
增强可分离卷积通道特征的表情识别研究
2022-01-25 18:54梁华刚雷毅雄
计算机工程与应用 2022年2期
梁华刚,雷毅雄
长安大学 电子与控制工程学院,西安 710064
机器视觉是人工智能领域的一个飞速发展的分支,随着科学技术不断进步,人脸表情识别(facial expression recognition,FER)技术正在经历前所未有的发展。人们在日常生活中经常会听到“表情”这个词,它是面部肌肉的动作或状态的结果,是一种非语言交流的形式。面部表情是日常生活中最为重要的一种信息传递方式,人们在日常生活中可以通过面部表情进行交流,传递大量的信息。当人们面对面交流时,55%的信息是通过面部表情传递的[1]。目前人类主要有七种情感:愤怒、高兴、悲伤、惊讶、厌恶、恐惧和自然。面部表情识别的研究从未停止过,人脸面部表情识别是人脸识别技术中的重要组成部分,近年来在人机交互、安全、机器人制造、自动化、医疗、通信和驾驶等领域得到了广泛的关注,成为学术界和工业界的研究热点。
人脸表情识别主要包括人脸图像采集、人脸图像预处理、特征提取和表情识别四个步骤,其中特征提取是最重要的步骤,一个好的特征提取方法可以直接决定人脸面部表情识别的准确率。传统的人脸表情识别方法主要采用手动提取特征的方式,比如提取表情几何特征的ASM[2]方法,提取表情边缘特征的HOG[3]方法和表情纹理特征的LBP[4]方法等,再用SVM[5]进行分类。传统的人脸表情特征提取方法受人为因素影响识别率不高,而卷积神经网络面临大数据样本时更易训练,并能提取到人脸表情的高维特征,用在人脸表情识别的特征提取当中可以取得相当不错的效果。
LeCun等人[6]首次提出第一个真正意义上的卷积神经网络,并于1998年提出了应用卷积神经网络的算法解决手写数字识别的视觉任务。深度卷积神经网络起源于2012年的AlexNet网络[7],与以前的卷积神经网络相比,AlexNet网络最显著的特点是层次更深,参数规模更大,使用了新的激活函数修正线性单元(the rectified linear unit,ReLU),并且引入dropout机制。2014年,Simonyan等人[8]提出VGGNet,通过不断加深网络来提升性能,证明了深度对模型性能的重要性。随后Szegedy等人[9]提出GoogleNet模型,不仅增加了网络模型的深度,还增加了网络模型的宽度,在没有增加计算代价的同时反而能提取到更多的特征,从而提升训练结果。深度卷积神经网络是一种深度学习方法,也是一种特征学习的方法,可以提取到更深的图像特征,使得表情识别的准确率也得以提升,已经取得了相当不错的成果。王建霞等人[10]通过增加卷积神经网络的深度和宽度来增强特征提取能力,将高层次与低层次的特征进行融合,取得了较好的表情识别效果。杜进等人[11]在网络结构中引入了残差学习模块,目的是解决随着网络深度的增加神经网络出现的退化问题,从而导致表情识别精度下降。吕诲等人[12]使用超级精简的轻量化网络,网络只有66 000个参数,主要是保证网络的实时性需求。这些方法虽然取得了较好的效果,但也面临着一些问题:(1)随着网络层数的加深,网络结构的复杂程度也越高,计算代价会越来越昂贵;(2)网络参数降低后精度却得不到一定的保证。
因此,本文采用深度学习方法,设计并训练轻量化的卷积神经网络表情识别模型,将可以增强特征提取能力的Squeeze-and-Excitation(SE)[13]模块与深度可分离卷积神经网络相结合,来减少网络模型参数,同时更高效地提取人脸表情特征。在网络结构通道数不同的层加入的SE模块的压缩率是不同的,可以更好地将通道间的相关性结合起来,增强特征提取能力。
1 基于深度可分离卷积的表情识别
1.1 卷积神经网络
卷积神经网络(convolutional neural network,CNN)在分类问题中表现优异,对其进行训练,可以学习到输入和输出之间的多层非线性关系。卷积神经网络的结构一般由卷积层、池化层和全连接层组成,如图1所示。

