
基于小样本知识蒸馏的乳腺癌组织病理图像分类
2022-05-16 08:48王雷奇陆慧娟朱文杰霍万里
中国计量大学学报 2022年1期
王雷奇,陆慧娟,朱文杰,霍万里
(中国计量大学 信息工程学院 浙江省电磁波信息技术与计量检测重点实验室,浙江 杭州 310018)
医学图像在临床诊断中应用广泛,如使用磁共振图像(Magnetic Resonance Imaging, MRI)进行脑部肿瘤识别和病灶区域分割,使用超声图像进行甲状腺癌的检查,使用胸部X射线进行肺部疾病的检测,使用显微镜下的细胞涂片进行宫颈癌的早期诊断,使用组织病理图像进行乳腺癌、结肠癌的诊断等。随着模式识别与计算机视觉技术的发展,医学图像的计算机辅助诊断研究成为国际医疗影像研究的重点领域,具有十分重要的科学意义。
目前对乳腺癌的诊断主要通过组织病理学分析[1]。其中最关键的步骤是活体组织检查,病理学家根据活体组织检查的结果来最终诊断患者是否罹患乳腺癌。然而,随着乳腺癌患者数量不断增多,仅仅依靠人工诊断将无法满足未来的患者需求。加之不同医生的主观意识与个人经验偏差及长期工作导致的劳累等,使得效率低下甚至误判。因此,近年来医学图像信息提取和处理分析已成为计算机辅助诊断的一个重要研究领域。
随着机器学习在生物信息学中的广泛应用,将深度学习方法用于乳腺癌医学影像识别分类[2],以辅助疾病诊断是学者们一直在致力研究的方向。与人工诊断相比,机器诊断更为客观,且诊断效率高,可以在短时间内处理大量图像数据,其诊断准确性也在不断提高,为医生在病理分析过程中提供了客观有效的数据,极大地减轻了医生的负担。然而,深度学习网络通常规模很大,其部署会占据大量的计算资源。通过知识蒸馏技术将大规模的深度学习网络知识转移到小模型上,则可以显著降低计算资源需求。
本文在公开的乳腺癌数据集BreakHis数据集上,通过模块化知识蒸馏技术,将大型网络模型的知识转移到小规模网络模型上,在小规模网络模型上实现BreakHis数据集图像的分类,探索小样本知识蒸馏技术在医学图像分类上的可行性。本文在多教师知识蒸馏中提出一种简单有效的多教师soft target整合方法,以提高优秀教师模型在知识蒸馏中的指导作用。本文使用的知识蒸馏方案是基于小样本的双级蒸馏策略,其核心在于它通过将学生模型的部分参数替换成教师模型的参数的方法,来学习学生模型的参数。这种嫁接策略可以更好地利用教师模型中训练有素的参数,并且显著缩小了学生模型的参数空间。
1 相关工作
小样本学习利用少量样本进行图像分类学习,可以解决训练数据量少的问题[3-4]。基于度量学习的方法[5-7]和元学习[8-10]是当前在小样本学习中广泛应用的两种方法。从形式上看,小样本学习的训练集有着很多不同的类别,每一个类别中包含多个样本。在模型训练阶段,将在训练集中抽取N类,每类K个样本(总共N×K个样本数),构建一个meta-task,作为模型的支持集(support set)输入;再从这N类的余下数据中抽取一批(batch)样本数据作为模型的查询集(query set)。即要求模型从N×K个样本数据中学会区分这N类,这样的任务被称为N-wayK-shot问题。
近年来恢复预训练网络引起了该领域内研究人员的关注[11]。自2006年Bucilua等[12]提出了原型知识蒸馏方法,该方法使用来自一组异构模型的预测来训练神经网络。2015年Hinton等[13]提出了知识蒸馏的概念,引入温度参数(Temperature)来软化教师网络的预测。为了减少总的训练时间,2019年Yang等[14]提出了在线蒸馏的方法,将学生网络和教师网络的训练统一到一个步骤中,这些方法消耗了大量的标签数据来传递教师网络中的知识,这严重影响了实际部署的方便性。另一方面,Song等[15]的研究侧重于评估不同任务之间的知识可传递性,Yang等[16]则是在探索图域上的蒸馏。2020年徐国栋等[17]利用自我监督信号改进了传统蒸馏,在少样本和嘈杂标签场景下获得了显着收益。同年李天宏等[18]提出了一种从无标签样本中提取知识的新解决方案,以实现数据效率和训练/处理效率的提升;该方法将原始网络视为“教师网”,将压缩后的网络视为“学生网”。2021年Lim J T[19]提出的方法通过自我知识蒸馏使性能得到了进一步增强,自我知识蒸馏在学生网络训练期间提供了教师网络的指导,所以学生网络能够得到比教师网络更准确地传递知识。
2 网络体系结构
2.1 知识蒸馏
2015年Hinton首次提出了知识蒸馏的概念,通过引入与教师网络(teacher network)相关的软目标(softtarget)作为总损失(total loss)的一部分,以引导学生网络(student network)的训练,实现知识迁移。其中教师网络一般为复杂但推理性能优越的网络;学生网络一般为精简、低复杂度的网络。教师网络的推理精度越高,越有利于学生网络的学习。
知识蒸馏的目标是让学生网络与教师网络的softmax输出的分布足够接近。但是在一般的softmax函数中,其输出的是其中一个值很大,其他的都很小的,接近one-hot的向量。这种情况下知识的体现非常有限,携带的信息量很低。类似one-hot向量这样的硬性输出,知识蒸馏希望其输出向量更“软”一些。所以本文考虑使用一个这样的softmax函数:
(1)
其中T是温度参数,这是从物理学中借用的概念。当温度T趋向于0时,softmax的输出将收敛为一个one-hot向量;温度T趋向于无穷时,softmax的输出则更“软”。
如图1所示,教师网络(左侧)的预测输出除以温度参数T之后再做softmax变换,可以得到软化的概率分布,即软目标(soft target),数值介于0~1之间,且取值分布较为缓和。温度参数越大,则分布越平缓;反之温度参数数值越小,则越容易放大错误分类的概率,引入不必要的噪声。硬目标(hard target)则是样本的真实标注,一般用one-hot向量表示。总损失(total loss)为软目标和硬目标相对应的交叉熵加权平均所得,其中软目标交叉熵的加权系数越大,说明知识迁移引导过程越依赖于教师网络的贡献。
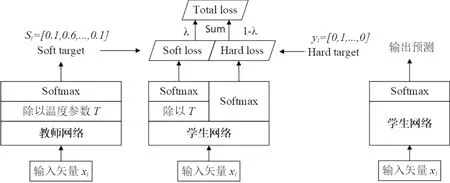
图1 知识蒸馏概念模型Figure 1 Model of knowledge distillation
LTotal=λLSoft+(1-λ)LHard。
(2)
式(2)中,λ为软目标的加权系数其大小由网络训练时自动得出。引入加权系数λ的目的是,在软化硬标签的同时,最大限度的保留软标签输出的分析类信息。
模型融合能够有效提升模型预测的效果,但会带来耗时的增加。因此,可以通过知识蒸馏的方式,让student模型从多个教师模型中学习知识,来达到近似或比模型融合更佳的效果。因此,本文提出一种多教师模型知识蒸馏,其结构如图2。

