
径向基神经网络和遗传算法优化热电负荷分配
2022-02-14 12:13徐朔文
自动化仪表 2022年1期
徐朔文,王 丹
(浙能阿克苏热电有限公司设备管理部,新疆 阿克苏 8430000)
0 引言
为缓解能源压力、提高电厂经济性,减少热电联产机组能耗势在必行。热电厂节能工作主要分为三个方面[1]:减少设备电耗,提高热效率;优化、完善热力系统及其设计,提高运行效率;优化负荷分配。
并列运行机组间负荷优化分配方法有[2]以下几种。①效率法,即效率高的机组带多的负荷。但实际运行中,机组间的负荷分配并不只由机组效率决定。效率法不能得到最优运行方案。②等微增率法[3]。该方法建立在古典变分原理上,但在实际应用过程中存在一些困难和缺陷,并且对于热电联产机组,负荷分配更复杂。该方法不可通用。③智能算法。这类算法建立在优化理论的基础上,例如遗传算法、免疫算法、蚁群算法等[4]。其中,基于仿生学的智能算法计算速度更快。
本文将采用遗传算法来优化热电负荷分配。
1 径向基神经网络优化及模型构建
1.1 径向基神经网络局限性
径向基(radial basis function,RBF)神经网络只具有三层前向网络:第一层为输入层;第二层为隐藏层,对输入信息进行空间映射变换;第三层为输出层,结构相对简单,涉及的神经元连接数目较少[5]。与其他类型的神经网络相比,RBF神经网络具有更强的逼近能力,在确定局部结构后,只需略微调整整个结构。RBF神经网络理论上是前向网络中映射最佳的网络,拓扑结构简单,逼近精度高且速度更快,可逼近任意非线性函数,应用广泛。
RBF神经网络算法中,输入与输出关系如下:
(1)
(2)
式中:wij为连接权重;xi为在输出样本中选取的隐藏层函数的中心;a为基函数的方差;dj为样本期望输出值;yi为输出向量元素;n为输入向量的个数;m为输出向量的个数;p为输出层神经元的个数;xp为第p个输入向量元素。
RBF神经网络算法的激活函数有高斯函数、反常S型函数和逆畸变校正函数。此处选取较为常用的高斯函数。
RBF神经网络算法中隐藏层函数的中心在样本中选取,难以反映输入与输出之间的真实关系,并且没有考虑在不同的应用过程中产生的各种误差。
1.2 优化RBF神经网络
①优化隐藏层函数中心的选取。为了更好地反映输入与输出之间真实的关系,需要对函数中心的选取方式进行优化。一种选取方式为选取样本值,能在一定程度上反映样本值与所选取中心值的距离。另一种选取方式为不断更新中心,使输出值根据中心的变化而变化,且输入与输出之间没有明显的固定关系。要解决隐藏层函数中心选取所带来的问题,不妨将样本理想值ci作为函数中心。一方面,可以根据确定的中心值确定输入与输出之间的连接关系,客观地反映输入与输出之间的关系;另一方面,也可以看出样本实际值与理想值之间的偏差。
②优化权值初始化方法。权值是神经网络算法中的重要组成部分,影响着所要构建模型的整体准确度。权值初始化如式(1)所示。
(3)
式中:kmin与kmax分别为第k个输出神经元所有期望值中的最小值与最大值;j为神经网络的层数;q为神经元个数。
③优化权值更新方法。权重的迭代更新采用梯度下降法[6]。沿着梯度向量的反方向,梯度减小的速度最快,可以高效地得出所构建函数的最小值。
增加修正项R矫正实际应用过程中存在的偏差。实际应用过程中对应不同的数据处理,有针对性地增加修正项,以构建精准的算法模型。
考虑所有优化之后,输入和输出之间的关系为:
(4)
1.3 模型的经济性指标
