
基于元学习的不平衡少样本情况下的文本分类研究
2022-03-10 01:25熊伟,宫禹
中文信息学报 2022年1期
熊 伟,宫 禹
(1.华北电力大学(保定)计算机系, 河北 保定 071000) (2.华北电力大学(保定)复杂能源系统智能计算教育部工程研究中心, 河北 保定 071000)
0 引言
深度学习在图像[1-2]、自然语言处理[3-5]等领域已获得巨大成功。但由于有效标注数据获取代价高昂,通常很难获得大量带标注样本,因此将少样本学习方法应用于深度学习已成为一种新的研究方向[6]。元学习基本方法包括MAML[7]、原型网络[8]、关系网络[9]。但是如果将元学习框架直接应用于自然语言处理领域,则面临着语义、语境迁移困难等问题[10]。
在计算机视觉领域,底层信息(如边缘、形状等)及其相应表示可以在任务间共享。然而,大多数自然语言处理的相关任务是在词汇层面上进行的[11-12]。由于语义的多样性,以及语境的复杂性,在一项任务中包含很多信息的单词,可能在其他任务中无任何意义;对某一个类别具有突出分类贡献的单词,对其他类别分类可能没有太大作用。相关实验表明,当元学习被直接应用于自然语言处理方面时,其性能会低于一个简单的最近邻分类器,这进一步说明了传统意义上的元学习无法放大重要文本信息特征。例如,当考虑目标阶层(中年人的生活方式)时,标准原型网络关注诸如“date”之类的非信息性词语,而淡化诸如“grandma”之类的高度预测性词语。
文本的底层信息包括词汇、语境、语义、分布信息。尽管文本信息中存在上述较难迁移的问题,但是使用本文方法依然可以有效使用跨类信息,使信息更具迁移性[11,13]。通过实验发现,尽管文本中语义、语境很难迁移,但它们的分布信息是相似的。因此,本文专注于学习单词重要性和单词分布之间的联系,即不直接考虑单词,而是重点关注潜在单词分布的特征。由于这些特征在分类任务中表现出一致的行为,从而可以更好地表达单词的重要性,且此种特征并不局限于某一类别,因此在一定程度上可以达到跨类别分类的目的,使其迁移性更强。在元学习框架下,这些特征可以使模型将注意力转移到不同的任务上,从而可以用来衡量单词的词汇表征[14-15],能够对字级、词级、句级等信息进行充分的发掘,使模型能够更好地使用底层文本信息。这种应用分布式特征的一个常见例子是TF-IDF加权,其根据单词在文档集合中的频率来明确指定单词的重要性。
本文所提出的模型对传统TextCNN[16]网络结构进行优化,引入动态卷积[17],提高网络提取特征的能力,最后使用元学习中主流的MAML模型中双层优化的方法,使其自动寻找到最优的参数结果。与此同时,本文考虑了现实世界中常常被忽略的数据不平衡问题,主要包括数据选择不平衡(class chosen imbalance)以及数据不平衡(class imbalance)。数据选择不平衡产生的原因是在进行训练构建新的数据组时,每次类别的选取可能会出现很大的差异,导致模型无法充分学习每一种类别所包含的信息,数据不平衡产生的原因是来自于各个类别的数据量的差异过大,出现数据不平衡的情况,导致训练不充分。为了解决上述问题,本文提出一种新型的平衡模型。根据输入获得数据的均值、方差等数据集的特征信息,由此网络可以自动学习平衡变量(balance variable),以此来控制数据不平衡的程度。
本文提出的模型主要分为三个部分,首先是数据集平衡变量产生器,通过数据集的统计信息特征来生成平衡变量,以此来控制数据不平衡的程度。其次为文本注意力生成器,通过学习数据的分布式特征生成注意力分数,以反映单词在分类中的重要性。最后将平衡变量、注意力信息输入到模型中,以此获得较好的分类准确率。实验表明,本文提出的方法在传统文本分类数据集上取得了较好分类效果,相比于现有的方法,其准确率有一定程度的提升。
本文主要贡献包括:
(1) 将元学习应用于文本处理领域,并考虑到了语义、语境迁移较难的问题,提出一种基于分布式特征的方法,在一定程度上解决了文本信息底层特征无法迁移的问题。
(2) 考虑到真实世界中容易被忽略的数据不平衡问题: a.数据不平衡;b.数据选择不平衡,通过处理数据集的统计特征信息产生平衡变量,以此降低不平衡的程度。
(3) 使用动态卷积层代替传统的卷积层,对TextCNN网络进行优化,提升了网络提取特征能力。
(4) 本文所提出方法经过实验比对,较现有的少样本学习方法在准确率有一定程度上的提升。
1 相关工作
1.1 元学习


