
SM2专用指令协处理器设计与实现
2022-01-25 18:54王腾飞张海峰
计算机工程与应用 2022年2期
王腾飞,张海峰,许 森
1.上海交通大学 电子信息与电气工程学院,上海 200240
2.北京智芯微电子科技有限公司,北京 100192
3.观源(上海)科技有限公司,上海 200241
随着信息技术的发展和对信息安全需求的增长,公钥密码的使用变得更加广泛。在公钥密码体制中,与RSA算法相比,椭圆曲线密码(ECC)[1]算法能够使用较短的密钥而达到较高的安全性,因而得到了越来越多的关注。2012年,中国国家密码管理局公布了基于ECC的公钥商用密码标准,简称SM2[2],并且在2017年被国际上确立为ISO标准,正在得到越来越广泛的应用。但由于其中涉及到的数学运算较为复杂,在具体应用中还存在计算效率不高的问题,因此,对SM2软硬件快速实现技术的研究成为一项重要课题。
SM2标准属于椭圆曲线密码体系,它与基于ECC的其他国际标准,如ECDSA之间在数学基础、算法结构和实现方式等方面具有相同点,椭圆曲线标量乘算法是实现这一类标准的关键部分。针对ECC的实现通常有两种途径:一是软件实现,即在通用处理器(general purpose processor,GPP)上通过软件编程方式实现相应算法;二是硬件实现,硬件平台主要包括专用集成电路(application specific integrated circuit,ASIC)和现场可编程门阵列(field programmable gate array,FPGA)两种。前者的优点在于灵活性高,可以很方便地进行各种参数的配置,缺点是GPP缺少对大数运算的支持,计算效率低;后者的优点在于计算速度快,缺点是灵活性差,尤其是基于ASIC的实现,指定参数后就不能随意修改,而FPGA因为具有可编程特性,在灵活性上比ASIC要强一些。
由于FPGA在计算效率和灵活性上的优势,目前国内外有许多对ECC(包括SM2)实现的研究选择FPGA作为实验平台。Loi等人[3]提出的椭圆曲线密码处理器能够支持美国国家标准技术研究所(NIST)推荐的五种素域椭圆曲线,利用Xilinx Virtex-5 FPGA上的DSP48E达到了较高的性能。Zhang等人[4]针对SM2推荐的椭圆曲线在Altera StratixII FPGA上实现了高性能的标量乘。但是上述文献所采用的实现方法都是利用状态机来控制算法流程,这样会导致控制逻辑占用大量硬件资源,同时也不利于应用流水线技术进行加速。除此之外,还有一类实现方法是设计专用指令集处理器(application specific instruction-set processor,ASIP)[5],即可以针对ECC算法的计算特点设计专用的指令,使处理器能够以执行指令的形式高效灵活地实现算法。张军[6]提出面向二元域和素数域上ECC运算的专用指令集,设计了一种可以实现多种ECC算法的专用指令向量协处理器。夏辉等人[7]提出了一套通用的专用指令处理器的设计验证方案,并将该方案应用于ECC,从而大幅提升其在硬件资源受限的嵌入式环境中的执行效率。但目前还没有专门针对SM2标准的专用指令协处理器的研究。
本文借鉴利用ASIP高效实现ECC算法的设计思想,在详细了解SM2算法特点的基础上,提出一种适用于实现SM2算法的专用指令协处理器。所提出的SM2专用指令协处理器能够结合软硬件实现各自具有的优势,以FPGA为平台,高效利用其计算资源,同时考虑抵御侧信道攻击的安全性,实现了从底层硬件单元到上层指令序列的整体优化,具有面积小、速度快、灵活性高的特点。
1 背景概述
SM2底层的基本运算是定义在有限域上的,具体分为素域和二元扩域两种,本文主要讨论基于素域的实现。
1.1 素域运算
阶为素数的有限域称为素域,素域上的运算可以通过在整数的基本运算后再加一步对素数阶P的约减运算完成,以使结果同样落在素域下面。简单来说,素域运算包括模加、模减、模乘和模逆运算,而模逆可以由一系列的加法和移位运算实现。
SM2算法在实现的过程中,会不断调用底层的素域运算,其中模加减运算比较简单,不会占用太多时间,而模乘运算调用次数多,计算时间长,是提高整体性能的关键运算。为了提高计算效率,本文采用Montgomery模乘方法[8]来实现素域上的模乘运算。Montgomery模乘方法避免了使用耗时的除法运算来进行约减,取而代之的是简单的移位运算,其计算形式如公式(1)所示:

其中,R=2k,k为P的位数,其核心思想是将对P的取模运算转化为对R的取模和除法运算,这样在执行的过程中就只需要简单的截取和移位操作,非常适合硬件实现。在SM2的计算过程中,可以首先将原始数据与R2做Montgomery模乘运算,使其转换为“Montgomery形式”,然后在这种形式下就可以用Montgomery模乘代替普通模乘,模加减仍为普通模加减,得到的中间结果保持“Montgomery形式”不变,直到最后一步通过将结果与1做Montgomery模乘运算,使其转换至普通形式。这样只需增加开始和结束时的两步转换过程,而节省了中间大量模乘运算的耗时,能够起到良好的加速效果。
相比于模乘运算,素域上的模逆运算更为复杂,对素域上的元素X求模逆,即找到素域上的元素Z,使得Z与X的乘积模P的结果为1,如公式(2)所示:

二进制扩展欧几里德算法[9]可以将模逆运算转换为一系列的加减和移位运算,因此在设计模逆的硬件计算单元时,可以通过控制逻辑调用模加减和移位单元执行运算,从而节省硬件资源。另外,将椭圆曲线上的点由仿射坐标转换为Jacobian坐标可以减少模逆运算的调用次数,从而提高计算速度。
1.2 椭圆曲线密码算法
椭圆曲线密码算法的安全性是基于椭圆曲线上离散对数问题[10],该类型算法是目前公认的单比特安全度最高的公钥密码算法。ECC具备密钥长度短、计算资源需求少等优势,尤其适用于资源受限设备上的应用,如智能卡等。
椭圆曲线E是一个具有两变量的三次方程,该方程一般定义在某个数域K上,在本文中K为素域,方程的定义如公式(3)所示:
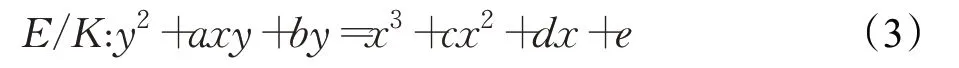
其中a,b,c,d,e∈K,且其判别式Δ≠0,判别式的定义为:

则,椭圆曲线E上所有点的集合为:

这里O为无穷远点。
SM2标准给出的定义在素域上的椭圆曲线方程具有如下形式:

设椭圆曲线E上不同的两点P=(x1,y1)和Q=(x2,y2),两点相加称为点加运算,点P和Q的点加运算结果为P+Q=(x3,y3),其计算公式为:

相同的两点相加称为倍点运算,点P的倍点运算结果为2P=(x4,y4),其计算公式为:

同一个点的多次重复相加称为该点的多倍点运算,如P的d倍点:

椭圆密码算法的安全性来源于椭圆曲线上离散对数的计算复杂性,即Q=[d]P。其中,P和Q为椭圆曲线上的点,而d为标量,由P和d计算得到Q是易于实现的,而由P和Q得到d,在计算上不可行。与RSA算法的模幂运算类似,[d]P是椭圆曲线密码算法的核心,也称之为标量乘运算。为了抵御简单功耗分析(SPA)攻击,本文采用Montgomery Powering Ladder(MPL)算法[11],如算法1所示。
算法1MPL标量乘算法
输入:整数d和点P,d的比特长度l
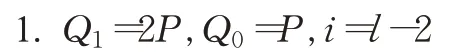

1.3 SM2算法
SM2算法呈现层次性特点,自上而下可以分为四层,如图1所示。在协议层包括数字签名算法、密钥交换协议和公钥加密算法三部分,向下调用椭圆曲线点乘运算和素域GF(n)上的模运算。点乘运算层实现公式(9)所示的椭圆曲线标量乘运算,由算法1可知该运算的实现过程包括一系列的点加和倍点运算,在群运算层完成。而点加和倍点的计算过程如公式(7)和(8)所示,通常为了减少计算量,会将其转换至Jacobian坐标下进行,但都需要调用素域GF(p)上的模运算。有限域层实现大数的模加、模减、模乘和模逆运算,本文只考虑有限域为素域的情况,包括协议层直接调用的素域GF(n)和群运算层调用的素域GF(p),运算规则如1.1节所述。除此之外,协议层还需调用一些辅助函数,如密码杂凑函数、密钥派生函数和随机数发生器,这类函数可以通过软硬件方式单独完成,与本文所设计的协处理器结合即可实现完整的协议。