图1 卷积神经网络结构Fig.1 Structure of convolutional neural network
1.1.1 卷积层
卷积层即卷积操作,在图像处理中,卷积操作其实就是对一组多维矩阵的不同局部与卷积核每个位置的元素相乘,然后求和,计算表达式如公式(1)所示:
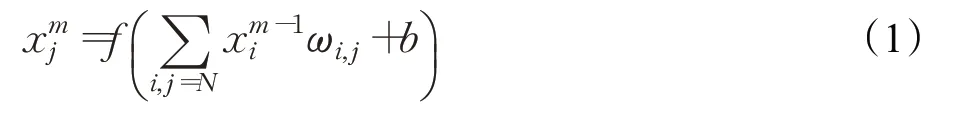
1.1.2 池化层
池化层常见的两种方式为平均池化和最大池化,即取对应区域的平均值或最大值作为池化后的元素值。例如,对一个4×4的输入,使用2×2的核进行最大池化操作的过程为:

1.1.3 全连接层
全连接层的每个结点与前一层所有结点进行连接,将前一层所提取到的各个特征结合起来,使网络学习到的特征图转换为一个多维特征向量,送入分类器后可以实现图像的分类与识别。假设全连接层输入为X,输出为Y,计算表达式如公式(2)所示:

式中,Yi表示输出Y中的元素,Xj表示输入X中的元素,wij表示权重系数,Q表示输入X的元素总数,b为偏置。
1.2 深度可分离卷积
深度可分离卷积实质上将卷积分为两个阶段:深度卷积DW(depthwise convolution)和点卷积PW(pointwise convolution)。DW属于深度可分离卷积滤波阶段,每一个通道上有对应的卷积核进行卷积操作;PW是深度可分离卷积的组合阶段,整合多个特征图信息。深度可分离卷积能够大幅度减少参数,因而其计算量较传统卷积大幅缩减,并且在深度卷积和1×1卷积后都增加了BN(batch normalization)[14]层和激活层。深度可分离卷积的结构如图2所示,BN层用于对数据进行归一化,以保证每层的数据分布稳定,避免输入数据的偏移造成的影响。激活层增加了神经网络各层之间的非线性关系,通过激活函数稀疏后的模型能够更好地提取相关特征、拟合训练数据,同时有效地抑制了梯度消失的问题。
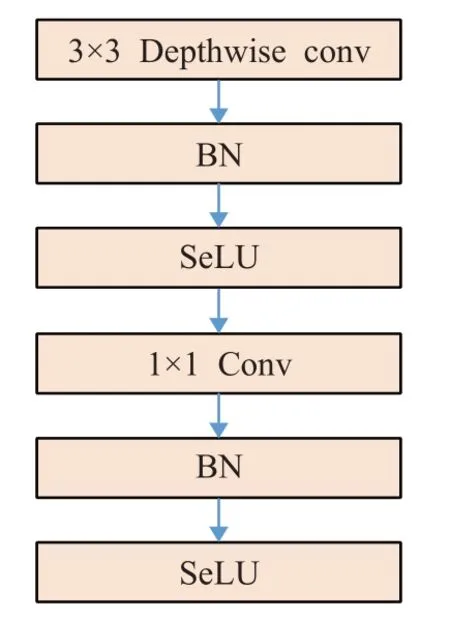
图2 深度可分离卷积结构图Fig.2 Structure diagram of depthwise separable convolution
1.3 激活函数
激活函数在神经网络中主要用来解决线性不可分问题,它可以增强神经网络模型的非线性能力,以及提升网络模型的学习和表达能力。ReLU激活函数是其中效果比较好的一种,根据公式(3)可看出,首先输入在正区间内,只有线性关系,可以让神经网络的训练速度提升数倍,不会对模型的泛化产生影响。其次,ReLU的非负区间的梯度为一个常数,所以梯度消失的问题基本上是不存在的,使得模型的收敛速率相对稳定。但是ReLU也有其局限性,由于其函数在负半轴上置0,此操作也称作单侧抑制,使得神经网络中的神经单元具备了稀疏激活性。但是,随着训练的进行,可能会出现神经单元的死亡,相应的参数不再更新的情况,而且ReLU函数的输出不是以0为中心的。

