
基于变分自编码器和三支决策的工控入侵检测算法*
2022-07-13 01:04张迪明
网络安全与数据管理 2022年6期
王 晨,张迪明,韩 斌
(江苏科技大学 计算机学院,江苏 镇江212100)
0 引言
工业控制网络其核心是将互联网技术同自动化控制技术相结合。随着工业化的推进,虽然越来越多的网络模块和控制器优化了工控系统并提升了生产效率,但是高度复杂的工控系统同样增加了其暴露高危漏洞的风险[1]。如今,工控安全是网络安全领域亟待解决的热点问题。
在工控安全的研究领域中,学者们针对不同的工业生产环境,设计出了不同的入侵检测算法模型。赵智阳等人[2]提出了一种基于卷积神经网络的电网工控系统入侵检测算法,在神经网络结构中加入级联卷积层提升了特征提取能力。庄卫金等人[3]提出了基于特征提取的电力工控系统入侵检测方法,通过堆叠稀疏编码器并在训练过程中引入迁移学习进行参数优化,提升了对数据关键特征提取的能力。Shang 等人[4]通过一类支持向量机(One-Class Support Vector Machine,OCSVM)概念建立正常的通信行为模型,并设计粒子群优化算法对OCSVM 模型参数进行优化,设计了工控系统中基于OCSVM 的入侵检测算法。Liu 等人[5]使用两级检测结构,结合CNN 特征提取来构建入侵检测的正常状态过程转移模型,提出了一种基于CNN 和过程状态转换的工业控制系统入侵检测算法。Brugman 等人[6]通过使用软件定义网络将流量路由到云,以使用网络功能虚拟化进行检查,提出了一种使用软件定义网络的基于云的工控入侵检测方法。根据上述研究成果可以得到,大多数算法模型关注到了特征提取对于工控入侵检测的重要意义,并通过相应的特征提取方法进行了实验,取得了相应的成果。但依然存在一定的局限性:
(1)对于特征提取部分仍然有提升的空间,例如对于级联卷积层的加入难以避免运算成本大和过拟合风险;对于堆叠稀疏编码器的应用,编码器只是单一地表征不同数据在隐空间的特质而忽视了其概率分布。
(2)多数算法模型的核心设计在于如何更好地进行特征提取,而忽视提取特征后的样本分类步骤,大多采用传统的二支决策分类器进行分类,存在盲目决策的风险。
针对上述问题,本文提出了一种基于变分自编码器(Variational Autoencoder,VAE)和三支决策(Threeway Decisions,TWD)的工业控制网络入侵检测算法(VAE-TWD)。该算法利用深度学习中的变分自编码器理论[7],先针对输入数据的密集表征进行学习和编码,通过属性映射,在降低输入数据的同时进行特征提取。在训练过程中,成本函数迫使编码在隐空间内移动。然后在由均值和标准差生成的高斯分布中随机采样,并使用解码器解码成重构数据。训练完成后,编码器生成的数据即是降维后的特征。最后基于三支决策理论[8]对决策域中由于暂时信息不足而无法决策的数据进行延时决策,当获得更多粒度特征后再进行决策。三支决策理论极大程度上弥补了传统的二支决策中容错能力差,且不能依靠特征粒度的信息来对网络数据行为做出动态决策的缺点。
