
地铁运营岗位应急处置培训的语音识别研究
2022-07-13 01:04钱雪军
网络安全与数据管理 2022年6期
周 杨,钱雪军
(同济大学 电子与信息工程学院,上海 201804)
0 引言
地铁行车事故和突发事件严重影响了地铁的正常运营并威胁到了人民群众的生命财产安全[1]。对于相应的应急预案而言,应急预案演练的效果直接决定了应急响应的速度和应急处置实施的有效性,其中应急处置培训是应急预案演练的重点。
目前的联合培训系统需要所有培训岗位均为在岗状态,无法实现在联合培训中的单岗位培训功能。因此在对各个岗位进行应急处置培训过程中需要模拟各个岗位之间的语音交互,实现单个岗位独立培训时的智能互动,同时实现对培训过程的记录与智能评价。语音识别是语音交互的基础。目前,国内外语音识别技术已经趋于成熟,走向真正实用化[2],在日常对话等常见领域已达到实用要求,但是在地铁等专业应用领域的识别效果不佳[3]。
本文基于DFCNN-CTC 框架提出新的语音识别声学模型结构,以实现对应急处置培训术语的高精度识别。实验表明,该语音识别模型可应用于应急处置培训系统中。
1 应急处置培训术语
本研究使用上海轨道交通培训中心列车故障救援场景处置培训方案的培训术语,记录列车故障救援场景下运营调度员、车站值班员以及列车司机的语音对话用语。对话内容涵盖了地铁列车到达及出发的技术作业、线路封锁、客运管理、技术设备的检查排故、各部门协调等环节。
1.1 培训术语研究
如表1 所示,应急处置培训用语有如下的特征:(1)培训用语中同时存在中文、英文、标点符号和数字。将数字和英文字母用汉语文本表示,发音为普通话,并去除相关标点符号。(2)车务人员对话用语按照标准多为长语句(30 至40 字),对过长的语句在不影响上下文的情况下进行切分识别。(3)培训用语中含有铁路专有名词,例如:济阳路、上南路、大渡河路、清客、入段线、联控、对标停车等。

表1 应急处置培训通话文本(部分)
对比科大讯飞、百度、Siri、Cortana等国内外公司所研发的语音识别软件,在对铁路车务专用术语的识别率中,Cortana 的综合得分最高,科大讯飞的识别率最稳定,但是准确率仅为50%[4]。目前,这些识别软件需要在联网环境下才能使用,无法满足在培训场景下离线局域网环境中使用的需求。本文针对上述问题收集专业术语语料,基于神经网络构建和训练语音识别模型,提高对培训术语的识别率。