图1 SM2算法的层次结构Fig.1 Layer of SM2 algorithm
与其他基于ECC的国际密码体制相比,SM2采用了独特的素数域,256位椭圆曲线,GM/T 0003规定了SM2算法的曲线参数[2]。依据标准所选取的参数,图1中的有限域层所需处理的操作数据均为256位无符号整数,因此在本文所设计的SM2协处理器中,使用256位无符号整数计算单元执行有限域层的基本运算,专用指令与存储单元也同样与此相适应。
2 协处理器设计
2.1 整体架构
针对SM2算法的特点,借鉴通用处理器执行计算任务的方式,本文提出的硬件协处理器整体架构如图2所示。
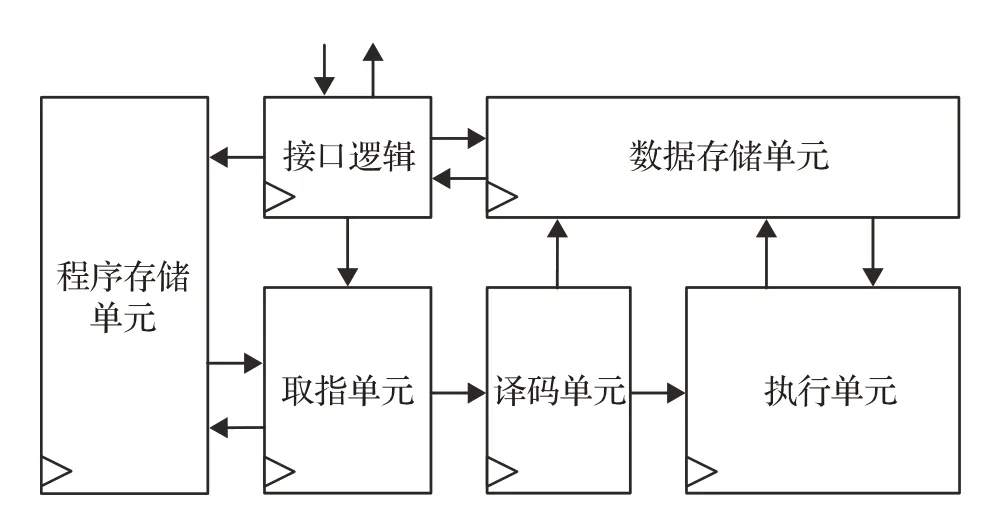
图2 SM2硬件协处理器整体架构Fig.2 Architecture of SM2 hardware co-processor
整体架构包含五个部分:接口逻辑、取指单元、译码单元、执行单元、程序存储单元和数据存储单元,其中的指令是根据SM2算法的特点而专门设计的,具有控制256位整数的模加减、模乘、模逆和移位运算、数据读写、指令跳转等功能。接口逻辑从外部接收数据和控制信号,根据控制信号决定协处理器的工作状态:存取数据、执行算法或者空闲;执行算法时取指单元会根据程序计数器所记录的当前指令地址从程序存储单元中取出指令,并更新程序计数器;取出的指令传到译码单元,译码单元按照一定规则对指令进行译码,确定当前指令所要完成的功能;执行单元负责实现具体的计算任务,包括256位整数的模加减、模乘、模逆和移位运算;程序存储单元负责存储实现SM2算法的指令序列,加密、解密、签名、验签分别对应不同的地址范围;数据存储单元负责存储曲线参数以及中间数据,能够根据需要快速地进行读写。
作为一个能够独立执行SM2算法的硬件模块,所设计的协处理器具有类似主处理器的简单工作过程,所有专用指令和中间数据的处理都在模块内部进行,并具有四级流水线结构。在执行SM2算法之前,协处理器需要首先通过对外接口从主处理器获取的输入数据,如待签名消息的哈希值、公私钥对等,将输入数据存入数据存储单元的特定位置,然后才能执行相应算法,算法执行结束后同样会将结果保存至数据存储单元的特定位置,主处理器可以通过接口进行读取,这一过程均在接口逻辑的控制下完成。
2.2 专用指令集
根据SM2算法的实际计算需求,本文设计了协处理器可执行的专用指令集,包含17条专用指令,每条指令具有30位固定长度,指令格式为:6位操作码opr+8位源操作数1地址rs+8位源操作数2地址rt+8位目的操作数地址rd,操作码决定了指令的功能,均为SM2算法在实现过程中涉及到的基本操作,包括素域GF(p)和GF(n)上的模加、模减、模乘和模逆运算,移位运算,指令跳转等,具体如表1所示。

