
任务型对话系统中的自然语言生成研究进展综述
2022-03-10 01:25覃立波黎州扬娄杰铭禹棋赢车万翔
中文信息学报 2022年1期
覃立波,黎州扬,娄杰铭,禹棋赢,车万翔
(哈尔滨工业大学 计算学部,黑龙江 哈尔滨 150001)
0 引言
任务型对话系统能够帮助用户完成特定任务,所以近年来受到学术界和工业界的广泛关注。传统的模块化任务型对话系统[1]主要包括四个模块: 自然语言理解模块[2-4];对话状态跟踪模块[5-7];策略学习模块[8-10]和自然语言生成模块(NLG)[11-13]。本文主要关注任务型对话系统中的NLG模块(ToDNLG),其是模块化任务型对话系统中最重要的模块之一,用于将系统生成的对话动作转化为用户可以理解的自然语言回复。如表1所示,输入包含对话动作inform和槽值对(name=Blue Spice,priceRange=low,familyFriendly=yes),ToDNLG的作用是将输入转换为对应的自然语言回复: “The Blue Spice is a low cost venue. It is a family friendly location.”

表1 样例示例
近年来,随着深度神经网络和预训练语言模型的发展,ToDNLG的研究已取得了重大突破。但目前仍缺乏对ToDNLG现有方法和最新趋势的全面调研。为了回顾现有进展,并帮助研究人员在未来开展新的工作,本文首次对ToDNLG近10年来的发展进行了全面的调研和总结。而且,尽管目前ToDNLG模型在标准数据集上取得了显著效果, 但在实际应用中仍有许多问题需要解决。例如,现有神经模型无法对生成的回复进行解释,也无法在低资源场景下获得满意的效果。因此,本文对ToDNLG的前沿和挑战进行了详细总结,也为ToDNLG后续研究带来了新的理解和思考。最后,目前ToDNLG研究领域中没有一个开源的资源库来帮助研究人员快速了解进展,故本文也构建了ToDNLG模块的相关研究资源库。我们希望该资源库能够促进该领域的发展。
综上所述,本文贡献可以总结为以下几点:
(1) 整体总结: 据我们所知,本文的工作第一次对ToDNLG方向近10年的发展进行详细总结,包括非深度学习年代的ToDNLG模型和基于深度学习的ToDNLG模型。
(2) 前沿和挑战: 本文讨论并分析了现有ToDNLG的局限性,并且探讨了一些新的前沿领域和面临的挑战。供研究人员了解ToDNLG领域的最新进展、前沿和挑战。
(3) 丰富的资源: 我们收集了关于ToDNLG的丰富资源,包括开源实现、数据集和论文清单(1)https://github.com/yizhen20133868/Awesome-TOD -NLG-Survey。据我们所知,这是首个ToDNLG社区的开源资源库。。
本文组织结构如下: 第1节概述ToDNLG的背景;第2节介绍ToDNLG现有工作的全面调研成果;第3节讨论新的前沿领域及其挑战;第4节对全文进行总结。
1 背景
1.1 任务定义

M={D,(s1,v1),…,(sn,vn)}
(1)
ToDNLG的输出是将输入的MR经过一系列变化,转换成句法正确、语义准确、语句流畅的自然语言回复y=[y1,…,yT],其中,yi是回复y中的第i个词,T是生成回复的长度。综上所述,ToDNLG任务的形式化定义如式(2)所示。
y=NLG(M)
(2)
1.2 数据集描述
