
基于深度学习PyTorch 框架下YOLOv3 的交通信号灯检测
2022-07-02 00:49李蒋
汽车电器 2022年6期
李 蒋
(苏州建设交通高等职业技术学校, 江苏 苏州 215100)
1 引言
2021年9月22日, 华为发布 《智能世界2030》 报告, 多维探索了未来10年的智能化发展趋势。 报告中明确预测,到2030年全球电动汽车占所销售汽车总量的比例将会达到50%, 中国自动驾驶新车渗透率将会达到20%, 整车算力超过5000TOPS, 智能汽车网联化 (C-V2X) 渗透率预计会达到60%。 中国国家发展改革委员会等11个部委于2020年2月联合印发了 《智能汽车创新发展战略》, 提出到2025年实现有条件自动驾驶的智能汽车达到规模化生产, 实现高度自动驾驶的智能汽车在特定环境下市场化应用, 到2050年全面建成中国标准智能汽车体系。
在这样的时代背景下, 中国自动驾驶汽车技术领域的研究开始快车模式。 在整个自动驾驶技术研究领域中, 复杂环境中目标物体的识别和判别一直以来都属于一项高难度的挑战, 也是亟需要解决的重点任务之一。 本文基于YOLO算法对实景图像进行目标识别和检测, 以期可以进一步在视频流中进行交通标志、 行人、 汽车等物体的识别和检测, 不仅是解决一个识别和检测的问题, 更是提出一种解决问题的思路和方法。
2 目标检测经典方法概述
目前, 在自动驾驶技术研究领域比较流行的目标检测算法, 主要是CNN (卷积神经网络)、 R-CNN、 faster RCNN、 SSD和YOLO等。 因为设计这些算法的初衷都是为了格物致知, 所以每种算法都有自己十分突出的优点, 但同时也都存在一些不可回避的缺点, 笔者简单介绍几种典型算法的优缺点。
2.1 CNN卷积神经网络
CNN是从视觉皮层的生物学上获得启发, 首先将图像作为输入传递到网络, 然后通过各种卷积层和池化层的处理, 最后以对象类别的形式获得输出。 对于每个输入对象,会得到一个相应类别作为输出, 因此可以使用这种技术来检测图像中的各种对象。 CNN网络结构如图1所示。
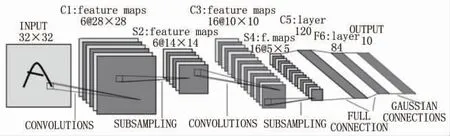
图1 CNN网络结构
使用这种方法会面临的问题在于图像中的对象可以具有不同的宽高比和空间位置。 例如, 在某些情况下, 对象可能覆盖了大部分图像, 而在其他情况下, 对象可能只覆盖图像的一小部分, 并且对象的形状也可能不同。 为了精准判断, 需要划分大量的区域进行采集、 识别和判定, 这会生成大量的数据, 而且要达到准确判定目标需要花费大量的计算时间。
2.2 R-CNN
R-CNN算法不是在大量区域上工作, 而是在图像中提出了一堆方框, 并检查这些方框中是否包含任何对象。 RCNN使用选择性搜索从图像中提取这些框。 R-CNN网络结构如图2所示。

图2 R-CNN网络结构
R-CNN模型存在的主要问题是不能快速定位物体, 原因是模型算法对于单元格产生候选框过多, 且易重复, 而每一次选择都需要代入卷积神经网络模型加以识别, 得出物体的预测置信度和具体坐标位置, 这一步骤在单一图片的处理上会消耗极多的时间。 这使得R-CNN在面对大量数据集时几乎不可能被应用。
2.3 Faster R-CNN
Faster R-CNN使用 “区域提议网络”, 即RPN。 RPN将图像特征映射作为输入, 并生成一组提议对象, 每个对象提议都以对象分数作为输出。Faster R-CNN网络结构如图3所示。
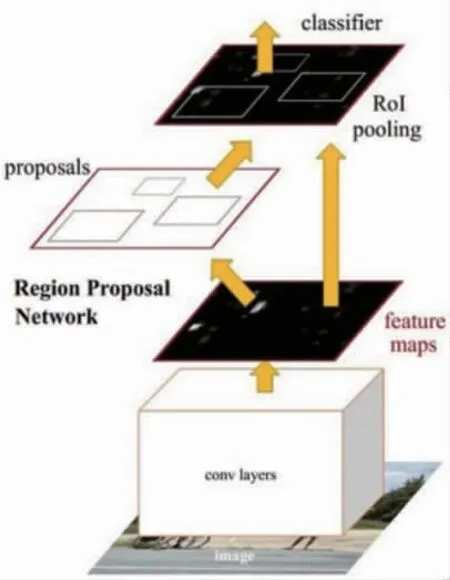
图3 Faster R-CNN网络结构
但是所有对象检测算法都使用区域来识别对象, 且网络不会一次查看完整图像, 而是按顺序关注图像的某些部分, 这样会带来两个复杂性的问题: ①该算法需要多次通过单个图像来提取到所有对象; ②由于不是端到端的算法, 不同的系统一个接一个地工作, 整体系统的识别性能对于先前系统的表现效果有较大依赖, 对最终识别结果也有较大影响。
3 相关介绍
3.1 PyTorch
PyTorch 是一个开源的深度学习框架, 该框架由Facebook人工智能研究院的Torch7团队开发, 它的底层基于Torch, 但实现与运用全部是由python来完成。 该框架主要用于人工智能领域的科学研究与应用开发。
PyTroch最主要的功能有两个: 一是拥有GPU张量, 该张量可以通过GPU加速, 达到在短时间内处理大数据的要求; 二是支持动态神经网络, 可逐层对神经网络进行修改,并且神经网络具备自动求导的功能。 深度学习框架PyTroch如图4所示。

