
高维混合入侵检测数据的单类分类算法研究
2022-06-24 10:02莫少慧古兰拜尔吐尔洪买日旦吾守尔
计算机应用与软件 2022年4期
莫少慧 古兰拜尔·吐尔洪 买日旦·吾守尔
(新疆大学信息科学与工程学院 新疆 乌鲁木齐 830046)
0 引 言
网络空间安全已经发展成为海、陆、空之外的另一国家战场。网络中融合了政治、军事、经济等各方面的信息。一旦网络空间安全不能得到保证,将会泄露个人甚至国家的隐私[1]。
近年来,随着大数据和人工智能的兴起,计算机行业再一次蓬勃发展起来。人工智能的核心就是机器学习,它具有归纳、综合的作用。现如今,机器学习算法的应用不仅限于医疗、商业、工业等研究领域,机器学习算法因其有自我学习、自我完善的特性,还能运用在入侵检测系统(Intrusion Detection System,IDS)。目前已将贝叶斯[2]、K近邻(K-Nearest Neighbor,KNN)[3]、支持向量机(Support Vector Machine,SVM)[4]、神经网络[5]等应用在入侵检测系统中,其本质就是分类和建模的问题。机器学习算法能够根据其特点,做出科学的判断和预测,并在该领域得到广泛的运用[6-7]。
入侵检测(IDS)中的入侵是指没有经过某一系统的主人的允许的情况下,通过各种方式进入该系统的行为,相对地,入侵检测就是对这种入侵行为的察觉,无论是内部或外部攻击,甚至是误操作,都会提供实时的防护[8]。入侵检测技术分为基于主机、基于应用程序、基于网络三类。基于主机的入侵检测技术依赖于要安装在主机上的IDS系统的本地客户端或代理,然后寻找是否有在主机逻辑内容或主机活动中恶意更改的行为。基于应用程序的入侵检测技术仅在应用程序范围内检测应用程序运行方式的所有内容。基于网络的入侵检测技术则将涉及网络或子网络上的所有设备,这部分检测因为各种范围等原因,常会有错漏现象。
吕峰等[9]提出将KNN算法运用在入侵检测领域。文献[10]表明KNN算法在入侵检测系统有着更好的检测结果,非常适合运用到入侵检测中。它具有用于非线性分类,不假设数据分布、准确度高、对边缘点不敏感等优点。但在样本不均衡中的预测效果相对较差,还有一点是k值的选择不具有客观性,不易选到最优值。而在入侵检测数据中,数据不平衡是最常见的情况。所以,自从将KNN算法运用到入侵检测领域,相关研究人员们纷纷都对KNN算法进行了各种优化和改进,比如:张浩[11]引入了密度峰值的概念,并有效地缓解了样本不平衡的问题,对于监视和其他探测活动(Probe)类型和正常(Normal)类型的数据的辨别上有着极强的准确率;江泽涛等[12]利用主成分分析混合(Principal Component Analysis mix,PCA)进行降维,针对样本的高维问题,加快了算法的计算效率。
但这些改进算法还是存在缺陷,密度峰值最近邻算法不能有效检测U2R攻击,PCA降维方法仅能运用在连续型数据中,而网络环境下的大多数入侵检测数据都是由离散型和连续型组成的混合数据。本文对于这些问题,综合了国内外的相关研究,优化了KNN算法:针对样本的高维、混合问题,利用主成分分析混合(Principal Component Analysis mix,PCA mix)[13]进行降维;对于大样本、多分类的数据集,使用单类分类的方法[14]的其紧凑性和描述性的特点,结合均值[12]的概念,提出了一种单类分类KNN均值算法,使其不会过分受制于参数的取值,以至于准确率偏差过大;对于算法的准确性,利用了百分位数Bootstrap(PB)方法[15]对决策边界进行选择;与在入侵检测领域应用最广泛的单类分类方法——单类分类支持向量机(One Class Support Vector Machine,OCSVM)作对比,对本文改进算法的优越性进行验证。
1 相关算法
1.1 传统KNN算法
传统的KNN算法是分类或回归的无参数学习。它属于懒惰学习,也就是无须训练阶段。其核心思想是用每个样本周围最近的k个邻居来代表该样本。若假设k=5,用实心圆表示要被代表的样本,用乘号和三角形代表两种不同类别的样本,如图1所示,被代表的实心圆会被分为乘号的类中。