目前深度学习方法中常用到的数据集有Hotel[11],Restaurant[11], Laptop[12], Television[12]和E2E[14], 具体描述如下:
Hotel和Restaurant数据集的背景为在旧金山市的酒店、餐厅预订; Laptop和Television数据集的背景为购买笔记本电脑、电视产品;E2E数据集的背景为餐厅预订。
以上数据集详细统计如表2所示。

表2 数据集统计
1.3 常用指标
ToDNLG任务的常用指标为BLEU[15]和Slot Error Rate(ERR)。
• BLEU: BLEU指标是N-gram相似度的指标,用来衡量生成句子的流畅度。
• Slot Error Rate (ERR): 用来衡量生成句子与输入的slot-pairs的匹配程度,如式(3)所示。
(3)
其中,N是MR中所含槽值对的数量,p和q分别是生成回复中缺少和多余的槽位数量。
2 方法分类
任务型对话中的自然语言生成方法可以划分为传统方法和深度学习方法两大类。其中传统方法包括: (1)基于模板的方法; (2)基于句子规划的方法; (3)基于类的方法; (4)基于短语的方法。深度学习方法包括: (1)基于解码器的方法; (2)基于序列到序列的方法; (3)基于Transformer的方法。
2.1 传统方法
2.1.1 基于模板的方法
基于模板的方法(Template-based)是一种根据人工设计的模板直接生成自然语言的方法。每个模板分为两部分: (1)固定的自然语言模板; (2)需要根据对话动作中的槽值进行填充的槽位。此方法生成语言的步骤如下: 通过输入的对话动作选择合适的模板,再根据对话动作中的信息填充槽位。
基于模板的方法是最朴素的ToDNLG方法,在早期的对话系统中比较常见。Reiter[16]首次在论文中提出了基于模板的概念。Axelrod等人[17]在IBM公司的航班信息系统中加入基于模板的对话系统。Baptist等人[18]在开发对话系统GENESIS-Ⅱ时使用基于模板的方法提高外语和非传统语言的生成质量。Becker等人[19]将词汇化扩展到整个短语,并提出了基于模板的部分派生方法。
该方法的优缺点总结如下:
优点:简单、高效,产生的回复精准、易控制且质量较高(依赖于模板集的质量)。
缺点:可移植性差,不同的领域需要编写不同的模板,人工编写和维护的工作量较大。
2.1.2 基于句子规划的方法
基于句子规划的方法(Plan-based)通过引入句法树的结构,自动加入语言结构的信息,使得生成的句子更加流畅。基于句子规划的方法包括三个模块: (1)句子规划生成模块; (2)句子规划排序模块; (3)表层实现器模块。
句子规划生成模块:句子规划生成模块包含一系列人工设置的语句合并操作规则,这些合并操作可以将一系列较低层的谓词变元表示逐层地组合成更高层的深层句法结构。句子规划通常以句子规划树的形式呈现。句子规划树是二叉树,内部结点表示语句合成操作。句子规划生成模块会先将MR进行一些可能的排序,而后将其作为句子规划树的叶子节点,并转化为基本短句。最后再层级地加入作为非叶子节点的语句合成操作,从而生成不同的句子规划树。
句子规划排序模块: 此模块的任务是对句子规划生成模块生成的一系列句子进行排序,并将得分最高的句子送给最后的表层实现模块进行自然语言生成。排序器的具体实现通常使用RankBoost算法[20],这种方法可以进行自动训练和排序,将最好的句子规划输入下一个模块。