表1 专用指令操作码功能Table 1 Functions of specific instructions’opcode
在表1中,[rs]、[rt]表示按照地址rs、rt从数据存储单元中取出的数据,[rd]表示按照地址rd待写入数据存储单元的数据,pc为程序计数器,用于存放当前欲执行指令在指令存储单元中的地址。指令1为空指令,不执行任何操作,用于算法执行结束;指令2~9控制素域上的运算,调用同一个计算模块执行256位模加、模减、模乘和模逆操作,然后依据具体指令选择模数是p还是n,需要注意的是,由于执行单元采用Montgomery模乘的实现方法,所以指令中的模乘同样是指Montgomery模乘;指令10可以读取[rs],用于算法执行结束后对外输出结果;指令11可以将当前指令地址加2后存入[rd],用于保存调用标量乘函数之后的返回地址;指令12是将[rs]左移一位后存入[rd],用于标量乘算法每次循环后对标量的处理;指令13~17为跳转指令,可以改变指令序列的执行顺序,用于算法中的循环控制,条件转移和函数调用,包括直接跳转、根据[rs]是否为0进行跳转、根据[rs]最高位是否为1进行跳转以及根据[rs]和[rt]的大小关系进行跳转。以上指令可以覆盖SM2中除辅助函数之外的所有基本操作,通过编写指令序列的方式即可实现相应的算法流程。
在定义了指令的格式和功能的基础上,SM2加密、解密、签名、验签算法中除辅助函数之外的计算过程可以通过手工编写指令序列完成。指令序列存储在程序存储单元中,程序存储单元在FPGA上以寄存器数组的形式实现,地址位宽是7位,数据位宽是30位,通过给寄存器赋初值的方式将指令序列写入。为了节省寄存器资源,程序存储单元可以根据算法类型被动态赋值,比如同一段地址对应的寄存器就可以依据输入的算法选择信号而被赋予加密或签名的指令序列。由于协议层会多次调用标量乘算法,所以依据算法1编写的标量乘算法指令序列会被写入特定的地址范围0x01~0x43,协议层在调用这段指令序列时只需将输入的标量值d和点P写入特定位置,并保存返回地址,然后指令跳转至0x01位置即可。协议层加密、解密、签名、验签算法的起始地址均为0x44,因为算法长度不同,所以有不同的结束地址,通过将pc的值初始化为起始地址并在wen信号的控制下使算法开始执行,当pc指向所选择算法的结束地址时终止执行。指令序列可以根据具体需求重新编写,可以实现更快速或更安全的优化算法。
程序存储单元中的指令序列通过取值单元逐条取出。取指单元包含一个程序计数器pc和一个指令寄存器inst,可以按照顺序或者转移的方式从程序存储单元中取出待执行的指令。程序计数器pc存放当前指令在程序存储单元中的地址,其初始值是SM2算法指令的起始地址0x44。当接收到接口逻辑发送的执行算法的命令时,取指单元将pc的值发送至程序存储单元的地址端口,经过一个时钟周期后取出指令,并将其存放在inst中发送至译码单元。之后需要对pc的值进行更新,以便去取下一条指令,对pc的更新要考虑当前指令是否为转移指令,如果是转移指令,则将pc赋值为指令中要转移的目的地址(条件转移指令还需要判断是否满足转移条件),否则令pc=pc+1。当pc增加至算法指令的结束地址时,停止取指操作并不再更新pc,同时给出执行结束的信号。
译码单元从取指单元获得inst指令并对其执行译码操作,工作时首先将30位指令分解成6位操作码opr+8位源操作数1地址rs+8位源操作数2地址rt+8位目的操作数地址rd的形式,然后对操作码opr进行判断,如果是表1所述的17种情况之一,则按照对应关系将操作码转换为具体的行为,完成对相关寄存器的赋值过程,向执行单元发送使能信号和运算类型的选择信号,向数据存储单元发送地址信息。由于不同类型的指令需要耗费不同的时钟周期数,所以译码单元同时还会根据操作码类型设定延时周期。
2.3 执行单元
执行单元是整个协处理器的核心运算模块,完成SM2算法中的底层计算任务,即素域上的大数模运算和移位运算,其硬件架构如图3所示。
在图3中,执行单元以256位无符号整数a、b为输入,执行以p和n为模数的模加减、模乘和模逆的运算,以及对a的移位运算。模逆单元实现的是二进制扩展Euclidean算法,其中需要用到模加减和移位操作,为了节省硬件资源,直接将执行上层指令的模加减和移位单元加入模逆单元中,通过控制命令来选择执行的运算类型,如果是模逆运算,则在模逆控制器的控制下完成计算任务,大约耗时1 300个时钟周期;如果是模加减或移位运算,则直接将数据输入模加/减或移位单元,只需1个时钟周期即可完成计算。

