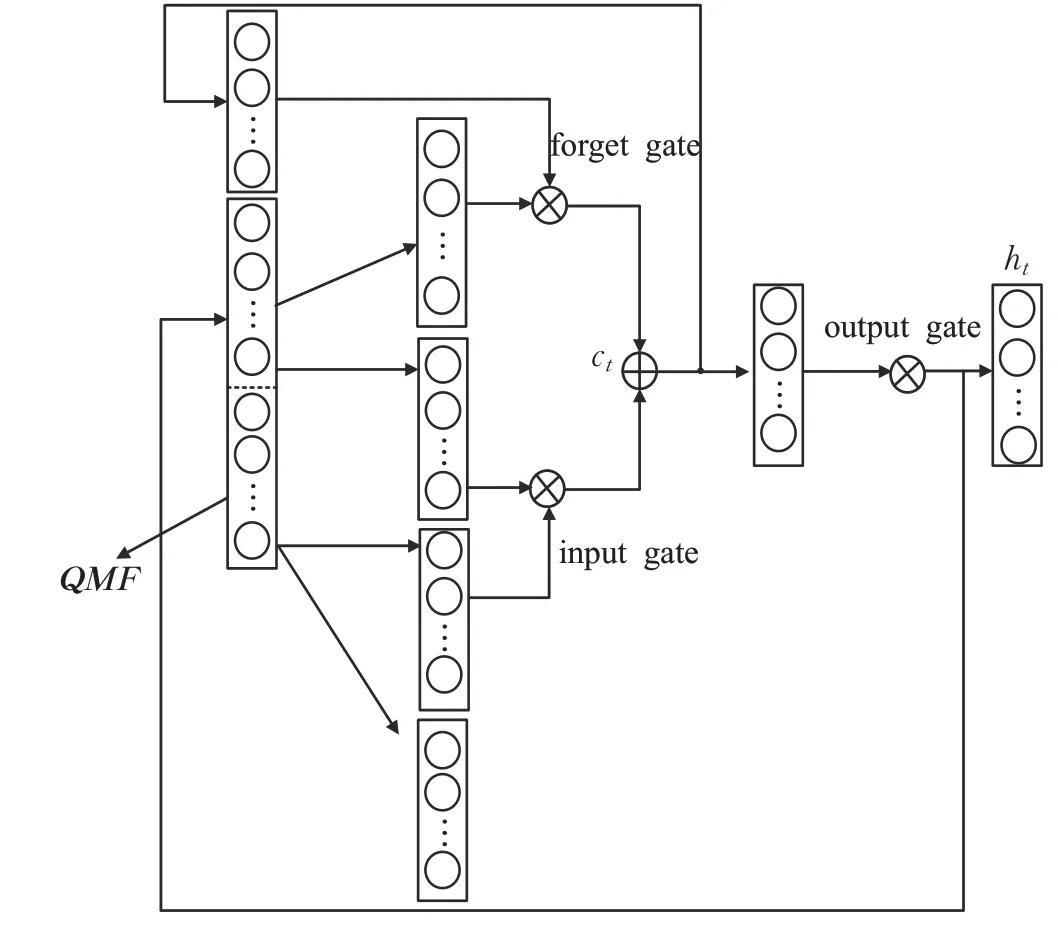
图3 LSTM单元的物理结构图Fig.3 Physical structure diagram of LSTM cell
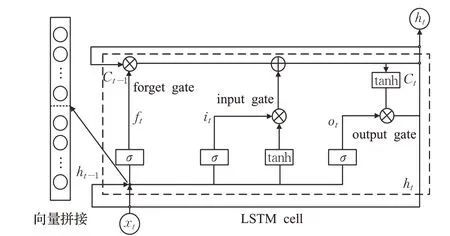
图4 LSTM单元内部逻辑关系Fig.4 Internal logic relationship of LSTM cell
一个LSTM单元有三个门:遗忘门ft、输入门it、输出门ot。其中,每个门对应64个隐含层神经元,每个隐含层都与输入向量全连接,通过LSTM单元内部计算后,最终得到当前时刻的输出,大小为64,作为下一时刻LSTM单元的一部分输入。各门值的计算方法见公式(6)~(10),Wf、Wi、Wo分别表示ft、it、ot对应隐含层神经元之间的权重,bf、bi、bo分别对应各隐含层神经元的偏移量。Ct表示t时刻LSTM单元的记忆,ht表示t时刻LSTM单元输出。
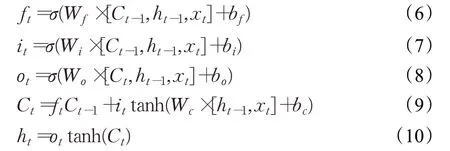
由公式(6)~(10)得到LSTM层隐藏层参数个数为:hiddenpar=hiddensize×(hiddensize+xt_dim+1)×4,其中hiddensize+xt_dim即为[ht-1,xt]。
FCN层参数个数为(ht+1)×FCNsize,输出层参数个数为(FCNsize+1)×outputsize。
LSTM-FCN基本参数如表1所列。LSTM输出层大小为64。LSTM层后增加一层全连接层进行特征融合,神经元个数为800。本文为每个待测查询指定3个执行计划,预测标签为3维向量。因此,输出层神经元个数为3。LSTM层激活函数选择Softmax,FCN层激活函数选择ReLu,输出层激活函数选择Sigmoid。为了防止过拟合,LSTM层后添加使Dropout,比率设为0.5。全连接层添加L2正则化,比率设为0.01。本文输入特征向量较稀疏,优化器选择Adam,初始学习率设为0.001。损失函数选择交叉熵categorical_crossentropy,迭代1 000次。

表1 网络参数信息Table 1 Information of network parameters
