
基于FPGA的通用卷积神经网络识别系统研究
2022-02-14 12:13赵不贿徐雷钧
自动化仪表 2022年1期
赵 凡,白 雪,杨 涛,赵不贿,徐雷钧
(1.江苏大学电气信息工程学院,江苏 镇江 212013;2.镇江芯智慧电子科技有限公司,江苏 镇江 212001)
0 引言
卷积神经网络的概念在19世纪60年代被提出。1998年,Yann Lecun提出了新的网络框架LeNet-5[1],并在分类任务上得到很好的效果。Hinton等在Imagenet上提出的Alexnet[2]网络,以其优异的识别效果,使卷积神经网络受到学术界极大关注。随后,超分辨率测试序列(visual geometry group Network,VGGNet)[3]、GoogleNet[4]、深度残差网络(deep residual network ResNet)[5]、YOLO[6]等新的神经网络模型不断被提出,使得图像识别的精度越来越高。如今,卷积神经网络已经被应用在工业、农业[7-12]、无人驾驶、医疗等各个领域。
然而,由于新型网络模型在网络层数上的增加,导致中央处理器(central processing unit,CPU)运行速度慢和图形处理器(graphics processing unit,GPU)功耗高的缺点开始显现。而专用集成电路(application specific integrated circuit,ASIC)在网络模型的通用性上表现较差,且造价昂贵。为了解决这些问题,近年来出现了许多利用现场可编程门阵列(field programmable gate array,FPGA)来加速卷积神经网络的研究。文献[13]~文献[17]利用FPGA设计了卷积神经网络加速器,实现并行化的卷积神经网络,取得了不错的效果。
1 卷积神经网络原理
卷积神经网络主要由输入层、卷积层、池化层、全连接层和输出层等构成。卷积神经网络通过对图像进行卷积和池化运算实现特征的提取,最终识别图像分类。
卷积神经网络的输入层可以是一维数据,也可以是多维数据。以彩色图像为例,由于图像由R、G、B这3个通道组成,所以输入层将会是三维数组。卷积层的作用主要是提取输入图像的特征。卷积层包括卷积核和激励函数等。输入特征的每个神经元会有1个权值系数。当卷积核在输入特征图上遍历时,权值会和卷积核的系数进行卷积运算。每种网络都可以有不同的卷积核大小、步长和卷积层数。相对来说,网络越复杂,则卷积层数越多。池化层的作用主要是对卷积后的输出特征进行再次提取和过滤,使输出特征图的神经元大幅减少。全连接层相当于传统神经网络中的隐含层,通过对输出特征的神经元和全连接层的神经元进行全连接实现非线性组合运算,最终由输出层输出结果。卷积神经网络框图如图1所示。

图1 卷积神经网络框图Fig.1 Block diagram of convolutional neural network
2 卷积神经网络的FPGA设计
2.1 FPGA的系统设计
目前,利用CPU和FPGA结合的多核异构系统进行硬件加速,已成为一种行之有效的方法[18]。基于FPGA的卷积神经网络识别系统总体结构如图2所示。

图2 基于FPGA的卷积神经网络识别系统总体结构图Fig.2 Overall structure diagram of convolutional neural network recognition system based on FPGA
该FPGA片上带有多处理器片上系统(multiprocessor system on chip,MPSOC),包含处理系统(processing system,PS)和可编程逻辑(programmable logic,PL)两个部分。在FPGA的PL侧设计了卷积、池化、激活函数、缩放函数、像素值归一化以及可配置直接内存访问(direct memory access,DMA)模块,而FPGA的PS负责主控系统以及PL侧的参数配置。此外,利用视频直接内存访问(video direct memory access,VDMA)和挂载在PS侧的以太网模块,可实时显示CMOS摄像头采集的图像。
2.2 数据量化及输入层归一化
在软件中实现卷积神经网络的方法是采用浮点数进行运算。然而,在硬件中实现浮点运算不仅需要消耗大量的数字信号处理器(digital signal processor,DSP)资源,而且会导致大量功耗。一旦网络层数过多,需要的乘法器资源增多,可能在算法实现过程中出现时序问题或者功耗过高。因此,将浮点数量化成定点数是很有必要的。文献[19]提出将64 bit的浮点数量化为16 bit的定点数,最终的试验结果是将FPGA与CPU的误差精度控制在3%以内。
值得注意的是,相关研究者仅关注了运算过程的量化,而输入图像归一化这部分量化过程大多被忽略。为了进一步提高识别速度与精度,本设计采用查表法对数据的归一化和量化进行处理。将0~255间的像素量化后的结果存入RAM,并以摄像头采集的像素值作为索引获取量化后的值,最终仅消耗512 KB的片上缓存。
2.3 图像预处理
FPGA图像缩放如图3所示。

