
大数据下基于决策树算法的企业客户关系管理研究
2022-04-19 14:13赖锦柏
经济研究导刊 2022年9期
赖锦柏


摘 要:1980年,在阿尔文·托夫勒的著作《第三次浪潮》中作出了如下的预测:未来的世界是被数据信息包围的世界。他将大数据形容成“第三次浪潮的华彩乐章”,全新的、将永久改变人类思路、生存方式的革新将围绕数据资源展开。正如其所言,时至今日大数据的时代已经到来,伴随着大数据一起到来的是机器学习、数据挖掘和商业智能在各个领域的运用。同时,大数据时代的社会舆情又与传统的社会舆论有所区别。在这一背景下,当企业面临各类客户时,如何进行客户关系管理成了当下的重点研究课题。在数据挖掘的各类算法中,决策树算法是比较优秀的一种,通过决策树算法,能够帮助企业更快地定位相关客户群体,从而進行更优决策。
关键词:大数据;数据挖掘;决策树算法;客户关系管理
中图分类号:F272 文献标志码:A 文章编号:1673-291X(2022)09-0008-03
一、研究综述
(一)大数据的定义
1980年,阿尔文·托夫勒在《第三次浪潮》一书里预测未来的生活是被数据信息包围着的全球,将大数据形容成“第三次浪潮的华彩协奏曲”,人们将紧紧围绕公共数据进行新一轮的技术革命。而随着大数据应用的发展趋势,大数据的内涵又有新的论述。Wiki百科对大数据的表述就是指所涉及的数据规模极大到没法根据现阶段流行工具软件,在有效时间内采撷、管理方法、解决和梳理有关商业资讯,进而合理地协助公司完成运营管理决策提升的总体目标。海外学者Tien James认为大数据便是一个专业名词,适用于数据集,其规模在现阶段除能用专用工具计量检定的能力以外,对数据信息开展搜集、浏览、剖析或程序流程运用都可以调控在有效的时间段内。
(二)大数据时代舆论的特征
随着大数据时代的到来而产生的网络舆情与传统的舆情有所不同,但又有着一些相似之处,网络舆情的形成大致有“沉默的螺旋”“蝴蝶效应”“滚雪球”“群体极化”等几种传播学经典理论。根据“沉默螺旋”理论,大多数人都是受大众心理的驱使,尽量避免孤立自己独特的观点来面对网络主流的、即使是未必正确的舆论。“蝴蝶效应”的理论则是传统蝴蝶效应的延伸,认为网络上一些微不足道的舆情都有可能发展成公众关注的热点与焦点。“滚雪球”理论指出,根据网民的“好奇心”和“关注”,一些问题会从地区问题转变为产业问题,甚至向国际问题转变。群体极化理论的观点是网民在遇到话题时会代入自身的主观感情从而对问题的看法有所偏颇,而在其他群体成员的认同下,导致了其舆论向极端发展,进而构成了舆论的非理性,最终影响了整个群体的舆论。
(三)数据挖掘的内涵
数据挖掘也叫作资料勘探,其内涵是从极其庞杂的数据中将埋藏在内的具有某些特定关系的相关内容进行自动化检索的进程。数据挖掘是以一个全新的角度为立足点,将各种信息技术性开展合理结合,同时结合发展趋势而成的能够对大量的业务流程数据信息开展较为系统的剖析和筛选的合理专用工具,主要是协助企业从不断更替并累积起来的数据信息中挑选对企业本身有效的信息,数据挖掘将企业制定的业务流程总体目标为根据,对全部商业服务大环境中的海量信息开展数据分析,从而筛选出对本身有使用价值的数据信息,为企业能够更好地开展商业服务、管理决策提出合理的根据。
运用数据挖掘对海量数据信息开展挖掘的分析方法有很多,主要是归类、多元回归分析、聚类算法、关联规则、特征分析、转变和误差值剖析、Web网页挖掘等,不同的分析方法可以从多角度对数据信息开展挖掘,使结果更加精准。
(四)决策树算法
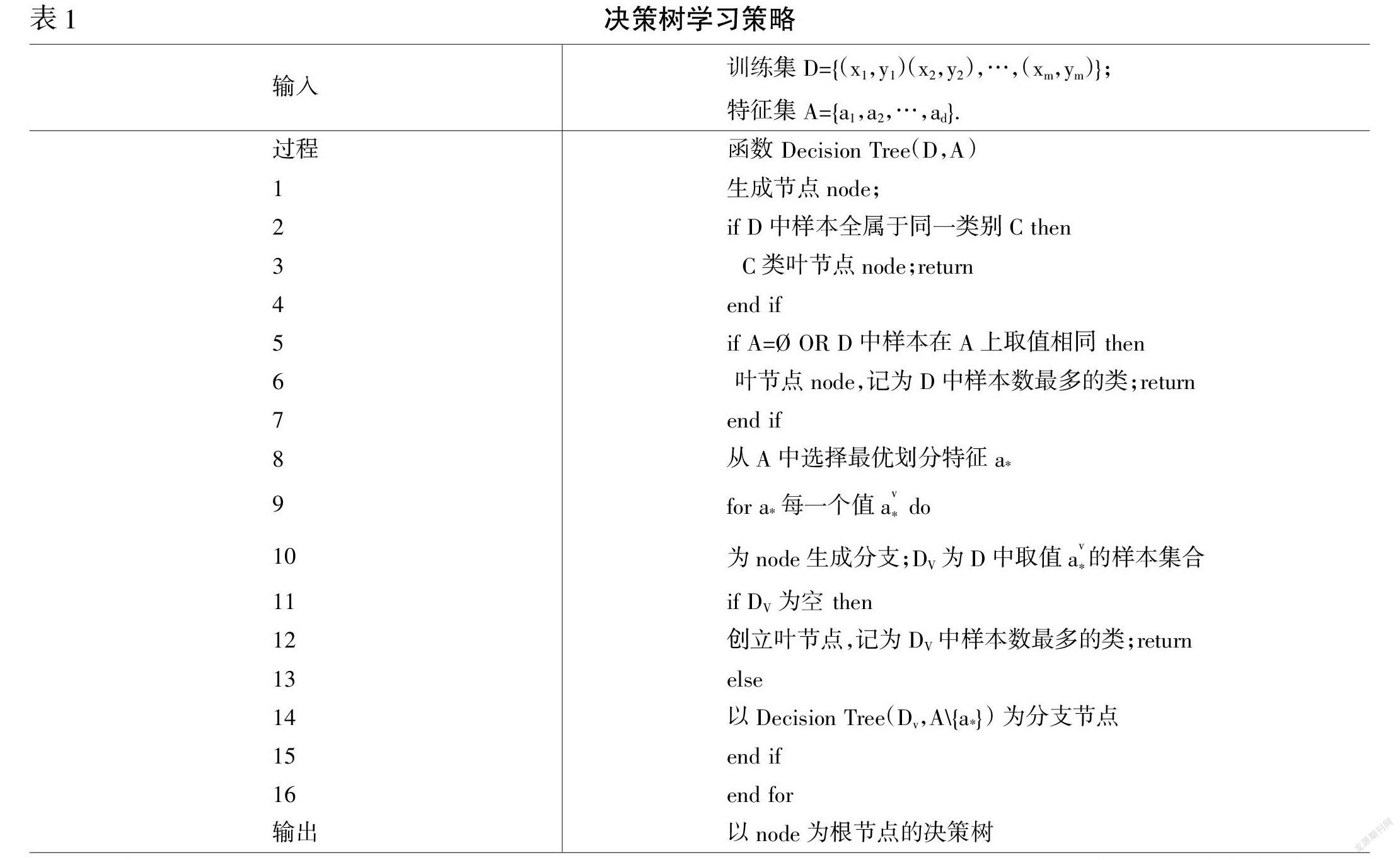
决策树算法是一种依据已知的概率,即样品数据具有不同的特性,形成可以用于分析对象的一种算法。数据分类算法家族中,决策树算法都是用于确定决策的经典算法。首先,所有数据特性都被视为包含所有特性的树木节点。统计的如果是一个横向特性,关于分点数据的信息被记录为纯度的基础,以便将节点划分。第二,比较已登记数据的特点,确定最佳特点,并找出将数据集从样本中隔开的分界点。最后,决策树按照这些规则建立。