3 实验结果与分析
本实验采用TPC-H标准[21]中的10 GB数据进行性能测试,实验数据库是PostgreSQL。操作系统为Windows Server2008、CentOS Linux release 7.4.1708(Core),硬件环境为Intel®Xeon®Bronze 3104 CPU@1.70 GHz RAM:64 GB,Intel Xeon CPU E5-2609 v4@1.70 GHz Mem:16 GB。编程语言采用Java、Python。实验从多个角度验证采用LSTM-FCN实现并发查询执行计划选择的可行性。3.1节介绍数据集的获取。3.2~3.4节从以下三个方面对LSTM-FCN模型进行评估:数据集大小对LSTM-FCN准确率的影响、LSTM-FCN输入特征选择的合理性、LSTM-FCN在不同并行度下(MPL分别为3、4、5、6、7)的稳定性。最后在3.5、3.6与3.7节中进行对比实验,3.5节比较LSTM-FCN与FCN及LSTM的选择准确率,3.6节中比较LSTM-FCN与查询优化器及TRating方法为查询选择合适的执行计划的准确率,3.7节中比较三种方法的耗时成本。
3.1 数据集的获取
从TPC-H标准中抽取6个查询模板:3,4,7,10,12,14,为这6个查询模板指定相关参数,得到6个对应的查询。实验获取这些查询的执行计划。PostgreSQL的pg_hint_plan插件可以通过指定表的连接顺序、连接方式等方法,为查询制定执行计划。使用explain命令运行6个查询,记录查询优化器为其生成的执行计划。然后利用pg_hint_plan为每个查询生成多个执行计划。从这些执行计划中选择3个响应时间不同的执行计划,作为实验的执行计划。
本实验中用于生成数据集的查询包括两部分:待测试查询、自定义查询。从TPC-H标准中抽取6个查询模板作为待测试查询、相同标准下自定义73个查询。这些查询涵盖了查询所用的分组、排序、聚集、子查询、连接等基本操作。对于其中的6个查询模板,每个查询指定3个执行计划,共得到18个查询。将这18个不同的查询,与自定义的73个查询自由组合。MPL=m(m=3,4,5,6,7)时,得到的样本总数为:

实验中,多次运行样本,将各查询的平均响应时间作为其真实响应时间。由于运行全部样本需要巨大的时间成本,本实验从全部样本中随机抽取一些样本作为数据集来源。
数据库并发执行每个样本即自由组合得到的查询组合,将查询组合执行计划按照2.3.1节中的方式编码成.csv特征文件。PostgreSQL中共有34种操作类型,TPC-H标准中共有8张表,共61列。则向量a1共34位,a2共8位,a3共61位。统计发现,结果a4设为20位时,可以涵盖实验涉及到的查询结果行宽度。那么一个执行计划的一个操作对应的向量pj共有123位。经统计,本实验中的查询,最多有25个操作。一个执行计划经过编码后,转换为3 075位的特征向量。多次运行待测试查询,记录其响应时间。运行样本中待测查询与自定义查询的两两查询组合,记录响应时间。按照2.1节中,公式(1)的方法计算查询组合交互值。统计发现,本实验中的查询组合交互值均小于50,按照2.3.2节中的方式将其编码成.csv特征文件。
3.2 数据集大小对LSTM-FCN准确率的影响
本实验中,不同大小的数据集下,LSTM-FCN的选择准确率变化如表2所列。数据集大小分别为:1 254个样本、1 917个样本、2 736个样本、3 636个样本,其中训练集与测试集比例大约按照4∶1分配。
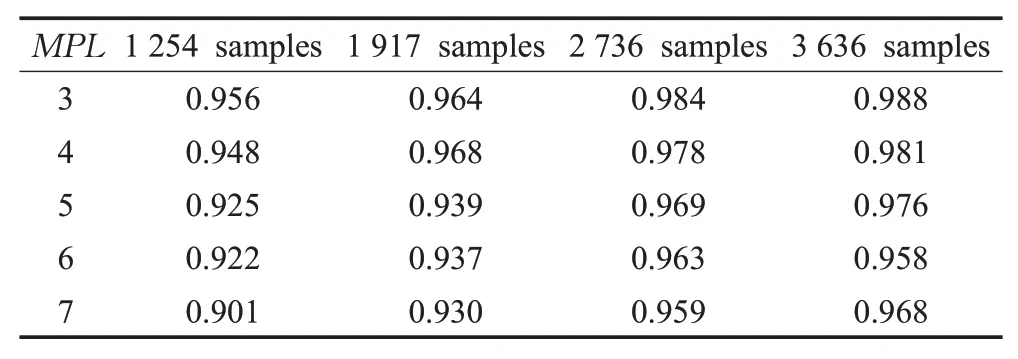
表2 不同数据集大小对LSTM-FCN准确率的影响Table 2 Influence of different data set sizes on accuracy of LSTM-FCN
分析表2得知,随着学习样本数增加,LSTM-FCN的选择准确率保持一定幅度的上升。2 736个样本作为数据集时,模型在同一并行度下的选择准确率及不同并行度下的平均选择准确率均高于前两种大小的数据集。与2 736个样本相比,3 636个样本作为数据集时,平均准确率提升了0.36个百分点,但是训练样本的时间成本增加。因此,为了取得准确率与训练成本的平衡,本实验数据集大小选择2 736个样本。
3.3 LSTM-FCN输入特征选择的合理性
本实验分别将FoP、FQI与QMF作为输入特征时,LSTM-FCN准确率变化情况如表3所列。
