
融合动态兴趣偏好与特征信息的序列推荐
2022-08-03 01:34普洪飞邵剑飞张小为魏榕剑
云南大学学报(自然科学版) 2022年4期
普洪飞,邵剑飞,张小为,魏榕剑
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
随着互联网的飞速发展,如何从海量的数据推荐用户感兴趣的内容是至关重要的.现在大量APP 和网站都应用自己的推荐算法为用户推荐商品和服务,例如快手、抖音、淘宝、QQ 音乐等.
序列推荐通常认为用户在某个时刻的行为(点击,购买)由该用户之前多个时刻决定的,它将用户与物品的交互视为动态的、顺序性的序列[1].序列推荐算法可分为传统推荐和基于深度学习推荐.传统的推荐主要有马尔科夫链模型[2]和协同过滤[3]等.基于深度学习的方法主要有循环神经网络(Recurrent Neural Network,RNN)[4]、长短期记忆网络(Long Short-Term Memory,LSTM)[5]和基于注意力机制的 Transformer 架构(Bidirectional Encoder Representations from Transformers,BERT)[6]等,它们都是针对用户对项目的交互关系进行建模.
RNN 和LSTM 依赖于前一时刻的计算结果无法很好地并行运算,且RNN 和LSTM 均无法很好地处理长距离依赖问题.实际中,每个人的兴趣是随时间动态变化的,例如,用户在某段时间内对数码感兴趣,另一时间段对衣服和化妆品感兴趣.为了捕捉这种变化,沈学利等[7]将自注意力机制与长短期兴趣偏好融合,实现推荐性能的提升.Zhou等[8]通过给定目标项目成功捕获用户的动态兴趣,但是它无法捕获到序列行为间更好的依赖关系.Zhou 等[9]设计带有注意力机制的门控循环单元对用户行为之间的依赖性进行建模,根据兴趣直接导致连续行为的原则,提出辅助损失,利用下一个行为监督当前隐藏状态的学习,从而对目标项目的动态兴趣变化进行建模(Deep Interest Evolution Network for click through rate prediction,DIEN).此外,针对用户长短期兴趣建模的还有基于会话推荐的长、短期兴趣并行建模[10]、对推荐的长期偏好和短期偏好的联合深度建模[11]等.
虽然对用户的兴趣建模增强推荐模型的泛化能力,但忽略了用户与商品交互之间的上下文特征信息[12].在实际生活中,用户和项目的特征,往往决定用户的行为,例如,用户的性别、年龄和职业等特征影响用户的兴趣爱好,女生比较喜爱化妆品,男生喜爱数码等.项目的种类、价钱等特征也影响用户的兴趣爱好.于是孙金杨等[13]提出将时间上下文与特征信息融合,对项目的特征属性进行建模与时间上下文融合,提高了推荐的性能,但它忽略了对用户的特征信息进行融合,因为用户的特征信息也是至关重要的.由于项目特征的异构性,很难知道哪些特征决定用户的行为,Zhang等[14]提出平凡注意力机制捕获用户对项目特征的偏好,根据影响用户行为的重要程度赋予项目特征不同的权重(Feature-level Deeper Self-attention Network for sequential recommendation,FDSA).例如,某用户购买某物,在项目的种类、价钱等特征下,觉得该物的价钱很重要,其他都是次要的,就赋予价钱较大的权重.虽然FDSA 模型提出平凡注意力机制,深层次地对项目特征提取,但它也忽略了用户特征的重要性.此外,将项目特征信息融合进行推荐的算法还有基于自注意力神经网络的自动特征交互学习[15]、融合上下文信息的个性化序列推荐深度学习模型[16]等.综上所述,融合动态兴趣与用户、项目特征信息可以模拟真实的用户行为,有望提高对用户推荐的准确性.
