
基于LDA主题识别与熵权法的岗位技能需求研究
2022-06-11 13:56陈平生
江苏广播电视报·新教育 2022年5期
关键词:熵权法


摘要:在线招聘作为人才招聘的重要渠道,在线招聘广告中蕴含了丰富的岗位技能需求信息,从在线招聘广告中识别并分析岗位技能需求,为专业人才培养目标的编制提供依据。本文以大数据技术相关岗位的在线招聘广告为例,分析岗位分布和开发工具词频,利用LAD主题模型分析技能主题,识别技能特征词,构建技能特征-开发工具映射关系,最后利用熵权法评估技能需求。评估结果:最需要的技能是数据分析,占45%。其次是数据库和机器学习,然后是数据报告、深度学习、网络爬虫、应用开发和数据处理。本文的研究有效避免了调查问卷、专家访谈等传统方法的主观干扰及样本量少、信息滞后等问题。
关键词:岗位技能需求;LDA;主题识别;熵权法
高职教育主要目标是培养岗位需要的高素质技术技能型人才,促进学生高水平就业。全面分析岗位技能需求并非易事,传统的智能制造等岗位因技术进度技能需求不断变化,Ai芯片元宇宙大数据等新行业伴生的岗位、因新冠疫情等特定事件产生的疫情管理等新岗位的技能需求更是无觅寻处;而且不同企业的相同岗位技能熟练程度多样化,如要求具备某项技能、熟悉某项技能或是精通某项技能。企业调研、专家访谈等难于快速准确分析岗位的技能需求。
分析岗位技能需求主要有三类方法:①从高职办学定位的宏观角度分析岗位技能需求,以“高适应性职业化专业人才”为定位[1],建立二维四向模型分析职业教育专业发展需求[2],按照产业职业岗位对员工理论、技能的最高要求开展专业技能培养[3]。②从学校出发,以学校的专业文件、教学资源、专业管理的数据中抽取知识实体与关系,采用知识图谱分析岗位技能[4];③从企业的生产、技术革新和产业的发展趋势分析技能需求,如利用负荷平衡与技能链模型[5]、回归模型预测[6]、多因素灰色模型[7]等方法预测分析技术技能型人才需求。
在线招聘广告蕴含了丰富的岗位技能需求信息,本文以在线招聘广告为研究对象,采用文本分析方法,对岗位技能需求做快速准确分析,为专业人才培养目标的编制提供依据。
1.研究方案设计
1.1研究对象选取
岗位技能需求常用专家调研、问卷调查等方式获取,但是成本高,难于获取大量样本。而在线招聘广告中的职位信息(岗位职责、任职要求)就有明确的岗位技能要求。在线招聘是人才招聘的主要渠道之一,传统招聘网站,如:前程无忧,智联招聘,中华英才网;垂直招聘网站,如:拉勾网;猎头招聘网站,如:人人猎头、猎聘网、猎上网;社交招聘网站,如:大街网、内推网、哪上班;综合分类信息网站,如:58同城、赶集网、百姓网。招聘企业在招聘网站发布了众多的招聘广告(如2020年3月15日23時51jobs,https:// mkt.51job.com/tg/sem/logo_v1.html?from=baiduad检索大数据招聘信息:24小时内11516条、近三天26241条、近一周35160条、近一月43482条);本文选择前程无忧网站大数据相关岗位招聘广告作为研究对象,分析岗位技能需求。
