
基于yolov5s的街道场景检测的实现
2022-05-10 05:25刘庆
电脑知识与技术 2022年9期
刘庆

摘要:随着人工智能的发展,其中的深度学习极大地推动了计算机视觉的发展。 目标检测作为计算机视觉中的一个重要分支,在街道场景检测以及城市交通管控中也有着重要作用。文章中采用yolov5s目标检测算法,实现了街道场景中目标的检测,首先分析了目标检测算法的类型以及文章中所用到目标检测算法的发展和框架。通过yolov5s对标注好了的数据集进行训练,然后利用yolov5s目标检测算法进行检测,从实验结果可以看出yolov5s对小目标检测以及多目标检测有比较好的效果,并且准确率较高,速度较快。
关键词:深度学习;目标检测;yolov5s;街道场景检测
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2022)09-0096-03
1 引言
近几年,随着计算机视觉的迅速发展,目标检测作为计算机视觉中的一个基本问题,也得到了很大的发展,已经应用到了智能交通、智慧医疗等领域,特别是在疫情期间随处可见的基于目标检测的红外热像仪,并且在日常的超市自助付款中也有用到。目标检测主要任务是在图像或图像序列中对目标进行精确分类和定位[1]。分类这一部分的任务是在获取输入图片时,判断一下图片中是否存在我们想要检测的物体,如果存在,那么就会输出一系列带有置信度分数的标签,主要是用来表示我们想要检测的物体在输入图像中的概率。定位这一部分的任务是确定输入图片中我们想要检测的物体的位置以及所占范围的大小,并且输出目标物体的外边框范围。目标检测算法分为两大类,一类是传统的目标检测算法,另一类是基于深度学习的目标检测算法。传统的目标检测算法存在检测难度大,不准确等特性,基于深度学习目标检测算法具有准确率高、速度快等特性。所以近年来,基于深度学习的目标检测算法往往应用范围较大一些。并且基于深度学习的目标检测算法分为两大类,一种是单阶段的目标检测算法,另一种是双阶段的目标检测算法。单阶段的目标检测算法检测速度较快,这是它最大的一个优点,双阶段目标检测算法相对来说检测准确率较高,两种方法各有利弊,所以要在不同的应用中选择合适的方法实现目标检测。yolov5目标检测算法凭借其优秀的检测速度和精度,已经广泛应用于医学图像、行人检测、车辆检测等实际应用中[2]。文章中将详细介绍利用单阶段的目标检测算法yolov5s实现街道场景的检测,因为是对小目标和多目标进行检测,并且yolov5s实现的街道场景检测效果基本满足应用需求。
2 传统目标检测算法与基于深度学习的目标检测算法
2.1 传统目标检测算法
目标检测的任务就是把存在的目标从图片中找到并识别出来。传统目标检测算法代表有V-J检测器、HOG+SVM方法以及DMP方法。V-J检测器用于人脸检测,HOG+SVM方法用于行人检测,而DMP方法更是传统目标检测算法的巅峰之作,它采用了“分而治之”的检测思想,并且为了加快检测速度,设计了将检测模型“编译”成一个更快的模型,实现了级联结构,在不牺牲任何精度的情况下实现了超过十倍的加速度,虽然目前的对象检测器在检测精度上远远超过了DMP,但是其中也有很多值得我们学习的地方。传统的目标检测算法可以概括为三个部分,分别是区域选择、特征提取、分类器。区域选择部分主要就是用來对检测的目标位置进行定位,由于被检测的目标可能会出现在图像中的任何一个位置,并且被检测的目标的长宽比例、大小也不能轻易确定。