式中,x是来自上一层神经网络的输入向量。
放缩指数线性单元(scaled exponential linear units,SeLU)[15]激活函数就是解决上述问题而产生的,如公式(4),使用该激活函数后可以使得样本的分布自动地归一化到零均值和单位方差,并且经过许多层的前向传播后还是会收敛到零均值和单位方差,即使是存在噪声和扰动的情况下依然如此。与ReLU函数相比较,在输入为负数的情况下,此时是有一定的输出能力的,并且这部分输出还具备抗干扰的能力。这样可以解决ReLU神经单元死掉的问题,因此,SeLU函数更有利于训练多层的深度神经网络,训练过程中梯度也不会爆炸或消失。

其中,λ=1.050 700 987 355 480 493 419 334 985 294 6,α=1.673 263 242 354 377 284 817 042 991 671 7。
1.4 Squeeze-and-Excitation
SE模块是一种基于注意力机制的网络子结构,是本文网络结构的核心模块,它通过对特征通道间的相关性进行建模,把重要通道的特征强化,非重要通道的特征弱化,以此来提升准确率,可以嵌入到各种分类网络模型当中,增强特征提取层的感受野,提升卷积神经网络的性能。模块主要由Squeeze(压缩)、Excitation(激发)和Scale(加权)三部分构成,当上一层网络结构输出一个宽为W、高为H、通道数为C的特征X时,SE模块可以学习到该特征不同通道的重要性并进行加权,最终输出一个表征能力更强的特征,SE模块结构如图3所示。

图3 SE模块结构图Fig.3 SE module structure diagram
一般来说,卷积神经网络的每个通道使用的滤波器都在局部感受野上工作,因此每个特征图不能有效地利用其他特征图的上下文信息,而且在网络的较低层次上,其感受野的尺寸都是较小的,这样情况就会变得糟糕。压缩操作是首先顺着空间维度来进行特征压缩,使用全局平均池化(global average pooling,GAP)进行压缩操作,将C个W×H大小的特征图提取成长度为C的实数列。这个实数列其实是拥有全局的感受野,输入的特征通道数和输出的维度是相互对应的。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层获得全局的感受野成为可能。紧接着将实数列送入两个全连接层去建模通道间的相关性,并输出和输入特征同样数目的权重。具体的,首先通过一个全连接层将特征维度降低到输入的1/r,其中r为压缩率,然后经过SeLU激活后再通过一个全连接层升回到原始维度。这样做比直接用一个全连接层的好处在于:(1)非线性度更高,能更好地拟合通道间复杂的相关性;(2)极大地减少了参数量和计算量。然后通过一个Sigmoid的门获得0到1之间归一化的权重,最后通过一个Scale的操作来将归一化后的权重加权到每个通道的特征上。
1.5 网络架构
本文提出了一种增强可分离卷积通道特征的表情识别研究方法,网络框架如图4所示。将输入图像送入卷积层进行一系列卷积操作提取特征后进行分类,为了提取到更好的特征,网络的结构设计借鉴了Xception[16]网络结构的轻量化设计思想,在通道数过大的卷积层采取深度可分离卷积取代一部分普通卷积,减少网络结构参数量。但是与Xception网络不同的是,本文网络结构没有大量堆叠深度可分离卷积,主要是因为在实验过程中发现堆叠太多深度可分离卷积并没有对表情识别精度的提升有明显帮助。此外,对网络进行改进的同时引入可以增强特征提取能力的SE模块来高效地提取人脸表情识别特征,在通道数不同的卷积层SE模块的压缩率是不同的。
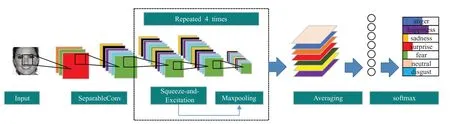
图4 网络框架图Fig.4 Network structure diagram
所提网络结构及详细参数信息如表1所示。网络主要由11个卷积层依次相连组成,第3个卷积层至第10个卷积层采用深度可分离卷积,卷积层的所有卷积核大小为3×3,步长为1,初始通道数为64,通道数依次递增,最高可达1 024个通道。最后接一个全局平均池化,分别累加每个特征图所有像素值并求平均,得到7个数值,将这7个数值输入到softmax分类器中,得到7个概率值,即这张图片属于每个类别的概率值,用于对七类表情的预测。网络中的部分卷积层后依次使用批量归一化、放缩指数线性单元和SE模块,并且分别在第4、6、8、10个SE模块后嵌入了窗口大小为3、步长为2的最大池化层。

