
基于随机分布的图像域隐写分析算法研究
2022-03-11 04:43毛春霞赵玄玉
湖北民族大学学报(自然科学版) 2022年1期
毛春霞,李 军,胡 涛,赵玄玉
(湖北民族大学 信息工程学院,湖北 恩施 445000)
互联网技术的发展和普及,为当今社会带来便利的同时,还带来许多潜在的风险,如信息的泄露、隐私窃取等,人们越来越关注互联网上的信息安全和个人隐私保护问题.现有的安全保障分为加密和信息隐藏两种方法:加密主要是对秘密信息本身进行操作,但经过特殊处理后的明文更加容易受到第三方的怀疑;而信息隐藏则是隐藏秘密信息的存在性,使秘密信息在不引起第三方的怀疑下进行隐蔽通信[1].数字图像隐写算法是信息隐藏技术的一个重要分支,它将机密信息难以感知地隐藏在公开的数字图像中,既保护了秘密信息的同时,也保证了隐蔽通信的正常进行.
但随着隐写算法的大量使用,一些非法组织通过隐写算法传递非法信息,给社会带来了很大的危害,如2010年俄国间谍发布的隐写报道,2012年用于隐蔽通信的位图图像隐写,以及2018年抓获的国际贩毒网络头目J.C.R.Abadia使用图像隐写逃避网络追踪和审计,用于记录交易信息,非法和恶意使用隐写算法给社会带来巨大的风险[2].因此,隐写分析的发展迫在眉睫,本研究有助于提升我国数字图像隐写分析技术水平.
主要介绍SRNet隐写分析方法,并在相同数据集上利用不同的隐写方法对SRNet的性能进行测试分析,实现了隐写分析在频域中的应用.主要贡献如下:① 基于Fisher-Yates随机置乱算法生成隐写数据,设计了一种基于随机分布的图像域隐写分析的验证框架;② 深入分析了SRNet隐写分析原理,利用交叉熵对SRNet网络进行损失迭代;③ 利用nsF5、J-UNIWORD和UERD 3种算法实现了BOSSBase v1.01数据集上的信息隐写,并使用训练的SRNet实现了随机分布的图像域隐写分析,实验结果验证了提出的模型在图像域的有效性.
1 隐写算法相关研究
自适应隐写与非自适应隐写是隐写算法中的两种方法[3],最早的LSB(least significant bit)[4]隐写算法是利用人眼对于色彩差异的不敏感性而基于图片最低有效位的隐写方法,之后还有LSB匹配(LSB matching,简称LSBM)[5],LSBM采用随机±1原则嵌入秘密信息,LSB和LSBM都是非自适应的隐写算法,其思想是尽可能少的对载体图像像素进行修改,以增强抗隐写分析能力,但非自适应隐写算法所用载体图像不能压缩,多应用于png、bmp等空域图像中.
自适应隐写算法主要针对载体图像(Cover)的自身属性,如图像内容的边缘信息、纹理信息,将秘密信息嵌入到纹理复杂的区域,提高载密图像(Stego)的抗隐写分析检测能力.常见的自适应隐写算法主要分为空域隐写算法和频域隐写算法,空域上的隐写算法有HUGO[6]、WOW[7]、S-UNIWORD[8]、HILL[9]等;在频域即JPEG域上,隐写算法的特点是将消息隐藏在通过变换域技术变换后的载体图像空间中,具有代表性的隐写方法有J-UNIWORD[8]、UED[10]、UERD[11]、nsF5[12]等,它们通过离散余弦变换、小波变换或奇异值分解等将消息隐藏在载体图像中[13],只要载体图像不被破坏到无法使用的程度,隐藏的信息都能被保留.隐写与隐写分析的关系如图1所示,首先发送方采用隐写算法将秘密信息嵌入到Cover中得到Stego,然后接收方通过公开信道接收到Stego,解密得到所传递的秘密信息.在通过公开信道传递载密图像时,隐写分析者(攻击者)截获到Stego,通过隐写分析算法找出数字图像中存在隐写信息的可能性,有针对性的破坏犯罪分子传递的信息.
