
以优秀个体为导向的多策略差分进化算法
2022-01-25 18:54陈颖洁刘三阳张哲辰
计算机工程与应用 2022年2期
陈颖洁,刘三阳,张哲辰
西安电子科技大学 数学与统计学院,西安 710126
差分进化算法(differential evolution,DE)是在1995年由Storn和Price为求解切比雪夫多项式而提出的一种群智能算法[1-2]。该算法的原理简单,受控参数少,实施随机、并行、直接的全局搜索,易于理解和实现[1-2]。差分进化算法在求解问题的过程中没有利用问题的相关特征信息,而是利用不同个体之间的差分信息来指导整个种群进化,进而实现对最优值的搜索,且其鲁棒性较好[3]。自差分进化提出以来,许多改进方法已被提出。除此,也有借助网络中的信息来指导差分进化中种群的进化[4-6]。近年来群智能进化算法以及应用也得到了广泛研究[7-13]。
一些实验结果表明差分算法中变异操作对DE算法的收敛性能影响最大[14-18]。针对处于不同状态的个体选取合适的变异策略和参数的问题,国内外许多学者对其进行了研究并提出了一些改进算法。Brest等[14]提出了jDE算法,其为种群中的每个个体设置了控制参数,并在进化过程中以一定的规则来实现对其自动的调整,虽然实现了参数的自适应,但其对不同状态的个体所需的变异策略没有进行分析考虑。Qin等[15]提出了一种自适应差分进化算法(SaDE),在进化过程中,个体的参数和所需的变异策略是通过学习自身历史的经验来实现其自动调整,在一定程度上提高了收敛速度,但是其对种群中适应度值差的个体没有进行独立的分析。Zhu等[16]提出了一种自适应的多种群差分进化算法,该方法对控制参数采用自适应的机制,但是对种群中差的个体采用DE/best/2策略,该策略虽然能提高收敛速度,但是会使整个种群陷入局部状态的概率增大。Liu等[17]提出了一种基于历史和启发式信息的自适应差分进化算法,该方法对种群中较差个体采用DE/rand/1策略,该策略能探索一些有潜力的解,但是当子种群较分散时,会影响整个种群的寻优进程。孙灿等[18]提出了一种融合邻域搜索的多策略差分进化算法,该方法利用优秀个体的优势,在优秀个体的邻域进行探索,降低了种群陷入局部最优状态的概率,但是针对种群中差的个体其变异策略采取DE/rand/1策略,并且其控制参数是定值,对于不同的优化问题,其求解效果和寻优进程都会受到影响。
以上文献主要是针对优秀种群和适应度较好的种群提出的改进。但是,正如一些动物的尾巴对于整个身体的平衡性是十分重要的,同样在进化过程中,差的种群对于维持整个种群的平衡也十分重要。如果只是针对较好个体进行改进,而忽略差的个体,则会导致整个种群在进化过程中失去平衡,进而影响种群的收敛速度和精度。所以,针对这一缺陷,本文提出了一种基于优秀个体的多策略自适应差分进化算法(BEMA-DE)。首先,根据适应度值的排序将种群等分为三个子种群,对每个子种群使用不同的变异策略和控制参数因子,从而使不同种群具有不同的搜索能力,来实现搜索能力的互补,进而有利于平衡整个种群的全局搜索与局部搜索能力。其次,为了提高收敛速度,针对适应度差的子种群,提出了一种新的变异策略,一方面通过引入学习因子以此来增强其向优秀个体的学习能力,另一方面,为了平衡收敛速度、精度和易陷入局部最优的状态,引入了平衡因子。并且对其控制参数采取自适应的机制,以此来降低种群陷入停滞状态的概率,保持算法的稳定性。
1 以优秀个体为导向的多策略自适应差分进化算法
1.1 初始化种群
在维数为D的空间中按式(1)随机生成规模大小为NP初始种群。

