
一种高性能极化码SC译码器设计
2022-07-16 07:21王晓蕾戴吴骏杜高明李桢旻张多利
电子科技 2022年8期
王晓蕾,戴吴骏,杜高明,李桢旻,张多利
(合肥工业大学 微电子设计研究所,安徽 合肥 230601)
信道极化[1]的概念及极化码[2](Polar Code)分别于2008年和2009年被提出。极化码是目前唯一被证明可达信道容量的编码[3]方式,吸引了广泛的关注。2016年,极化码成为了5G移动增强宽带场景下控制信道编码方案。部分学者将极化码引入神经网络[4-6]加速器,促进了5G的发展。5G网络要求信息传输具有低延时[7]和大容量的特点,同时使用的芯片资源越少越好。因此设计低延时、高吞吐率[8]和高资源效率[9]的极化码译码器已成为趋势。
文献[2]提出的串行抵消(Successive Cancellation,SC)译码算法采用串行译码方式造成高延时。根据该算法设计的SC译码器采用蝶形译码架构,造成了资源浪费。简化串行抵消[10](Simplify SC,SSC)译码算法对已知是冻结比特的结点不再译码,直接判定译码结果为0。预计算简化串行抵消[11](Precomputation SSC)译码算法将SSC译码算法的周期进一步减少,通过减少译码周期,降低了延时,提高了吞吐率。相比于传统蝶形SC译码器,研究人员根据降阶串行抵消(2b-SC)译码算法设计的译码器[12]在延时、吞吐率以及资源消耗方面均有所改进。流水线架构的SC译码器[13-14]通过复用对数似然比计算单元(Process Element,PE)减少了资源浪费。
上述算法都是从单个角度解决问题,没有充分压缩译码周期和发掘电路性能,因此无法满足5G通讯的要求。本文从算法和电路两个层面减少译码周期,实现低延时和高吞吐率,并从PE单元复用角度设计电路,实现高资源效率。本文的研究主要集中在以下3个方面:
(1)通过剪枝冻结比特结点的方式化简SC译码二叉树,减少译码冻结比特消耗的周期。设计PE单元存储模块,存储对数似然比(Log Likelihood Ratio,LLR),后续阶段可以直接调用该模块存储的计算结果,减少再次计算LLR需要的译码周期。在译码最终阶段采用2b-SC算法,该算法采用组合电路,因此不消耗译码周期,可进一步减少总的译码周期;
(2)设计资源复用的硬件电路结构,假设码长为N,该译码器所需要的PE单元为N/2个,将PE单元组合成PE阵列。译码到某个阶段时,如果子码的长度为Nv,那么只需激活前Nv/2个PE单元参与计算,提高了资源效率;
(3)本文设计了码长为1 024,信息位为512的SC译码器,采用专用集成电路(Application Specific Integrated Circuit,ASIC)方式实现。在华润上华(CSMC)180 nm和中芯国际(SMIC)40 nm标准工艺下完成电路测试。结果表明译码周期仅为330,吞吐率达到388.85 Mbit·s-1和343.60 Mbit·s-1,资源效率为2.204 Mbit·s-1·kGE-1(kGE=1 000个与非门)和1.949 Mbit·s-1·kGE-1,译码器性能得到了显著提升。
1 SC与SSC译码算法分析
1.1 SC译码算法
利用码长为N,信息位为K的极化码可以构建深度log2N的译码二叉树。如图1所示,图中白色叶子结点表示单个冻结比特,黑色叶子结点表示单个信息比特。从叶子结点向上递归,对于任何一个结点,如果左右孩子结点都是冻结比特结点,则父结点也是冻结比特结点;如果左右孩子结点都是信息比特结点,则父结点也是信息比特结点,否则就是混合比特结点,即图中灰色结点。定义译码二叉树的叶子结点深度为0,根结点的深度为log2N。
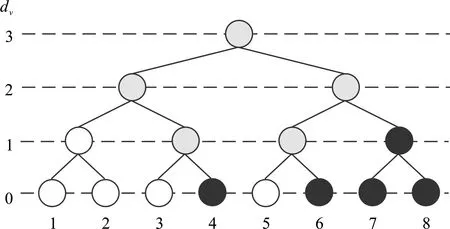
图1 (8,4)译码二叉树Figure 1. (8,4) decoding binary tree
SC算法译码过程是一个满二叉树深度优先遍历的过程,译码所有叶子结点得到的结果就是最终的译码序列。遍历二叉树的串行特点导致译码周期消耗多,延时大,吞吐率低。如图2所示,SC译码流程按照图中虚线箭头所示路径进行遍历,总的译码周期为τd=2×(N-1)。
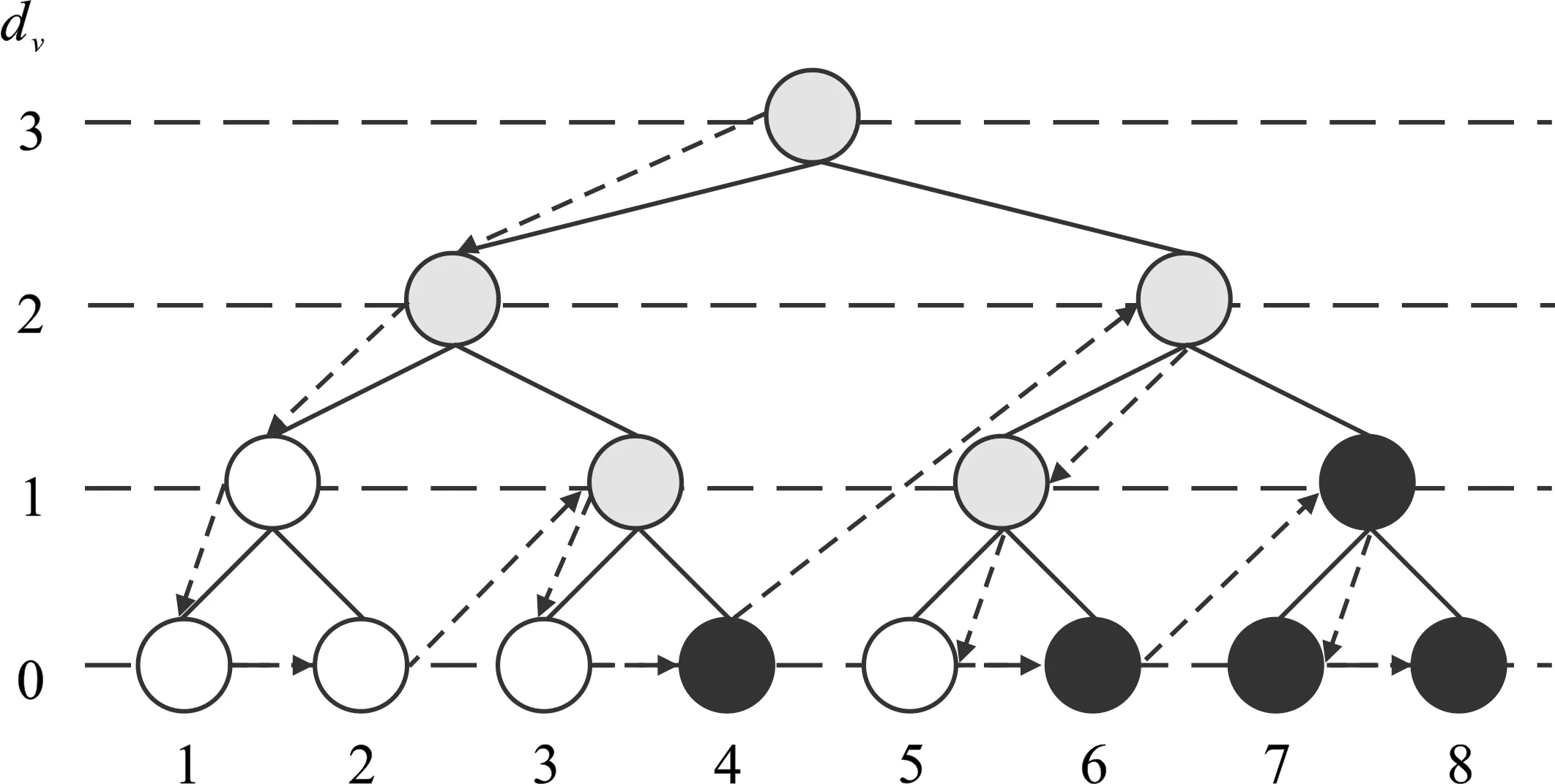
图2 SC译码算法流程Figure 2. The process of SC decoding algorithm
1.2 SSC译码算法
文献[10]提出了SSC译码算法。此算法对冻结比特不进行译码,直接判决译码比特为0,减少了译码冻结比特消耗的周期,使得总译码周期减少。具体译码遍历流程描述为以下步骤:
步骤1确定译码二叉树深度;
步骤2二叉树进行深度优先遍历,确定译码结点在二叉树上的深度dv,每层结点LLR数目为Nv=2dv,如果孩子结点是冻结比特结点,则直接返回码长为Nv/2的冻结比特序列(Nv≥2),否则继续进行深度优先遍历;
步骤3完成最后一个结点遍历,译码结束。

