
基于关键点特征融合的六自由度位姿估计方法
2022-03-09 03:30王太勇孙浩文
天津大学学报(自然科学与工程技术版) 2022年5期
王太勇,孙浩文
基于关键点特征融合的六自由度位姿估计方法
王太勇1, 2,孙浩文1
(1. 天津大学机械工程学院,天津 300350;2. 天津仁爱学院,天津 301636)
针对单张RGB-D图像进行六自由度目标位姿估计难以充分利用颜色信息与深度信息的问题,提出了一种基于多种网络(金字塔池化网络和PointNet++网络结合特征融合网络)构成的深度学习网络框架.方法用于估计在高度杂乱场景下一组已知对象的六自由度位姿.首先对RGB图像进行语义识别,将每一个已知类别的对象掩膜应用到深度图中,按照掩膜的边界框完成对彩色图与深度图进行语义分割;其次,在获取到的点云数据中采用FPS算法获取关键点,映射到彩色图像与深度图像中进行关键点特征提取,将RGB-D图像中的颜色信息与深度信息视为异构数据,考虑关键点需要充分融合局部信息与全局信息,分别采用了金子塔池化网络(pyramid scene parsing network,PSPNet)和PointNet++网络提取颜色信息与深度信息;采用一种新型的关键点特征融合方法,深度融合提取到颜色信息与几何信息的局部及全局特征,并嵌入到选定的特征点中;使用多层感知机(multilayer perceptron,MLP)输出每一个像素点的六自由度位姿和置信度,利用每一个像素点的置信度,让网络自主选择最优的估计结果;最后,利用一种端到端的迭代位姿求精网络,进一步提高六自由度位姿估计的准确度.网络在公开的数据集LineMOD和YCB-Video上进行测试,实验结果表明和现有同类型的六自由度位姿估计方法相比,本文所提出的模型预测的六自由度准确度优于现有的同类型方法,在采用相同的评价标准下,平均准确度分别达到了97.2%和95.1%,分别提升了2.9%和3.9%.网络同时满足实时性要求,完成每一帧图像的六自由度位姿预测仅需0.06s.
六自由度位姿估计;深度学习;特征融合;机器视觉
六自由度位姿估计是指在标准坐标系下识别物体的三维位置和姿态,是机器人抓取和操纵[1-3]、自主驾驶[4-5]、增强现实[6]等应用中的重要组成部分.理想情况下的解决方案可以处理形状和纹理不同的对象,并在传感器噪声和变化的光照条件中表现出鲁棒性,同时达到实时性要求.
传统的方法如Papazov等[7]与Alvaro等[8]使用手工制作的特征来提取图像和物体体素模型之间的对应关系.这种依靠人类经验设计的特征在光照条件变化或严重遮挡的场景准确度会大幅下降,导致传统的方法很难应用到实际中.
最近,随着机器学习和深度学习技术的爆炸性增长,基于深度学习的方法被引入到这一任务中.Tekin等[9]与Tjaden等[10]提出直接使用深度卷积网络回归对象的旋转和平移.然而,由于旋转空间的非线性,这些方法通常具有较差的泛化能力.Peng等[11]提出了PVNet,通过霍夫投票得出关键点,并使用多点透视成像(perspective-n-point,PNP)算法计算对象的六自由度位姿,Park等[12]与Yu等[13]采用了类似的方法.虽然这两个阶段的方法表现更稳定,但大多数都建立在物体的二维投影的基础上.在真实的三维空间中,投影中较小的误差会被放大,并伴随投影重叠现象导致对象间难以区分.此外,刚性物体的几何约束信息由于投影导致部分丢失.
另一方面,随着廉价RGB-D传感器的发展,越来越多的RGB-D数据集被提出.借助从深度相机中获取额外的深度信息,许多优秀的二维空间算法被扩展到三维空间,如Xu等[14]提出了PointFusion、Qi 等[15]提出了Frustum PointNet和Chen等[16]提出了MVSNet++.传统的方法如Teng等[17]直接将深度信息视作与颜色信息同构的数据,用相同的特征提取方法处理深度信息;Wang等[18]提出了DenseFusion网络将深度信息利用已知的相机内参转换为点云数据采用PointNet模型来处理点云数据提取几何特征,并进行像素级特征融合实现了高准确度的六自由度位姿估计;Deng等[6]利用自监督学习与霍夫投票来进行六自由度位姿的预测;Chen等[19]提出一种类别级的六自由度位姿预测方法,将目标对象进行三维空间上的归一化再进行位姿预测;Gao等[4]直接利用激光雷达获取到的点云图像完成六自由度位姿预测.