图3 执行单元硬件架构Fig.3 Hardware architecture of execute unit
相比于普通模乘,Montgomery模乘因避免了取模过程当中的除法操作而更加高效,因此执行单元采用了实现Montgomery模乘算法的模乘单元。在可并行的高阶Montgomery模乘算法[12](算法2)实现方案的基础上,本文增加了对模数p和n的选择,以及针对“Montgomery友好”[13]的模数p作了优化,进一步提高了计算速度。另外,硬件实现过程中的最后一步约减操作具有固定时长的特点,避免了算法最后一步的条件约减可能存在侧信道信息泄露的风险。
模乘单元包含模乘控制器、乘加模块、寄存器堆和减法器四个主要部分,其硬件架构如图4所示。其中模乘控制器通过状态转换的方式控制算法的执行顺序,在接收到外部传来的start信号之后,其状态由空闲转为开始运行,之后每个时钟周期状态转换一次,同时向乘加模块和寄存器堆发送当前状态下的执行命令;乘加模块包含两个并行执行(c,z)=a+xy+b的乘加器,不同状态下会有不同的数据给到输入端口a、x、y、b,当状态对应于算法2中的第5步和第6步,第8步和第9步,以及第12步与下次循环中的第3步时,两个乘加器同时工作,经过一个时钟周期得到计算结果;寄存器堆存放计算过程中产生的中间结果,并根据当前状态将相应的值传入乘加模块,当算法2中的外层循环部分执行结束后,将所得结果传给减法器;减法器执行最后一步减法运算,根据减法是否产生借位决定最终的输出结果。模乘单元可以根据输入的sel信号选择模数为p还是n,对应的w会通过预计算得到,写入乘加模块中。因为p是“Montgomery友好”模数,通过p计算得到的w值为1,所以当模数为p时可以省略算法2中的第4步运算,得到更快的计算速度。
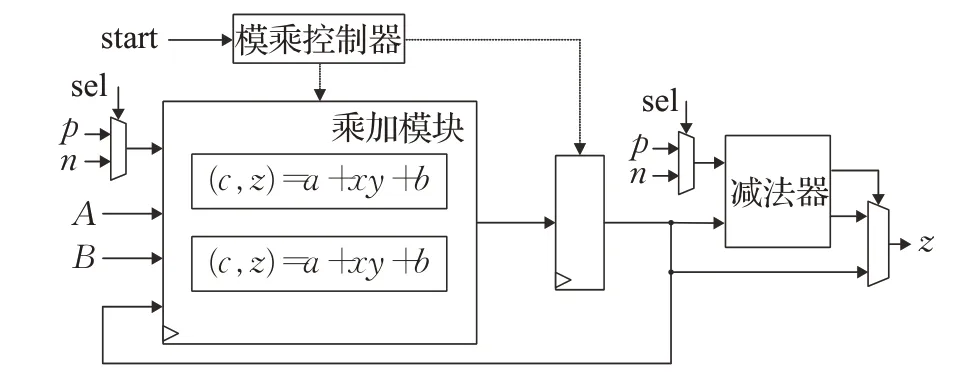
图4 模乘单元硬件架构Fig.4 Hardware architecture of modular multiplication unit
算法2可并行的高阶Montgomery模乘算法
输入:A,B,P,w,wherew=-P-1modr,r=2n
输出:Z=A×B×R-1modP,whereR=rm

