
神经网络分类器检测异常数据的方法*
2022-04-14 09:58刘洋张胜茂王斐樊伟邹国华伯静
数字技术与应用 2022年3期
刘洋 张胜茂 王斐 樊伟 邹国华 伯静
1.中国水产科学研究院东海水产研究所,农业农村部渔业遥感重点实验室;2.上海海洋大学信息学院;3.上海峻鼎渔业科技有限公司;4.湖南省武汉市武汉纺织大学
神经网络默认所有输入数据均属于正常数据,当输入异常的数据,网络会在已知的标签中找到高度自信的错误结果,这种无法检测异常数据的现象出现在所有学习模型中。使网络具备检测异常数据的能力,对于系统安全、算法可靠性和算法的实际应用具有重要的意义。实验提出一种区分异常数据和正常数据的方法,该方法首先训练一个名为Wildnet的分类网络,而后去掉该网络的Softmax层作为特征提取器,提取正常数据的高层语义信息Embedding,并用该Embedding构建卷积网络的认知域,通过计算测试数据的Embedding是否属于该认知域,来判断该数据是否为异常数据,达到异常检测的目的。实验在海鲜市场拍摄的1284张包含13个种类的鱼类图像上进行,用前11种鱼类数据作为正常数据,后2种鱼类数据作为异常数据。并用正常数据的60%训练Wildnet网络,得到测试精度91.10%的分类网络,然后去掉网络的Softmax层作为特征提取器,提取训练数据的Embedding,建立认知域,最后用20%未经训练的正常数据和异常数据作为测试集,测试其是否属于网络认知域,来判断测试数据区分异常数据的能力,精度达到71.59%。证明通过建立卷积网路的有界认知域,可以区分异常的数据,达到异常检测的目的。该方法能让神经网络算法具备检测“异常数据”的意识,为传统神经网络算法增加了异常检测功能,进一步提高系统安全性和算法鲁棒性。
自Rumelhart等人[1]证明反向传播算法的可行性以来,神经网络被广泛的应用目标识别[2]、分类[3]、检测[4]、跟踪[5-6]等领域。通过反向传播算法学习数据分布特征的方法,使它具有了逼近真实的结果的能力,超越了传统机器学习方法。在图形识别领域,神经网络分类器在训练数据集上学习决策规则,将卷积模型提取的特征,分配给正确的类标签[3,7]。该方法的缺陷是将训练数据的识别域作为网络的全局识别域,默认所有的输入数据均属于网络的识别域,当算法预测训练数据分布之外的数据时,由于其不具备识别异常数据的能力,完全有可能得到高度自信却错误的结果。此外训练数据可能不足以表达实际应用中所有类的完整情况,因此分类网络的泛化能力可能很差[8]。由于大多数神经网络算法不具备异常数据检测的能力,导致实际应用部署中面临巨大的挑战。而这些问题都有一个共同的特点,那就是测试数据为学习窗口之外的异常数据,解决这个问题的关键在于量化当前神经网络的自我的认知范围。
Chow等人[9]将分类问题转换为决策问题,为每一个类别建立一个模型,用权重函数来度量系统决策结果,通过不断的优化权重函数来提高异常检测能力。通过后验概率建立决策系统,如果后验概率的最大值小于阈值,则拒绝输入,并阐述了错误识别、拒绝识别和正确识别在决策系统中相关关系。利用Weihull分布计算Softmax层向量的激活分数(OpenMax分数),来判断图像是否属于异常数据,该方法能提高网络的识别率。Softmax层的设计方式,没有表达异常检测的能力,而Softmax层的前一层没有受到这种约束,并且同一个类别的数据应当属于同一个集合,对于未知类应当远离已知数据集合,基于此,他们为网络的Embedding设计了被称为ii-loss的损失函数,可以最大程度的减小类内距离,并扩大类间距离。通过减小异常数据在反向传播过程中的贡献,来增加网络检测异常数据的能力。SVDD(Support Vector Data Description)的级联分类器,对训练数据进行建模,任何不属于该模型的样本将被标记为异常数据。
