
基于IC卡交易和车辆调度信息的站点客流分析算法研究
2022-04-07 14:38李少彬
城市公共交通 2022年1期
孙 健 李少彬
(南京公共交通(集团)有限公司,南京 210037)
引言
合理科学的公交调度和线网规划,可以缓解城市快速发展、人口激增、出行需求大幅度上升引起的交通拥挤、交通安全事故等普遍问题。而公交调度和线网规划也依赖于对海量客流的全面、精准分析和统计。国内外研究学者通过运用海量IC卡数据,结合车辆GPS数据,对客流建立多维度数学模型,从客流OD、候车时长、客流拥堵等方面分析客流特征和规律。本文通过原始刷卡数据中已经提供的线路编码、车辆编码、刷卡经纬度、刷卡时间,结合车辆调度信息以及地理信息系统提供的线路下各站点经纬度信息,通过经纬度坐标投影算法以及车辆实时调度信息的查询计算,得出精确的刷卡站点信息。同时利用redis数据库内存高吞吐的特性,实时过滤清洗刷卡设备记录到的重复刷卡数据。刷卡站点信息反映了各线路各站点客流量的高低,对整个公交线路的运营具有指导意义,对客流量拥挤地区的治安管理也具有一定的参考价值。
1 原始数据采集
1.1 原始刷卡数据
原始刷卡数据只包含了部分信息:
(1)车辆注册线路编码。线路编码是市民卡中心对线路名称的一种规范。同时,在本地数据库维护一张线路编码和线路名称一一对应的映射关系表。
这样做的好处在于:存储线路编码比存储线路名称更节约数据库空间,而且查询线路编码比查询线路名称更快。
(2)车辆编码。车辆编码也是市民卡中心对车辆名称的一种规范。
(3)刷卡经纬度、刷卡时间。这两者分别记录了刷卡所在的空间和时间上的信息。空间的信息可以用于计算线路上各个站点的距离,时间的信息可以用于查询当前车辆所在的实时调度信息。
1.2 车辆实时调度信息
调度信息指的是车辆的进出站信息,包括:
(1)车辆实际运营线路编码。车辆所在的运行线路编码区别于原始刷卡数据中的注册线路编码,实际运营中,车辆可能会被临时调度至其他线路运营。
本文计算中,刷卡数据属于哪个线路、哪个站点以实际调度信息为准,可以精确反映公交车辆的实时运营情况。
(2)线路上下行。车辆在某条线路上运行,根据运行方向的不同,可以规定为上行和下行。
(3)站点信息。站点信息指的是该时刻车辆“进”或“出”的站点。
车辆实时调度信息缓存在redis数据库,利用其内存高吞吐的特性,为原始刷卡数据实时计算刷卡站点提供了高性能的数据库查询条件。
1.3 线路下各站点经纬度信息
地理信息系统为我们提供了精确的位置信息,为了计算方便,在mysql数据库中维护了一张线路与站点的静态信息表。包含了各线路下所有站点的经纬度信息、上下行信息、各站点上一个站点和下一个站点的信息,见表1样例。
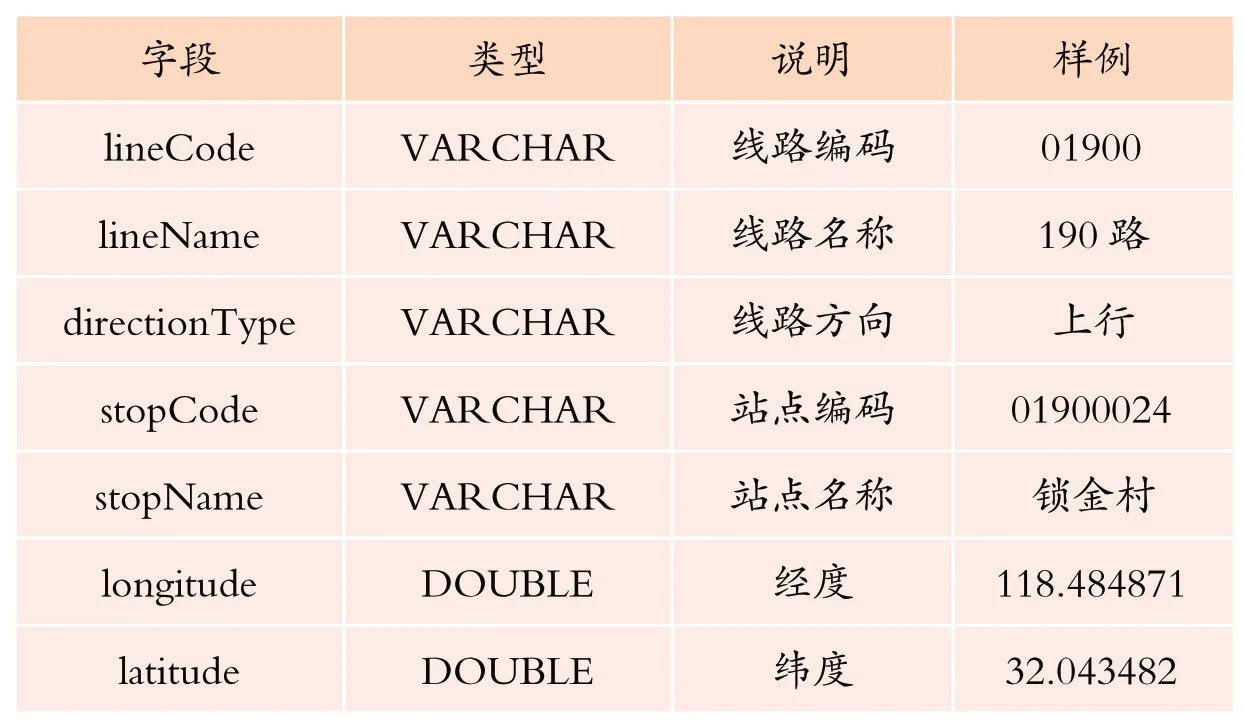
表1 线路经过的站点数据样例
2 基于坐标投影和车辆调度算法的数据处理
计算刷卡站点主要考虑两种算法,分别为:
(1)坐标投影算法,基于刷卡经纬度和站点经纬度计算刷卡站点。
(2)调度信息计算刷卡站点,基于刷卡时间和车辆的进出站时间计算刷卡站点。
两种算法各有优缺点,本文结合两种算法,得到较为精准的刷卡站点。
2.1 寻找运行线路和上下行
原始刷卡数据记录的是车辆注册线路,因此需要通过车辆自编码去redis或者mysql数据库查询车辆的进出站数据,进出站数据中记录的才是车辆真正的运行线路。同时明确了上下行可以为第2步减少需要比对的站点,提高计算效率。
2.2 经纬度坐标投影算法
计算刷卡经纬度与所在线路上各站点经纬度的距离。距离最小的站点记为minStopCode。最小距离记为minDistance。计算距离涉及到两个部分。
(1)经纬度转换。地球表面是一个不规则的球面,为了便于说明,以下用一个椭圆绕轴旋转形成的球面来表示:
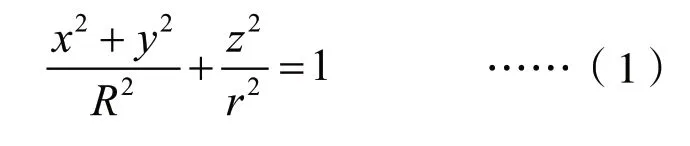
式中,R为赤道半径,r为极轴半径。由于推算资料的不同,R和r的值会有些许差异,本文采用的是WGS-84椭球体[1,6],即R=6378137米,r=6356752.314米。考虑到计算距离时需要使用同一套坐标系,对线路下各站点的经纬度进行坐标系转换。举例说明:(118.484871, 32.043482)经纬度转换后为(118.808118, 32.07247)。
(2)经纬度计算距离。影响两点之间距离计算的两个因素:
a.经度每度的距离,即弧长。纬度越小,弧长越大,反之,则越小。
b.纬度每度的距离大概是相等的,约为111000米。
计算某个纬度下经度平均每一度距离S[2-3]的公式如下:

式中,B为所在区域的纬度。
考虑到我们计算所在的目标区域纬度范围为:北纬31°14′至32°37′。因此分别将这两个纬度值代入公式(2),对两个计算的结果取平均值,为97850.268米。用这个值进行两个点之间距离的计算[4-5]。举例说明:刷卡经纬度(118.778736,32.051028)和转换后的站点经纬度(118.778835,32.051083)计算距离为11.2米。
如果minDistance≤50米,则取对应的站点作为刷卡站点。
如果minDistanc>50米,则说明刷卡点距离最近的站点都比较远,不好判别刷卡站点。进行第3步。
2.3 基于调度信息和刷卡时间查询刷卡站点
存在以下两种异常情况:
(1)原始刷卡数据无刷卡经纬度,这是由刷卡设备或者车辆GPS设备异常导致的。
(2)经纬度坐标投影算法计算的最近站点距离都大于50米,这可能是人为原因导致的。
上述两种情况都会导致原始刷卡数据计算不到刷卡站点。因此需要通过刷卡时间和车辆的进出站信息去进一步寻找刷卡站点。通过调度信息寻找刷卡站点的依据可以概括为以下公式:

式中,adTime为车辆的进出站时间,swipeTime为刷卡时间。整个公式的含义是:取调度信息中该车辆的进出站时间小于刷卡时间,且是最大的一个进出站时间,所对应的站点作为刷卡站点。
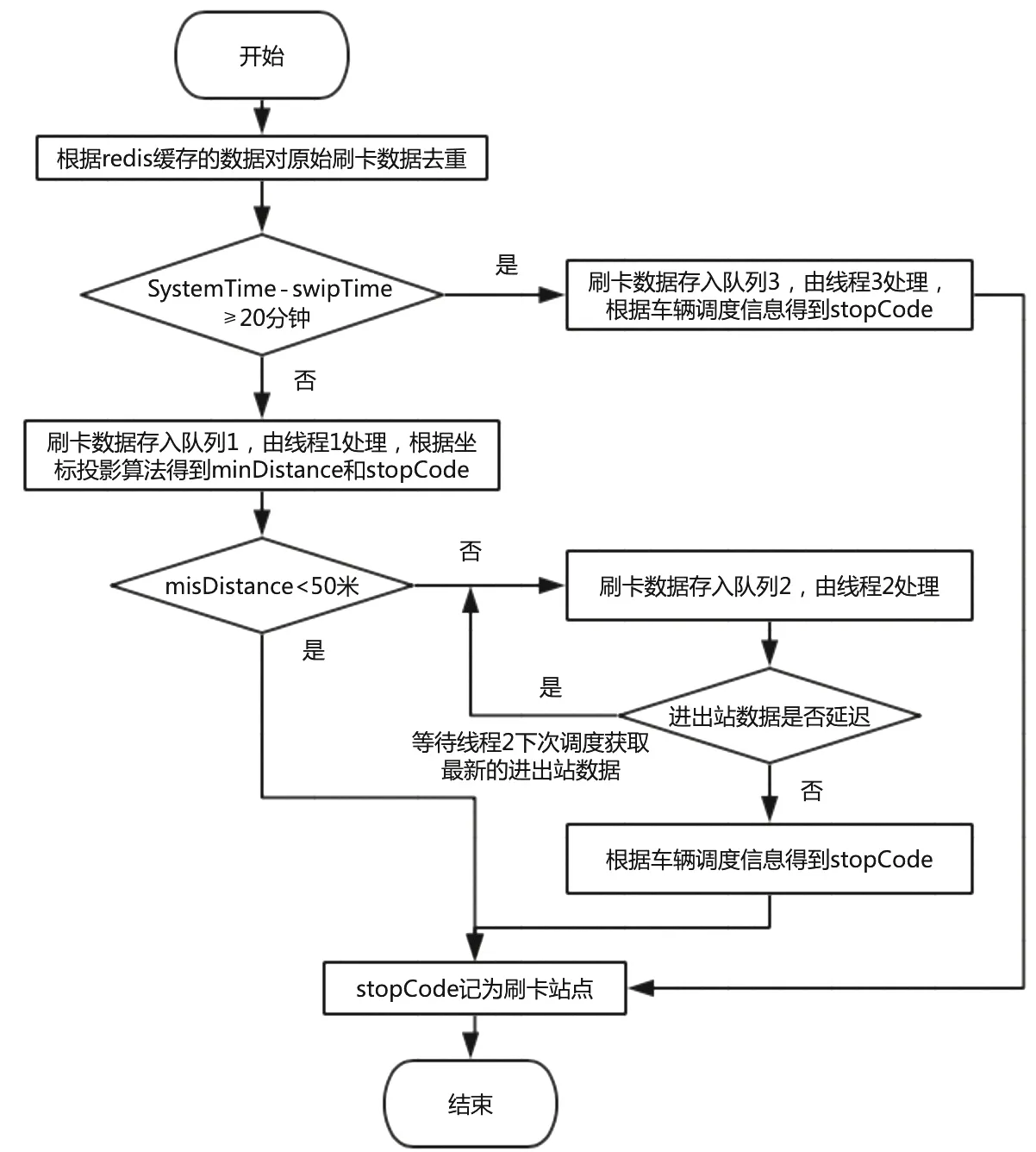
图1 刷卡站点计算流程图
3 程序设计(图1)
原始刷卡数据是通过activemq点对点的方式主动推送过来的,在进行站点计算之前我们首先借助redis数据库内存高吞吐的特性,对实时过来的刷卡数据进行去重,清洗掉重复数据。如果刷卡时间早于当前系统时间20分钟以上,则暂时放置在缓冲队列,记为队列3,新开一个线程基于历史的进出站数据,采用车辆调度算法计算刷卡站点,否则刷卡数据暂时放置在另一个缓冲队列,记为队列1。新开一个线程,基于车辆实时进出站信息寻找运行线路和线路方向,同时采用坐标投影算法,计算刷卡站点,记为线程1。这样设计的好处在于提高程序的计算性能,线程1中对于无经纬度和最小距离misDistance大于50米的刷卡数据,由于算法不一样,暂时放置在一个新的缓冲队列,记为队列2。新开一个线程2处理队列2中的刷卡数据,线程2只处理无经纬度和最小距离misDistance大于50米的刷卡数据,而这些数据依赖于车辆的调度信息,由于车辆调度信息是2分钟从接口获取一次,因此进出站数据可能存在延迟,此时队列2就发挥它的作用了,对于这些不具备处理条件的刷卡数据(刷卡时间大于调度信息里面最大的进出站时间,代表进出站数据延迟),队列2会暂时“保管”,直到延迟的进出站数据过来。这里需要考虑一个异常情况,比如说:进出站数据接口出问题了,就会出现进出站数据永远延迟的情况。
此时队列2的数据就会越积越多,严重消耗内存,最终影响程序的正常运行。因此,这里还有一个机制,就是每次对队列2中刷卡时间距离当前系统时间超过20分钟的刷卡数据进行批量处理,保证队列2的数据大小不会无穷地增大。