图3 SSC译码算法流程 Figure 3. The process of SSC decoding algorithm
为了更加清晰地了解SSC译码算法译码流程,以图3译码二叉树进行说明:
步骤1确定译码二叉树深度为3;
步骤2二叉树进行深度优先遍历,从根结点到叶子结点的深度分别为3、2、1、0;对应码长分别为8、4、2、1;根结点的左右孩子结点都是混合比特结点,所以根据路径①遍历到达左孩子结点。由于此结点的左孩子结点是冻结比特结点,所以根据路径②遍历右孩子结点,以此类推,根据路径③~⑨遍历剩余二叉树结点;
步骤3完成最后一个结点遍历,译码结束。
2 译码算法优化
2.1 2b-SC译码算法
文献[12]提出了2b-SC算法。该算法根据输入LLR(a)和LLR(b)的不同分成4种情况:
(1)当译码比特序列都属于冻结比特集时,译码结果都为0;
(2)当译码比特序列只有2i-1属于冻结比特集时,如果输入的LLR之和大于等于0,则译码结果都为0,否则2i-1对应的译码比特为0,2i对应的译码比特为1;
(3)当译码比特序列只有2i属于冻结比特集时,如果输入的LLR符号位乘积大于等于0,则译码结果都为0,否则2i-1对应的译码比特为1,2i对应的译码比特为0;
(4)当译码比特序列都不属于冻结比特集时,如果输入的LLR符号位乘积大于等于0,则2i-1对应的译码比特为0,否则2i-1对应的译码比特为1,2i对应的译码比特一直为LLR(a)的符号位。

