
基于难样本混淆增强特征鲁棒性的行人重识别
2022-02-18 06:44郝玲段断忠庞健
数据采集与处理 2022年1期
郝玲,段断忠,庞健
(昆明理工大学信息工程与自动化学院,昆明 650504)
引 言
随着深度学习的出现,行人重识别技术得到了广泛的发展[1],它是利用计算机视觉的方法判断图像或视频中是否存在特定行人的技术,由此也常被认为是图像检索的子问题。具体来说是将同一个人在不同环境、不同摄像头下所捕捉到的图像关联起来,从而实现跨域跨设备的检索。行人重识别技术[2⁃3]的出现弥补了目前固定摄像头的视觉局限性、人工搜索时间长等问题,由此在刑事侦查、智能安防、无人超市等领域得到了广泛的应用。
目前,行人重识别过程主要分为两步:(1)行人图片的有效特征提取;(2)对有效特征进行距离度量。然而由于数据集中大量难样本的干扰(图1),使得模型不能有效地优化类内、类间距离。三元组损失函数[4]是一种被广泛用于难样本信息挖掘的方法,即选择3张图片作为输入,分别命名为固定样本a,难正样本p和难负样本n,它在特征层面减小类内距离的同时增大类间距离,然而该方法只关注如何改进网络提取出来的特征,忽略了数据集中存在的大量难样本图像中的信息。

图1 锚点图像集合及难负样本集合Fig.1 Positive sample sets and negative sample sets
随着深度学习的不断发展,2014年Goodfellow等[5]提出了一种新的深度学习模型即生成式对抗网络(Generative adversarial networks,GAN),2018年Wei等[6]首次将GAN应用到Re⁃ID中,将利用GAN生成的不同相机风格的行人图片以有监督的方式重新训练模型。随后提出的CycleGAN[7⁃8]使用两个生成器和两个判别器来进行不同域间行人图像的风格转换,SPGAN[9]则是在CycleGAN的基础上加入前景约束,在尽可能多地保留行人外观的前提下改变图片的背景风格。然而上述基于GAN的方法都需要建立十分复杂的网络,而且训练过程不稳定存在模型崩塌的风险。这类方法生成不同风格的行人图像仅仅是一种对数据的增强,提升了样本多样性,没有赋予模型挖掘难样本信息的能力。
针对上述方法中存在的问题,本文提出一种难样本混淆增强特征鲁棒性的行人重识别方法。主要工作如下:(1)使用基于ResNet⁃50的主体框架,充分利用难样本在图像层面的信息,赋予网络提取更具有鉴别性的特征的能力;(2)将距离度量的结果作为相似性找到与原图最为相似的难样本,在图像层面进行难样本混淆,增加了训练样本中信息的多样性,提高了模型泛化能力;(3)不需要额外的生成器和鉴别器,在端到端的模型中深度挖掘难样本信息,增强模型鲁棒性的同时让网络本身的结构相对简化。在不同数据集上的实验结果表明了本文方法的优越性,能够有效提升行人重识别性能。
