
基于多算法融合的文本抄袭检测的特征提取算法研究
2022-03-11 04:43张庆国何金波周文竹
湖北民族大学学报(自然科学版) 2022年1期
陈 滔,张庆国,何金波,周文竹
(1.安徽农业大学 工学院,合肥 230036;2.甘肃政法大学 民商经济法学院,兰州 720070;3.安徽医科大学 临床医学院,合肥 230031;4.安徽农业大学 资源与环境学院,合肥 230036)
2020年以来,国家自然科学基金委员会通报近百起学术不端案例[1],其中不乏学术抄袭现象.为解决学术抄袭乱象,越来越多的检测算法被提出.抄袭检测算法在原理和技术上各不相同,但都需要先对文本进行特征提取再进行抄袭比对,而特征提取结果的优劣和提取特征指标都直接影响到文本抄袭检测结果的准确性与可靠性.龚科瑜等[2]利用TF-IDF(Term Frequency-Inverse Document Frequency)算法对古籍文本内容进行特征提取,较好的提取到古籍文本中的内容特征.黄敏等[3]针对新闻类文本提出了一种NewTF-IDF算法,对TF-IDF算法做了多组合特征因子和离散度两个方面的改进,使得特征提取结果更加精确.金标等[4]提出了一种基于依存句法的文本抄袭检测算法,在依存句法分析的基础上,通过分析句子中词语间的关系以及合并短小词语建立句法框架,进而提取文本特征.李昌兵等[5]提出一种融合卡方统计和TF-IWF(Term Frequency-Inverse Word Frequency)算法的短文本分类方法,通过卡方统计对训练数据集提取特征词,然后利用TF-IWF算法对特征词赋予权重后进行文本分类检测,取得了良好的检测结果.
传统的文本特征提取方法在文本抄袭检测应用中已触及许多领域,但仍存在未考虑文本主题和文本作者写作风格导致检测结果不理想等问题.同时,国内外学者大多采用单一算法进行文本特征提取,但是不同的算法具有各自的优点和应用的局限性.本文采用NLP(Neuro-Linguistic Programming)与机器学习领域的相关算法,考虑文本写作主题和写作风格对文本特征提取结果的影响,自主设计了一套应用于抄袭检测的多算法文本特征提取流程.实验表明,本文所提出的文本特征提取算法能够准确地识别文本的特点,很大程度上提高了文本抄袭检测的精度与可靠度.

图1 LDA的贝叶斯网络图Fig.1 Bayesian network diagram of LDA

表1 LDA主题模型中各变量含义Tab.1 Meanings of variables in LDA subject model
1 算法原理
1.1 LDA主题模型
文本的虚词、标点甚至俚语的使用对于提取作者的写作风格相当有效[6-7],并且使用虚词的特征能够有效避开文章主题对于作者写作风格提取的影响.LDA[8](Latent Dirichlet allocation)是一种文档主题的生成模型,其本质是3层贝叶斯概率模型,其中包含词(W)、主题(t)和文档(d)3层结构.本文创新性地将LDA算法应用在虚词的提取与分析中,其目的是提取作者虚词的使用以及其反映的写作风格,此时的3层结构为虚词(W)、写作风格(s)和文档(d),如图1.
图1中W代表实际可观测值,S代表写作风格隐含变量,方框代表吉布斯采样迭代次数,箭头表示各变量之间的概率依赖关系.图1中各变量所代表的含义见表1.
LDA主题模型的具体思想[9]如下:
设D={d1,d1,…,dM}表示文档集,其中M表示文档数量.D隐含的写作风格数量为K,以V={v1,v2,…,vN}表示文本中出现的虚词的集合,其中N表示虚词的总数.根据LDA主题模型做出以下定义.
定义1(文档-写作风格分布) 对D中任意文档di,生成所有的写作风格概率为θd={ps1,ps2,…,psM},其中psi=Nsi/N表示第i个写作风格si的概率,Nsi表示di中第i个写作风格si所含有的虚词的数量.
