
基于自编码器与集成学习的离群点检测算法
2022-07-29 08:22郭一阳于炯杜旭升杨少智曹铭
计算机应用 2022年7期
郭一阳,于炯,2*,杜旭升,杨少智,曹铭
基于自编码器与集成学习的离群点检测算法
郭一阳1,于炯1,2*,杜旭升1,杨少智1,曹铭3
(1.新疆大学 信息科学与工程学院,乌鲁木齐 830046; 2.新疆大学 软件学院,乌鲁木齐 830091; 3.中国海洋大学 信息科学与工程学院,山东 青岛 266100)( ∗ 通信作者电子邮箱yujiong@xju.edu.cn)
针对基于自编码器的离群点检测算法在中小规模数据集上易过拟合以及传统的基于集成学习的离群点检测算法未对基检测器进行优化选择而导致的检测精度低的问题,提出了一种基于自编码器与集成学习的离群点检测(EAOD)算法。首先,随机改变自编码器的连接结构来生成不同的基检测器,以获取数据对象的离群值和标签离群值;然后,通过最近邻算法计算数据对象之间的欧氏距离,并在对象周围构建局部区域;最后,根据离群值与标签离群值之间的相似度,选择在该区域内检测能力强的基检测器进行组合,组合后的对象离群值作为EAOD算法最终判定的离群值。在实验中,所提算法与自编码器(AE)算法相比,在Cardio数据集上,接受者操作特征曲线下方的面积(AUC)和平均精度(AP)分值分别提高了8.08个百分点和9.17个百分点;所提算法与特征装袋(FB)集成学习算法相比,在Mnist数据集上,运行时间成本降低了21.33%。实验结果表明,在无监督学习下所提算法具有良好的检测性能和检测实时性。
离群点检测;集成学习;自编码器;基检测器;无监督学习
0 引言
离群点是指那些与数据集中绝大多数对象的产生机制不同的、偏离程度较大的数据对象[1]。离群点检测算法通常用于解决金融欺诈检测、网络入侵检测、医疗辅助诊断等问题[2-4]。
由于现实环境中往往缺乏数据集对应的标签,因此在离群点检测算法中通常采用无监督学习的方式[5]。近十年,深度学习在数据挖掘领域蓬勃发展[6]。基于自编码器的离群点检测算法利用神经网络的强大学习能力,学习输入数据的模式,最后将那些在自编码器的输出层中难以重构的对象判定为离群点。但该算法在中小规模数据集上容易产生过拟合问题,导致算法的检测精度低[7]。在集成学习中,不同的基检测器各自产生独立误差,将多个基检测器进行组合,可以降低单一基检测器的过拟合风险[8]。因此,将自编码器与集成学习相结合可以有效地降低过拟合风险。实际上,设计产生独立误差的集成学习框架具有一定的挑战性。动态分类器选择(Dynamic Classifier Selection, DCS)算法[9]有效地缓解了这个具有挑战性的问题,其基本思想是平衡集成学习中基检测器的准确性和多样性两者之间的关系。DCS算法生成多个且不同的基检测器,同时尽可能地提高基检测器的准确性,达到准确识别离群点的目的。DCS算法的检测效果取决于对基检测器局部区域检测能力的正确评估,如果在该局部区域内不能正确评估基检测器的检测能力,那么将导致检测精度低的结果。动态集成选择(Dynamic Ensemble Selection, DES)算法[10]通过优化选择一组基检测器的方式,并通过一些规则(如投票规则)将该组基检测器进行有效组合,解决了不能正确评估基检测器检测能力的问题。
受DCS和DES两种算法的启发,本文提出了基于自编码器与集成学习的离群点检测(Ensemble learning and Autoencoder-based Outlier Detection, EAOD)算法。由于数据对象之间在数据集中分布彼此有关联,EAOD算法假设一组基检测器在数据的邻近对象上检测能力良好,那么该组基检测器在该数据上的检测能力也同样良好。EAOD算法的主要流程为:首先使用随机连接的自编码器作为集成学习框架中的基检测器,初始化训练集数据对象的离群值,生成离群值矩阵和标签离群值矩阵;其次根据各个数据对象之间的欧氏距离在测试集数据对象周围生成一个局部区域;最后在该局部区域内,根据离群值矩阵和标签离群值矩阵计算数据对象余弦相似度,通过对比余弦相似度,选择检测能力强的基检测器进行组合,组合后的对象离群值作为EAOD算法最终判定的离群值。
本文算法的主要贡献如下:
1)提出了一种随机改变自编码器连接结构的方式。在EAOD算法中,通过对相邻隐藏层中的神经元进行有放回随机采样,使得神经元之间的一部分连接临时性地消失,达到随机改变自编码器连接结构的目的。
2)提出了一种在无监督学习下标记数据离群程度的方式。EAOD算法假设在不存在数据真实标签的情况下进行离群点检测,取全部基检测器对数据输出值的最大值作为数据离群程度的标签。
3)提出了一种在构建的数据对象局部区域内选择合适的基检测器进行组合的方式。EAOD算法以定义邻域簇的方式构建数据局部区域,在该局部区域内计算基检测器上数据对象的离群值与标签离群值之间的余弦相似度,根据该相似度大小选择合适的基检测器进行组合。
1 相关研究
从分类的角度,可以将现阶段的离群点检测算法分类为:1)基于统计;2)基于相似度;3)基于分类;4)基于聚类;5)基于神经网络;6)基于集成学习。值得注意的是,某些算法可能被划分到不止一类中。
1)基于统计的离群点检测算法通过对数据集中数据的分布情况做出假设,假定数据有一个已知的基本分布或统计模型,离群点则属于基本模型中概率较低的对象。例如:基于直方图的离群分数(Histogram-Based Outlier Score, HBOS)算法[11]假设数据在每个维度具有独立性,对每个维度做出直方图进行密度估计。该类算法常用到假设检验或极值分析,其主要缺点是假设性强,效果与真实情况的匹配程度低。
2)基于相似度的离群点检测算法针对正常点和离群点在数据集中分布不同的特点,通过数据对象之间的相似度(如:距离、密度等)检测离群点。例如:最近邻(-Nearest Neighbors,-NN)算法[12]通过计算数据对象之间的距离,得到数据对象的离群值等于该对象到它的第个近邻的距离;局部离群因子(Local Outlier Factor, LOF)算法[13]通过评估数据集中数据对象与其近邻的局部密度偏差,偏差较大的数据对象被定义是离群点。该类算法对数据对象的维度较为敏感,当对象维度较高时,该类算法检测性能较差。
3)基于分类的离群点检测算法通过在数据集中不断学习,找出有规律的决策边界或超平面,得到的决策边界或超平面所包含的少数数据对象被定义是离群点。该类算法的主要缺点是耗费时间长,且在稀疏数据集上效果较差[14]。
4)基于聚类的离群点检测算法首先计算数据对象到它在距离上最近的簇的质心之间的距离,其次根据该距离对数据对象赋予离群值,最后离群值越高的数据对象是离群点的可能性越高。该类算法的主要缺点是其寻找的是数据对象周围的簇,不是发现离群点,检测精度低[15]。
5)基于神经网络的离群点检测算法通过学习输入数据的模式,在输出层重构数据,以产生的重构误差作为对象的离群值。该类算法的主要缺点是其在中小规模数据集上容易产生过拟合问题,导致算法的检测精度低[16]。
6)基于集成学习的离群点检测算法通过组合多个不同的基检测器的输出,得到精确的结果。其基本思想是执行多个不同的基检测器,产生不同的输出值,对该多个不同的输出值进行评估,权衡偏差和方差。例如:文献[17]设计了多个不同的基检测器,增加模型的多样性,提升检测效果。该类算法的主要缺点是对集成学习中基检测器的多样性要求较高,若基检测器不满足一定程度的多样性,则该算法不能保证多个不同的基检测器的组合输出比单个检测能力强的基检测器输出更精确[18-19]。
2 本文方法
本章首先给出EAOD算法整体框架与流程,然后介绍EAOD算法中基检测器的体系结构及配置,最后给出EAOD算法的详细步骤和时间复杂度分析。表1详细列出了本节后续内容所使用的符号定义。