1.2研究模型选择
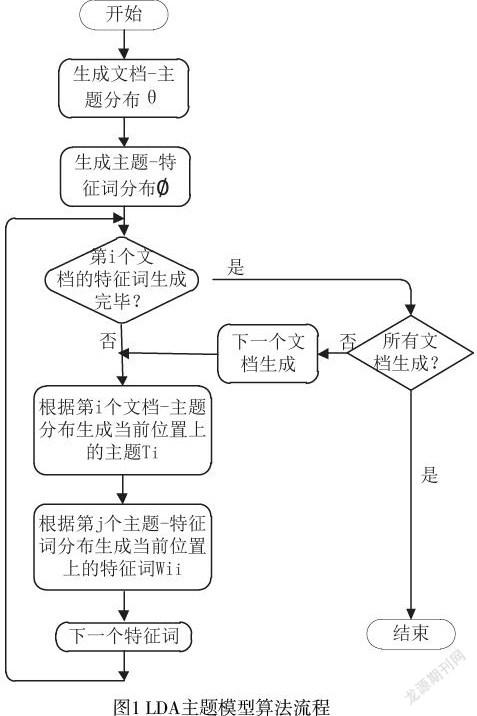
本研究采用LDA概率主题模型对在线招聘广告中的职位信息进行文本分析,利用文本的特征词的共现特征挖掘文本的主题,快速识别文档中的岗位技能需求信息。LDA概率主题模型最早由Blei et al.2003年提出,是一种文档主题生成模型[8],也称为贝叶斯概率模型,就是一篇文章的每个特征词都是通过“以一定概率p选择了某个主题topic,并从这个主题以一定概率p选择某个特征词语word”。
p(word|document)=∑_(k=0)^K▒〖p(word│topic) 〗|p(topic|document)(1)
LDA模型有三层结构:从上到下分别为文档层、主题层、特征词层,使用Dirichlet分布求解文档-主题概率分布和主题-特征词概率分布,确定潜在的主题和特征词。
pp(w_j |D_i)=∑_(k=0)^K▒〖p(w_j│T_k ) 〗|p(T_k |D_i)(2)
其中p(wj|Di)表示特征词wj出现在文档Di中的概率,此概率值为特征词的概率与主题特征词概率的乘积,即wj在主题Tk中出现的概率与主题Tk在文档Di中出现的概率的乘积,K为主题的个数。对于文档集合D中的每一个文档,LDA主题模型生成流程:
(1)从Dirichlet分布ᵅ中取样生成文档的主题分布θ,主题分布θ由超参数为ᵅ的Dirichlet分布生成。
(2)从Dirichlet分布ᵝ中取样生成主题T对应的特征词分布Ø,特征词分布Ø由参数为ᵝ的Dirichlet分布生成。
(3)对于每一个文档,根据θ分布,抽样获得文档di的主题分布,从主题分布中抽取主题Ti。
(4)根据Ø分布,抽样获得主题的特征词分布,从上述被抽到的主题Ti做对应的特征词中抽取特征词Wij。
(5)重复上述过程直至遍历文档中的每一个特征词。
1.3研究方案
(1)数据来源及处理
本研究主要包括在线招聘广告数据采集、技能要求和岗位要求挖掘,研究思路如图2。采集在线招聘广告数据,清洗非相关数据和重复数据。
(2)研究方法
数据预处理:对在线招聘广告中的岗位职责、任职资格进行数据清洗、分词、去停用词、词性标注等预处理。
主题分析和技术工具分析:利用LDA主题模型识别岗位技能特征词、统计技术开发工具词频。
岗位核心技能分析:分析岗位技能特征词与技术工具的映射关系,分析岗位技能。
2.数据处理与分析
2.1数据采集与预处理
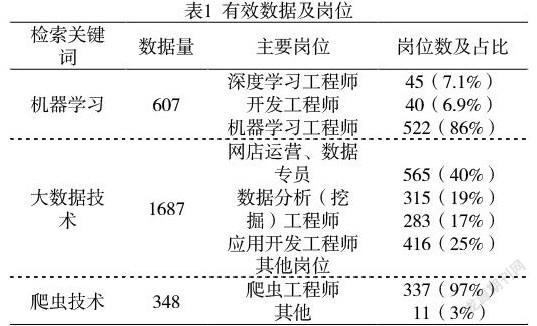