1.2 语料收集
为了提高模型的泛化能力,本文使用了三个公开的中文语音数据集以及一个自制的培训术语数据集。三个公开中文语音数据集分别是:清华大学语言与语音技术中心出版的THCHS-30,希尔贝壳公司开源的AI-SHELL-1 以及北京冲浪科技公司开源的ST-SMDS 中文语音数据集。语音的格式统一为采样频率16 kHz,16 bit 位深,单通道,总时长达到330 h,基本信息数据如表2 所示。对地铁应急处置培训用语进行收集后,组织10 人进行语料录制,共录制700 条语音,其中500 条作为训练集,200 条作为测试集。
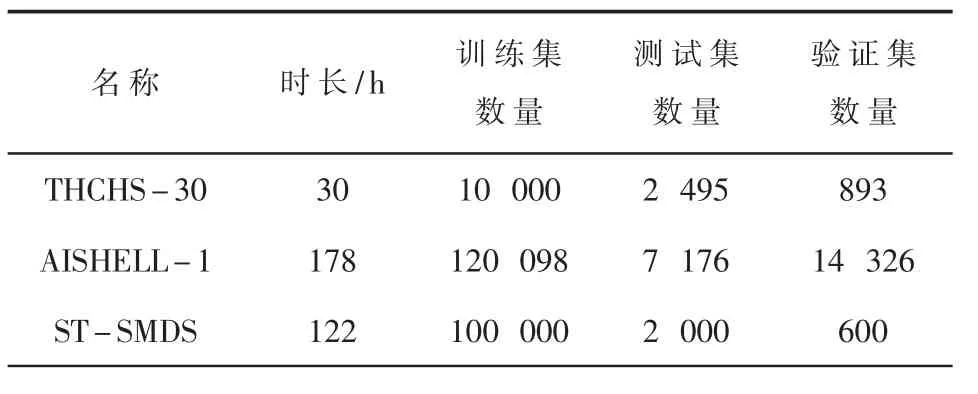
表2 中文语音数据集
2 语音识别系统结构
首先,将音频信号经过预处理转化为语谱图进行特征提取,使用声调和韵母组成的1 427 种拼音作为声学模型的建模单元,将声调标注为数字1~5,数字5 表示轻声,例如“我”(wǒ)表示为wo3,对音频信号所对应的拼音序列进行处理,生成拼音Index 序列。然后,将语谱图和拼音Index 序列作为训练声学模型的输入数据,经过构建的深层卷积神经网络提取语音特征,由全连接层进一步提取信息,通过Softmax 层分类输出概率矩阵。最后,由CTC 解码算法使语音与标签序列对齐,将状态概率解码为标签序列输出,采用Adam 优化器进行模型参数优化,完成对声学模型的训练。
使用统计学方法收集文本语料并构建N-Gram语言模型,将声学模型输出的拼音序列通过语言模型计算输出文本序列,实现拼音-汉字转换,最后经过模板匹配得出预测的汉字结果。语音识别结构如图1 所示。

图 1 语音识别系统结构
2.1 特征提取
目前常用的声学特征包括线性预测系数(LPC)、 滤 波 器 组 特 征(FBank)、 语 谱 图 特 征 以及梅尔频率倒谱系数 (MFCC)。相较于MFCC,语谱图不经过人工设计的滤波器进行特征提取,从而保留了更多信息。生成语谱图的过程主要分为预加重、 分帧加窗、 快速傅里叶变换(FFT)和特征提取四个步骤。