定义2(文档-虚词分布) 对任意写作风格si下对应词汇的概率为φs={pw1,pw2,…,pwN},其中psi=Nwi/N表示si生成V中第i个虚词的概率,Nwi表示分配写作风格si的V中第i个虚词的数量.
根据定义1、2,可以得到虚词、写作风格、文档的联合分布为
(1)
其中,θ是K维文档-写作风格分布,S是K维写作风格,W是N虚词和写作风格.要想得到每个虚词w的生成概率,就需要计算W的边缘分布,计算方法如下:
(2)
利用吉布斯采样对虚词进行抽样,再采用EM算法估计θ和φ,具体如下:
(3)
(4)
(5)
其中,s-1表示wi和di分配给非写作风格的概率,直到θ和φ趋于稳定时,停止采样.
1.2 同义词林
使用哈尔滨工业大学社会计算与信息检索研究中心研制的《大词林》[10]对文本的用词偏好特征进行提取,《大词林》收录了75万核心实体和核心实体对应的1.8万细粒度概念词表.
对输入的文本集合进行切词,将词列表看作词袋,统计各个同义词类内部的概率分布信息[11].对于任意的输入词袋,每一个同义词类内部各个词语w的概率的pw总和为1.选取词林中词语来代表等价类,并将信息记录在同义词字典(简称词字典)中.根据已经建立的各个同义等价类的字典(称为类字典),用词字典的词条对应一个词的方法,类字典的词条就会对应一个等价类.对于类字典中的类词条C,在维护等价类内成员的总出现频率计数器couC,还为类内任一个词语w维护一个计数器couw.couC与couw的关系应该满足:
(6)
由于既统计了等价类内部一个词语w的频率,又统计了整个等价类C的频率,实际上统计了等价类内部的概率分布,每一个词语在一个同义等价类中被选用的概率为
(7)
当分析完整个词袋时,词袋中出现的所有同义等价类内所有出现的词语被选用的概率分布,而该分布体现了文本的同义词选用特征.于是,两个词袋l1和l2间各个词被选用的概率的差别为
Dw,C=|pw,C,l1-pw,C,l2|,Dw,C∈[0,1].
(8)
通过比较不同作者撰写的文本W1词袋集、W2中的词袋,将文章中抓取的每一个词语对平均差异的贡献进行累加,就得到每一个类的总贡献,依序找到最能区分不同作者的等价类并进行等价类排序.利用主成分分析法[12]对向量进行降维,就得到文本的同义词林维度的向量.
1.3 GloVe和TF-IDF算法
在文本主题特征向量维度提取中,采用GloVe算法[13](Global Vectors for Word Representation)进行词向量训练,然后提取1篇文章内TF-IDF值最高的词汇,将这些词汇对应的词向量以正比其TF-IDF值[14-15]的权重进行加权,最终通过词向量叠加得到了文本主题向量维度.
GloVe算法模型为
(9)
其中,X为共现矩阵,其元素Xi,j表示单词i和j共同出现在一个窗口的次数,其中窗口大小一般为5~10.vi和vj是单词i和j的词向量,bi和bj是偏差项,N是共现矩阵N×N的维度,f是权重函数.权重函数满足[16]:
(10)
选取α=3/4,xmax=100作为参数值.
TF-IDF的计算公式为
(11)
其中,nm,i为词汇wi在文档m中出现的次数,M为文档总数,得到TF-IDF值.
1.4 变分自编码器VAE

logp(xi)=DKL(qθ(z|x)||q(z|x))+lVAE(θ;xi),
(12)
其中,DKL(qθ(z|x)||q(z|x))>0表示近似后验分布与真实后验分布之间的KL散度.lVAE(θ;xi)表示该数据点的边缘对数似然的变分下界.通过不断优化lVAE(θ;xi)的值就可以使近似后验分布qθ(z|x)不断逼近真实后验分布q(z|x).
本文中主要使用VAE来进行各方面信息的混合和降维得到文本的综合特征向量.