当种群生成之后,根据其适应度值的排序将其等分为三个种群,记为X1、X2、X3。
1.2 变异操作
1.2.1 优秀个体的选取
对于不同的算法,优秀种群与优秀个体的判定方式与选取方式也不尽相同。文献[17]中优秀种群是取种群的前10%,优秀个体则采取随机选取的机制,在前10%个体中随机选取一个个体作为优秀个体,该方法具有一定的随机性,能够在一定程度上避免种群陷入最优状态,但是优秀种群的数量与算法自身性能有很大关系,文中没有对其进行实验分析。文献[18]中将个体的k邻域作为优秀群体,再从其中选取适应度值最好的个体作为优秀个体,邻域操作能够更好地探索周围有潜力的解,但是将适应度值最好的解作为优秀个体则会使种群陷入局部最优的概率增大。文献[19]中对于优秀群体的选择是取排序后种群的前50%,并在其中任意选取一个个体作为优秀个体,这种选取方式能使种群保持良好的多样性,但是该方法的优秀群体过大,会使选取较好的优秀解的概率降低。文献[20]中则是用自适应的机制来选取优秀群体,然后在优秀群体中随机选择一个个体作为优秀个体,该方法能够实现优秀个体自适应的选取,但是在每一次迭代过程中,相关参数都会进行更新,其计算量会增大。为了减小计算量并避免种群陷入局部最优状态,本文对于优秀个体的选取参照文献[17]中所提的方法,同时为了探究不同优秀种群数量对本文所提算法的影响,本文将优秀种群数量分别设置为排序后种群的前5%、10%与15%,将函数f1~f16在不同维数下30次独立运行结果的均值列于表1和表2。由表1和表2可以看出当优秀种群数量选取10%时,本文所提在大部分函数上能取得较好结果。
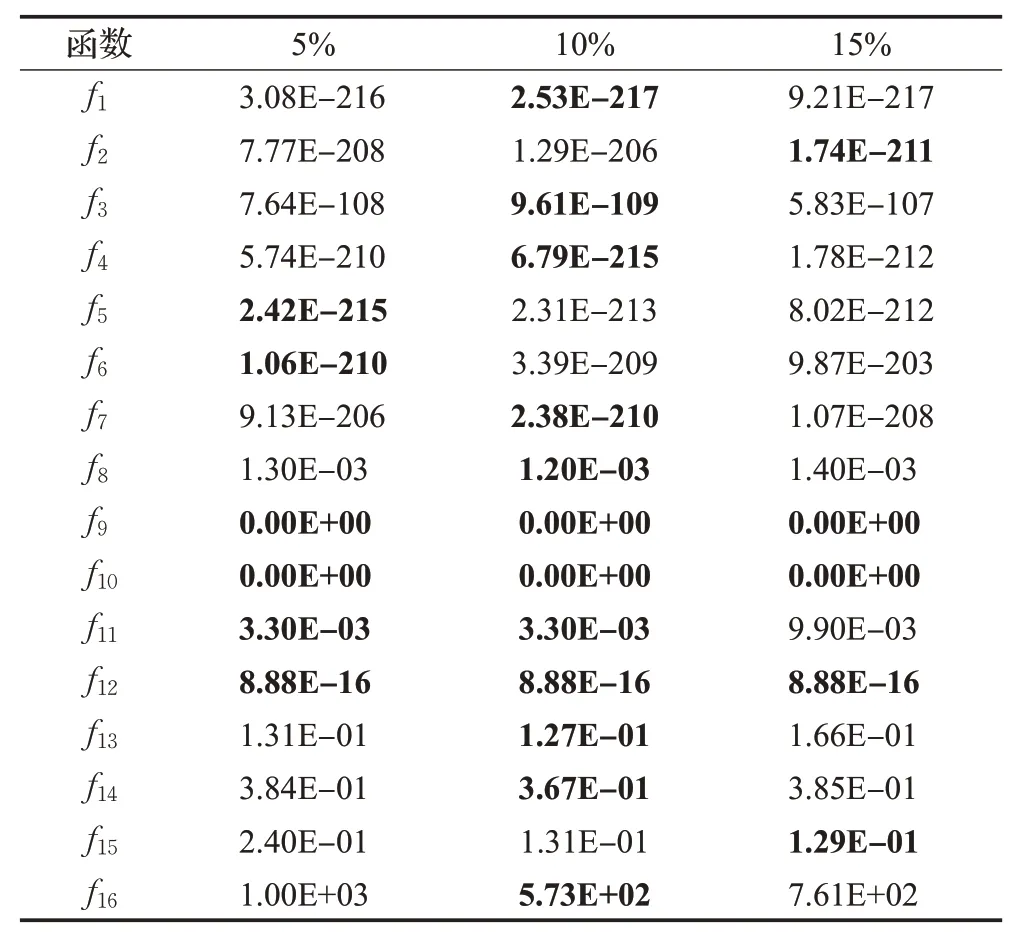
表1 函数在不同优秀种群数量时的取值(NP=60,D=30)Table 1 Value of function for different excellent populations when NP=60,D=30

