
基于相关性分析的配电网多源数据质量提升方法
2022-06-21 01:14蒙小胖,孙常浩,蔡雷鸣,施广德,金舒
计算机时代 2022年6期
蒙小胖, 孙常浩, 蔡雷鸣, 施广德, 金舒



摘 要: 智能配电网采集数据来源广、数据质量较差,价值密度低。因此首先对配电网中各类系统采集的数据应用K-means聚类算法进行特征提取,结合局部异常因子(LOF)算法进行异常检测,筛选出异常数据;随后根据数据的多维特征运用相关性分析结合数据特征对异常数据进行修正;最后通过实际工程应用,验证多源数据质量提升方法的数据修正效果。
关键词: 数据质量; 关联分析; 智能配电网; 聚类算法; 多源数据
中图分类号:TP3 文献标识码:A 文章编号:1006-8228(2022)06-01-05
A quality improvement method of multi-source data in distribution network
based on correlation analysis
Meng Xiaopang1, Sun Changhao2, Cai Leiming2, Shi Guangde2, Jin Shu2
(1. Shaanxi Regional Electric Power Group Co., LTD, Baoji, Shaanxi 721000, China; 2. Guodian Nanjing Automation Co., Ltd.)
Abstract: The data collected by distribution network has the characteristics of wide sources, poor data quality and low value density. Therefore, a strategy for improving the quality of multi-source data in the intelligent distribution network is proposed. Firstly, the K-means clustering algorithm is applied to the data collected by various systems in the distribution network for feature extraction, and the local outlier factor (LOF) algorithm is used for abnormal detection to screen out abnormal data. Then, according to the multi-dimensional characteristics of the data, the abnormal data is corrected by correlation analysis combined with the data characteristics. Finally, the effect of multi-source data quality improvement algorithm is verified by practical engineering application.
Key words: data quality; correlation analysis; intelligent distribution network; clustering algorithm; multi-source data
