
基于众包的多楼层定位方法
2022-02-11 13:33章翠君
计算机研究与发展 2022年2期
罗 娟 章翠君 王 纯
(湖南大学信息科学与工程学院 长沙 410082)
随着物联网技术的快速发展和移动智能终端的广泛普及,在市场消费级、企业级应用的需求推动下,人们对于基于位置的服务(location based services, LBS)需求日益剧增,精准的室内外定位和导航服务在日常生活中重要性日渐凸显.室外,全球定位系统(global positioning system, GPS)和北斗定位系统发展成熟可提供准确的位置服务.室内,随着大型建筑高度不断攀升以及建筑物内部结构越加复杂,目前仍缺少成熟的多楼层室内定位技术.无线局域网(wireless local area network, WLAN)的广泛部署和基础设施的完备,基于接收信号强度(received signal strength indication, RSSI)的WLAN指纹的定位技术因其无需额外的硬件设施,具有成本低、部署简单、穿透力强、接入方便等优势,受到广大科研工作者的青睐.
基于RSSI指纹定位方法也称匹配定位法,该方法不需要接入点(access point, AP)位置的先验知识,但需要在离线阶段划分网格,在位置区域中设置固定数量的采样点,记录每一楼层每一网格内的RSSI值,构建“楼层-位置-信号强度”指纹库,如图1所示.传统指纹库的构建过程依赖专业人员的现场勘测,耗时费力.同时由于室内多径效应,无线信号在传播过程中存在波动性,RSSI值需要随着室内物理环境的动态变化而进行周期性的更新,增加了指纹库的维护成本.
众包的基本思想是将冗余繁重的指纹数据采集任务隐式分配给多个普通用户,很大程度上减少指纹采集的时间成本和劳动成本.近年来,智能手机、智能手表等可穿戴式设备通常都内置了惯性传感单元(inertial measurement unit, IMU),配置有气压计、加速度传感器、角速度传感器、陀螺仪等传感器,此类智能设备的广泛普及使得人群比以往任何时候都更容易参与众包.
本文基于众包提出了一种多楼层指纹库构建方法——MCSLoc,根据室内地图构建室内语义拓扑图,利用卡尔曼滤波(Kalman filter, KF)融合智能手机内置加速度传感器和气压计的值进行高度测量,划分传感器数据到各个楼层,利用智能手机内置传感器获取众包用户相对轨迹和RSSI序列,使用隐马尔可夫(hidden Markov model, HMM)模型和轨迹匹配维特比(track matching Viterbi, TM-Viterbi)算法将用户相对轨迹和室内语义地图相匹配,从而获取轨迹绝对路径为RSSI标注物理位置,构建多楼层指纹库.

Fig. 1 Traditional fingerprint database construction process图1 传统指纹库构建过程
本文的主要贡献包括3个方面:
1) 提出一种“分段式”适用于众包场景的用户轨迹获取方法,设计拐角检测算法,以拐角划分轨迹子段,动态获取用户步长,消除众包用户步长异质以及智能手机内置传感器航向漂移问题;
2) 将隐马尔可夫模型应用到众包用户轨迹匹配,提出改进的维特比地图匹配算法TM-Viterbi,相邻节点之间加以公共的观测状态限制,保证匹配后的轨迹节点序列在语义地图上的节点连续性;
3) 提出一种RSSI众包指纹位置标记方法,利用时间戳为无标签RSSI序列标记楼层标签以及物理位置标签,获取用户轨迹绝对坐标.
1 相关工作
众包概念提出后,越来越多的研究学者致力于以众包的方式构建RSSI指纹库,按照用户的参与程度,众包技术可以分为主动众包和被动众包.主动众包要求参与者主动贡献数据信息.Yang等人提出的FreeLoc系统要求参与者贡献记录的指纹数据,并将位置标签上传到服务器.Zheng等人通过用户主动提供的图像数据、WiFi样本以及IMU感应数据构建视觉导航系统Travi-Navi.相比于主动众包,与智能手机内置IMU相结合的被动众包技术应用更加广泛,被动众包用户通常是无意识或弱意识参与,对系统的干预较少.LiFS系统利用用户的移动性,无需人工现场勘测实现房间级别的定位,该系统是国内基于众包定位的突破,但是定位精度不高.PiLoc利用智能手机内置IMU,根据行人航位推(pedestrian dead reckoning, PDR)算法估计用户轨迹,将用户位移和RSSI信号相结合,实现WiFi指纹库构建,定位精度较高,但系统需要用户初始位置先验知识.MPiLoc在PiLoc的基础之上,通过气压传感器对用户轨迹进行聚类划分楼层,构建多楼层指纹库.
有研究表明,将用户轨迹与室内地图匹配可以显著提高定位系统的性能,基于HMM的室内定位已经被证明为一种有效的方法.如基于HMM的室内地图匹配定位、基于HMM的WiFi信号光线跟踪3维路径匹配定位、基于HMM和网格的贝叶斯联合跟踪室内移动终端定位.随着IMU的发展,出现了HMM与惯性传感器数据融合定位,该类方法通常面临HMM状态数过大,算法复杂度较高问题.为减少状态数,Lu等人以拐角特征作为PDR轨迹上下文,使用HMM将其与数据库中的上下文相匹配,获得行人位置.该方法能够快速确定行人的起始点,具有良好的稳定性和鲁棒性.