表1 符号说明
2.1 算法整体框架与流程
基于自编码器与集成学习的EAOD离群点检测算法分为4个阶段实现:1)训练基检测器。将随机连接自编码器作为集成学习中的基检测器,并使用训练集训练基检测器。2)标记离群程度。在训练集的数据对象上标记标签作为对象的离群程度。3)构建局部区域。在测试集数据周围构建局部区域。4)基检测器选择与组合。在该局部区域选择合适的基检测器进行组合,组合后的对象离群值作为EAOD算法最终判定的离群值。EAOD算法整体的框架与流程如图1所示。

图1 EAOD算法框架与流程
2.2 基检测器的体系结构及配置
2.2.1随机连接自编码器
自编码器是一种特殊类型的多层前馈神经网络,具备对数据进行分层和非线性降维功能。如图2所示,自编码器的输入层节点数等于输出层节点数,隐藏层的节点数相对较少;在体系结构上,自编码器是分层且对称的。自编码器的目标是通过训练神经网络,最小化输出层误差进而重构输入层。
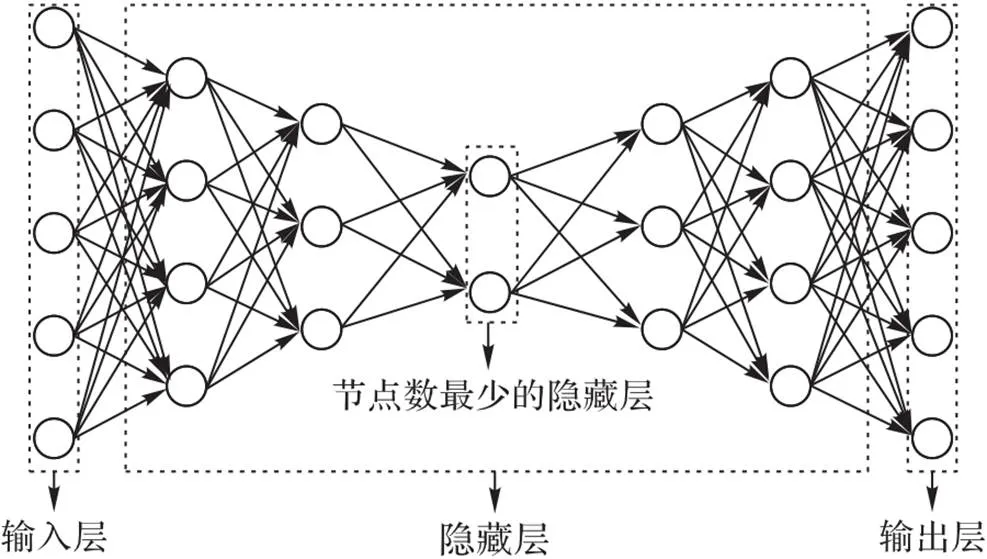
图2 自编码器模型
随机连接自编码器是一种随机改变自编码器的连接结构而产生的多层前馈神经网络。如图3所示,输入层节点数等于,从输入层到节点数最少的隐藏层,其中相邻两层之间的节点数比值为,从节点数最少的隐藏层到输出层,采用与从输入层到节点数最少的隐藏层相对应的完全对称结构。
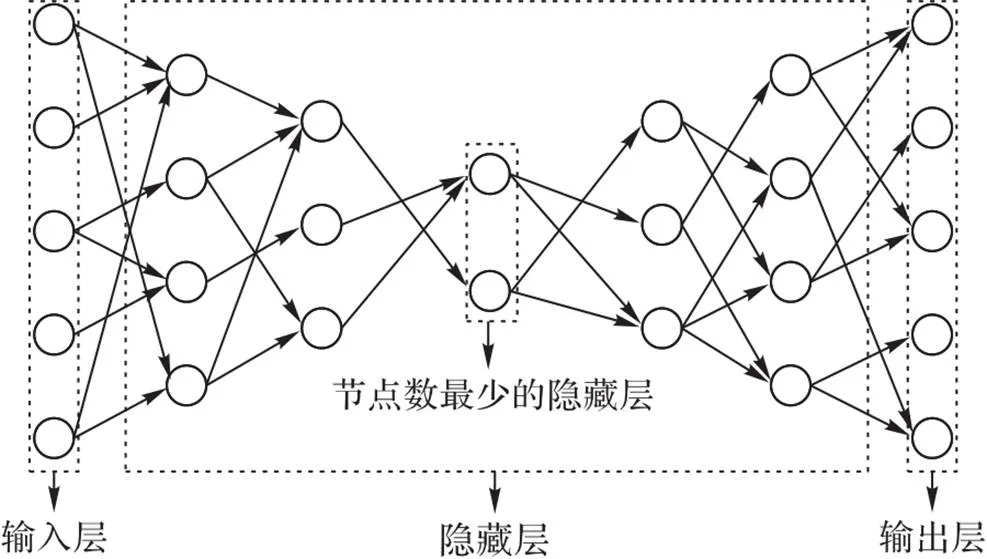
图3 随机连接自编码器模型