图1 元学习整体框架
实验结果表明,该方法在几乎不影响分类准确率的同时,大大降低了模型的计算复杂性。但此种方法会导致信息丢失。因此Nichol等人[18]提出一种新的一阶梯度近似算法Reptile。实验表明,该模型不存在由于一阶梯度近似而导致部分信息丢失的情况,在很大程度上降低了模型的复杂性,增加了网络的可计算性。
如图2所示,每一个任务具有训练集和测试集,为了区分元学习与机器学习中的训练集和测试,在元学习中,将训练集称为支撑集(support dataset),测试集称为询问集(query dataset)。

图2 元学习与机器学习
图3中,对于传统的机器学习,模型根据数据寻找一个分类函数f(),分类函数f()类似于卷积神经网络(convolution neural networks)这样的由人为设计的算法或网络。训练完毕后输出参数θ,参数θ决定f()。相比于机器学习,Meta-learning[19]寻找F,通过F在若干个任务上训练来生成所需要的参数。在遇到新的分类任务时,使分类器可以调整成适合新任务的分类模型。可以认为传统的机器学习是为了获得一种根据数据找特定函数的能力,而元学习则是为了获得一种根据数据找一个函数f()的的能力。
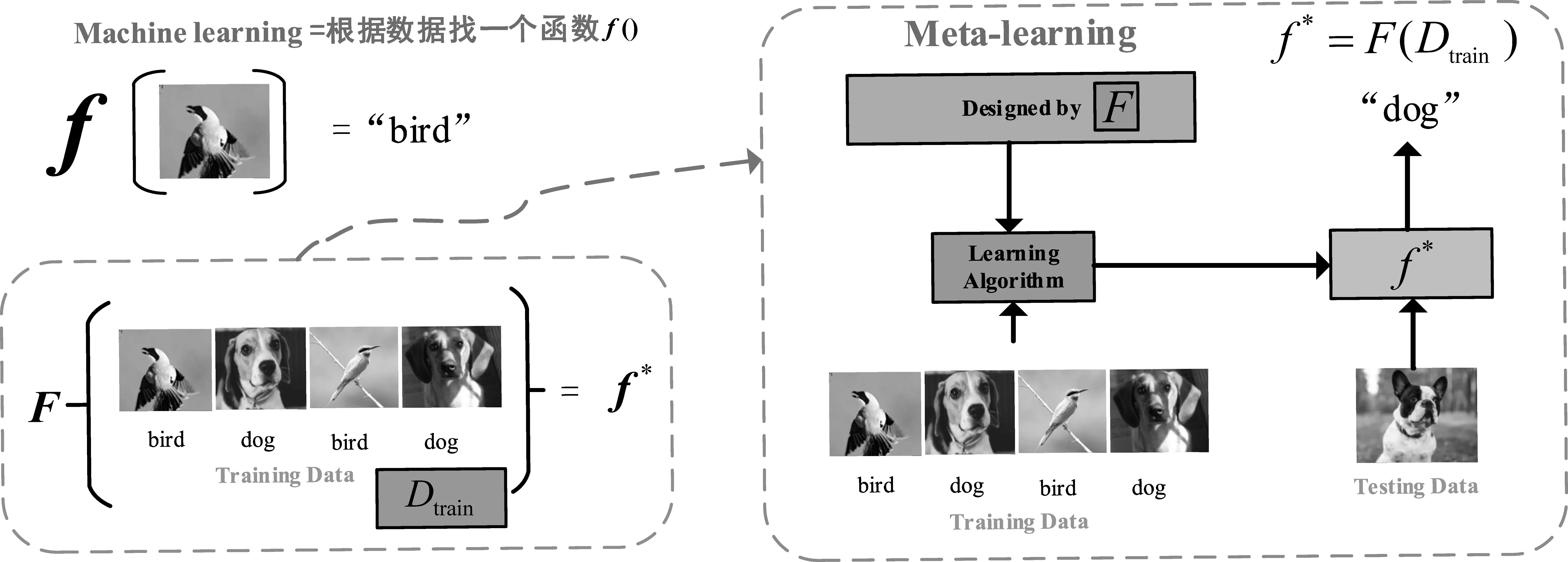
图3 元学习与机器学习模型概况
1.2 文本分类
在传统机器学习中,SVM[20]、朴素贝叶斯分类等方法都曾应用于自然语言处理领域。但是机器学习方法需要人为手动设置参数,标注特征,将数据输入分类器,最终获得分类结果。这种方法降低了模型的可靠性与准确性。
随着深度学习的不断发展,一些深度网络模型被应用于自然语言处理领域。与传统机器学习相比,深度学习能够自动学习文本特征,大大地提高文本分类的准确率。
常见的深度文本分类模型主要有TextCNN、CharCNN[21]、Bi-LSTM-Attention[22]模型,以及将两者优点融合的RCNN[23]模型。TextCNN 是一种利用卷积神经网络对文本进行分类的算法,将词向量拼接在一起。与基于词级文本分类方法不同,CharCNN中提出了一种字符级文本分类模型,在此之前,很多基于深度学习的文本分类模型都是基于单词(统计信息或者N-grams[21]、Word2Vec[24]等)、短语(phrases)、句子(sentence)层面,或者对语义和语法结构进行分析,但是CharCNN则提出了从字符层面进行文本分类,提取出高层抽象概念。Bi-LSTM-Attention 是在Bi-LSTM[15]模型上加入注意力机制,在Bi-LSTM模型中,使用最后一个时序输出向量作为特征向量, 注意力分数(Attention)先计算每个时序的权重,然后将所有时序向量进行加权,作为特征向量,最后使用softmax对数据进行分类。
对比于之前的机器学习,基于深度学习的文本分类方法虽然可以自动提取文本特征信息,但由于深度学习需要大量带标记数据以及需要强大的计算能力的特点,这便极大地限制了相关深度学习网络模型在自然语言处理领域的发展,因此本文研究了基于少样本情况下的文本分类方法,即少样本文本分类任务。
1.3 动态卷积网络
传统卷积网络在图像处理任务中取得了巨大成功。一般来说,网络结构深度越深,网络性能越高。但随着网络结构深度加深,经常会有梯度消失的情况发生。为了解决这一问题,He等人[25]提出ResNet网络,在很大程度上解决了随着网络深度加深所带来的梯度消失的问题,同时有文献[26]在ResNet基础上增加了网络结构的宽度,进一步提升了网络的特征提取能力。但上述方法均采用传统卷积神经网络,当受到计算约束时,轻量化卷积神经网络的性能会有所下降。为了解决这个问题,文献[17]提出动态卷积网络,可以在不增加网络深度的情况下提高模型性能。动态卷积生成器为每个输入动态生成卷积核。
动态卷积生成器的结构如图4所示。动态卷积生成器对每个输入进行处理,为每个输入动态生成一个卷积核。