模乘单元计算一次Montgomery模乘所耗费的周期数与算法2中m的取值有关,m取值越大周期数越少,但同时会导致乘加模块的计算延时增加,降低时钟频率,所以需要平衡时钟频率和周期数之间的关系。通过实验发现,对256位Montgomery模乘,当m=4时可以在计算速度上达到最优,此时n=64,即乘加模块的输入输出数据为64位。如果算法2中的每一步运算耗时一个时钟周期,那么对模数n的Montgomery模乘需耗时26个时钟周期,而对模数p的Montgomery模乘需耗时22个时钟周期。为了尽可能降低关键路径上乘加模块的计算延时,以提高整体时钟频率,本文对其中包含的乘加器作了优化设计,如图5所示。
乘加器包含16个16×16的乘法计算单元和8个不同位数的加法计算单元,计算(c,z)=a+xy+b的过程分为四级:第一级是将输入的64位乘数x、y以16位为单位从高到低分解成{x3,x2,x1,x0}和{y3,y2,y1,y0},然后按照图5所示的传输路径同时给到16个乘法计算单元实现两两互乘,得到16个32位部分积,与此同时,右上方的64位加法计算单元完成了a+b的计算;第二级是将16个部分积在移位、合并之后进行两两相加,移位操作按照部分积乘数的位置,如x0y1需左移16位,移位之后相差32位的数据可以直接合并,如左移16位的x0y1和左移48位的x0y3,再使用四个加法计算单元将合并之后的数据相加,包括a+b的和;第三级是将第二级得到的四个结果再进行两两相加;第四级执行最后一步加法运算,输出128位计算结果{c,z}。整个计算过程在一个时钟周期内完成,最长延时路径包括1个乘法计算单元和3个加法计算单元,在FPGA上此路径延时小于10 ns,有效地提高了乘法器的最高工作频率。