尽管Wang等[18]提出了DenseFusion网络在处理公开数据集中达到了良好的效果,但是在处理深度图像时采用了PointNet[20]方法,此方法只能提取采样点的几何特征,局部几何特征的欠缺,提高了预测六自由度位姿的难度.此外在生成全局特征的提取中,直接对所有采样点进行平均池化,虽然平均池化函数作为对称函数可以有效解决点云数据的无序性问题[20],但是没有充分利用点云数据间的几何关系和采样点与二维图像中像素点的映射关系.
Peng等[11]提出的PVNet已经在2D图像中证实选取存在于物体的几何边界处的关键点对于提高预测位姿的准确度有较大的提升.本文提出了一种三维点云数据中基于关键点的新型网络架构,在点云数据中利用最远特征点采样算法(farthest point sampling,FPS)选取关键点,引入金字塔池化网络和PointNet++网络[21]来分别处理彩色图像和深度图像,采用点云上采样和平均池化函数生成全局几何特征,对关键点进行像素级特征嵌入融合,提高模型的识别准确度,实现高准确度的六自由度位姿预测.
1 网络结构提出

在实际的应用场景中,六自由度位姿估计存在着物体相互遮挡、光线不佳等挑战,充分利用RGB-D图像中的颜色信息和深度信息弱化外界环境的影响是当下主流的解决方法.通过关键点进行六自由度位姿估计可以弱化物体之间相互遮挡的影响,但是需要充分提取关键点的几何信息与颜色信息.这两种信息处于不同的空间之中,所以从异构数据中提取特征并进行嵌入融合是六自由度位姿估计领域的关键技术挑战.本文所设计的网络首先通过两种不同的方式处理颜色和深度信息来解决数据异构的问题,之后利用颜色信息和深度信息在二维图像中内在的映射关系在预先选定的像素点中进行特征嵌入融合,最后通过可微迭代求精模块对估计位姿进行求精.
1.1 网络总体结构
本文所提出的网络总体结构如图1所示.网络模型包括两个阶段,第1阶段以彩色图像作为输入对每个已知类别进行语义分割,即提取出已知对象的掩膜,应用到彩色图像和深度图像中生成边界框以完成语义分割.语义分割网络是一个编码解码结构,利用输入的彩色图像,生成+1个语义分割图.每个分割图描述个可能的已知类别中的对象.由于笔者工作的重点是设计一种六自由度估计方法,并为了保证实验对比的公平性,笔者选取当前主流方法使用的语义分割网络[22].第2阶段处理分割结果并估计对象的六自由度位姿,包括5个部分:关键点选取过程、基于PointNet++模型的深度信息提取网络、像素级特征嵌入融合网络、基于无监督置信度评分的像素级六自由度位姿的估计、位姿求精网络.

图1 六自由度位姿估计网络总体结构
1.2 关键点选取
利用待估计物体的几何信息的关键点主要存在于物体的几何边界处这一先验信息[11,20],在高度杂乱的场景下,相较于从图像中随机选取个点作为关键点来进行位姿估计,预先选取几何边界处的采用点进行特征提取可以提高几何信息的提取效率,并且可以大幅降低需要的采样点数量,提高算法实时性.在二维RGB图像中,通过选取关键点来进行六自由度位姿的估计是常用的方法,但是刚性物体会由于投影造成几何信息的部分丢失,并且不同的关键点会由于投影而重叠,导致难以区分.在三维点云数据中,关键点通常选择三维边界框的8个角点,这些点是远离物体上的虚拟点,使得网络很难聚合它们附近的颜色以及几何信息,造成距离关键点越远的点的位姿估计的误差越大,对于六自由度位姿估计的参数计算有一定的影响.
本文选用了最远特征点采样算法(farthest point sampling,FPS)选取关键点.具体来说是将物体点云的中心点作为初始点添加入算法中来进行选择过程,每一次添加距离所选定关键点最远的点至关键点集中,将该点作为新的初始点进行迭代,直到集合数量达到个关键点.通过提取这些关键点的特征作为六自由度位姿估计的依据.LineMOD数据集中灯罩对象的关键点的选取如图2所示,橙色点代表选取的关键点,从图2(a)的点云关键点可以看出橙色点主要集中在图像的边缘处,图2(b)将关键点投影回二维图像,关键点产生了一定程度上的重叠.