由于网络在有限的训练集上学习数据的表征能力,数据能够表征的范围是网络认知能力的极限[10]。如果能量化有限数据的信息表征能力,即可表征网络的认知范围,对于认知范围之外的,就为异常数据。在分类神经网络中,这种数据表征能力的实质是“识别类内相似性和类间差异性”的分类能力。基于此,本文提出一种利用卷积神经网络的高层语义信息,量化训练数据(正常)的信息表征能力的方法。该方法首先用交叉熵损失函数训练了名为Wildnet的简单分类网络,然后去掉Wildnet的Softmax层,用Softmax前一层的Embedding表征数据的高层语义信息。而后将训练数据的Embedding特征集,用主成分分析法PCA(Principal Component Analysis )降维到3维,并计算3维特征点的凸包,以此构建网络的认知域,通过计算测试数据的特征是否属于该认知域,来区分正常数据和异常数据。经过测试,该方法在数据不够充分的情况下能得到了71.59%的正确检测率。实现了卷积神经网络对异常数据的检测,增加了算法的鲁棒性,并让神经网络具有了异常检测的能力。
1 数据与方法
1.1 海洋捕捞鱼类图像
利用深度学习的CNN卷积网络,对海洋捕捞鱼类图像的高层语义特征信息,进行精确提取,需要大量的、高质量的、多样化的和差异明显的图像数据,供给深度学习模型学习不同鱼种的纹理信息的区别。但是如何准确有效的采集和组织该类数据集,仍是关键的问题。为了收集高质量、多样化和差异明显的鱼类数据集,该实验的科研人员在海鲜市场挑选不同种类、大小、形态、姿势和其他个体差异的海洋捕捞鱼类,在纯色背景上,用相机从不同角度拍摄捕捞鱼类在不同摆放姿态下的照片1284张(如图1所示),而后鱼类鉴别专家将照片准确分成13个鱼种,包括斑尾刺虾虎鱼、舌鳎某种、银鲳、带鱼、棘头梅童鱼、三疣梭子蟹、对虾、小黄鱼、马鲛、龙头鱼、鮸、马面鲀、鮋(表1)。拍摄的图像大小为4000×2248像素。

图1 鱼类照片,从正面、侧面、以及改变鱼的摆放姿势拍摄照片Fig.1 Fish photos, taking photos from the front, side and changing the placement position of fish
在数据处理方面,考虑到深度学习中一张w×h像素的图像,通过一个r×c神经元的乘法计算量为w×h×r×c,为避免因图像尺寸导致乘法计算量太大引起学习过程中占用显存过多,从而导致网络计算缓慢的问题,本文使用OpenCV的区域插值法将图像缩小到224×224像素,大大降低了网络的计算量。另外为使网络具有更好的鲁棒性,提高网络的泛化能力,降低过拟合,对原图像进行偏移、旋转、缩放、裁剪增广数据集,并将图像进行归一化和白热化处理。根据图像所属的鱼种为每一张图像制作标签文档。为了模拟正常和异常的场景,实验将前11种鱼类数据共1036张图像作为正常鱼种,后2种鱼共计218张图像作为异常鱼种。本文将正常的鱼种图像数据充分打乱之后,按照6∶2∶2划分为训练集、验证集和测试集;将异常鱼种数据集作为异常鱼种的测试集合。为方便阐述,设正常训练集为Dtrain,正常的验证集为Dvalid,正常的测试集为Dtest,异常的测试集为Dwild。其中Dtrain={Dt}11t=1,包含11种鱼类,Dt表示第t种鱼类数据集。Dtrain用于训练Wildne网络的分类能力,Dvalid用于验证Wildne网络的分类能力,Dtest和Dwild用于验证本文提出的方法的可行性。