本文提出融合动态兴趣偏好与特征信息的序列推荐模型.首先通过带有注意力机制的门控循环单元和辅助损失函数对用户项目交互进行动态兴趣建模,得到动态兴趣的最终表示.然后对项目和用户特征进行编码,送入平凡注意力机制,为每个特征赋予不同的权重,加上位置编码,经过多头注意力机制,得到用户和项目的特征表示.之后将动态兴趣表示和用户项目特征表示拼接.最后通过多层感知机输出得到结果.
本文的主要贡献如下:
(1)提出融合动态兴趣偏好与特征信息的序列推荐模型.用户的兴趣是多变的,为了捕获这种变化,提出了动态兴趣建模.在实际生活中,用户和项目的特征,往往决定用户的行为,所以将它们融合可以更加真实地模拟用户的行为.
(2)采用经过带有注意力机制的门控和辅助损失函数对用户项目交互进行动态兴趣建模,分别对每个兴趣的动态变化进行建模.
(3)采用平凡注意力机制为用户和项目的特征赋予不同的权重,从而更好地得到用户项目特征的表示.
(4)融合用户的特征信息,这是其他模型所忽略的重要信息.
(5)在Yelp 和MovieLens-1M 两个数据集上进行实验,结果表明本文模型优于不少基线模型.
1 相关工作
1.1 一般推荐一般推荐早期使用协同过滤(Collaborative Filtering,CF)对交互历史建立用户偏好模型[17],其中,矩阵分解(Matrix Factorization,MF)是比较流行的一种,通过向量间内积预测用户对项目的偏好[18].此外,还有基于项目邻域方法,利用项目之间的相似性预测用户对用户的偏好[19].
1.2 序列推荐现实中,存在用户与项目交互记录较为稀少,一般推荐面临着局限性,其忽略了用户行为的顺序性.于是序列推荐被提出,根据用户与项目的交互历史预测下个交互项目,即使交互记录少,也可以更好地提供推荐.
早期的序列推荐运用马尔科夫链[2]从用户交互历史中获取用户的兴趣偏好.但是,随着深度学习的发展,RNN 及其变体门控循环单元(Gated Recurrent Unit,GRU)和长短期记忆网络得到广泛的运用,采用循环网络对编码后的交互记录进行兴趣建模.例如,基于GRU 的序列推荐[20]、基于注意力机制的GRU 序列推荐[21]、基于LSTM 的序列推荐[22].
除了上述方法,还引入下面各种深度学习方法用于序列推荐.Tang 等[23]提出一种卷积序列模型,使用卷积学习用户的兴趣.Liu 等[24]通过多层感知机捕获一般兴趣和当前兴趣.Wang等[25]通过图卷积对长短期偏好建模.
1.3 特征提取实际生活中,项目和用户的特征信息是重要的.Zhou 等[8]通过将特征向量直接拼接输出,但忽略了深层次提取.沈学利等[7]通过注意力机制对项目特征进行深层次提取,但忽略了不同特征之间的重要性.于是,Zhang 等[14]通过平凡注意力机制为不同的特征赋予权重,再通过自注意力机制进行深层次提取.
2 本文方法
2.1 主要符号含义为了增加上下文的连贯性,使用统一的符号表总结主要符号及其含义,如表1所示.

表1 本文方法中的符号及含义Tab.1 Symbols and meanings in this paper′s methods
2.2 问题定义本文使用U和I分别表示用户集合与项目集合.对于一个用户u∈U,Vu定义为用户交互按时间排列的序列,其中Vu∈I,Vu={V(1),V(2),···,V(T)}.T为用户交互的序列长度,同时也表示用户交互行为的数量.此外,每个用户和项目都有自己的特征.通过对当前时刻之前的交互信息动态兴趣和特征信息建模,预测下一个时刻用户感兴趣的项目,是本文的主要工作.
2.3 模型描述本文模型如图1 所示,整个模型分为3 个部分,分别是用户交互序列动态兴趣建模模块、用户和项目特征的提取模块、多层感知机输出模块.