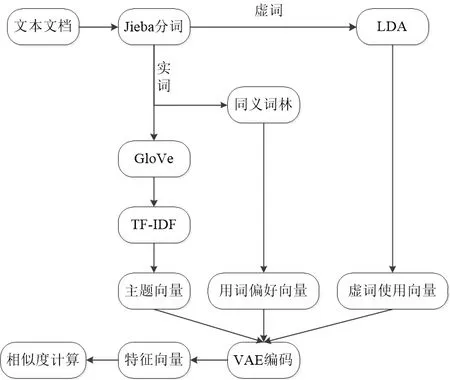
图2 特征提取流程Fig.2 Feature extraction process
1.5 相似度计算
利用Jaccard系数[21-23]来衡量文本的相似度,在得到文本特征后,统计两个文本中相同的特征向量与两个特征向量,相同的特征向量与特征向量的比即为相似度值.其计算方式为
(13)
其中,f(a)和f(b)分别表示文本A和待对比文本B的特征向量.本文取SIM(a,b)≥0.3时判定文本A存在剽窃文本B的现象.
2 多算法文本特征提取方法
多算法文本特征提取方法如图2所示,具体提取流程如下.
1) 利用Jieba工具对文本进行预处理,将虚词、实词分别存储,从而方便后续对文本特征进行提取.
2) 利用分词结果,分别从虚词、实词两个方向进行分析.对于虚词,采用LDA主题模型对虚词进行特征提取,得到文本写作风格其中一个方面的向量维度,即虚词使用维度向量.对于文本中的实词,将其细化为两个部分,分开处理.由于在汉语言中存在大量的同义词,认为不同作者使用同义词时有所差异,通过同义词林对于相同作者的文本使用的同义词进行统计,通过基本的降维,得到写作风格的另一方面的向量维度,即用词偏好向量;针对主题的分析,使用GloVe算法提取词向量,然后使用TF-IDF赋值加权计算得到代表写作主题的向量,即主题向量.
3) 用变分自编码器VAE将3个向量进行降维和混合,得到了能够代表文本的综合特征向量.
4) 进行相似度计算,相似程度给出是否存在抄袭的判断.
3 实验方案及结果分析
3.1 实验数据集
使用python爬取各大新闻平台的新闻文本,搜集了近3年来发布的13 029篇新闻,分为历史、军事、文化、读书等8个类别,所有的新闻文本均以txt文本下载保存.通过借助人工检测和计算机辅助手段,随机选取2 000篇新闻文本作为训练集,剩余11 029篇新闻文本作为验证集.
3.2 评价指标
从可行性与有效性两个方面对抄袭检测算法的准确性进行验证,选取精确率、召回率和F1作为评价指标[24-25].对于实验所用数据集,实际存在抄袭行为的新闻文本量用Np表示;经过相似度计算后检测到的存在抄袭行为的新闻文本量为N,其中检测结果判定正确的新闻文本量为Nt,检测结果判定错误的新闻文本量为Nf.
① 精确率P:正确检测出抄袭行为的新闻文本量Nt与检测出来存在抄袭行为的新闻文本量N的比值,即P=Nt/N;② 召回率R:正确检测出抄袭行为的新闻文本量Nt与实际存在抄袭行为的新闻文本量Np的比值,即R=Nt/Np;③F1值:F1=2PR/(P+R).