表1 网络结构及参数表Table 1 Network structure and parameter table
2 实验结果及分析
2.1 实验数据集
本实验分别采用FER2013[17]表情数据集和The Extended Cohn-Kanade Dataset(CK+)[18]表情数据集进行实验。
(1)FER2013数据集。该数据集共包含了35 887幅图像,其中有28 709幅图像为训练集,测试集和验证集分别为3 589幅图片。每幅图片是由48×48固定大小的灰度图像组成,共有7种表情,分别为:愤怒、厌恶、恐惧、高兴、悲伤、惊讶和自然。图5为FER2013表情数据集中部分表情样例,包含了不同年龄、肤色、性别的人脸表情。

图5 FER2013数据集部分图像Fig.5 Partial images of FER2013 dataset
(2)CK+数据集。该数据集总共包含了123个人的593段表情序列,但是有效标注表情的标签数据只有327个表情序列,本实验抽取了其中的1 101个比较明显的图片,检测到人脸并且将人脸裁剪到大小固定为48×48的灰度图像,分为7种表情:愤怒、厌恶、恐惧、高兴、悲伤、惊讶和自然。图6为CK+表情数据集中部分表情样例,包含了不同种族、肤色、性别的人脸表情。

图6 CK+数据集部分图像Fig.6 Partial images of CK+dataset
为了减少训练过程中的过拟合,在实验中进行了数据增强处理如图7所示,具体参数设置如表2所示。其中,“Rotation_range”表示将图像按顺时针或逆时针方向随机旋转一定角度;“Rescale”表示随机缩放图片;“Shear_range”表示逆时针方向的剪切变换角度;“Zoom_range”表示随机缩放图片的幅度;“Horizontal_flip”表示进行随机水平翻转图片;“Fill_mode”表示进行变换时若超出边界的点,会按照选择设置的参数进行处理。

图7 数据增强图Fig.7 Data augmentation diagram

表2 数据增强参数表Table 2 Data augmentation parameter table
2.2 实验结果与分析
本文使用Python3.6.5进行实验,操作系统为Windows 10,硬件平台为英特尔Core i9-9820X CPU,内存为32 GB,GPU为11 GB的NVIDIA GeForce RTX 2080 Ti。网络的batch为32,初始学习率为0.1,如果验证损失在10轮内都没有改善,则按照10倍的速率将学习率降低,最低降为0.000 1,采用交叉熵损失函数,并在实验中用Adam优化器优化训练过程。
图8和图9分别为CK+和FER2013数据集上的准确率迭代收敛曲线,图10和图11分别为CK+和FER2013数据集上的损失函数迭代收敛曲线。
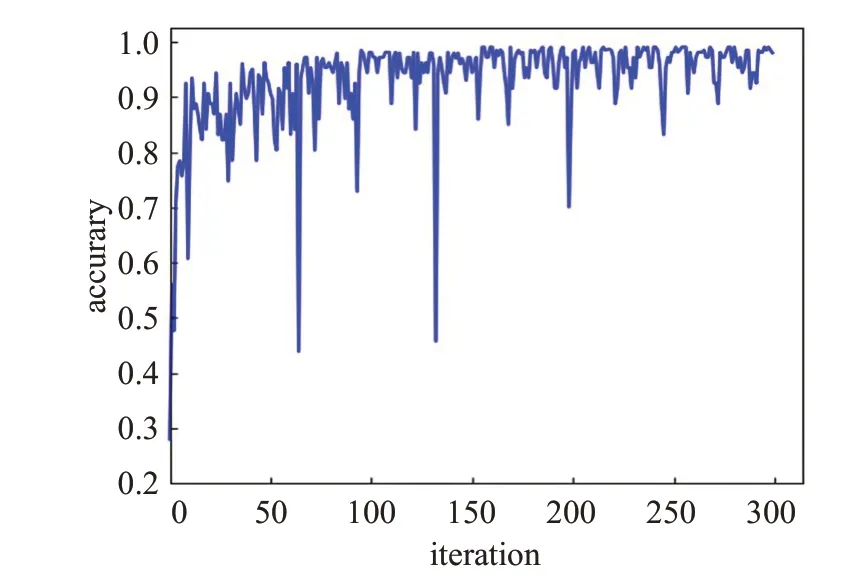
图8 CK+准确率曲线图Fig.8 CK+accuracy curve

