
应用人工神经网络的音乐多参数识别方法设计
2022-07-12 04:33王瑞李珊齐建立
常州工学院学报 2022年3期
王瑞,李珊,齐建立
(阜阳师范大学音乐舞蹈学院,安徽 阜阳 236037)
人工智能技术是人类未来三大研究技术课题之一。音乐是一种听觉艺术,能够表达人的情感与心情[1]。在人类历史与社会发展过程中,音乐在促进文化发展中起到了良好的作用,对共建和谐文化具有明显的作用。因此,随着社会文明的不断发展,为更好地发挥音乐的积极影响力,应不断发展音乐产业,创新音乐创作模式,以满足社会对音乐越来越多的需求。
参数识别是音乐创作过程中的一个重要过程。利用计算机技术识别音乐序列参数,不仅能节省创作时间,也能更好地展现出音乐人的想法和情感[2]。
随着大数据分析、分布式计算和共享技术的发展,人工智能技术飞速进步[3-4],其涉及的领域也越来越多。
因此,基于上述背景,本研究将人工智能技术中的人工神经网络应用于音乐多参数识别过程中。
1 音乐多参数识别过程设计
1.1 具体化音乐抽象空间
在音乐表达中,需要通过具体化音乐抽象空间来呈现不同的音乐风格和情感。有效判定两个音乐点的相似性是具体化音乐抽象空间的重要环节[5]。在以往的音乐表达中,不论是依靠人工技术还是依靠自动化技术,获得的都是一系列具有相同风格的音乐,在音乐抽象空间中,很难同时存在多种不同风格的音乐。造成这一现象的原因是,在抽象空间内音乐风格较为相似或者风格不同的音乐点之间有一定概率存在较大的相似度,这就导致不同风格的音乐之间存在不平滑的过渡[6-7]。因此,在音乐表达中,音乐创作风格的确定需要采用一些属性作为学习的特征,将音乐风格数值化,风格值以目标函数表示,根据不同的目标函数的值表示音乐风格[8]。
与音乐风格空间同样重要的是音乐情感空间。Russell提出了可以坐标化情感的方法,利用Arousal维度和Valence维度来定义音乐的情感风格,并构建了一个二维的情感空间,如图1所示[9]。
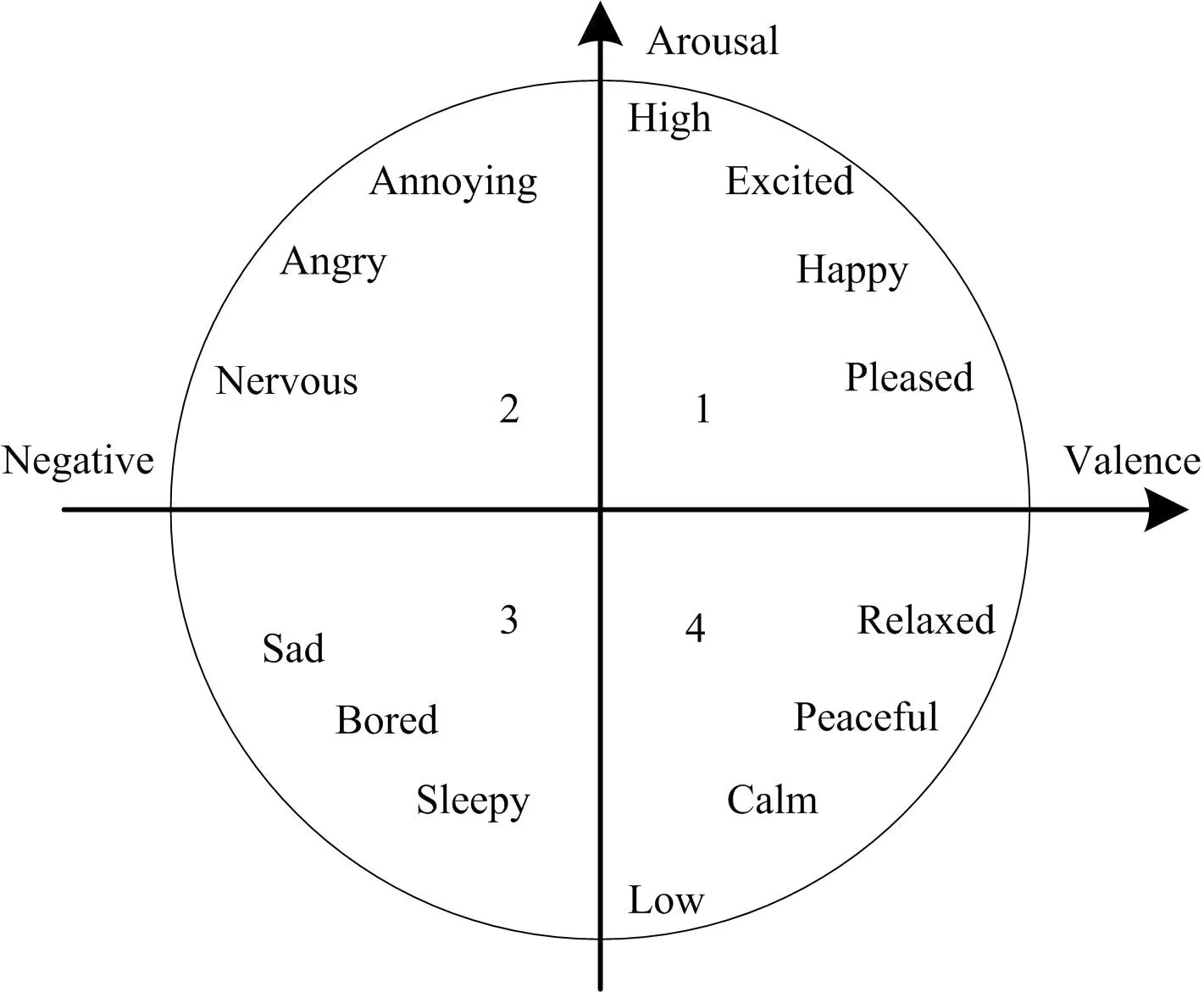
图1 音乐表达的二维情感空间
在图1所示的二维空间内分布了不同的情感,这样的空间即为情感空间。基于二维情感空间,在音乐表达中,只需要将音乐所具有的情感特征投射到二维情感空间内,将情感空间中的坐标刻度值作为输入信息,然后利用人工神经网络对样本信息展开训练即可[10-12]。在这一过程中,首先判断训练集中的各个音乐元素,赋予情感类别,从而确定其在情感空间中的所处位置,与图1中的情感特征一一对应,获得音乐情感范围,确定音乐创作情感和风格。
