
IMUT-MC:一个针对蒙古语语音识别的语音语料库
2022-07-03 14:05刘志强马志强张晓旭宝财吉拉呼谢秀兰朱方圆
中国科学数据(中英文网络版) 2022年2期
刘志强,马志强,2*,张晓旭,宝财吉拉呼,谢秀兰,朱方圆
1.内蒙古工业大学数据科学与应用学院,呼和浩特 010000
2.内蒙古自治区基于大数据的软件服务工程技术研究中心,呼和浩特 010000
引言
语音识别(Automatic speech recognition,ASR),尤其是大词汇量连续语音识别,是机器学习领域的重要课题。长期以来,隐马尔科夫高斯混合模型(GMM-HMM)[1]一直是主流的语音识别模型。随着深度神经网络的发展,深度神经网络隐马尔科夫模型(DNN-HMM)[2]和端到端模型[3-5]已经取得超越GMM-HMM的性能。这些语音识别模型通常需要大量高质量的语音数据来达到优异的性能。近年来,英语、汉语等大语种凭借丰富的语料资源在语音识别的不同任务中取得巨大的进步,其中一个重要原因是各种规模的公开数据集为语音识别研究人员提供开放的数据平台,如Ted-Lium[6]、Librispeech[7]、THCHS-30[8]和AISHELL[9]等。然而,对于许多小语种语言的语音识别,没有大规模高质量的标注语音数据已经成为阻碍它们进一步发展的关键因素。
蒙古语作为少数民族语言,其使用人群分布辽阔,收集标注语音数据困难,导致没有公开的大规模蒙古语语音语料库为广大研究人员提供实验支撑,蒙古语语音识别研究受到了极大的限制。在此之前,已有很多研究者致力于蒙古语语音识别研究[10-11]。但是,在没有普遍接受的蒙古语语音数据集的情形下,研究者都在其内部数据上进行实验并记录结果。这阻碍了实验复现和性能基准测试,从而限制了蒙古语语音识别进一步发展。为解决这个问题,课题组在国家自然科学基金(62166029,61762070)和内蒙古自然科学基金(2019MS06004)的资助下构建了蒙古语语音语料库IMUT-MC,其中包含417位说话人录制的约212小时的阅读语音,所有说话人均为能够熟练使用蒙古语交流的蒙古族学生。
IMUT-MC语料库主要是为蒙古语语音识别研究构建,共包含5期阅读语音数据集。每一期数据集构建目的不同,可用于语音识别任务下各种子任务研究,如语音表示[12]、声学建模[13]和说话人自适应[14]等相关研究。IMUT-MC也可以用于其他与语音相关的任务,如语音合成[15]和语音翻译[16]。课题组期望IMUT-MC成为语音识别研究社区的宝贵资源,并成为蒙古语语音识别研究的基线数据集。IMUT-MC语料库不仅致力于推进蒙古语语音识别研究,而且希望促进蒙古语在语音应用中的发展和使用,如消息听写、语音搜索、语音命令和其他语音控制智能设备。
1 数据采集和处理方法
IMUT-MC是一个单通道蒙古语语音语料库。语音话语是在密闭录音室内通过高保真的麦克风录制,采样为16Khz,16-bit WAV格式。IMUT-MC由约8.43万句语音话语组成约212小时,其中包含5期语音数据集,分别是IMUT-MC1、IMUT-MC2、IMUT-MC3、IMUT-MC4和IMUT-MC5。IMUT-MC1由8名录音人员按照不同方式朗读1255句录音文本录制而成,包括1人录制的1255句语音话语和7人随机录制的1255句语音话语,共2510句语音话语,总时长为1.8小时;IMUTMC2由99名录音人员朗读相同的200句录音文本录制而成,共包含1.98万句语音话语,总时长为23.5小时;IMUT-MC3是由111名录音人员朗读相同的200句录音文本录制而成,共包含2.22万句语音话语,总时长为40.8小时。不同于前三期数据集,IMUT-MC4是由100名录音人员朗读固定的200句录音文本录制而成。其中,100名录音人员分为5组,每20人朗读相同的200句录音文本进行录制,共包含2万句语音话语,总时长为69.74小时。IMUT-MC5与IMUT-MC4构建方式相同,共包含1.98万句语音话语,总时长为75.29小时。录制完成后,语音话语被处理成语音识别实验要求的格式,与转录文本一一对应。IMUT-MC语料库基本信息如表1所示。