采用一阶高通滤波器,对语音信号的高频部分进行加重补偿,使得频谱分布变得更平缓,提高语音信号信噪比[5]。将长时语音划分为帧信号,采用汉明窗降低旁瓣强度,对每一个语音帧进一步提取特征。采用FFT 提取分帧加窗处理后语音信号的频谱,将频谱取模得到幅度谱,然后取对数得到对数幅度谱[6]。对得到的对数幅度谱进行标准归一化,使不同频率之间的特征在数值上更有比较性,来提高分类器的准确性。最终将处理后的对数幅度谱拼接成时间序列的形式,得到特征序列语谱图。对训练集中一条语音数据进行特征提取,得到的语谱图特征如图2 所示。
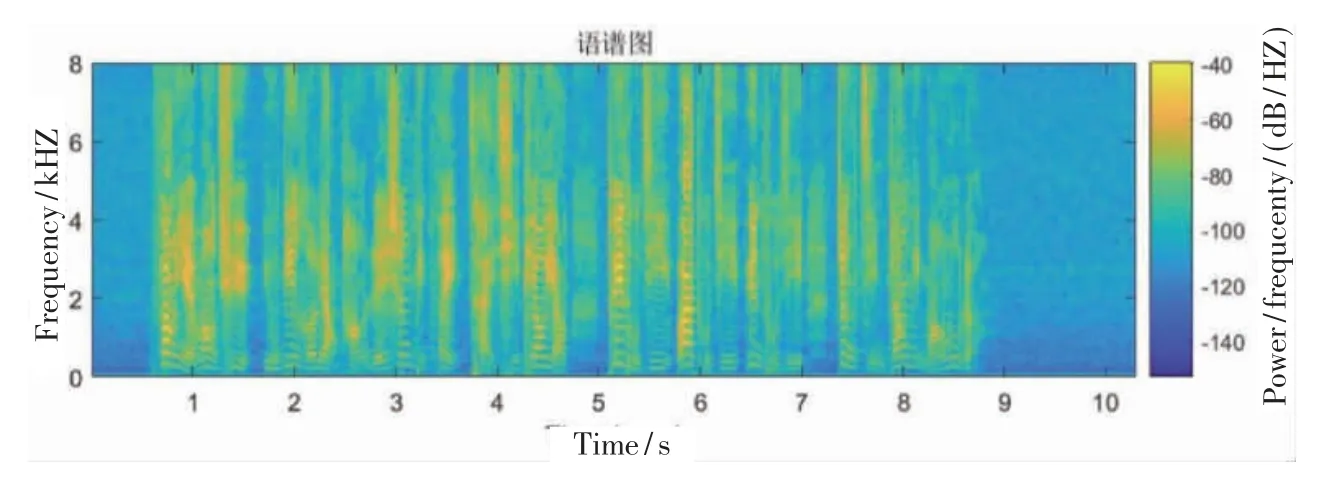
图2 语谱图特征
2.2 DFCNN-CTC 声学模型
经过对语音数据预处理和特征提取后,得到特征序列的横轴为语音的帧数,设置最大帧数限制为1 600 帧,约等于采样16 s。特征序列的纵轴为每一帧的特征矩阵,为200 维。输入特征序列进入声学模型,输出为对应1 427 个拼音和1 个空白单元的取值概率。
2.2.1 模型搭建
声学模型使用DFCNN 架构,采用卷积神经网络对输入的二维语谱图提取特征参数。模型中间部分采用多层卷积单元结构,每一个单元结构由卷积层、激活函数、批归一化层、最大池化层交错分布组成。声学模型结构图如图3 所示。
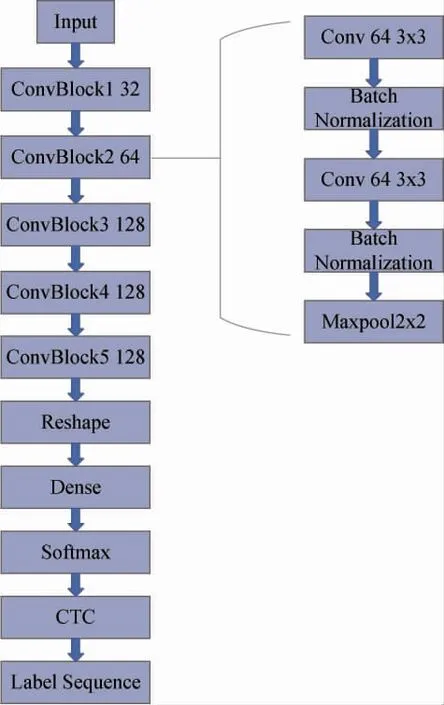
图 3 声学模型结构图
本文的声学模型使用了5 个卷积层模块,每一个卷积层模块由2 层卷积层、2 层批归一化层和1层最大池化层组成[7]。每个模块中的卷积层分别设置有32、64、128、128、128 个卷积通道和大小为3×3 的卷积核。前3 个模块的最大池化层窗口大小设置为2,后2 个模块的最大池化层窗口大小设置为1,进行下采样。padding 均设置为same,激活函数选用ReLU。使用两层全连接层,最后一层的建模单元个数为1 428,对应1 427 个拼音并加上1个空白单元。经过Softmax 输出维度为200×1427的分类概率矩阵,使用CTC 损失函数对模型进行训练。最后通过CTC 解码算法输出标签序列( 即拼音Index 序列),在发音字典中查找得出对应的拼音序列。