1 基于深度学习的行人重识别
1.1 标签平滑交叉熵函数
在基于深度学习的行人重识别中,一般使用交叉熵损失函数[9]对图像的特征进行分类,在距离度量中通常采用三元组损失函数[4]来进行距离约束。定义数据集中的图像集合为表示数据集中的图像总数表示图像标签,N为数据集中的行人身份总数。首先利用交叉熵损失函数优化模型,让网络对不同行人具有初始的鉴别能力,如式(1)所示。
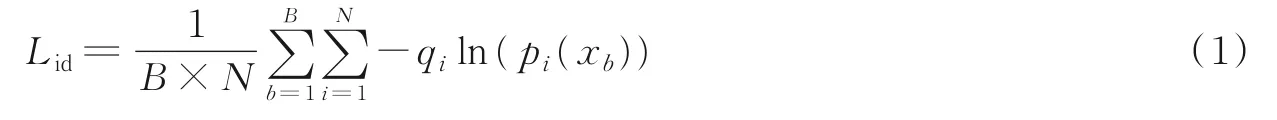
式中:B为每批训练图像数量,pi(xb)为将输入图像xb预测为第i个行人的概率,qi为指示函数,用来判断网络的预测结果是否正确。

式中mb表示与输入图像xb对应的真实行人身份标签。由于常用的交叉熵损失函数过度地依赖训练集中正确的行人标签,这使得网络容易出现过拟合的现象。通常解决上述问题,标签平滑(Label smooth⁃ing,LS)[10]是最常用的方法,因此对q i进行改写,具体过程为
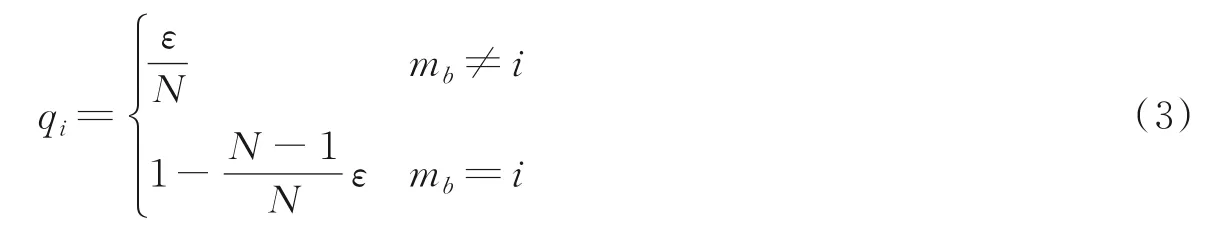
式中:ε为平滑超参数,在训练时作为容错因子引入到交叉熵损失函数中,实验中设置ε=0.1。由于训练集和测试集中的行人是互不重合的,标签平滑可以有效防止训练过程中出现的过拟合,进一步提升模型泛化能力。
1.2 三元组函数
常用的另一种优化特征的损失函数为三元组损失函数[4]。三元组由3张图片构成,分别命名为:锚点a,难正样本p,难负样本n。其中难正样本表示一批图像中与锚点图像身份一致,但与锚点具有较低相似度的行人图像,难负样本表示与锚点图像身份不一致,但与锚点具有较高相似度的行人图像。三元组损失函数表达为

式中δ为训练过程中设置的阈值参数。式(4)表示括号内的数值与0相比较,选择大的数值作为损失函数的结果。本文选用常用的欧式距离作为距离度量方式,后续实验中会分析不同度量方式产生的结果。三元组损失的学习目标是增大锚点与难负样本(类间)的距离,减小锚点与难正样本(类内)的距离,并采用欧氏距离来表示样本之间的距离。在一个欧氏距离空间Rd中,度量学习的目的是得到一个能够将x映射到Rd中的函数f(x)以实现三元组学习的目标,具体表示为

2 基于难样本混淆增强特征鲁棒性的行人重识别
2.1 难样本的挑选和混淆
图2为本文的网络结构图,本实验选择ResNet⁃50[11]作为编码器进行特征提取,在特征层面利用欧氏距离找出每个输入图像对应的难样本,通过混淆因子对输入图像和与之对应的难样本图像进行样本混淆,利用新生成的混淆样本重新优化网络,使网络进一步挖掘难样本信息从而提取更加具有鉴别性的特征。