所以采取的是利用滑动窗口机制对整幅图像进行遍历,这样就需要设置不同的尺度,不同的长宽比等,所以这部分存在很多缺点,例如时间复杂度过高,产生的冗余窗口相对较多等。这些缺点也会对后面的特征提取与分类这两部分产生不好的影响。并且这种机制对于长宽比浮动较大的多类别目标检测效果不是很好,因为滑动窗口遍历也不一定能得到很好的区域。特征提取过程中,由于目标的形态多样以及光照因素的影响等等,导致人工手动设置特征的方法存在鲁棒性不好、检测精度低等问题。这两大缺点使得传统的目标检测算法使用范围很小,目前目标检测问题都会采用深度学习相关的目标检测算法。
2.2 基于深度学习的目标检测算法
基于深度学习的目标检测算法分为两大类,一类是单阶段目标检测算法,另一类是双阶段目标检测算法。单阶段的目标检测算法在实现目标检测过程中不会产生候选框,而是直接把目标边框的定位问题转化为回归问题来处理,单阶段的目标检测算法是以YOLO、SDD、RetinaNet等为代表的基于回归分析的检测算法[3]。单阶段目标检测算法只需一次提取特征就可以实现目标检测,因此优点是检测速度快。双阶段目标检测算法是将检测过程分为两个阶段,第一个阶段是利用某些算法生成一系列的候选框,作为样本,第二个阶段是通过卷积神经网络对第一个阶段生成的样本进行分类,这种类型的目标检测的代表算法有RCNN、SSPnet等。由于这两种目标检测算法的差异,前者在检测速度上占优,后者在检测的准确率和定位精度上占优。近年来,yolov算法发展迅速,不仅实现了检测速度快,检测的精度也在逐步提高。所以文章中采用yolov5s算法实现街道场景检测,主要是对小目标以及多目标进行检测,采用yolov5s是因为其网络模型较为简单、检测速度快,准确率也能满足基本要求。
3 yolov算法的发展历程
在yolov提出之前,R-CNN系列的算法在目标检测领域被广泛应用,R-CNN检测算法最大的一个优点是检测精度高,但是它是一种双阶段的目标检测算法,这使得它的检测速度满足不了实时性这一个要求,因此设计一种检测速度更快的目标检测算法成为目标检测领域的主要任务。由此提出了yolov1算法,yolov1的主干网络是VGG-16,它是一种单阶段的目标检测算法,核心思想就是将目标检测转化为一个回归问题,利用整张图片作为网络的输入,经过一个神经网络,得到边界框的位置以及其所属的类别。yolov1算法检测速度十分快,实时检测效果也比较好,迁移能力强,可以应用到其他新领域,但是对于密集目标和小目标检测效果不太好,并且没有采用Faster RCNN的锚框机制,增加了训练难度。因此推出了yolov2,yolov2是yolov1的升级版。引入了BN层,以及anchor机制,移除了全连接层,丢弃pooling层,防止信息丢失[4]。并且提出了一个新的网络Darknet-19,提高了分类精度,并且该网络适应多种尺寸图片的输入。yolov2虽然解决了模型训练困难,泛化能力差等问题,但是使用了预训练,迁移比较难,小目标召回率不高,密集目标检测效果差。继而提出了yolov3,yolov3引进了多尺度预测,采用了多标签分类,使用了Darknet-53网络,分类器也抛弃了原先使用的Softmax分类器,并且分类损失采用二分类交叉损失熵,这使得yolov3的目标检测效果比yolov2更好。并且yolov3借用了残差网络,进行了多尺度检测,跨尺度特征融合,使得对小目标检测的精度进一步得到了提升。