2000年,Westfeld等[14]最早提出了针对空域隐写算法LSB的统计检验法,之后,研究者们相继提出了RS、DIH、WS分析法,提高了嵌入率的估计精度[2].近年来,结合深度学习的发展,将传统隐写分析的特征提取、特征增强和二分类模型训练统一起来实现自动化,2014年Tan等[15]提出一种4层深度学习隐写分析网络TanNet,2015年Qian等[16]提出了具有5个卷积层的网络结构,2016年Xu等[17]提出的Xu-Net网络,将高通滤波器层(HPF层)换成KV核对图像进行预处理操作[18],2017年Ye等[19]提出了10层的Ye-Net,2018年Boroumand等[20]提出了SRNet,该模型整体由4部分不同作用的卷积层模块组成,有效地利用BN层和残差网络,在空域和JPEG域都具有良好的检测准确率;2019年Zhang等[21]提出了Zhu-Net,提高了对空域隐写术的检测精度[22].
本文主要对SRNet模型进行测试分析,但SRNet模型的广谱适用性还有待进一步提升,由于在真实应用场景中载体图像的嵌入算法、嵌入容量千变万化,只使用一种隐写方法同一种嵌入率去训练和测试模型,运用到真实的场景中会出现检测准确率与实验所得数据相差甚远的情况,因此,本文提出了运用Fisher-Yates随机分布将3种不同隐写算法结合的数据集,在SRNet模型上去训练和测试,验证提出的模型在图像域的有效性.
2 随机分布隐写数据的图像域隐写分析
2.1 基于随机分布的图像隐写分析框架
基于Fisher-Yates置乱算法的隐写总流程如图2所示.首先输入载体图像数据集,设置嵌入率为0.1~0.5 bpnzac,使用nsF5、J-UNIWORD和UERD 3种隐写算法生成载密数据集;然后将载体和载密数据集通过Fisher-Yates随机置乱算法生成数据,输入到SRNet模型进行训练、测试和验证;通过线性分类器对输入的数据集进行预测,输出判定的载体Cover和载密Stego数据集.
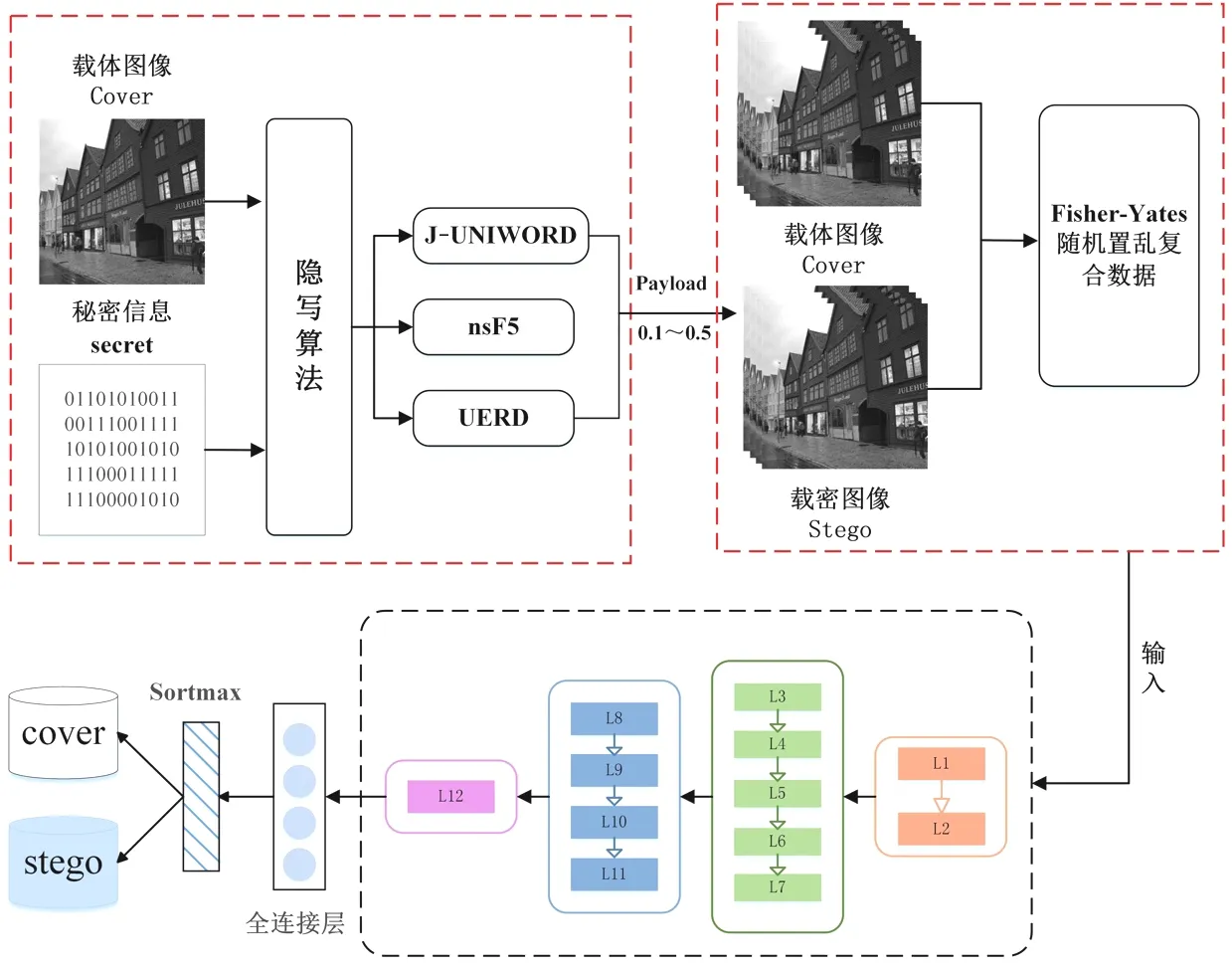
图2 基于Fisher-Yates置乱算法的隐写总流程图Fig.2 General flow chart of steganography based on Fisher-Yates scrambling algorithm
2.2 基于Fisher-Yates的隐写图像数据生成算法