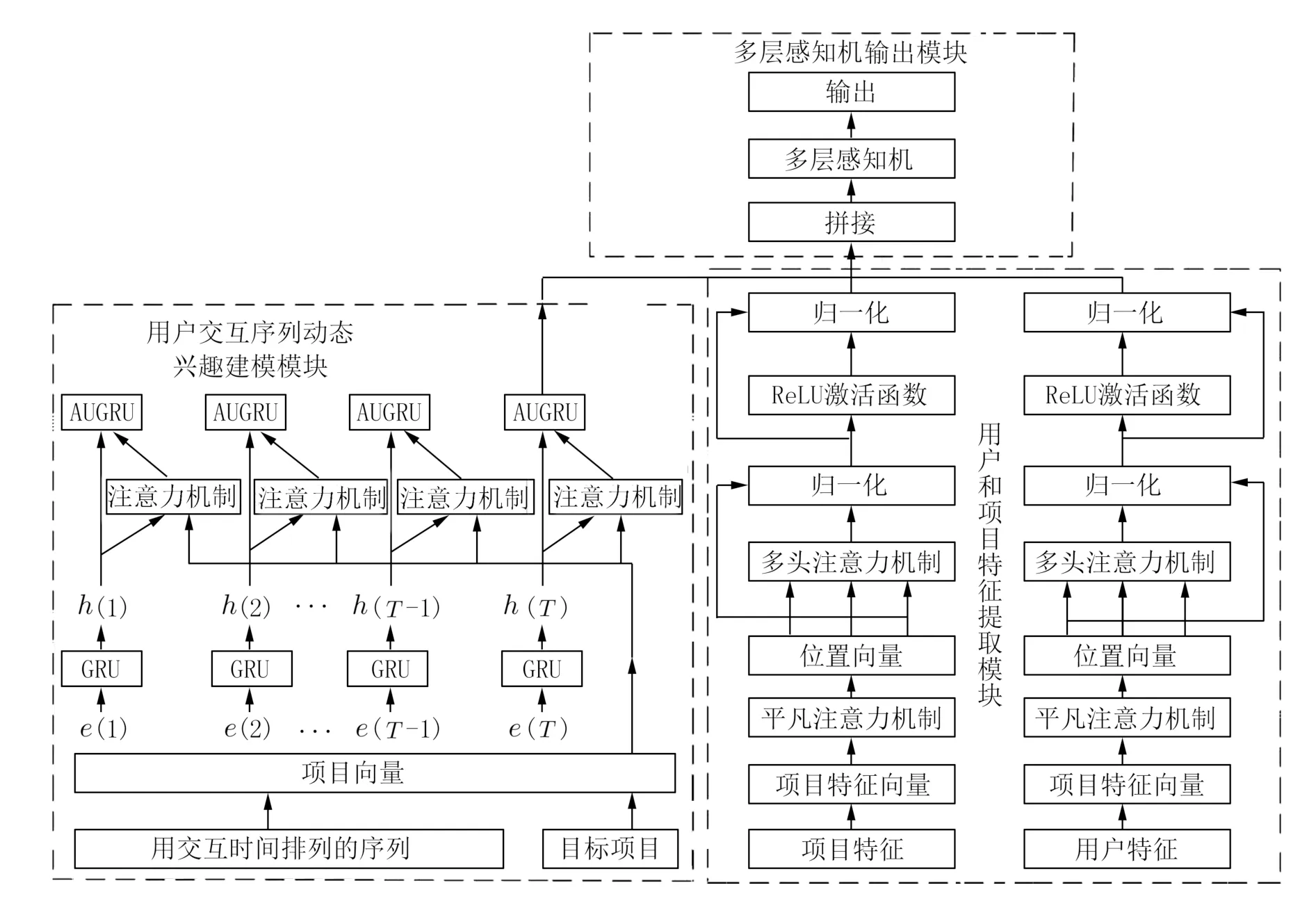
图1 融合动态兴趣偏好与特征信息的序列推荐模型Fig.1 Sequence recommendation fusing dynamic interest preference and feature information
2.4 用户交互序列动态兴趣建模模块
2.4.1 项目嵌入表示 定义用户交互按时间排列的序列Vu经过项目嵌入表示输出e.