但是由于yolov3的模型较复杂,所以对于中,大型目标检测没有很好的效果。后来又推出了yolov4,yolov4采用了CSPDarknet53网络结构,使用了Mosaic数据增强,采用Mish激活函数等等。这使得其在检测速度和检测精度之间取得了权衡,但是检测精度也有待提高。后来推出了yolov5,yolov5采用了CSPDarknet53+Focus网络结构,增加了正样本,加快了训练速度,实现了自适应图片缩放等等,使得yolov5模型小,检测速度高,灵活性高。虽然无论在速度和精度上yolov5已经算比较好的一种目标检测算法,但性能依旧有待提高。
4 yolov5s的网络结构
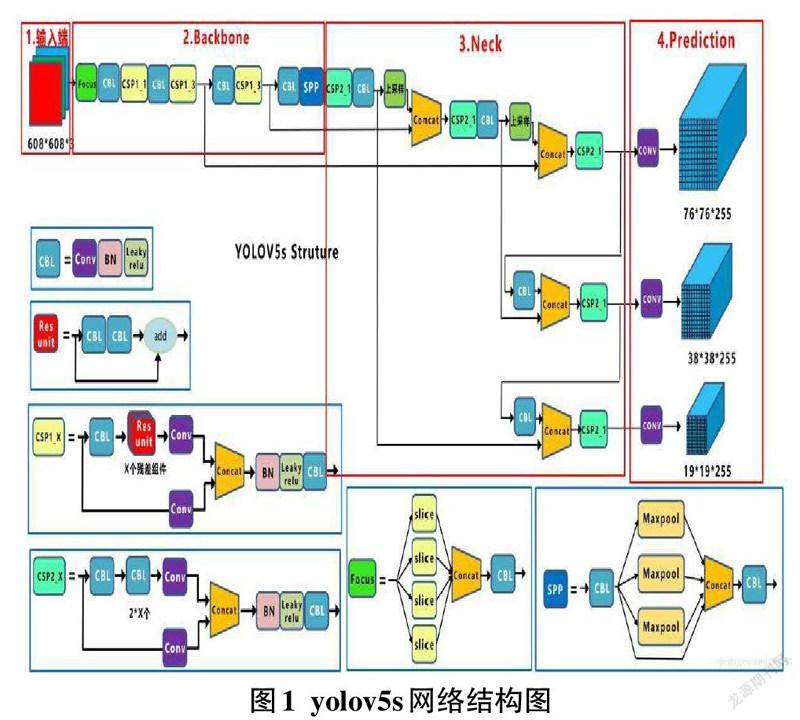
本文采用的是yolov5s的网络模型,yolov5目标检测算法包括yolov5s、yolov5m、yolov5l、yolov5x四个网络模型。网络模型复杂程度以及网络模型的深度和宽度依次递增,网络的特征提取能力也逐渐增强,目标检测的精度也是随着网络模型的复杂程度不断提高,但是目标检测所用的时间也逐渐增加的。yolov5s是yolov5系列中深度最小、特征图宽度最小的网络,实现起来较为简单。文中采用这个网络模型使得街道场景检测速度比较快且检测精度满足基本需求。 yolov5s网络结构包括四个部分,分别是输入端、Backbone、Neck、输出端,如图1所示。
yolov5s的主要组成部分
(1)输入端
yolov5s的输入端通过对图片进行翻转、缩放、色域变化等等操作,并且把原数据和增强数据拼接传入卷积神经网络进行学习[5],采用了自适应锚框计算,以获取合适的锚框,也采用了自适应图片缩放,减少了模型的计算量,也提高了对小目标的检测效果。
(2)Backbone
这部分融合了其他检测算法中的一些新思路,主要包括Focus结构、CSP结构以及SPP模块。Focus模块的作用就是图片进入Backbone前,对图片进行切片操作[6],切片操作是一个非常重要的部分,以yolov5s模型为例,切片过程如下:首先将608*608*3的原始图片输入Focus结构,进行切片操作之后,会变成304*304*12的特征图,然后把特征图经过一次32个卷积核的卷积操作,就会变成304*304*32的特征圖,这就是切片操作的过程。切片之后进行卷积操作,就会得到二倍下采样特征图,这个特征图是没有信息丢失的。图片经过Focus模块之后,最直观的就是起到了下采样的作用,但是和常用的卷积下采样不一样,计算量和参数量更加复杂,经过改进后,参数量变少了,达到了提速的效果。yolov5s的网络模型设置了两种新的CSP结构,主干网络采用CSP1_1结构和CSP1_3结构,颈部采用CSP2_1结构[7]。CSP结构的实现减少了计算瓶颈,减少了内存消耗。SPP模块借鉴了一种空间金字塔的思想,通过SPP模块实现了局部特征和全部特征,极大地丰富了特征图的表达能力。这对于yolov5实现复杂的多目标检测十分有利,并且检测精度也有了很大的提升。
(3)Neck
Neck是目标检测网络在Backbone与最后的Head输出层之间插入的一层,yolov5s中的Neck结构采用了FPN+PAN结构。yolov4中的Neck部分也采用了和yolov5一样的结构,但是yolov4中的Neck部分全都是普通的卷积操作,但是在yolov5中的Neck结构中,采用了CSPnet设计的CSP2结构,这种结构对网络特征融合的能力的提高十分有利。FPN采用向下采样,PAN采用向上采样,将高层的特征信息通过上采样的方式进行传递融合,就会得到进行预测的特征图,这种方式进一步提高了特征提取能力[8]。从而将获得的更有效的信息传输到预测层。