1.2 正常与异常数据
神经网络表征数据的能力,来源于对训练数据Dtrain(正常数据)的学习,所以网络对正常数据表征的信息分布是部分可知的;而异常数据Dwild表征的信息,网络是不可知的;即正常数据在网路的认知域之内,而异常的数据在认知域之外。网络对数据的认知域来源于数据本身表征的信息域,设正常数据和异常数据表征的全局信息域为G,正常数据表征(前11种鱼图)的信息域为R,异常数据表征(后2种鱼图)的信息域为O。理论上除了正常的数据,都是异常的数据,所以R∪O=G,R与O互斥。区分O和R的问题,只需在G中找到描述二者信息的边界,表达其中一个即可表达另一个。由于O是开域的(未知域),缺乏数据支撑,无法直接表征,而R在本实验中可通过训练集(正常)的图像数据间接表征。
由于卷积网络通过提取数据的特征信息来识别数据,理论上用图像的特征信息表征数据的信息域是合理的。假设卷积网络识别第t类对象的信息域为Et,Et∈R;第t类数据的第j张图像xj,通过映射关系(神经网络)F(·)提取的特征信息ej∈Et。设某种鱼有N张图像,其通过F(·)映射后的信息域集合为At={ej|ej=F(xj)}N,当N趋近于无穷的时候,At表达的信息域趋近于Et,其中At⊆Et。即,提取同类图像数据的特征信息表征类信息域Et,不同类的信息域组合R,从而构成网络的认知域。所以,图像xj可以准确有效的“映射”到其特征ej的情况下,更多样的图像可以更加完备的表达Et,而F(·)的准确性和可行性,是尽可能的将同类图像的特征聚集在一起,而不同类的特征互相远离,其取决于“描述种内相似性和种间差异性”的分类能力,这和深度学习分类网络能力相似,实质就是描述类内相似性和类间差异性。基于此,本文利用卷积网络训练具备分类能力的特征提取器Wildnet,描述图像xj与特征ej的映射关系F(·)。
1.3 特征提取器
Wildnet网络结构如图2所示。为了保证F(·)描述“种内相似性和种间差异性”的准确性和可行性,实验用包含11个鱼种的数据集Dtrain训练网络的分类能力,由于其数据量较少,不必使用较大参数量的网络结构,实验利用深度可分离卷积(Depthwise)搭建了一个较小的卷积网络,在该网络中,为了能灵活的压缩和扩张通道,用Pointwise卷积融合Depthwise卷积后的张量信息;为了加速训练与防止过拟合,在卷积之后使用Batch Normalization(简称:BN)模块;为了防止特征消失,使用了特征融合和残差的方法。在训练过程中,用包含11种鱼种的数据集Dvalid验证其分类准确度,以防止过拟合和欠拟合。

图2 Wildnet特征提取网络Fig.2 Wildnet feature extraction network
为了计算真实数据分布和生成特征数据分布的相似度,用多分类交叉熵函数计算损失(式1),在反向传播的过程中,用SGD (Stochastic Gradient Descent)更新权重。