图2 LineMOD数据集灯罩关键点
1.3 特征提取
1.3.1 颜色特征提取网络
颜色特征提取网络的目标是提取每个像素的颜色特征,以便在三维点特征和图像特征之间形成紧密的对应关系.本文采用了由Zhao等[23]提出的基于深度卷积网络的金字塔池化模型.该网络通过挖掘颜色特征并聚合了基于不同区域的上下文信息,在场景解析领域取得了良好的效果.它将尺寸为××3的图像映射到××rgb特征空间.每个像素嵌入了表示相应位置处的输入图像的颜色信息的rgb维特征向量.
1.3.2 几何特征提取网络
通过FPS算法选定的关键点集中在物体的边缘位置,为了能让边界点可以更好地预测六自由度,需要边界点能够充分地融合局部几何信息和全局几何信息.PointNet网络只是单纯地做了几何特征维度上的扩展,之后使用池化函数得到全局几何特征,完全丢失了点的局部几何特征.为了避免这一情况的发生,本文使用PointNet++来代替PointNet,利用PointNet++可以提取局部几何特征这一特性让关键点具有更加丰富的几何信息.
首先使用已知的相机内参将分割好的深度图像转换为3D点云数据,之后使用类似PointNet++模型来提取几何特征,PointNet与PointNet++提取几何特征原理如图3所示.从图3(a)中可以看出,PointNet模型直接对点的三维坐标特征进行学习,而忽略了点之间的几何关系.所以Wang等[18]使用的PointNet虽然可以提取三维坐标点的几何特征,但是忽略了三维坐标点之间的局部几何特征.Qi等[20]提出了PointNet++模型,从图3(b)中可以看出,模型将稀疏的点云进行分割,在分割区域内不断地提取几何特征作为局部特征,扩大局部范围继续学习局部特征,直到获得全局几何特征.

图3 几何特征下采样提取原理
为了更加充分地利用全局几何特征,本文改进了PointNet++模型,对提取出的点云全局特征进行了上采样,如图4所示.二维图像中的上采样技术是将学习到的全局特征上采样到每一个像素点,让每一个像素点都获取到全局特征.像素点根据全局特征预测所属类别信息,已经在二维图像中的图像分割领域取得了巨大的成功.利用点云三维数据与彩色图像二维数据的内在一一对应关系,将点云数据进行上采样,每个选定的像素点将获得geo维度的全局几何特征.

图4 几何特征上采样原理
1.4 像素级特征融合与位姿估计
为了减小由于语义分割误差对特征提取阶段的影响,特征融合阶段没有采用直接融合颜色特征与几何特征的全局信息方法,而是设计了像素级特征融合网络.其核心是先进行局部逐像素融合,再嵌入全局信息,以此增加每一关键点所携带的信息量.
由于像素点和三维点之间的映射是唯一的,所以融合过程首先利用已知的摄像头的内参,基于图像平面上的投影,将每个点的几何特征与其对应的像素点的颜色特征关联并进行局部特征的融合.如图5所示的特征融合阶段,橙色方格代表的是每一个关键点对应像素点的颜色特征,蓝色方格代表的是每一个关键点的局部几何特征,通过维度拼接的方式进行特征融合,融合后代表每一个关键点的局部特征.产生局部特征后嵌入经过点云上采样的全局几何特征,并送入多层感知机进行学习,为了消除点云无序性的影响加入了平均池化函数,最终得到了代表全局信息的绿色方格.通过这种方式有效地结合了提取到的所有特征,关键点的局部信息保证每个选取的像素点都可以做出预测,嵌入全局特征可以丰富每个像素点的特征,以提供全局上下文信息,达到了最小化遮挡和噪声影响的目的.最后将全局信息送入多层感知机进行位姿估计.同时利用自监督机制,让网络决定通过那个关键点可以得到最好的位姿预测,在输出六自由度位姿估计的同时还输出每个关键点的置信度分数.
本文的六自由度位姿估计的损失定义为真实位姿下物体模型上的关键点与预测姿态变换后的同一模型上对应点之间的距离.每一个关键点的损失函数的公式为

式中代表在N个关键点中第个关键点.
式(1)只对非对称物体有良好的效果,当估计对象是对称物体时会有多个正确的六自由度位姿,使用式(2)来计算估计模型上每个点和真实模型上的最近点的距离.