图4 动态卷积核生成器
1.4 SENet网络
SENet[27]网络对通道施加注意力机制(图5),本质上,这种注意力机制使模型着重关注信息量最大的通道特征,而抑制相对不重要的通道特征。论文提出使用全局平均池化,对每个通道H×W个数字进行处理,使用一个标量来代表该通道信息。再通过FC-ReLU-FC-Sigmoid得到C个0到1之间的标量,作为通道权重。最后将原始输出通道与每个通道对应权重进行加权(对应通道的每个元素与权重分别相乘),得到新的加权后特征。

图5 SENet整体架构
本文提出采用全局平均池化策略,将全局空间信息转换为一个通道描述符,具体如式(1)、式(2)所示。
其中,c为输入变量通道数,H,W分别代表图片高、宽。首先利用式(1)对输入图片进行处理X∈RW′×H′×C′→U∈RW×H×C,再使用式(2)对图片进行池化处理,最后将每一个通道的全局信息通过全局平均池化方法变成一个标量,此标量用来代表通道信息。除了采用全局平均池化策略外,也可以采用聚合策略来描述这个通道。通过激发(excitation)操作将全局信息进行共享,如式(3)所示,将各层信息进行融合。Excitation操作力求获取各通道信息依赖关系。将1×1×C信息进行全局信息共享。
s=Fex(z,W) =σ(g(z,W)) =σ(W2δ(W1,z))
(3)
在图像处理中,一张图片包含若干个通道。基于此思想,将通道引入到自然语言处理的卷积网络TextCNN中。
对句子进行分词处理,设单词数为s,根据嵌入矩阵可得词向量,设词向量为d维,便可以得到矩阵A∈Rs×d,将矩阵A类比为图片,使用卷积神经网络提取特征。由于句子中单词有很强的关联性,所以在本文中采用一维卷积对文本进行特征提取操作,即文本卷积与图像卷积的不同之处在于只在文本序列的一个方向(垂直)做卷积操作,卷积核宽度固定为词向量维度d。可设置超参数h,对于每一个输入进行卷积操作获得特征图,如式(4)所示。
C=[c1,…,cs-h+1]
(4)
图像数据和语言数据之间的可转移知识存在着内在差异,而传统元学习器无法在标准多类分类数据集上进行推广。相关实验表明,即使文本信息中重要特征无法转移,但其分布信息是极其相似的。因此,本模型将专注于学习单词重要性和分布信息之间的联系。综上所述,本文提出的模型可以准确地识别出新类中的重要特征。由上可知,完全可以将动态卷积方法应用于自然语言处理领域。
2 TADCB 网络结构
本文所提出的TADCB(TextCNN+Attention+Dynamic Convolution+Balance)模型目标是通过学习输入分布式特征,以及数据集统计信息,来获得高质量注意力分数以及平衡变量,从而提高少样本分类性能。在进行训练前,对数据进行编码获得数据集样本信息,生成可变平衡变量,在某一特定轮次中,从原始数据集分数池(source pool)和支撑集合(support set)中提取相关统计信息。根据统计信息估计出单词对分类重要性,利用注意力生成器生成注意力分数来提高信息利用率,进而提高文本信息可迁移性,为接下来的特征提取器以及分类器提供高质量数据信息并提供指导方向。
2.1 网络结构设计
本文提出一种基于元学习的少样本情况下的文本分类模型。首先对数据集进行两次编码,将编码后的数据传入平衡变量生成器产生平衡变量处理不平衡问题,将原始数据信息传入注意力分数生成器。遵循元学习双层优化思想对本文提出模型进行训练,网络整体架构如图6所示。

图6 网络整体架构
首先将训练集、验证集数据传入编码器(Encoder)以及平衡变量生成器(Balance generator)中,前者用于将文本数据转换为词向量,并进行特殊编码,后者产生平衡变量ω,γ以平衡数据不平衡以及数据选择不平衡问题,二者共同作为模型的输入,使用元学习双层优化思想对网络权重w与参数θ进行更新,训练集数据用于训练模型参数θ′,验证集数据用来更新模型参数θ,传统MAML模型使用卷积神经网络进行特征提取,此处使用动态卷积层代替传统卷积层以提升特征提取能力,最后使用softmax分类器用来预测每一类别概率。
2.2 注意力生成器
在元学习训练阶段,首先在训练集中选取N个类别,之后在这N个类别中构造支撑集会以及询问集合,最后使用剩余类别来构造分数池。在元学习测试阶段,从测试集中选取N个从未见过的类别,并用这N个类别构造支撑集合以及询问集合,最后使用测试集所有样本来构造分数池(source pool)。
注意力生成器目标是从每个输入分布特征中评估单词的重要性。利用分数池来生成全部单词注意力分数,并利用支撑集合来估计特定于某类的单词注意力分数。
根据分数池和支撑集合数据的分布信息输出一个对于特定输入x的注意力分数α。使用分布式信息为输入增加鲁棒性,如图7所示。

图7 关于数据集的单词注意力分数
以整个训练集计算每个词得分为例,每个词分数作为分数1,将分数1与其他得分相结合,以产生最终注意力结果α。分数1计算如式(5)所示。
(5)
probability(a word)利用TF-IDF方法来计算某一单词在整个数据集中的频次与重要性,其根据单词在文档集合中的频率及其在特定文档中的频率来明确指定单词的重要性。可以观察到,如果这个词出现的频率比其他词高,那么它的重要性就比其他词低。换句话说,频繁出现的单词不太可能提供有效信息。TF-IDF计算如式(6)所示。