表层实现器模块: 此模块是将接收到的上一模块输出的句子规划转换成自然语言形式的最终回复。转换过程是基于各个语句合并操作的规则,在句子规划树上,自底向上、逐层地将所有子节点合并成父节点,最终生成自然语言回复。
在基于句子规划的方法中,Reed等人[21]首次提出了句子规划概念,构造了简单的分层规划框架;Reed[22]总结了基于句子规划方法显著性的含义和实现。Walker等人[20]提出了SPoT结构,将基于规划的方法分为了随机句子规划生成器和排序器,并提出了基于反馈自动训练的方法,提升了方法的效果。Stent等人[23]基于SPoT为对话系统构建句子规划器时,引入了更多的修辞关系组合,以建模句子内部的复杂信息。François等人[24]在处理对话系统时,将基于句子规划和基于模板的方法结合起来,并使训练过程可训练,因而模型能自动适应特定的领域。
该方法的优缺点总结如下:
优点:基于句子规划的方法使用了句法树,可以建模和生成复杂的语言结构。
缺点:同样需要大量的领域知识,可移植性和可拓展性差,对于新领域需要大量的人工工作,且效果并不一定优于基于模板的方法。
2.1.3 基于类的方法 (Class-based)
基于类的方法(Class-based)是一种统计方法,使用语言模型进行自然语言生成。此方法先构建话语类(Utterance Class)和单词类(Word Class)的集合,并为语料库中的语料标注话语类和单词类,然后将处理好的语料库依次输入两个模块: (1)内容规划模块,(2)表层生成模块。
内容规划模块:此模块的输入是系统回复的话语类别,输出是系统回复中应包含的单词类数量及应包含的单词类。该模块使用一个双阶段的语言模型来决定回复中应该包含哪些单词类。
在第一个阶段中,模型根据给定的话语类别统计出单词类的概率分布P(n|c),其中,c是待生成的系统回复的话语类别,n是系统回复应该包含的单词类的数量,再通过概率分布预测本句应该包含的单词类的数量。在第二个阶段中,使用bi-gram语言模型,单词类集合的概率分布为P(Sn|Sn-1),其中,Sn-1是前一条语句的单词类集合,Sn是待预测的当前语句的单词类集合。根据前一条语句中的单词类集合的概率分布预测系统回复中应该包含的单词类,参数估计一般使用最大似然法。为了减少待估计的参数数量,通常会做一些独立性假设,将估计单词类集合转化为估计P(si|sk),其中,si、sk是单个单词类别;i,k分别是预测单词类集合和前一条语句中单词类集合的下标。
表层生成模块: 此模块的任务是使用语言模型随机生成回复。训练阶段,先对语料进行去词汇化(将单词替换成相应的单词类),再对每一个话语类别,使用去词汇化后的语料建立N-gram语言模型。针对某一个话语类别生成回复的时候,使用相应类别的语言模型,用集束搜索的策略生成多个回复,再结合内容规划模块的结果,设计一些启发式的标准,对语言模型生成的多个回复进行打分,选择最高分的回复。最后用真实的值来填充其中的单词类,得到最终的自然语言回复。
基于类的方法由Oh等人[25]首次提出,他们在表层生成中使用了语言模型,减少了标记工作,增加了生成语言的速度。Barzilay等人[26]受到生物信息学的启发,将多序列对齐技术应用于映射字典获取问题,提高结果字典的准确性和表达能力,而且多种语言表达的存在有助于系统学习多种表达概念的方式。Belz[27]使用基于类的自然语言生成模型,半自动地创建了五个不同版本的天气预报生成器,且最好的生成器性能超过了专家预测。
