
动态层次Transformer序列推荐算法
2022-03-10 01:25牛树梓李会元
中文信息学报 2022年1期
袁 涛,牛树梓,李会元
(1.中国科学院大学,北京 100049;2.中国科学院 软件研究所,北京 100190)
0 引言
为了解决互联网时代信息过载[1]的问题,推荐技术应运而生。目前主流的推荐算法均将用户与物品的交互历史看作序列数据,预测用户下次会与哪些物品交互,即序列化推荐(Sequential Recommendation)。序列化推荐的核心问题在于预测物品对历史序列的依赖建模。现存大量相关研究工作表明这种依赖是多层次的。典型的研究方法有长期依赖推荐算法[2]、短期依赖推荐算法[3-4]、长短期混合依赖推荐算法[5]以及多尺度依赖推荐算法[6]。
多尺度依赖算法大都关注于启发式地设计多尺度的隐式空间的表示。常见的启发式设计方法是从时域或频域的角度对隐式空间表示进行多尺度的硬划分。基于兴趣的变化频率与神经元的更新频率对应假设,对隐层神经元进行划分,为不同分块内的神经元设置不同的更新频率[6-7]。更新频率较高的神经元假设对应短期兴趣表示,因为短期兴趣多变。更新频率较低的神经元学到的是长期兴趣表示,因为长期兴趣稳定。更新频率处于两者之间的神经元学到的是中期兴趣表示。然而,这种启发式的划分方法并没有明确的物理意义,也无法生成显式的多尺度层次结构。
另外一些多尺度依赖算法关注于从原始序列中得到多尺度的训练样本[8]。例如,为不同的尺度设置不同的窗口大小,采用滑动窗口得到不同尺度的训练样本。虽然针对数据的层次化采样可以有效避免物理意义不明确的问题,但这种做法依旧需要启发式地设置窗口大小,从而可能会导致把具有语义关系的片段被切分开。
无论从隐式表示空间还是数据层面的启发式划分,现有多尺度依赖算法都不足以灵活应对不同的数据。因此,如何从序列中自动学习出多尺度依赖的层次结构以及隐式表示仍旧是具有挑战性的问题。为此本文提出从历史序列的自注意力矩阵中学习序列的层次结构,并依据该结构预测即将交互物品,即动态层次Transformer序列推荐算法(Dynamic Hierarchical Transformer for Sequential Recommendation,DHT4Rec)。
首先,本文提出了动态层次Transformer模块,利用多个动态层次Transformer层自底向上,推断出一个原始序列的层次结构。每层先利用近邻块间注意力机制,计算与左右近邻的合并概率,并判断是否做合并,并由此生成块掩码来更新隐式表示。根据每层的块掩码可以推断出多尺度层次结构,连接每层的隐式表示即得到多尺度的隐式表示。然后,Transformer层利用自注意力机制建模用户下一时刻的瞬间兴趣表示对不同时间尺度下用户兴趣表示的依赖。最后,全连接输出层的目标在于预测用户下次可能感兴趣的物品概率分布。
