
Python数据结构在社保大数据领域的应用
2022-04-14 09:58鄂尔多斯市人力资源和社会保障局综合保障中心达斯孟
数字技术与应用 2022年3期
鄂尔多斯市人力资源和社会保障局综合保障中心 达斯孟
当前大数据应用在政务服务各个领域正在如火如荼的进行,Python语言作为一种高效的编程语言正在成为软件开发的趋势,本文从Python语言不同数据结构在社保大数据应用方面进行了构造方法的介绍、性能的比较和造成性能差异的分析。
社保领域作为我国重要的民生工程,一直备受关注。社保大数据在推动社会保险管理服务模式创新,改进公共服务水平,减少重复参保,查处重复领取待遇方面有着非常重要和广泛的应用。Python语言可以被应用于系统编程、GUI编程、互联网脚本、数据编程等多个领域。根据2018年5月KDnuggets对“最受欢迎的分析、数据科学、机器学习工具”的调查,Python以65.2%的比例夺冠。本文以A市社保大数据比对工作中应用Python语言编写相关应用程序时所应用的集合SET、列表LIST等两个高频数据结构进行性能和特点分析,以便为更多政务服务领域提供可供遵循的指导。
1 Python数据结构中的集合SET,列表LIST介绍
要用好Python语言并发挥其作用,必须理解数据结构的一般性知识和Python的特殊情况[1],笔者在社保大数据应用领域使用的是Python数据结构中的集合SET,列表LIST。要弄清楚上述两个数据结构首先要从上述数据结构的构造原理进行探究。首先我们要明确任何数据结构其实都是一种从内存获取数据地址从而读取或者操作数据的一种方式。就像生活中我们想要出售一处房产,但是你不可能像推销其他产品一样将房产携带在身上四处给人看,最好的做法就是你告诉潜在客户一个地址让客户根据你给的地址自己过来访问。这个过程其实就是我们计算机用来读取内存中数据的一种形象的方式。在Python中我们建立一个列表MYLIST=LIST[1,2,3,4]的列表,其中的MYLIST本质上就是指针,指向LIST[1,2,3,4]占据的内存地址块。不同的数据结构其本质的区别就在于如何让指针更快,更准确的指向需要访问的地址。
1.1 LIST数据结构
Python中的LIST是处理一组有序元素得数据结构[2]。本质上是一个over-allocate的数组实现的。LIST可能是计算机科学中使用最为频繁的数据结构。Python中的LIST共有三类,分别为单链序列Singly Linked LIST,双链序列Doubly Linked LIST,环形序列Circular Linked LIST。下面对三类序列进行分析:
如图1所示为单链序列Singly Linked LIST:除了末尾节点外每个节点都包含一个数据值部分和指向下一节点的地址部分。单链序列只能进行单向的索引,因为每个节点只包含下一节点的位置。
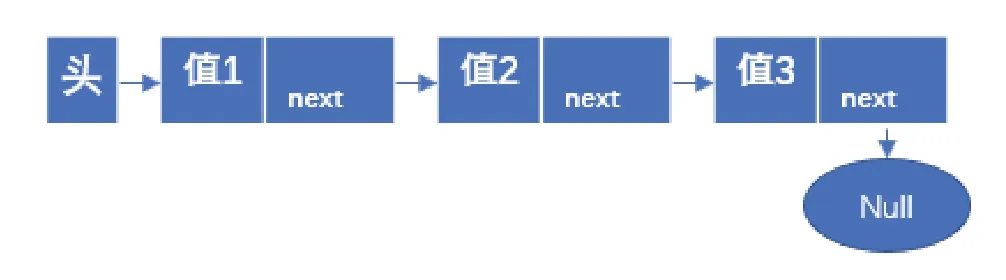
图1 单链序列Fig.1 Singly Linked LIST
如图2所示为双链序列Doubly Linked LIST:除了末尾节点外每个节点都包含一个数据值部分和指向下一节点的地址部分和指向上一节点的地址部分。双链序列可以进行向前和向后的双向查找,因为每个节点即包含了前一节点的地址又包含了后一节点的地址。
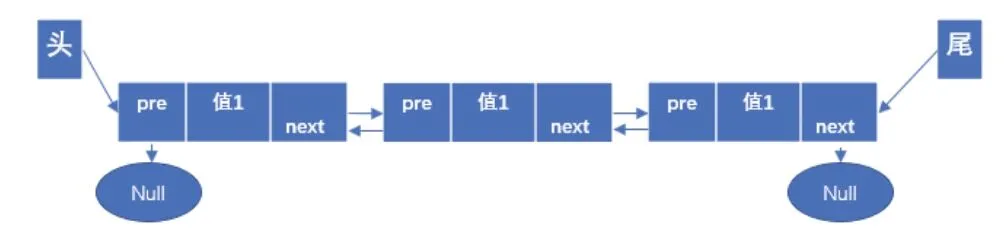
图2 双链序列Fig.2 Doubly Linked LIST
如图3所示为环形序列Circular Linked LIST:环形序列的末尾节点的下一节点指向的是序列的第一个节点,其他都和单项序列是一样的。