图1 KNN分类器示意图
传统的KNN算法有三个关键点:选择k值、距离计算方式以及分类方法[16]。k值一般是不大于20的正整数,基本为奇数。k值的选择具有极强的主观性,是直接输入的,所以k值非常不容易选到关键数值。而k值一旦偏差,会带来较大的误差,影响实验结果。
传统的KNN算法常用的计算距离的方式有:欧几里得距离、曼哈顿距离、余弦值、相关度等。本文使用欧几里得距离,并计算其均值,大大减少了实验结果的偏差幅度。欧几里得距离计算如下:
(1)
式中:x1i表示矩阵中第1列第i行的数。
1.2 OCSVM算法
SVM算法是分类或回归的有参数学习[17]。其核心思想是尽可能地利用一个超平面将不同类别的样本分割开来,并且将两种类型的样本分割得越远越好[18]。其原理表示大致如图2所示,假设它们的间距为d。
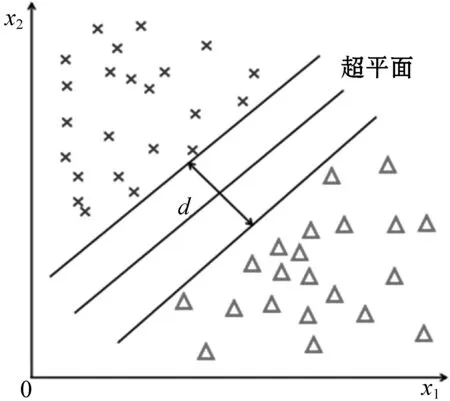
图2 SVM算法原理示意图
对于不平衡数据来说,要想分类不同类型的样本,采用OCSVM算法是一种不错的选择[19]。简单来说,OCSVM算法就是只使用其中一类样本来建立模型,然后预测两种类别的样本[20]。假设原点到超平面的最大距离为d,其大致原理如图3所示。