本文结合众包和HMM技术,采集众包用户跨楼层走动时的智能手机内置传感器信息,提出分段式用户轨迹获取方法获取用户相对轨迹,建立HMM模型,利用TM-Viterbi算法将用户轨迹与地图匹配,构建多楼层指纹库,MCSLoc可以去除指纹库构建阶段的专业人工勘测,无需众包用户初始位置先验知识.
2 研究框架
MCSLoc方法研究架构图如图2所示,系统由离线阶段和在线阶段2部分组成.离线阶段构建多楼层指纹库,为在线阶段用户的位置请求提供服务,本文的主要工作在于离线阶段的基于众包的多楼层指纹库的构建,下面将具体描述这部分关键过程.

Fig. 2 MCSLoc method research framework图2 MCSLoc方法研究框架
2.1 地图预处理
通过读取JPG形式的室内平面图,获取地图坐标和属性信息,采用“霍夫变换+Harris角点检测”算法将室内平面图转换为由节点和路段构成的语义地图G
(Q
,V
),其中路段表示室内地图可行走区域的主要路径,V
={v
,v
,…,v
}表示路段集;节点表示路径的拐角点以及路径的端点(起始点和终止点),Q
={q
,q
,…,q
}表示节点集.
()描述语义地图如图3所示: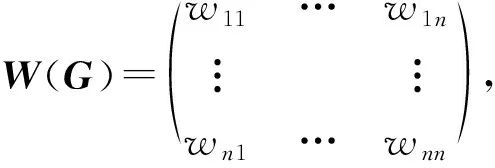
(1)
其中,w
表示节点q
到节点q
之间的位移长度,即路段长度,当节点q
和q
是相同节点,w
=0,当节点q
和q
不相邻或者不在一条直线上,w
为无穷.n
表示节点的数量,m
表示路段的数量.

Fig. 3 Indoor floor plan and semantic map图3 室内平面图及语义地图示意图

Fig. 4 Process of segmented trajectory acquisition method图4 分段式轨迹获取流程
2.2 分段式轨迹获取过程
轨迹获取即是利用智能手机内置传感器获取数据计算用户运动轨迹,设计了一种分段式众包用户轨迹获取方法,其流程如图4所示.众包用户智能手机后台采集的传感器数据由以下五元组组成:P
=(t
,dirc
,rss
,acc
,pres
),分别有时间戳、陀螺仪方向数据、RSSI序列、加速度值、气压值.主要分为3个步骤:传感器数据所属楼层划分、拐角检测、子段长度获取.2.2.1 传感器数据所属楼层划分
由于众包参与者为跨楼层行走,采集的传感器数据为多楼层连续型数据,按照分层思想,首先将传感器数据划分到各个楼层.采用文献[15]中提出的高度测量方法(Kalman filter and floor change detection, KF_FCD)划分传感器数据,即利用KF融合智能手机内置加速度传感器和气压计的值进行高度测量,利用楼层变化检测算法对KF输出的值进一步修正,根据实时测量的高度和时间戳判断传感器数据所属楼层.
2.2.2 拐角检测
根据传感器数据估计众包用户在相应楼层的轨迹.航向角的大小反映了行人行走的方向,航向角的偏移导致的误差会随着时间累积,但是短时间内航向角偏移较小,即行人轨迹的行走方向相邻2步之间角度的误差较小.假设众包用户在室内沿直线行走且拐弯呈直角,由室内地图的构造可知,用户在拐弯处有左拐或右拐.即可通过航向角获知用户是否拐弯.据此,设计了一种拐角检测算法检测轨迹拐角.设定角度变化允许的上下限阈值分别为thMin
,thMax
,其中thMin
为陀螺仪允许的最大角度误差,通过经验将其设为50°,thMax
为相邻2步角度变化最大值,根据经验将其设为180°.
算法具体步骤算法1所示,输入陀螺仪角度数组ω
,其中ω
[i
]为第i
步的行走角度,算法时间复杂度为O
(n
).
算法1.
拐角检测算法.输入:陀螺仪角度数组ω
、阈值thMin
,thMax
;输出:拐角方向数组Ψ
(1代表右拐、-1代表左拐).
① fori
=1:n
-2 do②nextS
=abs(ω
[i
-1]-ω
[i
]);③tnextS
=abs(ω
[i
]-ω
[i
+1]);④ if (nextS
>180°)∨(tnextS
>180°)⑤next
=360°-nextS
;tnext
=360°-tnextS
;⑥ end if
⑦/
*比较角度变化值nextS
和tnextS
与阈值的大小*/
if (nextS
>thMin
∧nextS
<thMax
∧tnextS
>thMin
∧tnextS
<thMax
)⑧ if (ω
[i
+1]-ω
[i
]>0)/
*右拐*/
⑨Ψ
[i
+1][0]=ω
[i
+1];⑩ end if





.
2.
3 子段长度获取子段为拐角检测算法检测到一条轨迹相邻2个拐角间的距离,n
个拐角即可划分n
-1条子段.
那么轨迹D
可由m
条子段组成,D
={d
,d
,…,d
},获取各子段的长度d
(1<j
<m
=n
-1),即可得到众包用户预估轨迹.