(6)
IDF为逆向文件频率,如式(7)所示。

(7)
计算所有单词的分数,得到如图7所示的图表。
对于支撑集合,每个单词注意力计算方法与图7(a)类似。
相关研究[17]表明,频繁出现的词大多情况下是没有语义价值的。因此,要降低频繁词的权重,提高稀有词的权重。为了衡量一般词的重要性,本文选择了Arora等人[28]建立的方法,如式(8)所示。
(8)
另一方面,同一个词的重要性在支撑集中和询问集中是有区别的。因此,本文定义以下统计数据来反映某个单词对于某一类别的重要性,如式(9)所示。
t(xi) =H(P(y|xi))-1
(9)
其中,使用正则化线性分类器在支撑集上估计条件似然P(y|xi)。H(·)为熵算子,由于注意到度量类标签y的不确定性,因此,呈现偏态分布的词将被高度加权。
对经过注意力分数加权后的属于相同例子的输入和输出进行可视化操作,如图8所示。本文所提出模型产生的注意力权重与任务关联性极强。可视化模型的输入为s(x)(上部), 模型的输出为t(x)(中部)以及本文模型所产生的输出our(x)(下部)。首先,可以观察到,本文提出的模型从有噪声的分布特征中确定了对于分类有效的信息。此外,对于在专属任务(task-specific)所生成的例子中,如果这一批次的例子中包含其他与人类学相关的类,“man”一词就会被模型淡化。相反,当本批次的任务中并没有与“人类学”相近的类别时,那么“man”一词对于该类别的分类会有突出贡献。

图8 输入数据注意力可视化
2.3 数据编码
基于数据集D,通过一些统计方法(即“Mean、var和Set cardinality”)捕捉统计信息,以此识别类别不平衡。但传统的非层次结构会忽略标签信息,性能较差。因此,本文使用了两层分层结构,第一层是将类别编码为一系列样本,然后将集合编码为类集合。本文引入了一个两层的分层集合编码,此外,了解到求和池化(sum-pooling)有一个限制,即无法计算集合的数目。作为补充,本文还对集合的方差进行了编码。将集合编码器称为统计池化(StatisticsPooling),它生成一系列集合,统计均值、方差和基数。
在表1中可以通过一项消融实验研究来讨论数据集编码的有效性。Mean和Var分别表示数据集的均值和方差,N代表集合基数。可以发现,元素样本Skewness和Kurtosis很难提高性能,集合基数具有更好的性能。

表1 数据集编码消融实验
2.4 平衡变量生成器
平衡变量的生成过程如图9所示,它扩展了n-way-k-shot的定义和任务生成过程。D包含了训练集DT={XT,YT}以及测试集,如式(10)所示。
(10)

图9 平衡变量生成网络整体架构
在每个轮次中,随机选取n个类,k个实例属于这n个类。在这里,本文发现有两种不平衡,分别为: 数据不平衡(class imbalance)和数据选择不平衡(class chosen imbalance)。然而现有的少样本学习方法并没有考虑到上述的不平衡情况,阻止模型有效地解决实际问题。
① 数据不平衡: 少样本方法没有任何结构来处理类别不平衡问题,因此含有较多样本的类别,在训练阶段会占据主导地位,使该类特征被充分学习。然而含有较少样本数的类别在模型中表达得并不充分。(类别A包含500个样本,类别B包含10个样本)
river basin in Dongchuan PENG Rui GAN Shu GAO Sha et al.(9)
② 数据选择不平衡: 在之前的工作[29]中,已经知道如何构建一个n-way-k-shot任务,随机选择导致了数据选择不平衡,某些类会被多次选取,而其他类被选择次数较少,选择次数多的类别可能会学习得更加充分,但也存在着过拟合的情况,而被选择次数少的类别被学习到的特征便会很少。当数据集非常大并且有很多类别时,这种不平衡可能非常严重。被选中的类别往往学习更充分,反之亦然。最后,总有一些类别的选择次数远远大于其他类别,这将导致训练不足,影响分类器的性能。
2.4.1 处理不平衡
针对上文出现的两种不平衡问题,本文提出如下解决方案。


③ 假设所有提出的变量都被集成到原始的元学习框架中,并且更新规则被改变如式(11)所示。

(11)
其中,α为全局学习率,∘为乘法算子,k=1,…,K。
2.4.2 产生平衡变量
如图9所示,本文模型引入了γ、ω两个平衡变量来降低数据不平衡所带来的影响。首先,将数据输入到NN1网络进行处理。所得结果由统计池化处理,得到统计数据,如平均数、方差和集合基数。然后,由NN2网络处理所得结果。再次通过统计池化处理获得过滤后的统计数据。利用Mean、Var、SC的原始统计数据以及过滤后的相关数据,生成平衡变量。