表1 IMUT-MC语料库基本信息Table 1 Basic information of IMUT-MC corpus
2 数据样本描述
2.1 说话人信息
IMUT-MC共有417名说话人参与录制,说话人的性别、电话、年龄和生活地区被记录为元数据。参与录制的说话人都具备熟练使用蒙古语进行日常交流的能力,大多数来自蒙古族的在校大学生,年龄分布在18-25岁,并且性别比例平衡,分别为48%的男性和52%的女性。IMUT-MC语料库说话人具体信息如表2所示。

表2 IMUT-MC语料库说话人信息Table 2 Speaker information of IMUT-MC corpus
由于蒙古族在内蒙古自治区分布情况不同,导致课题组采集语料难度有所差异。每一位说话人的生活地区信息被记录,他们大多数来自通辽、赤峰、兴安盟和锡林郭勒盟等地区。不同地域的说话人具有当地口音特色,因此IMUT-MC也可用于蒙古语方言语音识别。同时行政分区编码也被加入语料的处理中,用于区分说话人的口音信息。IMUT-MC语料库说话人口音信息如表3所示。

表3 IMUT-MC语料库说话人口音信息Table 3 Voice information of speakers in IMUT-MC corpus
IMUT-MC语料库存在说话人重复情况。例如,一名说话人可能同时参与了IMUT-MC1、IMUT-MC2和IMUT-MC3的构建。据统计,参与数据集IMUT-MC1、IMUT-MC5构建的都是独立不重复的说话人,而数据集IMUT-MC2、IMUT-MC3和IMUT-MC4存在说话人重复情况。从图1可知,共有310名说话人参与IMUT-MC2、3、4期的录制,其中有143名是独立不重复的说话人。IMUT-MC2、3、4期数据集说话人重复具体信息如图1所示。
2.2 转录和词汇
IMUT-MC语料库包含5期语音数据集,每期数据集构建目的不同,其转录文本来源也不同。其中IMUT-MC1、IMUT-MC2、IMUT-MC3针对扩充蒙古语口语知识构建,而IMUT-MC4、IMUTMC5针对扩充更多的文本领域知识构建。IMUT-MC1从蒙古语教材《蒙古语会话手册》[17]摘选1255句文本进行录制;IMUT-MC2是在IMUT-MC1的基础上选用其中200句文本进行录制;IMUT-MC3从中国新闻网(蒙语版)摘选200句文本进行录制;IMUT-MC4从中国新闻网(蒙语版)中的时政、教育、体育、环境和经济等5个领域分别选取200句文本进行录制;IMUT-MC5从中国新闻网(蒙语版)中的人文、法律、科学、技术和饮食等5个领域分别选取200句文本进行录制。同时,本文分别从文本句子数、词数和平均词个数等方面对IMUT-MC的各期数据集的转录文本进行对比,转录文本信息具体情况如表4所示。

表4 IMUT-MC语料库转录文本信息Table 4 Transcription text information of IMUT-MC corpus
在转录文本的制作过程中,对原始蒙古语文本语料进行如下处理:(1)对转录文本手动过滤,消除敏感政治字眼、用户隐私、色情和暴力等不适当内容:(2)转录文本句子中的一些符号,如“、”、《、》、[、]、=等均被删除;(3)所有转录文本格式采用“UTF-8”编码。转录文本处理完成后,本文对IMUT-MC语料库各期数据集转录文本的蒙古语单词重合情况进行了统计。其中,IMUT-MC语料库各期数据集转录文本蒙古语单词重合情况如图2所示。IMUT-MC4和IMUT-MC5语音数据集各子领域转录文本蒙古语单词重合情况分别如图3和4所示。
2.3 发音词典