决策树算法的基本思想是利用属性选择度量(ASM)来确保属性是决策节点,并将数据集分割成更小的子集,使数据集被分割成更小的子集,思想是选择最好的属性来划分。通过递归,对每一个子集重复这个过程,就满足了其中一个条件,可以开始构建树形结构,直到用来划分数据的属性选择度量的最佳分割标准集合,它是一种启发式算法,也称为分割规则。这是因为它有助于确定给定节点上元组的断点,其过程如图1所示。
用决策树学习的核心问题之一是特征的区分。经典的三种情况可以得出三种有代表性的决策树算法。
同时,决策树算法可以较好地应对过拟合的风险,可通过“剪枝”来一定程度避免因决策分支过多,以至于把训练集自身的一些特点当作所有数据都具有的一般性质而导致的过拟合,进而提高决策树的泛化能力,而“剪枝”又可以分为先剪枝和后剪枝两种方案。
二、模型构建
(一)指标选择
以消费者为对象,对其采用问卷调查的形式,针对影响消费者对品牌好感度的因素分析,选定的评价指标应力求全面反映消费者对品牌的好感。对品牌评价进行决策树分析,最终将指标分为:K1,即商品价格;K2,即商品使用寿命;K3,即商品售后;K4,即网络上该商品的普遍评价;K5,即对该商品的感受。并对10种商品进行商品体验。其中将K1分为5级:A为0~100元;B为100~300元;C为300~500元;D为500~1 000元;E为1 000元以上;将其他四个评价等级也分为5级,分别为:A为优秀(90—100);B为良好(80—90);C为中等(70—80);D为合格(60—70);E为不合格(<60);获得10种商品评价如表4所示。
(二)模型構建
通过表4所示的评价结果,利用ID3算法构成决策树,部分程序代码如下:
Print(Start training)
Tree=train(train_features,train_labels,list(range(feature_len)))
Time_3=time.time()
Print(training cost %f second'%(time_3—time_2))
Print(Start predicting)
Tests_predict=predicting(test_features,tree)time_4= time.time()
Print(predicting cost %f second'%(time_4—time_ 3))
根据表4中获得的质量评价结果和建立的决策树,确定样本期望信息熵为:
I(S)=-log2()-log2()-log2()=1.25775996
对于商品价格K1,存在有Values(K1)=(A,B,C),SA={6,8},|SA|=2,SB={1,2,3,5,9,10},|SB|=6,SC={4,7},|SC|=2,计算获得商品价格K1条件期望信息,可得到E(K1)=0.758。
比较样本的信息熵有:Gain(K1)=I(S)-E(K1)=0.503,同理可得到其他属性的信息熵分别为Gain(K2)=0.607,Gain(K3)=0.476,Gain(K4)=0.432。
比较样本的信息熵有:Gain(K2)>Gain(K1)>Gain(K3)>Gain(K4)。可以看出,样本中商品使用寿命属性信息增益具有做大值,因此选择教学内容K2作为根节点测试属性,在每个值根节点创建分支,并基于ID3从根节点进行进一步细分。若根节点到当前节点路径包含了所有样本的全部属性,或属于同一训练样本层,则算法完成,根据教学内容K2测试属性建立的决策树形图如图1所示。
(三)决策结果
根据已建立的决策树可以确定知识的表述形式为:
if(K2=A),then K5=优秀;
If(K2=B),then K5=良好;
