
基于双向长短记忆网络和门控注意力的文本分类网络
2022-03-31 15:03童根梅朱敏
华东师范大学学报(自然科学版) 2022年2期
童根梅 朱敏








摘要: 首先 , 提出构建双向的全连接结构用于更好提取上下文的信息;然后 , 利用双向的注意力机制将包含丰富文本特征的矩阵压缩成一个向量;最后 , 将双向的全连接结构和门控制结构相结合. 通过实验验证了上述结构对于提升文本分类的准确率具有积极的作用.将这3 种结构和双向的循环网络进行结合 , 组成了所提出的文本分类模型. 通过在7 个常用的文本分类数据集(AG、DBP、Yelp.P、Yelp.F、Yah.A、 Ama.F、Ama.P)上进行的实验 , 得到了具有竞争性的结果并且在其中5 个数据集(AG、DBP、Yelp.P、 Ama.F、Ama.P)上获得了较好的实验效果. 通过实验表明 , 所提出的文本分类模型能显著降低分类错误率.
关键词:文本分类; 注意力机制; 长短记忆网络
中图分类号: TP399 文献标志码: A DOI: 10.3969/j.issn.1000-5641.2022.02.008
Bi-directional long short-term memory and bi-directional gated attention networks for text classification
TONG Genmei1 , ZHU Min2
(1. School of Computer Science and Technology, East China Normal University, Shanghai 200062, China;
2. School of Data Science and Engineering, East China Normal University, Shanghai 200062, China)
Abstract: In this paper, we propose the construction of a bi-directional fully connected structure for better extraction of context information. We also propose the construction of a bi-directional attention structure for compressing matrices containing rich text features into a vector. The bi-directional fully connected structure and the gated structure are then combined. This research demonstrates that the proposed combined structure has a net positive effect on text classification accuracy. Finally, by combining these three structures and a bi-direction long short-term memory, we propose a new text classification model. Using this model, we obtained competitive results on seven commonly used text classification datasets and achieved state-of-the-art results on five of them. Experiments showed that the combination of these structures can significantly reduce classification errors.
Keywords: text classification; attention; long short-term memory
0 引言
互联网技术的迅猛发展产生了海量的数据信息 , 使得人们进入了大数据时代 , 互联网也成为人们获取信息的主要渠道之一.通过互联网可以传递各种形式的信息 , 其中绝大部分信息都以文本的形式存在, 文本形式的信息能够让用户快速、便利地获取.面对海量的信息, 用户如何能从其中精准地获取对自己有价值的信息变得越来越难 , 这就对于信息检索和信息分类技术的要求越来越高.因此 , 如何让用户从互联网的海量信息中快速、精准地获取对自己有用的信息 , 寻找一种能对文本信息进行准确分类的方法变得尤为重要.
自然语言处理的目的是让计算机能成功地处理大量的自然语言数据. 文本分类是自然语言处理的一个基本任务 , 同时也是自然语言处理任务中一个非常重要的环节. 文本分类是指计算机按照预先定义好的分类标准 , 根据文本的内容自动地将文本数据集中的每一个文本划分到某一个类别中 , 整个系统输入的是需要进行分类的大量文本数据集 , 输出的是每个文本所属的类别. 相对于传统手动获取文本特征进行分类的方法 , 通过计算机对文本的自动处理 , 不仅提升了分类的效率 , 而且能进一步提高分类的准确性. 如今, 文本分类被广泛应用 , 比如, 情感分析、问答系统和垃圾邮件检测等.