2.2.1 频域隐写算法 nsF5算法通过使用湿纸码(wet paper code,WPC)[23]来减轻收缩的负面影响,解决了F5[24]算法中存在的收缩问题,能得到较少的数据变化,实现更高的嵌入率,达到比F5更高的安全性.均匀嵌入重访问失真(uniform embedding revisited distortion,UERD)是UED算法的改进方法,该方法采用了包括直流系数、零系数和非零交流系数的所有DCT系数作为覆盖单元,在安全嵌入能力方面获得了显著的性能提升,并降低了计算的复杂性.通用小波相关失真J-UNIWORD (JPEG-universal wavelet relative distortion)隐写算法,通过水平、垂直和对角线3个不同方向的线性平移不变滤波器,找到图像中噪声或纹理最复杂的区域,作为信息的嵌入区域[25].Seto()是对载体数据集Image进行隐写算法J-UNIWORD、nsF5或UERD隐写的函数.
(cover,stego)=Seto(Image,secret).
(1)
2.2.2 基于Fisher-Yates的图像数据生成 结合Fisher-Yates随机置乱算法,生成1个有限集合的随机排列.由于Fisher-Yates随机置乱算法是无偏估计的,所以每种排列都是等可能的,其需要的时间正比于要随机置乱的数,不需要额外的存储空间开销,因此可以快速并有效地进行图像数据融合.
基于Fisher-Yates随机置乱算法生成隐写数据的公式如式(2)~(5)所示,
(2)
输入:
temp=ImageN-K[C1,C2,C3;S1,S2,S3],
(3)
ImageN-K[C1,C2,C3;S1,S2,S3]=Imagej∈[0,N-K][C1,C2,C3;S1,S2,S3],
(4)
Imagej∈[0,N-K][C1,C2,C3;S1,S2,S3]=temp.
(5)
输出:Image[C1,C2,C3;S1,S2,S3].
其中j表示随机抽取的数,N代表总数,K代表轮数.
设计基于Fisher-Yates随机分布的图像数据融合算法1,对嵌入率为0.1、0.3和0.5bpnzac的数据集进行隐写,得到相应的数据集,并将其放入SRNet隐写分析网络进行混合验证.
算法1Fisher-Yates随机分布的图像数据融合算法.
数据准备:选取嵌入率相同的nsF5、J-UNIWORD和UERD 3种算法的隐写数据集,
通过nsF5、J-UNIWORD和UERD 3种算法隐写得到3万张混合图片数据集,
按照训练集(train)、测试集(test)和验证集(validation)为5∶4∶1的比例进行分配,
其中每类数据集分为载体图像(Cover)和载密图像(Stego).
