
顾及地理空间信息的无人机影像匹配像对提取方法
2022-03-24 09:05任超锋蒲禹池张福强
自然资源遥感 2022年1期
任超锋, 蒲禹池, 张福强
(长安大学地质工程与测绘学院,西安 710054)
0 引言
无人机(unmanned aerial vehicle, UAV)低空摄影测量具有现势性强、分辨率高、采集方式灵活、传感器多样化等优点,近年来在应急测绘[1]、城市三维重建[2]、滑坡地形重建[3]、文物三维重建[4]等领域得到了越来越广泛的应用。然而,由于低空UAV一般搭载非量测相机,且受平台不稳定性及传感器多样化等诸多因素影响,获取的影像尺度不一致,且数据量庞大,为影像匹配带来极大挑战。此外,近年来新兴的仿地飞行、环绕飞行、贴近飞行等数据获取方式,更使传统的影像匹配方法难以满足需求。
影像匹配作为三维自动重建的基础环节,其效率与稳健性对重建结果起着决定性作用。尤其针对复杂地形条件下的三维重建,能够获取的有效匹配像对越多,影像连接成功的概率也越高。总体上可将其分为2个环节: ①提取匹配像对,即从大数据量的遥感影像中按照一定方法提取具有重叠区的一对影像; ②按照影像匹配算法对提取的像对进行双像匹配提取匹配像对,获取同名点列表。近年来,针对多角度、大倾角的无人机影像,文献[5-7]在尺度不变特征变换(scale-invariant feature transform,SIFT)[8]和仿射尺度不变特征变换(affine-scale-invariant feature transform, ASIFT)[9]算法基础上提出了相应的匹配策略,同时借助图形处理器(graphics processing unit, GPU)[10]并行运算,这一类方法均可快速完成像对的同名点匹配。然而,如何从大量影像中提取匹配像对的研究还处于比较初级的研究阶段。
在UAV影像匹配像对提取方面,文献[11-12]采用穷举遍历策略,对影像集中任意两两影像进行匹配。该类方法可靠性最高,但存在大量盲目的无效运算,效率太低; 文献[13]利用影像初始地理位置信息,计算当前影像与其相邻影像的空间距离,进而采用固定阈值范围内的像对进行匹配; 文献[14]则通过动态搜索的方法确定阈值,提高了匹配的可靠度,但当测区内存在多层次、不同分辨率的UAV影像时,其获取的搜索阈值无法保证为全局最优值; 文献[7,15-16]则利用影像的定位定向系统(positioning and orientation system, POS)测量数据、传感器结构设计参数及内方位元素、测区地形信息等先验知识,计算每张影像的脚印图,进而利用脚印图的拓扑关系,判定像对是否具有重叠区。由于该类方法计算量小,且对常规数据获取方式具有较好的适应性,因此是目前低空UAV影像匹配像对提取的主要方法。然而,从原理可知,该类方法高度依赖先验知识的准确性,因此,当测区地形信息不确定(如滑坡、山谷、独立地物等)、或者传感器设计参数无法准确得知时(如多镜头倾斜相机、组合倾摆相机),该类方法便无法准确计算出像对的相关性。文献[17]则从影像内容信息出发,利用提取的特征信息构建视觉词袋(bag of visual words, BoW)模型,进而利用影像检索方式确定待匹配像对; 文献[18]在生成BoW模型过程中,计算海明嵌(hamming embedding, HE)来提升影像检索的准确度; 文献[19]则提出了一种霍夫投票算法加速影像检索过程。由于这类方法一般面向的都是无序、无地理信息的网络图像数据,其检索结果与影像是否具有重叠区没有明确关系,且计算量过大,难以直接使用。
针对上述问题,本文提出一种顾及影像地理空间信息的BoW模型方法来确定待匹配像对,对地形条件、影像获取方式、传感器类型均无限制条件,进而减少影像匹配过程中的冗余计算,以解决UAV影像匹配像对的高效、准确提取问题。
1 方法原理
本文提出的UAV影像匹配像对提取方法流程为: ①按照文献[8]和[10]所述方法,依次完成测区所有影像的SIFT特征提取; ②为了提高影像检索效率,对提取的SIFT特征进行降维,降低生成视觉词汇树的运算量; ③采用文献[20]方法,利用降维后的特征向量构建视觉词汇树; ④检索所有影像,并计算词汇树内单词的检索权重; ⑤在词汇树内,查询与当前影像最相似的影像列表,并计算其与查询列表内影像的空间距离指数,综合相似指数与空间距离指数对检索列表进行排序,最后利用综合指数计算查询深度阈值,将阈值之前的查询影像与当前影像组合形成匹配像对。具体方法流程如图1所示。