本文以大数据技术相关岗位群为例,以前程无忧网站(www.51job.com)作为数据来源,该网站的招聘信息包括:岗位名称、发布时间、公司名称、公司类型、公司规模、薪资、福利政策、工作地点、经验要求、学历要求、招聘人数、职位信息(岗位职责、任职资格)、联系方式、公司信息等,以文本方式存放在html网页中,可利用python、scrapy、xpath等技术爬取企业招聘广告。按大数据技术、机器学习、爬虫技术三类岗位关键词爬取招聘广告,针对爬取数据中的无效数据按以下原则清洗:①清洗与大数据相关岗位无关的招聘数据。②清洗企业在不同时间重复发布的同一岗位的数据。③清洗职位信息为空的数据。④清洗职位信息描述不超过15个字的无效数据。⑤清洗岗位名称与职位信息描述明显不符的数据。⑥对大数据技术、机器学习、爬虫技术三个关键词均能爬取到的相同的数据,根据岗位相似程度分别归类到相应的类别中。清洗处理后三类岗位的招聘广告数据量及其对应的岗位如表1:
使用jieba库对在线招聘数据的任职要求和技能要求文本数据进行分词和标注,对照自定义词库分词保留专业名词,按照停用词库删除停用词、与技能无关的词和无意义的特殊符号,如:“【】@[]”等,最后形成职位信息词向量。
2.2开发工具词频分析
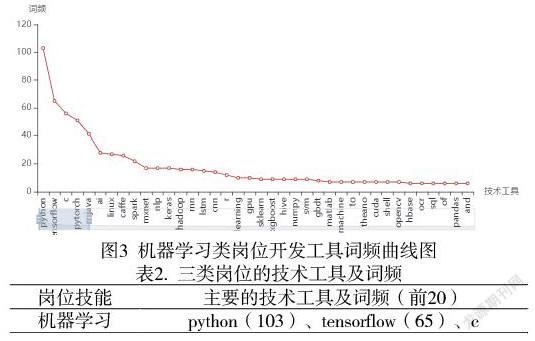
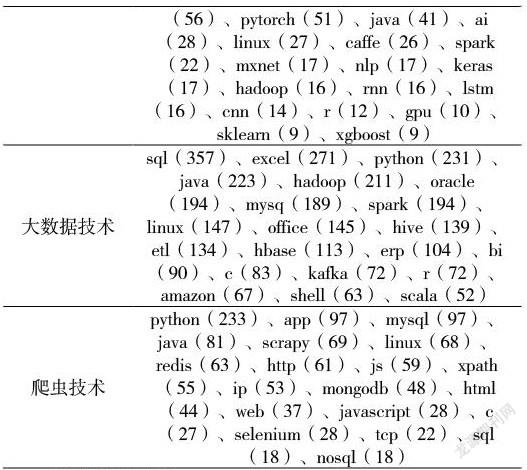
采集的数据经分词预处理后,三类岗位的开发工具进行词频统计,机器学习类岗位开发工具的词频曲线如图4(大数据技术、爬虫技术的开发工具词频曲线与图4相似,为节省篇幅省略)。开发工具词频分布呈现“长尾现象”,在线招聘的岗位技能要求是非结构化数据,是岗位自身需要而发布招聘信息,众多的岗位需求各异,必然导致技术开发工具的需求多样。三类岗位的技术开发工具词频表1。
2.3技能主题建模
(1)主题数选择
LDA主题建模的质量有主题困惑度(Perplexity)[9]和主题一致性[10]两种方法判断。主题困惑度可以理解为所训练出来的模型对某一文档属于哪个主题有多不确定,这个不确定则为困惑度,困惑度越低,说明主题建模效果越好。主题一致性是指生成每一个主题所对应的高概率词语在语义上是否一致,主题一致性得分越高,主题模型效果越好。本文采用主题一致性得分来判断主题模型的好坏,主题一致性有u_mass、c_v、c_uci 以及c_npmi四个度量值[11]。
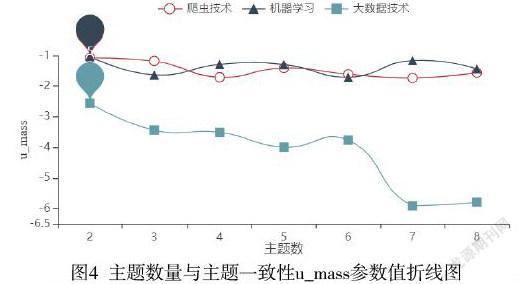
采用gensim模块中CoherenceModel类计算u_mass值来确定最佳主题数,三类岗位的LDA主题建模u_mass值与主题数的关系如图4所示。