LEAM (Label-Embedding Attention Model)认为一个典型的文本分类方法包含3 个步骤[1]:第 1步 , 将文本通过词嵌入转化为矩阵 V, 其中 Word2vec 和 GloVe 是2种常用的词向量生成方法[2] , 目前用得比较多的还有动态词向量 , 它是将输入的文本 , 经过预训练的模型后 , 输出相应单词的词向量表示 , 这类词嵌入的预训练语言模型主要有 ELMo (Embedding from Language Models)[3] , BERT (Bidirectional Encoder Representations from Transformers)[4] , GPT-2(Generative Pre-Training-2)[5]等.第 2步 , 通過不同的方法将词嵌入形式的矩阵 V 转化成固定长度的向量表示 Z, 该过程的目的是从文本的分布式表达中提取特征.第 3步 , 设计一个分类器对固定长度的向量表示 Z 标记标签 , 该过程的分类器通常是由一个全连接层和 softmax 函数构成.虽然很多研究人员在设计各种不同的特征提取方法时 , 将文本的分布式表达矩阵 V 转化为固定长度的向量表示 Z, 但这些方法在提取文本的上下文信息上仍然存在局限性. 卷积神经网络 CNN (Convolutional Neural Network)和循环神经网络 RNN (Recurrent Neural Network)是最为常见的2 种特征提取方法. Kim[6]首先提出了采用 CNN 进行文本分类并且实现了超越传统方法的效果. 但是该方法只是通过使用不同尺寸的卷积核和不同的池化操作来考虑短语的重要性 , 不具有联系上下文的能力. 为了解决这个问题 , 文献[7-8]提出了使用 Deep- CNN 进行文本分类 , 虽然这种方法具有联系上下文的能力 , 但是会导致参数的增加 , 使得模型训练过程更加困难. RNN 具有更强的联系上下文的能力 , 但是它是具有偏向性的模型 , 很难联系长距离的依赖关系.为此 , Hochreiter 等[9]提出了 LSTM (Long Short-Term Memory)和门控循环单元 GRU (Gate Recurrent Unit), 它们能较好地解决传统 RNN 的弊端. 文献[10-11]提出了将 CNN 和 RNN进行结合的方法 , 这种方法首先利用 RNN 来提取上下文信息 , 然后通过 CNN 构造更深层的特征表达 , 最后使用最大池化操作进行特征选取 , 从而提取到一些重要的特征.
为了解决 RNN 在联系长距离依赖关系中存在不足的问题 , 本文所提出的结构从2个方向上对特征矩阵进行特征提取.实验表明这种方法能更好地提取上下文信息.同时 , 将该方法和循环神经网络相结合 , 进一步强化了整个模型对上下文的理解 , 其中 , 循环神经网络主要负责提取局部的信息 , 双向的全连接网络则将局部的信息整合成包含全文信息的特征.此外 , 本文还提出了一种双向的注意力机制 , 这种方法能从2个方向上将富含文本特征的矩阵融合为一个向量 , 尝试将 LSTM 中的门控制结构和本文所提出的双向的全连接结构进行结合 , 以提升分类模型在文本分类运用中的效果.在 7个通用的文本分类数据集(AG、DBP、Yelp.P、Yelp.F、Yah.A、Ama.F、Ama.P)上进行了实验 , 得到了具有竞争力的结果 , 在其中的5 个数据集(AG、DBP、Yelp.P、Ama.F、Ama.P)中 , 本文所提出的模型达到了最低的测试错误率 , 特别是在2个较大的数据集(Ama.F、Ama.P)中 , 本文所提出的组合模型使得测试错误率相比于之前最好实验效果的错误率降低了约17.47%.
1 相关工作和模型算法
1.1 模型
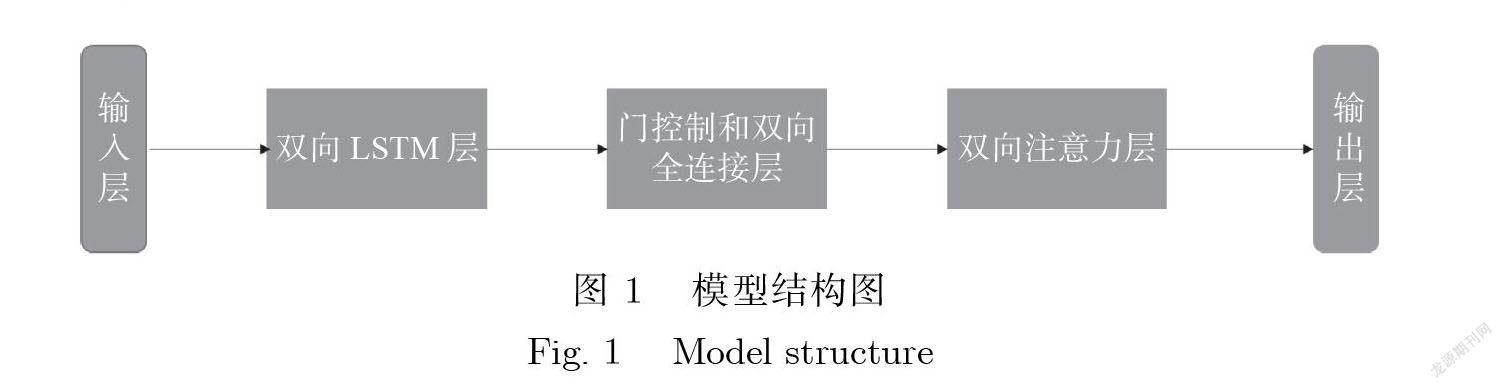
本文所提出的模型结构由5 个部分组成:输入层、双向 LSTM 层、门控制和双向全连接层、双向注意力层及输出层 , 模型结构如图 1所示.