根据拐角时刻时间戳获取相邻拐角时间间隔内传感器数据,以此估计各子段长度.
研究表明,行人在行走过程中,加速度具有周期性类正弦波特性,波峰检测法根据此特性对波形的峰值波谷进行计数,可有效估计行人的步频.
此外,也可有效估计行人步长,为减少行人运动状态影响,选择合加速度作为特征值.
公式为
(2)
其中,a
(t
)表示时刻t
的合加速度,a
(t
),a
(t
),a
(t
)分别表示3轴加速度传感器在X
轴、Y
轴和Z
轴的加速度,g
表示重力加速度,其值为9.
81 m/s.受智能手机内置传感器本身精度的制约以及行人身体抖动等外部因素的影响,加速度传感器采集的数据通常含有噪声.有限脉冲响应(finite impulse response, FIR)数字滤波器为高保真低通滤波器,它可以同时满足幅频特性和线性相位特性.为了去除高频噪声降低误检率,采用FIR数字滤波器最优化设计方法设计低通滤波器,其中,采样频率f
=500 Hz,期望幅频特性的频率向量=(4,0,2,3,500)/f
,幅值向量=(1,1,0,0),加速度传感器合加速度滤波前后对比如图5所示.
低通滤波后的伪波峰基本消除,噪声干扰大大减少.
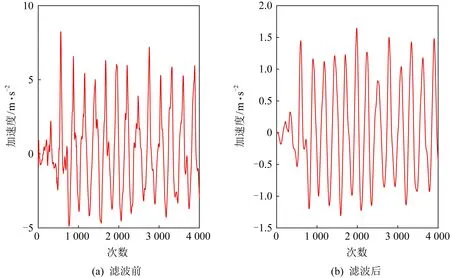
Fig. 5 Contrast before and after acceleration FIR low pass filtering图5 加速度FIR低通滤波前后对比图
目前常用的行人步长估计方法有:常数步长模型、运动机械模型、线性模型、非线性模型以及人工智能模型等.
其中非线性模型通常在步频与步长之间建立相应的非线性估计模型,该类模型仅与加速度、速度等特征变量有关,受行人自身身高、体重、腿长等因素影响较小.
结合更适合众包场景的非线性模型Weinberg算法动态估计用户每一步步长.
子段长度公式为
(3)
其中,1≤i
≤n
,d
表示子段的长度,S
表示本子段内第i
步的步长,K
为模型系数,取值为0.
42,a
max和a
min分别表示步频检测本子段第i
步中得到的最大加速度值和最小加速度值,n
表示本子段内的行走步数.
2.3 HMM模型
HMM模型是关于时序的概率模型,可由=(,,)表示.
应用于本场景的Markov过程即是将未知起点的众包用户轨迹与语义地图匹配获取绝对轨迹过程.
在地图匹配问题中,语义地图的节点作为隐藏状态;语义地图的路段作为观测状态;智能手机内置传感器数据获取的众包用户轨迹子段的长度序列视为观测序列.
根据HMM模型原理,地图匹配过程遵循2个规则:1)任意时刻的隐藏状态值依赖于前一时刻,即每个节点之间转移的可能性为状态转移概率;2)任意时刻的观测状态只依赖当前时刻的隐藏状态.
假设Q
={q
,q
,…,q
}是隐藏状态的集合,即语义地图节点集合,N
表示隐藏状态数;V
={v
,v
,…,v
}是观测状态集合,即语义地图中路段集合,M
表示观测状态数.
图6是以图2为对象建立的HMM模型示意图.P
(q
|q
)表示转移概率,即每一时刻节点之间转移的可能性,P
(v
|q
)表示发射概率,即节点下观测到路段的概率.
表示初始时刻隐藏状态的概率向量.
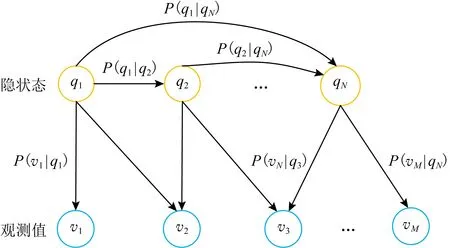
Fig. 6 Hidden Markov model schematic diagram图6 HMM示意图
由于在未知起点下,用户在任意一个节点位置的概率相等,因此.

(4)
=[a
]×表示节点之间转移概率矩阵,由转移概率组成,定义与节点q
处于一条路段上的节点的集合为Ψ
,集合Ψ
的节点数量之和为k
.
状态转换概率计算公式为
(5)
表示发射概率矩阵,即在某个节点下观测到某个路段的概率.
将与节点直接相连的路段作为该状态下的可观测值.
定义节点q
可观测的路段的集合为φ
,集合φ
中路段的数量之和为z
.
发射概率公式为
(6)
2.4 TM-Viterbi地图匹配算法
Viterbi算法是HMM模型求解预测问题的算法之一, 已知模型λ
=(,,)和观测序列O
={o
,o
,…,o
},求对给定观测序列条件概率最大的状态序列,其基本思想是基于动态规划寻找最优路径的隐藏状态序列.
MCSLoc利用TM-Viterbi算法求解语义地图中与众包用户轨迹最相似的路径,即输入一条轨迹的子段长度序列O
=D
={d
,d
,…,d
},求语义地图中最有可能出现该序列的节点序列.