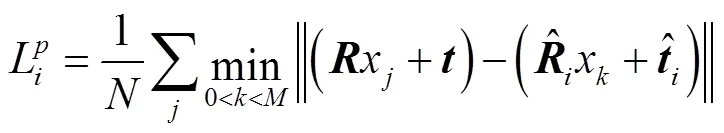
损失函数定义为每个关键点的损失综合,本文所提出的网络在输出六自由度位姿的同时还输出了每个关键点的置信度.关键点的置信度是根据每个关键点的上下文信息决定哪个位姿估计可能是最好的假设,最终的损失函数定义为

1.5 位姿求精模型
迭代最近点(iterative closest point,ICP)算法是许多六自由度位姿估计方法使用的一种求精方法,虽然准确度很高但是效率较低,无法满足实时性要求.


2 实验及数据对比
2.1 数据集
LineMOD数据集由Hinterstoisser等收集提出,是一个包含13个低纹理对象视频的视频数据.数据集中有标注的真实六自由度位姿和实例的掩膜.这个数据集的主要挑战是场景杂乱、存在低纹理物体和环境光照变化.它被经典方法和基于学习的方法广泛采用.本文没有额外的合成数据,挑选1214个关键帧作为训练集,1335个关键帧作为测试集.
YCB-Video数据集包含21个形状和纹理各不相同的YCB对象.捕获了92个对象子集的RGB-D视频,每个视频显示不同室内场景中21个对象的子集.这些视频中包括六自由度位姿和实例语义分割产生的掩码.数据集同样具有多变的光照条件、显著的图像噪声和遮挡等挑战.本文将数据集分割成80个视频用于训练,从剩余的12个视频中挑选2949个关键帧用于测试.
2.2 训练细节
本文对深度学习模型和测试模型都是基于pytorch1.7环境,在一个具备6Gb的GTX 1660 显卡的计算机上完成的.颜色特征提取中下采样部分采用的是ResNet-18,金字塔池化模型采用4层结构,每一层的上采样前特征图尺寸为1×1、2×2、3×3、 6×6.深度信息提取选取1024个点进行预处理,选取200个点作为关键点.每一个关键点在嵌入全局特征后包含1408维的特征向量.网络的学习率为0.001,位姿迭代求精由4个全连接层组成,这些层直接输出位姿的残差,每一个实验都采用了2次迭代求精.
2.3 评价标准

在测试集中每一次输入一帧图像进行六自由度位姿估计.在测试集中为了验证位姿估计在整个物体上的准确度,每一次在整个物体上随机采样500个点,通过计算ADD/ADD-S曲线下的面积,即计算500个采样点在欧氏空间下的平均距离来评估预测结果.阈值设定为0.1m,平均距离小于0.1m视为对此帧图像六自由度位姿估计成功.通过计算所有数据集下的平均准确度对算法进行评价.
