
基于鲁棒稀疏PCA的工业异常检测
2022-07-09 03:04梁海玲白森李坚
科学技术与工程 2022年15期
梁海玲, 白森, 李坚
( 广西中烟工业有限责任公司技术中心, 广西 530001)
数据驱动的工业异常检测方法目前已被广泛应用于实际生产过程,其核心思想是基于历史数据构建离线监测模型并设计监控策略开展在线异常检测。在历史数据不包含异常数据的条件下,只能利用正常生产数据开展研究,即无监督学习模式。主元分析(principal component analysis, PCA)法是一种非常经典且流行的无监督特征提取方法,通过特征分解的方式,将含有冗余特征的高维原始数据投影到新的低维空间实现对冗余特征的筛选保留。在此基础上,通过设计监控统计量预测误差平方和(squared prediction error, SPE)和Hotelling-T2(简称“T2”),在线对数据进行实时异常检测。基于PCA的异常检测方法原理简单、操作方便且功能丰富,被普遍应用于工业无监督异常检测场景[1]。
PCA方法的一个前提假设是高维原始数据的各特征变量应满足高斯分布。因此,当原始数据集中存在异常数据偏离正常分布时,显然就不能满足这个要求。现代工业的整个生产工艺是由众多离散间歇的工序组成,生产数据由传感器采集,并经过数据总线传送给数据中心或者其他服务器予以处理,中间环节众多,生产数据难免会受到内部或外部环境的噪声影响而异常扰动,产生一些异常数据。如非封闭生产条件下的温湿度,传感器本身的随机扰动,以及数据存储、管理系统的突发性问题等。这些不确定性因素均会造成偏离正常高斯分布的强噪声以及离散的离群点等异常值。实验证明,PCA方法对异常值十分敏感,极易受到制约,导致工作性能严重退步。另外,PCA最终提取的主元本质上是原始数据各维度的线性组合,因此所有主元都是非稀疏的,即主元的各低维元素大部分非零。这就导致了每个主元很难与相应的数据特征相对应,具有较差的解释性,即很难将一个故障归结于某类数据特征。
鲁棒PCA技术可用于解决PCA的异常值敏感问题,其中研究最广泛的是L1-PCA方法。L1-PCA假设模型参数服从拉普拉斯分布,且将PCA技术中的L2范数改为L1范数求解,以便得到较好的鲁棒性[2]。这主要有两方面的考虑:一是服从拉普拉斯分布的随机变量,出现极端值即异常值的概率远大于正态分布;另一方面,L2范数本身对异常值敏感,会通过倾向于减少异常值误差的计算实现目标函数的最小化,造成训练结果的偏差,而L1范数则不存在这个问题。但是,由于L1范数中有绝对值,大大增加了计算复杂度,使得L1范数优化比传统L2范数优化在计算上要求更高[3]。文献[4-5]对优化算法进行了改进,以减小计算复杂度。针对主元解释性差问题,直接有效的方法是利用稀疏技术计算得到稀疏主元,使得主元在保存必要信息的同时获取最大解释方差。稀疏PCA(sparse PCA, SPCA)基本思路是在原有PCA基础上增加带有稀疏度的惩罚项或者稀疏约束条件,获取多个元素为零的负载向量,最终得到稀疏主元[6]。文献[7-9]对SPCA在计算复杂度、自适应以及罚函数等多个方面进行了改进。