1.2 双向 LSTM 层
为了解决梯度消失和梯度爆炸问题 , Hochreiter 等[9]首先提出了 LSTM.其主要思想是采用当前的输入信息和门控制结构决定之前状态的保留程度. 将输入的文本表示成 X =(x1; x2; ·· ·; xl). 其中 l 是输入文本的长度 , xi 表示文本中的第 i 个词向量. 式(1)是 LSTM 的基本单元 , 用于更新t 时刻的记忆Ct和隐藏层的状态 , 具体表示为
式(1)中: W ∈ R4n (n+m) , m 是词向量的长度 , n 是隐藏单元的个数; b ∈ R4n 是一个偏置项;[ht ; xt]是一个级联的操作; 是一个sigmoid 函数 , 表示输入门 t 、忘记门ft 和输出门ot 的激活函数; tanh 表示候选状态 t 的激活函数是双曲正切函数 , 当前的状态Ct用于存储上下文的信息 , 忘记门ft 和输入门 t用于过滤上一时刻的状态Ct 1和当前时刻的候选状态 t并将它们组合成当前的状态Ct , 具体输出的内容由输出门ot控制;⊗表示向量对应元素进行数乘运算 , 通过相应的门控制结构控制相关内容的删除和保留. Hochreiter 等[9]通过连接相反时间顺序流中每个时刻的信息 , 将无向的 LSTM 网络扩展为双向的 BLSTM (Bidirectional Long Short-Term Memory), 因此该模型能考虑过去和未来的信息.在本文中 , BLSTM 用于捕捉过去和未来的信息 , BLSTM 在每个时刻的输出主要考虑了较小范围内的信息.在 BLSTM 中t 时刻的输出ht 可以表示为
1.3 门控制和双向全连接层
从 LSTM 的网络结构中可以知道 , LSTM 通过门控制结构能从模型的输入、输出以及上下文中筛选出有效信息.这个方法的核心是在全连接层利用 sigmoid 和 tanh 作为激活函数来获取文本特征 , 并将所得到的结果进行点乘.
门控制结构能选择更有效的信息以及消除一些无用的信息 , 因此 , 本文将双向的全连接结构和门控制结构进行了组合 , 提出了门控制的双向全连接结构. 双向的全连接结构经过激活函数之后 , 将2 个输入矩阵进行点乘 , 如图 2所示.
1.4 双向注意力层
在介绍双向注意力结构之前 , 首先对注意力机制进行介绍. Pappas 等[12]第一次提出了一种将 GRU 网络和注意力机制相结合的方法 , 并在文本分类中进行运用. 注意力机制表示为
(3)
式(3)中: H 表示一个特征图矩阵; Ws表示该全连接层的特征向量; bs表示对应的偏置项; tanh 表示所对应的激活函数; 表示权重矩阵; T 表示转置. H 由 GRU 网络在各个时刻的输出组成 , 例如 , i 时刻的输出即为 hi .首先 , 将 GRU 網络中每一时刻的输出经过一个全连接层 , 再将一个随机初始化上下文向量us(T)和上一步所得到的结果进行相乘 , 得到 hi 和上下文的相似度值Si;然后 , 将每个得分利用 softmax 函数进行正则化 , 得到归一化的权重矩形 ;最后 , 对每个输入利用相应的得分进行加权求和得到对应句子向量v .这是一个自注意力机制 , 通过自身的输入确定自身的权重 , 对所有的输入进行加权求和得到模型的输出.如果将所有的输入组合成一个矩阵 , 那么这个过程可以看成是将一个矩阵融合成一个向量的过程.式 (3)表示的注意力机制通过对特征向量进行加权求和 , 得到包含丰富文本信息的文本向量.因此 , 也可以采用对相同特征维度、不同时间维度的向量进行加权求和的方法 , 以得到最适合的句子表示向量 , 这也是一种将矩阵融合为向量并且通过输出层对文本进行分类的方法.本文对这种方法进行了测试 , 式(4)展示了该方法的定义 , 用时间维度的向量表示替代式(3)中的特征维度向量表示 , 具体为
最后 , 本文将特征维度注意力机制所获得的向量v 和时间维度注意力机制所获得的向量连接成一个向量 V .