2.4 测试结果评价分析
2.4.1 LineMOD数据集实验结果分析
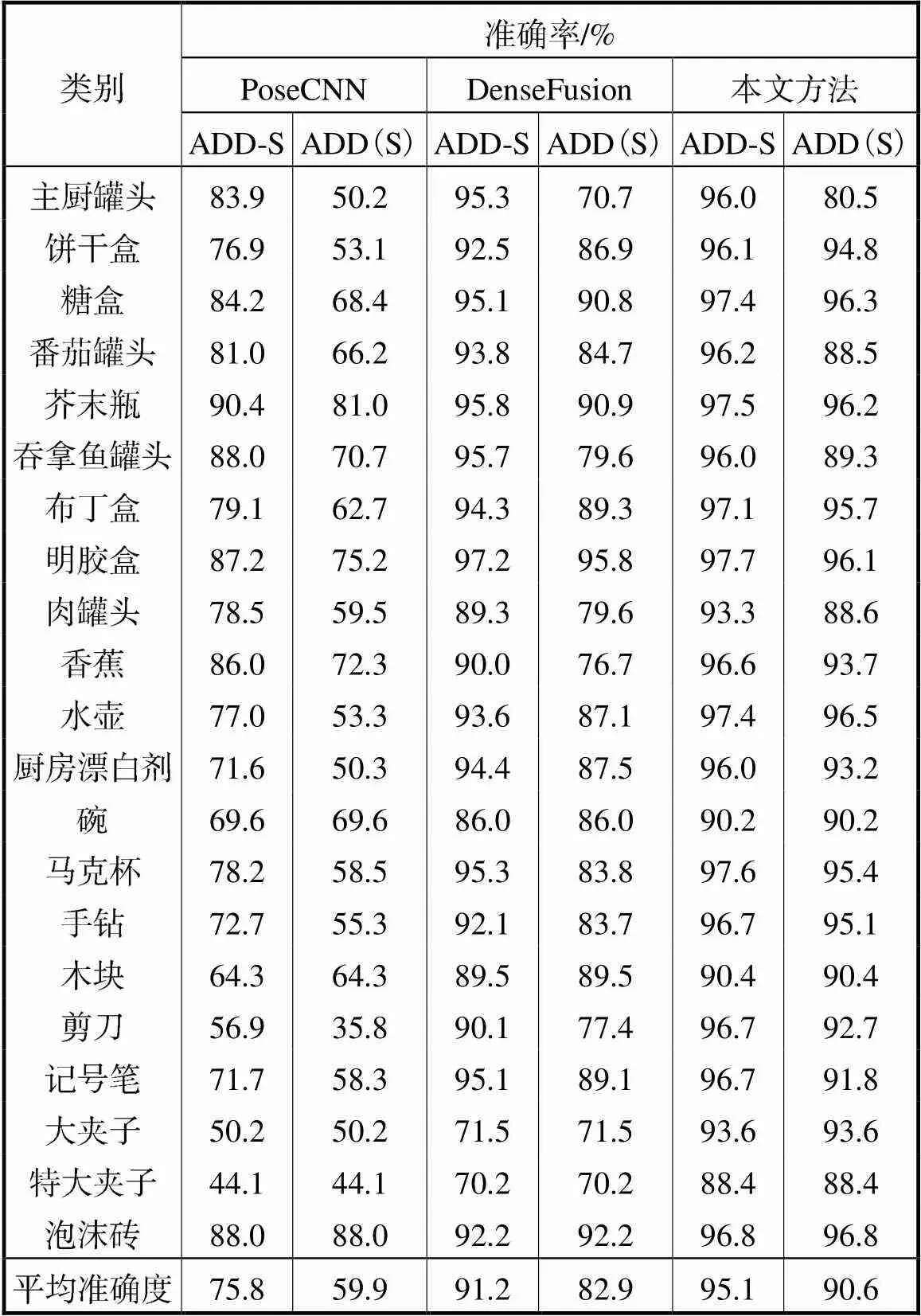
在基于LineMOD数据集的实验中,将本文提出的方法与Wang等[18]DenseFusion方法在训练过程中损失值的下降收敛情况进行对比,如图6所示.从图6中可以看出本文提出方法的收敛速度高于DenseFusion方法.在进行70次训练后本文方法的平均误差达到0.608cm,而DenseFusion的平均损失为0.708cm.在测试中,同时对比分析了输入为RGB图像的方法:PoseCNN方法[22]和PVNet方法[11];与输入为RGB-D图像的方法:SSD方法[24]和DenseFusion方法[18],这些方法都与本文采用了同样的评价标准,测试结果如表1所示.
在表1通过4种方法进行对比,列出了LinMOD数据集中每一个类别的ADD(S)准确率,可以看出本文提出的方法在准确率上高于现有的同类型方法.其中SSD方法将RGB-D图像中的颜色图像和深度图像视为同构数据采用了共享参数的多层感知机进行特征提取,从最终的位姿预测的准确度看出这种方法甚至逊于RGB图像中的方法.本文将其视为异构数据,采用了不同方法处理两种数据,大幅提高了预测准确度.相较于传统的RGB图像的方法,本文所提出的方法也更加具有优势.由于本文充分利用了关键点之间的几何关系,并设计了新的像素级特征融合方法,较于目前最优秀的位姿预测方法DenseFusion,平均预测准确度提高了2.9%.对于LineMOD数据集训练结果的可视化如图7(a)所示,可以看出将经过变换后的点云投影到图片上与RGB图像重合度 较高.

图6 LineMOD数据集损失值变化曲线
表1 LineMOD数据集实验预测准确度

Tab.1 6-DoF estimation result of the LineMOD dataset

图7 LineMOD数据集与YCB-Video数据集中本文方法实验结果效果
2.4.2 YCB-Video数据集实验结果分析
在基于YCB-Video数据集的实验中对比分析了PoseCNN方法[22]DenseFusion方法[18],两种方法与本文采用了同样的评价标准,测试结果如表2所示.从表2中可以看出本文所提出的方法相较于当前最优秀的方法在ADD-S标准下提升了3.9%,在ADD(s)标准下提升了7.7%.