为了同时增强PCA方法的鲁棒性和稀疏性,文献[10]提出了一种鲁棒稀疏PCA(robust sparse PCA, RSPCA)方法。与传统SPCA不同,RSPCA试图最大化数据的L1范数方差,并通过添加L0范数约束条件控制稀疏性。文献[11]设计了基于Lp-模的SPCA (LpSPCA),通过极大化带有稀疏正则项的Lp-模样本方差, 使得其在降维的同时保证了稀疏性和鲁棒性,并应用于人脸重构。实验证明,这些方法能够在一定程度上提升鲁棒性和稀疏性,但是并没有从根本上解决PCA的异常值敏感问题。另外,RSPCA并没有给定稀疏度的确定方式。稀疏度的增加意味着解释方差的减小。因此,为每个稀疏主元指定非零负载元素的数目是非常重要的。现对RSPCA方法进行改进,提出应用于工业异常检测的IRSPCA(improved robust sparse PCA)方法,在RSPCA基础上开发基于稀疏性准则的两阶段稀疏度选择技术,以及基于SPE统计量的异常值剔除策略;最后,通过一个数值案例和一个烟草烟支成品质量检测案例验证所提出IRSPCA方法的有效性。
1 主元分析异常检测方法
1.1 主元分析法
PCA本质是通过对原坐标轴进行平移和旋转变换,得到一个新的坐标轴。新坐标轴的第一主轴是原始数据能够投影得到最大方差的方向,也就是数据特征差异最大的方向。新坐标轴的其他主轴在与前一主轴标准正交的条件下,选取数据特征差异相对最大的方向。数据特征差异最大方向可以通过优化问题计算得到[12]。
输入数据矩阵为X=[x1,x2,…,xN]T∈RN×V,其中,N为样本个数,V为过程变量个数。首先需要标准化处理原始数据矩阵,避免因为各特征变量量纲的区别而淹没重要信息。设xi∈R1×V(i=1,2,…,N)为数据矩阵X的行向量,即一个样本向量。
原始数据特征差异的大小是通过投影数据的方差来表征的。将原始数据沿不同的向量进行投影,将得到不同的投影数据,那么投影数据的方差也是不同的,即所表征的信息大小也将发生改变。可以得到,数据投影的方差是与数据分散程度成正比的,方差越大,则意味着该方向所含差异信息量越大,反之则越小。这样,为了尽可能大地反映原始数据的信息,需要确定某个单位向量w,使得原始数据在其上的投影数据具有最大方差。首先考虑样本X与其在单位向量w上投影的最大化方差问题。
样本X在单位向量w上投影向量t的数学表达式为
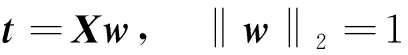
(1)
式(1)中:‖·‖2为向量或矩阵的L2范数。t的方差为
(2)
优化问题的数学表达式为
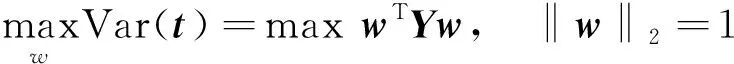
(3)
引入拉格朗日乘子求解,令λ为拉格朗日系数,得到拉格朗日方程为
L(w,λ)=wTYw-λ(wTw-1)
(4)
分别求L对w和λ的微分,并令其为0,即
(5)
这样w的解满足以下特征方程,即
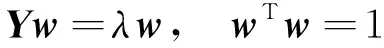
(6)
可以得到,w是Y的一个标准化特征向量,其所对应的特征值为λ。根据式(2)和式(6),得到Var(t)=λ。所以,若要使Var(t)最大,则向量w对应的特征值λ应该是所有特征值中的最大值。令λ1是矩阵Y的最大特征根,向量w1是λ1对应的特征向量,且w1模为1。w1作为第一主轴,其投影向量t1则为第一主元。
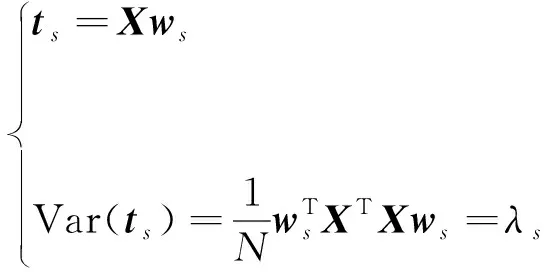