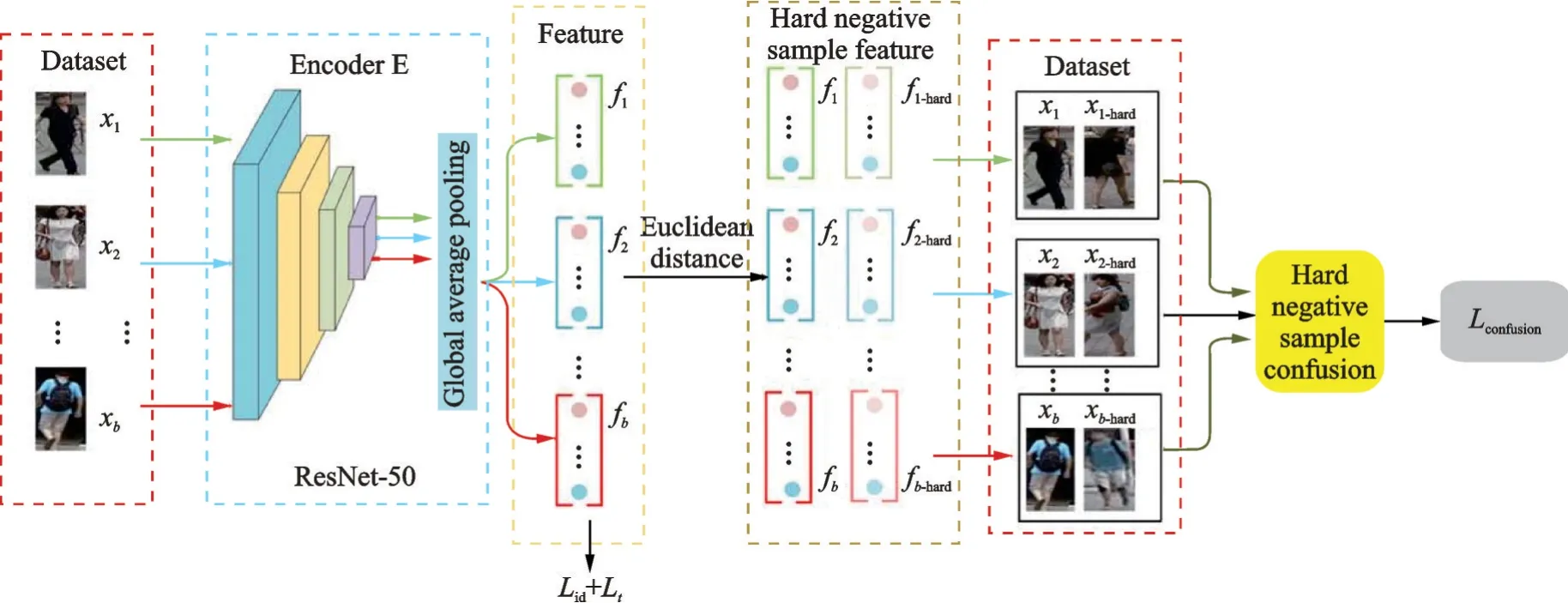
图2 网络结构示意图Fig.2 Schematic diagram of network structure
所提方法的一个关键点在于寻找图像的难样本,数据集中的难样本很多,要挑选与到目标图像最相似的难样本是本节主要目标。给定一个锚点样本,a表示该样本的身份,将其通过网络得到的特征f()与训练批次中其他身份的图像特征逐一进行距离度量,找到与xa i最为相似的难样本。具体过程如下
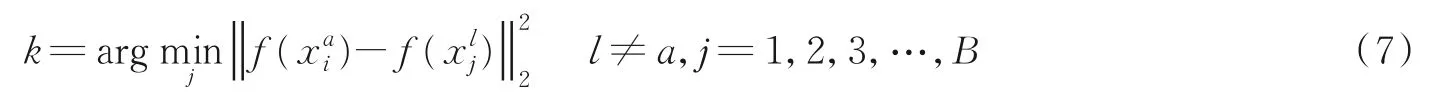
式中:B为每个训练批次的图像数量(Batch size),定义为第i个样本对应的难样本,其身份为l。通过式(7)可以找到每张图像对应的难样本图像,接下来进行难样本混淆。难样本混淆的目的是使锚点样本带有其难样本图像的部分信息,从而使训练得到的网络更加具有鉴别性不易被难样本干扰。每批训练图像和其对应的难样本都需进行如下难样本混淆过程
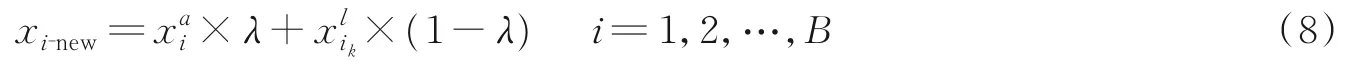
式 中:xi⁃new为生成的 混 淆 样 本,λ为混 淆 因 子。不 同 的λ会 影 响 生 成 的 混 淆 样 本xi⁃new中 难 样 本 信 息 含量,后续实验中会展示不同λ的生成图像可视化结果,并且讨论λ的变化对性能的影响。对于混淆样本xi⁃new对 应 的 标 签,应 与 锚 点图 像的标签保持一致,同样为mi。因为所提出的难样本混淆方法目的是让当前锚点图像携带有部分难样本图像信息,从而生成一个新的混淆图像,通过这类混淆图像提升模型鉴别性,使网络在识别行人时不容易被难样本信息干扰。
2.2 鲁棒性特征的提取
通过2.1节的训练过程找到难样本图像,并进行难样本混淆生成一批含有难样本信息的新图像,将生成的含有难样本信息的新图像重新利用1.1节介绍的平滑交叉熵函数以有监督的方式训练网络,以提高模型的鲁棒性,公式如下
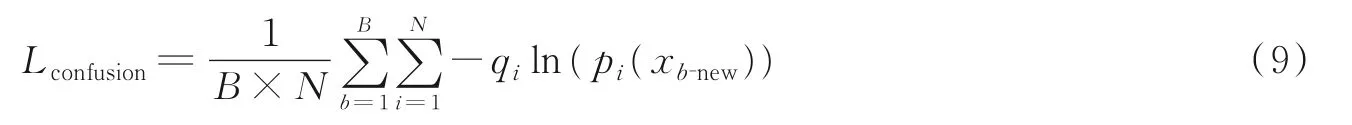
目前大部分行人重识别研究都在特征层面挖掘难样本信息[12],很少有根据难样本的图像信息降低其对模型性能的干扰,而且所提方法不需要额外的生成和鉴别网络,相较于基于GAN[6]的方法训练速度更快且更稳定。最后综合上述本文的损失函数表示为

式中超参数β用来衡量所提方法对整体性能的影响,后续实验会进一步讨论β的变化对整体模型的影响。
3 实验结果与分析
3.1 数据集及评估指标