2.5 变分推理

(14)

图10 变分推理
遵循具有可训练均值和方差的单变量高斯分布。p(ψT)服从N(0,1)分布。最后带有蒙特卡洛近似的目标函数如式(17)所示。
(17)
为了提高计算效率,在式(18)中设置S=1,而在测试阶段设置S=10。
3 实验与分析
3.1 数据集
本文使用THUCNews[30]中文文本数据,包括10个类别。IMDb[30]数据集—互联网电影资料库(Internet Movie Database)是一个关于电影演员、电影、电视节目、电视明星和电影制作的在线数据库。数据集基本信息如表2所示。为模拟数据不平衡现实情况,需要对数据集进行特殊处理。

表2 数据集统计信息
3.2 数据预处理
3.2.1 模拟数据不平衡
为模拟数据不平衡的情况,首先对数据进行处理,对于数据不平衡问题,总类别假设为N,对K中类别的数据进行裁剪,使其数据与剩余的N-K类数据中的数据量相差超过50%;对于数据选择不平衡问题,是由于算法本身所存在,可以不用进行特殊处理。
3.2.2 数据清洗
进行数据清洗工作,去除无效、错误字符,进而使用Word2Vec来对本文数据进行词向量构建,确定Word2Vec所需要的超参数。定义维度为m,第i个词所对应的词向量为ai∈Rm。对于Skip-gram模型,当前词为w,对其上下文进行预测Context(w)目标函数如式(20)所示。

(20)
在卷积神经网络中,一般会用多个大小不同卷积核,每个卷积核可以抽取特定n元语法特征,如式(21)所示。
ci=f(wi: i+h·xT+b)
(21)
其中,wi:i+h是从i个词开始的连续h个词对应的词向量的拼接,h是卷积神经网络 卷积核的宽度,b是偏置项,最后将所有位置的输出拼起来便得到特征映射向量c=[c1,c2,…,cn-h+1]。由于本文采用动态卷积层,所以对于每个输入动态生成卷积核,如式(22)所示。
(22)

(23)

(24)

使用改进后的TextCNN模型作为MAML的元学习器,对数据进行特征提取。首先经过改进的DCMAML(Dynamic Convolution MAML)学习φ,作为验证集的初始参数,用来更新元学习底层参数,此时网络参数不更新,式(24)用来计算网络损失值,使用SGD[30]来进行后续梯度下降。当一个轮次的数据训练完成后,根据式(25)可以得到同构的初始化参数,对参数进行更新,如式(26)、式(27)所示。
3.3 实验细节
在训练过程中,学习率采用动态余弦退火学习率,Adam优化器、卷积网络参数借鉴文献[31]。此外,为了防止训练出现过拟合现象,本文在实验过程中使用了dropout机制和权重正则化限制。
3.4 实验环境
操作系统为Windows 10 专业版,内存32GB,处理器为Intel Core i7-7200U CPU@2.50 GHz* 4,在Pytorch框架下使用Python 语言。
3.5 相似网络模型对比实验分析
为保证模型评估效果与真实情况结果相近,分别使用训练集、测试集、验证集对模型进行评估。为验证模型的有效性,本文使用少样本领域经典模型与现存性能良好模型与本文模型进行对比。结果如表3和图11所示。