1.3.1 农村高龄空巢老人问题突出加大居家养老需求 随着城镇化进程的推进,人口流动频率不断提高,导致了农村地区的留守老人增多。据统计,2016年六合区祖孙二代留守老人5 216人,其中城镇460人,农村4 756人,农村祖孙二代留守老人是城镇的10倍之多。据六合区民政局有关调查显示,“我国农村空巢老人生活中存在困难的项目包括:去医院看病占 34.3%、买菜占 12.5%、购买生活用品占 18.7%、洗衣服占 17.1%、打扫卫生占 13.9%。”受制于种种现实因素,无人照料的农村留守老人还要承担繁重的田间劳动并养育子孙,形成了较大的养老服务需求,推动农村居家养老服务的发展。
2.2.2 模型训练
使用公开中文语音数据集作为本模型的训练集,通过测试集和验证集来调整学习率与验证精度,并使用自制培训术语训练集对模型进行微调。使用Adam 优化器对模型进行训练,bacth_size 为8,每一个epoch 训练量为5 000,进行1 000 次迭代,初始的学习率为3×10-4,在300 次迭代后减少到1×10-4,在700 次迭代后减少到3×10-5。
2.3 DFCNN-CTC 声学模型
语言模型在语音识别系统中的作用是将声学模型输出的拼音序列转换成文字序列,得到具有汉语规律和符合人说话方式的语句。拼音与汉字具有一对多的关系,在发音字典的构建过程中需要考虑多音字、谐音字以及生僻字等问题。
2.3.1 统计语言模型
本文使用N-Gram 统计语言模型,通过概率统计的方式来表示句子中每个词语出现的可能。一个句子的概率由所有词概率相乘得出,通过概率大小判断句子是否合理。基于马尔科夫假设,一个词出现的概率只依赖于前面出现的多个词。本文采用二元模型对收集的培训语料进行词频统计,由大数定律可知,词频约等于概率。
因为存在一音多字的情况,通过拼音序列找寻最匹配的语句的操作类似于搜寻最短路径的行为。维特比算法是一种动态规划求解概率最大路径的算法,可以用来实现拼音序列转换到文本的解码[8]。求解最优路径时,对句子设置初始概率1.0,每一步取一个拼音,将其在发音字典中对应的字接在已拼出的字序列后,将原序列概率与当前字出现概率相乘得出拼凑后的概率,类似于路径的延伸。如果路径概率过低,低于设置的阈值,则将该路径剔除。本文设置每一步的字阈值为0.001,在第n 步时,路径阈值为0.001n。这样可以剔除不常见的词组合,大大降低计算量。最后对到达终点的所有路径通过概率进行排序,取概率最大路径对应的句子输出。