输入:等待随机置乱的N张图像数据集Image.
fori从m-1到1
j取随机整数,并满足条件0≤j≤i
交换Image [i]和Image [j]
end
输出:数据集Image’.

图3 SRNet网络结构图Fig.3 SRNet network structure diagram
2.3 基于SRNet的隐写分析算法
SRNet是隐写分析残差网络(Steganalysis Residual Network)[20],它是一种端到端的隐写分析网络结构.SRNet有效地利用批归一化BN(Batch Normalization)[26]层和残差网络,通过引入通道选择,提高了模型对隐写算法的检测准确率.
SRNet包含两种快捷方式的层,因为非池化层(Type2)与池化层(Type3)需要不同的快捷连接方式.Type1的(L1~L2)带有3×3过滤器,能在Type2之前将特性映射的数量从64减少到16以节省内存;Type 3与Type 4的最后一层不同,Type 3使用平均池化,而Type 4应用了可以缩小计算图并减少运算量的全局平均池化,然后将得到的数据放入全连接层帮助网络的训练.
设输入灰度图像的尺寸为256×256,所有非线性激活函数均为ReLU.如图3所示,图层L1~L7在输入时使用未合并的特征映射.在图层L8~L11的输出上应用3×3的池化,并使用步长为2进行平均,在L12层,通过计算每个16×16特征图的统计矩(平均值),将512个维度16×16的特征图简化为512维特征向量,这个512维输出进入网络的线性分类器部分,输出判定的载体图片(Cover)和载密图片(Stego).
由于隐写分析属于二分类,模型最后预测的结果只有载体Cover和载密Stego两种情况,对每个类别预测得到的概率为p和1-p,SRNet使用交叉熵[27]做损失函数,损失函数表达式为
(6)
其中Sj表示样本j的标签,载密Stego为1,载体Cover为0;而pj表示样本j预测为正类的概率.
3 实验与验证
3.1 数据集与预处理
使用的原始图像数据集是BOSSBase v1.01[28],数据集包含10 000个大小为512×512的.pgm格式的灰度图,其中包含生活、景点、建筑等多种类型图片,BOSSbase1.01是Fridrich团队2011年所创建的用于隐写分析竞赛的专用数据集,采用7种不同类型数码相机拍摄得到的图像,可以防止单个数码相机拍摄出现相机指纹,使判别器学习出现偏差[2],图4是BOSSbase数据集中不同类别的图片.
首先将所有的图像调整为256×256,并转换为.jpg格式.本文选择了3种有代表性的隐写术:nsF5、J-UNIWORD和UERD作为攻击目标,这3种隐写术都是JPEG域隐写算法.
隐写容量可用嵌入率(Payload)表示,表示平均每一个嵌入位置所能承载的隐蔽信息量,令m表示传输的消息量,n为嵌入样点的数量,则负载率e计算如式(7)所示:
e=m/n.
(7)
其单位为bpp(比特/像素)或bpnzac(每个非零AC系数的位数).利用0.1~0.5 bpnzac的隐写率对nsF5、J-UNIWORD和UERD 3种算法进行隐写,将生成9类不同的载密图像数据集,其中,图像质量因子(QF)都为95.在每次实验中,数据集共有原始图像10 000张,载密图像8 000张,训练集、测试集和验证集按照5∶4∶1的比例进行分配.

图4 BOSSbase数据集中部分图片Fig.4 Part of pictures in BOSSbase datasets

图5 3种隐写算法嵌入后的图像隐写点图(0.4 bpnzac)Fig.5 Dot map of image steganography after three steganography algorithms are embedded
3.2 频域隐写算法性能分析
在自适应隐写算法中,图像中纹理复杂区域的元素被修改的可能性大于纹理平滑区域的元素,因为在统计规律负载区域造成的扰动不容易被察觉.如图5所示,随机从BOSSBase 1.01数据集中抽取3张不同类型的图片,经过嵌入率Payload为0.4 bpnzac的3种隐写算法嵌入以后,所得到的图像隐写点图,从图5中可以看出,自适应隐写算法更倾向于在图像纹理复杂的区域进行嵌入操作.