2.2.2激活函数
自编码器中的每一个节点都会对输入使用一个线性函数计算,激活函数将一个非线性函数应用在线性函数的输出结果上。实际上,在神经网络中应用两种不同的激活函数比应用一种固定的激活函数效果相对要好,由于在神经网络不同层之间使用两种不同的激活函数可以平衡不同激活函数之间的利与弊。
在自编码器中,在最接近输入层的隐藏层中和输出层中使用Sigmoid激活函数。Sigmoid激活函数计算公式如式(1)所示:

在其余隐藏层中,使用整流线性单位(Rectified Linear Unit, ReLU)激活函数。ReLU激活函数计算公式如式(2)所示:

Sigmoid激活函数会引起梯度消失问题,且它的计算代价高于ReLU激活函数。ReLU激活函数计算公式相对简单且计算代价相对较小,不存在梯度消失问题,但ReLU激活函数触发的神经网络权值更新可能导致神经元失活,使其他神经元处于停工状态,神经网络权值更新停滞。为了解决两个激活函数导致的问题,在自编码器中最接近输入层的隐藏层中和输出层中使用Sigmoid激活函数,在其余隐藏层中使用ReLU激活函数。这样做的目的是:其一,若自编码器处于最坏的情况,即使用ReLU激活函数的神经节点全部失活,至少可以保证自编码器两端的神经节点正常工作;其二,ReLU激活函数引起的问题往往发生在梯度非常大的情况下,Sigmoid激活函数引起的梯度消失问题有助于抑制ReLU激活函数所带来的负面作用。
2.2.3权值更新
在自编码器上更新权值使用了一种自适应学习方法——均方根传播(Root Mean Square propagation, RMSprop)。RMSprop自适应学习方法是利用最新的梯度大小来标准化梯度的一种优化器。
权值更新计算公式如式(3)(4)所示:


其中:w是在时刻的移动平均梯度;是调节自适应学习水平的参数,设置为0.9;g是在时刻的梯度;W是在时刻的权值;是学习率,初始值设置为0.02;是非常小的数值,其作用是避免零除。
2.3 算法详细步骤
2.3.1训练基检测器
在集成学习中,只有基检测器具有较高的个体质量,同时具有互补性,集成学习才能正常工作。实际上,由于预知基检测器的适用区域不易实现,因此,侧重于生成多样化的基检测器成为普遍做法,以实现模型学习不同的数据特征。在此,本文使用自编码器作为基检测器,变换其网络体系结构以产生差异性,实现基检测器多样化的目标。
在训练基检测器后,由于不同的基检测器具有不相同的量纲,故应对基检测器输出进行归一化处理,以提高收敛速度。归一化处理具体过程:数据减去其均值,并除以方差,使处理后的数据满足标准正态分布。归一化公式如式(5)所示:

首先,将数据集(m+n)×d随机划分成两部分:60%训练集X×d和40%测试集Y×d;其次,使用随机连接自编码器作为基检测器构建具备多样性的集成学习模型,把X×d放入该集成学习模型训练;最后对集成学习中每个基检测器输出结果做归一化处理,生成离群值矩阵。离群值矩阵只针对X×d中的数据,离群值矩阵如表2所示。
表2离群值矩阵

Tab.2 Outlier value matrix
本阶段涉及的局部变量及函数:表示1×num_detector中每个基检测器的列位置,split()表示对数据集(m+n)×d进行随机划分,init()表示初始化基检测器,train()表示由X×d训练基检测器。具体算法如下:
算法1 base_detector_training((m+n)×d,1×num_detector)
1)=1
2)X×d,Y×dsplit((m+n)×d)
3) while≤do
4) init(1×num_detector)
5) train(X×d,1×num_detector)
6)×num_detector.append(train(X×d,1×num_detector)
7)++
8) end
9) output(×num_detector)
2.3.2标记离群程度
在绝大多数的实际应用场景下,进行离群点检测所遭遇的核心挑战是数据标签的缺失。这引起了无法有效地衡量基检测器的预测结果与缺乏标签的数据离群程度之间差异的问题。其解决思路只能从缺乏标签的正常数据和离群数据组成的混合数据出发。通常情况下,模型学习数据特征后,对数据输出的离群值越大,该数据是离群点的可能性越大。因此,本文提出了一种从原始训练数据中生成伪离群值的方法,即定义了标签离群值这一概念:对于X×d中的某个数据,可从算法1输出的离群值矩阵中获取个不同的基检测器对其计算所得的个不同的离群值,从该个离群值中取最大值作为衡量该数据的离群程度。
由于模型学习数据特征后所得到的输出值通常包含离群值,因此,本文所提标记离群程度的方法符合工业实际场景。
定义1 标签离群值。X×d中数据的标签离群值等于个基检测器对该数据进行计算输出的最大值。其计算公式如式(6)所示:

根据式(6)计算得到X×d中所有数据的标签离群值矩阵,如表3所示。
表3标签离群值矩阵

Tab.3 Outlier label value matrix
本阶段涉及的局部变量及函数:表示X×d中每个数据的行位置,表示临时存储变量,getMax()表示使用式(6)获取在×num_detector中第行的最大值。具体算法如下:
算法2 label_computing(×num_detector,X×d)
1)=1
2)0
3) while≤do
4)=getMax(×num_detector,)
5)×1.append()
6)++
7) end
8) output(×1)
2.3.3构建局部区域
在测试阶段,EAOD算法首先要构建局部区域,这是因为:由于数据对象之间在数据集中分布彼此有关联,EAOD算法根据基检测器在测试数据的邻近对象上的检测能力来估计该基检测器在上的检测能力,因此,EAOD算法需要在局部区域上计算基检测器的检测能力。将算法2输出的标签离群值划分为多个簇,找到测试数据所属的簇构建局部区域。
定义2 邻域簇Ψ。计算与周围邻点之间的欧氏距离,根据欧氏距离长短得到的个最近邻,由个最近邻构成的邻域簇Ψ。如式(7)所示:

其中表示在欧氏距离上最接近的第个数据。
定义3 局部区域Ω。从Ψ中检索出属于X×d中的数据,这些数据构成的局部区域Ω。如式(8)所示:

其中表示Ω中第个数据。
如图4所示,通过-NN算法找到邻近的个数据,存入邻域簇Ψ中,再从邻域簇Ψ选择出属于X×d的数据存入Ω,进而构建出的局部区域,即Ω是Ψ的子集。
其中:值的取值影响Y×d中某一个数据的局部区域的建立,较小的值导致EAOD算法过多关注数据的局部关系,较大的值导致EAOD算法过多关注数据的全局关系。为了解决这两个问题,在实验中,发现将值设置为0.05(是X×d包含的数据总个数)取得了良好的效果。

图4 数据对象的局部区域
本阶段涉及的局部变量及函数:表示Y×d中每个数据的行位置,Ψ表示邻域簇,getKPoints()表示使用式(7)获取最接近的个数据点,Ω表示局部区域,表示Y×d中所有数据的局部区域集合selectSubset()表示使用式(8)获取Ψ中属于X×d的数据。具体算法如下:
算法3 local_area_constructing(X×d,Y×d)
1)=1
2)Ψ=[]
3)Ω=[]
4)=[]
5) while≤do
6)Ψ.append(getKPoints())
7)Ω.append(selectSubset(Ψ,X×d))
8).append(Ω)
9) end
10)output()
2.3.4基检测器选择与组合
由算法3确定了测试点的局部区域Ω之后,在此局部区域上计算所有基检测器的检测能力,目的是为了选择对检测能力强的基检测器进行组合。
在算法2输出的离群值矩阵×num_detector中,可获取局部区域Ω中每个数据所对应的个离群值,将每个数据对应的个离群值存入矩阵×num_detector如式(9)所示:
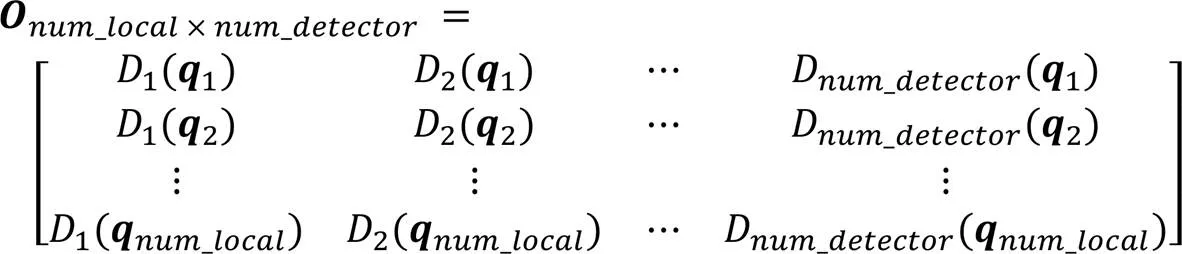
在算法3输出的标签离群值矩阵×1中,可获取局部区域Ω中每个数据所对应的1个标签离群值,将每个数据对应的1个标签离群值存入矩阵×1。如式(10)所示:

余弦相似度可确定每个特征之间是否密切相关,故EAOD算法使用余弦相似度衡量基检测器输出值与标签离群值之间的差异,进而推断出基检测器的检测能力。
对于来说,基检测器的检测能力δ正相关于其在上的输出值与的标签离群值之间的余弦相似度,即余弦相似度越高的基检测器检测能力越强。如式(11)所示:

对于Ω中第个数据,根据式(9)~(11),计算在×num_detector中个离群值与在×num_detector中1个标签离群值之间的余弦相似度,即得到个δ;然后,对该个δ进行降序排列,通过Top-个δ获取对检测能力强的个基检测器。
同理,对于Ω中所有数据,共选择出在局部区域Ω上(×)个检测能力强的基检测器,使用(×)个检测能力强的基检测器检测,输出(×)个离群值;最后,计算(×)个离群值的均值作为的最终离群值。
其中:降序排列个δ之后,前10%的δ有较高的相似度分值,因此=[/10]。
本阶段涉及的局部变量及函数:searchOD()表示检索得到在×num_detector中个离群值,searchLabel()表示检索得到在×num_detector中1个标签离群值,computingCosine()表示计算在×num_detector中个离群值与在×num_detector中1个标签离群值之间的余弦相似度,selecetTop()表示检索得到Top-个余弦相似度对应的基检测器,base_detector_training()表示使用算法1在检测能力强的基检测器上检测,average()表示计算检测能力强的基检测器对的检测结果的均值,该均值是判定最终的离群值。具体算法如下:
算法4 outlier_ predicating(Y×d,Ω,×1
×num_detector)
1)[]
2)[]
3)[]
4)[]
5)[]
6)[]
7) while≤do
8) while≤do
9)searchOD(,×num_detector)
10)searchLabel(,Q×1)
11)computingCosine()
12)selecetTop()
13) end
14)= base_detector_training(,)
15)=average()
16)end
17)output()
2.4 算法时间复杂度分析
设数据的数量和维度分别为和。算法1中,步骤1)~2)划分数据集,时间复杂度为(),步骤3)~8)遍历基检测器,由训练集训练基检测器,时间复杂度为(),步骤9)为输出训练值,时间复杂度为();算法2中,步骤1)~7)检索获取每个数据在基检测器上的最大值,时间复杂度为(),步骤8)输出检索结果,时间复杂度为();算法3中,步骤1)~9)使用k-d tree为每个测试点构建局部区域,其中用于距离计算的时间复杂度为(),用于根据距离长短进行排序的时间复杂度为(log),步骤10)输出局部区域中数据,时间复杂度为();算法4中,步骤1)~16),遍历测试集和局部区域中数据,找到在局部区域上检测能力强的基检测器,并使用这些基检测器对测试集中数据进行检测,时间复杂度为(2),步骤17)输出数据最终判定的离群值,时间复杂度为()。
综上可得EAOD算法的时间复杂度规模为(2)。
3 实验
3.1 实验环境
实验的硬件环境是:处理器为Intel Xeon Gold 5117 CPU@ 2.00 GHz(2处理器),显卡为Nvidia Tesla V100-PCIE-16 GB(共3块),内存(RAM)为256 GB。
实验的软件环境是:操作系统环境为Microsoft Windows Server 2016 Standard,算法的实现环境为pycharm professional、python-3.6.2、tensorflow_gpu-1.14。
3.2 数据集及评价指标
表4总结了在实验中使用到的5个数据集。数据集选自ODDS(Outlier Detection DataSets)公开数据集,分别是Cardio、Ionosphere、Mnist、Pendigits、Satimage-2。其中,大多数的数据被标记为正常点,小部分的数据被标记为离群点。ODDS提供了离群点检测的标准数据集(http://odds.cs.sto-nybrook.edu/)。