2b-SC算法Inputs: (LLR(a) && LLR(b) from (n-1)th decoding stage)Description:(get^u2i-1 && ^u2i)Case 1:2i-1 && 2i belong to froze bits set^u2i-1=0, ^u2i=0Case 2:only 2i-1 belong to froze bits set if LLR(a) + LLR(b)≥0^u2i-1=0, ^u2i=0 else^u2i-1=0, ^u2i=1Case 3:only 2i belong to froze bits set if sign(LLR(a))sign(LLR(b))≥0^u2i-1=0, ^u2i=0 else^u2i-1=1, ^u2i=0Case 4: none of them belong to froze bits set if sign(LLR(a))sign(LLR(b))≥0^u2i-1=0, ^u2i=sign(LLR(a)) else^u2i-1=1, ^u2i=sign(LLR(a))Outputs: ^u2i-1,^u2i
如图4所示,当译码二叉树遍历深度为1时,该深度结点存在两个LLR,采用2b-SC算法可以同时得到两个译码比特。
2.2 SC译码算法优化
本文对SC译码算法进行优化,具体的译码算法步骤如下:
步骤1确定码长N、信息位K以及构造方法,所需PE数目为N/2,输入来自信道的{LLR1,LLR2,…,
LLRN};
步骤2深度优先遍历译码二叉树,当译码深度为log2N~1时,对每层译码结点进行遍历,确定译码结点在二叉树上的深度dv。如果深度在log2N与2之间,则对应该结点的对数似然比数目为Nv=2dv,需要激活前N(PE)=(N/2)×2dv个PE单元。如果该译码结点的孩子结点为冻结比特结点,则直接返回码长为Nv/2的冻结比特序列,否则继续进行深度优先遍历。遍历到深度为1的结点时,直接利用2b-SC译码算法进行译码,得到两个译码比特;
步骤3遍历完最后一个深度为1的结点,译码结束。