图9 FER2013准确率曲线图Fig.9 FER2013 accuracy curve

图10 CK+损失曲线图Fig.10 CK+loss curve

图11 FER2013损失曲线图Fig.11 FER2013 loss curve
网络在CK+数据集上得到的最终准确率为98.95%,在FER2013数据集上得到的最终准确率为70.30%。由准确率迭代收敛曲线图可以看出,随着迭代次数的增加,准确率逐渐上升,虽然迭代过程中会产生一些波动变化,但是总体是趋于稳定收敛状态的。由损失函数迭代收敛曲线图可以看出,在迭代过程中损失值会逐渐下降,最终收敛到一个接近于0的值,并保持稳定状态。
2.2.1 压缩率对比实验
本文引入了SE模块来提高人脸表情识别精度,选择不同的压缩率r可以使得模块具有不同效果的通道加权能力。实验中分别将压缩率r设置为2,4,8,16,32,与本文所提出的在网络结构的不同层采用不同的压缩率进行对比实验,实验结果如图12和图13所示,combination代表本文方法,None代表在网络结构中不加入SE模块。可以看到引入SE模块会提高表情识别准确率,且本文方法效果优于所有模块使用同一个压缩率。

图12 FER2013表情识别准确率Fig.12 Expression recognition accuracy rate with FER2013
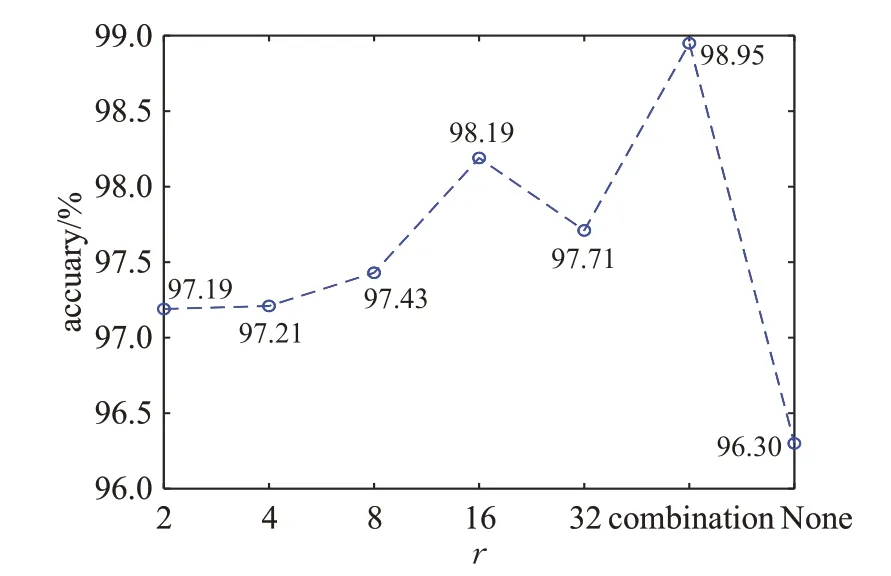
图13 CK+表情识别准确率Fig.13 Expression recognition accuracy rate with CK+
选择不同的压缩率会影响最终的人脸表情识别精度,因此压缩率的选取很关键。基于此在不同层采用不同的压缩率,由于初始层通道数较少,所以设置的压缩率小,随着通道数的增多,逐渐增加SE模块压缩率到网络结构的不同层。网络结构从第三个SE模块开始,每隔两个SE模块的通道数是一样的,所以选择压缩率的时候将这些通道数一样的SE模块的压缩率设置为同一个压缩率。进行实验对比后,实验结果如图14和图15所示,图中为7组效果较好的不同压缩率组合方式,选择了性能最佳的压缩率组合方式r1。图中网络结构的SE模块压缩率r1至r7具体设置如表3所示,表中总共10个SE模块,分别对应其压缩率取值。选择合适的压缩率主要是为了更好地利用两个全连接层来拟合通道间的相关性,利用通道间的相关性来增强特征提取能力,从而提升表情识别精度。
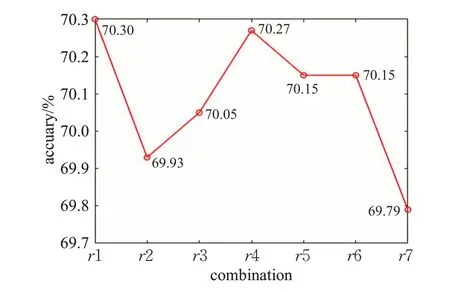
图14 FER2013不同压缩率组合方式识别准确率Fig.14 Recognition accuracy of different squeeze ratio combinations with FER2013