图2 多教师模型知识蒸馏Figure 2 Multi-teacher model knowledge distillation
多教师模型同时向学生模型传递知识的最简单方式就是对所有教师模型的输出进行平均求和。这种做法虽然实现简单,但是不同的教师模型的结构和训练框架都不同,所能够提供的知识的重要程度也是不同的,如果有一个效果较差的教师模型,将会较大程度影响到学生模型的学习效果。
另一方面多个教师模型的损失“富集”在学生模型中,也会影响学生模型的判断能力。因此可以对不同教师模型的知识传导进行加权,本文提出的权重计算方式如下:

(3)
式(3)中λn即为得到的权重,为教师模型得到的软目标和硬目标做对比得到,λn越大则说明该教师模型的判断效果越优秀。通过λn加权得到的软目标可以表示为
(4)
然后对得到的软目标归一化,降低噪声的影响。
提出的方法相较传统知识蒸馏的优越性在于可以整合多个教师模型的软目标,通过权重λn调整每个教师模型在总的知识蒸馏过程中的影响占比,从而保证分类效果优秀的教师模型在知识蒸馏过程中起到更显著的指导作用。
2.2 基于小样本的原则性双级蒸馏策略
2020年Shen等[20]提出一种针对少量数据定制的原则性双级蒸馏方案。该方案分为两步,第一步,将学生区块逐一嫁接到教师网络身上,并与其他教师区块交织在一起训练,训练过程只更新嫁接区块的参数。第二步,将训练有素的学生区块逐步连接,然后一起嫁接到教师网络上,让习得的学生区块相互适应,最终取代教师网络。小样本知识蒸馏的目标是将知识从教师网络转移到学生网络,每个类别仅使用少量样本取得优秀的蒸馏效果。