图4 优化的SC译码算法流程Figure 4. The process of optimized SC decoding algorithm
为了更加清晰地了解译码过程,以图4所示的二叉树进行说明。输入LLR后,需要4个PE单元,遍历路径①时,消耗1个周期,计算得到的LLR输入存储阵列,供路径②和根结点的右孩子结点使用。遍历路径②也消耗1个周期,然后直接利用2b-SC译码算法得到译码比特。遍历根结点的右孩子结点不消耗周期。遍历路径③时,消耗1个周期,得到的LLR可以供5、6、7、8号译码比特使用。因此,总的译码周期为3。
3 优化的SC译码算法硬件实现
3.1 整体架构
本文提出的SC优化译码算法的硬件架构如图5所示,为了方便说明,本文设定N=8。
该硬件电路主要有6个模块:对数似然比计算模块、数据存储模块、数据选择模块、部分和模块、控制器模块以及P结点模块。本文采用对数似然比模块对输入的LLR进行计算,将所得结果作为下一阶段输入的LLR或者传递到P结点模块。数据存储模块用来存储对数似然比计算模块产生的数据,该模块受时序控制,可以保持数据存续多个周期,如果下次需要数据,可直接从该模块取出,无需再次计算。数据选择模块用来选择下一阶段计算所需要的数据。部分和模块用来计算g函数的指数项u_s。控制器模块对整个电路的数据分配以及周期跳转进行控制。P结点模块用来计算最后一阶段的LLR,该阶段可以同时译码两个比特。

图5 优化的SC译码算法硬件架构Figure 5. The hardware architecture of optimized SC decoding algorithm
3.2 对数似然比计算模块
对数似然比计算模块是指图5中的PE阵列,将PE单元分别标号PE1~PE4。PE单元由两个函数组成,分别是f函数与g函数,其中a为LLR(a),b为LLR(b),us为u_s,取值为0或1。
(1)
g(a,b,us)=(-1)usa+b
(2)
为了方便实现硬件电路,将上述数学表达式修改为如下3个函数。
f=sign(a)sign(b)min(|a|,|b|)
(3)
g0=a+b
(4)
g1=b-a
(5)
对于二叉树某一节点的左孩子结点,本文采用f函数进行计算。对于右孩子结点,则根据之前译码出的部分比特用g0或者g1函数计算。将这3个函数的电路融合在一起构成一个对数似然比计算模块,即一个PE单元。

图6 PE单元Figure 6. PE unit
如图6所示,PE输入输出都是2的补码形式。g0和g1函数直接利用加法器和减法器进行运算。f函数先将输入的LLR(a)和LLR(b)通过补码转符号量(C2S)转换成绝对值表达形式,再选择出两个绝对值中较小的一个,通过符号量转补码(S2C)转成补码形式,取补码数值部分;然后由两个输入LLR的最高位MSB(sign(LLR))通过XOR异或构成符号位;最后将符号位与补码数值部分拼接起来,得到f函数的计算结果。
3.3 数据存储阵列模块
数据存储模块是指图5中的数据存储阵列。该模块受时钟信号控制,且模块的大小与码长有关。当二叉树的深度为1~log2(N-1)时,每级深度的单类型存储容量为2dv,因为每级都要存储f、g0以及g1的计算结果,所以该级总的存储容量为3×2dv。因此对于一个码长为N的译码电路,该电路的存储容量为3×(N-2)。

图7 二叉树与存储单元对应关系Figure 7. The relationship between decoding binary tree and storage
如图7所示,图中深度为0的矩形表示P结点,无需存储计算结果;深度为1时,该级容量为3×2;深度为2时,该级容量为3×4,总的存储容量为18。
3.4 选择阵列模块
数据选择模块是指图5中的选择阵列。它用来选择下一阶段所需要的LLR。如图4中的路径①,计算得到的LLR通过数据选择器选择出路径②计算所需的LLR。单个数据选择器如图8所示。

图8 数据选择器Figure 8. Data selector
数据选择模块的输入数据为前一级计算得到的LLR,当u_s取0时,数据选择器选择g0输出,否则选择g1输出。将选择出的数据输入下一级数据选择器,当f_s为0时,选择f输出,否则输出上一级数据选择器选择的值。f_s为0表示选择二叉树的左孩子结点译码,否则对右孩子结点译码。数据选择阵列需要N/2个数据器,数据选择模块激活的数量随着深度的降低可成倍数降低。
3.5 部分和模块
部分和模块用来计算g函数的指数项u_s,决定下一阶段计算的数据是g0还是g1。为了使该模块在产生译码比特时就能刷新电路,将该模块设计为组合电路,具体电路结构如图9所示。