表4 实验中使用的ODDS公开数据集
Cardio数据集是由专业医生处理成的心电图上的胎儿心率测量值,它属于分类数据集,其中类别被分为3类:正常类、病理类、可疑类。在离群点检测中,正常类被标记成正常值类,病理类被标记成离群值类,疑似类被丢弃;Ionosphere数据集是一个二分类数据集,原本该数据集维度是34,但其中有一个特征全是0值的属性被丢弃,故总维度是33。其中,“bad”类作为离群值类,“good”类作为正常值类;原Mnist数据集是手写数字数据集,训练集和测试集分别包含60 000个数据对象和10 000个数据对象。现将原Mnist数据集转化为离群点检测数据集后,共包含7 603个数据对象。其中,零位数字类作为正常值类,从六位数字类中抽样700张图像作为离群值类,且从总特征随机抽取100个特征;基于原始笔数字的Pendigits数据集是一个包含10个类和16个整数属性的分类数据集,在该数据集中,所有类的频率均相等。Satimage-2数据集是一个多类分类数据集,合并了训练数据和测试数据,从类别2中抽样71个离群值,其他类别合并成一个离群类。
实验中所使用的全部数据集具有类别不平衡的特性。由于准确率一般适用在平衡的数据上,因此,在使用类别不平衡的数据集的情况下,不适合使用准确率作为评估指标。使用接受者操作特征曲线下方的面积(Area Under receiver operating characteristic Curve, AUC)和平均精度(Average Precision, AP)对数据偏斜的数据集进行实验评估是当下的普遍做法。
根据真实标签和检测结果,把样本划分成真正例(True Positive,)、假正例(False Positive,)、真反例(True Negative,)、假反例(False Negative,)四种类型。分类结果的混淆矩阵如表5所示。

表5 分类结果的混淆矩阵
接受者操作特征(Receiver Operating Characteristic, ROC)是一条曲线,其横坐标和纵坐标分别是假正例率(False Postive Rate,)和真正例率(True Positive Rate,),AUC是ROC曲线与横轴之间的面积。通常情况下,AUC分值越接近于1,算法的检测性能越好。AUC计算过程如式(12)~(16)所示:


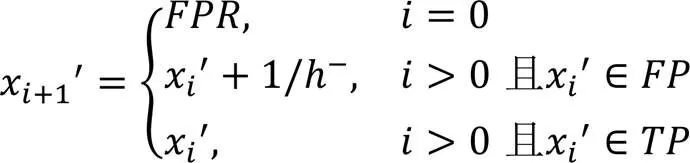


查准率-查全率(Precision-Recall curve, P-R)曲线的横坐标和纵坐标分别是查全率(Recall)和查准率(Precision)。AP是在P-R曲线中,在每个阈值下计算得到的查准率的加权平均值。AP计算过程如式(17)~(19)所示:



其中P和R分别表示在第个阈值处的查准率和查全率。
3.3 实验设计
在实验中,对于每个数据集,60%的数据作为训练集,剩余的40%作为测试集。
在实验中,为了解决基检测器因隐藏层压缩程度过高而导致的数据无法重构的问题,将自编码器中隐藏层节点数最小值设置为3,若按计算,若隐藏层中某一层节点数小于3,则该层节点数设置为3。为了确保本实验的结果具有稳定性,现对EAOD算法执行10次,对10次产生的结果计算均值作为最终的结果。集成学习中基检测器的个数设置为50、层数设置为9、迭代次数设置为300、某一层节点数与它上一层的节点数比值设为0.5。
在实验中,为了验证EAOD算法的有效性,将其与其他离群点检测算法在各数据集上进行了对比实验。具体来说,该实验使用了HBOS、主成分分析(Principal Component Analysis, PCA)[20]、LOF、孤立森林(Isolation Forest, IForest)[21]、自编码器(AutoEncoder, AE)[22]、特征装袋(Feature Bagging, FB)[23]离群点检测算法进行了比较。对于LOF算法,将其最近邻个数从2~100选取20次,选取其最佳检测结果;对于IForest算法,将采样大小设置为256,将树的数目设置为100;对于AE算法,其参数设置与EAOD算法中自编码器参数设置保持一致;对于FB算法,其基检测器设置与EAOD算法中基检测器设置保持一致。
在实验中,为了探究EAOD算法对起决定性参数的敏感程度,对集成学习中基检测器个数、层数、迭代次数这3个参数进行了敏感性实验分析。
3.4 实验结果与分析
表6展示了各个算法在5个离群点检测公开数据集上的AUC和AP的对比分值。
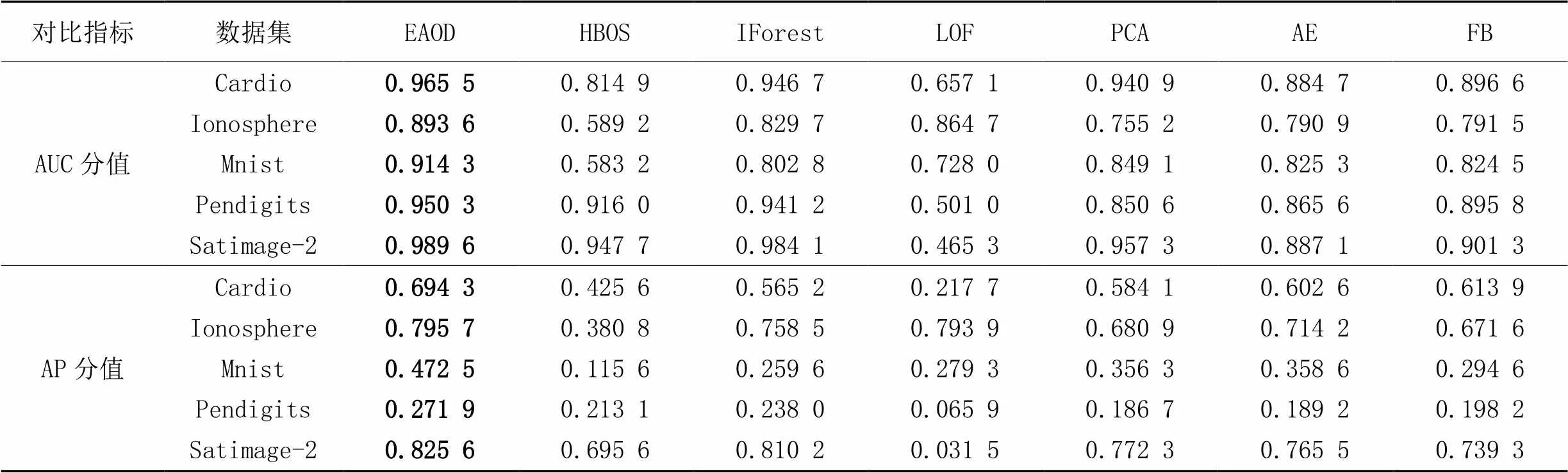
表6 各算法AUC分值和AP分值对比
如表6的AUC分值所示,EAOD与HBOS、IForest、LOF、PCA、AE、FB在AUC分值上相比:对于Cardio数据集,样本检测的精度分别提升了15.06个百分点、1.88个百分点、30.84个百分点、2.46个百分点、8.08个百分点、6.89个百分点;对于Ionosphere数据集,样本检测的精度分别提升了30.44个百分点、6.39个百分点、2.89个百分点、13.84个百分点、10.27个百分点、10.21个百分点;对于Mnist数据集,样本检测的精度分别提升了33.11个百分点、11.15个百分点、18.63个百分点、6.52个百分点、8.9个百分点、8.98个百分点;对于Pendigits数据集,样本检测的精度分别提升了3.43个百分点、0.91个百分点、44.93个百分点、9.97个百分点、8.47个百分点、5.45个百分点;对于Satimage-2数据集,样本检测的精度分别提升了4.19个百分点、0.55个百分点、52.43个百分点、3.23个百分点、10.35个百分点、8.83个百分点。
如表6的AP分值所示,EAOD与HBOS、IForest、LOF、PCA、AE、FB在AP分值上相比:对于Cardio数据集,样本检测的精度分别提升了26.87个百分点、12.91个百分点、47.66个百分点、11.02个百分点、9.17个百分点、8.04个百分点;对于Ionosphere数据集,样本检测的精度分别提升了41.49个百分点、3.72个百分点、0.18个百分点、11.48个百分点、8.15个百分点、12.41个百分点;对于Mnist数据集,样本检测的精度分别提升了35.69个百分点、21.29个百分点、19.32个百分点、11.62个百分点、11.39个百分点、17.79个百分点;对于Pendigits数据集,样本检测的精度分别提升了5.88个百分点、3.39个百分点、20.6个百分点、8.52个百分点、8.27个百分点、7.37个百分点;对于Satimage-2数据集,样本检测的精度分别提升了13个百分点、1.54个百分点、79.41个百分点、5.33个百分点、6.01个百分点、8.63个百分点。
表6表明,EAOD算法在5个数据集上的AUC分值和AP分值均高于HBOS、IForest、LOF、PCA、AE和FB算法。这是因为EAOD算法具备权衡偏差和方差的功能:EAOD算法通过随机连接自编码器使基检测器具备多样性,在选取标签离群值阶段间接权衡偏差和方差,对检测能力强的多个不同的基检测器的输出结果计算均值,再一次权衡偏差和方差,进而减小了泛化误差,提高了检测性能。
如图5所示,HBOS、IForest、LOF、PCA和AE算法也具有较短的时间耗费,但从AUC和AP指标来看,它们没有较好的检测性能。FB算法检测时间耗费较长,是因为其对特征选取进行了较为复杂的特征统计计算,且缺乏对基检测器进行选择性统计组合。EAOD算法对5种数据集均具有较为合理的检测时间耗费,以检测一般规模的数据集最短耗时6.8 s来看,已基本满足实际使用时的一般情况。因此综合来看,EAOD算法在具有稳定较高的检测性能的前提下,也具有较为合理的检测时间成本。

图5 各算法在5种数据集上的时间耗费对比
实验结果表明,EAOD算法在无监督学习下,对真实数据集具有较好的检测性能,同时具有较为合理的检测时间成本。因此,EAOD算法是有效可行的。
3.5 参数敏感性分析
以Cardio数据集为例,通过实验分析了EAOD算法中基检测器个数、层数以及迭代次数等3个关键参数变动对AUC和AP分值的影响。
基检测器个数分别设置为25、50、75、100、125和150。实验结果由图6可知,基检测器个数的变动对于AUC分值没有明显影响。对于AP分值,基检测器个数由25增加到50,再从50增加到100的过程中,AP分值先上升后下降;基检测器个数由100增加到150过程中,AP分值无显著变化;AP分值在基检测器个数等于50时达到最大值。