0 引言
智能配電网信息化和智能化的程度不断提升,配电网采集数据逐步呈现多源、异构的大数据特征[1]。对海量多源数据进行整合,可以为配电网运行态势感知[2],运行状态综合评价提供重要数据支撑。
配电网数据采集终端由于数量多、分布广并且部分终端环境恶劣,工况复杂,在采集和通信过程中经常发生数据丢失或异常现象[3]。异常数据严重影响数据挖掘分析的效率,对缺失或者异常数据进行统计分析会使得结果与实际值差别较大,影响预测精度和运行控制决策的准确性[4]。因此,如何对配电网采集的多源数据进行异常检测和数据预处理是配电网大数据分析的前提和基础。
近年来,对于大数据技术在配电网中应用已有很多研究成果。文献[5]对大数据在电网中的应用场景进行了总结。文献[6]提出一种基于大数据分析的配电网态势感知方法,通过对配电网运行历史数据进行分析预测电网运行的趋势。文献[7]运用大数据技术对配电网运行历史数据进行挖掘和评估,实现配电网的风险预警。但研究成果大多集中在数据分析层面,对底层多源数据融合以及数据质量的提升研究较少。对于配电网的大数据分析应用而言,数据的多源融合是基础,数据质量的好坏,对数据挖掘效率和结果准确性有重要影响。文献[8]采用插值法对电网采集数据中缺失较少且变化较为平缓的数据进行修正,取得较好效果;文献[9]提出一种基于数据动态治理和修复策略的配电网数据质量提升管理平台架构。文献[10]提出基于自适应模糊神经网络模型对风电缺失数据进行填补,取得较好效果,但不适用于大面积数据缺失。以上对数据质量提升的研究大多基于某一维度或者某一方法对数据异常进行修正,应对大数据量和连续、大面积的异常数据处理较为困难。配电网中各个系统采集数据之间关联性较强,其多维关联性特征不可忽视。因此,本文根据配电网数据的多维相关性特点,采用聚类算法和相关性分析结合的方法提升数据修正的效率和效果,从而提升配电网整体数据质量,成为大数据分析和应用的有力支撑。
1 多源数据质量提升整体架构
多源、异构的数据场景给数据集成带来困难并且使得信息系统产生数据质量问题。针对这些问题,本文提出一种多源融合数据质量提升架构如图1所示。
架构包含数据来源层,数据存储层,数据质量管理层以及数据发布层。该框架通过分析不同数据源数据特征进行分库存储;随后通过数据质量管理模块对数据整体质量进行把控;最后将修正数据进行整理发布,支撐智能配电网的大数据分析应用。
2 多源数据质量提升方法
系统数据质量管理模块首先对缺失数据进行检测,并进行补0操作;随后采用K-means聚类法对系统输入数据进行特征提取,结合LOF算法进行异常数据筛查。数据修正模块通过多维数据相关性特征来进行数据修正。
2.1 异常数据检测方法
LOF算法是一种基于数据密度对异常点进行筛选的高精度算法,能够量化数据的异常程度,在数据清洗和异常检测中具有广泛应用。传统LOF算法需要计算数据集合中所有数据两点之间的距离,导致复杂度达高,难以应对大规模数据[11]。
本文运用K-means算法[12]与LOF算法结合进行异常数据检测,首先运用K-means算法将相同数据特征的数据进行聚类,随后运用LOF算法对每个类簇中的数据进行异常筛查,最后将待检测数据集筛选出异常数据。K-means算法可以用于数据特征提取,降低LOF算法复杂度,LOF算法对类簇内异常值进行检测可以增强K-means数据特征提取的准确性和效果。
2.1.1 K-means聚类法数据特征提取
配网系统采集数据具有较强的周期性,采用数据挖掘中的K-means聚类法对数据进行分析,获取采集数据的数据特征。