实验在MovieLens-100k和Amazon Movies and TV两个公共数据集上进行。定量分析的结果表明,本文提出的DHT4Rec算法在预测准确率上分别比当前最先进的基准方法提升了2.09%和5.43%。定性分析的结果表明,模型学习到的多尺度结构符合直觉。
1 相关研究工作
综上所述,序列化推荐算法核心在于建模预测目标对于用户历史行为序列的依赖。已有的算法研究表明不同的数据集上对预测起关键作用的是序列的不同部分[7]: ①长期依赖推荐算法认为整个序列的全局信息比较重要; ②短期依赖推荐算法认为最新最近的局部信息对于预测比较重要; ③长短期混合依赖推荐算法认为全局与局部信息对于预测都是不可或缺的; ④多尺度依赖推荐算法认为除了全局与局部信息以外,中间某些层次的信息对预测也有用。
长期依赖推荐算法利用用户对物品完整的交互历史序列来建模全局信息,从而捕获用户的长期偏好。传统的推荐算法将历史序列视为集合的做法也是一种建模长期依赖的方式,如CDAE[9]与NeuCF[10]。目前主流的做法是基于循环神经网络RNN、记忆网络(Memory Network)、自注意力机制(Self-Attention Network)以及Transformer等的序列推荐算法,如DREAM[11],CMN[12],SASRec[13],BST[2]等。
短期依赖推荐算法利用用户近期的行为序列建模局部信息,以捕捉用户短期偏好,如上一个物品或上一个会话中交互的物品序列。传统的基于马尔可夫链的做法如FPMC[14]等都属于此类算法。基于会话的推荐算法通常采用序列模型和注意力机制来捕捉一个会话内部的时序依赖关系,如GRU4REC[4]和STAMP[3]。GRU4REC采用GRU捕捉会话中用户点击行为之间的依赖关系。STAMP采用注意力机制建模会话内不同时间浏览过商品的重要程度。HRNN[15]采用层次循环神经网络建模会话内的顺序依赖。
长短期混合依赖推荐算法强调全局序列与近期局部序列对于预测物品的重要性,利用深度神经网络来分别捕捉用户的长、短期兴趣。HRM[5]假设用户与物品都为隐式空间的向量,将用户隐式空间的表示作为用户长期兴趣表示,最近一次购物车的物品表示作为短期兴趣表示,两者结合用来预测下次购买的物品。LISC[16]分别采用矩阵分解模型与循环神经网络来建模用户的长、短期兴趣,并以生成对抗网络的方法对二者进行融合。与之类似,AttRec[17]分别采用协同度量学习与自注意力机制的方法来建模用户的长短期兴趣,并采用线性加权的方式进行融合。
预测物品对历史序列的长期依赖反映的是用户长期兴趣偏好,预测物品对历史序列的短期依赖反映的是用户短期兴趣偏好。长期偏好稳定,不易变;短期兴趣动态多变。真实场景的实验结果表明,预测目标对于历史序列的依赖是多层次的。除了长期与短期依赖之外,存在处于两者之间的依赖,物理意义并不像长、短期依赖那么明确,本文暂且称之为中期兴趣。