从图5可以看出,爬虫技术和机器学习两个岗位的u_mass值随主题数的增大反复波动、大数据技术岗位的u_mass值随主题数的增大而逐渐减小,三类岗位的主题数为2时u_mass值最大,主题建模质量最好。
(2)技能主题识别与可视化
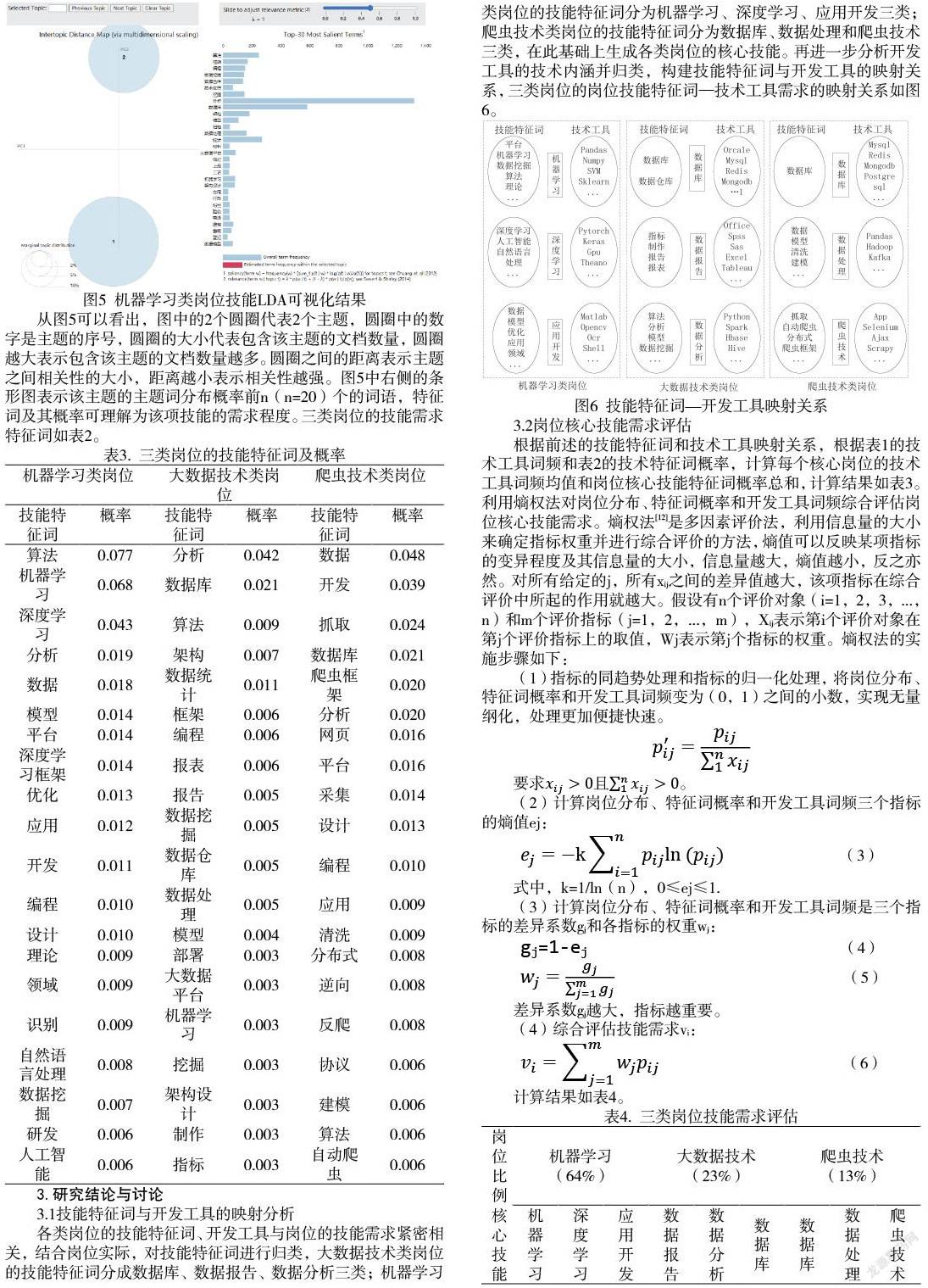
对大数据技术、机器学习和爬虫技术三类岗位的职位信息(任职要求、技能要求)文本数据进行LDA主题建模分析,将 LDA 模型的参数设置为:K=2,迭代次数300次,超参数α=50/K,β=0.01。利用gensim库和pyLDAvis库进行主题建模和可视化,识别在线招聘广告数据中的技能特征词。机器学习类岗位的LDA可视化结果如图6所示(大数据技术、爬虫技术的LDA可视化结果与图6相似,为节省篇幅省略)。
从图5可以看出,图中的2个圆圈代表2个主题,圆圈中的数字是主题的序号,圆圈的大小代表包含该主题的文档数量,圆圈越大表示包含该主题的文档数量越多。圆圈之间的距离表示主题之间相关性的大小,距离越小表示相关性越强。图5中右侧的条形图表示该主题的主题词分布概率前n(n=20)个的词语,特征词及其概率可理解为该项技能的需求程度。三类岗位的技能需求特征词如表2。
3.研究结论与讨论
3.1技能特征词与开发工具的映射分析
各类岗位的技能特征词、开发工具与岗位的技能需求紧密相关,结合岗位实际,对技能特征词进行归类,大数据技术类岗位的技能特征词分成数据库、数据报告、数据分析三类;机器学习类岗位的技能特征词分为机器学习、深度学习、应用开发三类;爬虫技术类岗位的技能特征词分为数据库、数据处理和爬虫技术三类,在此基础上生成各类岗位的核心技能。再进一步分析开发工具的技术内涵并归类,构建技能特征词与开发工具的映射关系,三类岗位的岗位技能特征词—技术工具需求的映射关系如图6。
3.2岗位核心技能需求评估
根据前述的技能特征词和技术工具映射关系,根据表1的技术工具词频和表2的技术特征词概率,计算每个核心岗位的技术工具词频均值和岗位核心技能特征词概率总和,计算结果如表3。利用熵权法对岗位分布、特征词概率和开发工具词频综合评估岗位核心技能需求。熵权法[12]是多因素评价法,利用信息量的大小来确定指标权重并进行综合评价的方法,熵值可以反映某项指标的变异程度及其信息量的大小,信息量越大,熵值越小,反之亦然。对所有给定的j,所有xij之间的差异值越大,该项指标在综合评价中所起的作用就越大。假设有n个评价对象(i=1,2,3,...,n)和m个评价指标(j=1,2,...,m),Xij表示第i个评价对象在第j个评价指标上的取值,Wj表示第j个指标的权重。熵权法的实施步骤如下:
(1)指标的同趋势处理和指标的归一化处理,将岗位分布、特征词概率和开发工具词频变为(0,1)之間的小数,实现无量纲化,处理更加便捷快速。
3.3结果讨论
技能需求第一层次:
数据分析技术需求占比45%,主要是电商数据、企业生产数据、仓库数据的统计分析、预测。技能特征主要是数据统计、算法、数据挖掘、框架、数据处理、分析、模型;主要开发工具:excel、BI、Python、Hadoop、Hive等。
技能需求第二层次:
数据库技术占比12%,最主要的是利用SQL和NoSQL统计分析数据,技能特征主要是数据库和数据仓库,主要开发工具主要是Oracle、Mysql等传统的结构化数据库,Redis、Mongodb、PostgreSQL等非结构化nosql数据库的需求也日益凸显。
机器学习占比11%,主要对大数据按数据集准备、探索性的对数据进行分析、数据预处理、数据分割、机器学习算法建模、选择机器学习任务、效果评价及优化流程处理,重点是特征工程处理。技能特征词是机器学习、数据挖掘、平台、算法、分析、理论,技术工具:Python、R、Sklearn、Xgboost、Hive、Numpy等。
技能需求第三层次:
数据报告技术占比8%,主要是选择分析指标、撰写分析报告。技能特征词是报表、报告、制作、指标,主要的技术工具是Office、Excel、ERP、Spss、Tableau以及商务智能BI软件。
深度学习占比7%,在自然语言、视频等领域,按数据集准备、数据预处理、数据分割、定义神经网络模型、训练网络流程处理,核心是引入复杂网络模型结构,定义神经网络模型结构、确认损失函数、确定优化器、反复调整模型参数。技能特征词是深度学习、人工智能、自然语言处理、深度学习框架,主要的技术工具是tensorflow、pytorch、caffe、mxnet、keras、gpu等。
爬虫技术占比7%,主要是面向商业平台的数据采集,需要熟练的反爬虫技术。技能特征词是抓取、网页、采集、设计、编程、协议、自动爬虫、反爬、分布式、逆向、爬虫框架、平台,主要的技术工具是app、selenium、ajax、ios、scrapy、pyspider等。
应用开发占比6%,主要是在自然语言、视频等领域的web应用开发。技能特征词是数据、模型、优化、应用、编程、设计、领域、识别、研发、编程,主要的技术工具是java、django、flask、matlab、opencv等。
数据处理占比5%,主要是数据清洗、集成、规约、存储等。技能特征词是数据、分析、清洗、应用,主要的技术工具是java、pandas、numpy等。
4.结语
本文以在线招聘广告数据为分析对象,利用LDA主题模型开展潜在主题分析,挖掘岗位技能特征词、分析技术工具词频,能准确把握岗位技术的需求,避免了问卷或访谈等调查方法的主观干扰,研究结果更加客观。此外,在线数据可以实时采集分析,分析结果具有实时性。分析数据不包含线下招聘以及校招岗位的技能需求,补充线下招聘广告数据将使分析更全面。
对比不同时间段内的在线招聘数据可以挖掘岗位技能需求的变化,预测岗位技能变化趋势。