图3 OCSVM算法原理示意图
2 算法设计
2.1 PCA mix算法简介
PCA mix算法包括主成分分析(Principal Component Analysis,PCA)和多重对应分析(multiple correspondence analysis,MCA),是对定性变量和定量变量混合描述的一组个体(观察值)执行主成分分析[18]。换句话说,就是直接对于离散数据和连续数据组合而成的混合数据的主成分分析。PCA mix算法对离散数据进行量化矩阵计算,然后将该矩阵与连续数据矩阵连接起来进行主成分分析。此过程的目的是减少描述问题的变量数量[21]。
PCA算法是一种连续型数据的降维算法,其算法思路主要是:数据从原来的坐标系转换到新的坐标系,由数据本身决定。这是一种使用正交变换将一组可能相关变量的观测值转换为一组称为主成分的线性不相关变量的值的统计过程[22]。
具体来说,PCA算法先对所有样本去中心化,即取m个样本:
(2)
然后计算样本的协方差矩阵,再对协方差矩阵做特征值分解,取最大的j个特征值所对应的特征向量:ω1,ω2,…,ωj,最后将原样本投影到新坐标上。具体取几个特征值则要看降到的低维空间的维数,几维的低维空间就取几个特征值,这个维数通常是用户事先指定的[23]。
MCA算法是对应分析(CA)的一个扩展,用于分析若干相关类别变量的关系模式,在统计过程控制(Statistical Process Control,SPC)中称为属性特征。MCA算法是基于最优尺度变换的多重对应分析,是以点的形式在较低维度的空间中表示联列表的行与列中各元素的比例结构。能够更加直观地分析定性变量中多种状态间之间的相互关系[24]。当观察结果是分类的时,MCA算法可被视为PCA算法的一个推广。因此,可将PCA mix算法作为PCA和MCA的组合来处理不同类型的质量特性。
大多数数据分析方法多年来只专注于纯定量数据或纯定性数据的处理。PCA mix方法可直接处理离散数据和连续数据组合而成的混合数据,使得PCA mix方法在实际应用中非常有用,因为它可以从混合变量中提取相关信息,并且在数据库混合时不需要单独研究纯定量或定性变量,这对人们处理混合数据库提供了极大的方便,并节约了大量的时间。
具体的PCA mix算法如下所示[21]:设有一个n×m的样本矩阵A,n是矩阵中样本的个数,m是每个样本的总特征数。并且该样本矩阵中有k种不同的标签。设这m个特征中有a个连续型特征,b个离散型特征。即:
m=a+b
(3)
那么用矩阵B1表示n×a的连续型特征矩阵,矩阵B2表示n×b的离散型特征矩阵。
首先,使用矩阵K中心化连续矩阵B1为矩阵Z1,离散矩阵B2为矩阵Z2:
(4)
式中:En为单位矩阵;X=(1,1,…,1)T,一共有n个1。
然后计算离散矩阵B2中的每个特征与不同标签的相关性比例,并用对角矩阵D表示,假设第i个离散特征的不同标签的相关性比例矩阵为Di,则对角矩阵D为:
D=diag(D1,D2,…,Dk)
(5)
最后合并连续矩阵和离散矩阵为Y。
(6)
式中:Y1是中心化后的连续矩阵;Y2是经式(7)处理过后的连续矩阵。
(7)
2.2 单类分类KNN均值算法
在传统的KNN算法上应用均值计算,使改进算法不会受到样本之间可能出现的距离偏差太大的影响,具体方法如下:假设k=5,用实心圆表示要被代表的样本,用乘号和三角形代表两种不同类别的样本,如图4所示,被代表的实心圆会被分在乘号的类中,并用式(8)计算实心圆到周围乘号的均值。
d=(d1+d2+d3)/3
(8)
因为传统的KNN算法对于数据不平衡的样本有着严重的缺陷,所以本文在KNN均值算法的基础上加入了单类分类的方法,针对数据不平衡的数据集,期望能得到较好的实验结果。
单类分类KNN均值算法就是在训练时仅使用正样本作为训练样本,并计算每个样本周围k个样本到该样本的距离的均值,然后使用百分位数Bootstrap计算训练样本的距离的均值的决策边界,并去除1%以下和99%以上的极端值,存储到数组C={C1,C2,…,Cj}中。

图4 KNN均值分类器示意图
接着,计算测试样本中正样本到训练样本的距离的均值D={D1,D2,…,Dl}和测试样本中负样本到训练样本的距离的均值E={E1,E2,…,Em},让这些距离的均值与数组C中的值作对比,进行预测:
(9)
不同于原来的KNN算法,修改后的算法是半监督学习算法,原算法是监督学习算法。
本文改进算法具体如下所示:
输入:降维后的n个训练样本R;降维后的m个测试样本S;最近邻个数k。
输出:m个测试样本的分类。
1) 计算训练样本R中ri到自身最近k个点的均值欧氏距离;
2) 用百分位数Bootstrap计算1)中得到的n个距离,得到j个决策边界;
3) 计算测试样本S中si到训练样本R中最近的k个点的均值欧氏距离;
4) 用3)中得到的m个距离与2)中得到的j个决策边界作对比得到预测分类结果,如式(9)所示。
2.3 百分位数Bootstrap(PB)
Bootstrap方法是无模型的方法,以原始样本作为总体来进行重采样,无须预先了解参数分布,以此无限逼近最佳组合[26]。换句话说,就是Bootstrap方法对数据分布不要求,适用于所有的数据集,是计算决策边界的极佳方法。
估计置信区间的Bootstrap一共有四种方法:标准Bootstrap(SB)、百分位数Bootstrap(PB)、t百分位数Bootstrap(PTB)和修正偏差后的百分位数Bootstrap(BCPB)[27]。本文采用百分位数Bootstrap(PB)方法来估计单类分类KNN均值算法的决策边界。利用Bootstrap计算置信区间的经验分布的方法,计算(1-α)的quantile值,最终找出最佳的决策边界,达到分类效果最佳的目的。
2.4 本文算法流程
综合前面各节,本文算法的算法流程如图5所示。