(4)输出端
输出端包括了Bounding box损失函数和nms非极大值抑制。yolov5s中采用GIOU_LOSS作为Bounding box的损失函数,在目标检测的后处理过程中,针对很多目标框的筛选,通常需要进行nms操作。采用nms算法把GIOU_LOSS贡献值不是最大的预测结果都去除,然后将概率最大的预测结果输出,生成边界框并且预测其所属类别。
5 实验结果及分析
本次实验主要环境有window10、pycharm、pytorch等等,数据集采用的是coco数据集。主要是利用yolov5s目标检测算法实现街道场景检测,实现的效果图如下。
从实验结果可以看出,利用yolov5s目标检测算法对街道场景进行检测,是因为其网络模型小,使得检测速度比较快,并且检测的准确性也能满足基本需求。图中有人和车以及石柱这些目标,可以看出yolov5s目标检测算法在小目标检测和多目标检测中有着比较好的检测效果。如果采用yolov5m、yolov5l或者yolov5x作为目标检测算法,检测的准确性会逐步提高,检测所用的时间也会逐渐增加。文章采用yolov5s目标检测算法主要是为了追求检测速度快,并且准确性也基本满足需求。
参考文献:
[1] 董文轩,梁宏涛,刘国柱,等.深度卷积应用于目标检测算法综述[J/OL].计算机科学与探索:1-20[2022-02-24].http://kns.cnki.net/kcms/detail/11.5602.TP.20220129.1108.004.html.
[2] 黄振龙,吴林煌.基于Yolov5s和Dlib的视频人脸识别[J].电脑知识与技术,2021,17(32):94-96.
[3] 许德刚,王露,李凡.深度学习的典型目标检测算法研究综述[J].计算机工程与应用,2021,57(8):10-25.
[4] 李成.基于改进YOLOv5的小目标检测算法研究[J].长江信息通信,2021,34(9):30-33.
[5] 杨晓玲,蔡雅雯.基于yolov5s的行人检测系统及实现[J].电脑与信息技术,2022,30(1):28-30.
[6] 刘彦清.基于YOLO系列的目标检测改进算法[D].长春:吉林大学,2021.
[7]张锦,屈佩琪,孙程,等.基于改进YOLOv5的安全帽佩戴检测方法[J/OL].计算机应用:1-11[2022-02-24].http://kns.cnki.net/kcms/detail/51.1307.TP.20210908.1727.002.html.
[8] 彭雅坤,曹伊宁,刘晓群.基于YOLOv5s的滑雪人员检测研究[J].长江信息通信,2021,34(8):24-26.
【通联编辑:梁书】
猜你喜欢
软件(2016年4期)2017-01-20
科教导刊·电子版(2016年28期)2017-01-10
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
科学与财富(2016年28期)2016-10-14
电脑知识与技术(2016年5期)2016-04-14
科技视界(2016年4期)2016-02-22
现代电子技术(2015年14期)2015-07-22