表2 YCB-Video数据集实验结果
Tab.2 6-DoF estimation result of a YCB-Video dataset
在YCB-Video数据集主要的挑战是存在物体之间大量的遮挡,因此按照Wang等[18]提出的方法分析了在不同的遮挡条件下,遮挡对六自由度位姿估计的影响,如图8所示.从图8中可以看出在遮挡条件下本文所提方法明显优于现有的方法.在高遮挡下仍然拥有较高的准确度,说明本文所提出的基于关键点的特征融合算法在高度遮挡情况下仍然可以利用余下的关键点之间的几何关系,达到较高的位姿估计准确度,再次证明了关键点的选取在位姿估计中的重要作用.在YCB-Video的数据集上的具体实验效果对如图7(b)所示.
2.4.3 算法实时性
由于增加了提取关键点局部几何特征的PointNet++网络,增加了网络的复杂度.为了验证方法的实时性,本文也计算了在测试环境下对数据集中每一帧图像进行六自由度位姿估计所需要的时间.实验结果表明仅需要0.06s就可以完成一帧图像的预测(16帧/s),满足了实时性的要求.
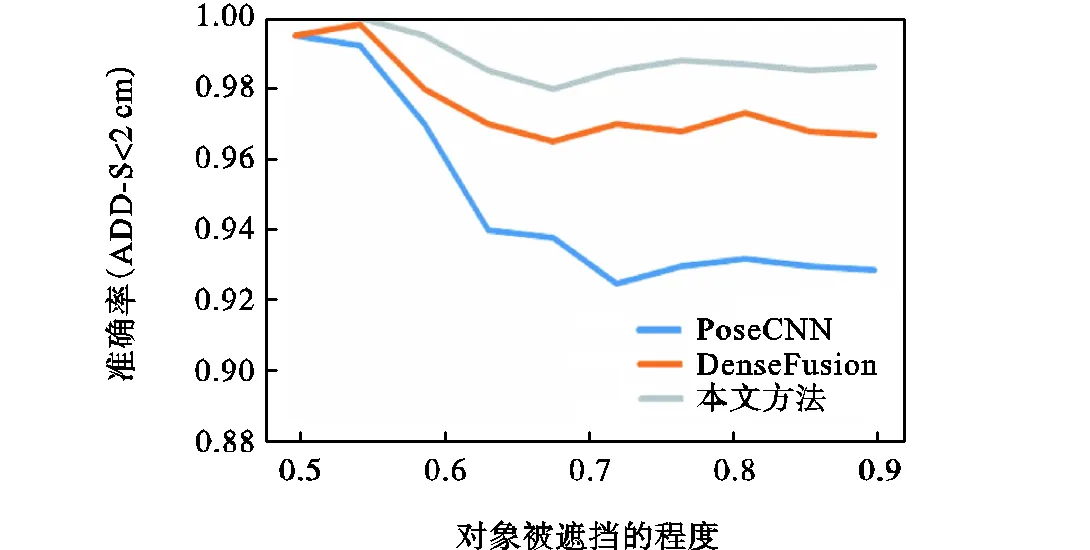
图8 在YCB-Video数据集上,不同方法在遮挡程度不断增加的情况下的性能
2.4.4 六自由度参数误差
网络最终输出为平移矩阵与旋转矩阵,为了更加直观地表达各个六自由度的预测误差,将旋转矩阵转化为欧拉角,最终结果如表3所示.其中e、e、e分别代表在测试集中平移矩阵在、、方向平移分量的平均误差.、、代表测试集中欧拉角表示下3个旋转分量的平均误差.从表3中可以看出网络预测的平移分量的误差较小,在欧拉角表示下的旋转误差由于一个旋转矩阵是3个欧拉角共同作用的线性变换,误差相较于平移分量偏大.
表3 六自由度位姿参数误差

Tab.3 6-DoF estimation pose parameter error
2.4.5 消融实验
为了验证位姿求精环节的效果并得到进行迭代的最优次数,设计了关于位姿求精网络的消融实验.将网络设定为不进行迭代求精,最终结果如表4所示.通过实验可以看出,位姿求精环节可以提高最终的位姿预测准确率,达到了网络的设计目的.通过实验结果的对比分析,在满足六自由度位姿估计的实时性要求下,本文最终选择在每次预测六自由度位姿后进行两次位姿迭代求精.