图5 本文实验整体流程
3 数据处理
3.1 数据预处理
3.1.1特征提取
KDDCUP99数据集共有41个特征,其中有9个离散型特征,32个连续型特征。由于本文采取kddcup.data_10_percent文件,所以,“is_hot_login”、“wrong_fragment”、“num_outbound_cmds”这三个特征由于相同值太多,没有太大意义,被去除。所以真正参加实验的是8个离散型特征、30个连续型特征,共38个混合特征。
NSL-KDD数据集共有41个特征,其中有9个离散型特征,32个连续型特征。同样,由于选取KDDTrain+文件,文件中的“is_hot_login”、“wrong_fragment”、“num_outbound_cmds”这三个特征由于相同值太多,没有太大意义,被去除。真正参加实验的是8个离散型特征、30个连续型特征,共38个混合特征。
UNSW-NB15数据集共有45个特征,其中有5个离散型特征,40个连续型特征。本文选取的是专门被处理用来进行入侵检测的UNSW_NB15_training-set文件,除了文件中“is_sm_ips_ports”的特征由于相同值太多,没有太大意义,被去除之外,“id”与“attack_cat”都是因为在实验中无意义,所以被去除。真正参加实验的是4个离散型特征、38个连续型特征,共42个混合特征。
3.1.2特征值转化
实验中为了方便起见,将所有特征的特征值都转换为数字。具体情况如表1所示。

表1 特征值转换
对于数据集中少量的缺失值,本文采用缺失值均值填补的方式进行填补。
PCA mix降维方法能直接使混合数据集数据降维,所以对于PCA mix降维方法,数据集仅需将离散型特征转换为字符类型,将连续型特征标准化。若要使用传统的PCA降维方法[28],由于该方法仅适用于连续型特征,所以需将离散型特征强制转换为数值类型,这种转换可能导致原有的数据里的信息丢失,有着一定的缺陷。
3.1.3降维处理
现将全部样本分别通过PCA mix方法和PCA方法进行降维。然后通过欠采样的方法,分别从PCA mix降维后的数据和PCA降维后的数据中抽取样本进行实验。其中,KDDCUP99数据集抽取2 431个正样本作为训练样本,再抽取2 371个正样本作为测试样本中的正样本,2 380个负样本作为测试样本中的负样本;NSL-KDD数据集抽取2 357个正样本作为训练样本,再抽取2 339个正样本作为测试样本中的正样本,2 345个负样本作为测试样本中的负样本;UNSW-NB15数据集抽取2 405个正样本作为训练样本,再抽取2 387个正样本作为测试样本中的正样本,2 357个负样本作为测试样本中的负样本。
本文采用的单类分类算法,在训练模型时仅需选择一个类型的样本进行训练,样本类型并不强制。所以,实验选择的是正样本作为训练样本。
3.2 度量方法
对于入侵检测方法的学习器的泛化能力的评估,通常使用错误率、精度、P-R曲线、ROC曲线、AUC图等方法进行评估。本文实验中我们使用混淆矩阵、P-R曲线和ROC曲线对算法结果进行评估。
3.2.1混淆矩阵
混淆矩阵是统计真实标记和预测结果的组合。当真实标记为正样本时,且预测出来也是正样本时,叫作真正例,用TP表示这类情形的样本个数,当预测结果为负样本时,叫作假反例,用FN表示这类情形的样本个数;当真实标记为负样本时,且预测出来也是负样本时,叫作真反例,用TN表示这类情形的样本个数,当预测结果为正样本时,叫作假正例,用FP表示这类情形的样本个数。其形式如表2所示。