K-means算法的主要思想是将n个对象划分为K个类簇[C1…CK],每个类簇具有较高的相似度。算法的优化目标是最小化类簇的平方误差E。
[E=i=1Kx∈Cix-ui22] ⑴
其中,[ui=1Cix∈Cix]为类簇[Ci]的聚类中心。
其算法流程如下。
⑴ 从数据集合D中选取K个初始聚类中心点。
⑵ 计算集合内各个数据点到聚类中心点之间的欧几里得距离(公式2),选取最近的聚类中心点并纳入到该类中。
⑶ 计算完所有数据点后对各个类簇重新计算聚类中心。
⑷ 判断聚类中心是否发生变化,如果发生变化则返回步骤⑵,如果不发生变化则输出结果。
2.1.2 LOF算法概念
LOF算法的核心概念有以下四点。
⑴ 第k距离邻域:给定一个数据集合D,对于集合内的任意一点p,计算其他点与p点的欧几里得距离并从小到大排序,第k个记为该点的第k距离,第k距离以内的所有点为第k距离邻域,记作[Nk(p)]。其中欧几里得距离可以表示为:
[distp,q][=(p1-q1)2+(p2-q2)2+…+(pn-qn)2] ⑵
其中,[ p]和[q]分别为n维空间中的两个数据点,[dist(p,q)]为两个点之间的欧几里得距离。
⑵ 可达距离:空间中p点和o点之间的可达距离定义为点o的第k距离和[dist(p,o)]之间的最大值,记为[reach-dist(p,o)]。
⑶ 局部可达密度:数据点p的局部可达密度[lrdk(p)]为它邻近点之间平均可达距离的倒数。
[lrdk(p)=1o∈Nk(p)reach-dist(p,o)Nk(p)] ⑶
⑷ 局部异常因子:局部异常因子为点p邻域内点的局部可达密度与点p的局部可达密度之比的平均值,记为[LOFk(p)]。
[LOFk(p)=1Nk(p)o∈Nk(p)lrdk(o)lrdk(p)] ⑷
根据局部异常因子的定义,[LOFk(p)]值在1左右说明点p数据密度与其邻域内点的数据密度相当;当[LOFk(p)]远大于1或者远小于1则说明点p与其他点较为疏远,为异常点。
2.1.3 算法流程
基于K-means聚类和LOF算法的数据异常检测流程如图2所示。
通过两种算法结合,我们可以提取数据集合的特征,并筛选出数据集合中的异常数据。随后通过数据的多维相关性,来对异常数据进行修正和填补。
2.2 多维数据相关性分析原理
本文相关性分析算法采用皮尔逊相关系数法[13,14]来衡量不同来源数据之间的相关性;随后通过熵权法计算变量之间的权重关系。
2.2.1 皮尔逊相关系数
皮尔逊相关系数的计算公式如下:
[ρx1,x2=Cov(x1,x2)σxσx2] ⑸
其中,[x1,x2]分别为n维数据变量,[σx1, σx2]分别为[x1]和[x2]的标准差,[Cov(x1,x2)]两者间协方差。协方差计算公式如下:
[Cov(x1,x2)=i=1nx1(i)-x1x2(i)-x2n-1] ⑹
皮尔逊相关系数用于评价两个数据之间的相关性,当相关系数大于某一特定值则认为两个数据具有强相关性。
2.2.2 熵权法确定权重
熵权法[15]通过指标所含信息量大小来确定权重,能够有效地利用数据,排除主观因素影响。首先根据公式⑺计算各个变量之间的熵。
[Εj=i=1mρx1,x2lnρx1,x2lnm ] ⑺
各个变量的权重也可以由公式⑻获得。
[ωj=1-Εjj=1m1-Εj ] ⑻
权重[ωj]体现了指标信息量的大小,能够量化指标对于结果的影响。[j=1mωj=1]。
2.3 基于多维数据特征的配电网数据修正方法
配电网数据采集周期选定为T=24h。采集的数据集合[C={c1, c2,…,cM}]中包含有M个属性(如电流、电压等)。对于属性[ci]的异常数据集合,基于多维数据特征的数据修正方法如下。