多尺度依赖推荐算法能够捕获多层次的顺序依赖模式。HPMN[6]在记忆网络(Memory Network)中引入分层和周期性更新机制。不同层间神经元数量一致,但是更新频率不同,自底向上更新频率变慢,相应建模用户的短期、中期以及长期兴趣。MARank[18]提出目标物品的预测不但依赖于单个物品间的顺序关系,还依赖于不同大小的物品集合与物品间的顺序关系的假设,并用多层残差网络和注意力机制来学习不同阶集合的表示。S3Rec[19]对BERT[20]中常用的掩码机制进行扩展,建模被掩盖的子序列对上下文的依赖,这种子序列掩码机制可视为一种简单的多尺度的建模方法。
2 动态层次transformer序列推荐算法
为了避免启发式设计多尺度结构,本文提出基于用户多尺度兴趣树的序列推荐算法 DHT4Rec来从用户交互历史序列中自动推断出多尺度层次结构以及隐式表示。
2.1 形式化定义
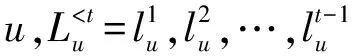
2.2 DHT4Rec体系结构
DHT4Rec模型的体系结构主要由Embedding嵌入层、动态层次Transformer模块、Transformer层以及全连接输出层四个部分组成,如图1所示。通过Embedding嵌入层,得到用户和物品初始的分布式表示。动态层次Transformer模块通过相邻块的注意力机制,自底向上逐层进行相邻块合并,形成多尺度用户兴趣树,获得多尺度的用户兴趣表示。Transformer层采用自注意力机制建模下一时刻用户兴趣对历史序列中体现出来的多尺度结构的依赖关系。通过全连接输出层获得用户下一个时刻可能感兴趣的物品的概率分布。
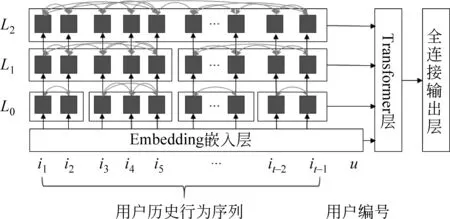
图1 DHT4Rec体系结构
2.3 Embedding嵌入层
2.4 动态层次Transformer模块
动态层次Transformer(Dynamic Hierarchical Transformer)模块由D层构成,D为尺度数上限。每层由近邻注意力与具备动态掩码机制的Transformer层构成,简称为动态掩码Transformer层,结构如图2所示。根据近邻注意力机制,生成该层Transformer的掩码矩阵,故称之为动态掩码。Transformer根据该掩码更新物品表示。更新后的表示与动态掩码一起作为下层的输入。如此通过D层,在近邻注意力机制与动态掩码机制不断交互地作用下,生成多尺度层次结构。
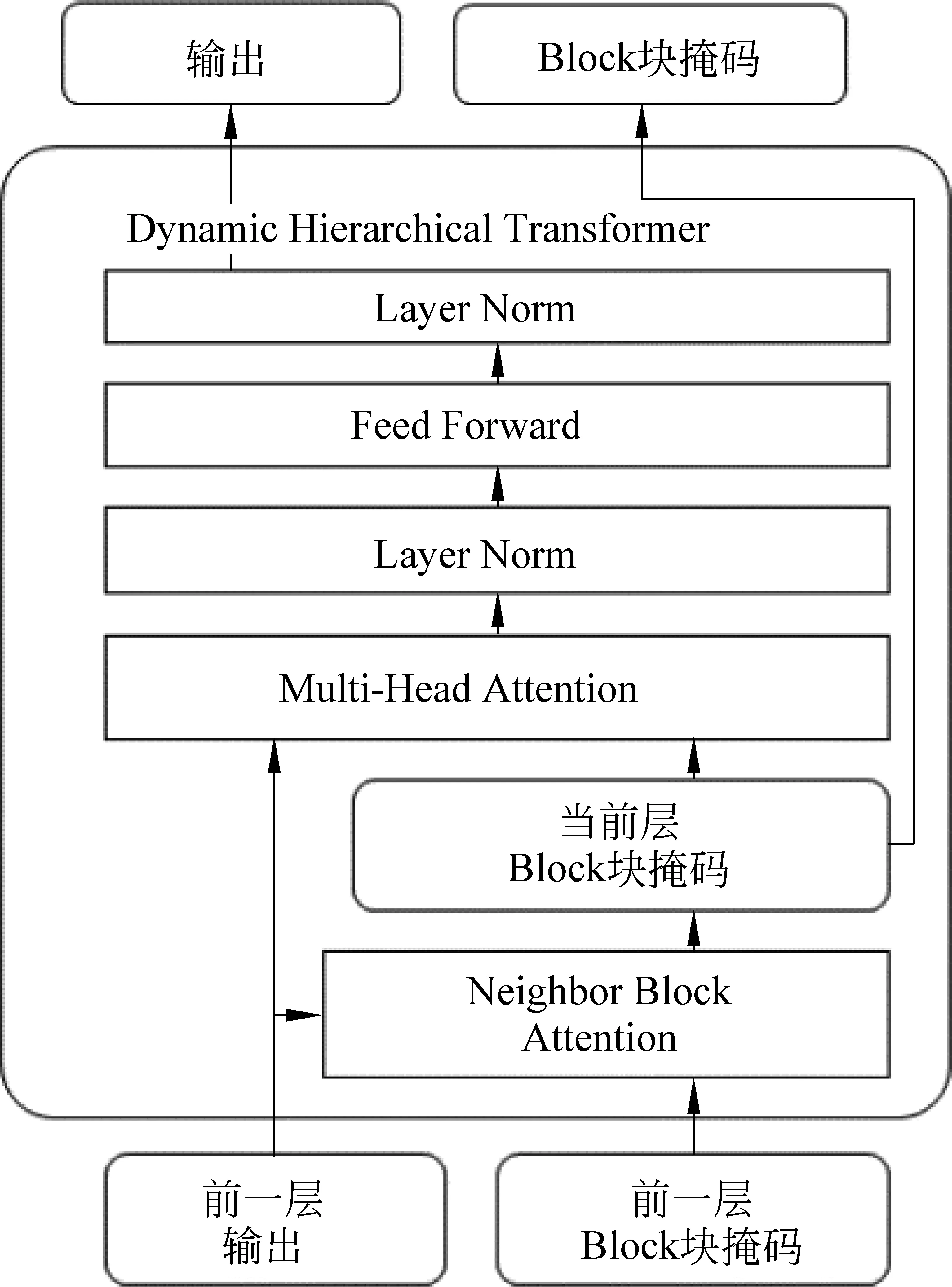
图2 动态掩码Transformer层结构