(7)
各主元存在以下关系:Var(t1)≥Var(t2)≥…≥Var(tV),即第一主元t1携带最大信息量,后续依次减小。
1.2 异常检测
原始数据空间经过PCA方法处理后,可以分解为两个正交子空间。取前p个主元的主元子空间W0=[w1,w2,…,wp],剩下主元构成残差子空间W1=[wp+1,wp+2,…,wV]。在线检测时,新的测量数据xnew=[x1,x2,…,xV]T投影到主元子空间W0,得
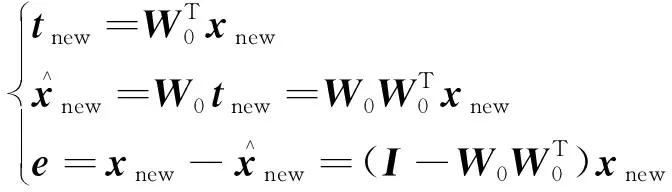
(8)
对工业过程运行状态的监控是通过T2和SPE两个多元统计量来实现的。T2统计量用于监测主元的波动情况,定义为

(9)
式(9)中:tnew=[t1,t2,…,tp]T为式(8)计算得到的主元得分向量,协方差矩阵Y的前p个特征值对应对角阵S的对角元素。
SPE统计量又称为Q统计量,用于度量当前测量数据与主元空间的偏离程度,定义为

(10)
当监测数据服从正态分布时,T2和SPE统计量的统计控制限分别定义为
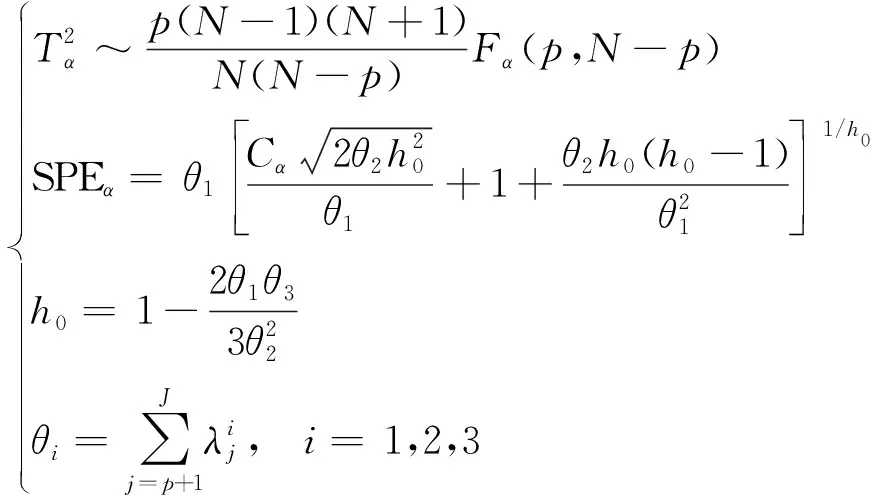
(11)
式(11)中:T2统计量服从F分布;α为显著性水平,Fα(p,N-p)为自由度为p、N-p条件下的F分布临界值,可直接从统计表查到。SPE统计量的Cα为标准正态分布在显著性水平α下的临界值。
基于PCA的异常检测过程,离线阶段通过原始数据计算得到PCA模型,并估计出T2和SPE两个多元统计量的控制限。在线阶段面对新的测量数据,计算T2和SPE的统计值,并且与控制限比较,若任一指标超出控制限,则表示异常发生。
1.3 RSPCA建模
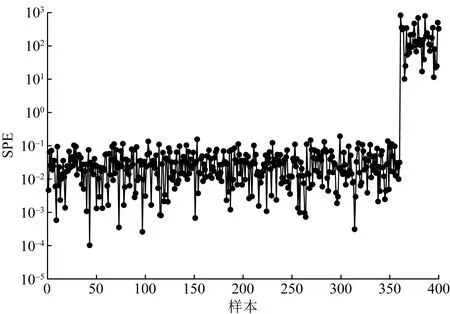
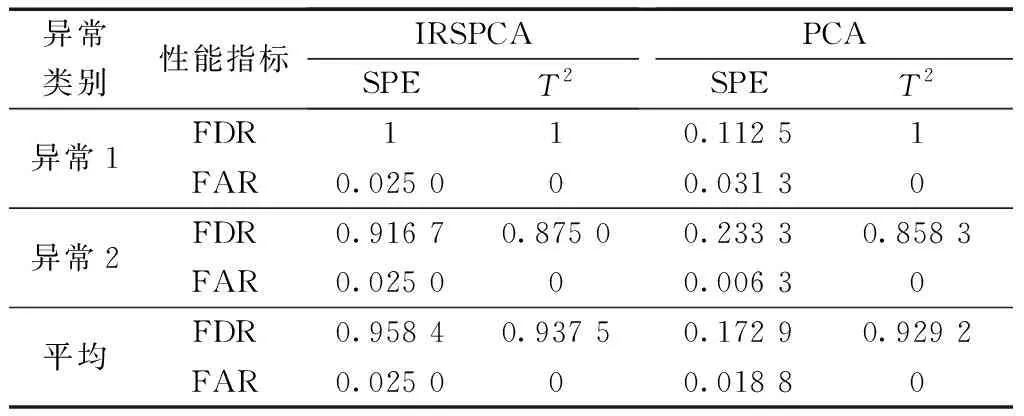
PCA方法的目标是要找到使得输入数据X方差最大化的p( (12) 式(12)中:k为稀疏度。 式(12)存在两个问题,一是计算得到的主元wi是随着p的预设值不同而改变的。二是当p> 1时,很难找到式子的全局最优解。为了便于求解,贪心搜索策略被用于将式(12)简化为一系列p= 1的优化问题。尽管通过连续贪心搜索得到的解可能并不是最优解,但能很好地近似最优解。当p= 1时,式(12)修改为 (13) 由于w的L0约束,式(13)是一个非确定性多项式难(nondeterministic polynominal-hard, NP-hard)问题[13]。为了便于计算,通常将非凸L0惩罚函数修改为凸L1惩罚函数,即‖w‖1 (14) 算法1 用于一个稀疏主元的求解算法RSPCA输入:原始数据矩阵X, 稀疏度k输出:稀疏度为k的主元向量w^1 初始化:w0=w0‖w0‖2,t=02 设置qi(t)=1,wT(t)xi≥0-1,wT(t)xi<0 3 u=[u1,u2,…,uV]T=∑Ni=1qi(t)xi4 σ=‖u‖中第k+1大的元素值5 令(a)+=a, a>00, a≤0 6 sgn(a)=1, a>00, a=0-1, a<0 7 β=[β1,β2,…,βV]T,其中,βi=sgn(ui)(ui-σ)+, i=1,2,…,V8 w(t+1)=β‖β‖2且t=t+19 判断是否收敛:如果w(t)≠w(t+1)转到步骤2,否则,继续执行下一行10 如果存在i满足wT(t)xi=0且sgn[wT(t)]sgn(xi)≠0,则令wT(t)=wT(t)+Δw‖wT(t)+Δw‖2 且返回步骤2,否则,继续执行下一行。