TM-Viterbi算法对传统Viterbi算法的改进主要有:1)传统的Viterbi算法依赖概率矩阵,未考虑节点序列的物理连续性.因此,本文对节点的转移加入物理约束,即寻找最优路径时,本节点与下一个节点加以公共的观测状态限制,利用路段关联节点.2)通过传感器获取的用户轨迹子段长度与真实路段长度存在误差,即存在观测子段长度d
不属于观测状态集合V.
为获取该类观测值的发射概率,使用高斯函数来表达误差因素的发射概率.
计算公式为
(7)
其中,μ
表示路段集合φ
中与子段d
绝对值最小的路段长度,δ
表示误差,取值为(μ
-1)/
4.
导入变量θ
和φ
,变量θ
(i
)为时刻t
概率最大值,变量φ
(i
)为时刻t
所有单个路径中概率最大的路径的第t
-1个节点.
TM-Viterbi算法步骤如算法2所示.传统Viterbi算法的时间复杂度为O
(N
M
),N
表示隐藏状态数,M
表示观测状态数,TM-Viterbi算法对节点的转移加以约束,在寻找最佳路径时,下一节点需为上一节点的邻居节点,因此其TM-Viterbi算法时间复杂度为O
(NMγ
),γ
表示上一节点的相邻节点数量.
分析可知,改进的TM-Viterbi算法时间复杂度明显降低,且地图匹配过程为离线阶段,运行时间可容忍性强,时延要求低,该时间复杂度满足需求.
算法2.
TM-Viterbi算法.输入:HMM模型λ
=(,,)、子段序列O
={d
,d
,…,d
};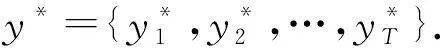
θ
(i
)=b
(d
),φ
(i
)=0,i
=1,2,…,N
;/
*初始化*/
② fort
=2:T
do③ ifd
∉V
then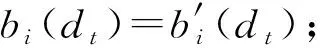
/
*误差因素发射概率*/
⑥ ifb
(d
-1)>0,i
=1,2,…,N
;/
*判断节点是否有连接*/
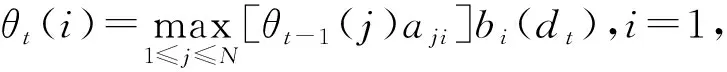
N
;/
*递推计算最大概率*/
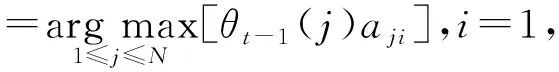
N
;/
*记录路径*/
⑨ end if
⑩ end for
/
*终止*/
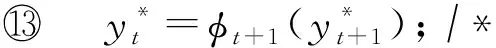
/
*返回最优节点序列*/
2.5 多楼层指纹库构建
地图匹配获取的节点序列可视为轨迹拐角序列, 由于语义地图节点的绝对坐标已知,因此可快速获取轨迹的起始位置、终止位置以及拐角绝对位置坐标.本文设置WiFi接收器采集RSSI数据的频率为1 Hz,设a
(x
,y
)和b
(x
,y
)分别为轨迹的2个相邻拐角坐标,t
和t
分别为用户的智能手机记录经过拐角的时间戳(单位为s),假设众包用户匀速行走,那么RSSI的位置标签Crss
(x
,y
)为
(8)
其中,t
=1,2,…,t
-t
.
由此,即可为每一条RSSI值序列标记位置标签,一条RSSI指纹构成:[F
,Crss
(x
,y
),RSSI
,RSSI
,…,RSSI
],其中F
表示楼层,n
表示AP的数量,RSSI指纹汇总即可构建多楼层指纹库.
2.6 在线定位
在线阶段定位过程包括待定位点所在楼层判别与2维坐标获取.定位过程采用基于多分类线性判别分析(linear discriminant analysis, LDA)的楼层判别方法判断用户所在楼层,楼层判别精度为99%~100%;利用位置指纹加权k
最近邻(k
weighted nearest neighbor, WKNN)算法获取最终位置坐标,其中k
=4.具体描述为:根据多分类LDA的楼层判别模型,分别对楼层和AP属性进行两两分组,利用LDA方法求出各分组的广义瑞利商J
最大化的目标值,根据分组中的最大值J
选择最优分组进行两两楼层的判定,利用投票法选择最终的楼层号,确定用户所在楼层F
. 2维坐标获取阶段,采集待定位点RSSI指纹序列,在多楼层指纹库F
层指纹中选取与待定位点RSSI指纹相似程度最高的k
个指纹的位置坐标,并根据相似程度赋予指纹位置坐标相应权值,最终加权平均得到待定位点2维位置坐标(x
,y
).

Fig. 7 Plan of experimental building图7 实验平面图
3 实验结果与分析
为了评估MCSLoc的性能,实验在真实3层实验楼建立实验场地,实验楼3D平面图如图7所示,总面积4 800 m,其中1楼楼层高4.3 m,2楼楼层高2.64 m,3楼楼层高2.48 m.由室内平面图转换的语义地图如图8所示,共158个节点.使用了4种不同类型的安卓智能手机进行实验,分别是:小米5 s、小米8、华为Mate 20 Pro、华为Mate 30 Pro.实验过程中,为了尽可能模拟众包场景,众包参与者手持智能手机随机从不同的位置(不指定起始位置)开始行走.采集10位众包参与者使用不同型号手机的80条用户轨迹数据.其中加速度传感器的采集频率为250 Hz,气压计的采样频率为100 Hz,陀螺仪和WiFi接收器的采样频率为1 Hz,实验区域记录可检测到15个AP.