表2 函数在不同优秀种群数量时的取值(NP=90,D=60)Table 2 Value of function for different excellent populations when NP=90,D=60
1.2.2 学习因子和平衡因子
为了增加适应度值差的个体向优秀个体的学习能力,引入学习因子LF1、LF2。对个体Xi而言:

其中,Xpbest是在优秀种群中随机选取的个体。f(Xpbest)是该个体的适应度值。式(2)和(3)中的参数如下:

其中,Gm是最大迭代次数,t是当前迭代次数。随着进化的推进,由式(5)可以看出WP的值是在逐渐增大。f(Xmax)为个体Xi的适应度函数值,f(Xmin)和f(Xmax)表示种群在当前代数t中个体适应度值的最大值和最小值。
由式(4)、(6)和(7)可知,BF、IS1、IS2、(1-BF)可看作是关于个体Xi的单调函数,即当个体适应度值越大时,其BF、IS1的值越大,IS2与(1-BF)的值越小,当个体适应度值越小时,其BF、IS1的值越小,IS2与(1-BF)的值越大。以函数f16为例,为了更加直观地观察BF的变化趋势,绘制其最后一次迭代过程中的曲线图,如图1所示。
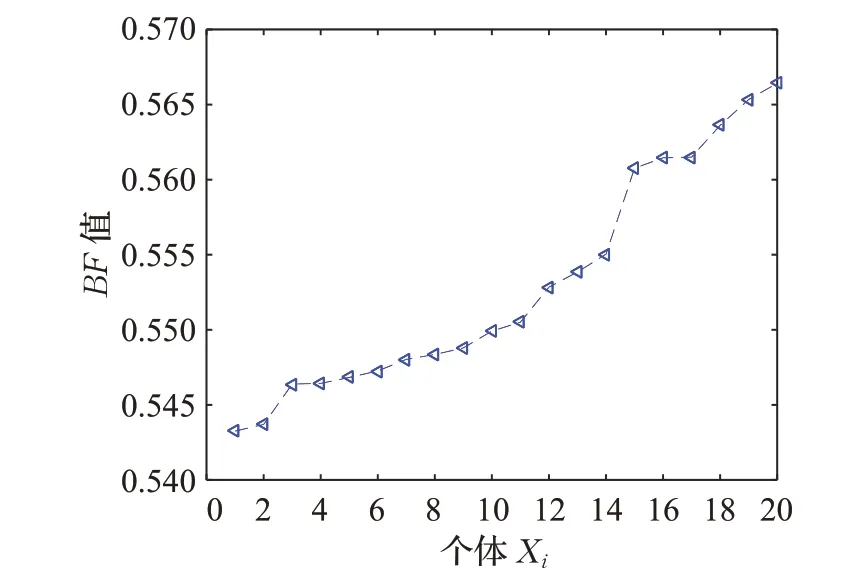
图1 种群X3中BF值变化曲线Fig.1 Change curve of BF value in population X3