公式(1)中,C为类别总数,i表示类别数,xi表示输入图像,yi表示图像的真实标签,;表示Wildnet网络的权重,L为损失率。在成功训练之后,先用测试集Dtest测试网络识别能力,确定其已经具备“识别类内相似性和类间差异性”的分类能力后,再将网络去掉Softmax输出层,留下Embedding层作为输出层,改造成特征提取器,作为图像到特征的映射关系F(·)。去掉Softmax的原因是Softmax激活层输出11维张量,其维度偏少且数值分布不均匀,不能很好的表达图像的高层语义信息,不适合作为特征提取器的输出。而经过Embedding层输出128维的张量,是经过Batch Normalization归一化处理的,其分布较为均匀,且维度足够表达图像的高层语义信息,对于输入图像xj能够得到一个表达更全面的特征ej。因此在特征提取过程中,去掉该网络层Softmax层,留下Embedding层,作为特征提取器。由于该特征提取器已经具备了“描述种内相似性和种间差异性”的能力,其输出的特征能够很好的表征真实数据分布,因此本文将该特征提取器作为图像xj和特征ej的映射关系F(·)。
Convolution(k,k,s,c):表示c个卷积核大小为k,步长为s的CNN卷积。
Pointwise (1,1,s,c):表示c个卷积核大小为1,步长为s的CNN卷积。
Depthwise(3,3,2,c):表示c个卷积核大小为3,步长为2的通道可分离卷积。
Route:表示两个张量在通道上拼接。
BN(Batch Normalization):表示对输出特征归一化,使其符合均值为0,方差为1的分布,防止ICR现象。
Mish:平滑的激活函数,能让模型拟合更细腻。
Embadding:128∶128的特征张量层。对于输入图像xj,该层输出128维的特征张量,即图像经过映射关系F(·)输出的ej。
Softmax:分类层有11个神经元,表示11个已知鱼种。
1.4 已识别信息域
在成功制作特征提取器Wildnet之后,为了近似的量化正常数据的信息域R,达到在全局信息域G中描述“正常和异常的边界”的目的,如图3所示,实验将Dtrain,Dtest和Dwild数据集输入到Wildnet特征提取器中,分别生成正常特征集Etrain,Etest和异常特征集Ewild。由于Dtest和Dtrain拥有同样的鱼种,属于同种数据分布;Dwild数据集与Dtrain数据集拥有不同的鱼种,表征不同的数据信息,其数据分布不同。由于使用交叉熵作为损失函数训练网络,最小化了真实分布和预测分布的差异,即输入数据(真实分布)和特征数据(预测分布)是相似的分布。所以,同一分布的数据与经过映射关系F(·)生成的特征数据,其分布相似,反之亦然。即Dtrain,Dtest和Etrain,Etest分布相似,Etrain和Ewild属于不同分布,加之Wildnet的认知域来源于Dtrain表征的数据信息(正常的信息域R),即Etrain可近似表征Wildnet的认知域。而Dwild数据集与Dtrain属于不同的分布,故Ewild表征的数据信息属于异常的信息域O。因此实验将Etrain,Etest,Ewild用PCA方法降维,将128维特征向量的维度降到3维,而后将Etrain的特征集构成的空间作为Wildnet网络的认知域,其外为异常信息域O。
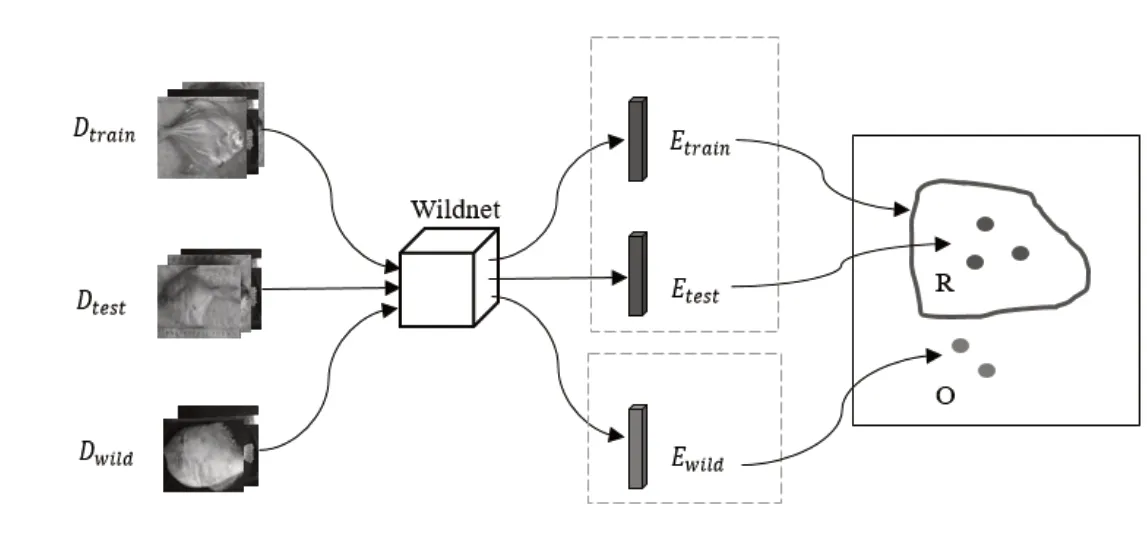
图3 特征提取流程图Fig.3 Flow chart of feature extraction