表2 混淆矩阵
这四种情形的样本个数加起来的总和为样本总数。通过混淆矩阵,可以计算出该分类器的精确率P、召回率R、准确率Accuracy等一系列比较标准。
(10)
(11)
(12)
3.2.2P-R曲线
P是指查准率,R是指查全率,横轴是查全率,纵轴是查准率。P=TP/(TP+FP),R=TP/(TP+FN)。通过学习器对测试样本的预测结果与实际结果进行对比,可将对比结果分为四类:TP、FN、FP、TN。通过不同的学习器的P-R曲线进行对比,可根据是否被“包住”,就能判断出哪一个学习器的学习效果好。若两者交叉,可通过对比由平衡点转化来的F1值来判断。F1值越高,效果越好。
(13)
3.2.3ROC曲线
ROC(Receiver Operating Characteristic)曲线的横轴是假正例率、纵轴是真正例率。假正例率=TP/(TP+FN),真正例率=FP/(FP+TN)。通过不同的学习器的ROC曲线进行对比,可根据是否被“包住”,就能判断出哪一个学习器的学习效果好。若两者交叉,便难以分辨。但可以通过比较ROC曲线下的面积AUC来判断优劣。
4 实 验
本实验采用2.6 GHz的CPU、4.0 GB的RAM、装有Window 7系统的电脑配置。使用R软件编写代码,将KDDCUP99的数据集作为实验数据,使用R语言实现了PCA mix降维后的单类分类KNN均值算法,同时对比了PCA mix降维后的OCSVM算法。
4.1 参数取值
根据PCA mix降维后的散点的分布图,发现维度降到15以内的各个散点分布图的差别不大,所以主要的维度取值确定权在PCA方法中。再根据PCA降维后的训练样本的组成的重要性占比对比,训练样本在组成数为12时,KDDCUP99数据集的重要性占比已经达到了71.124 721%,NSL-KDD数据集的重要性占比已经达到了70.244 561%,UNSW-NB15数据集的重要性占比已经达到了100%,如表3所示。最终综合三个数据集的PCA mix和PCA的情况,选定降维的维度为12。

表3 PCA降维后的组成部分的重要性占比对比
取不同的k值,如k=3,5,7,…,19,通过对比它们的F1值的情况,最终选定在单类分类KNN均值算法中的k取5时,分类效果最好。
4.2 实验数据
4.2.1KDDCup99数据集
KDDCUP99数据集是在第五届知识发现和数据挖掘国际会议KDD-99联合举办的第三届国际知识发现和数据挖掘工具竞赛所使用的数据集,含有模拟美国军事网络环境中的各种入侵[29]。整个KDDCup99数据集分为有标识的训练数据集和无标识的测试数据集。KDDCup99数据集的训练数据集有4 898 461个,总共可被分为两大种类型:正常和攻击。其中,攻击又可被分为4种类型的攻击:DOS、Probe、R2L、U2R。
本文选取原本训练数据集的10%,即kddcup.data_10_percent文件作为实验数据集。本数据集属于高维混合数据集。有41个特征属性,其中有32个连续型特征,9个离散型特征。此外,同时包含了原数据集的各种攻击类型:4种大攻击类别和22种小攻击类别。在整个训练数据中,正常的数据约为19.85%,剩下的都为攻击数据,攻击数据与正常数据的相差比例高达近4 ∶1,数据极其不平衡,并且在攻击的数据中,各种攻击类型的数据比例也极为不平衡,具体情况如表4所示。

表4 KDDCUP99数据集
4.2.2NSL-KDD数据集
KDDCUP99数据集有不少缺陷,如:其训练集的攻击数据包中没有生存时间值(TTL)为126和253,不符合现实的网络情况;攻击类型不全面,无法代表现实的网络环境;数据集中数据冗余,会影响分类器的分类结果。
NSL-KDD数据集的提出,解决了KDDCUP99数据集存在的一些问题:对正负样本的比例进行了合适的选择;训练集和测试集的样本数量更加合理;除去了KDDCUP99数据集中的冗余数据。
虽然NSL-KDD数据集仍不能完美地反映现实的网络环境,但在缺少基于网络的公开的入侵检测数据集的情况下,其还是能够作为一个帮助研究人员对比不同的入侵检测方法的有效的基准数据集。
本文选取原本数据集处理过后的KDDTrain+文件作为实验数据集,属于高维混合数据集。有45个特征属性,其中有40个连续型特征,5个离散型特征。此外,同时包含了原数据集的各种攻击类型(4大攻击类别)。在整个训练数据中,正常的数据约为53.45%,剩下的都为攻击数据,攻击数据与正常数据的相差较不平衡,且在攻击的数据中,各种攻击类型的数据比例极为不平衡,具体情况如表5所示。