图1 顾及地理空间信息的UAV影像匹配像对提取方法流程
1.1 特征向量降维
SIFT算法以其尺度、旋转不变性并能克服一定程度仿射变形和光照变化得以在影像匹配领域得到广泛使用[7],但原始的SIFT特征包含128维特征向量,若将其直接用于影像检索,会产生大量的高维度运算,造成影像检索效率过低。因此,本文采用主成分分析(principal component analysis, PCA)方法对高维度的SIFT特征向量进行降维。
将构建视觉词汇树的m个SIFT特征组成矩阵Xm×128,按照PCA原理对其进行奇异值分解 (singular value decomposition, SVD),即
(1)
式中:U和V分别为m阶和128阶正交矩阵;Wm×128为r个降序排列的特征值σi(i=1,2,…,r)构成的m×128矩形对角矩阵。

(2)
1.2 视觉单词检索
将降维后的SIFT特征进行聚类,聚类的过程即为构建视觉词汇树过程。聚类之后,每一个聚类中心表示为一个视觉单词,一幅影像可以表示为多个视觉单词的无序集合,此时,UAV影像之间的相似性判定即可转变为视觉单词之间的相似性判定。
本文采用文献[20]的方法构建层次词汇树,同时采用词频逆文档频率(term frequency-inverse document frequency, TF-IDF)评价某一个视觉单词对于视觉词汇树中某一影像的重要程度,其定义为:
(3)
式中:ft为词频;fid为逆文档频率;nip为影像p中出现视觉单词i的数量;np为影像p中出现的所有视觉单词数量;N为影像总体数量;ni为包含视觉单词i的影像数量。
词频ft表达了某个视觉单词在影像中的出现频率,而逆文档频率fid则表达了该视觉单词在其他影像上的重复频率,两者组合之后可将视觉单词的重要性随着它在影像文件中出现的频率呈正比增加,同时也会随着它在视觉词典中出现的频率呈反比下降。
当视觉词汇树创建完成后,依次检索数据集中每一幅影像中视觉单词的出现频率。检索完成之后,即可计算其TF-IDF因子。此时,每一幅影像均可表示为一组带不同权重的视觉单词组合。评价2幅影像是否相似,即可通过计算2幅影像的单词向量点积完成,公式为:
(4)
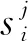
1.3 影像查询
相似因子只是评价2幅影像所含视觉单词的相似性,在大部分情况下,具有相似内容的影像一般也具有重叠区。然而,当地表类型比较单一时(如大片田地、灌木、裸露山地),相似的区域并非一定具有重叠区。此时,若将影像之间的空间距离作为影响因素参与评价,则可大大提高两者之间的相关性。图2为反距离权重因子示意图。

图2 反距离权重因子
如图2所示,当前影像Ii与查询影像Ij之间空间距离越近,则其存在重叠区的可能性越高。因此,本文计算当前影像与相似影像列表之间的反距离权重因子,用以评价两者之间的空间相关性,公式为:
(5)