图15 CK+不同压缩率组合方式识别准确率Fig.15 Recognition accuracy of different squeeze ratio combinations with CK+

表3 压缩率取值Table 3 Squeeze ratio value
2.2.2 不同方法对比实验
通过多次实验后得出实验结果,FER2013和CK+数据集上七类表情的混淆矩阵如图16和图17所示。

图16 FER2013数据集上七类表情的混淆矩阵Fig.16 Confusion matrix of 7 types of expressions on FER2013 dataset

图17 CK+数据集上七类表情的混淆矩阵Fig.17 Confusion matrix of 7 types of expressions on CK+dataset
由图16可以看出,FER2013数据集中表情识别率最高的是高兴和惊讶,可能原因是高兴和惊讶的表情特征辨识度更高。愤怒和恐惧表情识别率相对较低,可能原因是这两种表情特征很相似,具有相同的嘴角、眉毛等特征,很容易发生混淆,从而导致表情识别率不高。由图17可以看出,CK+数据集的整体表情识别准确率可以达到95%以上,其中识别率最高的为愤怒和高兴,可能原因是由于CK+数据集中愤怒和高兴的表情特征相对于其他表情区别更大一些,识别率较低的是悲伤类,因为在数据集特征都相对明显的情况下,悲伤表情和厌恶表情特征相近似,使其识别率有所影响。图18和图19为FER2013和CK+数据集中容易发生混淆的表情示例。

图18 FE(Rb20)13恐数惧据表集情易混示淆例图片对比Fig.18 Confusing expression contrast on FER2013 dataset