(a) (b)图9 部分和模块Figure 9. Partial sum accumulation module
传统的SC部分和模块如图9(a)所示,该模块每译码1 bit就刷新电路,得到新的u_s。由于优化的译码算法在获取信道的LLR时已知信道分布,且冻结比特信道传输0,因此部分和电路可以化简为如图9(b)所示的形式。经过简化得到的部分和模块随着码长的增加,减少的加法器数量显著增加。
3.6 控制器模块
控制器模块主要用来控制电路的状态转移,也具有数据分配等辅助功能。电路的状态转移如图10所示。当Stage_en1激活时,遍历图4中的路径①,同时在图10中周期上标注了①。当Stage_en2激活时,遍历图4中的路径②,译码两个比特,同时在图10中周期上标注了②。当Stage_en3激活时,遍历图4中的路径③,同时在译码4个比特,在图10中周期上标注了③。当Stage_en4激活时,输出译码结果。

图10 控制器模块与译码关系Figure 10. The relationship between controller and decode
3.7 P结点模块
P结点模块采用2b-SC译码算法,在译码的最后一个阶段同时译码2 bit,加快译码速度。如图11所示,首先根据fr1、fr2决定使能信号。如果使能信号激活,则再根据LLR进行判断,具体关系如表1所示。

图11 P结点Figure 11. P node

表1 P结点译码真值表Table 1. P node decoding truth table
4 实验结果与分析
本文设计了码长为1 024,信息位为512的SC译码器,所需PE数目为512,译码周期为330。在SMIC40 nm工艺下测试得到电路数据,如表2所示,其中时钟频率为250.6 MHz,资源效率为2.204 Mbit·s-1·kGE-1,面积为0.18 mm2,电路门数为176 460,吞吐率为388.85 Mbit·s-1,在电压为1.21 V的情况下功耗为19.89 mW。

表2 译码器在SMIC 40 nm工艺下的综合结果Table 2. Comprehensive results of decoder under SMIC 40 nm process
为了保证对比分析的公平性,本文在CSMC 180 nm工艺下测试了电路,实验对比结果如表3所示。其中clk是时钟周期,即1 clk=1/Frequency ns。对比对象全部采用SC译码算法,但是采用的硬件结构各不相同。文献[15]采用了半并行架构,虽然PE可以进行复用,提高了资源效率和吞吐率,但是每次译码只能译码一位数据,效率的提升幅度有限。文献[16]采用了带有P结点的树型架构,虽然可以加快译码速度,提高译码吞吐率,但是由于PE消耗太多,因此不适合提高资源效率。文献[17]采用了PE位宽扩展的树型译码架构,同样提高了译码吞吐率,加快了译码速度,但也存在资源效率不高的问题。与文献[15~17]相比,提出的译码器译码周期分别减少了78.85%、78.48%和78.48%;吞吐率分别提升了601.22%、130.60%和172.70%;资源效率分别提升了629.96%、285.94%和296.14%。

表3 译码器在180 nm工艺下的结果对比Table 3. Comparative results of decoder in 180 nm process
译码器的功耗[18-19]也是一个重要的研究参数。本文中,3组译码器的功耗比较如表4所示,文献[15]所提的译码器在工作电压为1.5 V时的功耗为67 mW;文献[16]所提出的译码器在工作电压为1.8 V时的功耗为1 072.9 mW;在CSMC 180 nm工艺下,本文提出的译码器在工作电压为1.61 V时的功耗为200 mW。

表4 译码器在180 nm工艺下的功耗对比Table 4. Comparisons of decoder power in 180 nm process
5 结束语
本文提出了优化的高性能SC译码算法以及硬件架构。首先对译码二叉树进行了简化,设计了PE单元存储模块;然后融合了2b-SC算法,设计了资源复用的对数似然比计算模块;最终设计了码长为1 024,信息位为512的SC译码器,并在CSMC 180 nm和SMIC 40 nm标准工艺下完成ASIC实现和电路测试。测试结果表明,该算法可以显著降低延时,提升吞吐率与资源效率,从而提升译码器的性能,增强译码器的实用性。但是,文本所提新模型的电路功耗仍然有改善的空间,低功耗极化码SC译码器也将是未来的重点研究方向之一。
猜你喜欢
深圳大学学报(理工版)(2022年5期)2022-09-27
电子制作(2022年16期)2022-09-23
舰船电子工程(2022年7期)2022-09-06
沈阳工业大学学报(2021年6期)2021-11-29
现代计算机(2021年14期)2021-07-09
现代电子技术(2021年7期)2021-04-08
现代计算机(2021年36期)2021-03-14
计算机与数字工程(2020年8期)2020-10-14
科技视界(2018年27期)2018-01-16
时代英语·高一(2017年5期)2017-11-14