假设当前迭代次数为t,则LF1与LF2也可看作是关于个体Xi的单调函数,此时,当个体适应度值越大时,LF2的值越大,当个体适应度值越小时,LF1的值越大。对于种群X3中的个体Xi,当其适应度值越大时,其向优秀个体学习的能力就需越强,故用学习因子LF2来增强其向优秀个体的学习能力,但是为避免其收敛过快,陷入局部最优状态,引入呈递减趋势的平衡因子(1-BF)来对其进行平衡。当其适应度值越小时,需要降低其向优秀个体的学习能力,故用学习因子LF1来增强对自己的学习能力,但是因种群X3中个体适应度值相对其他两个种群而言较差,为了避免对个体自身学习能力过大,故用呈递减趋势的平衡因子BF来对自身进行平衡。随着进化过程的推进,即t逐渐增加时,应该适当地加快种群的收敛速度,此时WP与1-WP可分别看作是1-IS2与IS2的权重,故此时向优秀个体学习的能力应该增强,进而能够起到加速收敛的目的。以函数f16为例,图2能够更加直观地观测出平衡因子BF在进化中对学习因子LF1、LF2的影响及变化趋势。
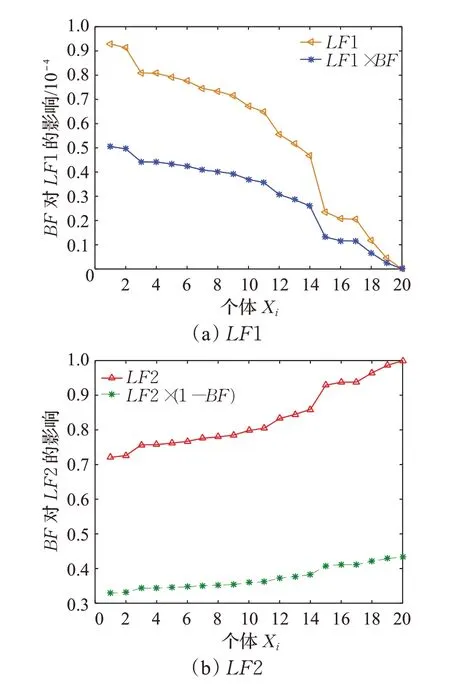
图2 BF值对学习因子的影响曲线图Fig.2 Graph of BF value influence on learning factor
1.2.3 控制参数的选取
DE算法中,有两个控制参数,尺度因子F和交叉概率CR。控制参数的引进有助于了解种群和个体的信息,对于选取不同变异策略的种群来说,控制参数的选取也极为重要,而参数调整的目的也在于平衡种群的探索能力和开采能力[8]。F取值越大,种群多样性下降缓慢,增加了从局部极值点逃脱的可能性[8]。F越小,开采能力越好,但是容易陷入局部最优状态。CR的值越小,试验向量中变异向量所占的比例较小,有利于维持种群的多样性,CR值越大,有利于局部搜索和加速收敛[8]。对于种群X1中的个体来说,其参数值参照原文献。对于种群X2中的个体,设置其尺度因子F=0.6,交叉概率CR=0.9,在本文中能够取得较好的实验效果。