图4 深度学习框架PyTroch
3.2 YOLO
YOLO (全称为You Only Look Once, 译为: 你只看一次), 是一个经典的one-stage的算法, 该算法与two-stage的算法相比, 减少或简化了预选的步骤, 直接把检测问题转换为回归问题, 只需要一个CNN网络就可以了。 YOLO最为核心的优势就是速度非常快, 非常适合做实时的检测识别任务, 应用在自动驾驶技师领域, 尤其是现在基于摄像头的视频处理就需要很快的速度。 当然它同样存在缺点, 因为少了预选的步骤, 在检测识别的品质上通常不会有预期的那么好。 YOLOv3与其他目标检测算法对比如图5所示。
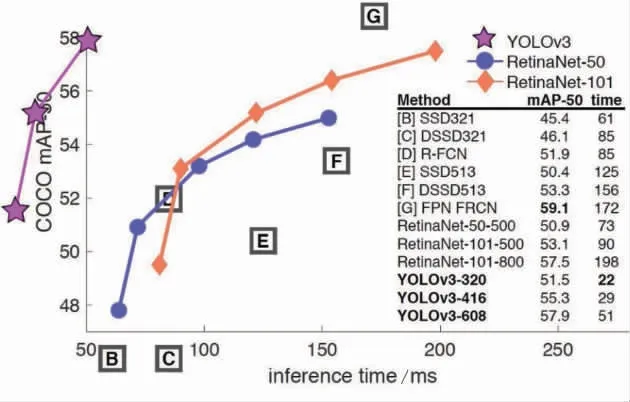
图5 YOLOv3与其他目标检测算法对比
YOLOv3在当年和其他算法相比, 无论是速度还是mAP(mean Average Precision, 综合衡量检测效果) 值都远远优于其他算法。 YOLO目前已经有5个版本, v3版本是其中最经典的一个版本, 应用率也较为广泛。 因此, 本文主要应用YOLOv3版本进行目标检测。
4 YOLOv3的版本改进及运作过程
4.1 v3版本改进
YOLOv3和之前的版本相比, 整体的网络架构没有改变, 但YOLOv3相较之前版本有很大的提升, 其中最大的改进有以下4点。
1) 改进网络结构, YOLOv3仅使用卷积层, 使其成为一个全卷积网络。 作者提出一个新的特征提取网络——Darknet-53, 它包含53个卷积层, 每个后面都跟随着batch normalization层和leaky ReLU层, 没有池化层, 使用步幅为2的卷积层替代池化层进行特征图的降采样过程, 这样可以有效阻止由于池化层导致的低层级特征的损失。 Darknet-53基本网络结构如图6所示。
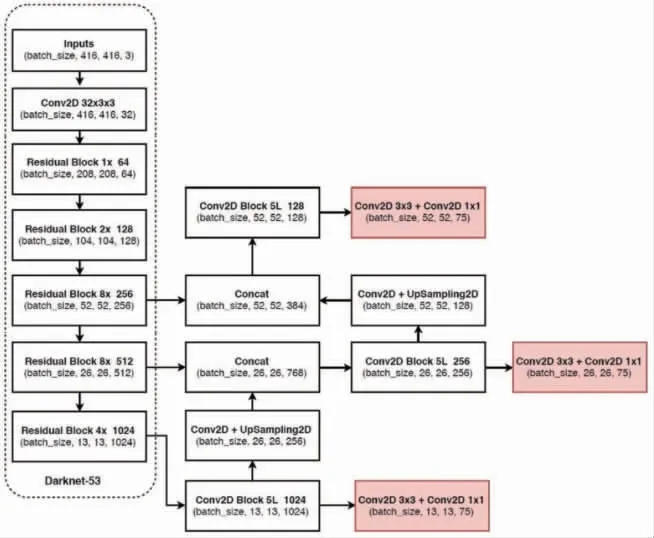
图6 Darknet-53基本网络结构
2) 特征做得更加的细致, 融入多尺度特征图信息来预测不同规格的物体, 在多个尺度的融合特征图上分别独立做检测。 由于YOLO是针对于目标识别速度的算法, 使其更加适合小目标检测。
3) Anchor (先验框) 更加丰富, 为了能够全面检测到不同大小的物体, 设计了3种scale, 每种3个规格, 一共9种, 其初始值依旧由K-means聚类算法产生。 YOLOv3先验框种类如图7所示。