如算法2所示,判断测试数据是否为异常数据,只需判断其特征是否在R中。在该实验中,用凸面体体积法判断Etest和Ewild的3维特征点是否属于Etrain构成的凸面体,来判断是否属于认知域内。为了获得由Etrain中不同类别鱼种数据表征的信息域,首先用Graham扫描法计算Etrain中3维特征点的凸包Tt,根据凸包计算邻点集合{P1,P2,P3}N,其中P1, P2, P3表示三角形的顶点集,N为凸包顶点数量。然后根据邻点集依次计算三角形的面积,以及测试点到所有三角形的高,并用三角形的面积和测试点到该面的距离计算四面体的体积,最后求和所有四面体的体积,得到测试点与凸包构成的多面体的体积。如果其值等于原凸包构成的凸面体体积,则在认知域内,否则在认知域外。实验在Dtest与Dwild数据集上测试,其异常检测的正确率为71.59%。
2 结果与分析
实验在32G内存,16G显存(TeslaV100)的Linux主机上进行,开发框架为Pytorch。为了让神经网络对不确定的数据具有认知能力,本文做了两个实验,第一个实验是训练Wildnet网络,使其具有识别“种间差异性和种内相似性”的能力。第二个实验利用Wildnet网络生成的高层语义信息,描述正常数据的信息域,并通过该信息域来判断测试数据是否属于正常范围。
2.1 Wildnet分类网络
实验用Dtrain数据集训练网络具备分类能力,设置SGD优化器的初始学习率η;η为0.001,momentumα为0.9,decay为1e-9;用Softmax激活函数激活最后一层的神经元,并配合交叉熵损失函数(公式1)计算网络损失。为了防止训练过程中的过拟合和欠拟合现象,实验用Dvalid数据集每迭代10次计算网络的验证损失,如果降低则保存权重,可有效的防止过拟合。训练在经过90次迭代后,训练精度为97.10%,验证精度为92.29%(如图4所示)。
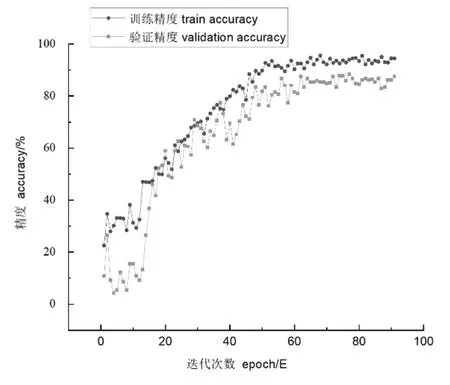
图4 Wildnet训练过程图Fig.4 Wildnet training process
在网络训练成功之后,用测试集Dtest测试网络的分类能力,其测试精度为91.10%。说明该网络已经具备“识别种间差异性和种内相似性”的能力,可以表征11种数据的大部分信息特征,将输入数据和输出数据分布的差异最小化,这是量化正常信息域的基础。
2.2 正常信息域
由于Softmax层中的神经元被限定为只能表示已知类别,无法表示未知类别,其张量信息难以表征未知类别的高层语义信息。而Embedding层位于Softmax的前一层,没有受到该限制,并且相比于Softmax层的11维张量,Embedding层有128维的张量,能够更加全面的表征数据的高层语义信息。据此,实验将Wildnet网络去掉Softmax层,用Embedding层作为网络的输出层,将修改后的网络作为特征提取器。实验将训练集Dtrain的图像输入到特征提取器,生成128维的特征向量集合Etrain={At}11t=1,其中At表示第t种鱼的特征集合;将Dtest和Dwild数据集分别输入到Wildnet网络,生成Etest和Ewild。其中Etrain中包含640个128维的具有类别标签的特征向量;Etest包含213个128维的具有类别标签的特征向量;Ewild中包含218个128维的具有类别标签的特征向量,其中马面鲀的数量为104,龙头鱼的数量为114。