表4 消融实验位姿估计结果

Tab.4 6-DoF estimation result of the ablation experiments
3 结 论
本文针对复杂环境下六自由度位姿估计问题,提出了基于关键点特征融合的六自由度位姿预测方法.网络将RGB-D图像作为输入,相较于传统的仅RGB图像作为输入的方法,弱化环境因素对位姿估计的影响,可以适用于光照条件不佳以及待检测物体属于低纹理物体等多种情况,具体可以应用到机械臂抓取等场合.利用LineMOD数据集和YCB-Video数据集对所提出模型进行了多方面的实验与测试,实验结果表明:
(1) 通过采用基于关键点的六自由度位姿估计网络,大幅减少了预测一帧图像所需要的采样点数量,同时提高了预测的准确度.在增加几何信息提取网络层数时,满足了实时性要求,达到了估计每帧图像位姿只需要0.06s.证明了关键点选取在六自由度位姿估计中的重要性;
(2) 将颜色信息与深度信息视为异构数据,并将深度图像转换为点云数据可以更好地利用RGB-D图像中的信息,使得网络不需要去学习已知的转换关系,提高了网络的收敛速度;
(3) 通过PointNet++网络从深度图像中提取几何信息的方法可以有效地提取出关键点之间的局部几何信息和全局几何信息,有利于关键点做出准确的位姿估计;
(4) 通过像素级特征融合可以让关键点更加充分地利用网络学习到的颜色信息和几何信息,可以让每一个像素点都根据对应信息做出位姿估计,提高了网络在物体相互遮挡条件下物体的位姿识别准确度;
(5) 利用端到端的神经网络来进行位姿求精,可以加快预测速度,无需繁杂的迭代过程,可以更好地应用到实际中去.
通过实验也说明了笔者所提出模型仍存在优化和提升的空间,未来的研究重点为进一步简化特征提取网络、加快模型的训练速度和提高在复杂环境下模型的适应能力.
[1] Cui S,Wang R,Wei J,et al. Grasp state assessment of deformable objects using visual-tactile fusion perception[C]//2020 IEEE International Conference on Robotics and Automation(ICRA). 2020:538-544.
[2] Zakharov S,Shugurov I,Ilic S. Dpod:6D pose object detector and refiner[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul,Korea,2019:1941-1950.
[3] Zeng A,Song S,Yu K T,et al. Robotic pick-and-place of novel objects in clutter with multi-affordance grasping and cross-domain image matching[C]//2018 IEEE International Conference on Robotics and Automation(ICRA). Brisbane,Australia,2018:3750-3757.
[4] Gao G,Lauri M,Wang Y,et al. 6D object pose regression via supervised learning on point clouds[C]// 2020 IEEE International Conference on Robotics and Automation(ICRA). 2020:3643-3649.
[5] Qi C R,Chen X,Litany O,et al. Imvotenet:Boosting 3D object detection in point clouds with image votes[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle,USA,2020:4404-4413.
[6] Deng X,Xiang Y,Mousavian A,et al. Self-supervised 6D object pose estimation for robot manipulation[C]// 2020 IEEE International Conference on Robotics and Automation(ICRA). 2020:3665-3671.
[7] Papazov C,Haddadin S,Parusel S,et al. Rigid 3D geometry matching for grasping of known objects in cluttered scenes[J]. International Journal of Robotics Research,2012,31(4):538-553.
[8] Alvaro C,Dmitry B,Siddhartha S S,et al. Object recognition and full pose registration from a single image for robotic manipulation[C]//2009 IEEE International Conference on Robotics and Automation. Kobe,Japan,2009:48-55.
[9] Tekin B,Sinha S N,Fua P. Real-time seamless single shot 6d object pose predition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City,USA,2018:292-301.
[10] Tjaden H,Schwanecke U,Schomer E. Real-time monocular pose estimation of 3D objects using temporally consistent local color historams[C]//Proceedings of the IEEE International Conference on Computer Vision. Venice,Italy,2017:124-132.
[11] Peng S,Liu Y,Huang Q,et al. PVNet:Pixel-wise voting network for 6DoF pose estimation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Lone Beach,USA,2019:4561-4570.
[12] Park K,Patten T,Vincze M. Pix2pose:Pixel-wise coordinate regression of objects for 6D pose estimation[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul,Korea,2019:7668-7677.
[13] Yu X,Zhuang Z,Koniusz P,et al. 6DoF object pose estimation via differentiable proxy voting loss[EB/OL]. https://arxiv.org/abs/2002.03923,2020-05-04.
[14] Xu D,Anguelov D,Jain A. Pointfusion:Deep sensor fusion for 3D bounding box estimation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City,USA,2018:244-253.
[15] Qi C R,Liu W,Wu C,et al. Frustum pointnets for 3D object detection from RGB-D data[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City,USA,2018:918-927.
[16] Chen P H,Yang H C,Chen K W,et al. MVSNet++:Learning depth-based attention pyramid features for multi-view stereo[J]. IEEE Transactions on Image Processing,2020,29:7261-7273.