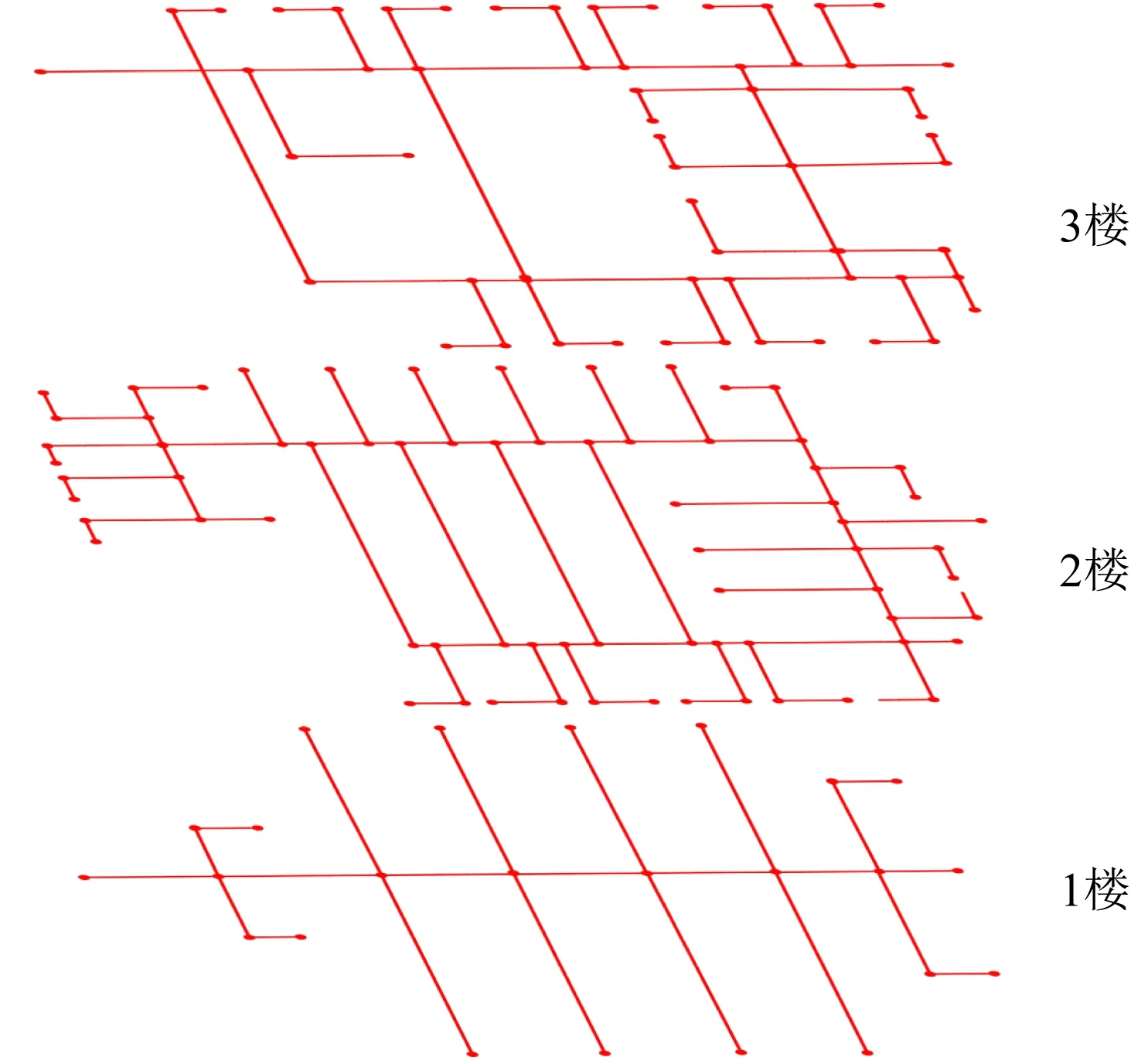
Fig. 8 Semantic map of experimental building图8 实验楼语义地图
3.1 传感器数据所属楼层划分
由2.2节可知,MCSLoc利用轨迹高度和时间戳划分传感器数据到所属楼层.一条轨迹的高度测量情况如图9所示,虚线为真实高度,实线为KF_FCD方法测量高度,由图9可知,KF_FCD方法测量的高度几乎与真实高度一致,误差图如图10所示,平均误差为0.11 m,最大误差为0.31 m.由于实验大楼楼层高度已知,1楼高度范围为0~4.3 m,2楼为4.3~6.94 m,3楼为6.94~9.42 m.根据众包参与者每一时刻测量的高度所属的楼层范围判定每时刻所属楼层,结合时间戳划分加速度传感器、陀螺仪以及WiFi接收器的数据到各个楼层.需要说明的是,实验未对楼梯之间的信号进行处理,因此上下楼过程中的采集的传感器数据为无用数据,已将其剔除.