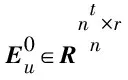
(1)
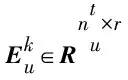
(4)
(5)
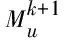
(6)
(7)
(8)
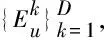
(9)
2.5 Transformer层
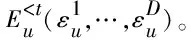
(10)
2.6 全连接输出层
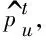
2.7 讨论
Transformer通常涉及两类掩码: 一类是在计算自注意力权重时,如式(7)所示,通常用掩码来去掉冗余信息,提高计算效率,如DHT4Rec;另一类是在掩码语言模型(Masked Language Model)作为训练目标函数时,随机采样序列中不同位置,用掩码替换原来位置的符号,如BERT4Rec以及S3Rec等。与DHT4Rec不同,S3Rec的多尺度建模是通过计算掩码语言模型时,对不同长度子序列采样来实现的。
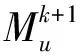
传统的不带掩码的Transformer每层的注意力权重计算时间与空间复杂度约为O(n2·r),其中,n为序列长度,r为隐式表示的维度。Longformer采用静态掩码来实现窗口注意力机制,从而解决长程依赖问题,其每层的注意力权重计算时间与空间复杂度约为O(n·w·r),其中,w为窗口大小。DHT4Rec的第k层的注意力权重计算时间与空间复杂度为O[(bk)2·r],其中,bk表示当前层掩码矩阵的块数,1≤bk≤n/2,k≥1。对于D层Transformer网络结构、不带掩码的Transformer,Longformer以及DHT4Rec的计算时间与空间复杂度分别为O(D·n2·r),O(D·n·w·r),O(2·n2·r)。
3 实验与分析
本文采用四种排序性能的评价指标来度量DHT4Rec在两个公共标准数据集上的推荐性能,对比了五类基准方法,并分析了不同网络结构参数对模型性能的影响。
3.1 实验设置
本文在MovieLens-100k和Amazon Movies and TV两个常用的公共标准数据集上进行实验。
MovieLens-100k数据集包含943个用户对1 682部电影的100 000条评分数据,数据信息包括用户ID、电影ID、评分和时间戳。