图6 基检测器个数变动分析
基检测器层数分别设置为3、5、7和9。实验结果由图7可知:基检测器层数的变动对于AUC分值没有明显影响。对于AP分值,基检测器层数由3增加到5时,AP分值显著下降;基检测器层数由5增加到9的过程中,AP分值持续上升;在基检测器层数等于9时,AP分值最大。
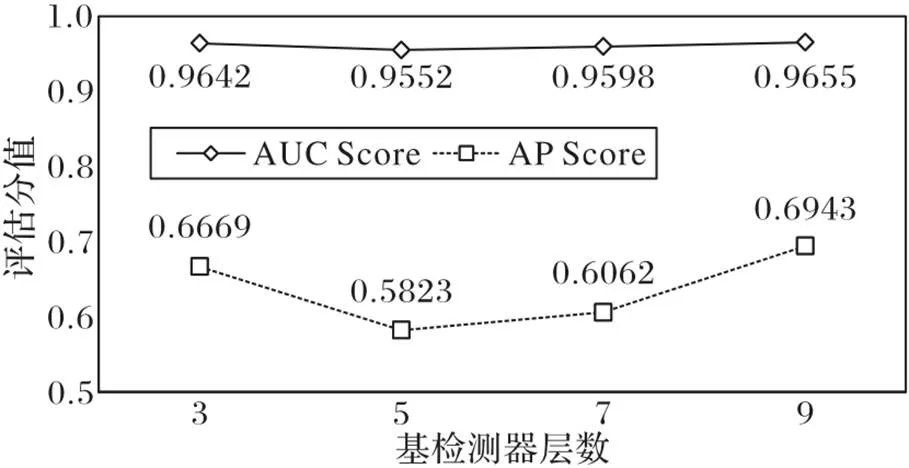
图7 基检测器层数变动分析
基检测器迭代次数分别设置为50、100、150、200、250和300。实验结果由图8可知,基检测器迭代次数的变动对于AUC分值没有明显影响。对于AP分值来说,基检测器迭代次数由50增加到100时,AP分值下降;基检测器迭代次数由100增加到300的过程中,AP分值持续上升;在基检测器迭代次数等于300时,AP分值取得最大值。