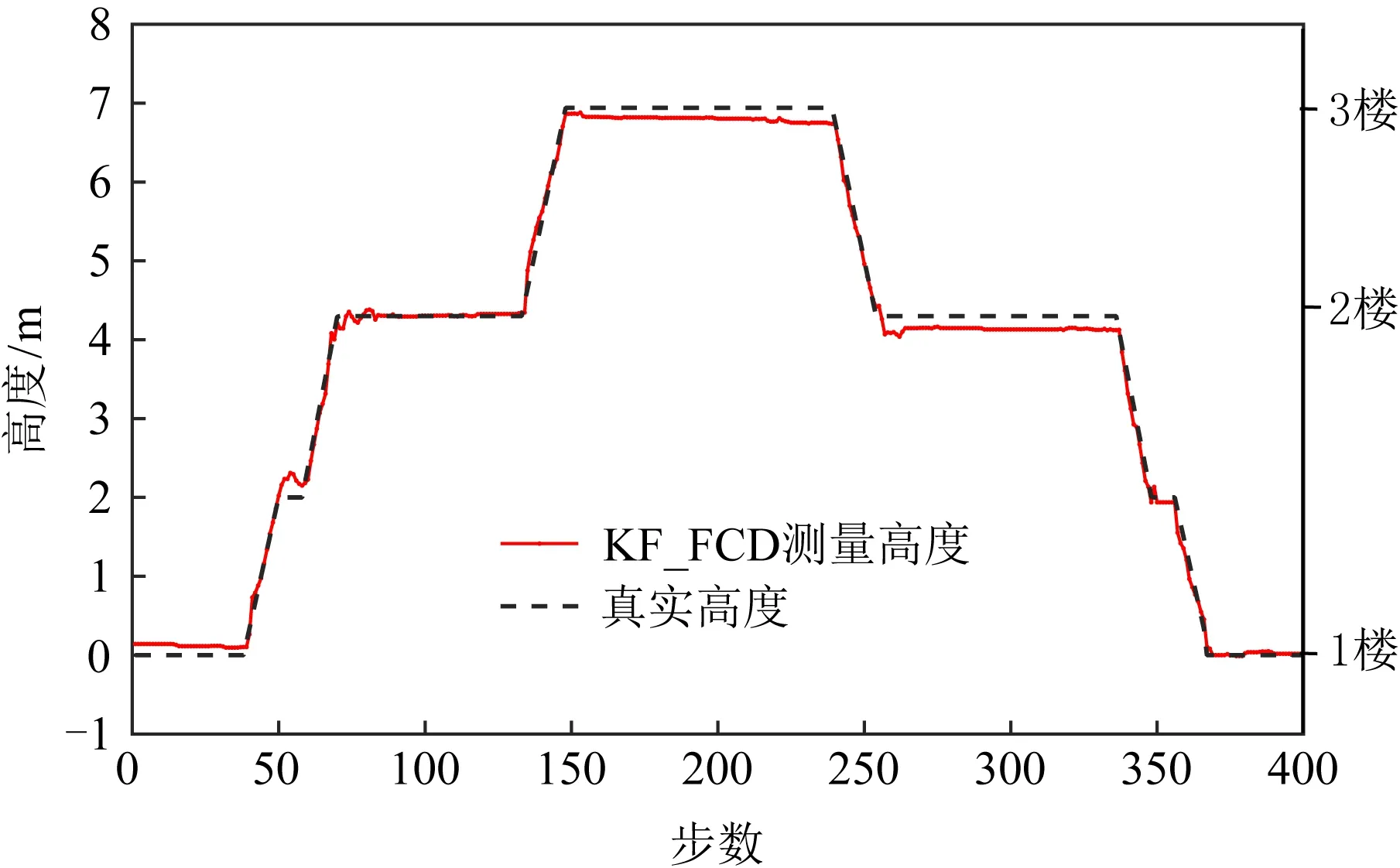
Fig. 9 Height measured by KF_FCD method图9 KF_FCD测量高度
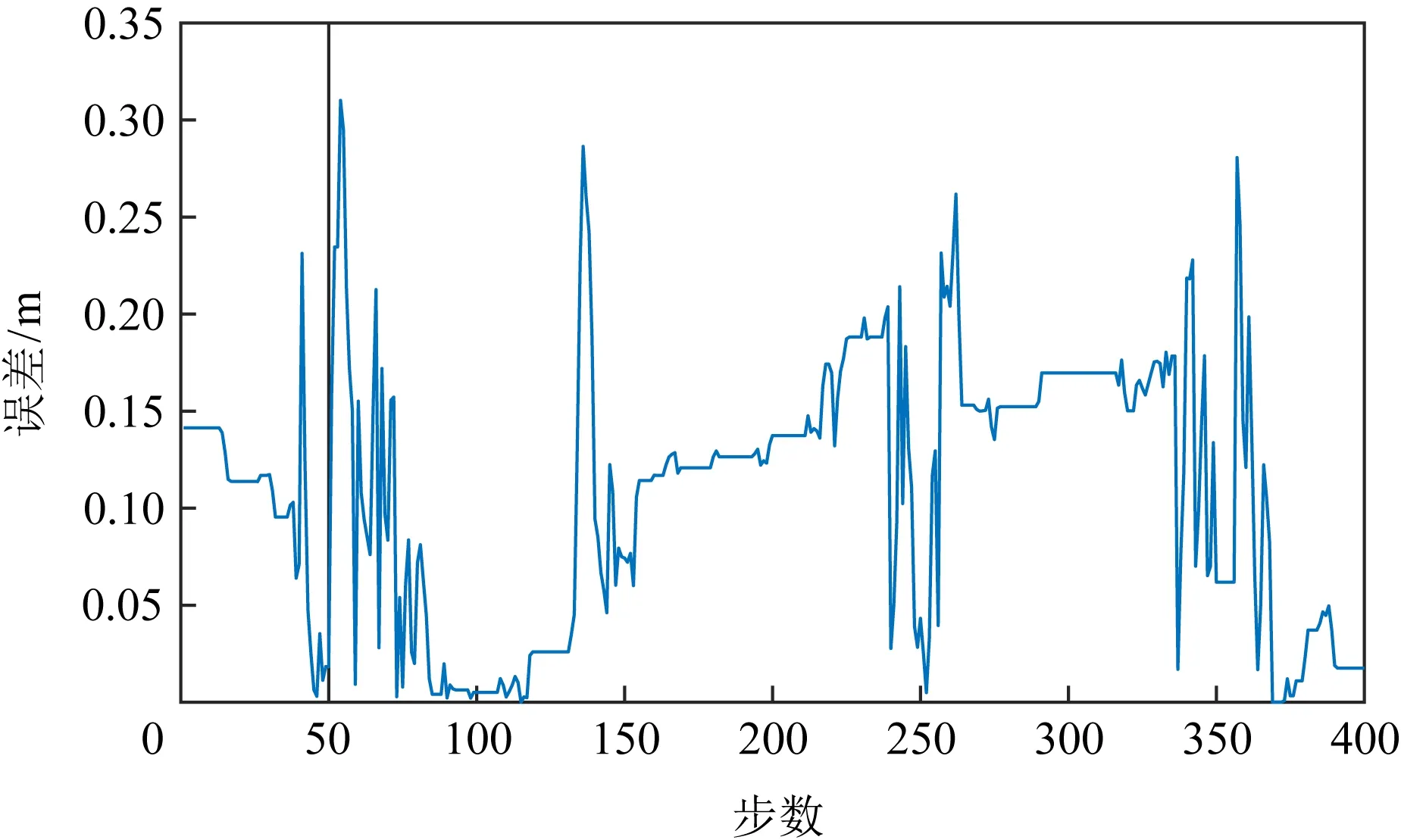
Fig. 10 Height error measured by KF_FCD method图10 KF_FCD高度测量误差
3.2 拐角检测算法与子段分析
实验选择代表性轨迹进行分析说明,拐角检测算法检测到9个拐角,即可划分10个子段,利用拐角检测算法获取的拐弯方向以及利用加速度值获取的步数、子段长度与真实值对比如表1所示:

Table 1 Comparison of Measured Value and Real Value of Sub Segment
该轨迹中,实际总步数为233步,检测总步数为236步,根据每一子段的步数的误差,步数检测精度为97%;该层轨迹总长度为90 m,测量总长度为91.27 m,子段长度平均误差为0.905 m,拐弯方向检测精度为100%.
3.3 TM-Viterbi地图匹配算法分析与定位精度分析