[17] Teng Z,Xiao J. Surface-based detection and 6-DoF pose estimation of 3-D objects in cluttered scenes[J]. IEEE Transactions on Robotics,2016,32(6):1347-1361.
[18] Wang C,Xu D,Zhu Y,et al. DenseFusion:6D object pose estimation by iterative dense fusion[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach,USA,2019:3343-3352.
[19] Chen X,Dong Z,Song J,et al. Category level object pose estimation via neural analysis-by-synthesis[C]// European Conference on Computer Vision. Glasgow,UK,2020:139-156.
[20] Qi C R,Su H,Mo K,et al. PointNet:Deep learning on point sets for 3D classification and segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Hawaii,USA,2017:652-660.
[21] Qi C R,Yi L,Su H,et al. Pointnet++:Deep hierarchical feature learning on point sets in a metric space[EB/OL]. https://arxiv.org/abs/1706.02413,2017-06-07.
[22] Xiang Y,Schmidt T,Narayanan V,et al. Posecnn:A convolutional neural network for 6D object pose estimation in cluttered scenes[EB/OL]. https://arxiv.org/abs/ 1711.00199,2018-05-26.
[23] Zhao H,Shi J,Qi X,et al. Pyramid scene parsing network[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Hawaii,USA,2017:2881-2890.
[24] Kehl W,Manhardt F,Tombari F,et al. SSD-6D:Making RGB-based 3D detection and 6D pose estimation great again[C]//Proceedings of the IEEE International Conference on Computer Vision. Venice,Italy,2017:1521-1529.
Six Degrees of Freedom Pose Estimation Based on Keypoints Feature Fusion
Wang Taiyong1, 2,Sun Haowen1
(1. School of Mechanical Engineering,Tianjin University,Tianjin 300350,China;2. Tianjin Ren’ai College,Tianjin 301636,China)
There exists a key technical challenge in performing six degrees of freedom(6-DoF)object pose estimation from a signal red,green,blue,and depth(RGB-D)image to fully leverage the color and depth information.To address this,we present a deep learning framework based on multiple networks pyramid scene parsing network(PSPNet)and PointNet++ combined with a feature fusion network.This method is used for estimating the 6-DoF pose of a set of known objects under a highly cluttered scene.The first stage involved taking colored images as input,performing semantic segmentation for each known object category,and feeding the masked depth pixels as well as an image patch cropped by the mask bounding box to the next stage.Second,point cloud data use the farthest point sampling algorithm to obtain the keypoints and map the keypoints to the color image and the depth image for feature extraction.Color and depth information in the RGB-D image are regarded as heterogeneous data.In the feature extraction process,the keypoints need to fully integrate the local and global information by regarding the color and depth information as heterogeneous data.The PSPNet module and PointNet++ module were used to extract color and geometric information for the RGB image and point cloud data,respectively.Then,a novel pixel-wise feature fu-sion was used to deeply fuse the local and global features of color and geometric information in the selected pix-els.Additionally,a multilayer perceptron was used to output the 6-DoF pose and confidence of each pixel.Finally,an end-to-end iterative pose refinement procedure further improved the pose estimation.Under the open dataset test,LineMOD and YCB-Video,the experimental results showed that compared with other similar existing methods,the proposed method has higher accuracy.Under the same evaluation metrics,the average precisions of the two datasets reach 97.2% and 95.1%,respectively,an increase of 2.9% and 3.9%.The network also meets real-time requirements,and it only takes 0.06s to complete the 6-DoF pose prediction of each image frame.
6-DoF pose estimation;deep learning;feature fusion;machine vision
10.11784/tdxbz202101024
TP391
A
0493-2137(2022)05-0543-09
2021-01-13;
2021-04-12.
王太勇(1962— ),男,博士,教授.
王太勇,tywang@tju.edu.cn.
国家自然科学基金资助项目(51975402);中国兵器工业集团公司基础性创新团队项目(2017CX031).
Supported by the National Natural Science Foundation of China(No. 51975402),the Basic Innovation Team Program of China North Industries Group Corporation Limited(No. 2017CX031).
(责任编辑:王晓燕)
猜你喜欢
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
建材发展导向(2022年3期)2022-04-19
今日农业(2021年8期)2021-11-28
中国科技纵横(2020年13期)2020-12-11
现代信息科技(2020年22期)2020-06-24
山东工业技术(2019年16期)2019-07-19
福建基础教育研究(2019年6期)2019-05-28
科技与创新(2018年12期)2018-06-22
广东教育·高中(2017年10期)2017-11-07