式(5)表示将向量v 和连接成一个向量 , 最后将连接后的向量作为输出层的输入.
1.5 输出层
在输出层中 , 本文采用了一个全连接层和 softmax 函数来预测文本所属的类别. 式(6)表示选择最高概率值所对应的标签作为文本的标签 , 具体为
式(6)中: Ws为该全连接层的特征向量; bs为对应的偏置项; 是利用 softmax 函数计算得到对应的输出值; 表示该文本标签值.
2 实验准备
2.1 实验数据集和设置
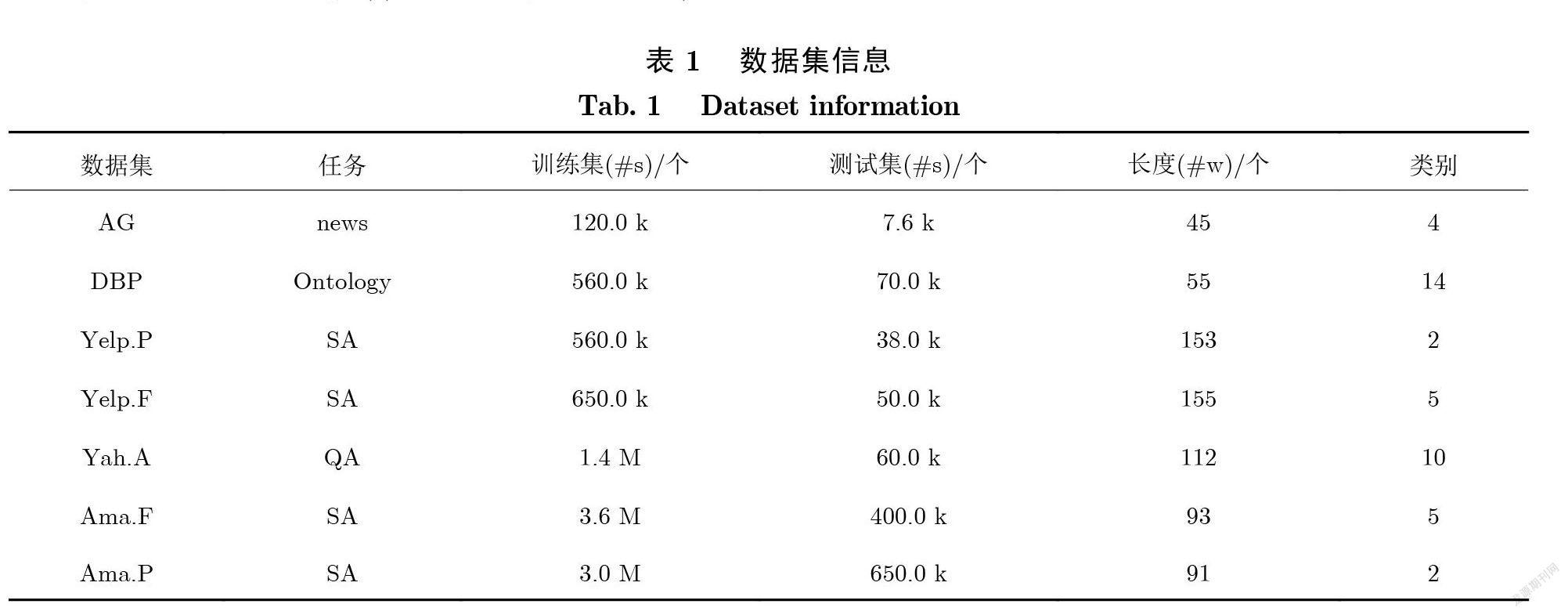
为了方便和之前的模型进行比较 , 本文采用了7 个常用的数据集( 表1).这 7个数据集是由 Zhang 等[13]收集得到的. AG (AG_news)数据集是有关新闻(news)的 , 它包含了4 个类别. 数据集中句子的平均长度是45个词 , 训练集和测试集数据相对都比较小. DBP (DBPedia)是一个关于 Ontology 的具有 14个类别的分类数据集. 该数据集中文本的平均长度是55. Yelp 和 Ama 是2 个有关评价的数据集.“.P”表示“Polarity”意味着是他们是二分类的数据集.“.F”是“Full”的缩写意味着该数据集是对评论更为细致的划分 , 具有更多的类别. Yelp.F 和 Ama.F 的类别数都是5. Yah.A 是一个10分类的数据集, 数据来源于 https://answers.yahoo.com/. 表1展示了每个数据集的统计信息.
