
基于情感计算与深度学习的弹幕文本敏感词识别方法
2022-07-12 04:33叶海燕
常州工学院学报 2022年3期
叶海燕
(巢湖学院信息工程学院,安徽 合肥 238024)
要实现对弹幕文本数据的安全保护,必须准确识别弹幕文本内容,并进一步确认,并识别出的弹幕文本是否存在敏感部分和机密部分,如果及时隐藏此类弹幕文本,可进一步保证数据在传输和使用过程中的安全性[1-3]。传统的弹幕文本识别方法,一般需要手动设置一些敏感词,然后利用大数据技术对屏幕文本进行批量筛选,找到相同的文本。但是一般的词都会有近似词,只有设置的敏感词才能被识别,而相似词无法识别。因此,在批量筛选弹出文本中的敏感词时常有遗漏。例如,如果文本中含有“秋季果实”“丰收成果”“大丰收”等与“丰收果实”意义相近的词语时,就无法准确识别和隐藏;丁建立等[4]基于组合式深度学习网络,进行混合文本情感分类,有效提升了混合文本分类的准确率;周锦峰等[5]通过对汉字进行特殊编码,提出一种综合考虑读音及字形特点的音形码汉字相似度改进算法。
因此,本文提出一种基于情感计算与深度学习的弹幕文本敏感词识别方法。在情感计算和深度学习的相互配合下,构建出弹幕文本识别模型,它可以进一步识别弹幕文本表达的内容,迅速掌握关键词,然后对其敏感度进行计算,并对其分级,进而不同程度地隐藏识别出的敏感词,保证弹幕文本的安全性。
1 数据预处理
在分析弹幕文本前对弹幕文本进行预处理,可减少多噪音数据的干扰,从而提高文本识别准确度。
通常情况下,中文弹幕文本的词语之间没有分割之处,只能靠人工朗读分辨。本模型采用gxy分词辅助器对中英文混合弹幕进行分词处理。首先将中英文弹幕分为中文弹幕和英文弹幕,然后对中文弹幕文本中的常用名词进行识别。这些常用名词的出现会对分词辅助器造成干扰。比如,“情感计算方法”通常会被分词辅助器分为“情感”“计算”“方法”,举例不当将“情感计算”4个字分开后,以此得到的分词内容会对后期敏感词识别造成一定的干扰。为此,在进行分词前,一定要注意识别常用名词和涉及保密文件的名称代号,将其去除后才可以分词。
为了使分词更容易,去掉不利于判断文本敏感度的辅助词,如“的”“地”“得”等。此外,采用NbZ方法去除辅助词。列出所有敏感词内容相似的词,判断每个弹幕文本与敏感词的相似度,记录最小相似度,比较多个最小相似度范围,最终结果用于确定每个敏感词的最小相似度范围。预处理过程如图1所示。

图1 预处理过程
图1中,由于相似度越小的弹幕文本对判断弹幕文本敏感度的干扰越大,因此经过上述过程后,当弹幕文本与敏感词的相似度小于最后确定的值域时,则默认为这个弹幕文本的敏感因素被去除。
2 关键词提取
弹幕文本的所有内容都是由词语表达出来的,在一个文本中,每个词语对表达文本主题起到的作用不尽相同,例如,“情感敏感计算”“敏感程度”等词语对表达文本主题的作用远高于“保护”“持续”等词语,因此,提取出文本中对表达文本主题作用更大的关键词,可以更加快速地识别出弹幕文本是否包含敏感词。目前,能够提取出关键词的算法非常多,如TF-IDF算法和TextRank算法,本文采用情感计算法提取文本关键词[6-11],其计算表达式如下:
(1)

3 情感计算与深度学习弹幕文本敏感词识别模型构建
情感计算与深度学习弹幕文本敏感词识别模型是以深度学习理论中的卷积神经网络原理为基础,模型的识别过程利用阶层结构对输入信息进行平移不变分类。首先,利用情感计算方法构建弹幕文本敏感词识别模型;其次,为了提高工作效率和准确性,采用DHT方法对模型进行敏感度训练。
3.1 构建弹幕文本敏感词识别模型
基于深度学习理论,采用情感计算方法构建的识别模型工作流程如图2所示。