2.3.2 术语匹配
最短编辑距离为字符串所经过的最少增删改操作数,该距离越小,表示两个字符串的相似度越高。本文将所收集的培训语料制作成术语匹配库,将语言模型输出的语句与库中语句进行匹配,找出最短编辑距离最小的语句,即为相似度最高的培训语句。
3 模型测试与分析
对语音识别模型的测试主要针对声学模型进行测试,测试可分为两部分:一是采用公开中文数据集的测试集进行,并与其他模型进行对比;二是采用自制培训术语测试集进行,对比使用自制数据集训练后模型的识别精度,取最好表现。测试结果如表3 所示。
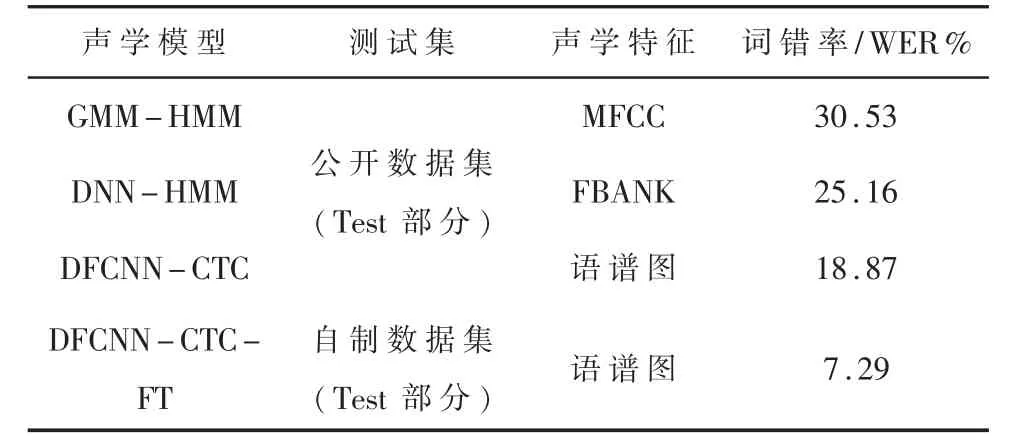
表3 声学模型测试结果对比
由表3 可知,基于统计学原理的GMM-HMM 模型和DNN-HMM 模型词错率都较高,本文所提出的声学模型利用提取的语谱图特征进行训练,在公开数据集上的词错率相较于前两个分别降低了11.66%和6.29%。对模型进行微调 (Fine turning)后,测试集上的词错率下降了11.58%,明显提高了对地铁培训专业术语的识别率。
通过语言模型将声学模型识别后得出的拼音序列转化为文字序列,经过模板匹配得出匹配度最高的培训语句。最终识别效果如表4 所示。
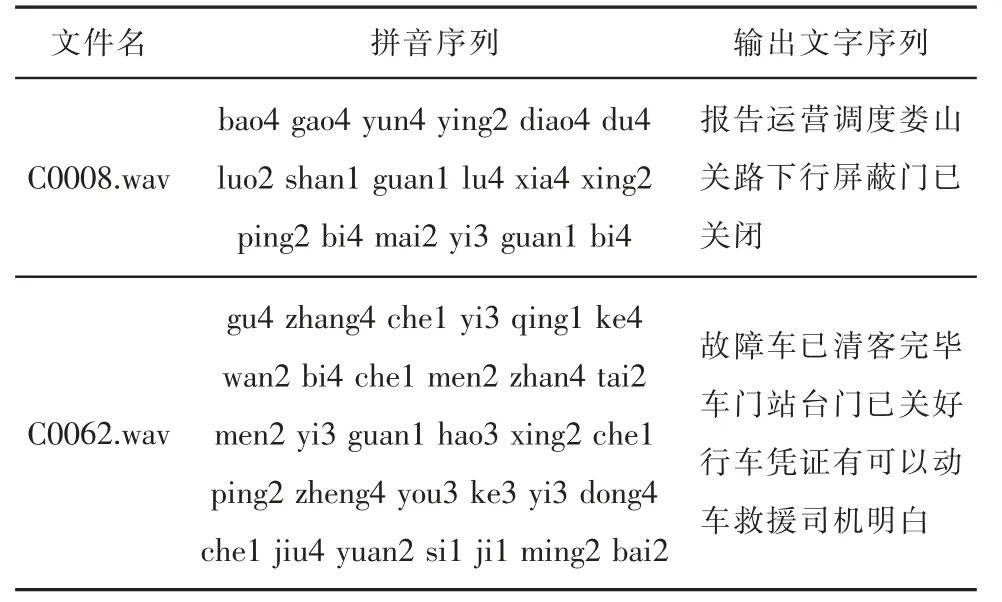
表4 语音识别效果
4 结论
本文提出的针对地铁运营岗位应急处置培训术语的语音识别方法,基于深度学习和DFCNN 神经网络,实现了离线语音识别功能。其相较于传统的语音识别方法和市面上的其他语音识别应用,提高了对应急处置培训术语的识别率。本语音识别方法可以用于实现培训系统智能评价功能和研究语音交互。
猜你喜欢
家庭影院技术(2020年11期)2020-12-28
家庭影院技术(2020年5期)2020-08-24
家庭影院技术(2020年6期)2020-07-27
中国外汇(2019年13期)2019-10-10
电子制作(2019年23期)2019-02-23
小天使·一年级语数英综合(2015年8期)2015-07-06
小天使·一年级语数英综合(2015年2期)2015-01-14