4 算法和程序结果分析
4.1 站点客流准确性分析

表3 站点刷卡分析统计

表2 不同推送时间的站点刷卡分析
以2020-07-15一整天的刷卡数据进行分析,得出数据表2、表3。
通过表2可以看出,原始刷卡数据存在发送延迟的情况,但是数据量不大,仅占0.51%。后期也通过算法找到了部分刷卡数据对应的刷卡站点。但是原始刷卡数据的延迟对刷卡站点计算的准确性会一定的影响,尤其跟大屏展示站点实时刷卡数据量的理念是不符的。
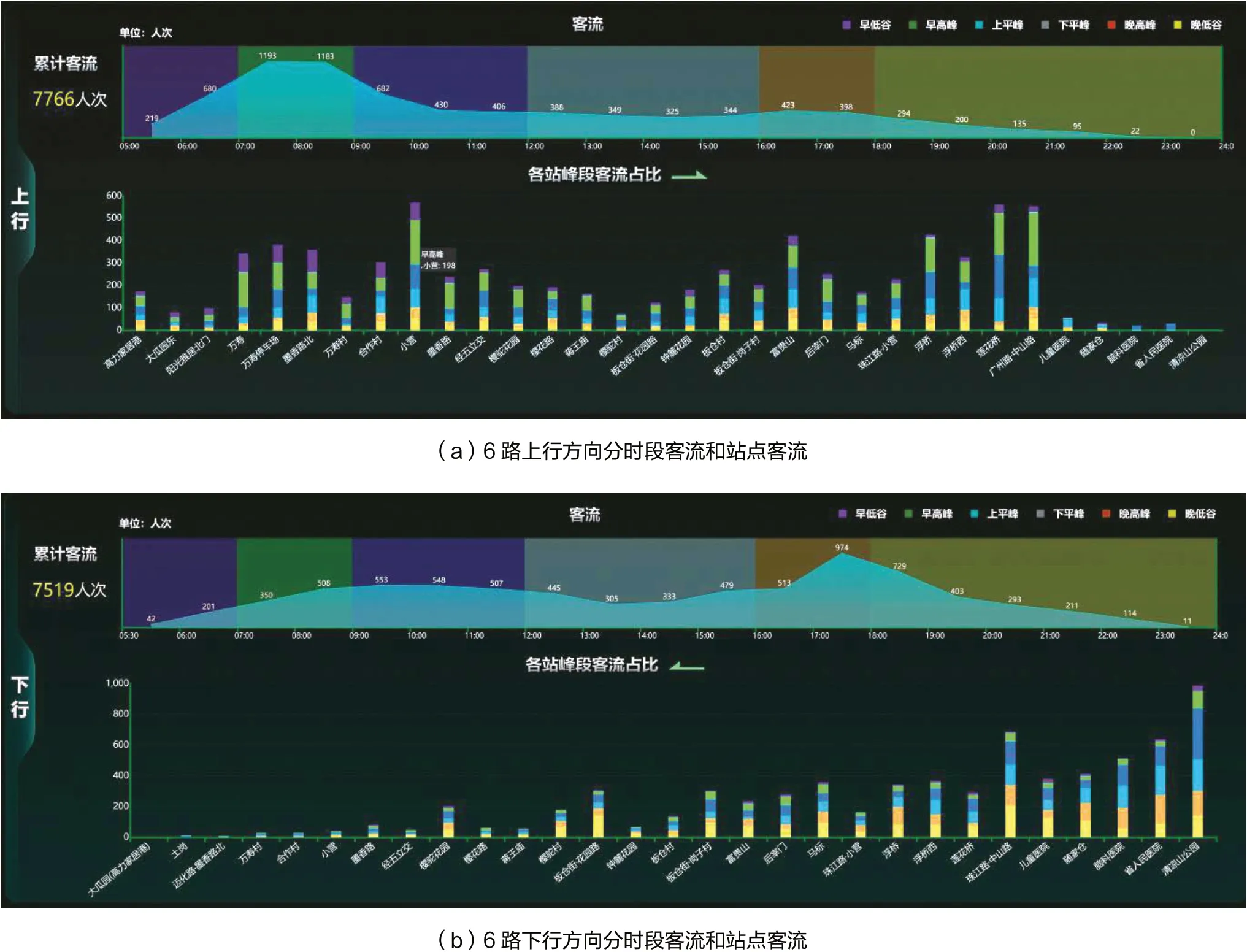
图2 线路分时段客流统计和各站点客流统计
通过表3可以看出,通过坐标投影算法无法判断刷卡站点的数据(包括:无经纬度和misDistance>50米)大部分依然可以通过新的算法(根据刷卡时间和车辆调度信息判断刷卡站点)找到对应的站点。
由于车辆进出站数据中站点和上下行的对应关系与各线路下各站点信息这个基础表的对应关系不符。例如:在进出站数据中A站对应的方向是:上行,但是在基础表中A站对应的方向是:下行。这种信息不符的情况导致了143条刷卡数据找不到刷卡站点。
总体匹配效果还是可以实际应用的,正常发送的刷卡数据中找不到站点的数据,仅占一天的3.63%。
4.2 线路客流多维度统计分析
图2给出了6路两个方向不同时段的客流数量,以及各站点所属不同峰段的客流数量。不同时段的客流数量对于公交运营在不同时间段投入的人员部署具有参考意义,各站点所属不同峰段的客流数量反映了客流分布的主要区域,对多热点区域的治安和交通管理具有参考价值。本文基于时间和站点两个维度的客流统计可以更精确更全面地反映公交乘客出行偏好规律。
4.3 站点客流热力分析
本文利用GIS技术将线路站点客流量热力图层和地图图层叠加,通过热力图的方式展现了线路上各站点的客流分布情况。热力图支持分时段查询,便于分析不同峰段的客流分布情况。图3分别展示了南京市早晚高峰的客流分布特点,对于公交分时段运营部署的调整具有指导意义,更能满足乘客的出行需求。