参考文献:
[1]周建松,唐林伟.高职教育人才培养目标的历史演变与科学定位——兼论培养高适应性职业化专业人才[J],中国高教研究,2013(02):28-34.
[2]陈嵩,郭文富.现代职业教育专业发展的需求模型构建—上海的思考与做法[J],职教论坛,2019(19):61-65.
[3]孙湧等.高职院校人才培养目标定位研究与实践[J],计算机教育,2006(10):24-26.
[4]胡光水.专业知识与技能体系知识图谱的构建研究[J],工业与信息化教育,2020(12):123-127.
[5]廖丽萍.随机需求下的工人技能分布模型研究[J],湖南科技学院学报,2013(19):127-132.
[6]安鴻章,邹勇.企业技能人员需求预侧模型建立与应用[J],经济与管理研究,2007(11):64-68.
[7]田楠.基于多因素灰色模型的技术技能型人才需求预测与分析—以天津市为例[J],职业技术教育,2014(19):43-48.
[8]Blei D, Ng A,Jordan M. Latent Dirichlet Allocation.Journal of Machine Learning Research,2003,3:993-1022.
[9]陆艺,曹健.面向隐式反馈的推荐系统研究现状与趋势[J].计算机科学,2016,43(4):7-15.
[10] Roeder M. and BothA., et al. Hinneburg, Exploring the Space of Topic Coherence Measures[J].Association for Computational Linguistics,2015,2(13),399-408.
[11]https://blog.csdn.net/weixin_31468621/article/details/112195887.
[12]陈传军,王智峰,刘伟,等.数据建模简明教程-基于Python[M],科学出版社.
基金支持:2020年浙江省中华职业教育科研项目“企业岗位技能需求模型构建与专业人次啊培养目标研究”(编号ZJCVB09)。
作者简介:陈平生(1973-),男,江西赣州人,绍兴职业技术学院副教授,硕士,研究方向:大数据技术应用。
猜你喜欢
考试周刊(2016年103期)2017-01-23
海峡科技与产业(2016年11期)2016-12-26
现代情报(2016年11期)2016-12-21
商(2016年34期)2016-11-24
价值工程(2016年29期)2016-11-14
商(2016年27期)2016-10-17
现代经济信息(2016年9期)2016-05-24
商场现代化(2016年3期)2016-04-08
商业会计(2016年6期)2016-04-07