为了验证难样本混淆算法的有效性,本文在两个大型主流数据集DukeMTMC⁃ReID和Market⁃1501以及两个小数据集GRID[13]和PRID2011[14]上进行了测试,采样图像如图3所示。4个数据集都由训练集和测试集两部分组成,见表1。并且这两部分的行人身份互不重合,查询数据集(Query)由测试集中抽取的部分样本组成。Market⁃1501[15]数据集于2015年在清华大学采集得到,数据集中的图像来自于5个高分辨率摄像头和1个低分辨率摄像头,共计1 501个行人,32 668张图片。DukeMTMC⁃ReID[16]在杜克大学内采集得到,图像来自8个不同的摄像头,共计1 404个行人和34 183张图片。PRID2011数据集提供了2个不同静止监控摄像头下拍摄到的行人图像,也是一个规模不大的数据集。这个数据集中行人图像的检测框都是人工手动提取,并且两个摄像头拍摄到的相同身份行人有200个,这些行人随机分为两组,分别作为训练集和查询集。GRID数据集采集于6个不重叠相机,共包含250对行人图像。其中该数据集还有775张剩余图像,这类图像均为干扰样本,没有对应的身份信息,在训练过程中不予使用。

图3 4个不同数据集下的行人样本Fig.3 Samples from four different datasets
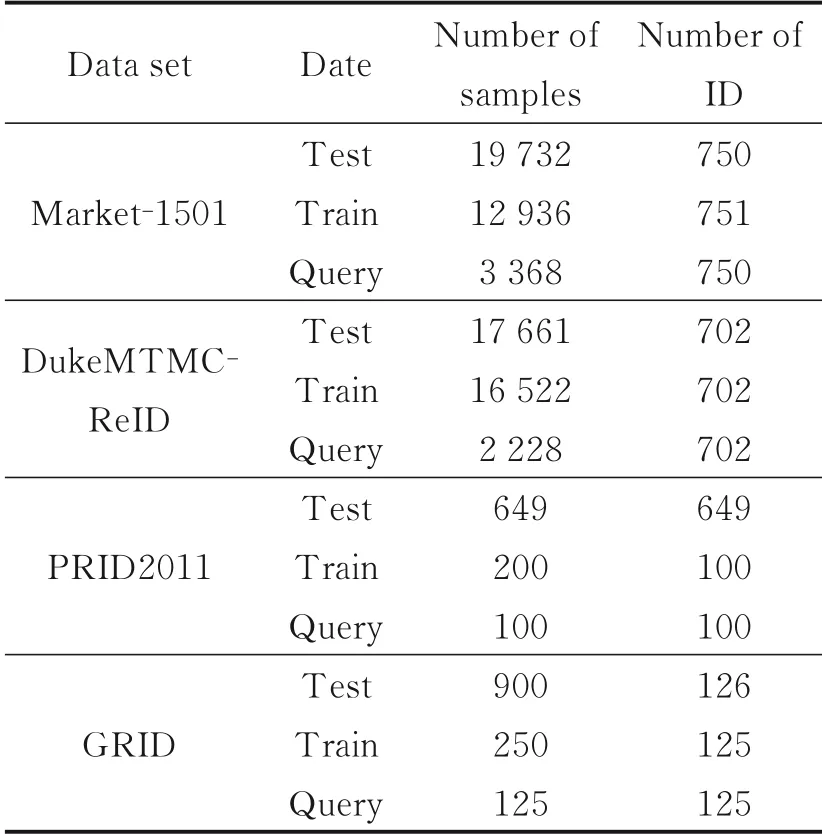
表1 数据集介绍Table 1 Introduction to the datasets
实验中,本文采用累计匹配曲线(Cumulative match characteristic,CMC)中的Rank⁃1、Rank⁃5、Rank⁃10以及平均精度均值(Mean average precision,mAP)[15]进行性能评估,对于所有数据集,使用单个查询图像(Query)在样本库(Gallery)中进行检索,没有使用重排序(Re⁃ranking)或随机擦除(Random eras⁃ing)等数据增强的方法。
3.2 实验环境和参数设置
本文采用在Image⁃Net预训练过的ResNet⁃50[11]作为主干网络进行特征提取,最后额外增加了一个全局平均池化层。本文实验所采用的Tricks参考文献[17],对学习率进行了Warm up,初始学习率为0.000 35,前10代线性增加学习率至0.003 5,在40代和70代分别降低至当前值的1/10。将主干网络的最后一个空间下采样的步长(Last stride)改为2。在最后一层的分类器前面加入Batch normalization(BN)层,消除特征分布的偏差。实验中采用Pytorch深度学习平台,CPU为I7⁃8700,内存为32 GB,显卡为11 GB的GTX1080Ti。