图3 环形序列Fig.3 Circular Linked LIST
三种序列对存放于其中的数据都进行了精确的索引,数据值可以重复。其特点为高扩展,可任意大小位置切片,任意位置删除或插入。
1.2 SET数据结构
Python中的SET数据结构是由具有唯一性的hashable对象所组成的无序集合。由于SET数据结构索引数据的方式为hash算法,因此相同值的数据经过hash算法后其哈希值也是相等的,所以SET中不会有重复的数据。常见的用途包括成员检测、从序列中去除重复项以及数学中的集合类计算,例如交集、并集、差集与对称差集等[3]。
2 集合SET,列表LIST性能比对
在A市社保大数据应用领域,目前需求最密集的数据应用方式为跨统筹区或跨险种(企业养老保险、机关养老保险、城乡居民养老保险)比对重复参保与重复待遇领取人员。由于政务服务特点,上述数据大多以Excel格式存放于社保部门不同科室且每个表格的数据较多(通常为几十万条)。因此如何高效、精准、快速进行数据比对就显得尤为重要。
下面笔者以10000机关养老待遇领取人员和10000城乡居民待遇领取人员比对为例展示Python中不同数据结构在上述需求中的性能差异(如表1所示)。LIST数据结构主要的算法为将两个数据源的10000人的数据分别装入两个LIST中。之后经过FOR循环进行遍历比对。
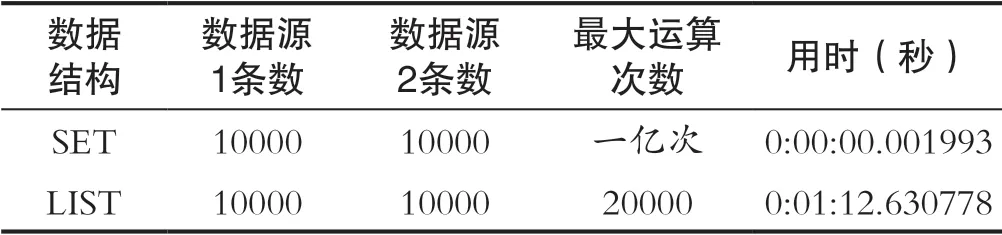
表1 为数据比对结果Tab.1 Shows the results of data comparison


SET数据结构主要的算法为将两个数据源的10000人的数据分别装入两个SET中,通过intersection函数求解交集。

3 集合SET,列表LIST性能差异分析
经过上述实验结果可以看出SET数据结构在社保大数据比对中效率明显更优。其原因主要在于SET数据结构和LIST数据结构的构造方法的不同。众所周知,最快速的访问数据集合中数据的方式是随机访问,而不是顺序访问。下面我们就对两种数据结构分别进行分析。从上述实验结果得知LIST的查找效率较低,下面我们首先查看LIST的查找算法的抽象源码和原理图(如图4所示)。


图4 LIST数据存储方式Fig.4 LIST data storage method
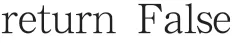
从图四中可以看出我们现在有一个test=LIST[10,11,12,8,9,13,14]的未排序序列,序列中共有7个整数值。根据源代码如果我们要查找13这个Key值,则需要从这个序列的head位置起循环比对(源码中的WHILE循环)如果比对不成功则进行temp=temp.next操作进入下一节点进行比对直到比对成功为止则返回True跳出循环。因此得出LIST(以双向链表为例)查找数据时需要按照索引顺序对整个序列进行遍历直至匹配到Key值。它适用于对顺序敏感的数据。平均查找复杂度是O(n)(如果是以排序的序列则平均查找复杂度是O(log n))。
从上述分析得知要从一个LIST中查找某一Key值必须要对整个LIST进行遍历,如果想要查找的Key值在序列的前端则还比较省时间,如果所要查找的Key值在序列的末尾则需要遍历完整个序列才可以匹配到Key值。这样无疑是非常耗费系统资源和时间的。因此我们不禁要问,为什么不能有一种数据结构可以直接告诉我所要查找的Key值的位置,从而让我可以直接去访问呢,就像我们之前提到的例子所说的那样,直接告客户一个详细的地址,而不是像LIST一样只告诉客户需要出售的房产在某一个小区(内存块),让客户逐户去查找是否为要出售的房屋。而SET数据结构恰好就是利用哈希算法实现了一次寻址即得到结果的结构。下面我们首先查看set的查找算法的抽象源码和原理图(如图5所示)。