对于种群X3中的个体来讲,同时考虑了进化代数与种群中不同个体之间的差异,在此基础上对其参数采取自适应的机制。假设当前迭代次数为t,对X3中适应度值较大的个体而言,需要增大其尺度因子的值,减少交叉概率的值来维持种群的多样性来避免种群陷入停滞的状态。反之,对于适应度值较小的个体来讲,需要减小其尺度因子的值,增大交叉概率的值。随着进化过程的推进,即t逐渐增加时,为了平衡算法的全局搜索能力与局部搜索能力,此时F和CR的值随着迭代次数的增加应该逐渐增加。所以对种群X3中的每个个体来说,设置其控制参数如下:
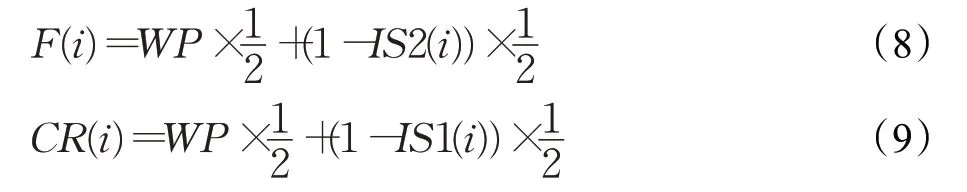
为了更加直观地观察种群X3中控制参数的变化。以函数f15为例,绘制其在最后一次迭代的F和CR的取值变化图,如图3所示。
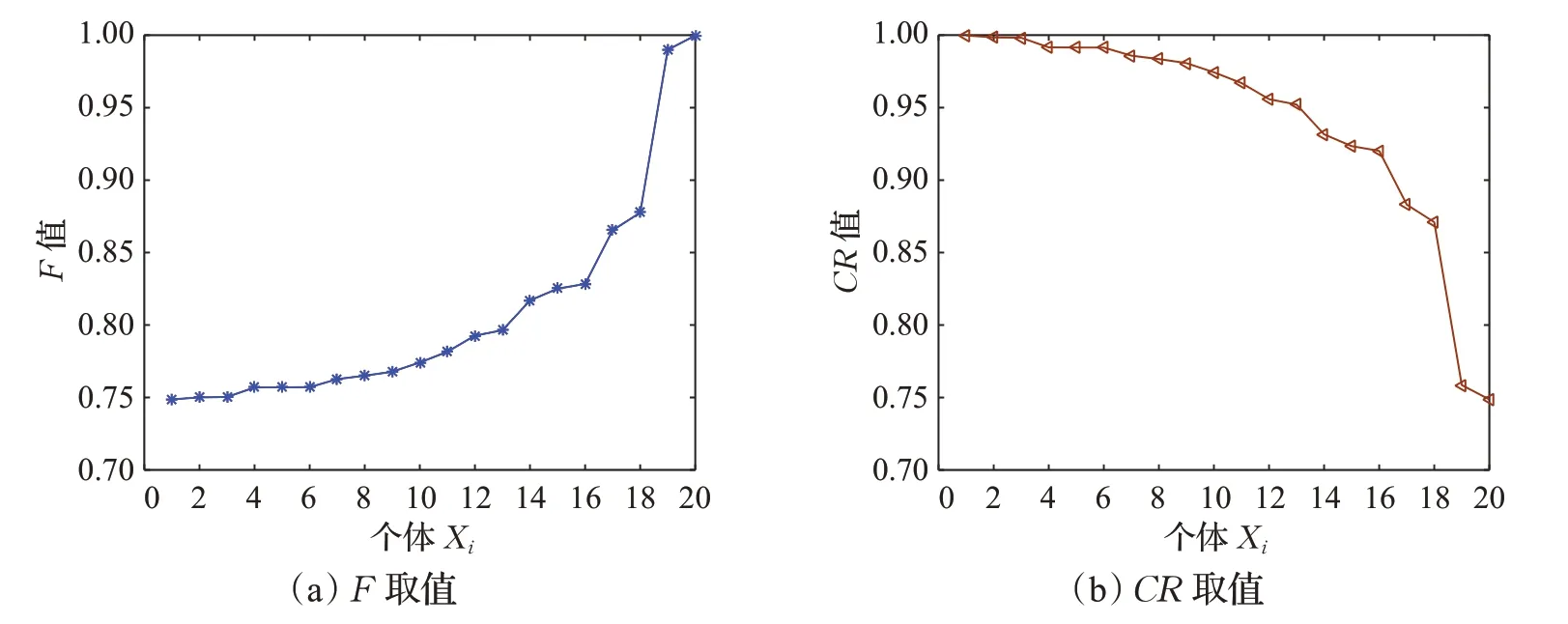
图3 种群X3中不同个体的F和CR取值Fig.3 Values of F and CR for different individuals in population X3
图4给出了对于函数f15在进化过程中适应度值不同的个体,即IS1和IS2取不同值时,F和CR随着种群进化的变化曲线图。由图4可以看出,当t是定值时,IS1值越小,其CR的值就越大,此时有利于增强局部搜索能力;IS2值越小,其F值就越大,此时有利于增强勘探能力。随着t的增大,F和CR的值也在不断地增大,对于种群X3来说,有利于平衡其全局搜索能力与局部搜索能力。