Δw是一个各元素值都较小的非零随机向量11 设置w^=w(t),停止迭代 算法2 用于p个稀疏主元的求解算法RSPCA输入:原始数据矩阵X, 稀疏度k, 主元个数p>1输出:p个稀疏主元向量{wi}pi=11 设置w0=0∈RV,0是全0向量,定义X0={x0i=xi}Ni=12 forj=1,2,…,pdo3Xj={xji=xj-1i-wj-1(wTj-1xj-1i)}Ni=14使用算法1计算投影向量Xj对应的稀疏 主元向量wj5 end 通过算法2计算得到p个稀疏主元向量wj(j=1,2,…,p),则第j个主元的方差被定义[14]为 (15) 在PCA中,相应特征向量的特征值等于方差。类似地,λj可以看作是wj的伪特征值。 通过算法2可以得到RSPCA最优解的较好近似值,但是每个主元会随着稀疏度k的不同而改变,所以如何确定稀疏度的值应重点考虑。目前普遍采用一种序列化的方式来选择稀疏度k。例如,文献[13]提出了一种最小信息损失的方法选择稀疏度k。k以1为增量取值从1到变量个数V,从完全稀疏到非稀疏。k的取值被确定为一个数值,那么在该数值之后,任何进一步的增大k值均不会显著提高伪特征向量所捕获的方差总量。显然,这类方法以贪心的方式依次搜索k序列,得到的解往往是局部最优的。当监测变量较大时,得到的局部最优解将严重影响故障检测的效果。现从全局角度出发,提出一种新的稀疏度选择策略。 通过上节介绍可以得到,RSPCA[式(12)]本质上是在PCA-L1的基础上增加了L0范数的约束条件。RSPCA的解一方面应尽量与PCA-L1的解拟合,另一方面应具有尽量好的稀疏性。因此,设计稀疏度选择的目标函数即稀疏性准则(sparsity criterion, SC)函数为 (16) 式(16)中:Vα为RSPCA的调节方差;V0为PCA-L1的原始方差;Vα/V0表示拟合度;#0为RSPCA负载矩阵中零负载的总个数;#0/p2则表示稀疏性。λ用于控制拟合度和稀疏性之间的权衡。 在SC函数的基础上,采用两阶段求解方法计算稀疏度。第一阶段使用累积百分比方差(cumulative percent variance, CPV)方法[15]选择p个主元。在第二阶段,采用遗传算法(genetic algorithm, GA)求解最大化的稀疏性准则函数,为第一阶段计算得到的每一个主元分别指定一个k。 GA算法是一种功能强大的进化算法,已经在多个领域具有成功的应用[16]。GA本质是在解空间中不断随机搜索,在搜索过程中不断地产生新的解,并保留更优的解,最终得到最优解。其基本步骤见图1。 图1 GA算法基本步骤Fig.1 The basic steps of GA algorithm 当负载矩阵W=[w1,w2,…,wp]∈RV×p包括p个计算得到的主元,样本矩阵X可以分解为 (17) 式(17)中:T∈RN×p定义为得分矩阵,即 T=XW (18) 对一个新的测量数据x∈R1×N,x映射到监测模型,即 (19) T2和SPE统计量用于异常检测,令I为单位矩阵,重新定义为 SPE=xT(I-WWT)x (20) T2统计量重新定义为 (21) 式(21)中:D为l大伪特征值的对角矩阵。