所有训练图像剪裁为256×128作为网络的输入,训练批次的大小设为64,其中为了满足三元组的要求,每个身份采样4张图像。使用Adam[18]对网络参数进行优化,其中权重衰减因子设为0.000 5,初始学习率为0.000 35,在40代和70代学习率下降为当前值的1/10,总共训练120代。交叉熵损失函数中的ε设为0.1,三元组损失函数中的δ设为0.3,混淆因子λ设为0.98。
3.3 与其他方法比较
为了验证本文提出的算法性能,首先在大数据集Market⁃1501和DukeMTMC⁃ReID上与当前性能较为优异的方法进行了比较。
首先在Market⁃1501数据集上与3类方法进行了比较:(1)基于深度学习和属性的方法。PAN[19]、APR[19]、TFusion⁃sup[20]、FPO[21]、DAI[22]、LWL[23];(2)基 于 注 意 力 机 制 和 特 征 融 合 的 方 法。HA⁃CNN[24]、MCFF[25];(3)基于三元组改进的方法。TriNet[12]、IDTL[26]。表2中,本文提出的算法在Mar⁃ket⁃1501数据集上Rank⁃1和mAP分别达到了94.0%和82.5%,性能上超过了所有对比的方法,相较于性能较高的挖掘难样本信息的方法IDTL,所提方法在Rank⁃1和mAP上分别高于其2.6%和6.1%。对于传统的优化特征类内类间距离的三元组方法TriNet,本文方法在性能上大幅领先,说明了所提算法的优越性。
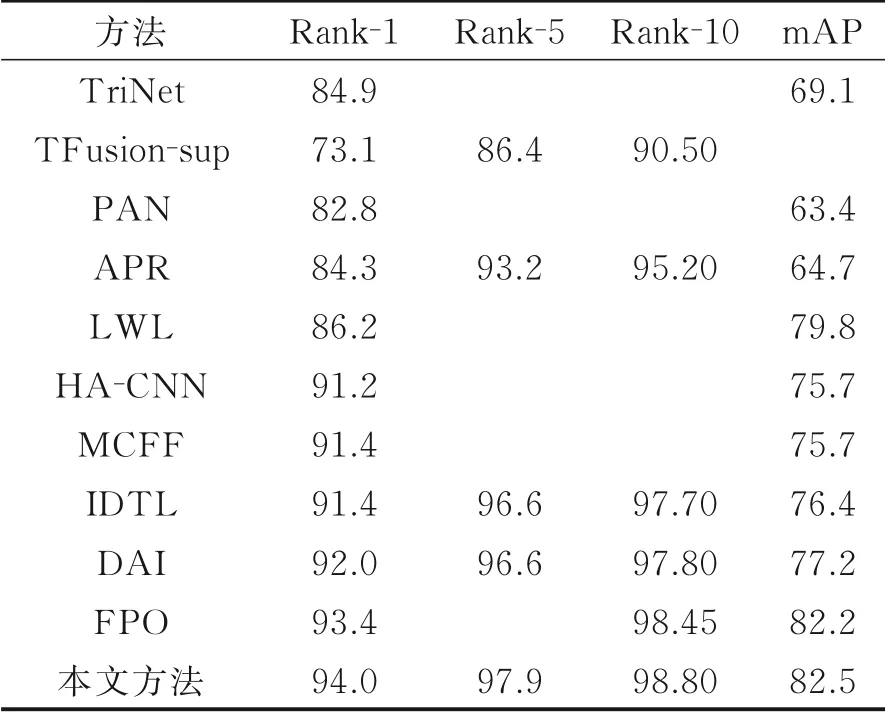
表2 Market⁃1501结果对比Table 2 Results comparison of Market⁃1501 %
同样地,将本文提出的算法在DukeMTMC⁃ReID数据集上与目前较为主流的上述3类算法进行对比,额外加入行人掩膜引导的方法Human parsing[27]进行比较,该方法在图像层面降低了背景对行人的干扰。性能对比如表3所示,相较于目前性能较高的行人掩膜引导方法Human parsing,本文算法在Rank⁃1和mAP上分别提升了1.1%和0.5%。在和难样本信息挖掘方法IDTL的比较中,本文方法在Rank⁃1和mAP上优势明显。尽管两项指标提升的效果没有在Market⁃1501数据集上那么优越,但是也足以说明模型的鲁棒性。
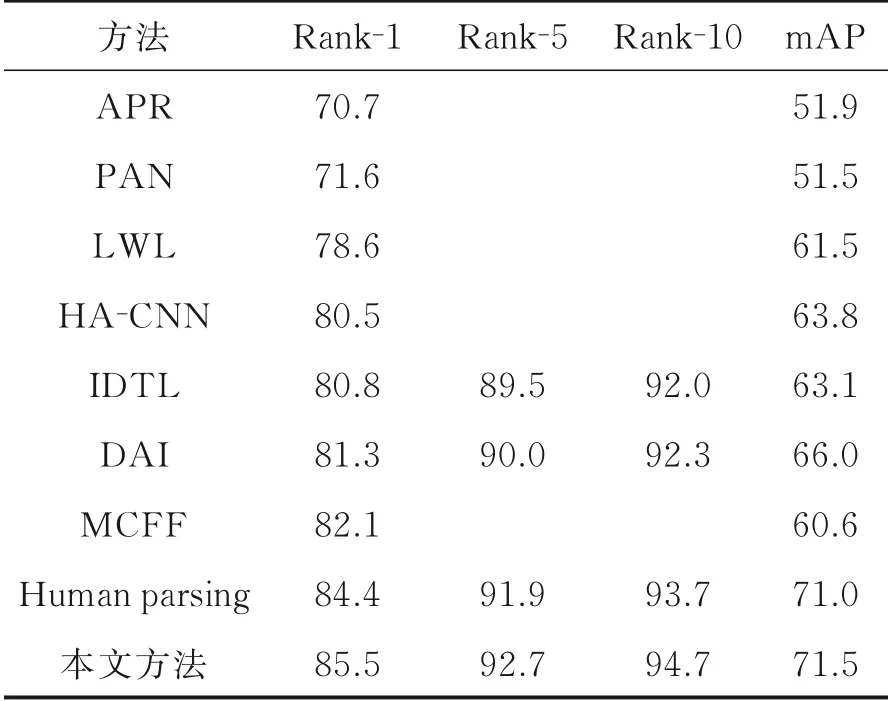
表3 DukeMTMC⁃ReID结果对比Table 3 Comparison results of DukeMTMC⁃ReID %