将音乐数据视为一个时间序列,两段不同的音乐序列Y1和Y2,它们的特征量分别为(a1μ,b1μ)和(a2μ,b2μ),且μ=1,2,…,n表示音乐Y1和Y2的时间长度。在每一个时间点μ上,计算(a1μ,b1μ)与(a2μ,b2μ)的欧式距离D(μ),则整个时间段μ=1,2,…,n内,音乐序列Y1和Y2的相似度可以定义为
(1)
然而,上述相似度计算过程仅适用于两段音乐序列时间长度相同的情况。针对两段时间长度不同的音乐序列,令两个时间序列分别为X=(x1,x2,…,xi)和Y=(y1,y2,…,yi),设定度量函数k(x1,y1),可以度量分量x1和y1的距离,也就是(a1μ,b1μ)与(a2μ,b2μ)的欧式距离。
在此基础上,建立一个矩阵Ki×j,矩阵中的元素就是k(xi,yj),以矩阵Ki×j作为输入,输出X和Y的相似度D(x,y)[13-14]。依据相似度完成时间序列的聚类,最终输出具有独特风格、情感的音乐。
1.2 旋律特征识别及合成
根据上述过程可以判断音乐本身的风格和情感,在此基础上需明确音乐的旋律特征。一首完整的音乐离不开动人的旋律,而旋律特征的识别及合成则需通过构建音阶参数、提取频率等步骤实现。
从初始的旋律运动轨迹中提取音高的信息,所提取的信息用来生成旋律线,且旋律线符合一定的音阶规则。旋律合成流程如图2所示。
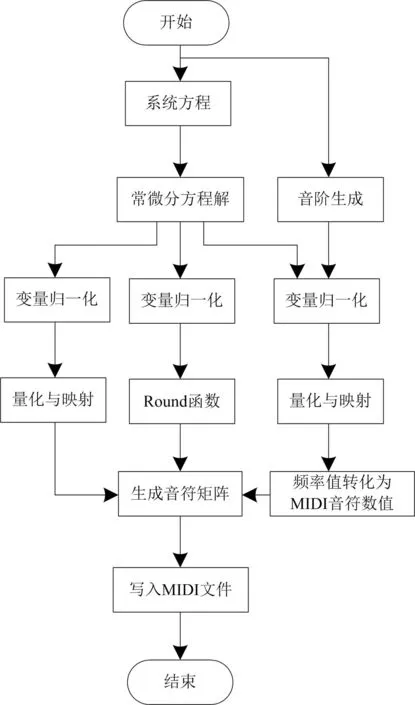
图2 旋律合成流程图
利用下式计算音高频率比:
Qi=2i/120≤i≤12
(2)
式中i表示特定音阶的起始音。在不考虑微分音的情况下,利用音阶结构变量可以定义音阶提取过程的特征函数为
(3)
式中:Q表示预先设定的音阶数据;xi表示特征阈值,基于这个阈值可以过滤半音阶内不属于当前音阶类别的项。在此基础上,利用音高频率比和特征函数获得归一化变量,过程如下:
z(t)=Qiz(t)+xi
(4)
对利用公式(4)得到的z(t)进行量化处理,将频率比映射到已选定的音阶中,并完成对归一化变量与音阶数据间的匹配,从而找到数值最接近的音符频率数值。找到音符的频率值之后,即可完成频率对标准MIDI数值间的转换,从而完成旋律的合成。
1.3 音乐多参数识别
在上述具体化音乐抽象空间识别及合成旋律特征的过程中,本研究充分发挥了人工智能技术的应用优势,通过人机协作辅助音乐表达,并合成了音乐旋律特征。在此基础上,利用人工神经网络实现对音乐多参数的识别。