T2和SPE统计量的上限可以通过核密度估计(kernel density estimation, KDE)[17]得到。KDE可以用来估计两个统计量的概率函数,然后可以分别使用95%和99%分位数作为控制限制。 鲁棒稀疏异常检测方法的核心目标就是对异常点具有鲁棒性,最直接的方式是能够发现异常点并进行剔除。考虑到异常数据必然比正常数据有更大的残差,这就意味着具有高SPE统计量的样本更可能是异常值。目前关于异常值检测的方法很多。通过对这些算法的有效性和复杂性进行综合考量,提出了如下方案:若异常数据的数量较少,可直接使用基于核密度估计的非参数方法[18];否则,若异常数据的数量较大,建议采用基于高斯混合模型(gaussian mixture model, GMM)的参数化方法[19]。 基于RSPCA的故障检测方法详细示意图如图2所示。整个方法包括两个阶段: 第I阶段:离线建模。 步骤I-1:原始历史数据集标准化。 步骤I-2:使用CPV选择p个主元,应用GA选择一组k值,基于计算得到的p个鲁棒稀疏主元构建RSPCA模型。 步骤I-3:计算每个样本对应的SPE统计值,用于异常检测。 步骤I-4:使用异常检测方法剔除异常值。当异常值所占比例较大时,建议采用GMM方法剔除。否则,建议使用KDE方法剔除。 步骤I-5:基于新的数据重新构建RSPCA模型。 步骤I-6:将异常值剔除后的历史数据投射到特征空间。 步骤I-7:确定T2和SPE统计量的控制限。 其中,步骤I-3至I-5主要用于基于当前构建模型剔除异常值,这些步骤可以执行多次,用于精确的异常值剔除。一般执行一次即可达到效果。 第II阶段:在线建模。 步骤II-1:使用剔除异常值后的原始数据的均值和方差对在线过程数据进行标准化。 步骤II-2:将标准化后的样本投射到特征空间。 图2 IRSPCA方法框架示意图Fig.2 The framework of IRSPCA 步骤II-3:计算相应的T2和SPE统计信息。 步骤II-4:检查计算的T2和SPE统计值是否超出其控制限。如果是,则检测为异常;否则,转至步骤II-2监测下一个样本。 该节通过两个案例即一个数值仿真数值和一个工业案例来验证IRSPCA方法的有效性和实用性。对于比较方法的检测统计,均采用99%的置信限作为异常检测阈值。 选用两个指标评估系统的异常检测性能,一个是错误报警率(false alarm rate, FAR),用于度量报警的数据中误报的概率,另一个是故障检测率(fault detection rate, FDR),用于度量异常数据被报警的概率。设Jth为检验统计量J的上限。FAR及FDR分别定义[20]为 (22) 式(22)中:f表示为异常样本数量。 本案例利用文献[9]中提出的模拟稀疏多元过程,验证IRSPCA方法的鲁棒性和稀疏性,并展示异常检测效果。模拟稀疏多元过程的数学模型为 (23) (24) 该案例训练数据集包含360个正常观测值以及40个异常观测值。异常观测值通过xi=0(i=1,2,…,8)和xi=ζi(i=9,10)得到,其中ζi~N(0,3 000)。另外,通过仿真得到两个包含400个样本的异常验证数据集。