为验证TM-Viterbi地图匹配算法性能,实验分别获取20条、40条、60条、80条轨迹的子段序列,将传统的Viterbi算法与TM-Viterbi算法进行对比.匹配精度如图11所示.当轨迹条数在40~80条时,传统的Viterbi算法匹配精度稳定在66%左右,而TM-Viterbi算法匹配精度稳定在85%左右,精度将近提高了20个百分点.由图11可知,当轨迹条数足够多时,TM-Viterbi算法可以获得足够高的地图匹配精度.

Fig. 11 Accuracy comparison of Viterbi map matching algorithm图11 Viterbi地图匹配算法精度对比
为验证构建的多楼层指纹库的性能,实验采集了400个不同楼层不同待定位点的RSSI值进行精度分析.定位过程包括基于多分类LDA楼层判别与基于WKNN算法的2维坐标获取.由图12可知,平均定位误差为1.87 m,82%的定位误差在3 m以内,91%定位误差在5 m以内,定位误差主要是地图匹配算法误差导致的多楼层指纹库“指纹-位置”根本性错位偏差.由于MCSLoc指纹库构建方法可操作性强、成本低,可实现指纹库的定期更新,有效减少室内环境变化导致RSSI指纹的不稳定波动性对定位精度的影响,分析可知,构建的基于众包的多楼层指纹库可以满足室内基本定位需求.