图19 CK+数据集易混淆图片对比Fig.19 Confusing expression contrast on CK+dataset
为了验证本文提出方法的有效性,在CK+和FER2013数据库上,对比本文算法与表情识别经典算法的准确率和网络参数量,参与对比实验的经典算法有Alexnet[19]、InceptionV4[20]、Xception[16]。除此之外,还与近几年最新的表情识别算法进行了比较,参与对比实验的最新算法有Parallel CNN[21]、CNN[22]、Attention Net[23]、FaceNet2ExpNet[24]、GAN[25],对比结果如表4所示。Alexnet是2012年ImageNet大赛上的冠军网络,InceptionV4是Inception系列网络中的一个性价比较高的网络,本文网络是根据Xception设计思想进行改进的,这三个经典网络都具有典型的代表性。Parallel CNN方法设计的网络结构具有两个并行的卷积池化结构,分成三个不同的并行路径来提取三种不同的图像特征。CNN方法主要考虑核大小和滤波器数目对分类精度的影响,设计了两种新颖的CNN网络结构来提取人脸表情特征。Attention Net方法将注意力集中在人脸上,用高斯空间表示来进行人脸表情识别。FaceNet2ExpNet方法提出一种基于静态图像训练表情识别网络的新思路,首先提出一种新的分布函数来模拟表达网络的神经元,在此基础上设计了两个阶段的训练算法,先预训练一个表情网络,在正式训练时将全连接层与预先训练的卷积层相结合并共同训练。GAN方法在StarGAN的基础上,改进重构误差,用生成器进行下采样,由某一个人的一种表情可以生成其他不同表情。
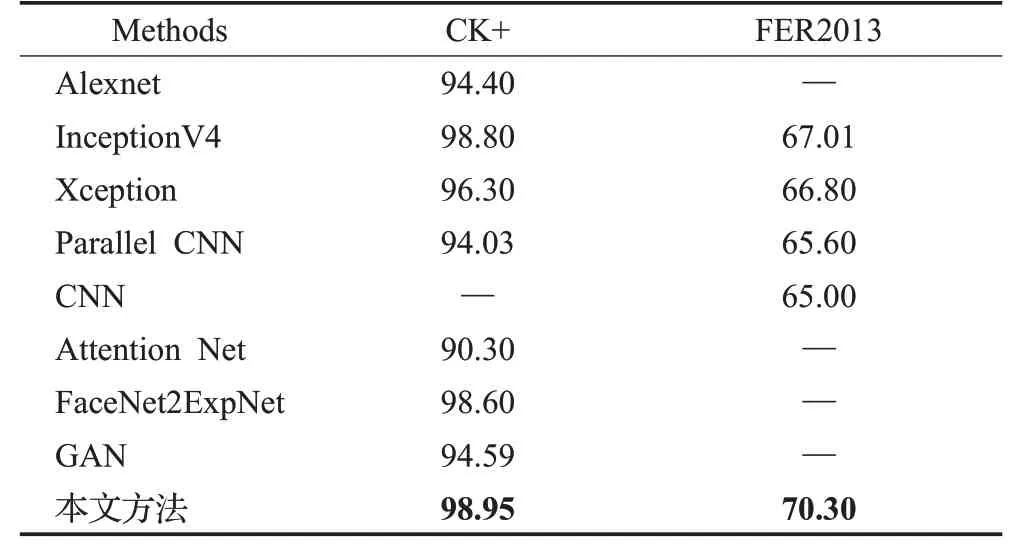
表4 不同方法在数据集上的识别结果Table 4 Recognition results of different methods on dataset %
目前人类在FER2013数据集上的识别率平均约为65%±5%[17],本文模型在CK+数据集上取得了98.95%的识别准确率,在FER2013数据集上取得了70.30%的识别准确率,已经能够达到平均识别的效果。与现有方法相比,本文提出的网络结构在CK+和FER2013数据集上,识别率分别提高了0.15个百分点和3.29个百分点,证明本文模型具有一定的稳定性和泛化能力。CK+数据集的识别率相对FER2013表情数据集整体提高了许多,主要原因是FER2013数据集中存在很多错误标签以及非正常表情图片,图20为FER2013数据集中部分非正常表情示例。

图20 FER2013数据集中非正常表情示例Fig.20 Example of abnormal expressions on FER2013 dataset
此外,为了进一步验证本文网络模型的轻量性,对比了表4中与本文实验结果准确率相近的部分网络结构参数量,如表5所示,本文提出的神经网络结构的参数量是最少的,且与改进前的Xception网络相比,参数少了75%,并且在服务端进行了测试,算法的平均识别速度可以达到137 frame/s,满足实时性(30 frame/s以上)的要求。

表5 不同方法的网络结构参数量Table 5 Network structure parameters of different methods
3 结语
针对目前人脸表情识别准确率不高、网络模型参数复杂等问题,本文提出了一种可以增强可分离卷积通道特征的神经网络,吸取了Xception网络的轻量化设计思想,并且引入了SE模块使得特征提取更加有效。最后在CK+和FER2013数据集上进行了对比实验,各自取得较高的识别率,表明本文提出的人脸表情识别方法能够在降低网络参数量的同时,提高表情识别精度,实现网络模型的轻量化。深度学习需要大量的训练数据支撑,希望在今后的工作中能够尽可能多地收集训练样本,建立自己的数据库,并且在以后的研究工作中将遮挡、人脸姿势变换等问题考虑进去,如何在面临这些问题的情况下还能保证人脸表情识别的准确率将是进一步的研究方向。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
西安邮电大学学报(2020年1期)2020-12-17
计算机系统应用(2019年9期)2019-09-24
动漫星空(2018年9期)2018-10-26
科学与财富(2018年26期)2018-10-24
科技信息·中旬刊(2018年4期)2018-10-21
航空维修与工程(2018年8期)2018-09-10
科教导刊·电子版(2016年23期)2016-10-31
军事运筹与系统工程(2016年4期)2016-07-10