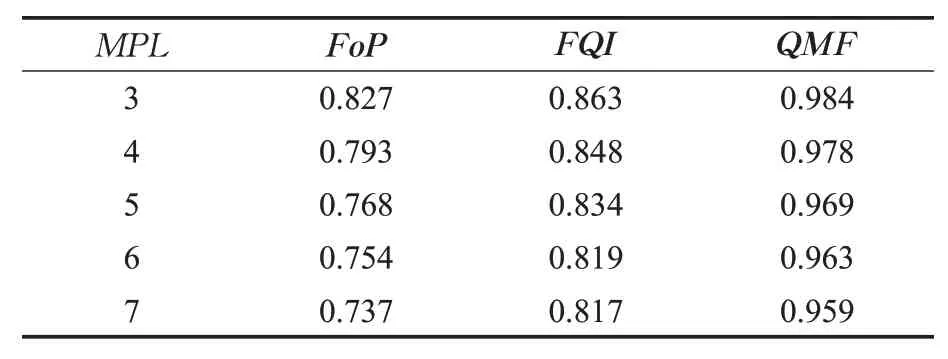
表3 不同输入特征下LSTM-FCN的准确率Table 3 Accuracy of LSTM-FCN under different input characteristics
分析表3知,五种并行度下,将QMF作为输入特征时,模型的预测准确率高于将FoP或FQI作为输入特征时的准确率,证明本文选择的输入特征是合理的。
随着并行度的增加,QMF与FoP分别作为输入特征,LSTM-FCN的准确率分别相差0.157、0.185、0.201、0.209、0.222,差距逐渐增大。这是因为并行度增加,查询交互对执行代价改变的程度增加,对执行计划选择的影响程度增加。QMF与FQI分别作为输入特征,模型的准确率的差距变化基本稳定,说明查询组合的执行计划特征对选择准确率的影响基本固定。FoP和FQI从静态和动态两个方面表征查询的性能,同时将FoP和FQI的组合——QMF作为输入特征,选择执行计划,具有合理性。
3.4 LSTM-FCN在不同查询并行度下的稳定性
实验中不同并行度下,LSTM-FCN的选择准确率变化情况如表4所列。
分析表4得知,随着并行度的增加,模型预测准确率出现小幅度的下降,分别下降了:0.006、0.009、0.006、0.004。因为并行度增加,模型中FCN的神经元个数相对固定,模型的表达能力相对固定。并行度增加,查询交互更加复杂,LSTM-FCN的选择准确率依然较高且保持相对稳定。
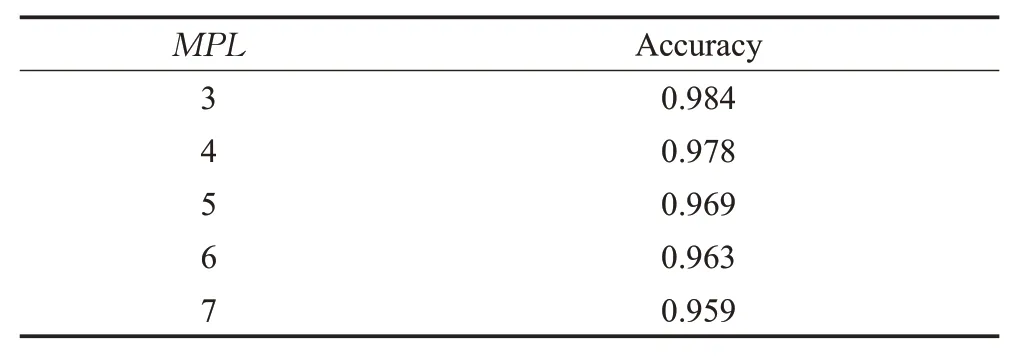
表4 不同并行度下LSTM-FCN的准确率Table 4 Accuracy of LSTM-FCN under different parallelism
3.5 LSTM-FCN与FCN及LSTM准确率比较
相同网络层数下,MPL=3、4、5、6、7时,FCN、LSTM与LSTM-FCN的准确率对比结果如表5所列。
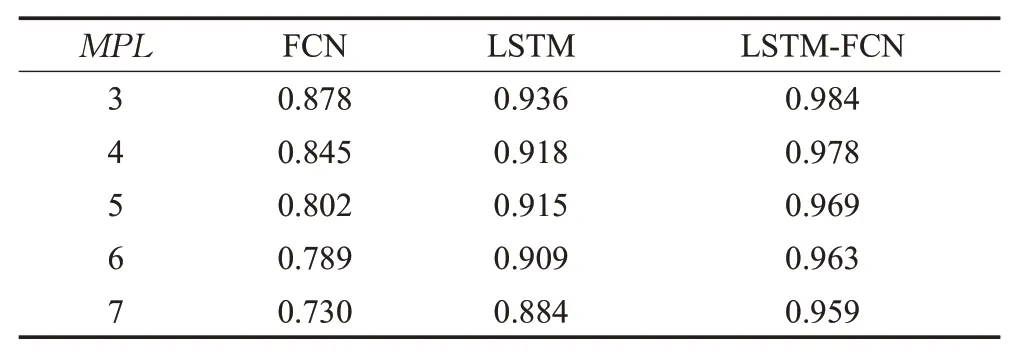
表5 不同并行度下LSTM、FCN与LSTM-FCN的准确率Table 5 Accuracy of FCN,LSTM and LSTM-FCN under different parallelism