表 1中: SA 表示情感分析(Sentiment Analysis); QA 表示问答(Question Answering);#s 表示句子的数量;#w 表示每个文档中词的平均数量; k 表示计数单位千; M 表示计数单位兆.
在文本数据预处理过程中 , 首先 , 使用空格将标点符号与句子中的单词分开 , 本文认为标点符号在分类中扮演非常重要的角色 , 因此保留了各种标点符号. 然后 , 使用 NLTK (Natural Language Toolkit)的标记器工具来划分句子. 最后 , 将所有大写字母转换为小写字母. 为了使模型的输入具有相同的大小 , 对于相同的数据集 , 将所有句子的长度限制为固定长度. 对于简短的句子 , 添加特殊词“PADDING”. 数据集中出现了大量单词 , 有些单词很罕见 , 这些罕见的单词中有些是拼写错误导致的.因此, 删除这些罕见的单词 , 有效地减少了詞汇量 , 对分类准确性几乎没有影响.
对于模型的参数设置和训练 , 本文实验使用未标记的数据训练单词向量 , 这样操作可以显著提高神经网络的泛化能力 , 并防止数据稀疏[14]. 在模型训练过程中 , 对词向量进行微调可以有效提高分类的准确性 , Pennington 等[2]使用 GloVe 模型训练本文中所使用的词向量. GloVe.42B 向量的维数为300.对于没有预训练词向量的词 , 本文实验将其随机初始化, 随机生成向量中的每个元素的值都在区间[–0.5, 0.5]上.双向 LSTM 网络中的隐藏单元数为305, 在双向完全连接结构中 , 第1—2步中的隐藏单元数都为305.对于不同的分类任务 , 本文所选择文本的平均单词量如表 2所示.
在双向注意机制中 , 第1 步隐藏单元的大小选择为152, 第2 步隐藏单元的大小选择为⌈l/2⌉ , 其中 l 为句子长度 , “⌈⌉”表示向上取整.从文本矩阵的输入 , 到 BLSTM 网络的输出 , 本文对所有任务都采用 dropout 方法来避免梯度消失现象的出现. 本文还使用 Adam 训练模型[15] , 初始学习率为0.001.学习率以指数方式衰减 , 经过一个时期的训练 , 学习率变为最后一个时期的94%.
2.2 实验基准
Linear model[13]:运行步骤为 , 首先, 进行人工提取特征;然后, 进行多项逻辑回归;最后, 得到相应文本的类别. 常见的人工特征工程包括词袋和词频逆文档频率.
Char-level CNN/Word-level CNN: Zhang 等[13]设计了一个9 层的卷积神经网络进行文本分类. 使用字符级和词级进行词嵌入来考虑其对文本分类的影响 , 其中, 词级输入由预训练的词向量表示.
Char-RCNN[16]:在此模型中 , 使用字符级嵌入方式 , 输入的字符级嵌入 , 首先 , 通过卷积网络层;然后, 通过 LSTM 网络;最后, 通过输出层获得不同标签的预测概率.
FastText[17]:该模型结构 , 首先 , 将文本转换为由 Word2vec 训练的词向量;然后 , 对文本的词向量进行平均池化操作;最后 , 使用线性分类器获得最终的输出结果.此模型结构不仅简单 , 而且训练速度非常快.
VDCNN (Very Deep Convolutional Neural Networks)[7]: VDCNN 是由 29个卷积层组成的网络 , 它可以获取更深层次的文本表示 , 增强了模型理解上下文的能力 , 在大型数据集上取得了非常好的实验结果.
DPCNN (Deep Pyramid Convolutional Neural Networks)[8]:这是一个具有15个卷积层的深度神经网络. 通过使用下采样 , 缩短模型的训练时间 , 使用短连接解决梯度消失和梯度爆炸问题.
Region.emb[18]:文献[18]提出了一种新的与任务相关的“局部嵌入”模型, 以分布式 n-gram 表示文本, 可以有效地捕获重要的句法细节 , 从而提高文本分类准确性.