(6)
1.4 查询深度阈值
查询深度是指以综合权重因子为依据,在影像集合中查询出与当前影像相似性最高的前Q张影像,组成待匹配像对,如图3所示。

图3 查询深度阈值
图3中,查询影像Ii与查询深度Q共组成Q对像对进行匹配。实际处理过程中,Q值过小会造成漏检,而Q值过大则会引入大量无效匹配像对,降低匹配效率。因此,本文采用查询深度阈值的方式对查询深度进行分割,仅将阈值前的影像与查询影像组成匹配像对进入匹配环节。阈值计算公式为:
(7)
式(7)以类间方差最大为原则,将Q内的影像分为前景与背景2部分。式中:N1为属于阈值t之前的影像数量;w1和w2分别为前景和背景的影像频率;μ1为阈值t之前影像的综合因子平均值;μ2为阈值t之后的影像综合因子平均值;g表示前景影像与背景影像之间的类间方差。在查询深度内,类间方差最大对应的位置即为查询阈值t*,公式为:
(8)
2 实验与分析
2.1 实验数据与配置参数
为验证本文方法在多采集方式、多传感器类型、多地形条件下提取匹配像对的可行性、精度与效率,共收集了5组实验数据进行实验。数据集的详细信息如表1所示。

表1 试验无人机数据集
基于Windows10 64位操作系统,采用VC++2015开发了海量UAV影像自动空三处理软件MRI,用于测试本文方法的适应性。硬件平台为Dell Precision 3630工作站,CPU i7-8700K 3.7 GHz,内存64 G DDR4,硬盘512 G SSD,显卡为英伟达 Titan XP 12 G。
2.2 结果与分析
为了评价低维特征对影像检索效率及精度造成的影响,对表1中5组影像提取的原始128维特征向量进行降维,分别降至96维、64维、32维,并按照文献[19]方法对影像进行检索。检索过程中,生成词汇树的聚类中心数量统一设置为影像数量的200倍,检索深度统一设置为100,构建词汇树的影像从数据集中随机提取,其数量设置为数据集影像数量的20%,且最大影像数量不超过500幅。评价检索方法精度时,首先采用穷举法完成5组影像匹配,然后以其匹配结果为基准,评价其他检索方法的查询精度。
评价影像查询精度通常采用查准率和查全率(图4)。查准率通过计算查询深度内正确的查询影像与查询深度的比值构成,它反映了查询过程中正确像对的比例,查准率越低,意味着匹配环节引入错误匹配像对数量越高,相应的匹配耗时也越高。查全率则通过计算查询深度内正确的查询影像与穷举法匹配中得到的所有正确影像数量比值构成,它反映了当前特征条件下,能提取到的匹配像对的完整度,查全率越低,意味着稀疏重建时的可靠性越低,容易丢片。因此,查准率与查全率之间相互制约,在查全率相当的前提下,查准率越高,则算法的效率越高。除了计算128维、96维、64维、32维特征的检索精度外,按照本文方法分别计算32维和64维的综合检索因子检索精度,分别用32G和64G表述。从图4(a)中可知,总体上,影像查询的查准率随着特征维度降低而递减,当特征维度降到32维时,其影像查准率明显降低。反观图4(b),此时的查全率却最高。其原因主要是32维的影像特征丢失了过多的细节信息,使特征之间的可分性降低,在引入大量错误匹配像对基础上,也将大量弱连接的像对引入匹配环节。虽然提升了整体的查全率,但后续的匹配环节效率太低。因此,综合考虑效率与精度,将特征降低至64维进行影像检索是合适的。


(a) 查准率 (b) 查全率
表1中的5个测试数据集,数据A和B为正射类型,数据C,D,E可归为倾斜类型。正射类型中,随着特征维度降低,其查准率和查全率均缓慢降低,而本文的综合查询因子方法在相同特征维度条件下,均获得了最高的查准率和查全率。为了分析综合查询因子的计算过程,从数据集B中提取一张影像在64维和64G模式下的查询因子曲线进行说明,其结果如图5所示。