Amazon Movies and TV数据集,我们从中选取了评分数量均大于50的用户和电影,共有2 074个用户、7 352部电影和268 586个评分。对于每个用户序列,先按时间排序,然后按比例4:1将其分别划分到训练集与测试集。为了增加训练集中序列的数量,且便于多尺度研究,限定训练序列的最小长度为M,将一个长度为L的原始序列,拆分成N=L-M个训练序列。假设原始序列为{(i1,i2,i3},M=1,则训练序列为{(i1),i2}与{(i1,i2),i3}。最小长度M在MovieLens-100k和Amazon Movies and TV分别为8和32。以MovieLens-100k为例,数据增强后训练序列个数由原来的983增加到72 823。
本文选取了五类基准算法进行性能对比实验。①传统推荐算法: ItemKNN[23]和BPRMF[24]。②长期依赖推荐算法: SASRec[13]、BERT4Rec[25]与BST[2]。③短期依赖推荐算法: GRU4REC[4]与STAMP[3]。④长短期混合依赖推荐算法: AttRec[17]以及HRM[5]。⑤多尺度依赖推荐算法: MARank[18]、S3Rec[19]、MC-RNN[7]与HPMN[6]。本文对比S3Rec时去除了物品信息相关预训练,只采用了物品掩码和片段掩码预训练过程。
本文采用排序的评价指标[26]来度量推荐算法的性能,如Precision、Recall、NDCG(Normalized Discounted Cumulative Gain)[27]以及MRR(Mean Reciprocal Rank),截断值为10。
将各模型在测试集上表现性能最优的参数作为各模型的参数配置。各模型批处理大小均为256,正则化系数为0.001,其他超参数分别选取如下配置: ItemKNN中近邻数为20;BPRMF采用128维的隐式表示,学习率为0.002;SASRec 、BERT4Rec和BST的物品隐式表示维度均为16,blocks个数为1,heads个数为4,dropout为0.1,学习率为0.001。此外BERT4Rec随机掩码概率为0.2, BST的负采样个数为4;STAMP和GRU4Rec的物品隐式表示维度均为16,学习率分别为0.002和0.001,此外GRU4Rec的GRU单元大小为32;AttRec和HRM的物品隐式表示维度均为16,学习率分别为0.001和0.006,负采样个数均为10。此外,HRM的双层聚合操作均为最大值,AttRec的长短期兴趣权重取值为0.5,margin取值为1.0;MARank残差层数为2,S3Rec的负采样个数为1,其他参数同SASRec、HPMN的记忆层数为4,更新周期为[1,2,4,8],MCRNN在MovieLens-100k和Amazon Movies and TV数据集上的尺度分为2和3,采样方式为指数;DHT4Rec在MovieLens-100k和Amazon Movies and TV数据集上的尺度分别为4和7,其他参数同BST和SASRec。