从图5中可以看出我们现在有一个test=set(对象1,对象2,对象3,对象4,对象5,对象6,对象7)的集合,其中共有7个对象值。根据源代码如果我们要查找对象6这个Key值,首先我们需要通过ComputeHash(Key)函数计算对象6的哈希值(13),之后通过哈希算法对13这个哈希值进行除7取余的哈希计算得到哈希表中的索引位置(6),之后判断索引位置的值是否与要查找的KEY值相等,如果相等则返回成功(在哈希算法出现冲突的情况下有可能出现索引值相同但是数据不相同的情况)。最终得到需要查找的值。因此SET数据结构的查找复杂度是O(1)(理想无冲突状态下),且和SET规模大小无关。在SET中查找任何值在理想情况下只需要查找一次,只需要将需要查找的值进行哈希算法,将其哈希值与SET中相应位置进行比对,如果比对成功,则找到,如果比对失败,则不存在。
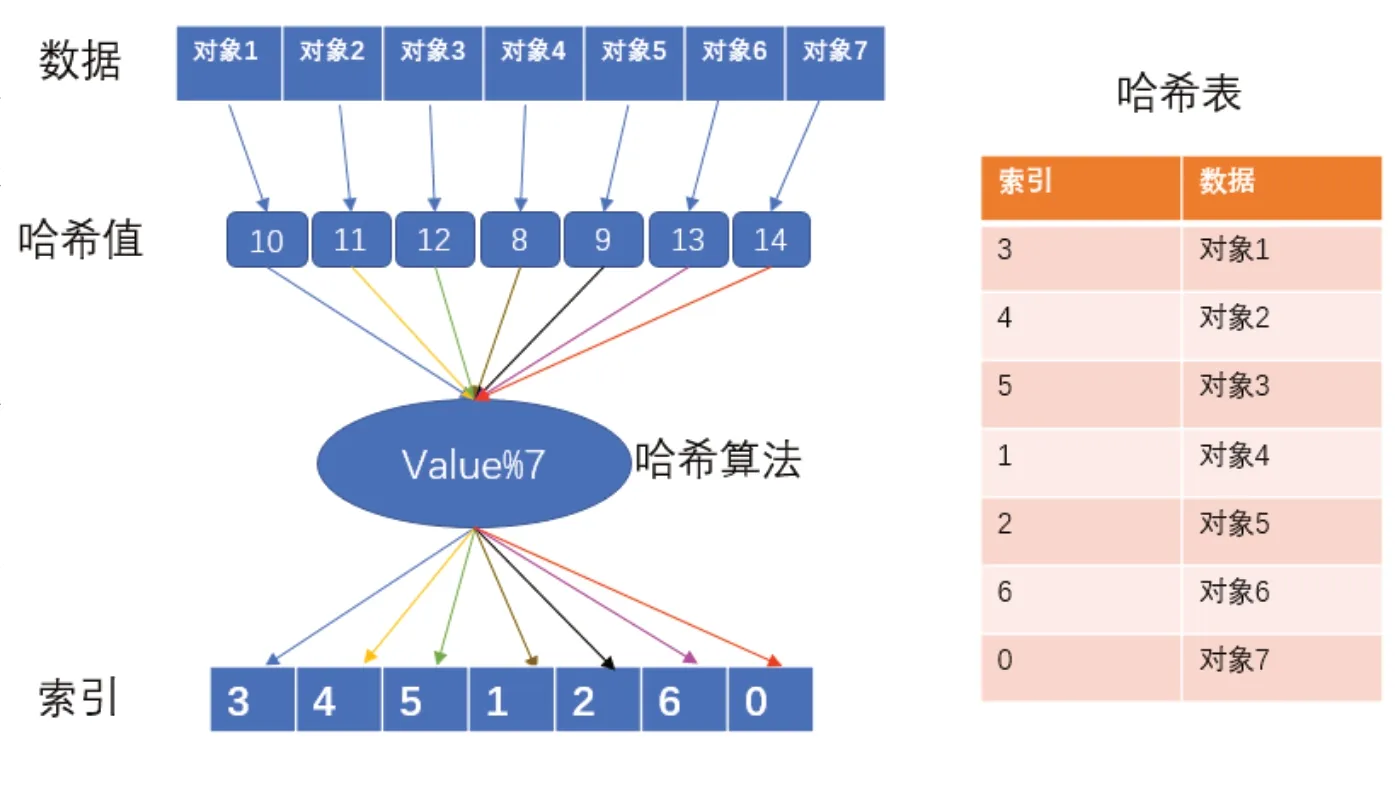
图5 SET哈希算法实现方式Fig.5 Implementation of SET hash algorithm
4 结语
根据上述实验数据和结构原理,我们可以得出Python在社保大数据应用领域中SET具有查找比对速度的绝对优势,其优势来源于其数据结构的构成方法,而LIST则在数据比对查找方面不具有速度优势,但是在需要按照某种规则进行排序使用数据时具有优势。
猜你喜欢
小学生学习指导(中年级)(2021年4期)2021-04-27
广东技术师范大学学报(2016年5期)2016-08-22
计算机工程(2015年8期)2015-07-03
华东师范大学学报(自然科学版)(2014年3期)2014-03-11
上海理工大学学报(社会科学版)(2014年2期)2014-02-28
计算机工程(2014年6期)2014-02-28
河南科技(2014年5期)2014-02-27
电子设计工程(2014年12期)2014-02-27