表5 NSL-KDD数据集
4.2.3UNSW-NB15数据集
UNSW-NB15数据集是在2015年由澳大利亚网络安全中心(ACCS)模拟显示网络环境生成的一个新的数据集,数据集中包括现代正常的数据和9大类攻击的流量数据。UNSW-NB15数据集包含了新型的隐蔽攻击方式,能完全代表现实网络环境下的真实情况。
UNSW-NB15数据集的训练数据集有82 332个,总共可被分为两大种类型:正常和攻击。其中,攻击又可被分为9种类型的攻击:溢出攻击(Fuzzers)、渗透攻击(Analysis)、后门攻击(Backdoors)、拒绝服务攻击(DOS)、漏洞攻击(Exploits)、哈希函数针对攻击(Generis)、探针攻击(Reconnaissance)、软件漏洞攻击(Shellcode)、蠕虫攻击(Worms)。
本文选取原本数据集处理过后的UNSW-NB15 Training Set文件作为实验数据集,属于高维混合数据集,有45个特征属性,其中有40个连续型特征,5个离散型特征。此外,同时包含了原数据集的各种攻击类型(9大攻击类别)。在整个训练数据中,正常的数据约为44.94%,剩下的都为攻击数据,攻击数据与正常数据的相差较不平衡,且在攻击的数据中,各种攻击类型的数据比例极为不平衡,具体情况如表6所示。

表6 UNSW-NB15数据集
4.3 实验结果
4.3.1对比算法
本文改进算法是单类分类方法下的改进算法,近年来,国内在入侵检测领域的单类分类方法仅有OCSVM算法,所以使用OCSVM算法与本文改进算法作对比。为对比PCA mix降维后的OCSVM算法和本文改进算法的分类效果,可以通过对比它们的混淆矩阵、准确率、ROC曲线和AUC值来得出结论。
其混淆矩阵的对比结果如表7所示,准确率对比结果如表8所示。在PCA mix降维之后,三个数据集的单类分类KNN均值算法的分类效果都远好于OCSVM算法:KDDCUP99数据集的准确率相差4.33%,NSL-KDD数据集的准确率相差2.94%,UNSW-NB15数据集的准确率相差16.1%。

表7 PCA mix降维后算法的混淆矩阵对比结果

表8 PCA mix降维后算法的准确率对比(%)
本文使用Bootstrap方法确定决策边界,取α值从0.01~0.99总共99个决策边界,每个决策边界都会有不同的预测结果。根据这一特点,能够画出P-R曲线,并算出F1值。
通过计算F1值,比较出最好的取值,并选用这个值绘制该算法最佳的ROC曲线和计算其AUC值。
根据F1值,可以得到混淆矩阵,画出PCA mix降维后的单类分类KNN均值算法的ROC曲线,并与PCA mix降维后的OCSVM算法的ROC曲线作对比,如图6所示。虚线代表的是PCA mix降维后的单类分类KNN均值算法,直线代表的是PCA mix降维后的OCSVM算法,三个数据集的ROC曲线对比图中,虚线都“包括了”直线,说明PCA mix降维后的单类分类KNN均值算法的分类效果更好。

(a) KDDCUP99

(b) NSL-KDD

(c) UNSW-NB15图6 PCA mix降维后的两种算法的ROC曲线对比
同样,通过图7的AUC值对比,也能得出PCA mix降维后的单类分类KNN均值算法的分类效果远好于PCA mix降维后的OCSVM算法。

图7 PCA mix降维后的两种算法的AUC值对比
根据两种算法的混淆矩阵、准确率、ROC曲线和AUC值的对比结果,可得出本文改进的单类分类KNN均值算法的分类效果远好于OCSVM算法。
4.3.2对比降维方法
对比PCA降维后的单类分类KNN均值算法和PCA mix降维后的单类分类KNN均值算法的散点分布图、混淆矩阵、准确率、P-R曲线、F1值、ROC曲线和AUC值。得出PCA mix降维后的单类分类KNN均值算法比PCA降维后的单类分类KNN均值算法的分类效果好。
单类分类KNN均值算法两种降维方法的散点分布如图8所示。为方便查看,本散点图每种样本仅选用了近500个,完全按照原本的抽取比例进行抽取。用乘号代表负样本到训练样本的距离,用三角形代表正样本到训练样本的距离。可以看出,PCA降维后的数据分类过于紧凑,并且没有完全分类好;而PCA mix降维后的数据分类比较宽松。PCA mix降维后的数据明显比未降维时的数据的分类效果更好。特别是UNSW-NB15数据集的散点分布情况,更具有对比效果。