该方法的优缺点总结如下:
优点:相比于之前的方法,基于类的方法使用了语言模型,在生成结果的流畅度、多样性上都有明显提升。
缺点:每个领域都需要手工创建类别集合,可移植性和可拓展性差。此外,语言模型的计算效率低,稀疏问题未能得到很好的解决,且该方法的独立性假设过强。
2.1.4 基于短语的方法
基于短语的方法 (Phrase-based)是一种基于统计的数据驱动型方法,将人工工作从模板的设计和维护转移到数据标注上。该方法在训练前需要对训练集中的句子以短语为单位进行对齐标注;训练时,将标注的结果,即一系列无序的强制语义堆(Mandatory Semantic Stack)送给语言生成模块生成自然语言回复。基于对齐标注数据进行语言生成比较简单,比较通用的方法是使用动态贝叶斯网络[28]生成回复。主要包括数据对齐标注和语言生成模块。
数据对齐标注:基于短语的方法需要对齐标注的数据,即用一个基于堆的语义表达去约束语义概念序列。每一个句子会被自动映射到一个短语层次的语义堆(Phrase-Level Semantic Stacks)。
语言生成模块:此模块的任务是输入一个含有多个强制语义堆的集合,生成最可能的回复序列。
基于短语的方法由François等人[28]首次提出,他们构造了一个统计语言生成器BAGEL,并使用贝叶斯网络进行学习,在小部分数据训练中和人类评估的效果接近。Dušek等人[29]提出的基于句法的方法是对基于短语方法的改进,它可以使模型利用大规模来对齐的标注数据。Lampouras等人[30]加入了模仿学习的方法进行结构性预测,并调整了局部最优学习搜索框架,在三个数据集上都达到了与最优方法相近的结果。
该方法的优缺点总结如下:
优点:该方法是数据驱动的方法,不依赖手工写成的生成器,可以用较少的参数建模长距离的依赖关系和特定领域的惯用短语。
缺点:需要大量的语义对齐处理,难以移植和拓展。标注数据的方法对结果影响很大,需要进行大量标注方式的尝试。
2.2 深度学习方法
随着深度学习技术的迅速发展,ToDNLG模块的研究趋势也从需要大量特征工程的传统方法中转移到基于深度学习的方法上来。
深度学习方法主要包括: (1)基于解码器(Decoder-based)的方法; (2)基于序列到序列(Seq2Seq-based)的方法; (3)基于Transformer的方法。其中基于解码器的方法首次开启了ToDNLG深度学习时代,基于序列到序列的方法首次借鉴了机器翻译领域的相关技术来提高性能,而基于Transformer的方法很好地解决了之前自回归方法因无法并行而效率低下的问题,以及模型上界不高的缺点。
接下来我们将详细描述这三种方法及其优缺点。
2.2.1 基于解码器的方法
如图1(a)所示,基于解码器的方法使用简单的编码方式(如One-hot向量)来表示输入,不需要通过编码器将输入进一步变化。而是直接使用RNN构造的解码器[31]来生成回复。此类方法通常分为语言生成模块和重排序模块。
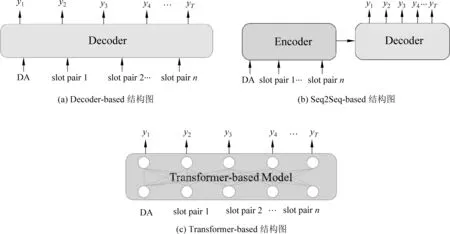
图1 深度学习方法结构图