将Etrain,Etest和Ewild的128维高层语义信息,用主成分析法PCA降维到3维,并将其3个维度上的数值作为3维坐标系的x, y, z上的坐标值。通过Etrain和Etest在3维坐标系中的分布分析,Etrain和Etest特征点在空间中呈现彼此交融的分布状态,这证明了本文的观点,即网络成功学习了Dtrain数据集的分布特征,而Dtest数据集与Dtrain拥有一样的鱼种,表征同样的数据特征信息,故Etrain和Etest属于同一分布。由于Wildnet网络表征数据的信息有一定的误差,并且少部分数据质量较差,导致少部分的特征点游离于聚集区域以外。
由于Dtrain中没有Dwild包含的新鱼种数据,如果不经过处理直接交给Wildnet分类网络分类,肯定会在训练集的标签上找到高度自信却错误的结果。Dwild数据集通过Wildnet特征提取器生成Ewild特征集,包含异常鱼类马面鲀和龙头鱼的高层语义信息。将Ewild加入3维空间中,马面鲀和龙头鱼的大多数特征点分布于Etrain和Etest的两边,证实了本文推论,即不同分布的数据,其特征信息属于不同分布。并且同一鱼种的特征点聚集在一起,这种现象一定程度上说明分类网络,对同类数据表征的信息具有聚集作用,对不同种类的数据表征的信息具有远离作用,这证实了本文的观点,即分类的实质就是“识别种间差异性和种内相似性”,而数据量如果足够大。聚集在一起的特征,可以逼近表征该类数据的完整信息域(Et),从而表达正常信息域R,达到检测异常数据的目的。
为了表达正常信息域R和异常信息域O的边界,实验用Gramham-Scan算法计算Etrain中不同鱼种数据的特征集At的凸包,得到11个不同类别数据特征的3维凸包,用每一个类别的凸包构成的凸多面体作为该类鱼的信息域,所有凸面体空间作为Wildnet的认知域。实验用体积法计算测试样本是否属于这11个凸面体,首先分别计算11个凸面体的体积,如果测试特征点属于某一凸面体,则测试特征点与凸包组成的新凸面体体积等于原凸面体的体积。如果测试特征点不属于任何一个凸面体,则该测试数据为异常数据。从未被训练的马面鲀和龙头鱼大多分布在认知域外,而正常的鱼种,大多分布在认知域内。如算法2所示,实验在Dtest与Dwild数据集上测试,检测正确率为71.59%,证明了该方法的可行性。
根据实验结果,可以得出如下结论:(1)卷积神经网络对同一种类的数据特征信息具有聚类作用。(2)用训练数据表征的数据信息域,可检测异常数据。(3)具有分类能力的卷积神经网络,其认知范围可近似表征。
3 结论
为了让卷积神经网络具备检测异常数据的能力,本文研究了卷积神经网络对正常数据的表征能力。实验用卷积网络提取图像的高层语义信息,构建正常数据的信息域,通过计算测试数据的高层语义信息是否属于该空间,来判断测试数据是否为异常数据,取得了71.59%的检测正确率。结果表明该方法可量化卷积神经网络的对数据的表征能力,让神经网络算法具备识别“异常数据”的能力,可达到检测异常数据的目的,进一步提高系统安全性和算法鲁棒性。
猜你喜欢
农村百事通(2023年7期)2023-08-05
北京航空航天大学学报(2021年9期)2021-11-02
科学养鱼(2020年8期)2020-12-20
当代水产(2019年8期)2019-10-12
电子制作(2019年11期)2019-07-04
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2017年11期)2017-04-04
渔业致富指南(2016年12期)2016-11-11
噪声与振动控制(2015年4期)2015-01-01