如图6所示,随机从BOSSBase 1.01数据集中选取到1张建筑图像,然后分别用3种隐写算法以0.1、0.4 bpnzac的嵌入率隐写后的图像修改点图,图6中(a)~(d)嵌入率为0.1 bpnzac,(e)~(h)嵌入率全为0.4 bpnzac,Stego是以J-UNIWORD算法隐写的载密图像.分析图6中的修改点图,嵌入率越大,隐写的内容越多;当嵌入率相同时,nsF5隐写算法的嵌入点轮廓最清晰,边缘的嵌入比重与其他两种算法相比较多,UERD隐写算法的修改点比较分散,而J-UNIWORD算法修改点主要集中在纹理复杂的中间区域.
当嵌入率为0.1、0.4 bpnzac时,图7是图6对应嵌入的隐写像素点数直方图.从图7中可以看出,当嵌入率为0.1 bpnzac时,3种隐写算法的空间域像素差范围在[-5,5]之间,远小于嵌入率为0.4 bpnzac的空间域像素差[-10,10];并随着嵌入率的增加,像素的点数也逐渐增加,空间域的像素差分布得更加均匀.

图6 3种隐写算法在嵌入率为0.1、0.4 bpnzac时的隐写点图Fig.6 Dot map of steganographic of the three steganography algorithms when the embedding rate is 0.1 and 0.4 bpnzac
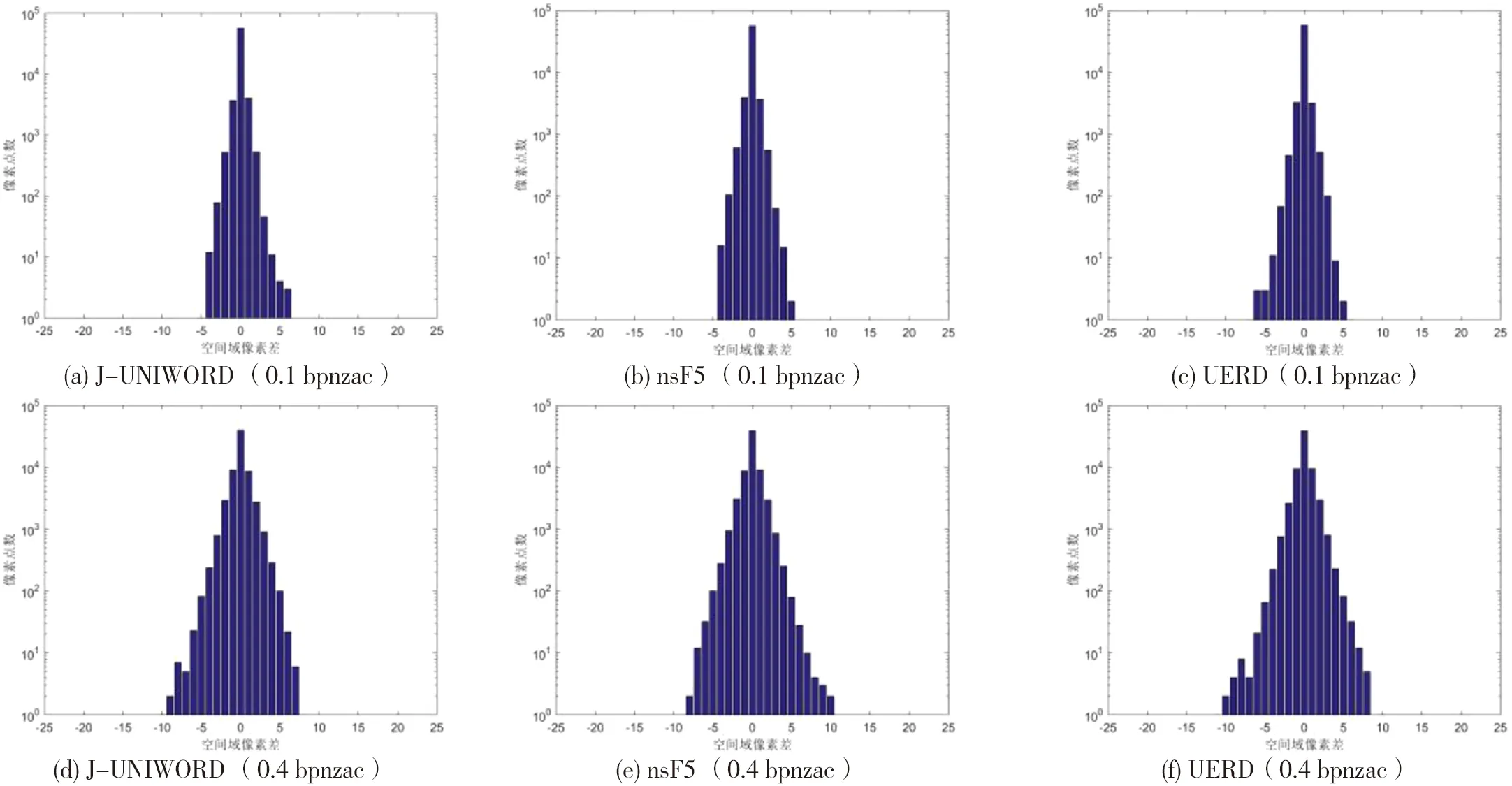
图7 3种隐写算法嵌入率分别为0.1、0.4 bpnzac的直方图Fig.7 Histogram of three steganography algorithm with embedding rates of 0.1 and 0.4 bpnzac
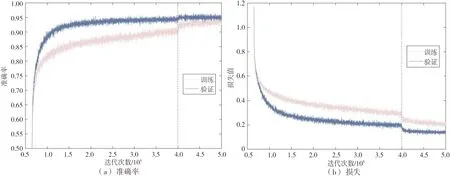
图8 嵌入率为0.4 bpnzac的J-UNIWORD训练和验证准确率与损失Fig.8 Training and validation accuracy and loss for J-UNIWORD at 0.4 bpnzac(QF=95)
3.3 随机分布的隐写性能分析