语言生成模块的输入为语义表示,输出是多个可能的去词化(delexicalisation)的语句。该模块输入MR表示的编码,应用RNN及其衍生的神经网络结构,如LSTM、GRU[31-33]等,使用随机生成或集束搜索的方式输出多个可能的句子。而重排序模块的任务是将生成的多个去词化语句进行打分并排序,选出最好的语句并输出语句。一般使用CNN或者Backward RNN进行重排序。
Wen等人[34]首次将基于解码器的方法应用到ToDNLG任务中,提出了Recurrent Generation Model,如图2所示。Wen等人使用one-hot编码分别将对话动作DA和slot type进行编码,然后再将所有生成的one-hot向量拼接在一起,作为输入的MRs表示。为了能让模型在生成时能考虑到输入的MR语义信息,他们对RNN cell进行了修改,使其能够接受MR表示中的信息。在每个生成的时刻,生成的词表示是基于去词化后总词表的one-hot向量,并使用一个门控向量来控制每个时刻接收多少MR信息。生成多个可能的句子后,使用CNN或者Backward RNN进行重排序。当使用CNN时,一般的做法是经过卷积层、池化层和全连接层,生成表示候选句所含MR表示的multi-one-hot向量。这个multi-one-hot向量以模型输入的MR表示作为参考进行评分。而Backward RNN的方法会将输入的去词化语句逆序输入到RNN模块,通过计算后向RNNLM的对数似然进行重排序。Wen等人[11]基于Recurrent Generation Model,进一步对LSTM cell进行了改进,提出了SC-LSTM模型。SC-LSTM cell引入了语义控制模块。对于每个时刻输入的语义信息,使用GloVe词向量[35]编码,然后根据当前输入的单词和上一时刻的隐层来得到门控值,通过门控的方式传递,更新当前的语义控制向量。而语义控制向量则会参与到LSTM cell的当前状态计算中,从而达到语义信息控制的目的。
该方法的优缺点总结如下:
优点:开创了在ToDNLG使用神经网络方法的先河,同时使用了语言模型和神经网络方法,生成的语句具有多样性,且减少了人工特征干预。
缺点:使用语义控制的one-hot编码含有的信息较少,设计较为简单;生成语句的标准太简单,搜索空间小,有时无法得到较好的结果。此外,模型无法应对二值化的或者无法去词化的slot情况。
2.2.2 基于序列到序列(Seq2Seq)的方法
随着Seq2Seq类的模型在机器翻译等领域取得了较好的效果[36-38],近年来有一些工作开始探索Seq2Seq在任务型对话自然语言生成中的应用,如图1(b)所示。
该类方法在编码器端,对于输入的MR,DA使用one-hot向量表示,而对于每个槽值对,对它的槽位和槽值分开进行编码操作,然后将它们的表示相加得到这个槽值对的表示。在解码时,采用自回归的方式,引入注意力机制,生成回复。
Dušek等人[39]探索了用Seq2Seq方法生成句子规划树和直接生成自然语言回复这两种方式的优劣性,如图3所示。其工作首先对输入的MR进行处理,对于每个槽值对,都将对话动作表示加入其中,形成DA-slot type-slot value三元组,然后将这些三元组拼接形成输入序列。编码器使用LSTM编码,解码器使用LSTM结构和注意力(attention)机制进行解码,使用句子级别的注意力分数与每个词的加权和,生成自然语言。