异常数据集设计如下: (1)系统在正常模式下运行,从第161个样本对V1施加一个阶跃偏差-400。 (2)系统在正常模式下运行,从第161个样本对V2施加斜率为20的斜坡变化。 首先,利用CPV选择PCA-L1的前p个主元,将鲁棒主元的累积贡献率阈值设为75%。然后在建立RSPCA模型时,利用遗传算法确定所选主元的非零负载个数。本文中采用实数编码遗传算法[21]求解整数优化问题。实验中使用了MATLAB的遗传算法工具箱。基于数据规模和实验实际效果,采用SC作为适应度函数,考虑到数据规模,将λ指定为1.4,种群规模设置为50,代数设置为10。经过10次迭代,得到的结果是(4,4),这意味着尽管存在异常值,IRSPCA仍然能够正确识别了重要变量。 如图3和图4所示,对于IRSPCA异常检测模型,所提出的基于GMM的SPE统计量异常点剔除策略可以发现这些异常值。剔除异常值后,可以基于新的数据集构建新模型,以用于异常检测。 PCA和IRSPCA的主元负载和方差如表1所示。显然,当训练集由10%的异常值组成时,IRSPCA能正确地识别相应变量。但是,第一主元和第二主元顺序相反。剔除异常值后,调整后的第一主元和第二主元完全正确。 关于两类方法的FDR和FAR信息记录在表2。很显然,对于异常1和异常2,IRSPCA的T2和SPE统计量FDR均显著高于PCA的T2和SPE统计量误检率。IRSPCA明显优于PCA的检测效果。而PCA计算得到的主元受异常值的影响严重。由于PCA试图减少所有输入数据的重构误差,其SPE统计量监测性能较差。 图3 IRSPCA方法的SPE监测图Fig.3 The SPE monitoring chart of IRSPCA 图4 GMM的异常值检测结果图Fig.4 The abnormal detection results of GMM 表1 PCA和RSPCA方法的负载和方差列表Table 1 The load and variance list of PCA and RSPCA 表2 IRSPCA和PCA的检测性能列表Table 2 The detection performance of IRSPCA and PCA 本案例通过对来自广西南宁卷烟厂烟支成品实际检测数据开展分析,验证IRSPCA的实际应用效果。广西南宁卷烟厂烟支成品重要物理指标的检测数据是由烟支/滤棒综合测试台采集得到的。本案例所使用的数据集由6 000个烟支检测实例组成,每个实例包含4个参数,分别为重量、圆周、吸入阻力和长度。这些实例的质量异常情况均是结合专家根据自己的经验和知识进行综合感官验证后得到的标注,样本中共包含268个异常样本。 实验采取交叉验证方法实施,选取50%的正常样本用于训练,选取80%的异常样本以及相等数量的正常样本用于测试,剩下的正常样本以及20%的异常样本用于验证。所有的数据集包括训练集、验证集及测试集均需统一的标准化预处理。基于数据规模和实验实际效果,用于确定稀疏度的GA算法超参数设置如下:λ为1.4,种群大小为100,遗传代数为50,鲁棒主元的累积贡献率为95%。 实验分两个阶段,第一阶段训练集中不存在易混淆的异常值,第二阶段在训练集中添加10%的易混淆异常值。实验结果见表3,表中FDR最大值标记为粗体。