在IMUT-MC语料库中,IMUT-MC1、IMUT-MC2和IMUT-MC3针对传统蒙古语语音识别研究构建,其涵盖的蒙古语单词发音标注已经完成。而IMUT-MC4和IMUT-MC5针对端到端蒙古语语音识别研究构建,课题组尚未对其涵盖的蒙古语单词进行发音标注。IMUT-MC语料库的发音词典通过课题组蒙古族老师和同学对蒙古语单词的发音进行人工标注构建而成,识别基元为音素。其中,蒙古语单词的音素标注以拉丁文字母的形式表示,可直接用于传统蒙古语语音识别实验。目前,发音词典仅涵盖IMUT-MC1、IMUT-MC2和IMUT-MC3数据集中的蒙古语单词,共有2092个蒙古语单词的发音标注。未来,课题组会对发音词典进行扩充,完成IMUT-MC4、IMUT-MC5数据集中蒙古语单词的发音标注。发音词典扩充完成后将会第一时间更新。
3 数据质量控制和评估
3.1 数据质量控制
课题组对录制好的蒙古语语音话语逐条检查完成数据质量的控制,筛选内容如下:(1)剔除含有强噪声或电流声的语音话语;(2)剔除含有明显发音错误的语音话语;(3)剔除因文件意外损坏而不能播放的语音话语。
3.2 数据质量评估
为了证明IMUT-MC语料库在蒙古语语音识别研究中的可靠性,课题组在传统语音识别模型和端到端语音识别模型上完成蒙古语语音识别基线实验。首先构建基于GMM-HMM、DNN-HMM的传统语音识别模型和基于Transformer的端到端语音识别模型,然后使用IMUT-MC语料库完成所有模型的训练,最后以字错率(Character Error Rate,CER)、词错率(Word Error Rate,WER)和句错率(Sentence Error Rate,SER)等评价指标完成模型评估。由于发音词典没有涵盖IMUT-MC4、IMUT-MC5中的蒙古语单词,因此IMUT-MC4、IMUT-MC5在传统语音识别模型上的可靠性还未得到验证。后续数据集的可靠性实验结果将会在发音词典扩充完成后,第一时间公布。
3.2.1 实验设置
基于GMM-HMM的语音识别模型:课题组使用Kaldi实验平台[18]进行实验,选用音素作为建模单元构建GMM-HMM蒙古语声学模型,特征提取使用梅尔频谱倒谱系数(Mel Frequency Cepstral Coefficient,MFCC)技术。MFCC提取特征的参数设置如下:声学特征维度为40维,三角滤波器数量为40个,倒谱数量为40,低截止频率为40 Hz,高截止频率为-200 Hz。GMMHMM蒙古语声学模型训练时,HMM状态数(HMM-state)为2500。
基于DNN-HMM的语音识别模型:课题组使用Kaldi实验平台[18]进行实验,选用音素作为建模单元构建DNN-HMM蒙古语声学模型,特征提取使用梅尔频谱倒谱系数技术。蒙古语DNNHMM模型由输入层,隐藏层和输出层组成,每个隐藏层有850个节点,每个隐藏层在长度归一化后得到该隐藏层的激活输出,并作为下一层的输入。MFCC提取特征的参数设置如下:声学特征维度为40维,三角滤波器数量为40个,倒谱数量为40,低截止频率为40Hz,高截止频率为-200Hz。在DNN网络训练时,超参数设置如表5所示,HMM-state为2500个,Batch_size为512,初始学习率为0.0015,最终学习率为0.00015,不使用i-vector。解码使用集束搜索(Beam Search)算法,Beam-size为 11。

表5 DNN网络训练超参数设置Table 5 Hyper-parameter settings of DNN network training
基于Transformer的语音识别模型:课题组在Espnet[19]实验平台进行实验,使用单词作为建模单元来构建基于Transformer的蒙古语语音识别模型。基于Transformer的蒙古语语音识别模型,编码器具有12层,解码器具有6层,注意力头为4个,维度为256维。输入语音特征为80维FBank特征,在25 ms窗口内每10 ms计算一次基音,三角滤波器数量为80个,采样频率为16000Hz。模型训练时的超参数设置如表6所示,Batch_size为16,Dropout-rate为0.1,Mtlalpha为0.3,优化器使用noam优化器,解码使用集束搜索算法,Beam-size为10。