接下来,在小数据集PRID和GRID上与其他方法进行比较。小数据与大数据集Market⁃1501和DukeMTMC⁃ReID有显著差别,主要体现在行人图像数量较少,一般方法都是用Rank⁃1、Rank⁃5、Rank⁃10和Rank⁃20进行性能对比,而不选用mAP,因为有的数据集中同一个人可能只有一张图像,因此无法计算mAP。在PRID上(表4),所对比的方法有RPLM[28]、KCCA[29]、MFA[30]、kLFDA[30]、NFST[31]、aMTL⁃LORAE[32]。与基于度量学习最好的方法RPLM相比,所提方法在Rank⁃1、Rank⁃5、Rank⁃10、Rank⁃20上分别高出26.6%、36.8%、35.9%和31.5%。和基于核的鉴别性空间学习方法中最优异的kLFDA相比,所提方法的Rank⁃1达到了41.6%,而kLFDA仅为22.4%。与属性信息辅助的方法aM⁃TL⁃LORAE对比,所提方法在Rank⁃1上提高了23.6%。和其他方法对比,所提方法均体现了大幅领先。
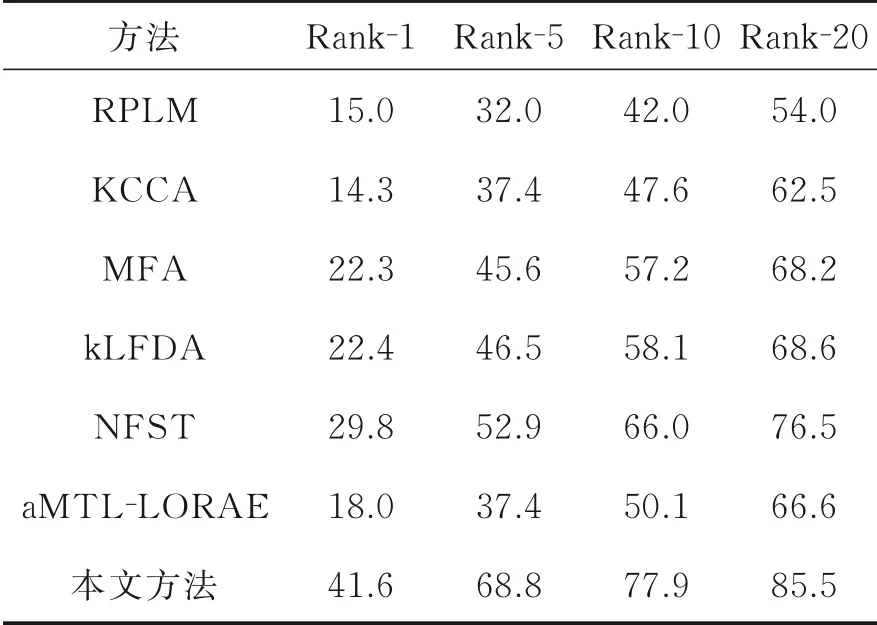
表4 PRID结果对比Table 4 Comparison results of PRID %
在GRID上 的 实 验 结 果 如 表5所 示,所 对 比 的 方 法 包 括GOG+XQDA[33]、MHF[34]、LOMO+DMLV[35]、MKFSL[36]、CRAFT⁃MFA[37]、DMVFL[38]、CSPL[39]、SRR[40]和DSRPDL[41]。在Rank⁃1、Rank⁃5、Rank⁃10、Rank⁃20的 对 比 中,所 提 方 法 比 手 工 提 取 特 征 的 方 法GOG+XQDA分 别 高 出11.86%、9.1%、7.12%和7.84%,证明了基于深度学习的方法在行人重识别数据集GRID上的性能远远超出手工提取特征的方法。和当前最好的利用字典学习进行特征学习的方法DSRPDL相比较,所提方法在Rank⁃1等4个评价指标上都大幅领先。综上证明了所提方法在小数据集上同样具有很强的竞争力。
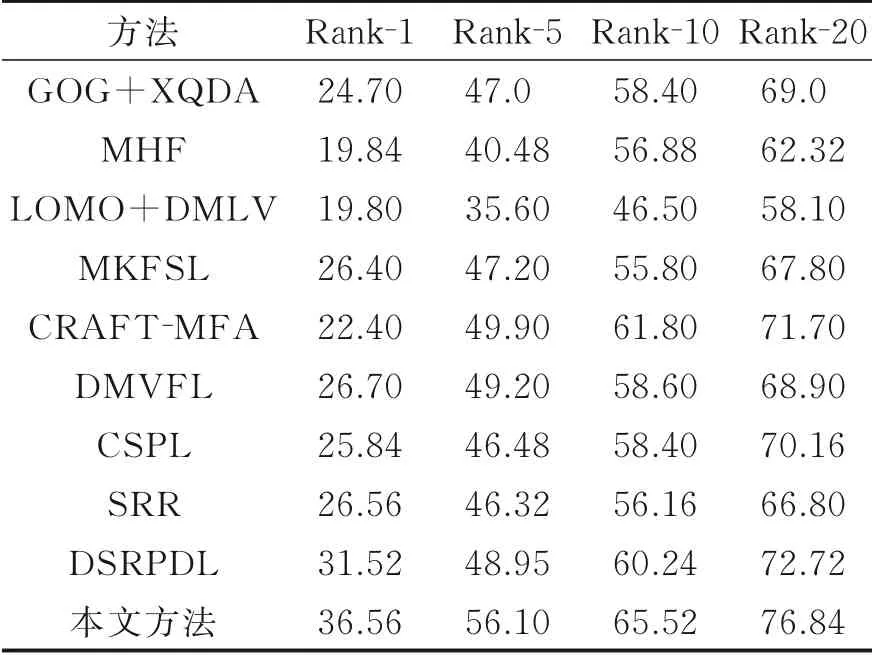
表5 GRID结果对比Table 5 Comparison results of GRID %
3.4 消融实验
通过图2可知,本文提出的难样本混淆算法主要包含3项损失函数:使网络提取行人鉴别性特征的身份损失(Lid),特征层面约束类内和类间距离进一步增强行人身份信息的三元组损失(Lt)以及难样本混淆后新数据的交叉熵损失(Lconfusion)。接下来进行消融实验证明本文所提方法的有效性。实验结果如表6所示,可以看出仅使用身份约束Lid时Rank⁃1和mAP分别达到了93.2%和82.0%,加入难样本混淆后Lid+Lconfusion性能进一步获得提升。结合所有损失函数(Ltotal=Lid+Lt+Lconfusion)后性能达到了最优,说明所提方法在加入三元组后能够进一步提高特征的鉴别性,与在特征层面进行约束的三元组函数具有互补性。