本文提出的VAE-TWD 入侵检测算法模型主要优势在于:
(1)在特征提取部分利用变分自编码器在损失函数中添加一个正则项,并返回数据在隐空间中的概率分布,进而将隐空间组织得更好,解决了仅仅描述单一数据属性而导致的隐空间不规则性,使提取的特征包含更多的数据属性。
(2)采用三支决策分类器,避免传统决策器的盲目分类以满足工控网络的安全性要求。
1 相关理论
1.1 变分自编码器
变分自编码器是自动编码器的一个重要分支。但变分自编码与其他编码器相比,具有独特的优势:(1)VAE 是概率自动编码器,这就表明当神经网络训练以后,VAE 的输出会部分由概率决定(这点与降噪自编码器在训练过程中仅仅依靠随机性相反);(2)VAE 是生成式自动编码器,这意味着VAE 生成的数据与原始数据的重构误差很小,即非常接近原始数据。
这两个属性使变分自编码器与受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)[9]类似,但是VAE 的优点在于训练适用性更强,同时采样过程所花的时间成本更少。在使用RBM 时,网络“热平衡”稳定的限制条件将迫使新实例的采样时间大幅度提高。同时变分自编码器执行变分贝叶斯推理,这是执行近似贝叶斯推理的有效方法。图1 显示了变分自编码器的基本结构,在基础自动编码的结构上,变分自编码对编码器部分进行了改进,通过编码器在隐空间中生成平均值μ 和标准差σ,然后实际编码是从均值μ 和标准差σ 的高斯分布中随机采样得到的,而不是将原始输入进行直接编码。最后,解码器进行相反的逆操作即可将编码通过解码得到重构数据。
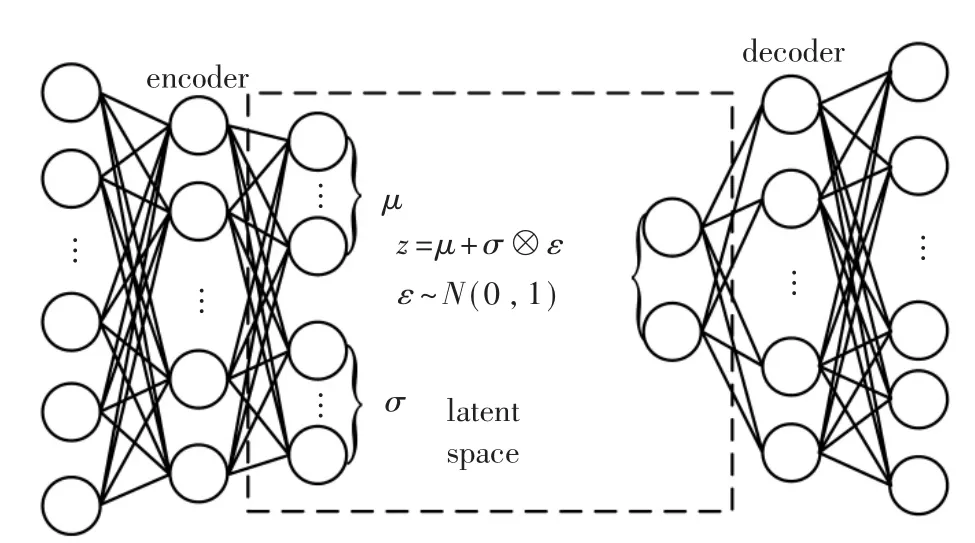
图1 变分自编码器结构
由图1 可得,虽然输入的数据可能繁多且复杂,但是变分自动编码器会通过均值和标准差来生成从高斯分布中随机采样的编码:在训练过程中,首先从先验概率分布pθ(z)中采样得到样本z,成本函数迫使编码逐渐地在编码空间内移动,最终看起来像高斯点云,而后在高斯分布中采样一个随机编码,根据条件概率分布函数pθ(Xi|z)解码即可得到重构出的新的网络样本实例。由于解码参数θ、隐变量z和隐变量z 的后验概率pθ(z|Xi)无法直接得到,因此,VAE 的主要思想是通过一个网络qφ(z|Xi)去逼近。
根据边缘概率公式,对于单个数据样本的似然函数可以表示成:
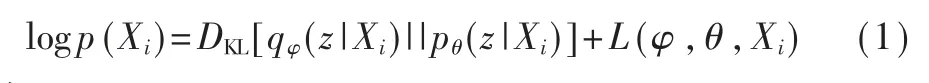
其中:

称之为变分下界,这就是变分自编码器网络的损失函数(loss function)。式(1)中第一项即为KL 散度[10],可以通过优化KL 散度来达到防止模型的过拟合;第二项为重构损失函数项,其作用是衡量原始数据与重构后数据之间的差异。
1.2 三支决策理论
三支决策理论[8]是由粗糙集理论衍生而来的,相较于传统的二支决策问题,三支决策在正向决策域和负向决策域的基础上(可用状态集Ω={X,}来表示)加入了边界决策域。
通过D={DP,DN,DB}来指代三支决策的决策集,其中DP表示正向决策域,DN表示负向决策域,DB表示边界域。对于划分数据对象属于指定区域的标准取决于有限条件集,满足接受条件的划分入正向决策域,满足拒接条件的划分入负向决策域,而对于低于接受条件而又高于拒绝条件的对象,则划分入边界域。在整个三支决策的决策过程中,针对边界域中的数据对象,在获取其他信息以后,将重新即时决定是否划分入DP或DN中,对于当前不符合条件的对象,将继续存放在DB中,然后重复决策过程,直至所有数据对象划分入DP或DN中为止。
根据上述两个可能的状态和三个可能的决策,列出相应的决策损失函数,如表1 所示。
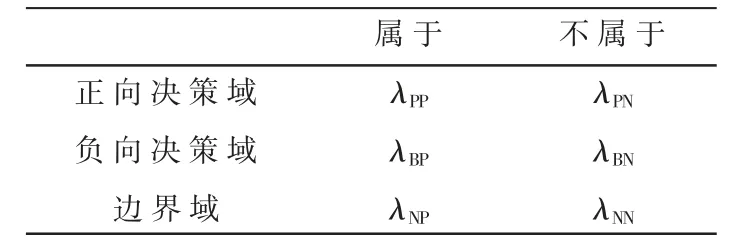
表1 决策损失函数
假 定0 ≤λPP≤λBP<λNP,0 ≤λNN≤λBP<λPN,式(3)和式(4)中的阈值计算公式可根据文献[11]的推倒证明而得到。
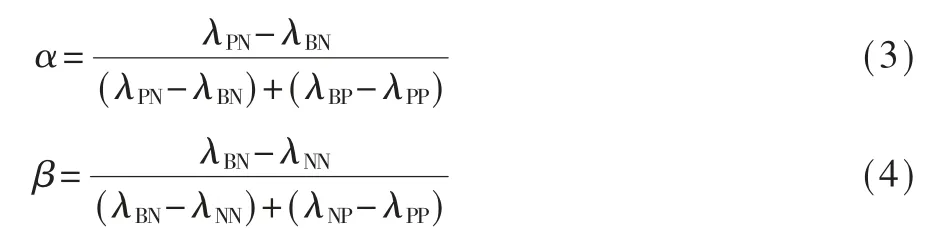
其中,0≤β≤α<1。根据工业控制网络环境,设置如下三条检测策略:
(1)如果P(X|[x])>α,将该数据划分入正向决策域,并认定该数据行为是入侵行为;
(2)如果P(X|[x])<β,将该数据划分入负向决策域,并认定该数据行为是正常行为;
(3)如果β≤P(X|[x])≤α,将该数据划分入边界域,即表示当前的信息缺乏,不足以对该数据行为进行正负域的即时决策。
其中,属性集中样本的等价类通过[x]进行表示,P(X|[x])指将等价类[x]分为X 的概率。
将三支决策与工控入侵检测结合,可以避免当目前的信息不足以支持做出明确的决策定论时而产生的误分类情况。显然,在工业控制网络的入侵检测中,如果将恶意的网络数据错分决策域,将导致致命性的后果。
2 入侵检测模型VAE-TWD
2.1 算法整体流程
VAE-TWD 算法的整体流程图如图2 所示,主要包括三个模块:数据预处理模块、变分自编码器特征提取模块和三支决策分类模块。
VAE-TWD 算法的具体步骤如算法1 所示。
算法1:VAE-TWD 算法
输入:数据X={x1,x2,…,xn};三支决策阈值α,β。
输出:网络数据分类结果。
初始化:网络参数φ,θ;代 价函数λPP,λPN,λNP,姿BP,姿BN,姿NN。

图2 基于VAE 和TWD 的工控入侵检测算法流程图