实验结果表明,使用Seq2Seq方法比直接生成自然语言回复的方式更好。Wen等人[40]参考内容选取领域的研究,提出了适应于ToDNLG的一种基于注意力机制的Encoder-Decoder架构,取得了比基于解码器的方法更好的效果。Dušek等人[41]从他们的上一个模型出发,引入了语言模型的信息。他们在保持模型总体框架不变的情况下,对输入进行了改进,将用户的话语拼接在输入的MR三元组前面,作为前置的上文;且新增加了一个上文编码器,单独对用户话语进行编码。然后将两个编码器的结果进行拼接得到解码器的输入。Tran等人[42]对Wen等人[40]的工作的了进一步的修改,他们在Encoder与Decoder之间增加了一个聚合模块Aggregator。Aggregator的目标是更好地利用语义信息对当前时刻输入的词进行处理。Agarwal等人[43]提出了Char2Char的生成模型,将MR转为字母级别的输入,从而免去了去词化步骤,输出时也采用了字母级别的生成。Juraska等人[44]提出了Slug2Slug模型,认为槽位与回复语句中片段的语义对齐十分重要,他们将这个对齐引入到数据预处理和重排序模块中,在E2E数据集上取得了当时的最佳效果。

图3 Dušek等人文中的模型结构图及示例
该方法的优缺点总结如下:
优点:相较于Decoder-based模型,Seq2Seq模型通过注意力机制的encoder-decoder架构,能够更好地编码MR输入,并且将输入中包含的语义信息加入到解码阶段中,获得了较好的效果。
缺点:对于MR输入,只将其视为一个序列进行编码,而忽略了其中的结构化信息。Encoder-decoder采用的自回归建模范式无法并行化处理,导致模型训练的时间较长。
2.2.3 基于Transformer的方法
随着Transformer结构的提出和发展,其在ToDNLG生成领域的各种变体也受到了广泛关注,如图1(c)所示。
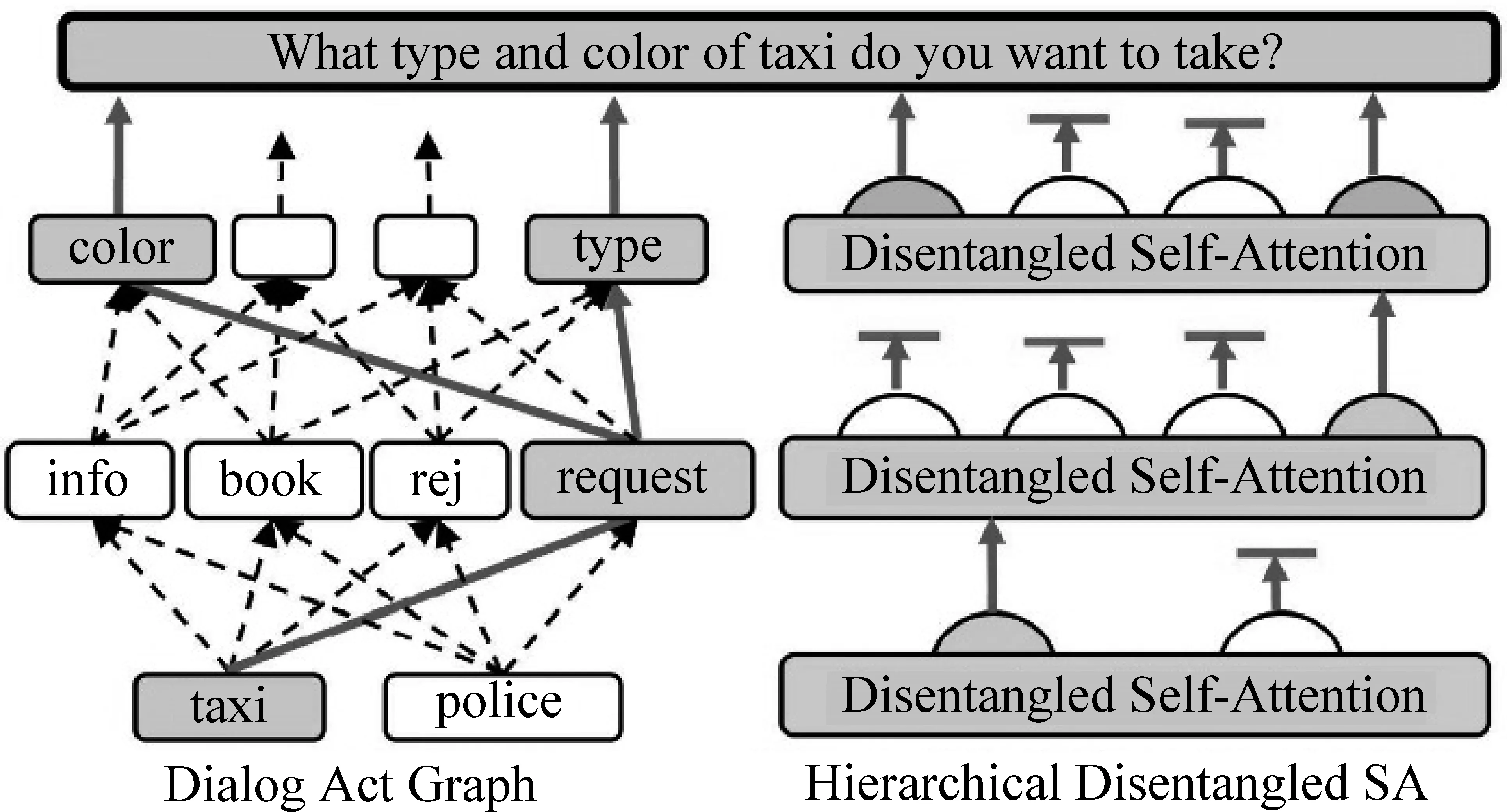
图4 Chen等人文中的模型结构图及示例
Chen等人[45]提出了SC-HDSA,如图4所示。之前关于MR的利用中,大部分工作忽略了MR之间的关系,将MR视为序列输入。而Chen等人关注MR的结构信息,使用了一个图式的结构来掌握语义信息,将MR分为领域—对话动作—槽位三层结构。在解码时,联合带有多抽头注意力的分层Transformer语言生成结构。标准的Transformer结构将不同的多抽头输出拼接成一个输出向量。SC-HDSA模型则是在每一层根据输入的分层MR结构,激活特定的多抽头,从而更好地控制信息传递的方向,获得了较好的效果。Peng等人[46]提出SC-GPT模型,将MR平铺输入到GPT预训练模型中,使用序列到序列的方法直接获得结果。Kale等人[47]认为预训练模型在预训练阶段使用的语料和微调时语料中的MR结构化输入有所区别,他们尝试使用了基于模板的转化方式。使用Text-to-Text Transfer Transformer(T5)构造的encoder-decoder模型进行训练,获得了比SC-GPT模型更好的效果。
该方法的优缺点总结如下:
优点:Transformer-based的模型可以通过预训练机制提高模型建模语言的能力,跨时序的注意力机制能够对结构化的MR输入进行更好的处理,达到了目前最好的效果。