图3 FPGA图像缩放框图Fig.3 FPGA image scaling block diagram
为了满足网络模型对输入图像尺寸的要求,需要设计缩放模块[20]。同时,为了减少图像送入网络的时间,本设计采用FPGA的逻辑资源实现双线性差值缩放算法。该差值方法与网络模型训练时保持一致,可降低图像尺寸对识别准确率的影响。通过编写可配置的DMA、片上缓存和缩放坐标生成模块,可实现FPGA缩放。与直接利用FPGA的片上系统相比,纯逻辑缩放的时间约为系统侧缩放的六分之一。
2.4 双卷积并行运算
卷积神经网络的计算量集中在卷积层和池化层两部分。其本质上是由大量的矩阵乘法和加法等数学运算构成的。卷积层的一般形式[21]如式(1)所示:
(1)
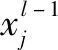
在通用处理器上实现这两个过程需要逐步遍历整个特征图,串行进行乘法和加法。而对于图像处理,FPGA可利用其并行优势,实现同一时钟下多通道的同时计算。其主要思想是通过将特征图输入通道分块合并为大位宽的数据,并调用乘法器计算出每个子块的结果。然而,某些卷积核多、网络层数深的网络模型不能充分利用FPGA的高速接口通道。本试验为了最大化利用FPGA的并行特性,在对特征图进行分块时:若卷积核尺寸为奇数,则使用单卷积;若卷积核尺寸为偶数,则将同时使用2个卷积模块。由于单卷积包含在双卷积模块中,本文以双卷积模块为例进行详解。卷积并行化如图4所示。
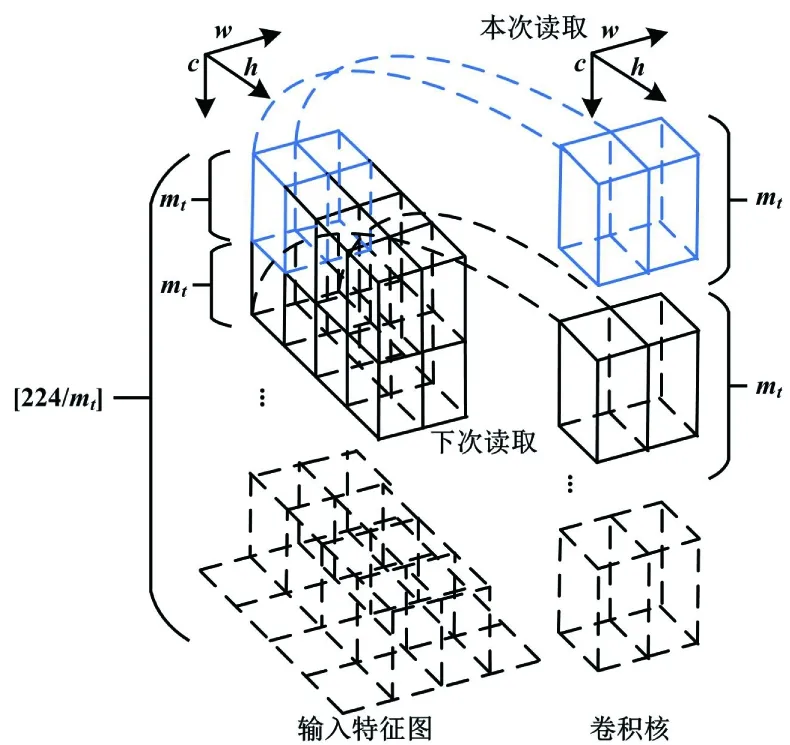
图4 卷积并行化示意图Fig.4 Schematic diagram of convolution parallelization
图4中,c、w、h分别为输入特征图的通道、宽度和高度方向。对于1个224×224×3的图像,从宽度和高度方向分块,需要考虑到特征图尺度的奇偶性。为了减少复杂度,本设计选择沿图像通道方向将其进行子块划分。
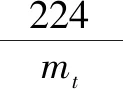
双卷积的子块具体运算过程中,子块一和子块二的数据分别来自2个高性能接口通道。2个子块计算过程相同且同时刻进行。子块卷积运算如图5所示。

图5 子块卷积运算示意图Fig.5 Schematic diagram of sub block convolution operation
特征图的16mt位数据与权重的16mt位数据对应乘加,即可求出双卷积子块的值。单个子块的计算式如式(2)所示。
(2)
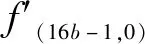
2.5 池化层流式处理
对于池化层的并行化处理,文献[22]利用高层次综合(high-level synthesis,HLS),把5个for循环综合成FPGA可用的池化层IP。HLS作为XILINX公司新推出的高效设计工具,可将C/C++语言转化为硬件描述语言描述的寄存器转换层(register-transfer level,RTL),而且开发周期短。不过,由于需要将IP挂载在高级可扩展接口(advanced extensible interface,AXI)总线上,工具自动转化后的IP突发传输效果不佳,使其对数据方向寄存器(data direction register,DDR)的读写操作变慢,对传输时间有较大影响。因此,本设计采用手写RTL来实现池化运算模块。
池化并行化计算如图6所示。