分析实验结果可知,网络层数、各层大小相同时,不同并行度下,LSTM-FCN选择准确率高于FCN与LSTM的选择准确率。其高于FCN的主要原因是:每个执行计划的操作之间有时序关系,而FCN无法拟合这种时序关系。作为模型输入层,LSTM层描述查询各操作间的执行次序,动态选择合适的执行计划。LSTM-FCN的平均选择准确率为97.06%,比FCN的平均选择准确率高16.18个百分点。随着并行度增加,LSTM-FCN在动态拟合查询各操作间时序关系的优势更加显著。LSTMFCN选择准确率高于LSTM的主要原因是:在LSTM层后添加一层FCN,可以充分融合特征,从而更好地描述查询组合特征,提升模型的预测准确率。
3.6 LSTM-FCN与查询优化器及TRating准确率比较
相同的实验场景下,分别在MPL=3、4、5、6、7时,对比LSTM-FCN与查询优化器及TRating方法在为并发查询选择执行计划时的准确率,结果如图5所示。
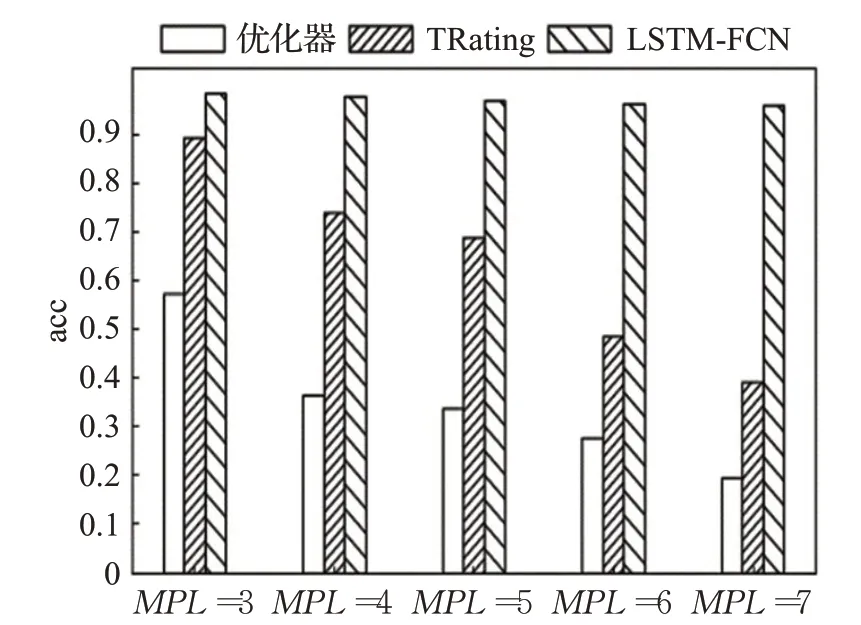
图5 LSTM-FCN、查询优化器及TRating准确率比较Fig.5 Comparison of LSTM-FCN,query optimizer and TRating accuracy
同一并行度下,LSTM-FCN的选择准确率高于优化器及TRating方法。LSTM-FCN平均选择准确率相比查询优化器与TRating分别提升了62.12个百分点、33.14个百分点。查询优化器通过配置参数的方法考虑查询交互,准确率较低。TRating只考虑查询交互对执行计划选择的影响,准确率高于查询优化器。但是,随着并行度增加,查询交互变得复杂,TRating线性模型难以准确拟合复杂的查询交互带来的查询执行代价的改变,准确率出现较大幅度下降。LSTM-FCN同时考虑体现查询执行代价的查询组合执行计划特征、体现查询交互的查询组合交互特征,为并发查询动态选择适合当前执行环境的执行计划,准确率高于前两种方法且保持相对稳定。
3.7 LSTM-FCN与查询优化器及TRating耗时比较
从模型平均耗时角度对比LSTM-FCN与查询优化器及TRating性能的实验结果如图6所示。