缺点:基于Transformer-based的模型需要更多的数据进行训练,并且基于预训练Transformer-based的模型需要更多的计算资源。
基于深度学习方法的ToDNLG实验结果总结如表3所示。
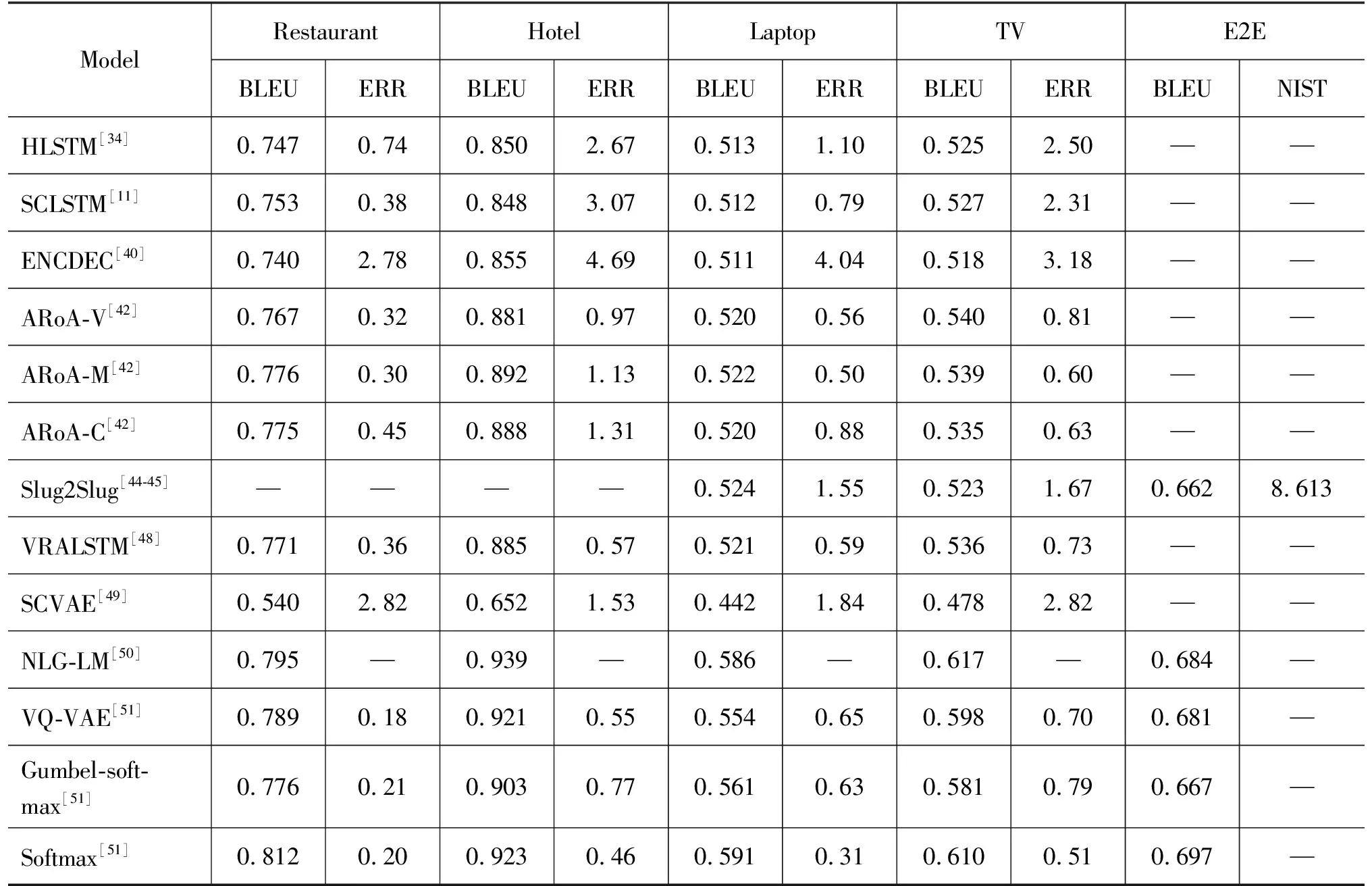
表3 基于深度学习方法的ToDNLG实验结果总结
3 前沿及挑战
3.1 跨领域ToDNLG
由于深度学习和预训练模型的发展,现有ToDNLG已经取得了很好的性能。但现有的ToDNLG模型依赖于大量的标注数据进行训练,限制了它们扩展领域的灵活性。且在真实应用场景中,为每个新领域收集丰富的标注数据集是不可取的。因此跨领域ToDNLG研究越来越受到关注。跨领域ToDNLG旨在利用多个源领域下的训练语料来帮助学习一个或多个目标领域的自然语言生成。
Wen等人[40]首次进行多领域ToDNLG的探索,他们提出首先将模型在合成的跨领域数据集上进行训练,然后在领域内数据集上进行微调的做法。这个方法在一定程度上能够实现多领域之间的知识迁移。Tran等人[48]提出了一个对抗式训练方法,加入多个适应步骤,并构建了相似度评价标准产生域不变特征,帮助生成器从源域到目标域进行有效的学习。Tseng等人[49]利用条件变分自动编码器架构,在生成过程中用句子层面的全局隐变量信息来改进基于解码器的模型。当测试在迁移领域内传达所需信息的能力时,模型显示出很好的效果。
跨领域的ToDNLG主要面临的挑战如下:
领域数量庞大: 在应用场景中,领域数量会迅速扩增,如何在巨大的领域之中迁移有利的领域知识,而避免有害的负迁移是一个值得探索的问题。
Zero-shot跨领域迁移: 当目标领域没有任何标注语料,如何建模源领域和目标领域的相关性进行有效的迁移是一个挑战。
3.2 可解释ToDNLG
如今,端到端神经网络已经在ToDNLG中取得了很好的表现。然而,现有的模型都采用神经网络,往往被视为一个黑盒结构。基于神经网络的ToDNLG模型无法对每个单词的生成产生合理可信的解释,不具备良好的可解释性。
为了解决这个问题,Li等人[50]提出了一个新的框架——异构渲染机(HRM)。HRM由一个渲染器集和一个模式切换器组成。在每一个生成步骤均显式地判断每个生成单词的类型。通过这个过程,模型可以清楚地解释每一个单词的来源和生成过程。该工作迈出了可解释性ToDNLG的第一步,非常具有启发意义。
可解释性ToDNLG主要面临的挑战如下:
性能损失: HRM尽管在一定程度上提高了模型的可解释性,但是也降低了准确率,如何在提高可解释性的同时又不降低模型的性能是一个有意义的课题。
端到端训练: 现有可解释性模型为了显式地解释每一步生成,无法进行端到端的训练。如何进行整体端到端的训练是一个值得被探索的研究方向。
3.3 多任务学习
多任务学习指的是通过联合学习多个相关的任务来提高各个任务的学习方法,已经在自然语言处理领域取得了很好的效果。近些年来,在ToDNLG领域,也有一些研究人员利用多任务学习去学习其他任务的知识,并将其迁移到ToDNLG上来提高ToDNLG的性能。
Zhu等人[51]提出NLG-LM架构,同时训练ToDNLG和语言模型(LM),借助同时训练语言模型来保证生成流畅的句子。Su等人[52]提出使用对偶监督学习来同时建模NLU和ToDNLG任务,利用ToDNLG的对偶任务NLU的知识来提升NLG的性能。