图4 进化过程中不同状态个体的F和CR取值Fig.4 Values of F and CR of individuals in different states during evolution
1.2.4 变异策略的选取
随着DE算法的不断完善,已经有很多的变异策略被提出来。常见的变异策略如下:


其中,r1、r2、r3、r4是在[1,NP]中随机选取的不同整数且和个体X的指标i不同。
针对不同的种群选取不同的策略对整个种群所起的作用是不一样的。而针对要解决的问题,使用的变异策略也是不一样的。在本文中,为了提高种群的收敛速度并且增加种群的探索能力,不使种群陷入停滞的状态,同时也能够维持整个种群的平衡状态,对于种群X1中的个体而言,为了增强其局部搜索能力,在利用当前优秀个体的优势之下,探索其周围更好的解选择MSDE-DE算法中的策略[18]:

选择策略DE/best/2;

其中,r1、r2、r3都是随机选取的数,且满足r1+r2+r3=1,lbesti是个体Xi在半径为k的邻域内的适应度值最小的个体。Xa和Xb是在个体Xi的k邻域内随机选择的个体。
对于种群X2中的个体来说,其主要作用是探索一些有潜力的解,进而增强种群的全局搜索能力。所以在利用当前优秀解的前提下,为了产生更加均匀的解,选取文献[21]中的策略:
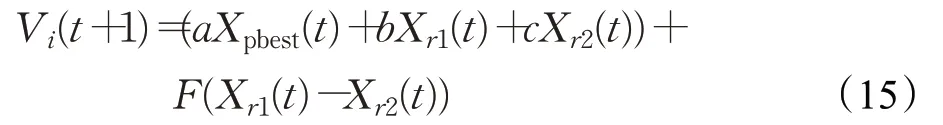
在变异策略中,基向量相当于局部搜索的中心。种群的多样性在很大程度上是由局部搜索中心来决定的,所以基向量的选取十分重要[8]。种群X3来讲,其适应度值较差,所以需要增强其像优秀个体的学习能力,故对其基向量的选取如下式:

其中:
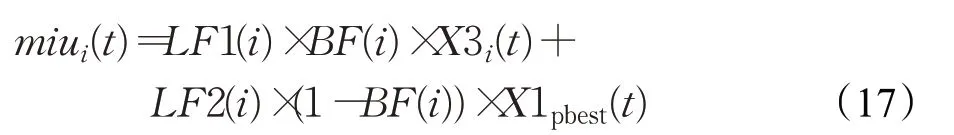
这里randCauchy是指以miui(t)为均值,0.1为方差的柯西分布形成的个体,其目的是探索周围邻域存在的有潜力的解。对于变异策略中差分向量采取随机选取的机制,从而在基向量的基础上向周围寻优。综上,对于变异策略的选取如下式:
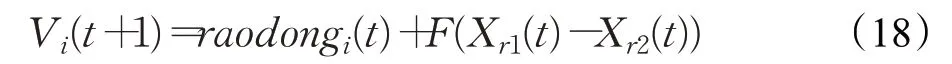
其中,r1、r2是在种群的前20个个体中随机选取的两个个体。在种群X3中,对于适应度值越差的个体,当其向优秀个体的学习因子过大时,此时基向量会侧重以优秀个体为中心,变异向量个体则侧重在优秀个体与差分向量的组合基础上产生,易使整个种群陷入局部最优状态,故此时引入平衡因子来放缓其向优秀个体的学习速度,在一定程度上避免其陷入局部最优状态。当其向优秀个体的学习因子较小时,此时基向量侧重以个体自身为中心,变异向量个体侧重在个体自身与差分向量的组合基础上产生,有利于维持种群的多样性。
通过对不同的种群使用不同的变异策略和控制参数,使得不同的变异策略和参数在进化过程中所发挥的作用不同,进而实现各个种群之间搜索能力的互补,最终达到平衡全局搜索能力和局部搜索能力的作用。
1.3 交叉操作
对于经过变异操作的种群中的每个个体Vi,j,按照下式产生试验向量个体:

其中,i=1,2,…,NP,j=1,2,…,D,rand(j)∈[0,1]为第j维分量对应的随机数。k=1,2,…,D用来保证产生的试验个体中至少有一个分量来自变异个体。
1.4 选择操作
传统DE算法中使用的是贪婪选择机制。在选择操作根据试验个体Ui,j和目标个体Xi,j的适应度函数值。按照式(20)产生进入下一代的个体。

本文为了增加优秀个体进入下一代的概率,选择使用基于目标排序的选择策略[5]。
2 BMEA-DE算法伪代码
BMEA-DE算法伪代码如下:
1.随机初始化种群,设置种群规模NP以及维数D。
2.设置当前迭代次数t,最大迭代次数Gm。
3.Whilet≤Gmdo:
4.根据适应度的值将种群分为3个子种群X1,X2,X3。
5.fori=1:NP/3 do:
6.对种群X1中的个体,使用策略(14)。对于种群X2中的个体,使用变异策略式(15)产生变异向量个体,再根据式(19)产生试验向量个体。对于种群X3中的个体,使用策略(18)产生变异向量个体,根据式(19)产生试验向量个体。
7.对于种群X1,X2中的个体选择贪婪选择机制,种群X3的个体则根据基于目标的排序选择机制[5]选取合适的个体进入下一代。
8.将三个子种群合并为一个种群并根据其适应度值再次将其等分为3个子种群。
9.t=t+1。
10.end while
3 数值仿真
3.1 测试函数
针对本文提出的算法,选取了19个标准测试函数来对其进行验证。其中,f1~f7为高维单模态问题,f8为Noise函数。f9~f16为高维多模态函数。f17~f19是低维函数,其维数D=2。表3为各个测试函数所对应的参数。