图2 识别模型工作流程
根据获得的敏感词汇集,计算输入文本的敏感相似度,公式如下:
Similarity(word)=
(2)
式中:P代表敏感词汇集;So代表敏感性系数。
根据敏感相似度,判断文本是否为敏感词:
(3)
若文本敏感度判断函数S(x)为0,则标记为非敏感词,加入敏感词判断词库后输出;若结果为1,则识别为敏感词。至此完成弹幕文本敏感词识别模型的基本构建。
为了对模型的识别能力进行强化,需要进一步分析敏感等级,对敏感词用敏感等级标注,与非敏感词一起加入敏感词判断词库,方便下次识别。
3.2 采用DHT方法训练模型敏感度
为了提高模型识别的准确性和工作效率,采用DHT方法对模型进行训练,将现有的敏感词进行等级分类,根据词语的实际应用场合对敏感词汇集进行由高到低的等级标注。
DHT方法将所有信息均以哈希表条目形式加以存储,这些条目被分散存储在各个节点上,构成巨大的分布式哈希表。因此,可以形象地把这张哈希大表看成是一本字典:只要知道信息索引的key,便可通过Kademlia协议来查询其所对应的敏感度信息,而不管这个敏感度信息究竟是存储在哪一个节点上。
将DHT方法应用到敏感词识别模型训练中,key的值等于已知的敏感词字符串的160 bit SHA1散列,而其对应的敏感度value则为一个列表,在这个列表中,给出了所有敏感词信息,这些信息可以简单地用一个4元组条目表示(敏感词、敏感集中词、文本长度、敏感度)。由此通过构造一个敏感词哈希表来实现敏感度计算,与敏感词汇集的敏感词相似度越高,则敏感程度越高,计算过程如下:
(4)

弹幕文本过长会对词语敏感程度造成一定的影响,所以要用得到的结果除以整个弹幕文本长度N,再进行SMALL缩放处理,使其处于0~2,根据值域结果判断词语的敏感等级。本文将值域划分为kSMALL≤0.5为L1等级,0.5 表1 敏感词集 模型经过以上训练,能够更快、更准确地完成敏感词识别。 本仿真实验在CPU为2.4 GHz、8 GiB内存的Inter Core(TM)i7处理器上进行,并与传统方法(文献[4]方法)进行对比。此次研究在Past KDDCups(http://www.kdd.org/kdd-cup)网站中随机抽选30个数据集,经过预处理后,将具有某些敏感词的2 000个数据随机分成5份,为实验提供数据基础。 查全率是被正确检索的样本数与应当被检索到的样本数之比。设,识别出的敏感词为TP,未识别出的敏感词为FN,查全率公式如下: (5) 对比本文方法与传统方法的查全率,结果如图3所示。 图3 查全率对比 从图3分析可知,当数据集为80个时,传统识别方法查全率相对较低,这可能是由于数据量较小,误判对实验结果影响较大所致,从而降低了查全率。而本文提出的基于情感计算与深度学习的弹幕文本敏感词识别方法的查全率达到85%以上,能对文本词汇进行综合分析,提高了识别效果。 查准率是被正确识别的样本数与被识别样本总数之比。设,识别出的敏感词为TP,未识别出的敏感词为FP,查准率公式如下: (6) 传统方法与本文方法的敏感词查准率的对比结果,如图4所示。 图4 查准率对比 通过分析图4发现,传统方法的查准率偏低,原因是敏感词识别过程中拆分较复杂,对识别结果干扰较大。而本文方法具有较高的查准率,基本能够保持在92%以上。 2种方法的敏感词汇识别时间见图5,通过分析可发现,随着数据量的增加,传统方法与本方法的识别时间也相应增加。对比可知,传统方法的识别时间一直高于本文方法,证明本文方法取得了较好的应用效果。 图5 识别时间对比 综上所述,本文的识别方法较传统方法查全率高、查准率高,并且有效减少了识别时间,证明了本文方法的有效性。本文的识别方法综合运用了情感计算方法与深度学习方法,对词汇特征进行了有效的扩展与学习,从而提高了应用效果。 本文提出的弹幕文本敏感词识别方法以当前最热门的情感计算方法和深度学习为基础,并与关键词提取和敏感度计算技术相结合,精准地计算出弹幕文本中每个词语的敏感度,并形成敏感词汇网络,将高于敏感值域的敏感词都记录在册,提高了查准率与查全率,保证了相似词、敏感词被准确识别。 由于研究条件与时间的限制,所设计的实验只选择了少部分的词汇进行实验,在未来研究中,为更加深入研究该算法,可进行大规模实验,以及时发现识别方法中存在的不足,从而为相关领域提供性能更为优越的敏感词识别方法。
4 实验对比
4.1 实验环境
4.2 查全率对比
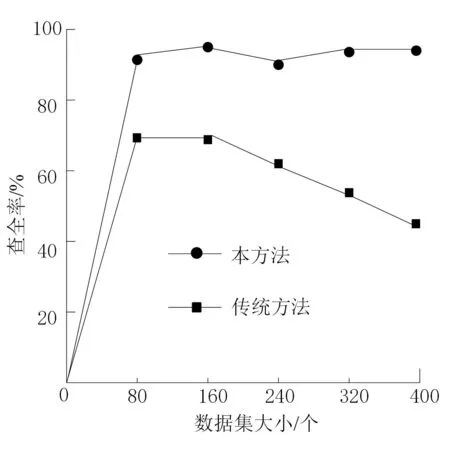
4.3 查准率对比

4.4 识别时间对比

5 结语
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
现代电子技术(2018年20期)2018-10-24
现代电子技术(2018年16期)2018-08-21
现代情报(2018年11期)2018-01-07
现代电子技术(2017年23期)2017-12-20
计算机应用(2016年10期)2017-05-12
中国管理信息化(2009年10期)2009-06-19
中学生英语·外语教学与研究(2008年4期)2008-03-18