图6 池化层并行化计算示意图Fig.6 Schematic diagram of data pooling layer parallelization computation
图6(a)为数据读取的过程。左侧为当前读取的数据,沿着c(高度)方向将mt(单个数据为n比特)个数据存入片内存储单元。右侧为当前数据读取完成后,执行下次读取,沿着h(高度)方向将第一行mt×n×hbit的数据全部存储。图6(b)为池化层数据具体的存储方式。若为最大池化,则将mt个数据读出后与下一行的mt个数据进行比较,并将最大值存入该存储单元,直至缓存的行数等于池化的高度。若为均值池化,则将缓存的数据读出后与下一行相加,作同样计算,直至缓存的行数等于池化的高度。整个池化层复用同一块缓存空间,以减少缓存的使用。
2.6 激活函数Softmax改进
Softmax分类器原理较简单,是一个概率计算过程[23]。Softmax函数主要应用在神经网络的输出层。它将整个网络的输出值归一化到(0,1)之间。Softmax公式如下:
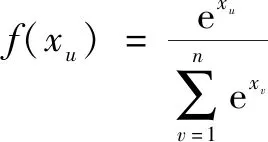
(3)
式中:xu、xv为激活层输入的参数,u、v为序号;n为激活层的输入总个数。
在分类、检测等问题上,对输出层进行Softmax操作。此时,可以将Softmax的结果看作事物出现的概率。对于Softmax的FPGA处理,采用相关算法予以实现,包括坐标旋转数字计算机(coordinate rotation digital computer,CORDIC)算法、多项式拟合法、分段拟合法、查表法。CORDIC算法计算时间长,精度不高。多项式拟合法消耗的资源与阶数相关。分段拟合法效果较好,但较为繁杂[24]。查表法精度高、速度快。文献[25]通过构建基底查表,实现了输入[-10,+10]内的计算。但是精度越高,消耗存储资源就越多,且受输入范围的影响越大。为了避免在Softmax函数的实现上消耗过多资源,并确保较高的精度,本设计提出改进的FPGA多次查表和乘法器并用的方法来实现Softmax。
首先,将计算公式作进一步变换,如式(4)所示。