图3 南京市高峰期客流热力分布
5 结论
5.1 优点
(1)本文针对南京地区的公交刷卡数据,选取一组可以唯一标识一条刷卡数据的特征值,借助redis数据库,利用其内存的高吞吐特性,在实时接收数据的同时,对重复的刷卡数据进行清洗。避免了由于刷卡设备故障而导致的重复统计问题。
(2)本文根据南京地区的实际地域特征和经纬度分布情况,基于GIS进行经纬度转换和距离计算,找到了部分较为准确的刷卡站点。
(3)针对坐标投影算法中不可避免出现的问题:原始刷卡数据没有经纬度。所谓“巧妇难为无米之炊”,缺少了经纬度这个必要条件,坐标投影算法失效。此时,车辆的调度信息就发挥作用了,结合刷卡数据本身包含的刷卡时间信息,依然可以判断出刷卡站点。
(4)通过一天的刷卡数据分析,最终找不到刷卡站点的数据仅占3.63%。
5.2 缺点
(1)原始刷卡数据延迟对刷卡站点计算有一定的影响。本文的算法在实时计算方面准确性更高些,但对于延迟过来的数据,虽然绝大部分都能找到站点,但是准确性会受影响。
(2)进出站数据和各线路下各站点基础信息的不一致性导致了少量数据算不到刷卡站点,这一点其实是可以避免的。
猜你喜欢
科学家(2021年24期)2021-04-25
科学家(2021年24期)2021-04-25
科技资讯(2018年10期)2018-10-26
世界家苑(2017年7期)2017-08-27
新课程·中旬(2017年1期)2017-03-27
科学家(2016年6期)2016-08-23
环球时报(2016-08-01)2016-08-01
小学生·新读写(2016年5期)2016-05-14
小学生时代·综合版(2014年12期)2015-01-17
奥秘(2014年8期)2014-08-30