(a) KDDCUP99:PCA降维后

(b) KDDCUP99:PCA mix降维后

(c) NSL-KDD:PCA降维后

(d) NSL-KDD:PCA mix降维后

(e) UNSW-NB15: PCA 降维后

(f) UNSW-NB15: PCA mix降维后图8 两种降维方法的单类分类KNN均值的散点分布
这两种处理方法的混淆矩阵如表9所示,准确率对比如表10所示,在同样使用单类分类KNN均值算法的情况下,PCA mix降维后的单类分类KNN均值算法的分类效果都远好于PCA降维后的单类分类KNN均值算法:KDDCUP99数据集的准确率相差0.65%,NSL-KDD数据集的准确率没有差别,UNSW-NB15数据集的准确率相差29.22%。

表9 单类分类KNN均值算法的混淆矩阵对比结果

续表9

表10 单类分类KNN均值算法的准确率对比(%)
如图9所示,用线段代表PCA mix降维后的P-R曲线,用直线代表PCA降维后的P-R曲线。可以看出三个数据集的P-R曲线都彼此相交,并不能够直观地确定哪种降维方法更好,但可以通过对比它们的F1值来比较两种降维方法的分类效果。

(a) KDDCUP99
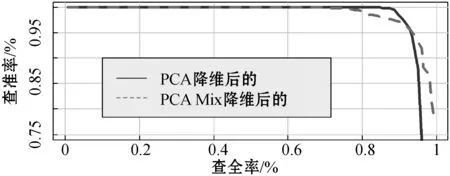
(b) NSL-KDD

(c) UNSW-NB15图9 两种降维方法单类分类KNN均值算法的P-R曲线对比
从表11可看出,三个数据集的PCA mix降维后的F1值的最大值都要略大于PCA降维后的F1值的最大值:KDDCUP99数据集的F1值相差0.682 478%,NSL-KDD数据集的F1值相差0.076 259%,UNSW-NB15数据集的F1值相差21.415 414%,所以PCA mix的降维方法略佳。

表11 单类分类KNN均值算法的F1值对比
再对比图10中ROC曲线,用点代表PCA mix降维后的单类分类KNN均值算法,用线段代表PCA降维后的单类分类KNN均值算法。图10中的两个曲线呈现交叉的状态,无法直观地对比两者的分类效果,所以通过对比AUC值来得出结论。

(a) KDDCUP99

(b) NSL-KDD

(c) UNSW-NB15图10 两种降维方法的单类分类KNN均值的ROC对比
根据表12的AUC值的对比,发现三个数据集的PCA mix降维后的算法的分类效果都要好于PCA降维后的算法:KDDCUP99数据集的AUC值相差0.655 4%,NSL-KDD数据集的AUC值相差0.001 7%,UNSW-NB15数据集的AUC值相差31.468 24%。

表12 两种降维方法的单类分类KNN均值的AUC值对比
5 结 语
本文采用了OCSVM和单类分类KNN均值两种算法对三个入侵检测系统数据集进行处理,并采用PCA mix与PCA两种降维方法分别对数据集进行降维。最终得到的结果证明PCA mix的降维效果要好于PCA的降维效果,本文改进的单类分类KNN均值算法优于OCSVM算法。
本文的改进算法能有效地处理具有高维、混合以及不平衡等特性的入侵检测数据,弥补了传统的机器学习算法的缺陷,为进一步实现对现实网络的实时监控提供了阶梯。并且本文的改进算法在UNSW-NB15数据集效果最好,说明本文的改进算法更适应于当代的网络情况。
然而,本文改进算法的计算复杂度并未降低,未来将进一步改进算法以降低计算复杂度,使其达到能够对现实的网络情况实时监控。
猜你喜欢
汽车实用技术(2022年4期)2022-03-07
海峡姐妹(2019年12期)2020-01-14
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
读与写·教育教学版(2017年10期)2017-11-10
发明与创新·中学生(2017年5期)2017-05-12
科技视界(2016年16期)2016-06-29
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