(1)数据预处理;
(2)训练变分自编码器,训练结束后编码器部分输出提取的特征;
(3)将步骤(2)中提取的特征输入三支决策分类模块;
(4)训练三支决策分类器,计算出每个数据样本属于正向决策域、负向决策域和边界域的具体概率p;
(5)将概率P(X|[x])同三支决策的阈值 琢,茁进行比较得出相应的决策结果,划分数据进入对应的决策域中;
(6)当边界域中不为空时,重复步骤(2)~(5)。
2.2 VAE 特征提取算法
变分自编码器利用概率理论将隐空间中经过编码后的特征概率表示出来,所以VAE 中的编码器职责转化为将输入的数据通过编码转换为在隐空间的概率分布,而不是单一地描述每个数据在隐空间的属性。
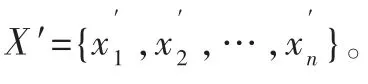
学习过程中将解码得到的重构数据与原数据进行比较,然后利用梯度下降法动态地调整VAE 中网络的权重和偏置,实现降低网络损失函数的目的,迫使VAE 进一步减小重构误差。学习完成后,所需的低维特征就是经过编码器降维后的数据。
选用SELU 函数作为VAE 网络的激活函数,RMSprop 为优化器,针对VAE 网络的权重参数通过梯度下降法来进行动态更新。
特征提取模块算法如下所示。
算法2:变分自编码器特征提取算法
输入:数据集X;网络循环次数M。
输出:X′(输入数据X 的低维特征数据)。
(1)随机初始化网络参数 渍,θ。
(2) For i=1:M
将获得的数据以概率p(k)传递给第k 个网络,计算相应的均值 滋渍与方差 滓渍;
计算后验分布q渍(z|Xi);
计 算KL 散 度DKL[q渍(z|Xi)||pθ(z|Xi)];
从q渍(z|Xi)中采样z;
计算重构误差损失Eq渍[logpθ(Xi|z)];
计算损失函数L(渍,θ,Xi);
使用梯度下降法更新参数 渍,θ;
End for
(3)根据步骤(1)~(2)得到网络参数,获取高维特征的低维表示,完成特征提取。
2.3 TWD 分类算法
当降维后的特征进入三支决策分类器时,通过设定好的阈值琢,茁对不同的特征进行即时决策,划分入对应的决策域中。同时,参照文献[12]定义三支决策域中关于损失函数的经验值,如表2 所示。
根据表2 所示的经验值,可以推导出式(3)和式(4)的相关阈值 琢,茁。
假设所有的数据样本集为X={x1,x2,…,xn},则需要计算出数据xi属于正向决策域的概率P(POS|xi),其中i=1,2,…,n。并将阈值 琢,茁 与p 值加以对比:如果p>琢,则将其分入正向决策域;假如p<茁,则将其分入负向决策域;若茁≤p≤琢,则分入边界域。
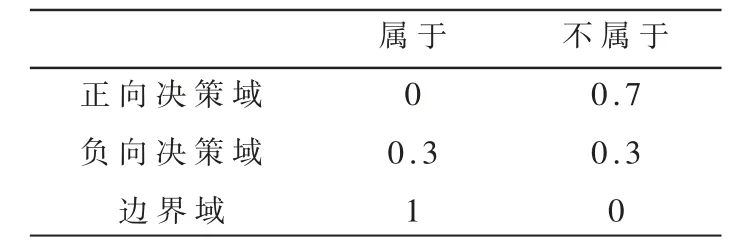
表2 损失函数的经验值