表3 函数的名称、搜索范围和最优值Table 3 Name、search space and optimal value of test function
3.2 实验结果
将文中所提的算法与4种不同的算法进行对比,分别是标准DE、jDE、SADE以及同样是多策略的MSDE-NS算法[17],其相关参数参照原文献中的值。实验所用处理器为Intel®CoreTMi5-6500CPU@3.20 GHz 3.19 GHz,所有算法均在Matlab2016a下进行,以迭代次数Gm=3 000次为停机准则,各算法独立运行30次,实验结果如表4。其中mean表示30次独立运行的最优值的均值,反映了算法的求解精度,std表示方差,反映了算法的稳定性。
当测试函数的维数升高时,函数的优化就会随之变得更加复杂,为此将种群规模和维度分别升至NP=90,D=60,得到均值和方差,如表5所示。由表4和表5可以看出,BMEA-DE在大部分函数上性能表现很好,当维数增加时其解的精度与其他算法相比仍有优势。

表4 NP=60,D=30时BMEA-DE算法与主流算法的结果对比Table 4 Results of BEMA-DE algorithm compared with mainstream algorithm when NP=60,D=30

表5 NP=90,D=60时BEMA-DE算法与主流算法的结果对比Table 5 Results of BEMA-DE algorithm compared with mainstream algorithm when NP=90,D=60
为了更直观地观察不同维数对算法的影响,选择单峰函数f6和多峰函数f13,将其维数由20维逐步升至40维,各算法独自运行30次,取平均值,得到各算法在不同维数下最优值结果的曲线对比图,如图5。
由图5可以看出,BMEA-DE算法对于维数的增加更具有稳定性。

图5 函数f6和f13在不同维数下的最优值Fig.5 Optimal values of function f6 and f13 in different dimensions
为了更加直观地观察不同算法的收敛速度和精度,将函数f1、f4、f11、f13、f15的收敛曲线绘制如图6。收敛曲线是各算法独立运行30次的平均曲线。
由图6可以看出BMEA-DE算法具有更快的收敛速度与精度,对于多峰函数,其部分函数精度也有所提高。对于多峰函数f13和f15,相比较的算法在进化后期基本都陷入一种停滞的状态,只有BMEA-DE算法还在不断寻优。

图6 5个函数在不同算法下的收敛曲线Fig.6 Convergence curves of five functions under different algorithms
表6给出了文中所有算法的Friedman排名,可以看出在不同维数下BMEA-DE算法的排名都为第一。

表6 BMEA-DE与改进的DE算法的Friedman排名结果Table 6 Friedman ranking results of BMEA-DE and improved DE algorithm
4 结束语
根据种群个体适应度值的排名,本文针对处于不同状态的种群个体使用了不同的变异策略,进而使不同的变异策略在整个种群进化过程中发挥其各自的作用。并针对适应度值较差的种群提出了一种新的变异策略,使其能够更加平衡地向优秀个体学习,从而达到平衡加速收敛以及避免陷入局部最优状态的作用。通过对其参
数使用自适应的机制也能使种群更加多样性。最后通过19个测试函数的实验结果可知,BMEA-DE算法在大部分函数上寻优精度和收敛速度上都有一定的提升。并且通过维数的分析,可以得出维数的增加对BMEA-DE算法的寻优精度影响较小,算法有较强的稳定性。
猜你喜欢
数学杂志(2022年5期)2022-12-02
计算机仿真(2022年8期)2022-09-28
湘潭大学自然科学学报(2022年2期)2022-07-28
新世纪智能(数学备考)(2021年5期)2021-07-28
郑州大学学报(工学版)(2018年2期)2018-04-13
科学与财富(2017年15期)2017-06-03
科技创新与应用(2017年1期)2017-05-11
科技与创新(2017年3期)2017-03-17
太空探索(2014年1期)2014-07-10
城市建设理论研究(2014年11期)2014-04-21