图8 基检测器迭代次数变动分析
由于AUC与AP两种评估指标之间在统计学中存在明显差异[24],所以EAOD算法的重要参数变动在AUC分值和AP分值表现上存在显著差异。
4 结语
基于自编码器的离群点检测算法在中小规模数据集上易发生过拟合现象和传统的基于集成学习的离群点检测算法未对基检测器进行优化选择均是导致检测精度低的主要因素。本文提出一种基于自编码器与集成学习的EAOD离群点检测算法来解决检测精度低的问题。该算法使用随机连接自编码器作为基检测器在数据对象的局部区域中选择一组检测能力强的基检测器进行组合,组合后的对象离群值作为算法最终的判定结果。通过对比实验发现在无监督学习下所提算法优于传统机器学习算法。
EAOD算法构建局部区域依赖计算欧氏距离来寻找最近邻,存在一定计算量,因此以后的研究应注重在保证检测精度的前提下尝试聚类等其他方法构建局部区域。另外,EAOD算法可以考虑异构算法作为其基检测器,以更加多样性地实现集成学习。
[1] PANG G S, CAO L B, AGGARWAL C. Deep learning for anomaly detection: challenges, methods, and opportunities[C]// Proceedings of the 14th ACM International Conference on Web Search and Data Mining. New York: ACM, 2021: 1127-1130.
[2] PANG G S, LI J D, VAN DEN HENGEL A, et al. Anomaly and Novelty Detection, Explanation, and Accommodation (ANDEA)[C]// Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. New York: ACM, 2021: 4145-4146.
[3] THUDUMU S, BRANCH P, JIN J, et al. A comprehensive survey of anomaly detection techniques for high dimensional big data[J]. Journal of Big Data, 2020, 7: No.42.
[4] QIAN J, ZENG G F, CAI Z P, et al. A survey on anomaly detection techniques in large-scale KPI data[C]// Proceedings of the 9th International Conference on Computer Engineering and Networks, AISC 1143. Singapore: Springer, 2021: 767-776.
[5] BERGMANN P, BATZNER K, FAUSER M, et al. The MVTec anomaly detection dataset: a comprehensive real-world dataset for unsupervised anomaly detection[J]. International Journal of Computer Vision, 2021, 129(4): 1038-1059.
[6] 梅林,张凤荔,高强. 离群点检测技术综述[J]. 计算机应用研究, 2020, 37(12): 3521-3527.(MEI L, ZHANG F L, GAO Q. Overview of outlier detection technology[J]. Application Research of Computers, 2020, 37(12): 3521-3527.)
[7] PANG G S, SHEN C H, CAO L B, et al. Deep learning for anomaly detection: a review[J]. ACM Computing Surveys, 2022, 54(2): No.38.
[8] CHEN W Q, WANG Z L, ZHONG Y, et al. ADSIM: network anomaly detection via similarity-aware heterogeneous ensemble learning[C]// Proceedings of the 2021 IFIP/IEEE International Symposium on Integrated Network Management. Piscataway: IEEE, 2021: 608-612.
[9] CRUZ R M O, SABOURIN R, CAVALCANTI G D C. Dynamic classifier selection: recent advances and perspectives[J]. Information Fusion, 2018, 41: 195-216.
[10] CRUZ R M O, SABOURIN R, CAVALCANTI G D C. META-DES.Oracle: meta-learning and feature selection for dynamic ensemble selection[J]. Information Fusion, 2017, 38: 84-103.
[11] GOLDSTEIN M, DENGEL A. Histogram-Based Outlier Score (HBOS): a fast unsupervised anomaly detection algorithm[EB/OL]. [2021-03-22].https://www.goldiges.de/publications/HBOS-KI-2012.pdf.
[12] WANG X C, JIANG H C, YANG B Q. A k-nearest neighbor medoid-based outlier detection algorithm[C]// Proceedings of the 2021 International Conference on Communications, Information System and Computer Engineering. Piscataway: IEEE, 2021: 601-605.
[13] BREUNIG M M, KRIEGEL H P, NG R T, et al. LOF: identifying density-based local outliers[C]// Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2000: 93-104.
[14] FONG S, LI T, HAN D, et al. Lightweight classifier-based outlier detection algorithms from multivariate data stream[M]// FONG S J, MILLHAM R C. Bio-inspired Algorithms for Data Streaming and Visualization, Big Data Management, and Fog Computing, STNIC. Singapore: Springer, 2021: 97-125.
[15] 杜旭升,于炯,叶乐乐,等. 基于图上随机游走的离群点检测算法[J]. 计算机应用, 2020, 40(5): 1322-1328.(DU X S, YU J, YE L L, et al. Outlier detection algorithm based on the graph random walk[J]. Journal of Computer Applications, 2020, 40(5): 1322-1328.)
[16] LÜBBERING M, GEBAUER M, RAMAMURTHY R, et al. Supervised autoencoder variants for end to end anomaly detection[C]// Proceedings of the 2021 International Conference on Pattern Recognition, LNCS 12662. Cham: Springer, 2021: 566-581.
[17] SARVARI H, DOMENICONI C, PRENKAJ B, et al. Unsupervised boosting-based autoencoder ensembles for outlier detection[C]// Proceedings of the 2021 Pacific-Asia Conference on Knowledge Discovery and Data Mining, LNCS 12712. Cham: Springer, 2021: 91-103.
[18] BHATIA R, SHARMA R, GULERIA A. Anomaly detection systems using IP flows: a review[M]// BAREDAR P V, TANGELLAPALLI S, SOLANKI C S. Advances in Clean Energy Technologies, SPE. Singapore: Springer, 2021: 1035-1049.
[19] AVCI B, BODUROGLU A. Contributions of ensemble perception to outlier representation precision[J]. Attention, Perception, & Psychophysics, 2021, 83(3): 1141-1151.
[20] AHSAN M, MASHURI M, KUSWANTO H, et al. Outlier detection using PCA mix based2control chart for continuous and categorical data[J]. Communications in Statistics-Simulation and Computation, 2021, 50(5): 1496-1523.
[21] LIU F T, TING K M, ZHOU Z H. Isolation forest[C]// Proceedings of the 8th IEEE International Conference on Data Mining. Piscataway: IEEE, 2008: 413-422.
[22] OOSTERMAN D T, LANGENKAMP W H, BERGEN E L. Customs risk assessment based on unsupervised anomaly detection using autoencoders[C]// Proceedings of the 2021 SAI Intelligent Systems Conference, LNNS 294. Cham: Springer, 2022: 668-681.
[23] LAZAREVIC A, KUMAR V. Feature bagging for outlier detection[C]// Proceedings of the 11th ACM SIGKDD International Conference on Knowledge Discovery in Data Mining. New York: ACM, 2005: 157-166.
[24] BELHADI A, DJENOURI Y, LIN J C W, et al. Trajectory outlier detection: algorithms, taxonomies, evaluation, and open challenges[J]. ACM Transactions on Management Information Systems, 2020, 11(3): No.16.
GUO Yiyang,born in 1996, M. S. candidate. His research interests include machine learning, data mining.
YU Jiong,born in 1964, Ph. D., professor. His research interests include distributed computing, machine learning, data mining.
DU Xusheng, born in 1995, Ph. D. candidate. His research interests include machine learning, data mining.
YANG Shaozhi,born in 1995, M. S. candidate. His research interests include machine learning, data mining.
CAO Ming,born in 1996, M. S. candidate. Her research interests include machine learning, data mining.
Outlier detection algorithm based on autoencoder and ensemble learning
GUO Yiyang1, YU Jiong1,2*, DU Xusheng1, YANG Shaozhi1, CAO Ming3
(1,,830046,;2,,830091,;3,,266100,)
The outlier detection algorithm based on autoencoder is easy to over-fit on small- and medium-sized datasets, and the traditional outlier detection algorithm based on ensemble learning does not optimize and select the base detectors, resulting in low detection accuracy. Aiming at the above problems, an Ensemble learning and Autoencoder-based Outlier Detection (EAOD) algorithm was proposed. Firstly, the outlier values and outlier label values of the data objects were obtained by randomly changing the connection structure of the autoencoder generate different base detectors. Secondly, local region around the object was constructed according to the Euclidean distance between the data objects calculated by the nearest neighbor algorithm. Finally, based on the similarity between the outlier values and the outlier label values, the base detectors with strong detection ability in the region were selected and combined together, and the object outlier value after combination was used as the final outlier value judged by EAOD algorithm. In the experiments, compared with the AutoEncoder (AE) algorithm, the proposed algorithm has the Area Under receiver operating characteristic Curve (AUC) and Average Precision (AP) scores increased by 8.08 percentage points and 9.17 percentage points respectively on Cardio dataset; compared with the Feature Bagging (FB) ensemble learning algorithm, the proposed algorithm has the detection time cost reduced by 21.33% on Mnist dataset. Experimental results show that the proposed algorithm has good detection performance and real-time performance under unsupervised learning.
outlier detection; ensemble learning; AutoEncoder (AE); base detector; unsupervised learning
This work is partially supported by National Natural Science Foundation of China (61862060, 61462079, 61562086, 61562078).
TP311.1
A
1001-9081(2022)07-2078-10
10.11772/j.issn.1001-9081.2021050743
2021⁃05⁃10;
2021⁃09⁃08;
2021⁃09⁃15。
国家自然科学基金资助项目(61862060, 61462079, 61562086, 61562078)。
郭一阳(1996—),男,山东滕州人,硕士研究生,主要研究方向:机器学习、数据挖掘; 于炯(1964—),男,北京人,教授,博士生导师,博士,主要研究方向:分布式计算、机器学习、数据挖掘; 杜旭升(1995—),男,甘肃庆阳人,博士研究生,CCF会员,主要研究方向:机器学习、数据挖掘; 杨少智(1995—),男,安徽凤阳人,硕士研究生,主要研究方向:机器学习、数据挖掘; 曹铭(1996—),女,山东菏泽人,硕士研究生,主要研究方向:机器学习、数据挖掘。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
数字技术与应用(2021年1期)2021-03-24
意林(2019年11期)2019-06-30
诗选刊(2018年7期)2018-07-09
科技风(2018年15期)2018-05-14
魅力中国(2016年52期)2017-09-01
科技与创新(2017年5期)2017-03-28
阅读(中年级)(2016年4期)2016-11-19