随着迭代次数的不断增多,编码器部分获取的特征将含括更多的信息来支撑三支决策分类器的决策,所以在VAE 中加入一个多粒度特征结构,用于提取更多的特征信息进一步提升分类器的决策速度。
如果边界域中的数据样本依然存在,将继续重复该过程,直至域内数据清空。
具体算法步骤如算法3 所示。
算法3:三支决策理论分类算法
输入:训练集Tx,测试集Ty。
输出:正向决策域POS,负向决策域NEG。
(1)初始化参数:VAE 特征提取方式G;初始化分类器f;三支决策阈值 琢,茁;正向决策域(POS)=负向决策域(NEG)=边界域(BND)=Ø。
(2)Do
Tx=G(Tx);Ty=G(Ty);
根据Tx训练模型f:

Until 测试集Ty为空
(3)输出:正向决策域POS,负向决策域NEG
3 实验分析
3.1 实验环境
本文提及的所有实验均在Ubuntu 16.04.7 系统上完成,具体硬件配置为:GPU GV100GL[Tesla V100S Pcle 32 GB],软件配置为:Python 3.9.2。
3.2 数据集介绍
为了评估VAE-TWD 算法在工控入侵检测中的综合性能,本文采用美国橡树岭国家实验室发布的天然气真实网络数据集[13]。该数据集的网络流量数据分别来自7 种恶意的网络攻击数据和正常的工控网络数据,在这其中已经定义好了1 个标签以及26 个特征。数据集中不同类别的数据具体分布如表3 所示。
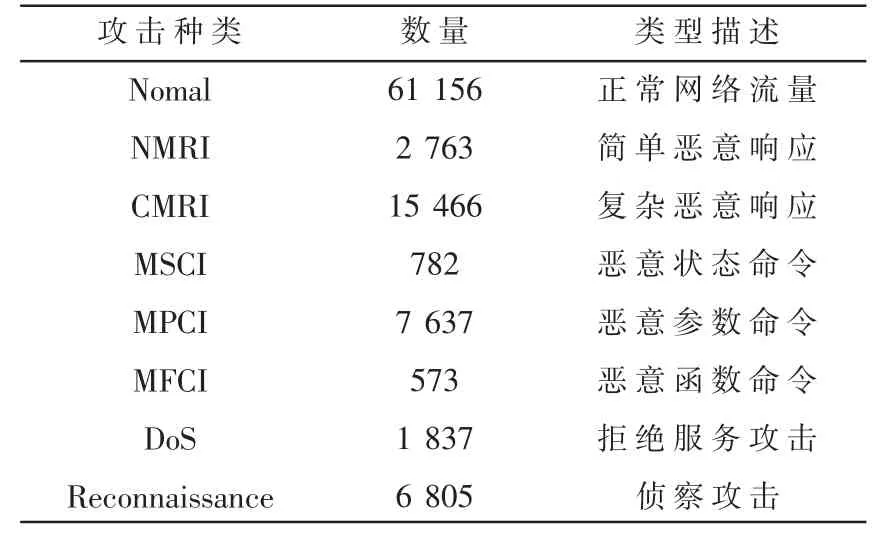
表3 数据集描述
在实验中,将所有的正常数据作为负类,所有异常数据作为正类(即需要被检测出的类)。本文所有实验均在相同数据集和相同实验环境中进行,同时,每个实验均重复进行5 次,并对得到的数据取均值,最终得到相应的实验结果。
3.3 数据预处理及评估指标
实验前进行如下数据预处理:
(1)删除缺失率高于0.7 的特征避免信息冗余和资源消耗。
(2)删去唯一值的特征。
(3)通过标准化处理来避免因数据差异较大导致的误差,并采用式(5)将特征值归一化至[0,1]区间。

其中,x 为原始值,x′为规范化值。
(4)生成特征向量。
(5)实行独热编码。
实验选用在入侵检测领域代表综合性能的误报率(False Positive Rate,FPR)[14]、准确率(Accuracy,ACC)、检出率(Detection Rate,DR)、精确率(Precison Rate,PR)以及F1-得分(F1-score,F1)[15]作为算法性能的评估指标,公式分别如下:
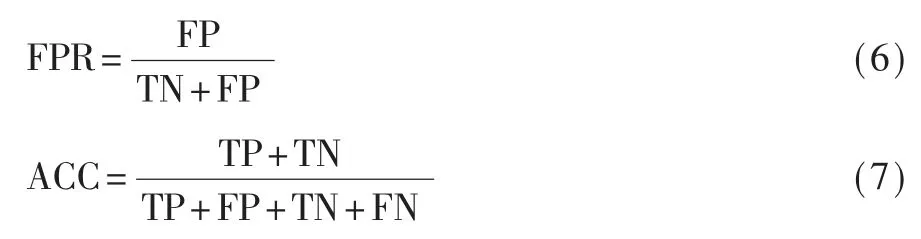

式中,TN 代表正常的网络行为被正确划分的数量;TP 代表恶意的网络行为被正确划分的数量;FP 表示正常的网络行为被错误划分的数量;FN 表示恶意的网络行为被错误划分的数量。
3.4 实验过程及结果分析