热电厂的经济性指标主要有以下三种:热电厂燃料利用系数ηtp、供热机组的热化发电率ω和全厂总煤耗量btp。由于ηtp涉及电、热直接相加,而两种能量本质上是不同的,故不能作为供热机组与热电厂的热经济性指标。对于参数不同的机组,不能比较ω。且对于抽凝式机组,由于ω未考虑纯凝发电部分的影响,故不适合作为单一的热经济性指标[7]。btp是整厂在单位时间里所要消耗的煤量。本文以煤耗量指标作为负荷优化的评判依据。
1.4 构建能耗模型
构建以全厂煤耗量(率)作为经济性指标的数学模型,可以有效简化模型,故负荷优化分配以煤耗量(率)最小为目标。目标函数为:
(5)
约束条件规定寻优的范围。要在保障机组安全运行的前提下,满足调度指令,求解得到最小煤耗量的负荷分配方案。约束条件如下。
①各机组的电负荷之和等于全厂总指令电负荷。
②各机组的热负荷之和等于全厂总指令热负荷。
③各机组电负荷要在其上下限之间。
④各机组热负荷要在其上下限之间。
根据两台350 MW 的超临界机组的实际运行数据,构建RBF神经网络模型,拟合机组的能耗特性。神经网络模型的输入量与输出量为:X=[x1x2...xk]是输入量,此处为机组热电负荷;Y=[y1y2...yk]是输出量,此处目标函数为全厂煤耗量。根据式(4)所示的输入和输出之间的关系,可利用优化后的RBF神经网络算法构建全厂煤耗量与机组负荷之间的算法模型。
1.5 机组能耗模型拟合图
1#机组能耗模型结果如图1所示。

图1 1#机组能耗模型拟合结果图Fig.1 1# unit energy consumption model fitting results
2#机组能耗模型拟合结果如图2所示。

图2 2#机组能耗模型拟合结果图Fig.2 2# unit energy consumption model fitting results
图1和图2中:x轴为机组的电负荷;y轴为机组的热负荷;z轴为机组煤耗量。根据图1、图2可知:随着机组热负荷以及电负荷的增大,机组煤耗量逐步减少。由于两台机组热负荷之和与电负荷之和要分别满足热电厂总指令的热负荷与电负荷要求,而两台机组的负荷分配互相制约,所以优化负荷分配可以降低两台机组的总煤耗量。
2 遗传算法优化热电负荷分配
2.1 遗传算法及其优化改进
遗传算法计算流程如图3所示。
图3 遗传算法计算流程图Fig.3 Flowchart of genetic algorithm computation
采用遗传算法解决实际问题时,把求解范围内的每个点看作一个个体,则个体在环境中的适应能力就是以个体的适应度、个体所处的环境为问题的目标函数。经过多轮计算,最终会得到一个适应度最高的个体,即问题最优解。
在遗传算法实现过程中,主要涉及以下操作。
①编码,常用的编码方式有实数、矩阵、树型和二进制编码。本文采用实数编码。
②计算适应度,即对个体进行评价。适应度函数需满足五大标准[8]:①规范性;②单值、连续、严格单调;③合理性;④计算量;⑤通用性。
适应度函数一般可由目标函数转换得到,通常有三种方式:第一种是直接将待求目标函数转化为适应度函数[9];第二种与第三种对于最小值问题,均涉及估值,精确度差,灵敏性有欠缺。因此,本文采用第一种方式将目标函数直接转换为适应度函数。
③遗传操作,包括选择运算、交叉运算和变异运算。
选择操作方式有随机遍历抽样法、局部选择法和轮盘赌选择法。本文采用较为常用的轮盘赌选择法。
遗传算法中,交叉算子[10]对收敛性有着决定性的影响。不同交叉方式适用于不同编码方式。本文采用的是实数编码。常用的交叉方式是算术交叉。
变异操作可以提高全局优化算法的局部搜索能力,并能防止进化过程过早收敛,从而得到全局最优的结果。
④确定终止条件。满足终止条件即表示得到了最终优化结果。算法终止条件有三种:①达到最大的迭代次数;②达到最小偏差σ;③适应度值的变化趋势减缓到了一定程度,或者已经停止。本文采用最大迭代次数作为终止条件。