表6 基于Transformer的语音识别模型训练超参数设置Table 6 Hyper-parameter settings Transformer-based speech recognition model training
3.2.2 评价指标
在实验过程中,GMM-HMM和DNN-HMM蒙古语语音识别声学模型使用音素作为建模单元,选用CER作为评价指标来评价蒙古语声学模型对音素预测的准确率,选用WER作为评价指标来评价蒙古语语音识别的准确率。基于Transformer的端到端语音识别模型使用单词作为建模单元,选用WER和SER作为评价指标来评价蒙古语语音识别的准确率。自动评价指标包括:CER、WER和SER。评价指标的含义如下:
CER指已知标注文本与解码的结果,将解码结果中错误字符的累计个数除以标注中总的字符数,其公式为:
式中,s为替换错误的字符数,d为删除错误的字符数,i为删除错误的字符,n为总字符数。
WER指已知标注文本与解码的结果,将解码结果中错误词的累计个数除以标注中总的词数,其公式为:
式中,S为替换错误的词数,D为删除错误的词数,I为插入错误的词数,N为总词数。
SER指已知标注文本与解码结果,将句子识别错误的句子个数除以总的句子个数,其公式为:
式中, Sincorrect为识别错误的句子数,S为总句数。
3.2.3 实验结果
基于GMM-HMM和DNN-HMM的语音识别模型在IMUT-MC语料库上的实验结果如表7、8所示。从表中得知,数据集IMUT-MC1、IMUT-MC2在GMM-HMM和DNN-HMM上的字错率和词错率较高。对于IMUT-MC1,其数据量较小造成模型对于蒙古语语音数据的分布拟合不够充分,导致模型出现欠拟合现象。通过对IMUT-MC2中语音数据逐条检查,课题组发现该数据集中存在部分弱噪声数据。而基于GMM-HMM和DNN-HMM的传统语音识别模型对复杂场景下语音识别的适应效果不高,对IMUT-MC2的识别精度较低。同时,课题组剔除IMUT-MC2中的弱噪声数据组成IMUT-MC2修正数据集,重新进行传统蒙古语语音识别实验,在GMM-HMM、DNN-HMM上识别错误率CER分别下降66.3%和69.2%,WER分别下降62.6%和65.5%。
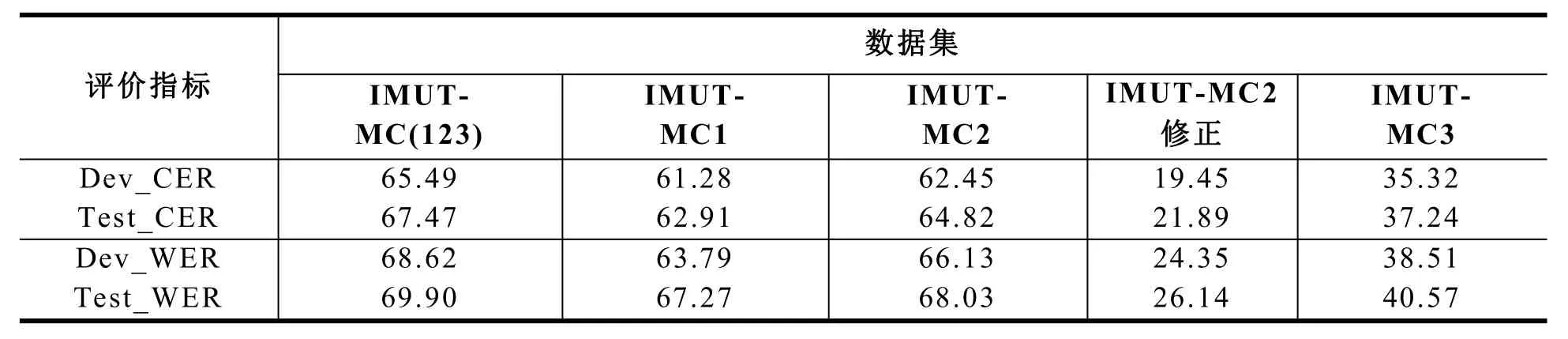
表7 基于GMM-HMM的语音识别模型基线实验结果Table 7 Baseline experimental results of speech recognition model based on GMM-HMM

表8 基于DNN-HMM的语音识别模型基线实验结果Table 8 Baseline experimental results of speech recognition model based on DNN-HMM
基于Transformer的语音识别模型在IMUT-MC语料库上的实验结果如表9所示。基于Transformer的端到端语音识别模型对复杂场景下语音识别的适应效果较好,对IMUT-MC2展现出不错的识别结果。但端到端语音识别模型是基于大数据量建模的概率模型,模型性能随着可用训练数据量的减少而显著下降。由于数据集IMUT-MC1数据量规模太小,在基于Transformer的语音识别模型下比GMM-HMM和DNN-HMM等传统语音识别模型下识别精度更差,WER和SER分别为77.40和80.47。数据集IMUT-MC4、IMUT-MC5在基于Transformer的语音识别模型上的识别错误率高于IMUT-MC2、IMUT-MC3,是由于它们的转录文本句子较长导致模型在推理预测时一定程度上受到长句依赖问题的影响。