为了体现VAE-TWD 算法模型对比其他算法模型的性能优势,本文进行了3 个实验。实验一:限定特征提取方式为VAE 进行提取,对比不同决策分类器(二支决策与三支决策)的分类表现;实验二:限定TWD 为决策分类器进行分类,对比主流的特征提取方法与VAE 进行特征提取时的性能差异;实验三:对比VAE-TWD 算法模型与学术领域中其他研究人员所提出的几种算法模型之间的性能差异。
(1)实验一
此实验中,主要研究工控入侵检测和三支决策分类结合进行寻找恶意网络数据的优势,在确保变分自编码器不变的前提下,对比三支决策分类器与二支决策分类器:K 最近 邻(K-Nearest Neighbor,KNN),支持向量机(Support Vector Machine,SVM),深度神经网络(Deep Neural Networks,DNN)和随机森林(Random Forest,RF)[16]在工业控制网络入侵检测领域实现网络监测的综合性能。
表4 列出了在本文使用的数据集进行实验的性能对比结果。

表4 不同决策方法的实验结果对比
通过表4 的结果可得,相较于传统的基于二支决策方法,本文提出的VAE-TWD 算法模型在工控入侵检测领域,在准确率、检出率、精确率和F1 分数上具有明显优势。从上述结果可以看出将三支决策理论应用于工控安全入侵检测具有积极意义。
图3 显示了上述方法的ROC 曲线图。从图中结果发现,本文提出的VAE-TWD 算法模型的曲线更加接近(0,1)点,且VAE-TWD 算法模型的曲线下方面积明显大于其他的几种方法,进一步表明了三支决策理论在分类上的优越性。

图3 不同决策方法的ROC 曲线图
(2)实验二
此实验中,主要探究限定TWD 为决策分类器进行分类的前提下,当前主流的特征提取方法与VAE进行特征提取时的性能差异。对比的特征提取方法有奇异值分解(Singular Value Decomposition,SVD)[17]、核主成分分析(Kernel Principal Component Analysis,KPCA)[18]和深度信念网络(Deep Belief Network,DBN)。实验结果如表5 所示。

表5 不同特征提取模型的实验结果对比
通过观察表5 可得,本文所提算法VAE-TWD 有更高的准确率、检出率、精确率以及F1 得分。结果表明,通过变分自编码器中的编码器来描述每个隐属性的概率分布并提取特征的方法优于其他特征提取方法。
图4 的ROC 曲线对比图清楚地显示了上述特征提取方法的性能对比,从中可以看出,VAE-TWD算法模型的AUC 面积最大,进一步表明VAE-TWD
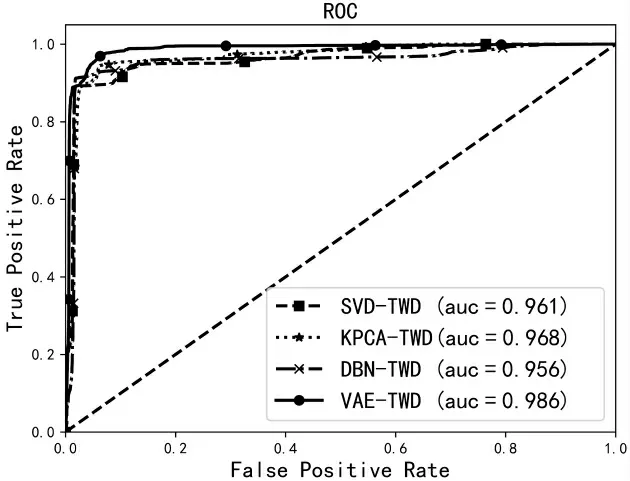
图4 不同特征提取模型的ROC 曲线图
算法模型能更加精确地进行特征提取。
(3)实验三