图5 乘加器硬件架构Fig.5 Hardware architecture of multiply-add unit
2.4 流水线结构
类似于通用处理器的指令处理方式,SM2专用指令协处理器同样采用了流水线技术,将指令的处理过程分为取指、译码、执行、写回四级流水,译码阶段同时包含了取操作数,流水线结构如图6所示。
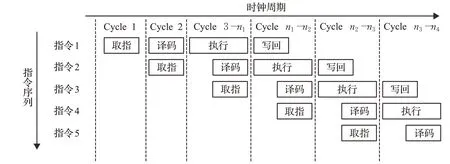
图6 指令流水线结构Fig.6 Pipeline architecture of instructions
为了使SM2协处理器的各功能单元能够按照图6所示的流水方式运行,需要合理安排时序。在指令流水中,取指、译码和写回都只需要一个时钟周期,而执行阶段所需耗费的时钟周期数取决于指令类型,所以在译码阶段需要给出指令的延时周期数。另外还需设置一个延时计数器来记录运行周期,在每条指令的执行阶段开始时刻将其置零,然后每个时钟周期加1。由计数器的值与当前指令的延时周期数的关系可以确定后续指令的译码、取指时刻以及当前指令的写回和下条指令的执行时刻。需要注意的是,由于相邻指令之间往往具有数据相关性,而下条指令的执行与当前指令的写回是发生在同一时刻的,这就要求数据存储单元能够及时为下条指令提供更新后的操作数,实现方法是当读写地址相同且写使能的情况下,数据存储单元直接提供即将写入的数据作为输出,并在下个周期将数据写入。由此,SM2协处理器实现了具有流水线结构的指令处理过程。
3 实验结果分析
本文采用硬件描述语言Verilog实现了所设计的SM2专用指令协处理器,在Xilinx ZYNQ-7 ZC706评估板上运行,验证了功能的正确性。在性能方面,协处理器的最高时钟频率为110 MHz,可以在2 480 210个时钟周期内完成一次SM2中的标量乘运算,时间约为2.25 ms,在此基础上执行不包含辅助函数的加密、解密、签名、验签算法所需耗费的时间分别为4.53 ms、2.27 ms、2.28 ms、4.51 ms。在资源使用方面,协处理器共占用7 146个Slice,其中LUT的使用量为14 658个,Register的使用量为17 420个,另外执行单元还占用了32个DSP资源。安全性方面,协处理器执行常时的MPL算法(算法1)实现标量乘运算,内部的执行单元能够在固定时钟周期数内完成底层运算,因而可以抵御简单功耗攻击。作为对比,如果使用最简单的二进制展开算法实现标量乘,则所需耗费的时间会减少为1.79 ms,资源使用量基本相同,但其功耗曲线会泄露标量值信息,不具备抵御侧信道攻击的安全性。与同样基于FPGA实现256位素域上椭圆曲线标量乘的硬件协处理器对比情况如表2所示。
从表2中与相关工作的对比可以发现,本文实现的SM2硬件协处理器在速度和面积上均达到了不错的效果。相比于较早的工作,如文献[14]和文献[15],本文的设计在速度和面积上均有优势,尽管使用了更先进的FPGA平台,但这种优势依然可以从设计方法中体现出来,其采用的乘完之后再约减的方法使模乘单元的数据通路中包含512位的数据,这样的数据位宽限制了其频率的提高,另外有限状态机(FSM)的使用也增加了控制逻辑所占用的资源。文献[3]提出的设计可以占用较少的资源,达到较高的频率,但在计算耗时上较本文稍差,说明本文提出的设计可以在较低功耗的条件下实现比其更快的计算速度。文献[4]实现了高性能低功耗的标量乘计算,其加速方法主要来自于针对SM2素数域GF(p)的快速约减,但没有考虑SM2协议层上除标量乘之外的其他运算,而本文的协处理器同时考虑了GF(p)和GF(n)上的模运算,更适用于协议层的实现。需要说明的是,本文提出的协处理器所占用的资源中,有很大一部分是用于标量乘之外的其他运算,如签名算法的指令和数据的存储需要使用额外的Slice,如果与其他文献一样只考虑标量乘运算所需的资源,则Slice的使用量将会减少20%左右。

表2 相关工作对比Table 2 Comparison between related works
4 总结
本文提出一种具有SM2专用指令的硬件协处理器,可以通过类似通用处理器的工作方式执行专用指令序列,从而实现了SM2签名、验签、加密、解密中除辅助函数之外的所有运算。其中,适用于SM2算法的专用指令集、高效的执行单元和四级流水线结构是所提出的SM2硬件协处理器的主要特点。与通过有限状态机控制算法流程的实现方法相比,设计专用指令可以结合软硬件实现各自的优势,更加灵活高效地利用资源,达到软硬件协同优化的效果。执行单元的设计采用可并行的高阶Montgomery模乘算法,减少执行模乘运算所需的时钟周期,同时对关键路径上的核心计算单元进行了优化,提高了工作频率。流水线结构将指令的实现过程分为取指、译码、执行和写回四个阶段,通过四级流水使协处理器的工作更加高效。
实验结果表明,本文所提出的协处理器可以以较快的速度实现安全的椭圆曲线标量乘算法,同时占用较少的硬件资源。与之前的工作相比,本文同时考虑了标量乘算法和SM2协议层的其他运算,更加适用于完整协议的实现。另外,通过修改指令序列,本文提出的协处理器可以实现更加安全或快速的标量乘算法,也能够很容易地修改为支持基于ECC的其他公钥密码协议,具有软件实现的灵活性优势。
猜你喜欢
高校应用数学学报A辑(2022年4期)2023-01-02
现代应用物理(2022年1期)2022-05-17
西安电子科技大学学报(2022年1期)2022-04-26
科技创新与应用(2020年29期)2020-10-20
学校教育研究(2020年11期)2020-06-08
软件导刊(2019年4期)2019-06-09
科教导刊·电子版(2018年2期)2018-06-05
新高考·高一物理(2015年7期)2015-09-21
科技传播(2015年20期)2015-03-25
湖南师范大学学报·自然科学版(2014年5期)2014-11-14