设置迭代40万次时,学习率由0.001降低到0.000 1,图8(a)和(b)是基于J-UNIWORD隐写算法、嵌入率为0.4 bpnzac的SRNet训练过程和验证过程中准确率和损失的变化.如图8所示,当迭代到40万次时,检测准确率明显升高,而模型损失下降,SRNet模型进入收敛状态,在后期,训练和验证的准确率趋于一致,证明了SRNet模型的适用性.
分别用J-UNIWORD、UERD和nsF5自适应算法在图像嵌入率为0.1、0.3、0.5 bpnzac的情况下对SRNet模型的检测准确率进行验证,如表1所示.实验对比发现,当训练嵌入率为0.3 bpnzac、测试嵌入率为0.5 bpnzac时,SRNet隐写分析模型对UERD算法的检测准确率更高,达到93.16%;当训练嵌入率为0.5 bpnzac、测试嵌入率为0.1 bpnzac时,SRNet隐写分析模型对nsF5算法的检测准确率更低,达到51.62%.
表2是表1三种隐写算法测试准确率的平均值和方差,测试嵌入率为0.5时,模型平均值在80.77%~91.66%之间,方差在2.56%~7.37%之间,因此,可以看出SRNet具有很强的鲁棒性.

表1 不同嵌入率SRNet模型上的准确率
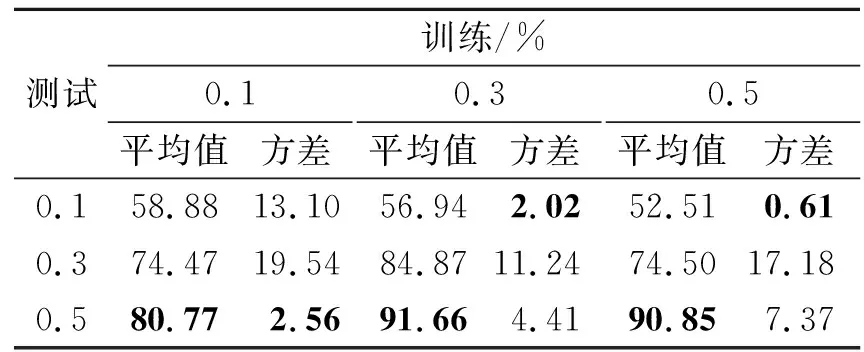
表2 SRNet模型上不同嵌入率的平均值和方差
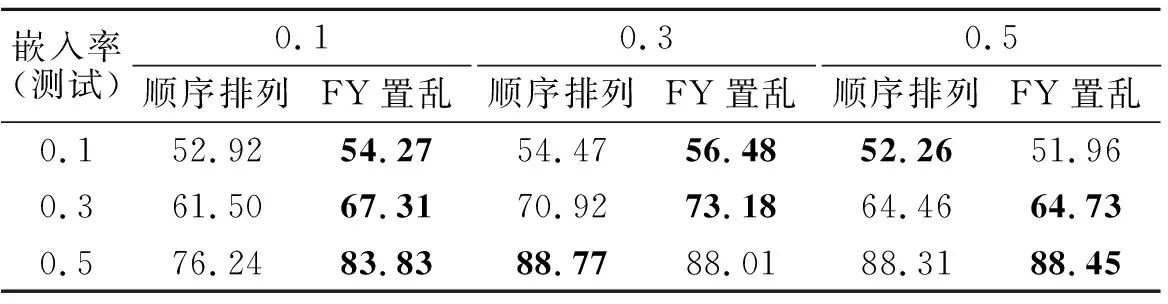
表3 随机分布数据上的SRNet模型的准确率Tab.3 The accuracy of the SRNet model on randomly distributed data %
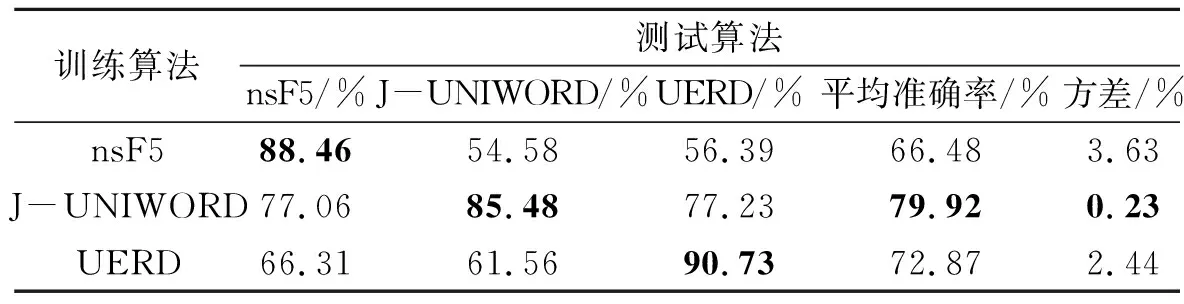
表4 0.4 bpnzac下SRNet训练算法和测试算法不匹配情况下的准确率Tab.4 Detection accuracy for SRNet trained on one algorithm and tested on other algorithms payload fixed at 0.4 bpnzac