3.2 性能分析
本文对比了DHT4Rec与其他五类基准算法在MovieLens 100k(以下简称MovieLens)与Amazon Movies and TV(以下简称Amazon)两个标准数据集上的性能,结果如表1和表2所示。m与M列分别对应四个评价指标下DHT4Rec相对于每个基准算法性能最小与最大提升的百分比。
和传统的推荐算法ItemKNN及BPRMF相比,在两个标准数据集上,DHT4Rec的相对性能提升显著。这种现象的主要原因在于序列推荐算法比传统推荐算法考虑了更多的信息,如交互历史中物品之间的时序关系。在数据稀疏性比较严重的Amazon数据集上,每部电影的评价较少,能利用电影间相似性的ItemKNN性能优势明显大于BPRMF。
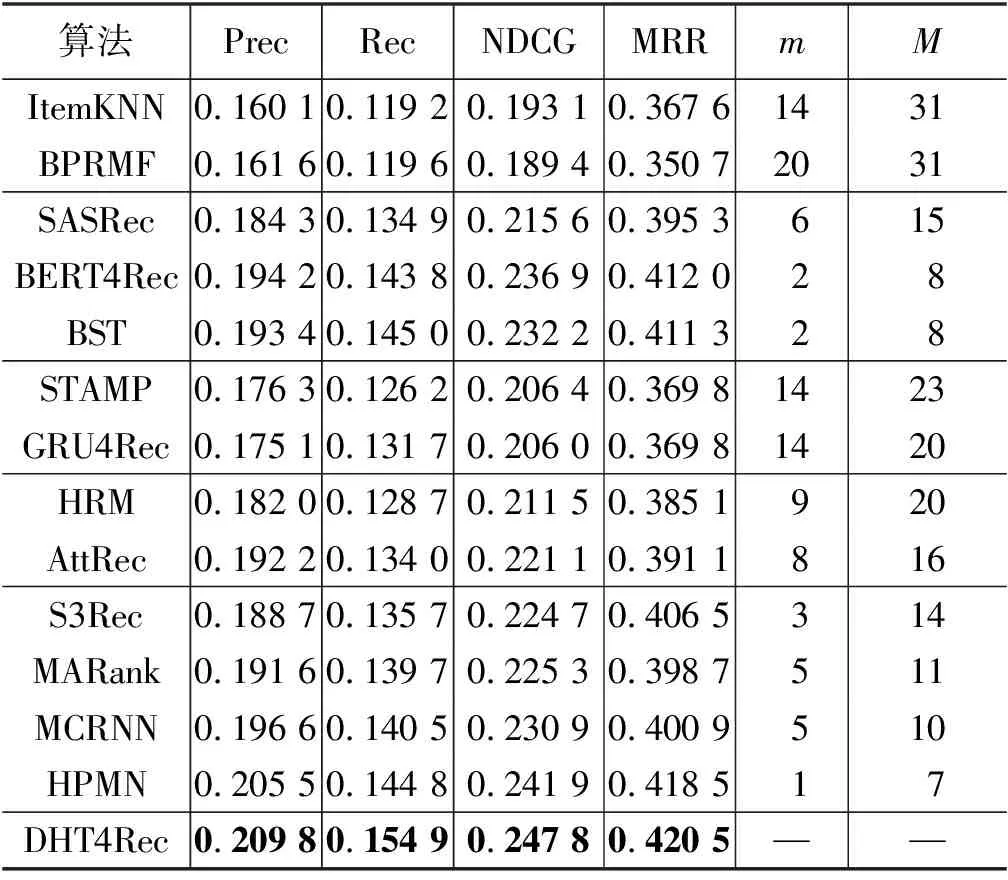
表1 MovieLens数据集实验结果
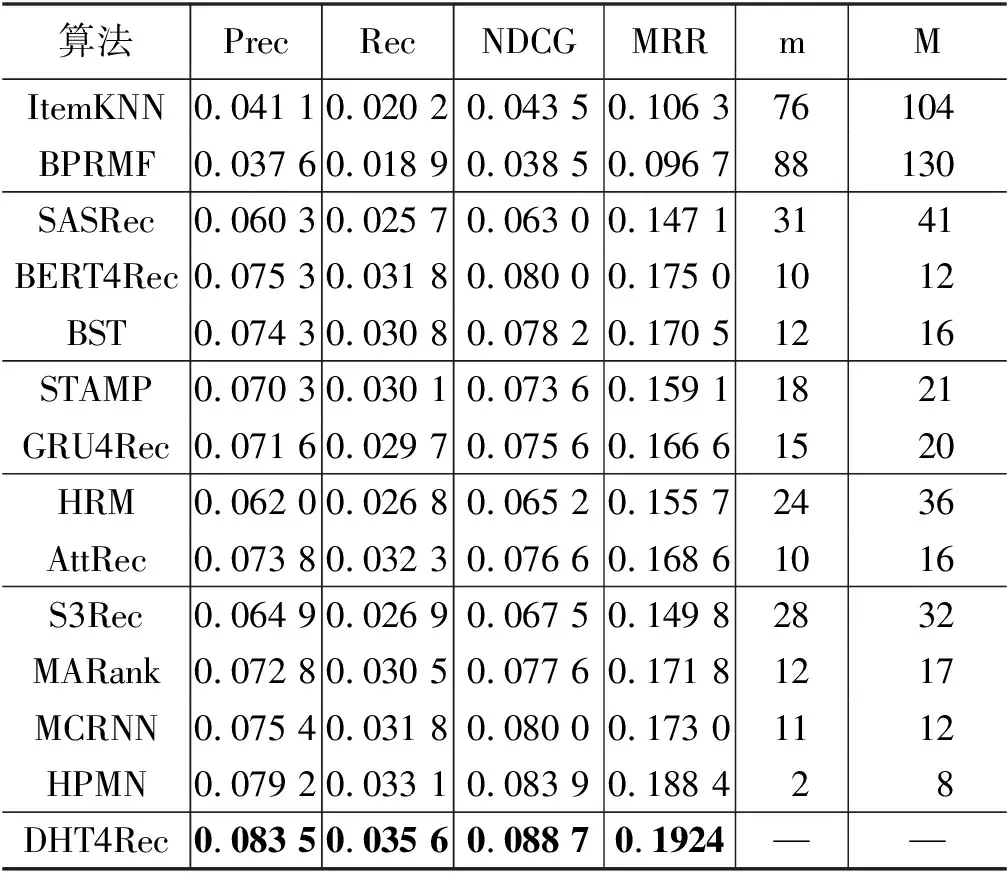
表2 Amazon数据集实验结果
与长期依赖算法SASRec和BST相比,DHT4Rec的性能在MovieLens上提升了2%~15%,在Amazon上提升了12%~41%。与单粒度随机掩码的BERT4Rec相比,DHT4Rec的性能提升了2%~12%。长期依赖模型只建模全局影响因素来捕捉稳定的长期兴趣,但无法适应预测物品对序列不同部分的依赖。
与短期依赖序列推荐算法STAMP和GRU4Rec相比,DHT4Rec算法的性能在MovieLens与Amazon上分别提升了约14%~23%和15%~21%。短期依赖算法采用如会话等特定的启发式方法来定义局部影响因素,试图捕捉动态的短期兴趣。这种固定的局部因素的定义无法灵活应对依赖的多样性。
与长短期混合依赖算法HRM和AttRec相比,DHT4Rec的性能在MovieLens与Amazon上分别提升了约8%~20%和10%~36%。混合依赖算法试图通过融合全局与局部的影响因素解决这个问题,但仍无法避免固定的局部因素定义的短板。作为多尺度依赖算法,DHT4Rec算法在解决这个问题上具有天然的优势,因此在基于排序的评价体系下要显著优于没有采用多尺度的基准算法。
与其他的多尺度依赖算法相比,DHT4Rec的性能在MovieLens与Amazon上分别提升了约1%~14%与2%~32%。MCRNN与HPMN均利用不同神经元的更新频率不同这样的启发式设计得到多尺度隐式表示。这种性能增益体现了自适应生成的多尺度层次结构对于预测下一步交互物品的优势。