多任务学习ToDNLG主要面临的挑战如下:
有效迁移:如何找到合适相关的其他任务来完成多任务学习,从而进行有效迁移,是一个挑战。
高效率:多任务学习往往通过牺牲时间效率来提高性能。如何利用多任务学习的优势,又保证单任务学习的时间效率值得被关注。
3.4 低资源ToDNLG
目前基于神经网络的ToDNLG模型都依赖于大量的标注数据进行训练,但是在真实应用中,很难对每一个新的场景去标注充足的数据。因此,如何在少量训练数据下进行ToDNLG模型的训练,也能取得不错的效果是目前的一个研究趋势。
Peng等人[46]提出SC-GPT,直接利用预训练模型GPT来进行小样本ToDNLG训练。将MR展平为序列作为输入来生成回复。该方法是对小样本ToDNLG领域的首次探索。Xu等人[53]认为,尽管SC-GPT模型在小样本ToDNLG上的应用取得了一定的效果,但模型没有进一步提升效果的能力。因此想尝试使用数据增广的方式来提高小样本ToDNLG的效果。将自训练的神经检索模型与小样本NLU结合,能够自动地从开放域的文本中自动创建ToDNLG的数据。该方法与前人的方法是正交的,可以将这些新数据与前人方法结合来获得更好的效果。
低资源ToDNLG主要面临的挑战如下:
结构融入:低资源场景下,如何有效融入ToDNLG的结构信息来提高性能,目前还没有得到足够的关注。
泛化性:低资源场景下,如何使训练的ToDNLG模型具有良好的泛化性是一个值得关注的课题。
3.5 复杂ToDNLG
目前的ToDNLG模型均只能考虑较为简单的场景: 即输入单个MR,也就是包含一个对话动作和与其对应的槽值对来进行对话系统回复的生成。但是现实场景较为复杂,在生成回复时,往往可能需要考虑多个MR输入,也就是多个对话动作和对应的槽值对,这样能够满足一些真实复杂场景的需求。近些年来,也有一些研究人员在该复杂ToDNLG方向进行了探索。
Balakrishnan等人[54]首次考虑了多个MR输入ToDNLG,提出了一个新的数据集,对多个MR进行处理,包括定义这些MR之间的关系,如约束关系、并列关系等。这篇文章是复杂ToDNLG方向的首个探索,具有推动该领域发展的意义。
复杂ToDNLG主要面临的挑战如下:
复杂建模:如何有效地建模多个MR之间的关系是一个待解决的挑战。
4 总结
本文完成了任务型对话系统中的自然语言生成模块(ToDNLG)全面调研。基于对最近工作的系统分析,本文首先对近10年的ToDNLG方法进行了总结归纳。此外,考虑到最近ToDNLG系统的局限性,本文分析并讨论了该研究领域的发展趋势。最后,本文提供一个开源网站,包括ToDNLG数据集、论文、基线项目,希望该网站能够促进ToDNLG社区的发展。
猜你喜欢
建材发展导向(2022年23期)2022-12-22
建材发展导向(2022年20期)2022-11-03
军事文摘(2022年17期)2022-09-24
建材发展导向(2022年12期)2022-08-19
家庭影院技术(2021年8期)2021-11-02
考试与评价·高二版(2020年2期)2020-09-10
计算机世界(2020年50期)2020-01-15
阅读(快乐英语高年级)(2020年8期)2020-01-08
青年生活(2019年23期)2019-09-10
智慧少年·故事叮当(2018年11期)2018-05-14