基于Fisher-Yates数据生成算法在SRNet模型上的准确率如表3所示.实验统一选定迭代为45万次时的模型做测试,通过顺序排列和FY置乱(Fisher-Yates置乱排列)的数据在进行相应的训练和测试时,除了训练嵌入率为0.3 bpnzac、测试嵌入率为0.5 bpnzac和嵌入率为0.5 bpnzac、测试为0.1 bpnzac时,顺序排列的准确率略高,FY置乱数据的准确率总体上都高于顺序排列,表明Fisher-Yates置乱排列具有更强的适用性.
在实际应用中,经常需要用SRNet模型去检测未知隐写源的图片,为了评估SRNet模型检测不匹配载密源的能力,本文在同一嵌入算法上训练SRNet,并在同一嵌入率下测试多种嵌入算法.表4中展示了嵌入率为0.4 bpnzac下测试了多种嵌入算法的准确率,从实验结果来看,J-UNIWORD算法具有很好的迁移效果,当基于J-UNIWORD训练的SRNet网络对3种算法进行测试时,平均准确率为79.92%±0.23%;相对来说,基于nsF5训练的SRNet网络的迁移效果最差,3种隐写算法分析的平均准确率为66.48%±3.63%.
4 结语
本文提出了一种基于Fisher-Yates随机分布的数据生成算法,选择J-UNIWORD、UERD和nsF5 3种自适应隐写算法,以0.1~0.5 bpnzac的嵌入率,通过SRNet隐写分析模型训练、验证每种隐写算法的测试准确率,通过实验数据分析,验证了随机分布数据上的SRNet模型在图像域的适用性.实验中,顺序排列的个别测试准确率比Fisher-Yates置乱排列略高,下一步将通过改进网络结构,进一步提高基于随机分布的深度学习网络图像隐写分析的性能.
猜你喜欢
华人时刊(2022年9期)2022-09-06
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
华人时刊(2020年15期)2020-12-14
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
作文小学中年级(2020年6期)2020-07-24
中国火炬(2013年11期)2013-07-25