LEAM[1]:该模型提出了一种用于分类标签的词嵌入新方法以及一种新的注意力机制 , 从而优化了分类效果.
3 实验结果
3.1 每个模块对模型的影响
构建整个模型的过程是 , 先构建出每个对分类具有积极意义的模块 , 再将各个模块通过合适的方式拼成一个大的模型.为了确保实验的科学性 , 在所有的模型上进行的实验所采用的实验参数和条件都保持一致.
3.1.1 双向注意力机制
假设在输入的文本矩阵中 , 每一个列向量代表一个特征向量 , 通常对该特征向量进行加权求和只能得到 y 维度的注意力值. 本文从2个方向运用了注意力机制 , 对输入矩阵的行向量进行加权求和 , 记为 x 维度的注意力值 , 对输入矩阵的列向量进行加权求和 , 记为 y 维度的注意力值. 通过一个简单的实验验证了二维的注意力结构比单个维度更为有效.本文实验对文本的特征矩阵添加注意力机制 , 利用一个输出层和 softmax 函数对所属标签进行预测 , ATTx 表示文本矩阵 x 维度的注意力机制 , ATTy 表示文本矩阵 y 维度的注意力机制 , ATTxy 表示对文本矩阵2 个维度的向量都使用了注意力机制.由表3可知 , 即使只对 x 维度添加注意力机制 , 仍然可获得不错的分类效果 , 而在 y 维度的基础上添加 x 维度注意力机制 , 能够使得模型在各文本分类数据集上的分类错误率进一步降低.由此可知 , 该模型对于提升文本分类的准确率具有积极意义.
3.1.2 双向全连接层
本文所提出的双向全连接结构 , 通过增加一个维度的全连接层使得模型具有更强的联系上下文能力. 本文对只有一个维度上的全连接层网络和2 个维度的全连接层网络在相同的数据集上进行了实验(表4).首先 , FC (Fully Connected)对输入的文本矩阵经过一个普通的全连接层;然后 , FC 再利用 y 维度的注意力机制对矩阵进行压缩;最后 , FC 利用输出层获得其对每个标签的预测概率. BFC (Bidirectional Fully Connected)相对于 FC 从一个维度的全连接层换成了2 个维度的全连接层. 通过比较 FC 和 ATTy 可知 , 增加简单的全连接层能使得分类的准确率有所提升 , 这和构建深层的卷积网络用于文本分类具有类似的作用.对比 BFC 和 FC 的结果可知 , 增加另一个维度的全连接层对提升文本分类准确率是一种有效的方法.
3.1.3 门控结构
为了验证 LSTM 的门控制结构对于提升模型的分類效果具有积极的意义 , 本文在 BFC 的基础上增加了门控制机制 , 注意力结构仍然采用的是 y 维度的注意力(表5).由表5可知 , 增加门控制机制 ,降低了在 AG、Yelp.P 和 Yah.A 3个数据集上的错误率.
3.1.4 BLSTM-ATTy
为了验证在 BLSTM 的基础上 , 增加双向注意力机制能有效提升文本分类的效果 , 本文构造了 BLSTM 增加一个维度的注意力机制的模型. 表 5展示了将 BLSTM 与注意力结构相结合的方法. 通过该实验可以发现 , 该结构在测试集上已经能取得非常高的准确率 , 但是和表 6中最好的结果相比仍然还有差距.