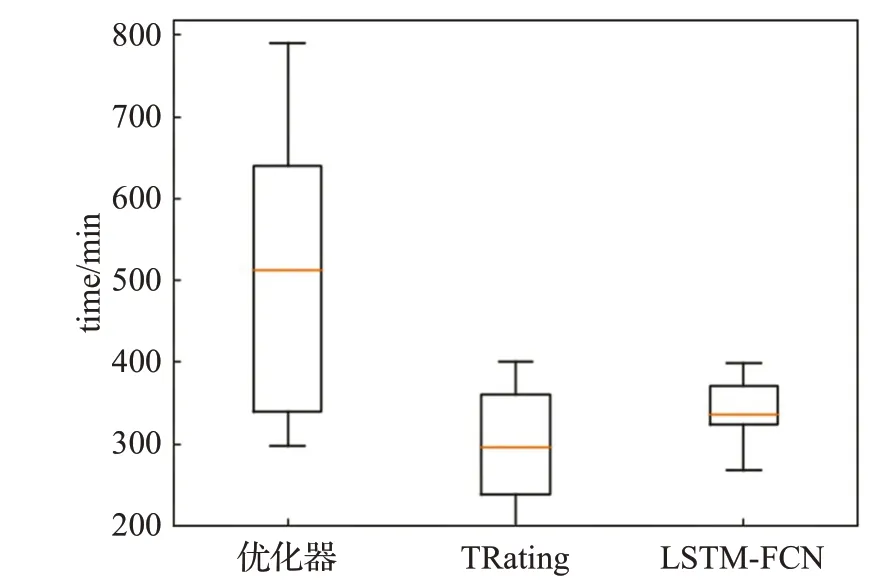
图6 LSTM-FCN、查询优化器及TRating耗时比较Fig.6 Comparison of time cost among LSTM-FCN,query optimizer and TRating
分析图6可知,LSTM-FCN所耗费的时间成本中位数低于查询优化器,略高于TRating。这是因为,查询优化器在选择执行计划时需要估算查询每个操作的代价,并行度增加,优化器计算代价大幅度增加。TRating线性模型构建之后,随着并行度增加,模型复杂度基本不变。与TRating相比,LSTM-FCN时间成本略高的原因是,并行度增加时,模型涉及到的参数数目增加。在OLAP场景下,与实时性相比,系统更加强调查询执行计划的选择准确率,LSTM-FCN以较小的时间成本换取执行计划选择的高准确率和稳定性。此外,LSTM-FCN所耗费时间的上、下限值差距小于其余两种方法,这也从侧面反映了LSTM-FCN模型在不同并行度下的稳定性。
4 结束语
查询是数据库系统的主要负载,查询执行的效率决定数据库系统的性能。LSTM-FCN拟合查询执行过程中各操作之间的时序关系,融合时域特征,实现分类。同时将分别表征查询执行代价及查询间相互作用的查询组合执行计划特征与查询组合交互特征作为输入,为并发执行的查询动态选择合适的执行计划。实验验证了本文方法的合理性,查询并行度增加,LSTM-FCN准确率较高且保持相对稳定。但是,LSTM-FCN也存在一定的局限性,由于运行所有样本需要的时间成本较大,在以后的工作中,将考虑使用深度信念网络生成更多的训练数据。同时,在输入特征完善方面,将数据库系统运行过程中的相关参数作为输入特征的一部分,期望取得更好的实验效果。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中国交通信息化(2018年5期)2018-08-21
海峡姐妹(2017年12期)2018-01-31
语文世界(初中版)(2017年5期)2017-06-22
作文与考试·初中版(2017年12期)2017-04-19
高中生学习·高三版(2016年9期)2016-05-14