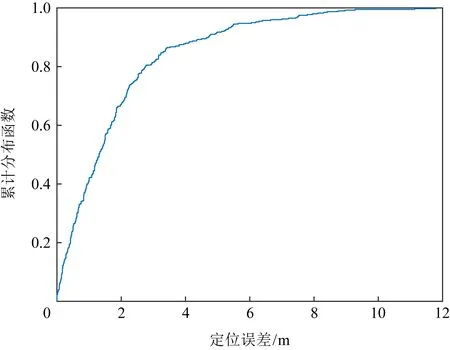
Fig. 12 Cumulative distribution function of location error in multi-floor fingerprint database图12 多楼层指纹库定位误差累积分布图

步数检测精度∕%子段长度平均误差∕m拐弯方向检测精度∕%970.905100
3.4 系统对比
本文将提出的基于众包的多楼层定位方法-MCSLoc从定位精度、实验面积、是否需要室内地图以及是否为多楼层4个方面与其他前沿的基于众包的WiFi指纹定位方法进行了比较.如表3所示:
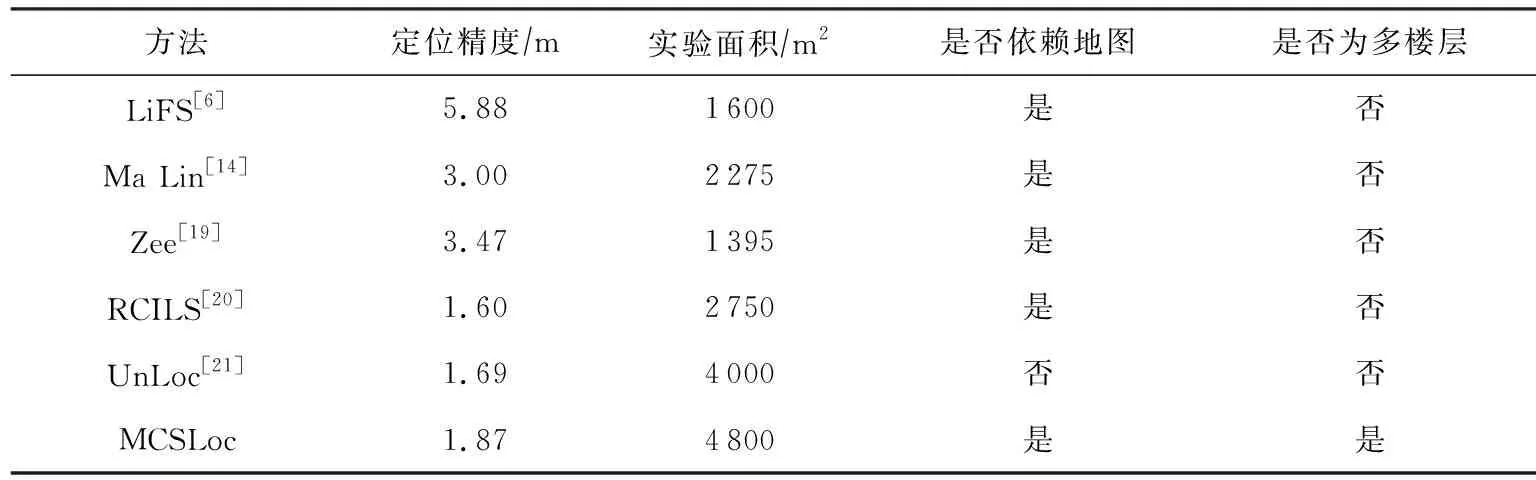
Table 3 Comparison of System Performance表3 系统性能对比
LiFS达到的是房间级别的定位精度,MCSLoc的定位精度明显优于LiFS系统.Zee利用拓扑图和粒子滤波限制行人轨迹,但粒子滤波比较耗时,不适合运行在计算能力有限的智能手机平台.定位精度与实验面密切相关,与RCILS和Ma等人方法相比,MCSLoc部署范围与实验场景面积相之较大,结果更具说服力;UnLoc定位精度较高,但是需要在室内环境中部署一定数量的锚节点,这必然会增加定位成本.除此之外,MCSLoc针对多楼层场景,更加符合当前市场定位需求,应用范围更广.
4 结束语
本文基于众包提出了一种融合智能手机传感器数据的多楼层指纹库构建方法MCSLoc,根据行人室内行走特点,设计分段式轨迹获取方法,建立HMM模型,设计改进的Viterbi算法、TM-Viterbi算法,将用户轨迹与语义地图匹配,获取绝对位置,有效构建多楼层指纹库.与其他经典的基于众包的定位方法相比,本文提出的方法效率更高、成本更低、适用范围更广.实验结果表明,MCSLoc可达到米级定位精度,具有良好的稳定性.
未来,进一步的研究包括:设计众包参与者运动状态检测算法,识别参与者快走、慢走、跑步等运动状态;考虑众包参与者智能手机的异质性;将语义地图的主路径抽取模式转成网格化抽取模式,拓展应用场景至大型空旷室内场所.
作者贡献声明
:罗娟提出研究思路和创新点,进行论文模型方法设计和文字修改;章翠君设计研究方案,进行实验和数据分析,起草论文;王纯协助进行实验和论文修订.猜你喜欢
中学生博览·文艺憩(2022年4期)2022-06-21
散文诗世界(2021年12期)2021-12-17
福建中学数学(2021年1期)2021-02-28
小资CHIC!ELEGANCE(2021年44期)2021-01-11
考试与评价·七年级版(2020年4期)2020-10-23
读者(2019年2期)2019-01-05
课堂内外(小学版)(2017年3期)2017-04-15
美文(2017年4期)2017-02-23
小雪花·初中高分作文(2016年5期)2016-05-14
初中生·作文(2004年5期)2004-05-26