⑴ 运用K-means聚类法对集合C中的各项属性历史数据进行特征提取,运用LOF异常检测算法筛选出异常数据集合和正常数据集合。
⑵ 选取各属性的正常数据集合,通过关联分析计算各个属性之间的皮尔逊系数。對于需要修正的属性[ci],筛选出与其强相关的m个属性建立各个属性之间的皮尔逊相关系数矩阵[Σ],运用熵权法确定各自权重[wj,j=1,2,…,m];
⑶ 属性[ci]的异常数据集记为[Xi={xi1, xi2, …,xin}],对于其中一条异常数据记为[xik, k=1,2..n],在m个强关联属性中选取[ci]的一个强关联属性[cj],在其数据集合[Yj={yj1, yj2, ...,yjn} ]中寻找与[xik]相同时间历史数据点记为[yjk],[ yjk]所处类的聚类中心记为[yj*k]。
⑷ 在选取所有m个强关联属性后,通过加权求和求得原始数据的最优修正结果:[xi*k=j=1mwjyj*k]。
⑸ 选取[Xi]中的下一条异常数据,重复步骤⑶和⑷直到所有异常数据被修复。
数据数据质量提升流程可以总结如图3所示。
3 实际应用验证
这里以陕西地电电力公司应用的数据服务中心的运行采集数据作为实例验证本文提出的数据质量提升策略的有效性。
数据服务中心接入数据包括:电力公司的营销系统、配电自动化系统、故障抢修管理系统的业务数据。
3.1 关键技术验证
本文以配电自动化系统中遥测数据50组采集数据为例,验证数据质量提升技术的应用效果。
首先根据历史数据关联性分析,得到与馈线A端断路器A相电流采集数据强关联的属性(皮尔逊系数)。如表1所示。
随后通过本文的数据质量提升方法进行异常数据的检测和修正,修正后的历史数据存入修正库。
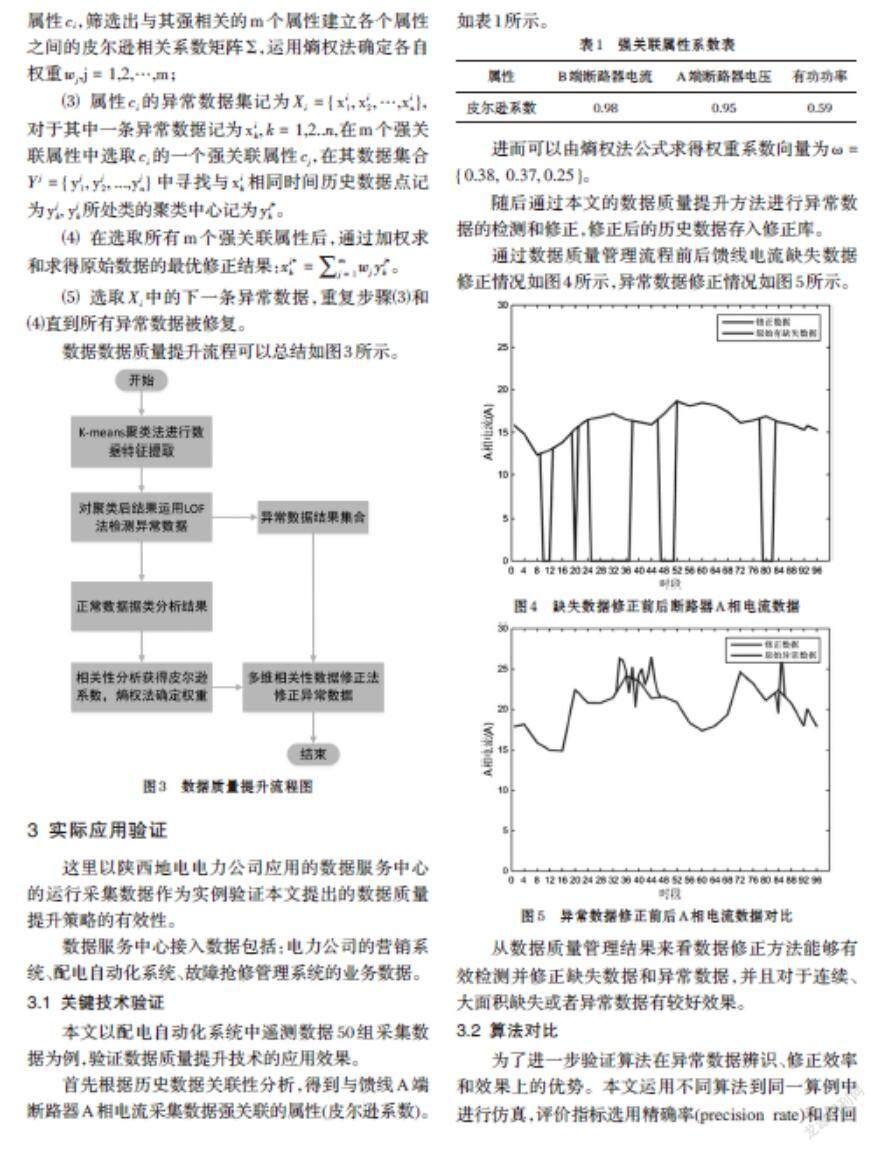
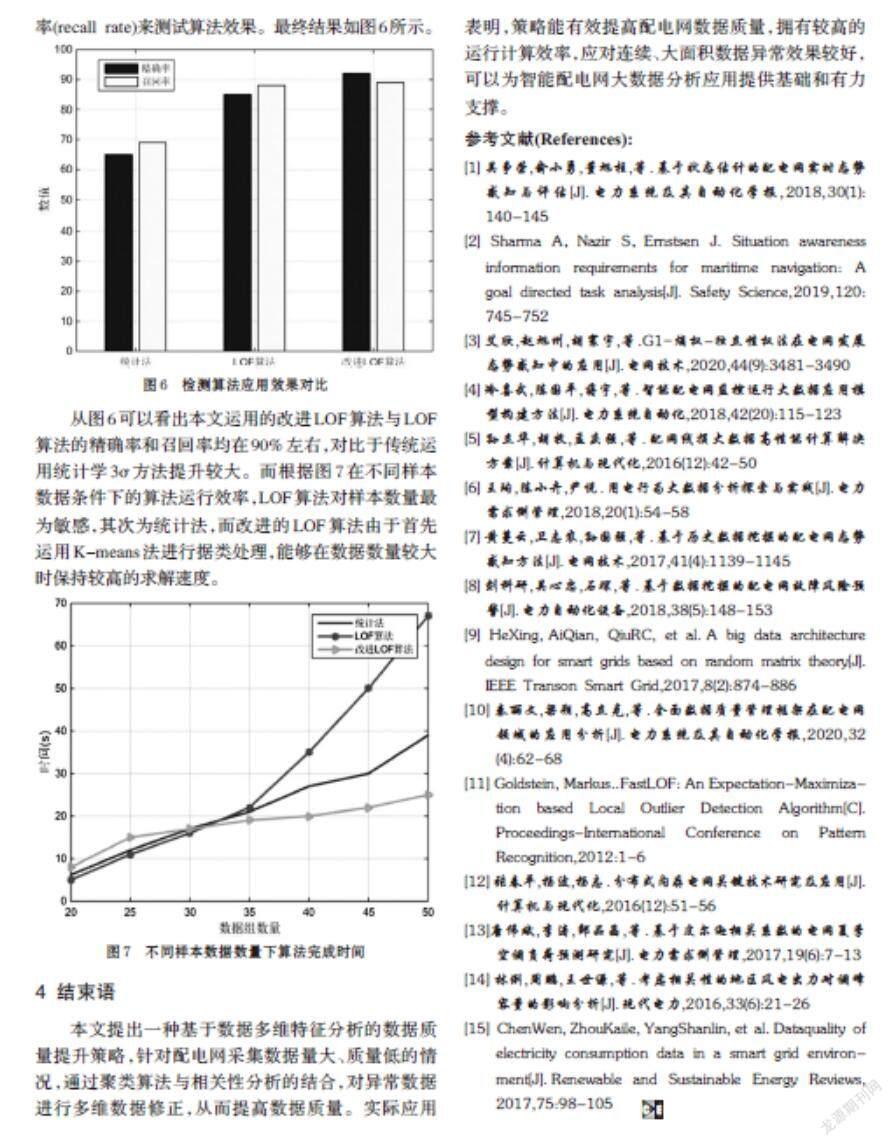
通过数据质量管理流程前后馈线电流缺失数据修正情况如图4所示,异常数据修正情况如图5所示。
从数据质量管理结果来看数据修正方法能够有效检测并修正缺失数据和异常数据,并且对于连续、大面积缺失或者异常数据有较好效果。
3.2 算法对比
为了进一步验证算法在异常数据辨识、修正效率和效果上的优势。本文运用不同算法到同一算例中进行仿真,评价指标选用精确率(precision rate)和召回率(recall rate)来测试算法效果。最终结果如图6所示。
从图6可以看出本文运用的改进LOF算法与LOF算法的精确率和召回率均在90%左右,对比于传统运用统计学[3σ]方法提升较大。而根据图7在不同样本数据条件下的算法运行效率,LOF算法对样本数量最为敏感,其次为统计法,而改进的LOF算法由于首先运用K-means法进行据类处理,能够在数据数量较大时保持较高的求解速度。
4 结束语
本文提出一种基于数据多维特征分析的数据质量提升策略,针对配电网采集数据量大、质量低的情况,通过聚类算法与相关性分析的结合,对异常数据进行多维数据修正,从而提高数据质量。实际应用表明,策略能有效提高配电网数据质量,拥有较高的运行计算效率,应对连续、大面积数据异常效果较好,可以为智能配电网大数据分析应用提供基础和有力支撑。
参考文献(References):
[1] 吴争荣,俞小勇,董旭柱,等.基于状态估计的配电网实时态势感知与评估[J].电力系统及其自动化学报,2018,30(1):140-145