人工神经网络的使用需要根据不同的需求情况进行训练,对模型进行训练的过程就是在最大化每一个音乐序列的基础上获得音乐序列的似然估计。模型训练过程如下:
将检索条件作为目标函数输入至人工神经网络模型,计算音乐序列的似然值之和及其最大似然估计值。为保证模型训练效率,预处理输入数据和检索条件,将所有检索条件输入到数据轴层中,通过并行计算获得所有检索内容的相关概率值。
在输入的检索条件下,获得的所有待识别的内容都保存在数据层中,通过训练获得每一个隐藏层单元中的数据样式。
基于此,对音乐序列多参数展开识别,过程如下:
1)确定每个音乐序列元素对应的势值Si;
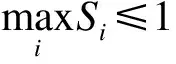
4)将最大势值元素作为神经网络中存在的新的隐节点中心,并通过设置Dropout值来控制训练过程中网络模型中部分节点的暂停工作。将Dropout的值设定为0.5,并在每次休眠中,保证1/2节点处于休眠状态,这样能够保证节点之间不会产生弱依赖关系,从而保证输出结果具有较高的相关性。
至此,完成了对基于人工神经网络的音乐多参数识别方法的设计。在此基础上,通过对比实验的方式验证该方法的有效性。
2 实验结果与分析
为验证上述设计的基于人工神经网络的音乐多参数识别方法的实际应用性能,设计如下对比实验,并将传统的基于概率模型的音乐参数识别方法和基于随机组合的音乐参数识别方法作为对比方法,与本文方法共同完成性能验证。
2.1 实验设计
实验参数如下:音频数据采样频率为28 kHz,单个音频分帧长度为25 ms。
实验样本均为大提琴发声的音符,从音符36(C3)到音符107(B8)共72类,每一类音符共有350个数据样本。针对从每一帧提取出来的音符数据,利用式(5)计算3项不同指代性的概率。只有当音符对应的概率值大于预设值,才可以判断此帧中包含这个音符。3项不同指代性概率的具体计算过程如下:
(5)
式中:Muw表示第u帧中出现音符w;M(u+1)v表示第u+1中出现音符v;P(Muw)表示总帧数与包含音符w的帧数的比值;P(M(u+1)v|Muw)表示当前帧末音符是w且下一帧是v的帧的数量。将式(5)中的概率计算结果作为后续音乐创作模式识别的约束条件。
实验过程中,选择相同的音符序列部分,利用本文方法、两种传统方法识别该段序列的音乐参数。首先检验不同方法能否有效标记出多余音符,然后以EB(空白音比率)、UPC(噪声音数量)和QN(合格音符比率)为指标,对不同方法的音乐创作模式展开评估。