图3 小样本知识蒸馏的两阶段知识蒸馏策略Figure 3 Two-stage knowledge distillation strategy for small sample knowledge distillation

2.2.1 嵌段嫁接
在可用样本较少的情况下,一般认为很难对神经网络进行优化,尤其是有大量参数的网络。为了降低网络优化的复杂性,将学生网络分解为一系列区块,每个区块包含较少的参数。学生区块嫁接到教师网络上,如图3所示。嫁接后的教师网络可以表示为
(5)


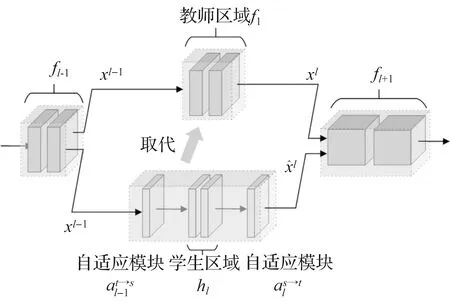
图4 训练分块嫁接Figure 4 Training block grafting
(6)
其中表示来自网络的第l个块的输出。自适应模块采用1×1卷积运算实现。它实现了输入特征在通道维度上的线性重组,并且不改变接受域的大小,该接受域旨在使学生和教师之间的特征对齐。有两个特殊情况需要说明:
(7)
(8)
其中H1(x)和HL(x)分别表示第一个包装的学生区块和最后包装的学生区块。结合公式(5)、(6)、(7)、(8),最终嫁接的教师网络可以写成
(9)
2.2.2 网络嫁接
从上面的部分可以得到一系列经过训练的学生区块,每个学生区块都可以与教师网络的区块一起进行决策。然而,这些训练有素的区块未曾合并在一起训练。在这一部分中,采用网络嫁接策略,逐步增加嫁接教师网络中的学生块,减少对原教师网络的依赖。

(10)

由于自适应模块是线性的,可以在不增加任何参数的情况下,将自适应模块的参数合并到下一块hl+1的卷积层中。对于
(11)

(12)

(13)
它与学生网络S具有相同的网络结构,也就是实现了从教师网络T到学生网络S的知识转移。
2.2.3 网络优化
不同网络架构的Logits规模可能会有很大差距,这会导致优化困难。通过优化损失函数来指导优化模型,提出了教师区块和学生区块之间知识转移的归一化的损失函数如下:
(14)

(15)

3 实 验
3.1 数据集
2016年Spanhol等[21]公开了一个乳腺癌组织病理学图像(BreakHis)数据集共有7 909幅乳腺肿瘤组织的彩色显微图像,这些图像来自82个受试者,放大倍数分别为40、100、200和400。图像高度和宽度分别为460和700。该数据集中共有8个类。代表性图像如图5(a),数据分布如图5(b)。图像为活体组织检查时收集到的乳腺组织切片在显微镜下放大不同倍数的影像。由经验丰富的病理学家对这些图像进行诊断,最终将乳腺组织切片图像分为8类,其中恶性乳腺组织4类,良性乳腺组织4类。
BreakHis数据集提供4种不同的放大倍数的图像数据,本文将不区分其倍数差别,将图像分为8类进行训练。
3.2 预处理
本文拟采用VGG16模型进行预训练,作为教师模型,VGG6-half作为学生模型。其中VGG16-half具有与VGG16相似的网络体系结构,但在相应层中的通道数比之VGG16减半,以此得到一个轻量化的VGG网络[18,21]。
BreakHis数据集图像数据大小为460×700,VGG的输入图像大小为224×224,需要将数据集图像缩小为224×224。本文采用等比例缩放,将图像长边缩放为224,等比例缩放图像短边,并在其短边填充黑框,调整图像大小为224×224。BreakHis数据集共有7 909幅图像,选取其中的80%作为训练集,剩余20%作为测试集。在小样本设计中,从原始数据集中每类随机抽取K个样本作为训练集,其中K∈{1,5,10}。将随机裁剪和随机水平翻转应用于训练图像以增加数据集。测试集与原测试集相同。
3.3 实验过程
本文仿真实验在NVIDIAGTX1070 8GGPU、Inteli7-6700KCPU上使用PyTorch框架进行训练和测试。在单类样本图像数目为10时(即10-shot),将批次大小(batchsize)设置为64。对于K-shot训练,将batchsize设置为[64×K/10]。所有的实验使用ADAM算法进行网络优化,ADAM是一种自适应优化器,它会在训练过程中自适应改变学习率,使其更加适合用于梯度下降。在batchsize=64情况下,文中嵌段嫁接和网络嫁接速率分别为2.5×10-4、1×10-4。对于其他K-shot训练,设置batchsize=B=[64×K/10],学习率分别为B/64。
实验所用教师网络为VGG16在完整BreaKHis数据集下,训练得到。
3.4 实验结果
使用本文多教师软目标整合方法得到的软目标和平均求和得到的软目标,分别进行了小样本蒸馏训练。
使用本文多教师软目标整合方法小样本蒸馏的性能如表1,多教师软目标整合方法能够提高小样本双级蒸馏策略的性能。随着教师模型的数量增加,学生模型VGG16-half的精度也随之增加。可以看到使用本文多教师软目标整合方法进行小样本蒸馏训练的情况下,在三个教师模型训练后的学生模型VGG16-half的精度的小样本条件下可以达到0.418~0.466。在10-shot条件下的分类精度较之所有教师模型都要高。同时学生模型的通道数较之教师模型要少许多,故学生模型分类精度接近教师模型的分类精度的同时,得到更加轻量化的模型。
直接通过平均求和得到的软目标用于模型训练是得到的实验结果如表2所示。与表1数据对比可知,使用本文提出的多教师软目标整合方法训练得到的学生模型精度更高,能够更好的通过知识蒸馏传递知识。