3.2 实验结果
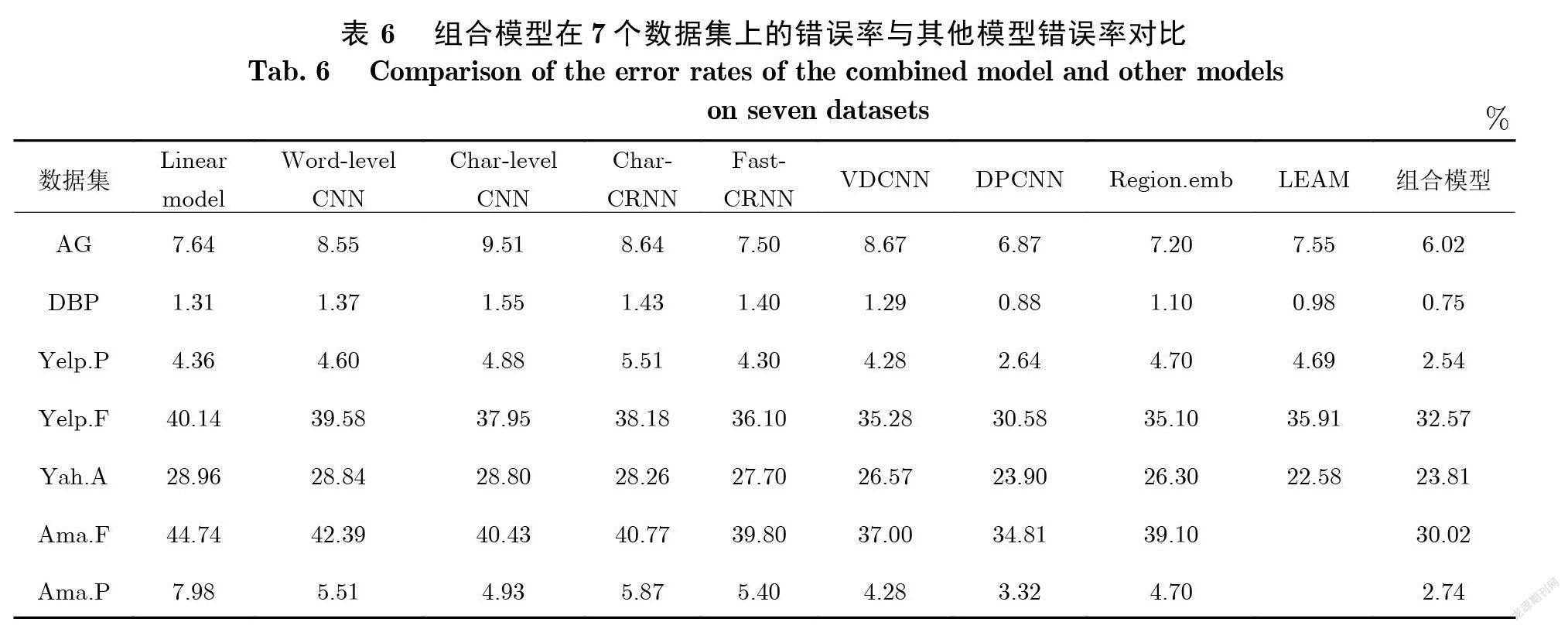
本文验证了整个模型中不同的组成部分对于提高文本分类准确率具有积极意义. 本文最后将所有的结构组合成一个更加完整的模型. 为了便于比较 , 表6列出了不同的模型在测试集上的错误率. 由表6可知 , 在所有的7 个数据集(AG、DBP、Yelp.P、Yelp.F、Yah.A、Ama.F、Ama.P)上 , 本文所提出的模型在其中的5 个数据集(AG、DBP、Yelp.P、Ama.F、Ama.P)上得到了较好的结果 , 在剩余的2 个数据集上也能得到非常具有竞争力的结果.
在 AG 和 DBP 2个较小的数据集上 , 本文的结果相比于其他模型所得到的结果在测试集上的错误率分别降低了12.37%和 14.77%.在 Ama.F 和 Ama.P 这2个较大的数据集上, 本文的模型使得错误率分别降低了13.76%和 17.47%.本文所提出的模型不仅拥有较强的联系上下文的能力 , 同时添加了双向注意力机制 , 使得文本特征的提取更加精确.虽然每个组成部分在文本分类任务中没有取得足够好的结果 , 但是本文将所有的结构组合在一起使文本分类的效果有了很大的提升.为了得到类似的效果 , DPCNN 和 VDCNN 都是通过不断地增加网络的结构 , 本文的模型只包含了5 层结构就得到比 DPCNN 和 VDCNN 更好的实验结果.对于 DPCNN 和 VDCNN 结构 , 只有更高层次的卷积核才能获得更大范围的上下文信息 , 底层的卷积核只能获得非常有限范围的信息.本文通过引入双向的全连接结构能将不同位置的单词信息联系起来.
4 结论
本文提出了双向全连接结构、双向注意力结构以及增加门控制机制的双向全连接结构 , 在验证了这 3种结构有助于降低文本分类错误率的情况下 , 通过一定的方式将这3 种结构和双向 LSTM 进行组合 , 构建了一种新的文本分类组合模型.在 7个通用的文本分类数据集上进行了实验 , 获得了具有竞争力的结果 , 证明了将本文所提出的3 种结构与双向 LSTM 进行组合所形成的新的模型能显著降低在测试集上分类的错误率. 和其他深层的 CNN 模型相比 , 在包含输出层的情况下本文只采用了5 层的结构 , 证明了将不同结构进行合理的组合相比于不断重复单一的结构更加有效.