表3 部分实验结果
在CONV-4作为特征提取网络情况下,相比于传统匹配网络,本文方法虽然在参数量上有所增加,但是在THUCNews 和IMDb两个数据集上,1-shot、5-shot情况下,其准确率分别有了0.91%、1.40%,5.36%、2.34%的提升。基于双层优化的MAML方法和匹配网络相比,其分类准确率有一定提升,且在相同数据集和实验条件下,本文所提出的方法精确度远高于MAML方法。此外,相关实验[32]表明,由于MAML是基于双层优化,所以在训练过程中经常会出现模型震荡的情况,但是在本文所使用的数据集上进行实验时,模型震荡情况并不明显,只是训练时间显著提升。TPN[33]与EPNet[34]分别为基于Matching网络与MAML网络的少样本学习的层次化网络。由于条件限制,TPN在现有条件下,由于模型参数量过大,无法完成实验,由表4可知其效果并没有随参数量的提升而有较大的变化。
而在特征提取网络为RESNET-12的情况下,各个网络的精确度分别有一定的提升。但是从整体可以看出,本文方法较当前性能较好的少样本学习处理方法,在准确率上有着很大的提升,同时其参数量相比于其他模型并没有增加很多。在某些网络上,其参数量甚至更少。相比于EPNet,本文所提出的模型在1-shot,5-shot实验下,其准确率分别提升2.47%、3.49%。当数据集较少时(在IMDb数据集上进行实验),其模型准确率分别提升1.89%、2.31%。