(4)
按式(4)变换,可将分母中每个指数函数的范围限制在(0,1)内。其优点是在制作查找表时可以减小数据的范围,降低ROM的深度。不过由于数据精度选择的不同,直接制作查找表依然会消耗过多ROM资源。本文采用多次拆分查表和调用乘法器相结合的方法。以进行一次查表为例。首先,在整个网络运算过程中,都是以定点数进行运算的。在制作查表时,需要将定点前输入数据所对应的指数函数结果制表。以式(4)中1个分母为例,其计算表达式如式(5)所示:
(5)
式中:xint为xu-x1结果的整数部分;xfloat为xu-x1结果的小数部分。
通过将整数部分和小数部分拆开查表,可以减少存储单元的使用。接着,继续将其分解,如式(6)所示。
(6)
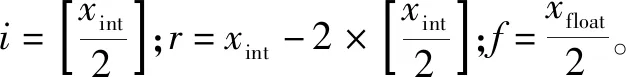
最后,由于r是在i的取值范围内,因此只需对整数和小数部分范围的一半进行制作查表,并通过查表和直接调用乘法器求出其乘积。该方法会消耗少量的乘法器,但可以节省大量的ROM资源。为求出f(xu),在求出分母的结果后,由于式(4)的分母是有界数,因此可以再次查表或者直接利用乘法器和线性逼近等方法求出其倒数。
3 试验结果及其分析
3.1 试验设计
本文设计的FPGA开发环境为Vivado 2019.1,开发平台为ZCU104,芯片型号为XCZU 7EV-FFVC 1156-2-E,摄像头型号为OV5640,软件开发平台为TensorFlow2.0,CPU型号为Intel i5-8250U,GPU型号为NVIDIA GTX1650。在试验中,分别在CPU、GPU实现上述网络模型,并对比FPGA实现的准确率、识别速度。整个试验流程如下。
①准备和制作数据集。通过高清摄像机采集正常的苹果、梨和腐败的苹果、梨这4种图像,并根据其类别,制作40 000张数据集。
②计算机端训练网络。利用TensorFlow2.0框架建立网络模型,对制作的数据集进行训练。由于对小样本的水果数据进行训练,采用的卷积神经网络模型参数如表1所示。
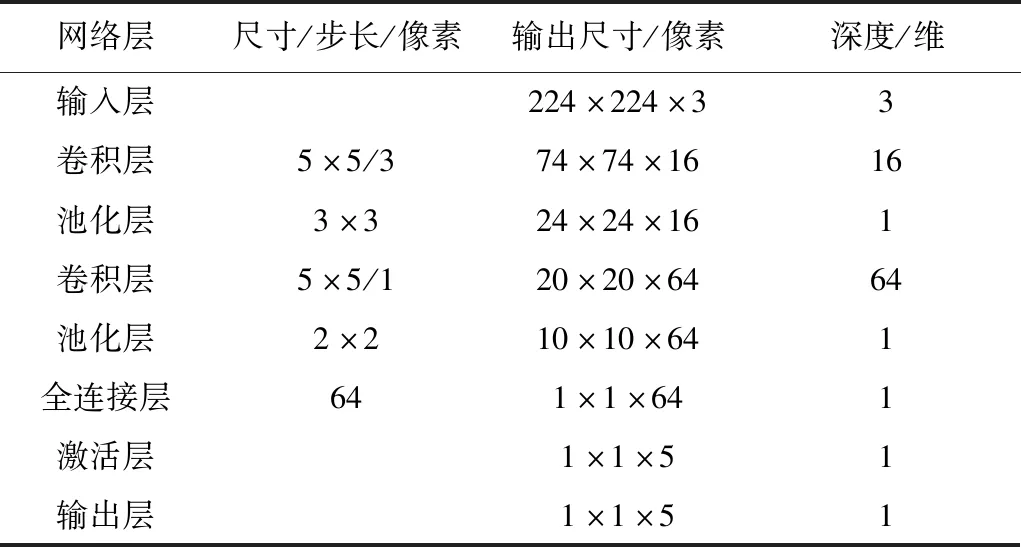
表1 卷积神经网络模型参数Tab.1 Convolution neural network model parameters
③计算机端将权重和阈值保存为二进制文件;利用ZCU104上的PS将权重写入FPGA的DDR中;利用ZCU104上的PL进行图像采集、预处理、数据量化和上述网络模型的前向推理。输出结果通过以太网口传输到计算机端的上位机。在Visual Studio2019中,通过C#的Socket通信搭建服务器,接收FPGA的采集图像和分类结果。
3.2 试验结果
在计算机端和FPGA平台分别测试1 000张图片。各平台准确率对比如表2所示。FPGA因为量化的原因,准确率相较于其他平台有所降低,但已经可以满足实际应用需求。

表2 各平台准确率对比Tab.2 Accuracy comparison of each platform
各平台识别速度对比如表3所示。与CPU相比,ZCU104的运行速度约为CPU的3倍。而与GPU相比,ZCU104略快于GPU,但相差不大。

表3 各平台识别速度对比Tab.3 Comparison of recognition speed of each platform
ZCU104资源主要使用了12%的查找表、30%的块随机存储器以及6%的乘法器。由于整个识别系统中包含缩放模块、卷积模块、池化,且缩放模块的实现本身就占用较多资源,所以资源使用量略高。但对一般的FPGA来说,足以满足该资源的消耗。
4 结论
本设计实现了卷积神经网络在FPGA上的搭建,并利用此网络模型,对自制的40 000张水果数据集进行测试,ZCU104的准确率达到95.8%。由于定点化的原因,ZCU104的准确率相较于CPU和GPU有所降低,但相差不大。而ZCU104、CPU、GPU的识别耗时分别为28.3 ms、88.9 ms、29.1 ms,表明ZCU104的识别速度达到CPU的3倍,同时也略快于GPU。
相比于以往的卷积神经网络加速器,本设计建立了基于FPGA的完整识别系统,包含了从图像采集到最终的识别分类。
首先,本设计采用查表法,优化图像预处理和归一化;其次,采用双通道进行卷积层计算和流式数据传输;最后,利用乘法器和多次查表相结合的方法,改进Softmax函数的计算。
本设计最大程度地减少了DSP的消耗,同时提高了识别的实时性。本文设计的卷积神经网络可通过ZCU104系统侧重配置,具有较高的通用性,对进一步研究卷积神经网络的识别以及检测模型的应用有着重要意义。
猜你喜欢
智能计算机与应用(2022年10期)2022-11-05
计算机应用(2022年9期)2022-09-25
软件导刊(2022年3期)2022-03-25
北京航空航天大学学报(2021年9期)2021-11-02
现代计算机(2021年36期)2021-03-14
南京理工大学学报(2020年4期)2020-09-21
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
计算机技术与发展(2019年1期)2019-01-21
计算机应用(2018年12期)2019-01-07