表1 本文多教师软目标整合方法小样本蒸馏的性能
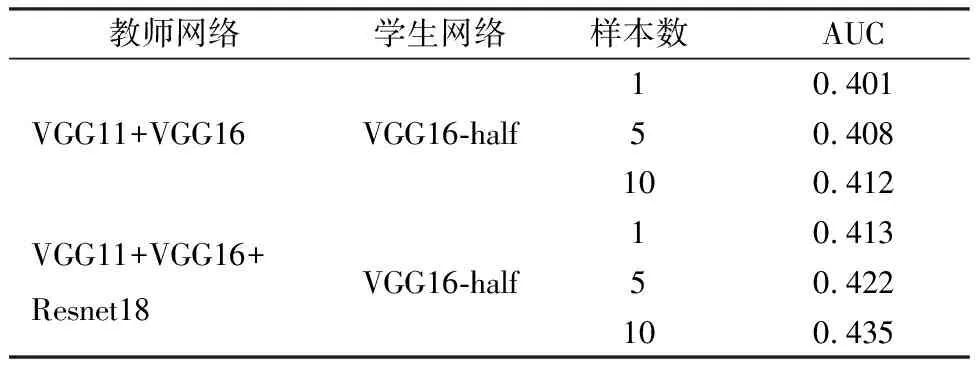
表2 软目标平均求和小样本蒸馏的性能
4 结 论
本文结合多教师小样本知识蒸馏技术改进双级递进知识蒸馏。在多教师知识蒸馏中提出一种简单有效的多教师软目标整合方法。在BreaKHis数据集上的实验结果表明,通过多教师软目标整合方法整合的软目标要比平均求和的软目标更加优于进行小样本知识蒸馏,表明使用多教师软目标整合方法整合的软目标训练的学生模型精度更高,能够更好的在知识蒸馏过程中传递教师模型的知识。并且在多教师模型的小样本双级蒸馏策略中,教师模型数量的提高,对学生模型学习效果也有促进作用。
本文利用每类较少的未标注样本来迁移教师网络的知识到学生网络。在第一阶段,学生网络被分成几块,嫁接到教师网络相应的位置上。利用蒸馏损失固定教师区块信息来优化学生区块。在第二阶段,将训练好的学生区块逐个嫁接到教师网络上,并训练它们相互连接,直到整个学生网络的区块完全取代教师网络的区块。在BreaKHis数据集上的实验结果表明,通过基于小样本的双级蒸馏策略成功地将教师网络的知识传递到学生网络,并获得了与教师网络几乎相当的决策性能,且其网络结构更加轻量化。
猜你喜欢
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化·高一版(2021年2期)2021-03-19
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
作文小学中年级(2020年6期)2020-07-24
红楼梦学刊(2020年3期)2020-02-06
中国外汇(2019年7期)2019-07-13
领导决策信息(2018年16期)2018-09-27
金桥(2018年7期)2018-09-25
当代贵州(2018年21期)2018-08-29
数学学习与研究(2017年3期)2017-03-09