两个数据集上相对于其他多尺度方法,DHT4Rec的MRR性能提升最小,Recall性能提升最大。DHT4Rec采用动态掩码Transformer层产生的数据自适应的层次结构,结构灵活多变,不同历史序列的表示分布更加分散,有助于放松分类边界。因此,DHT4Rec中动态层次Transformer对于提升Recall更有益。
3.3 网络结构参数的影响分析
DHT4Rec的动态层次Transformer结构中涉及以下三个关键参数: 动态掩码Transformer层数(尺度数)D,不同层间是否添加残差连接,如式(6)所示;同层节点的表示是否采用聚合操作,如式(9)所示。
3.3.1 尺度数
为了研究尺度数选取对模型性能的影响,实验中选取不同D∈{1,…,10},DHT4Rec在MovieLens与Amazon上的性能如图4(a)与4(b)所示。
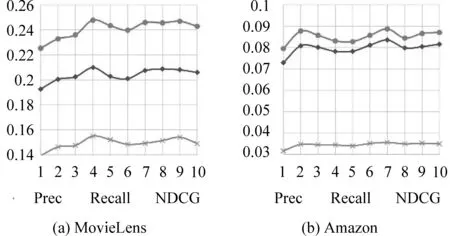
图4 尺度数D对性能的影响
图4展示了DHT4Rec性能在两个数据集上随着D的增加而增加,当D达到某个值之后,性能不再增加,而保持平稳。MovieLens数据集上,无论采用哪种评价指标,该临界值为4;Amazon数据集上,不论采用哪种评价指标,该临界值为7。当D=1时,模型结构中不存在动态层次Transformer,退化为单尺度,与SASRec、BST模型结构类似,性能相近。
3.3.2 不同层间的残差连接
DHT4Rec中的动态层次Transformer若采用残差连接更新物品表示,如式(6)所示,简记为DHT4Rec+Res;若不采用残差连接,简记为DHT4Rec,表1与表2中展示的是没有残差连接时的结果。是否引入残差连接的对比实验结果如表3所示。
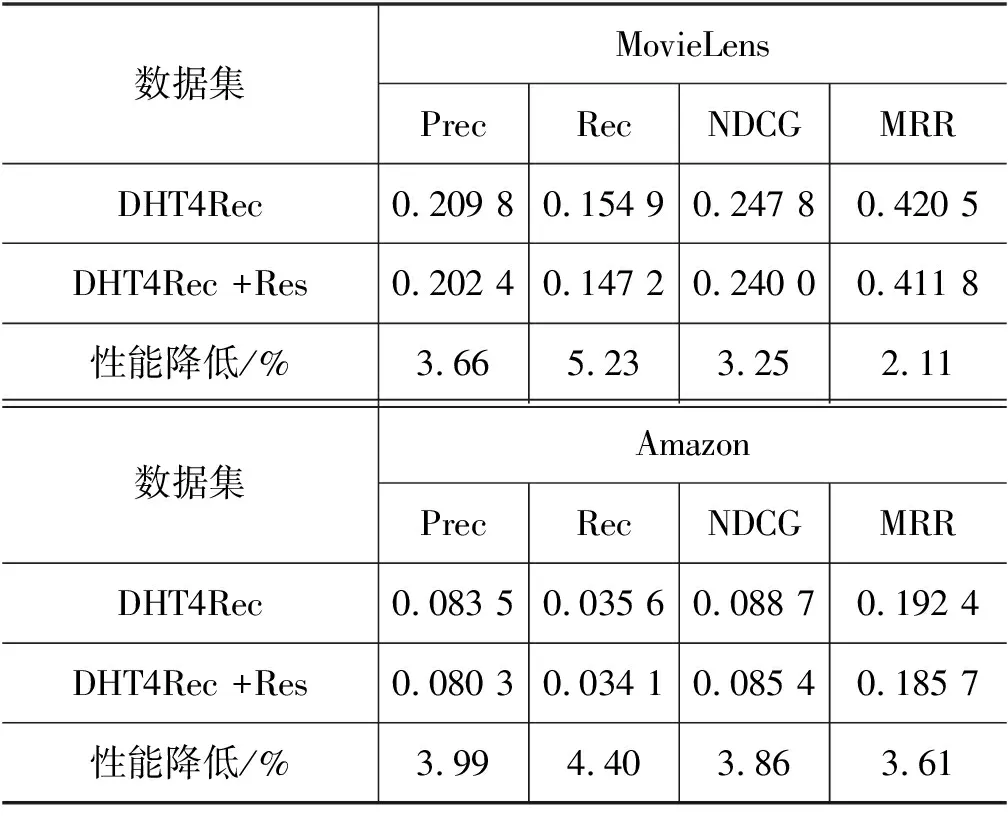
表3 是否引入残差网络对比实验结果
实验结果表明,引入残差连接性能变差。残差连接会将低尺度下物品表示叠加到高尺度下物品表示中,从而使得不同尺度下物品表示之间的区分度不大。尺度表示间的差异不大,导致分类效果变差。
3.3.3 同层节点内的聚合操作
DHT4Rec中动态层次Transformer采用均值聚合(AGG)操作得到节点的表示,如式(9)所示,记为DHT4Rec。若不采用AGG操作,记为DHT4Rec-AGG。是否进行均值聚合操作的对比实验结果如表4所示。
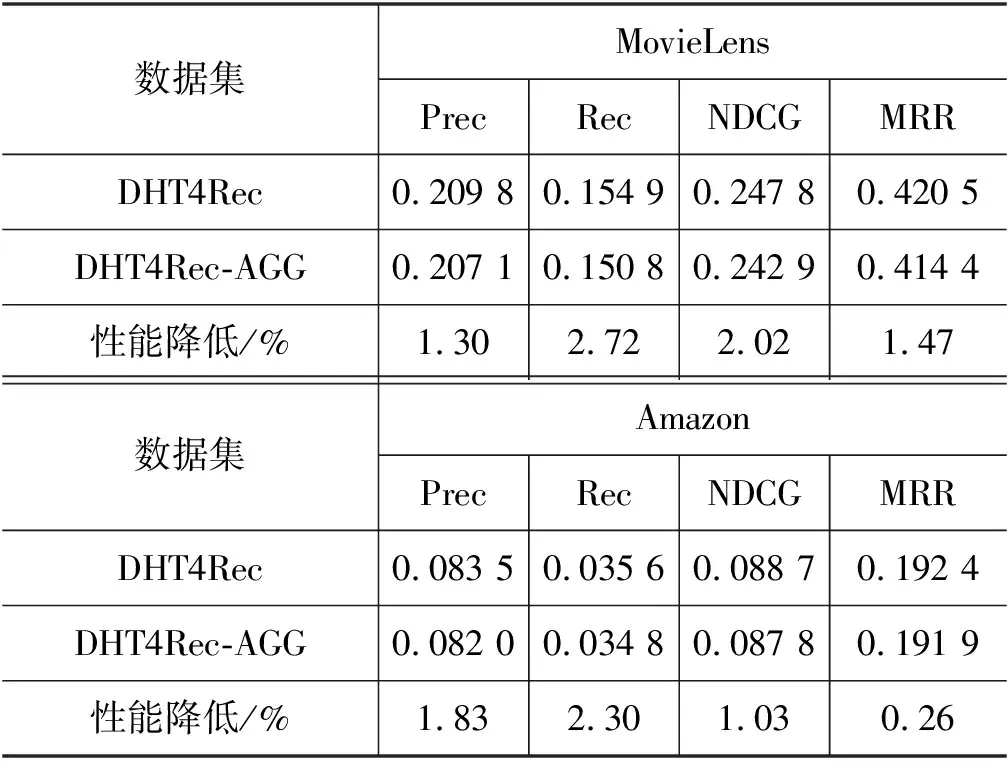
表4 是否引入节点聚合对比实验结果
实验结果表明,对多尺度层次结构中的节点进行均值聚合操作,能改善模型性能。没有均值操作相当于保留节点内部不同物品表示的细微差异,均值操作相当于对节点表示进行平滑。这种平滑技术忽略节点内物品表示的差异,使得节点表示间的差异凸现,从而带来分类性能的提升。
3.4 多尺度层次结构可视化