在特征提取网络为WRN(Wide Residual Networks)情况下,本文模型精确度虽然达到了顶点值,但是其参数量较ResNet增加了大约5倍,在数据量较大的THUCNews数据集上,1-shot、5-shot实验下,模型准确率分别提升2.43%、4.90%。当数据集较少时(在IMDb数据集上进行实验),其模型准确率分别提升2.58%、4.40%。
由图11可知,与其他模型相比,本文提出的模型训练准确率不断升高。在第5 000轮时,相比于其他模型,本文方法准确率最高,根据训练早停设置,如果20轮结果没有改善,便停止训练。相比于其他模型,本文方法平滑程度较为明显,训练与验证准确率基本持平。综上所述,本文所提出的模型的学习能力和泛化能力明显优于其他模型。
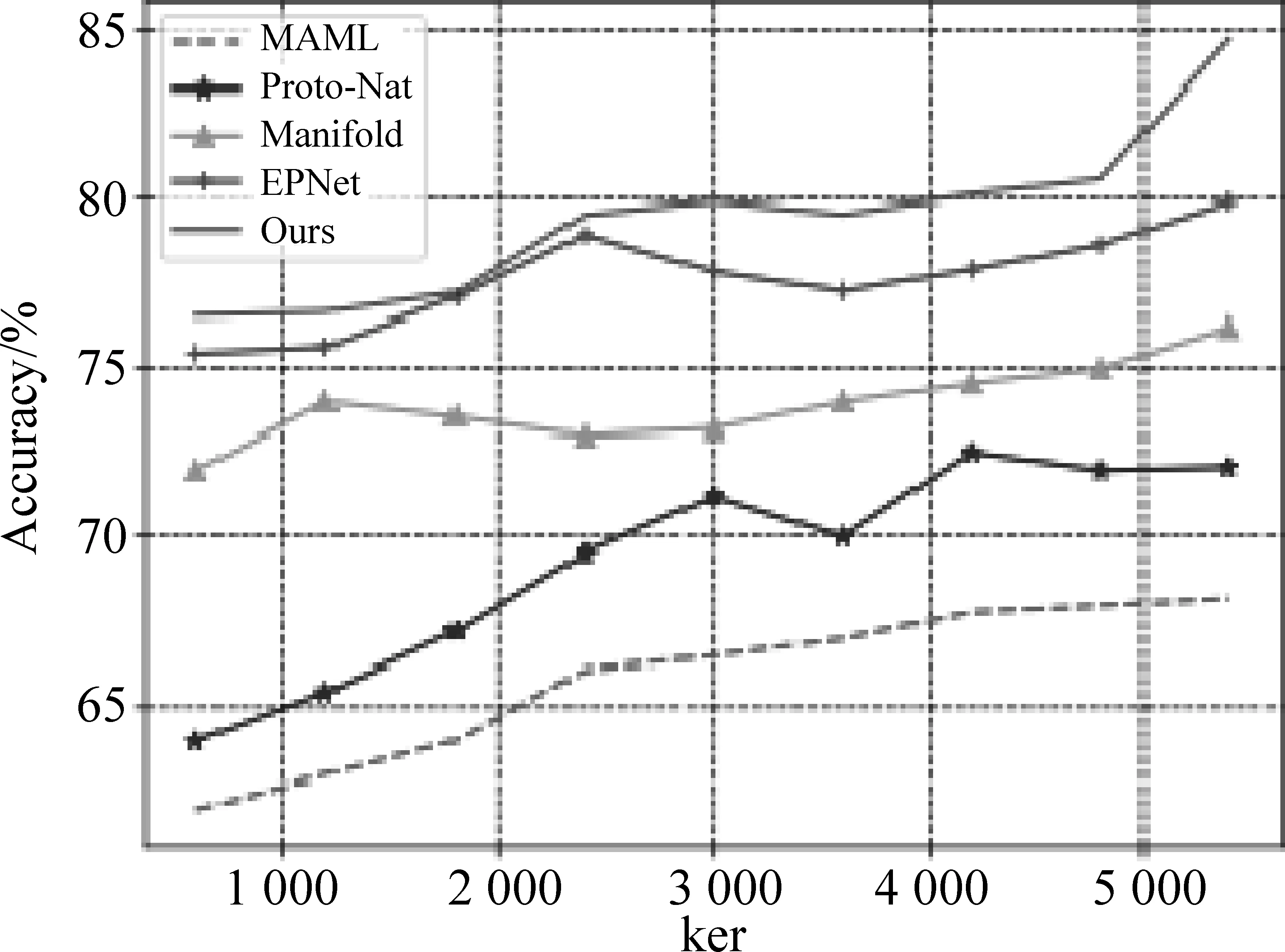
图11 测试集准确率
表4数据显示,卷积神经网络模型结构简单,计算耗时小,但是在文本分类的实验中准确率并没有降低,相比于某些网络结构复杂的方法其性能更好; 长短时间序列结构自身较为复杂,模型训练和测试耗时较长,引入注意力机制后,数据预处理阶段的复杂度显著上升,并且模型性能并没有很大的提升;循环神经网络和卷积神经网络的结合,形成的循环神经网络和卷积循环神经网络,有效提升了准确率,表明了循环神经网络和卷积神经网络简单结合及其变体结构模型的可靠性。长短时间序列和注意力模型由于网络结构复杂性增加,引入注意力机制在强化网络学习能力的同时模型计算量呈指数级增加,所以在实时性方面没有取得优势,但准确率相对提升了的2% ~ 3%,证实了模型的优越性。综合耗费时间与测试准确率两方面考虑,证明本文选取TextCNN作为元学习基础模型的正确性。