可以看出,在第一阶段,三种方法的T2统计量的性能差距不大,但是经过鲁棒处理的SPE统计量的性能明显高于未经过鲁棒处理的PCA方法,这说明原始正常数据中也存在少量的异常值。第二阶段刻意加入异常值后,PCA的整体性能下降明显,T2统计量的FDR减少了6.5个点,RSPCA和IRSPCA均保持了稳定,且SPE统计量的FDR也得到了显著的提升。总体来说,IRSPCA的T2与SPE统计量的FDR和FAR均明显优于PCA和RSPCA,这验证了IRSPCA受异常值影响较小,在鲁棒性方面具有优势,也决定了其检测性能的优越性。 提出了一种工业异常检测方法IRSPCA主要用于解决PCA的异常值敏感和主元非稀疏问题。针对稀疏度问题,设计了稀疏度选择的目标函数即稀疏性准则函数,用于权衡拟合度与稀疏性,并开发了一种两阶段稀疏度选择策略,并利用遗传算法求得了主元稀疏度的最优解。针对异常值敏感问题,考虑到异常样本必然比正常样本有更大的残差,则相应SPE统计值大的样本更可能是异常样本,设计了基于SPE统计量的异常值剔除策略。本章通过一个数值仿真案例和一个工业案例开展了方法有效性的验证,结果表明,IRSPCA方法较RSPCA、PCA能有效提升鲁棒性和稀疏性。下一步将继续对不同的实际工业应用场景进行应用研究。 表3 实验比较结果列表Table 3 The experimental comparison results
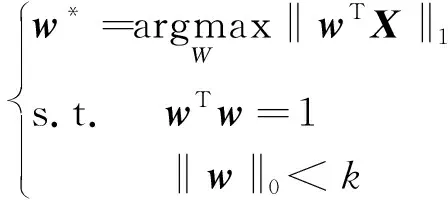



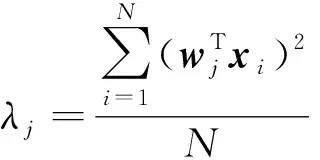
2 鲁棒稀疏异常检测
2.1 稀疏度选择
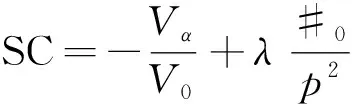

2.2 异常值剔除



2.3 整体流程

3 案例研究
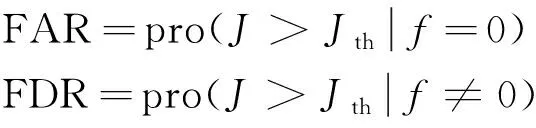
3.1 数值仿真案例



3.2 烟支成品检测
4 结论
 猜你喜欢
波谱学杂志(2022年1期)2022-03-15初中生世界·九年级(2017年10期)2017-11-08中国校外教育(下旬)(2017年8期)2017-10-30科技创新与应用(2017年17期)2017-06-16中学生数理化·八年级数学人教版(2016年5期)2016-08-23中学生数理化·八年级数学人教版(2016年5期)2016-08-23中学生数理化·八年级数学人教版(2016年5期)2016-08-23教学月刊·中学版(教学参考)(2016年5期)2016-06-14现代电子技术(2016年5期)2016-05-14
猜你喜欢
波谱学杂志(2022年1期)2022-03-15初中生世界·九年级(2017年10期)2017-11-08中国校外教育(下旬)(2017年8期)2017-10-30科技创新与应用(2017年17期)2017-06-16中学生数理化·八年级数学人教版(2016年5期)2016-08-23中学生数理化·八年级数学人教版(2016年5期)2016-08-23中学生数理化·八年级数学人教版(2016年5期)2016-08-23教学月刊·中学版(教学参考)(2016年5期)2016-06-14现代电子技术(2016年5期)2016-05-14