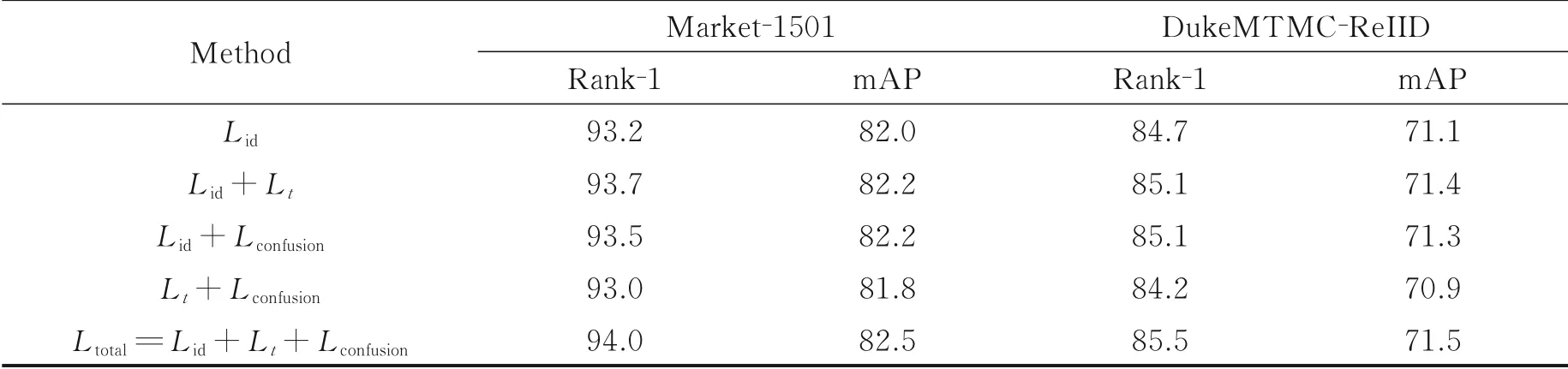
表6 消融实验Table 6 Ablation experiment %
3.5 超参数分析
本节内容是对式(10)中的超参数β进行性能分析,该超参数用来权衡所提难样本混淆方法对整体性能的影响。在两个较大数据集Market⁃1501和DukeMTMC⁃ReID上进行参数分析,以Rank⁃1和mAP进行说明。参数分析结果如图4所示,从Market⁃1501数据集可以看出,当β取值为1时Rank⁃1和mAP达到了最优值,当β大于1时性能显著下降,因此适用于Market⁃1501数据集的β最优值为1。当测试数据集为DukeMTMC⁃ReID,β取值为0.8时取得最优性能,同样地;β越大性能下降越明显,说明所提方法权重过大时可能会对模型造成干扰。
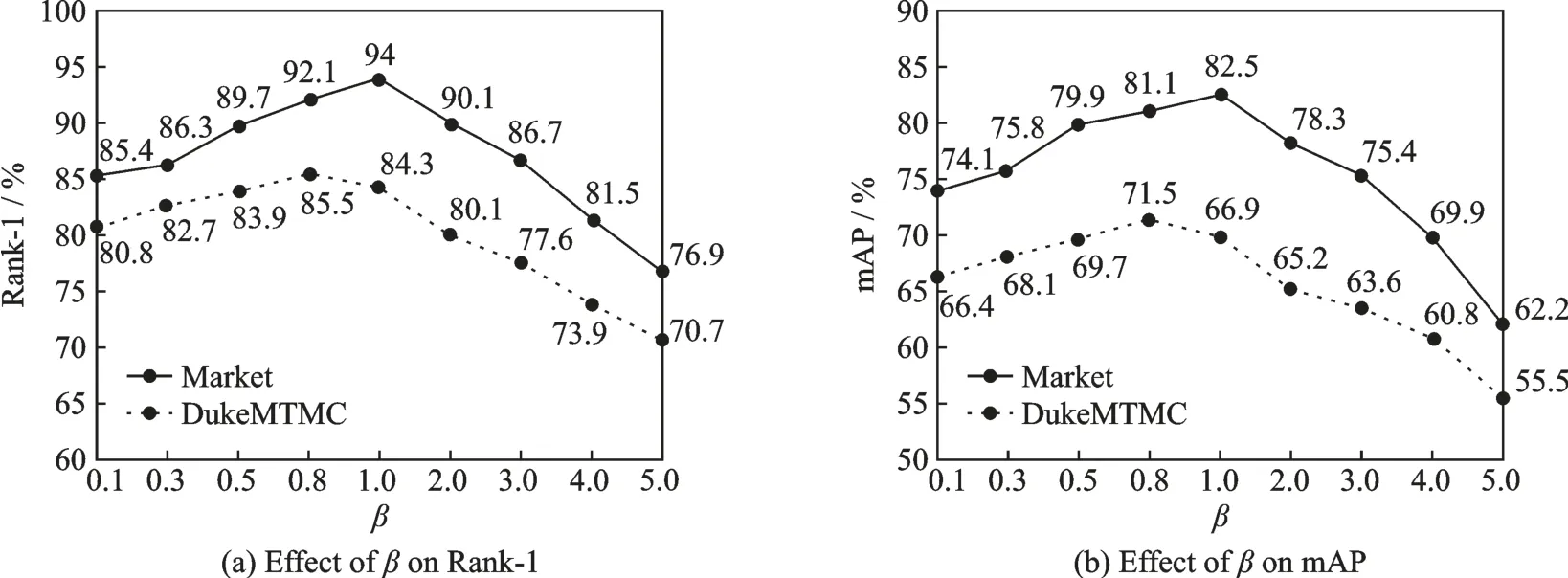
图4 β对Rank-1和mAP的影响Fig.4 Effect of β on Rank-1 and mAP
3.6 混淆因子分析
在本节中,讨论式(8)中控制难样本混淆程度的混淆因子λ的作用以及不同λ下的可视化图像。λ参数的取值范围是[0,1],该值越小,生成的混淆图像越趋近于难样本,反之越像原图像。图5中,列出了Market⁃1501中两组样本的难样本混淆图像,其中λ取值分别为0.1、0.3、0.5、0.7和0.98。从生成的混淆样本可以看出,λ取值越小时,其难样本在图像中所占的比重越高,例如第一行中λ=0.1时生成的样本和难样本几乎相同,而随着λ的增大,当λ=0.98时,生成的样本趋近于正样本同时带有部分难样本的信息。可视化进一步说明了随着λ的改变,其生成的混淆图像携带有不同含量的难样本信息,接下来讨论不同λ对模型性能的影响。

图5 难样本混淆可视化Fig.5 Visualization of negative sample confusion
为了分析不同λ对模型性能的影响,在Market⁃1501数据集上进行实验,并且以Rank⁃1和mAP进行说明。实验结果如图6所示,可以看出λ越小对模型性能影响越大,因为其生成的混淆样本携带大量难样本信息,而交叉熵损失函数会将该样本误分类为原图像从而造成模型性能下降。随着λ的增大,混淆样本中正样本所占有的信息越大,其对性能提高也越明显。当λ处于(0.9,1)时,模型的性能逐渐在高点趋于稳定,且在取值为0.98时达到了最优。对于λ的分析说明了当生成的混淆样本中带有少量难样本信息时确实能够提升模型的鲁棒性。