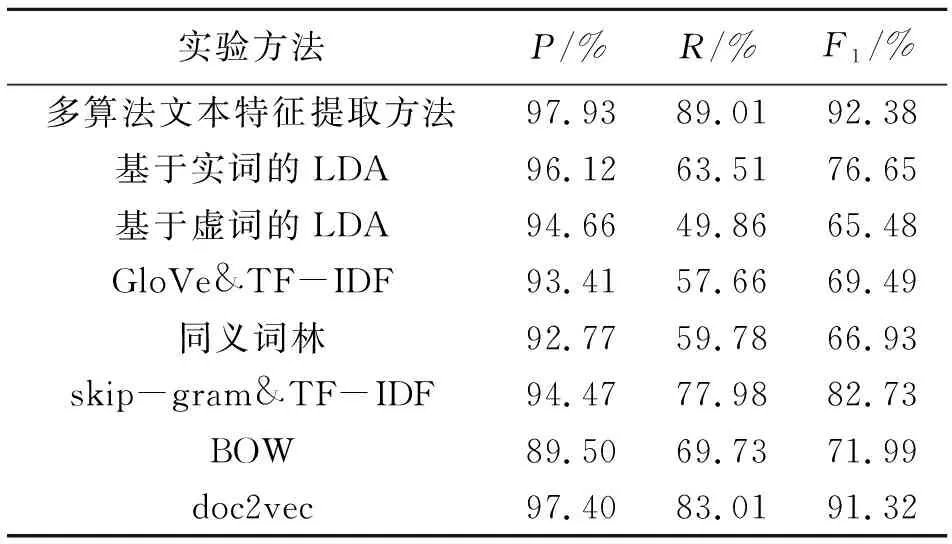
表2 不同特征算法下的抄袭检测结果对比Tab.2 Comparison of plagiarism detection results under different feature algorithms

图3 不同分类算法的精确率、召回率和F1对比图Fig.3 Comparison of precision,recall and F1 of different classification algorithms
3.3 实验结果与分析
使用LDA、GloVe&TF-IDF和同义词林3种算法结合生成文本的特征向量,而后基于此特征进行相似度分析.为了对比特征提取结果的有效性,将本文提出的多算法文本特征提取方法与其他常用于文本生成向量的算法在抄袭检测结果的精确度进行了对比,包括只使用基于虚词的LDA、GloVe&TF-IDF、同义词林统计算法,以及使用基于实词的传统LDA算法、skip-gram&TF-IDF算法、BOW算法和doc2vec算法[21].实验结果如表2所示.
从表2可以看出,本文所提出多算法文本特征提取方法的F1值最高,比doc2vec算法高出1.06%,这是因为虽然doc2vec性能很好,但是没有突出作者写作风格的影响.同时从表2可以看出本文所提出的算法的精确率和召回率均为最高,分别达到了97.93%和89.01%,具有良好的检测效果,说明了本文所提出方法的高度可行性.为了更加直观清晰地展示改进的特征提取算法对分类器分类的指标提升效果,本文根据表2中的数据绘制了不同分类算法的精确率、召回率和F1对比图,如图3所示.
由图3可知,通过折线图的趋势可以快速直观地看出本文所提出的算法在3项指标上的数值均领先于其他算法,同时可以发现doc2vec算法对文本抄袭检测的精确率较高,能够有效对文本进行抄袭检测,但是由于算法没有考虑到文本写作风格和文本主题的影响,导致正确检测出新闻抄袭文本数量相较于本文提出的算法低.本文提出的多算法文本特征提取方法对文本抄袭检测具有高度的有效性与可靠性.
通过上述实验结果分析可以看出,提出的多算法组合对文本特征提取效果有以下优点:① 考虑文本主题与文本风格对文本特征提取结果的影响,设计了一套完整的多算法流程组合对文本进行提取,并将其应用于文本抄袭检测技术中,在减少文本特征数量的基础上增加了抄袭检测的准确率;② 通过构建合理的组合算法流程成功提取出了具有代表性的文本特征,实验结果较为理想.通过上述实验可知,提出的多算法流程法能够准确提取文本特征,降低了特征数量,在查准率和查全率上都有一定的提高.
4 结语
通过分析国内外学者对文本特征提取的缺陷,提出了一套多算法结合的文本特征提取流程,在文本主题和文本写作风格两个维度,将文本从实词和虚词两个部分进行分析.对虚词部分使用LDA主题模型获得了一部分文本写作风格其中一个方面的向量维度;针对实词部分,使用同义词林算法得到文本写作风格另一方面的向量维度,再对实词使用GloVe&TF-IDF算法得到关于文本主题的向量维度.最后,使用变分自编码器(VAE)对上述向量进行混合和降维,提取出能够高度代表文本的特征向量.实验结果表明,考虑文本主题和文本写作风格的多算法融合特征提取算法能够准确提取文本特征,提高了抄袭检测精度.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
语文周报·教研版(2021年10期)2021-05-08
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
数学学习与研究(2018年15期)2018-11-12
文贝:比较文学与比较文化(2016年1期)2016-11-14
环球人文地理(2014年14期)2014-08-15