表4 模型训练及测试对比结果
表5为每一类别识别率对比结果。可以看出,相比之前提出的模型,本文使用的TextCNN模型相对提升了每一类别的准确率。几种模型在娱乐游戏的文本分类中性能最好,在家居、体育类分类性能有所降低。虽然双向长短时间序列的准确率在某些类别上的准确率比TextCNN要高,但是双向长短时间序列的模型更加复杂。卷积循环神经网络同理,模型较TextCNN更加复杂,但是准确率并没有很大提升。所以综上所述,本文所使用的TextCNN改进模型相比于先前的几种模型略占优势。

表5 每一类别识别率对比结果

表6 相关方法消融实验结果
3.6 消融实验
为了验证本文方法的有效性,在THUCNews 数据集上使用消融实验验证动态卷积,注意力生成器,两个平衡变量的有效性。如表 6 所示,实验结果由36%经过不断地增加相关方法,分类准确率逐步上升,但是由表6可以明显看出,DC(Dynamic Convolution)方法的加入使得分类准确率其有了很大提升,其次为AG(Attention Generator),对模型的分类效果提升显著,模型提升超过5%。实验结果表明,文中所提到的两种平衡变量对分类准确率有一定提升作用,分别为3%和4%。综上所述,DC方法的加入使得模型分类精确 的提升最为明显,其次为AG。虽然将AG、DC引入本文模型会导致网络模型参数量增加,但是其所获得的准确率提升效果相比于所付出的计算代价是值得的。
如图12所示,各个模型的准确率随着不平衡程度的加剧而降低,实验表明,使用两种平衡变量的模型的准确率的下降速度有所减缓。故两种平衡变量可以降低数据不平衡对模型所带来的影响。

图12 不平衡程度对模型的影响
4 结束语
本文提出了一种新的基于元学习的少样本情况下的文本分类模型。首先利用动态卷积对传统的TextCNN网络进行优化,较大地提升了网络提取特征的能力。同时充分考虑了文本底层信息无法迁移的问题,使用池化操作对输入特征进行处理,统计原始数据的信息,并结合TF-IDF方法获取文本局部以及全局信息。此外,本文研究了元学习算法本身所带来的数据不平衡问题,通过学习平衡变量来控制不平衡程度。据我们所知,动态卷积是首次被引入少样本文本分类模型中。实验表明,本文提出的方法在标准文本分类数据集上表现良好,与之前的少样本文本分类模型对比,模型分类准确率有所提高。未来我们将继续进行不平衡少样本情况下的自然语言处理研究,如将元学习的思想或方法应用于机器翻译、人机对话、语音识别等领域。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
陶瓷学报(2021年4期)2021-10-14
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
少儿画王(3-6岁)(2020年4期)2020-09-13
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