图5 相似因子与综合因子曲线
图5中,相似因子曲线在前端具有明显差异,后端则趋于平坦,不具有明显的可分性。而且,在常规相似因子曲线中,查询曲线后端还包含大量正确的检索影像。而采用本文综合因子的曲线,正确的检索影像大部分集中在查询曲线的前端。
图6即为图5的部分查询影像,其中图6(a)为当前查询影像,图6(b)为采用64维传统相似因子的查询影像,在曲线中索引位置为21,按照传统相似因子判定依据,图6(a)和(b)将会组成待匹配像对进入匹配环节。然而,从影像内容分析,虽然两者之间存在大量相似的林木区域,但却不具有重叠区,因此,内容相似的影像并非一定具有重叠区。通过计算综合查询因子,图6(b)所代表的影像已不在综合查询曲线内,而原本不在传统查询曲线内的图6(c)影像进入了综合查询曲线。因此,综合查询因子不仅可以有效剔除错误像对,还能将遗漏的部分影像纳入影像匹配环节。此外,通过式(7)计算得到的查询阈值,将大量错误的影像剔除匹配环节,进一步提高了查询过程的查准率。


(a) 当前查询影像(b) 采用64维传统相似因子的查询影像(c) 遗漏的待匹配影像
与正射类型数据不同,图4中的倾斜影像数据C,D和E呈现超高的查准率和超低的查全率,且查全率随着特征维度降低不降反升。通过分析实验数据发现,其原因主要在于数据类型的差异。通常情况下,正射摄影方式获取的UAV数据,其影像重叠度一般不超过50,即一个地物点可在50张影像上成像。而倾斜影像不同,其影像重叠度一般超过200。此时,将Q设置为100将使查询出的大部分影像都为正确的匹配影像,即查询结果表现为超高的查准率。而大量的正确匹配像对由于查询深度限制并未提取出来,从而造成了超低的查全率。
表2中依次设置Q为100,200和300时,对数据C,D,E的查询精度进行统计,随着查询深度的增加,倾斜类型数据的查准率逐渐降低,而查全率得到大幅提升,并且本文方法均取得最高的查准率和查全率。因此,针对倾斜类型的查询深度设置应不小于200。

表2 不同查询深度的查准率和查全率
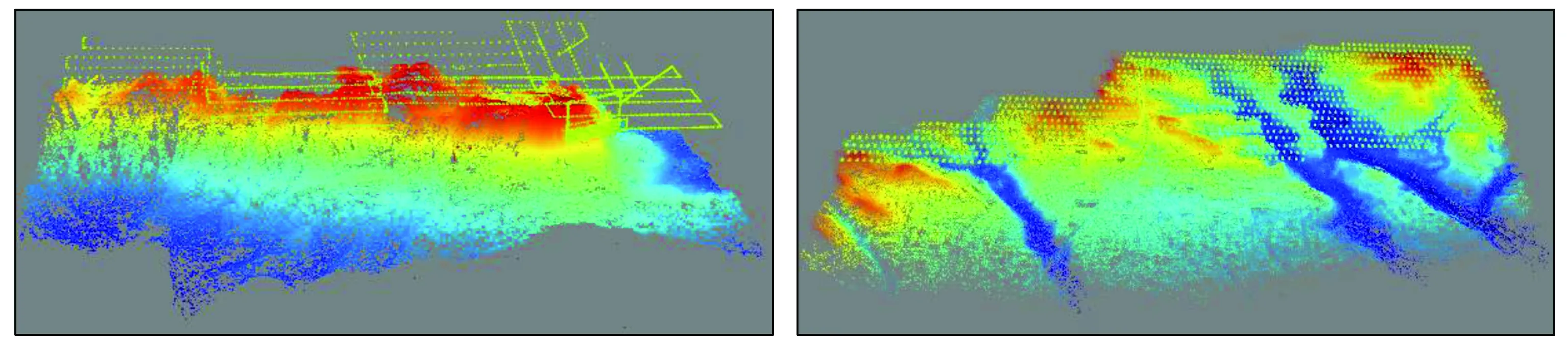
查询过程中会产生很多重复查询像对,而最终进入匹配环节的则是剔除重复像对之后的像对列表。因此,为了综合评价本文方法效率,特将匹配像对提取耗时归入影像匹配环节。此外,为便于比较分析,分别实现了基于脚印图的影像检索[7]、基于128维传统影像检索[17]以及本文顾及地理空间信息的64维特征影像检索3种匹配像对提取方法,针对倾斜影像数据C,D,E,其查询深度统一设置为200,稀疏重建采用增量式重建,统计结果如表3所示。采用本文方法进行稀疏重建的结果如图7所示。