表9 基于Transformer的语音识别模型基线实验结果Table 9 Baseline experimental results of Transformer-based speech recognition model
综上所述,IMUT-MC语料库是进行端到端蒙古语语音识别研究的可靠语料库。IMUT-MC1、IMUT-MC2和IMUT-MC3数据集是进行传统蒙古语语音识别研究的可靠数据集。IMUT-MC4、IMUT-MC5在传统蒙古语语音识别模型上的可靠性还未得到验证。后续数据集的可靠性实验结果将会在发音词典扩充完成后,第一时间公布。
4 数据使用方法和建议
IMUT-MC语料库中各期数据集使用方法如下:IMUT-MC1分为特定说话人文件夹跟非特定说话人文件夹。其中,特定说话人文件夹包含1名说话人录制的1255句语音话语,非特定说话人包含7名说话人随机录制1255句语音话语。对于其他数据集的语音数据存放形式,每个说话人作为一个文件夹,文件夹下面包含该说话人的语音数据文件,说话人的手机号作为说话人的唯一标识。每个说话人文件夹命名格式为“录音日期-手机号-地区编号-性别-年龄-录音序号”,语音文件命名格式为“转录文本编号-地区编码-年龄-录音序号”。对于IMUT-MC中的转录文本,编码格式为UTF-8,存放形式为txt文本文件。具体内容为“转录文本编号蒙古语文本”,每个蒙古语单词之间以空格符隔开,例如“00001243 ᠭᠠᠯᠭᠤᠯᠤᠮᠲᠠ ᠶᠢᠨᠳᠡᠭᠡᠭᠠᠯᠬᠤᠵᠤᠭᠠᠷᠬᠤᠶᠢᠪᠵᠠᠷᠲᠤᠬᠤᠭᠵᠤᠢᠮᠠᠭᠲᠠᠴᠡᠭᠷᠯᠡᠡᠭᠡᠡ”。
由于构建目的不同,IMUT-MC语料库中各期数据集具有不同的特点,可用于语音识别任务下各种子任务研究。根据各期数据集不同特点,本文给出的数据使用建议如下:数据集IMUT-MC1、IMUT-MC2和IMUT-MC3具有包含蒙古语单词量较少、转录文本句子较短和说话人个数较多的特点,不但可用于小词汇量蒙古语语音识别研究,而且可用于说话人自适应和说话人识别研究。数据集IMUT-MC4、IMUT-MC5具有包含蒙古语单词量较多、转录文本句子较长和说话人个数较多的特点,不但可用于大词汇量蒙古语语音识别研究和说话人自适应研究,而且可用于语音表示研究。IMUT-MC语料库也可以用于其他与语音相关的任务,如语音合成和语音翻译。
致谢
IMUT-MC语料库的构建获得内蒙古工业大学蒙古族同学的支持与帮助,在此表示由衷感谢!
数据作者分工职责
刘志强(1998—),男,山西省忻州人,在读硕士,研究方向为深度学习、语音识别。主要承担工作:数据论文撰写,数据处理和语料库的整理。
马志强(1972—),男,内蒙古自治区托克托县人,硕士,教授,研究方向为多媒体信息处理、自然语言处理、语音识别、对话生成等。主要承担工作:组织实施语料库的构建,语料库格式规范化。
张晓旭(1997—),男,山东省潍坊人,在读硕士,研究方向为深度学习、语音识别。主要承担工作:最终数据质量控制。
宝财吉拉呼(1983—),男,内蒙古自治区通辽人,博士,讲师,研究方向为机器学习、计算机视觉处理、生物信号处理、多媒体信息处理、自然语言处理等。主要承担工作:语料库格式规范化。
谢秀兰(1979—),女,内蒙古自治区兴安盟人,硕士,讲师,研究方向为蒙古语数据语义。主要承担工作:数据采集和处理。
朱方圆(1997—),男,山东省枣庄人,在读硕士,研究方向为深度学习、语音识别。主要承担工作:数据采集和处理。
猜你喜欢
江苏省社会主义学院学报(2022年2期)2022-05-07
外语学刊(2021年1期)2021-11-04
太原科技大学学报(2021年5期)2021-10-15
记者观察(2019年14期)2019-11-08
新一代(2017年15期)2018-01-12
——以乐山市为例
中共乐山市委党校学报(2017年5期)2017-10-21
支点(2015年11期)2015-11-16
外语教学理论与实践(2014年4期)2014-06-13