此实验中,主要对比VAE-TWD 算法模型和在工控入侵领域中其他研究人员研究的算法模型之间的性能差异。选用的算法模型包括:文献[4]提出的基于OCSVM 的工控入侵检测算法,文献[5]提出的基于CNN 和过程状态转换的工控入侵检测算法,文献[19]提出的改进TPOT 的工控入侵检测方法和文献[20]提出的DRL-IDS——基于深度强化学习的工业物联网入侵检测方法。
表6 显示了在实验数据集上,本文算法模型与其他算法模型的性能对比。

表6 不同工控入侵检测算法的实验结果对比
从表6 的结果可以得到,基于VAE-TWD 的算法模型在准确率、检出率、误报率以及F1 得分上均表现优秀,特别在检出准确率上,远远地超过了其他算法模型(所有实验均使用同一数据集和相同实验环境)。尽管在精确率上存在较小劣势,但是在总体综合性能上还是占据较大的优势。
本文提出的VAE-TWD 算法与对比算法的ROC曲线如图5 所示。
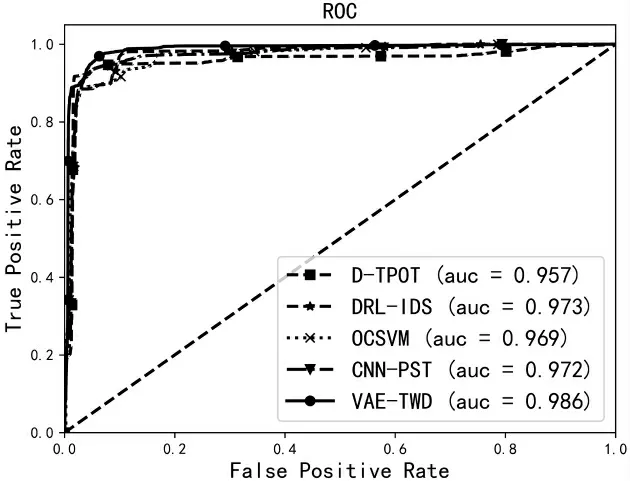
图5 不同工控入侵检测算法的ROC 曲线图
从图5 中可以看出,VAE-TWD 算法模型的ROC 曲线相较于其他对比模型更加接近于左上角的(0,1)点。同时,在图5 中VAE-TWD 算法模型的AUC 面积大于其他算法模型的AUC 面积。综合上述结果,进一步佐证了VAE-TWD 算法模型在工业控制网络入侵检测领域所具有的综合性能优势。
4 结论
提升工业控制网络数据的特征提取能力和分类准确率,对于工控入侵检测具有重要意义。本文提出的基于变分自编码器和三支决策的工业控制网络入侵防御检测算法,在特征提取部分利用变分自编码器在损失函数中添加正则项来返回高维数据在隐空间中的概率分布,再提取成低维抽象特征。在三支决策理论的基础上,划分经过提取的特征进入相应的决策域中,弥补了使用传统二支决策器分类的缺点。经过在真实天然气数据集上的多次实验可得,本文提出的VAE-TWD 算法的综合性能对比文中其他工控入侵检测算法的表现更优。但是,通过实验一与实验二的结果可知,VAE-TWD 算法在误报率方面存在一定劣势。在后续的工作中,将尝试加强数据间的相关性分析以及扩充负样本数量来降低误报率。未来工作的重点在于如何降低边界域决策时的时间成本,进一步提升决策速率和对更多数据集的泛化适用性。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
网络安全与数据管理(2022年1期)2022-08-29
网络安全与数据管理(2022年3期)2022-05-23
锻压装备与制造技术(2021年5期)2021-11-13
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
中国电子报(2019年75期)2019-01-16