遗传算法常会陷入局部最优,造成得不到全局最优解的问题[11]。轮盘赌选择法的缺点有误差较大、个体适应度不高,不利于控制种群进化方向。交叉概率通常在0.3~0.8中选择一个固定值。但交叉概率太大会使适应能力降低。而适应能力过低会使算法全局寻优能力和收敛速度下降。
对于陷入局部最优的问题,可以采取加入罚函数项的方法。罚因子的选取要根据输入值与输出值的大小关系而定,应该尽可能选取较小值,以免带来大误差。对于交叉概率,不再选取固定值,而是根据当前适应能力以及当前迭代次数,不断调整交叉概率的数值。前期选取较小的变异概率,以保存优良基因;后期选取较大的变异概率,以加强全局寻优能力、提高准确性[12]。
2.2 基于改进遗传算法优化热电负荷分配
采用改进后的遗传算法对两台 350 MW 供热机组进行负荷优化分配。这两台机组的负荷分别为1#机组电负荷N1、2#机组电负荷N2、1#机组热负荷D1、2#机组热负荷D2。查看机组实际运行数据,得到机组负荷的约束条件(数据单位均为 MW ):
(6)
种群规模T=30,最大迭代次数为500。采用实数编码方式,以目标函数作为适应度函数,采用均匀分布初始化种群,选择操作采用轮盘赌算法,变异操作采用自适应方式,交叉操作采用算术方式,不断调整交叉概率。
部分工况下负荷分配方案对比如表1所示。

表1 部分工况下负荷分配方案对比Tab.1 Comparison of load distribution schemes under some working conditions
表1中:工况一为N=600、DR=200,N为总电负荷,DR为总热负荷;工况二为N=600、DR=170;工况三为N=500、DR=160;工况四为N=500、DR=150;N1和N2分别为1#机组和2#机组的电负荷;D1和D2分别为1#机组和2#机组的热负荷。不同负荷分配方案总煤耗率对比如图4所示。
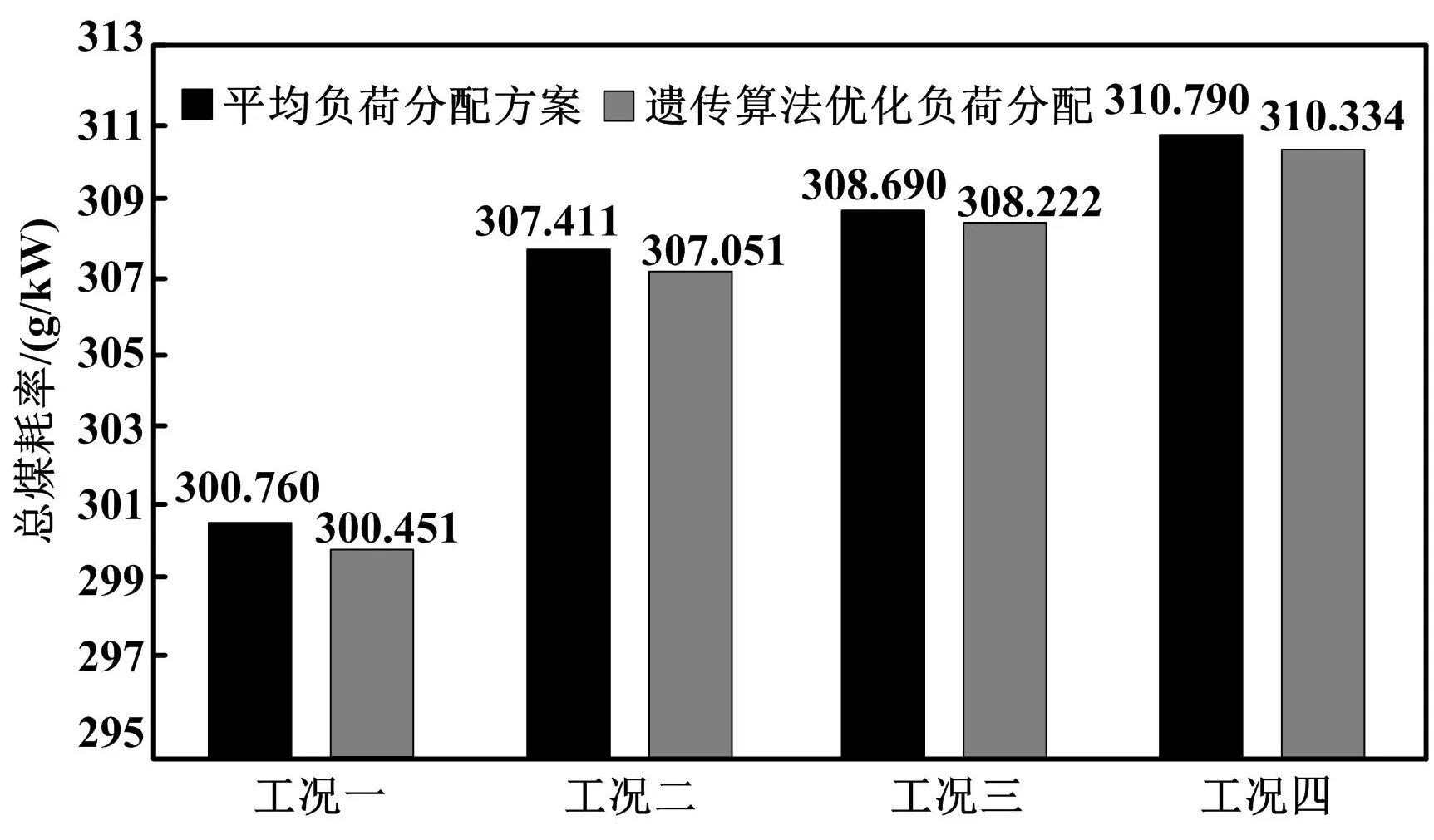
图4 不同工况下总煤耗率对比图Fig.4 Comparison of total coal consumption rates under different working conditions
由图4可知,本文采用遗传算法进行热电负荷优化分配,所得总煤耗率较平均分配方案的总煤耗率有一定程度的降低,说明遗传算法在机组负荷分配上的应用是有效的。
本文利用遗传算法进行负荷分配,能够降低能耗,节能环保,减少了电厂成本,提高了经济性。
3 结论
本文对RBF神经网络进行了优化分析,构建了神经网络模型;通过对某个电厂两台 350 MW 机组特性进行了分析,展示了机组性能特性图。本文分析了遗传算法的基本原理及其存在的局限性,对其进行了改进。通过将改进后的遗传算法应用于机组负荷优化,并比较遗传算法优化方案与平均分配方案,可以看出遗传算法的应用可以有效地降低全厂的总煤耗率。
综上所述,利用遗传算法进行负荷优化分配可以提高电厂经济性,给电厂带来巨大的经济效益,有着广阔的发展前景。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
能源工程(2021年2期)2021-07-21
中国注册会计师(2021年5期)2021-05-21
汽车工程(2021年12期)2021-03-08
热力发电(2020年9期)2020-12-05
电子制作(2019年16期)2019-09-27
电子制作(2019年24期)2019-02-23
当代旅游(2016年10期)2017-04-17
活力(2016年8期)2016-11-12
财经理论与实践(2015年2期)2015-04-16