表3 稀疏重建的效率、完整性及精度


(a) 数据A(b) 数据B

(c) 数据C(d) 数据D

(e) 数据E
为了综合评价不同方法之间的匹配效率,本文将构建词汇树、构建索引、影像检索及双像匹配耗时相加,统称为匹配时间。从表3中可知,针对正射影像数据A和B而言,传统的脚印图法匹配效率最高。而128维特征检索方法效率最低,且稳定性也不足。比如数据A中,相较于其他2种方式,128维特征的稀疏重建结果丢失了10幅影像,而丢失的影像基本都处于影像纹理匮乏的测区边缘区域,说明单纯依靠纹理特征的相似性判定像对是否具有重叠区并不严密。而针对倾斜类型的数据C,D,E而言,本文方法的效率、稳定性最高。如图7(c)所示,数据C由于地形条件限制,其航线设计比较混乱,且包含了正射、贴近2种摄影方式。传统的脚印图方法没法准确估算贴近摄影方式的脚印图,所以最终获取的稀疏重建结果丢片比较严重,且主要集中在测区右上角,即贴近方式获取的影像区域,而128维、64G检索方法则成功将大部分贴近方式获取的影像连接成功。此外,本文的64G模式获得了最完整的稀疏重建结果。当数据量增多时,本文方法的匹配效率优势更加明显。与脚印图方法相比,数据C,D,E的匹配效率分别提升了15.16%,23.27%,45.25%,而与传统128维检索方法相比,其匹配效率分别提升了39.66%,61.00%,51.73%。
综上所述,本文方法的优势可归纳为以下3点: 第一,适应性最高。不需要传感器的先验知识,对场地类型及数据获取方式也无限制。第二,通过综合查询因子,提高了匹配效率及精度,尤其适合海量UAV数据的匹配像对提取。第三,检索深度与影像类型相关。正射类型的影像数据,查询深度设置为100即可,倾斜类型的数据,查询深度应不小于200。结合处理效率、重建结果的完整性、算法的适应性等结果对比,本文提出的顾及地理空间信息的UAV影像匹配像对提取方法更具优势。
3 结论
本文针对UAV影像匹配像对的提取问题,将高维度的特征降维至低维特征,同时引入影像之间的空间信息构建综合查询因子,并通过计算检索阈值,舍弃检索深度内的无效匹配像对,获得了较高的效率及全面的重建结果。
利用5种不同类型的数据进行实验与分析,结果表明,与前人已提出的脚印图法相比,前2种常规类型的单相机正射影像数据匹配效率并未提高,而后3种多相机倾斜影像数据匹配效率分别提升了15.16%,23.27%和45.25%。与传统128维检索方法相比,5种数据的效率分别提升了46.29%,38.66%,39.66%,61.00%和51.73%。此外,本文方法仅需影像的空间位置信息,更适合数据量较大的倾斜影像,具有更好的适应性。
本文方法还需改进的地方在于,遗漏了少量正确的待匹配像对,其对三维重建结果的影响还需进一步评定。
猜你喜欢
科学与财富(2019年27期)2019-10-25
数码世界(2019年9期)2019-09-07
电子制作(2019年14期)2019-08-20
现代电子技术(2018年20期)2018-10-24
现代电子技术(2018年16期)2018-08-21
现代情报(2018年11期)2018-01-07
现代电子技术(2017年23期)2017-12-20
计算机应用(2016年10期)2017-05-12
中国管理信息化(2009年10期)2009-06-19