2.2 音符识别实验结果及分析
选择相同的音符序列部分,使用不同的音乐参数识别方法完成识别处理,从而获得识别结果,如图3所示。
图3中显示了在不同音乐参数识别方法下的音符序列识别结果,其中标记出的音符是识别出的多余音符。对比3组实验结果可以明显看出,前两组实验结果中或多或少存在识别错误,存在多余音符,第3组实验结果中在相同的位置,并没有识别出多余音符。综上所述,本文设计的基于人工神经网络的音乐多参数识别方法能够有效地将多余的音符过滤掉,保证音符识别质量。在此基础上,结合音轨对比实验结果分析不同识别方法的应用效果。
2.3 音轨对比实验结果及分析
在此基础上,分别以EB、UPC和QN为指标,对不同方法的音乐创作模式进行初步评估,结果如表1所示。

(a)基于概率模型的识别方法

(b)基于随机组合的识别方法

(c)基于人工神经网络的识别方法图3 不同识别方法的音符识别实验结果

表1 音轨实验结果
通过对比不同方法的EB指标可以看出,前两组数据和第3组数据相比,生成的音乐中产生空白小节的概率比较低;通过对比不同方法的UPC指标可以看出,前两组在同一时间产生超过4个音符,说明在音乐中可能存在部分噪声,而第3组结果中没有超过4个;通过对比不同方法的QN指标可以看出,本文构建的基于人工智能技术的音乐创作模式的合格音符比率明显高于前两组数据。再结合音符实验结果可知,构建的基于人工神经网络的音乐多参数识别方法在记录音符的标准模型中,能够准确识别出音符,其产生的音轨质量更高。
3 结语
音乐参数识别属于音乐创新领域的一个重要研究课题,利用人工智能技术使音乐参数识别过程更加智能是本文研究的重点。本文在识别过程中引入了人工神经网络。通过与传统方法的对比实验可知,人工神经网络的引入有效解决了传统识别过程存在的不足,充分证明了本文方法的应用优势。
猜你喜欢
中国音乐(2022年3期)2022-06-10
黄河之声(2020年5期)2020-05-21
空间科学学报(2020年4期)2020-04-22
电子制作(2019年10期)2019-06-17
作文大王·低年级(2019年5期)2019-06-13
作文小学中年级(2019年4期)2019-04-25
37°女人(2016年7期)2016-07-07
电源技术(2016年9期)2016-02-27
北京航空航天大学学报(2016年3期)2016-02-27
文化交流(2015年1期)2015-01-22