根据从动态层次Transformer模块得到的D个块掩码矩阵可以推断出历史序列的多尺度层次结构。从Transformer层的注意力权重矩阵可以看到多尺度用户兴趣表示对下一时刻预测物品的重要程度。例如,MovieLens中用户编号为604,历史序列长度为13,对应的多尺度层次结构如图5所示,其中颜色从深到浅表示对于预测物品的重要程度由高到低。
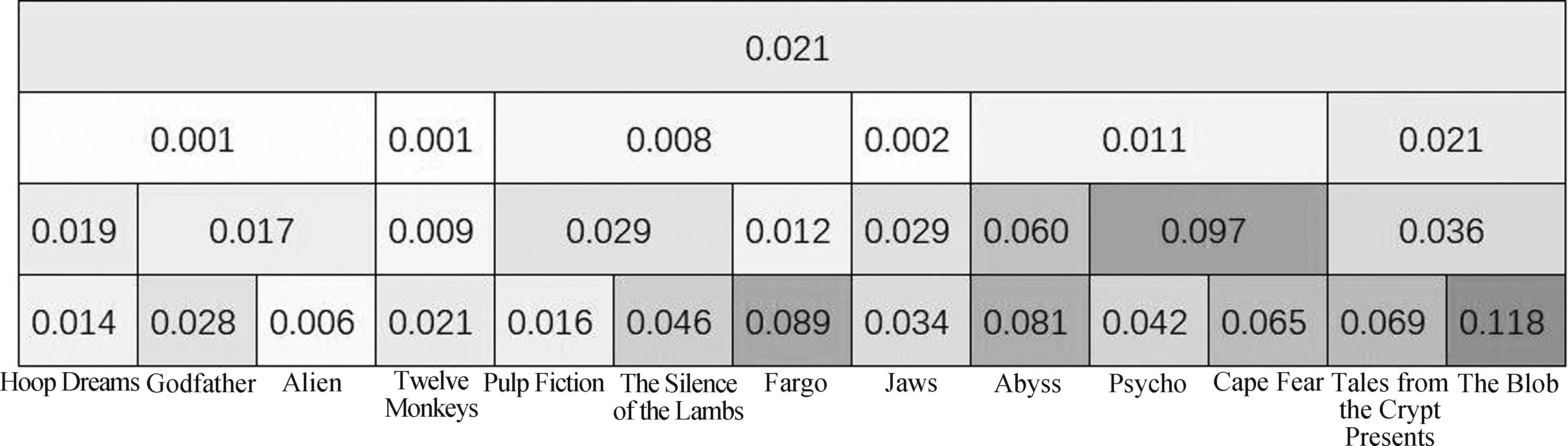
图5 用户多尺度兴趣树结构及依赖关系图
从图5可以看到,每个尺度下都有对预测较为重要的节点。这一现象表明多尺度存在的必要性。目标电影“Heavenly Creatures (1994)”的类别为“剧情、科幻和惊悚”。对于该目标电影来说,权重较大的节点分别是来自最低尺度的“The Blob(1958)”属于“恐怖、科幻”类型,中间尺度的{“Psycho (1960)”,“Cape Fear (1991)”}属于“恐怖、浪漫、惊悚、惊恐”类型,最低尺度的“Fargo (1996)”属于“犯罪、剧情、惊悚”类型。从电影类别的角度来看,这一多尺度结构是符合直觉的。
3.5 效率分析
在MovieLens数据集上,序列长度分别为8、16至512,尺度个数为4,隐式维度为16,批大小为64,每个epoch所花费的时间和内存占用情况如表5所示。从表5中可以看出,DHT4Rec模型的时间和空间复杂度均为平方阶。

表5 模型的效率分析
4 总结与展望
为了解决多尺度表示与层次结构不能自适应的问题,本文提出的动态层次Transformer序列推荐算法,可以同时学习用户兴趣的多尺度隐式表示与显式层次树。每层的动态掩码Transformer层采用近邻块注意力机制判断邻近块合并与否,得到动态块掩码矩阵,根据该矩阵得到该层次下的隐式表示。通过多层动态掩码Transformer层,得到多尺度的隐式表示,并由动态块掩码矩阵得到多尺度的层次结构。最后,通过Transformer层输出下一时刻预测物品的概率分布。实验结果表明,DHT4Rec在两个公共标准数据集上均优于当前最先进的序列推荐算法。下一步的工作考虑将物品的内容信息作为知识图谱来进一步改进推荐性能。
猜你喜欢
计算机技术与发展(2022年5期)2022-05-30
四川大学学报(自然科学版)(2021年6期)2021-12-27
密码学报(2021年2期)2021-05-15
计算机应用(2020年12期)2020-12-31
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
网络安全和信息化(2019年7期)2019-12-22
太空探索(2016年5期)2016-07-12
文苑(2015年9期)2015-09-10
电脑知识与技术(2015年12期)2015-07-18
时代英语·高三(2014年5期)2014-08-26