根据分析可知,商品使用寿命,即耐用程度K2在商品评价中占主导地位,若商品使用寿命为优秀时,获得的商品评价为优秀;若商品使用寿命为良好,则商品评价为良好。因此对商品评价中,商品的质量应作为主要的考虑因素,同时兼顾售后等其他样本。
结语
大数据时代对企业的生存带来了新机遇,也带来了很多的挑战,如何迎合客户喜好、如何进行更好的售后服务等等,都是企业要考虑的问题,但企业应将顾客对商品耐用程度的需求放在首位,应从如何提高商品寿命,降低次品率考虑。
数据挖掘对于现代企业而言是一种可以用于分类客户、进行产品定位等功能的重要辅助工具,其应用领域仍然有很大的开发空间。因此,研究人员应不断深入挖掘数据挖掘这一实用工具的应用潜力。
参考文献:
[1] 毛国军,段立娟,王实.数据挖掘原理与算法[M].北京:清华大学出版社,2005.
[2] 王珏,周志华,周傲英.机器学习及其应用[M].北京:清华大学出版社,2006.
[3] 闫友彪,陈元琰.机器学习的主要策略综述[J].计算机应用研究,2004,(7):4-10.
[4] 王爱平,张功营,刘方.EM算法研究与应用[J].计算机技术与发展,2009,(9):108-110.
[5] 孙志军,薛磊,许阳明,等.深度学习研究综述[J].计算机应用研究,2012,(8):2806-2810.
[6] 李旭然,丁晓红.机器学习的五大类别及其主要算法综述[J].软件导刊,2019,(7):4-9.
[7] 吴玉轩.机器学习算法在金融市场风险预测中的应用[J].信息系统工程,2019,(2).
[8] 李赟妮.神经网络模型在银行互联网金融反欺诈中的应用探索[J].金融科技时代,2018,(8):24-28.
[9] 王雅静.银行个人客户信用评分模型研究——基于决策树算法[J].现代商贸工业,2015,(19):6465.
[10] 严蔚敏,李冬梅,吴伟民.数据结构:C语言版[M].北京:人民邮电出版社,2011.
[11] West D.Neural network credit scoring models[J].Computers & Operations Research,2000,(11-12): 1131-1152.
[12] Domingosp.The master algorithm:how the quest for the ultimate learning machine will remake our world[M].England:Reed Business Information Ltd.,2015.
[13] Sun H.N.,HU X.G.Attribute Selection for Decision Tree Learning with Class Constraint[J].Chemometrics and Intelligent Laboratory Systems,2017,(163):16-23.
[14] KE G.L.,Meng Q.,Finley T.,et al.Light GBM: A Highly Efficient Gradient Boosting Decision Tree//Guyon I,Luxburg U V,Bengio S,et al.,eds.Advances in Neural Information Processing Systems 30.Cambridge,USA:The MIT Press,2017:3149-3157.
猜你喜欢
中国现代医生(2022年21期)2022-08-22
速读·下旬(2016年8期)2017-05-09
电子技术与软件工程(2016年24期)2017-02-23
时代金融(2016年27期)2016-11-25
科技视界(2016年20期)2016-09-29
哈尔滨理工大学学报(2016年2期)2016-09-12
企业导报(2016年6期)2016-04-21