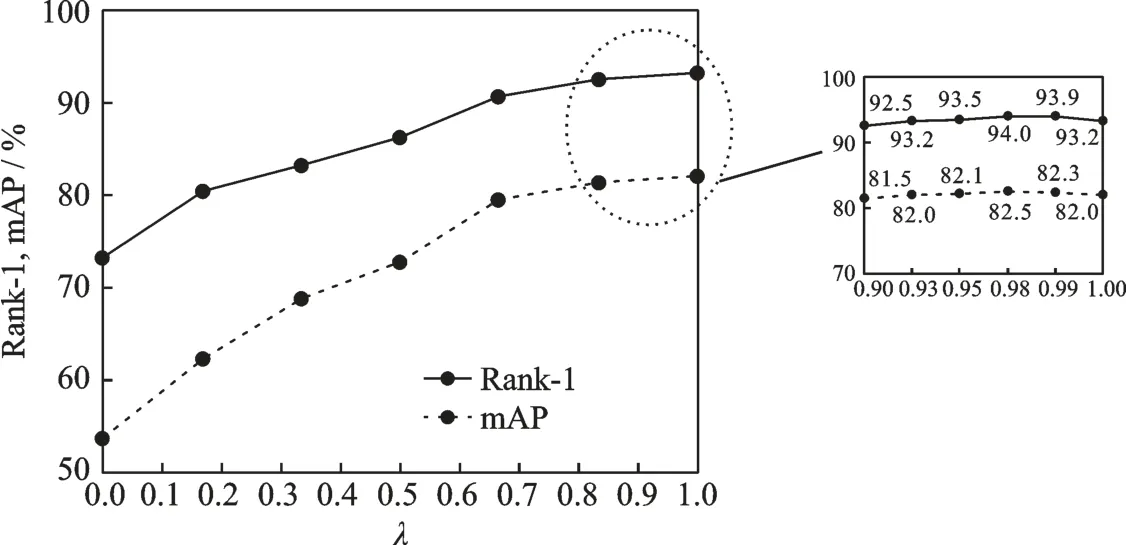
图6 λ对Rank-1和mAP的 影 响Fig.6 Effect of λ on Rank-1 and mAP
3.7 距离度量分析
本节对难样本选取过程中采用的度量方式进行分析。实验中,拟采用3种不同的度量方式选取训练批次图像中的难样本进行混淆。实验结果如表7所示,在实验过程中,除了度量方式不同,其余参数均保持一致。由表7结果可以看出,曼哈顿距离的效果最差,原因是该距离度量方式衡量的是特征间距离绝对值之和,导致求和后的值相对较大,降低了样本间的区分度。反观欧式距离的结果,其度量方式是特征差的平方和,使特征差异在数值上的体现较为明显,更易挑选出真实的难样本,而余弦距离更多的是反映两个特征间的角度差异,对特征整体分布的差异表现不明显,虽然相较于曼哈顿距离的结果有所提高,但仍逊于欧式距离的结果。
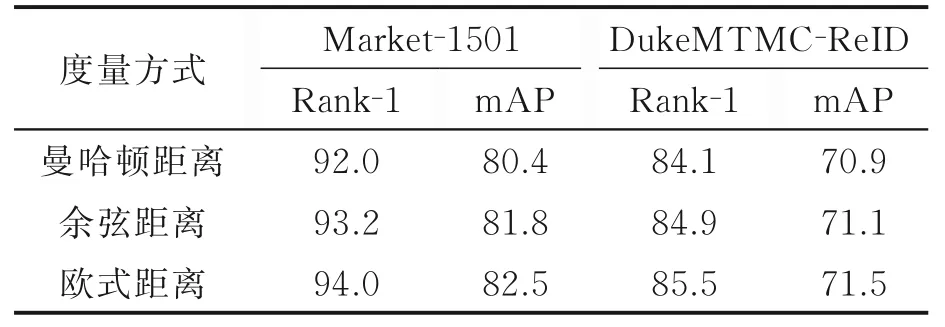
表7 不同度量方式的结果Table 7 Results with different measures %
4 结束语
本文针对不同视角下的背景、光照等因素造成数据集中存在大量难样本的问题,提出一种难样本混淆增强特征鲁棒性的行人重识别方法,通过相似性度量寻找每张图像对应的难样本,利用混淆因子合成具有难样本信息的新图像再以有监督的方式促使模型挖掘难样本信息,从而提高模型鲁棒性。在多个数据集上的实验结果表明,本文算法在性能方面优于目前难样本信息挖掘的方法和一些主流的深度学习方法。消融实验进一步证明了所提方法的有效性,通过后续的参数分析选择了适用于不同数据集的最优参数,最后由难样本可视化阐明混淆过程以及混淆因子的作用。未来会研究如何在图像风格更加相似的图像中更加快速有效地找到难样本,进一步提高行人重识别的精度。
猜你喜欢
山西大学学报(自然科学版)(2021年1期)2021-04-21
意林(2021年5期)2021-04-18
五邑大学学报(自然科学版)(2019年3期)2019-09-06
扬子江(2019年1期)2019-03-08
计算机技术与发展(2018年12期)2018-12-20
小学生导刊(2018年34期)2018-12-18
小天使·一年级语数英综合(2017年6期)2017-06-07
汽车与安全(2016年5期)2016-12-01
山东青年(2016年3期)2016-02-28
母子健康(2015年1期)2015-02-28