[参考文献]
[1] WANG G, LI C, WANG W, et al. Joint embedding of words and labels for text classification [C]// Proceedings of the 56th AnnualMeeting of the Association for Computational Linguistics.2018:2321-2331.
[2] PENNINGTON J, SOCHER R, MANNING C. GloVe: Global vectors for word representation [C]// Conference on Empirical Methodsin Natural Language Processing.2014:1532-1543.
[3] PETERS M, NEUMANN M, IYYER M, et al. Deep contextualized word representations [EB/OL]. (2018-03-22)[2020-10-16].https://arxiv.org/pdf/1802.05365v2.pdf.
[4] DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding [EB/OL].(2019-03-24)[2020-10-16]. https://arxiv.org/pdf/1810.04805.pdf.
[5] RADFORD A, WU J, CHILD R, et al. Language models are unsupervised multitask learners [EB/OL].(2019-01-08)[2020-10-16].https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf.
[6] KIM Y. Convolutional neural networks for sentence classification [EB/OL].(2014-09-03)[2020-10-16]. https://arxiv.org/pdf/1408.5882v2.pdf.
[7] CONNEAU A, SCHWENK H, BARRAULT L, et al. Very deep convolutional networks for text classification [EB/OL].(2017-01-27)[2020-10-16]. https://arxiv.org/pdf/1606.01781v2.pdf.
[8] JOHNSON R, TONG Z. Deep pyramid convolutional neural networks for text categorization [C]// Proceedings of the 55th AnnualMeeting of the Association for Computational Linguistics.2017:562-570.
[9] HOCHREITER S, SCHMIDHUBER J. Long short-term memory [J]. Neural Computation, 1997, 9(8):1735-1780.
[10] LAI S, XU L, LIU K, et al. Recurrent convolutional neural networks for text classification [C]// Proceeding of the 25th InternationalJoint Conference on Artificial Intelligence.2015:2267-2273.
[11] PENG Z, QI Z, ZHENG S, et al. Text classification improved by integrating bidirectional LSTM with two-dimensional max pooling[EB/OL].(2016-11-21)[2020-10-22]. https://arxiv.org/pdf/1611.06639.pdf.
[12] PAPPAS N, POPESCU-BELIS A. Multilingual hierarchical attention networks for document classification [EB/OL]. (2017-09-15)[2020-09-14]. https://arxiv.org/pdf/1707.00896v4.pdf.
[13] ZHANG X, ZHAO J, LECUN Y. Character-level convolutional networks for text classification [EB/OL].(2015-09-10)[2020-09-11].https://arxiv.org/pdf/1509.01626v2.pdf.
[14] TURIAN J P, RATINOV L A, BENGIO Y. Word representations: A simple and general method for semi-supervised learning [C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics.2010:384-394.
[15] KINGMA D, BA J. Adam: A method for stochastic optimization [EB/OL].(2015-07-30)[2020-10-16]. https://arxiv.org/pdf/1412.6980v8.pdf.
[16] XIAO Y, CHO K. Efficient character-level document classification by combining convolution and recurrent layers [EB/OL].(2016-02-01)[2020-10-16]. https://arxiv.org/pdf/1602.00367v1.pdf.
[17] JOULIN A, GRAVE E, BOJANOWSKI P, et al. Bag of tricks for efficient text classification [EB/OL].(2016-08-09)[2020-10-13].https://arxiv.org/pdf/1607.01759v3.pdf.
[18] QIAO C, HUANG B, NIU G, et al. A new method of region embedding for text classification [EB/OL].(2018-01-30)[2020-10-16].https://openreview.net/pdf?id=BkSDMA36Z.
(責任编辑:陈丽贞)
猜你喜欢
电子技术与软件工程(2019年5期)2019-06-20
软件导刊(2019年1期)2019-06-07
数字技术与应用(2019年2期)2019-05-14
现代电子技术(2018年8期)2018-04-13
软件工程(2017年11期)2018-01-05
智能计算机与应用(2017年5期)2017-11-08
计算机应用(2016年12期)2017-01-13
电子技术与软件工程(2016年22期)2016-12-26
数字技术与应用(2016年9期)2016-11-09
电脑知识与技术(2016年23期)2016-11-02