图7 YOLOv3先验框种类
4) YOLOv3一方面采用全卷积 (YOLOv2中采用池化层做特征图的下采样, v3中采用卷积层来实现), 另一方面引入残差 (Residual) 结构, Res结构可以很好地控制梯度的传播, 避免出现梯度消失或者爆炸等不利于训练的情形。这使得训练深层网络难度大大减小, 因此才可以将网络做到53层, 精度提升比较明显。 此外, softmax (归一化指数函数) 的改进, 可以预测多标签任务。
4.2 YOLOv3运作过程
YOLOv3实现原理: 通过输入416×416像素的图片, 将图片划分成13×13、 26×26、 52×52大小的网格图, 通过网络去判断我们需要识别的类别的中心点分别在哪一个网格的置信度比较大, 结合3种特征图输出的置信度, 只保留置信度最大的框, 最终通过自己认为设置的先验框和真实类别的中心点反算出真实框的位置。
5 基于YOLOv3训练自己的数据与任务
5.1 数据信息标注
首先安装labelme工具, 对于自己的数据集进行打标签工作。 如下:

安装完成, 运行软件, 把自己需要训练的数据集打上标签。 训练的数据越多, 最终目标检测的效果可能越好。虽然我们使用了迁移学习, 但一般也需要上千张图片才可以达到一个比较理想的结果, 根据自己的需要调整标注训练集。 数据集打标签如图8所示。
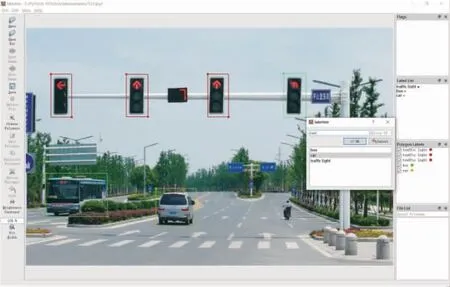
图8 数据集打标签
标注完成, 生成.json文件, 但是该文件还不可以直接使用, 需要转换格式。
5.2 生成模型所需配置文件
利用Git工具编写create_custom_model.sh 文档。 因为本文研究的只是一个三分类任务, 所以参数定为3, 运行后会自动生成一个YOLOv3-custom.cfg配置文件。 修改.sh配置文档如图9所示。

图9 修改.sh配置文档
5.3 json格式转换成YOLOv3所需输入
因为labelme中生成标签的格式是X1、 X2、 Y1、 Y2实际坐标值, 而YOLOv3中需要的格式是中心点的X1、 Y1,以及W和H值, 并且数值为图片中的相对位置 (取值范围0-1)。 因此, 需要对标签中的坐标值进行转换。 利用相关代码对坐标格式进行转换, 转换后形成YOLOv3所需的TXT文件。
5.4 完成输入数据准备工作
首先, 我们还需要完善训练过程中数据与标签的路径。转换后的标签文件文件名要和图像的文件名完全一致, 文件分别放在不同的相应文件夹中。
接下来, 把.names文件中的类别改成自己需要做的类别名称, 例如person、 car、 traffic light等。 然后, 修改train.txt和valid.txt中的文件对应的路径。 最后, 修改custom.data文件中的配置。
5.5 运行参数配置修改
训练代码train.py需要设置运行参数如下:--model_def config/YOLOv3-custom.cfg--data_config config/custom.data--pretrained_weights weights/darknet53.conv.74 #如果需要在别人预训练权重基础上进行迁移学习, 则需要配置该项运行参数 (不进行迁移学习则需要上万张图片的数据量)。
5.6 训练模型并测试效果
本文在实验中利用自己标注的1000张数据集进行训练,由于数据集只做了三分类, 标注工作量尚可。 训练过程中采用了darknet53预训练模型进行迁移学习, 减少由于数据量较少造成的训练结果不理想。 利用训练好的模型进行目标检测, 通过对100张图片进行测试, 发现无论mAP值还是检测速度都比较满意, 实际目标检测结果如图10所示。

图10 实际目标检测结果
6 总结
本文利用YOLOv3进行目标检测与识别训练, 主要针对交通信号灯进行试验。 该算法也可运用在视频流中的目标检测, 并且取得了较高的检测准确率和检测速度, 基本满足了图片检测和视频检测的预期需求。 同时, 该方法不局限于交通监控视频中的车辆检测, 也可以被应用于其他领域的目标检测与识别, 具有很好的应用场景兼容性。
但是在研究过程中, 我们尝试将该算法移植到ubantu系统上, 试图利用嵌入式系统进行实时摄像头的目标检测时, 遇到了一些软件配置上的问题未能突破。 此外, 该检测识别方法在光照强度不足时, 例如雨天、 夜间无照明路段等恶劣条件下可能存在误判的情况, 还需要进一步对算法进行优化。 同行研究试验时可以选择YOLO在2020年推出的v4和v5版本进行尝试, 期盼更多研究成果大家共享。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
中国新通信(2017年9期)2017-05-27
科学与财富(2016年15期)2016-11-24
科技视界(2016年18期)2016-11-03
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
软科学(2014年8期)2015-01-20