[2] Sharma A,Nazir S,Ernstsen J. Situation awareness information requirements for maritime navigation: A goal directed task analysis[J]. Safety Science,2019,120:745-752
[3] 艾欣,赵旭州,胡寰宇,等.G1-熵权-独立性权法在电网发展态势感知中的应用[J].电网技术,2020,44(9):3481-3490
[4] 冷喜武,陈国平,蒋宇,等.智能配电网监控运行大数据应用模型构建方法[J].电力系统自动化,2018,42(20):115-123
[5] 孙立华,胡牧,孟庆强,等.配网线损大数据高性能计算解决方案[J].计算机与现代化,2016(12):42-50
[6] 王珣,陈小卉,尹悦.用电行为大数据分析探索与实践[J].电力需求侧管理,2018,20(1):54-58
[7] 黄蔓云,卫志农,孙国强,等.基于历史数据挖掘的配电网态势感知方法[J].电网技术,2017,41(4):1139-1145
[8] 刘科研,吴心忠,石琛,等.基于数据挖掘的配电网故障风险预警[J].电力自动化设备,2018,38(5):148-153
[9] HeXing,AiQian, QiuRC, et al.A big data architecture design for smart grids based on random matrix theory[J].IEEE Transon Smart Grid,2017,8(2):874-886
[10] 秦丽文,梁朔,高立克,等.全面数据质量管理框架在配电网领域的应用分析[J].电力系统及其自动化学报,2020,32(4):62-68
[11] Goldstein, Markus..FastLOF: An Expectation-Maximiza-tion based Local Outlier Detection Algorithm[C].Proceedings-International Conference on Pattern Recognition,2012:1-6
[12] 张春平,杨波,杨志.分布式内存电网关键技术研究及应用[J].计算机与现代化,2016(12):51-56
[13]唐伟斌,李涛,邹品晶,等.基于皮尔逊相关系数的电网夏季空调负荷预测研究[J].电力需求侧管理,2017,19(6):7-13
[14] 林俐,周鹏,王世谦,等.考虑相关性的地区风电出力对调峰容量的影响分析[J].现代电力,2016,33(6):21-26
[15] ChenWen,ZhouKaile,YangShanlin,et al.Dataquality of electricity consumption data in a smart grid environment[J].Renewable and Sustainable Energy Reviews,2017,75:98-105
猜你喜欢
软件导刊(2016年12期)2017-01-21
计算机应用(2016年12期)2017-01-13
现代电子技术(2016年23期)2017-01-12
科技创新与应用(2016年34期)2016-12-23
软件导刊(2016年11期)2016-12-22
中国新技术新产品(2016年22期)2016-11-29
中国新技术新产品(2016年22期)2016-11-29
科技视界(2016年15期)2016-06-30
电脑知识与技术(2016年8期)2016-05-19
电脑知识与技术(2016年4期)2016-04-11