2.4.2 门控循环单元和辅助损失函数 本文采用门控循环单元GRU 建模交互序列之间的依赖关系,GRU 克服了RNN 梯度消失的问题,比LSTM减少了一个门控单元,效率更高[26].GRU 的原理如下:
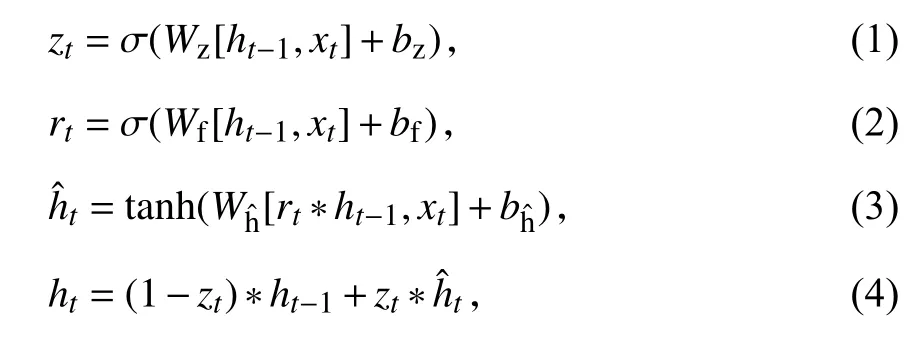
其中,*表示元素乘积,σ表示sigmoid 激活函数,Wz、Wf和Wh为权重参数,bz、bf和bh为偏置参数,门控循环单元中的重置门zt和更新门rt输入均为当前时刻输入xt与上时刻隐藏状态ht-1,ht为当前时间隐藏状态ht.
然而,隐藏状态只能捕获行为间的依赖关系,不能有效地表示动态兴趣.由于用户的兴趣是动态变化的,任何一个隐藏兴趣状态的变化都会直接影响下一个行为,因此为了更好地捕获用户的动态变化,设计一个辅助损失函数,应用下一个行为监督上一个隐藏兴趣状态的学习[9].此外,定义下一时刻的交互作为正例,相反,定义除去下一时刻交互剩下的项目作为负例.
定义N对用户交互嵌入序列:是大小为T×dE的矩阵,dE是嵌入向量的维度,ej表示正例,j表示负例.ej[t]∈I表示用户交互的第t个项目的向量,I是项目的集合.[t]∈I-ej[t]表示除了第t个项目剩下的项目向量.辅助损失函数Laux定义为:

2.4.3 带注意力机制的更新门 由于用户的兴趣存在不确定性,兴趣随时会发生转移.为了减弱兴趣转移带来的影响,将注意力机制与GRU 相结合[9],建立动态兴趣模型.本文引入的注意力机制的核心思想是根据对目标项目(下一时刻交互项目)影响程度大小,为每一个兴趣状态ht赋予不同的权重,以此减弱兴趣转移的影响,从而增强有利于目标项目的兴趣状态.
注意力机制定义如下:

在上阶段中,在辅助函数的帮助下,获得兴趣序列ht.T表示用户交互序列的长度,W是大小dE×dtarget权重参数,dE表示嵌入向量的维度,dtarget表示目标项目向量(下一时刻交互向量)的维度.注意力权重at的大小反映输入ht和目标项目etarget的关联关系.
带注意力机制的更新门(GRU with Attentional Update Gate,AUGRU)使用注意力权重影响GRU的更新门,定义如下:

其中,at是注意力权重,zt是更新门的输出,将at相乘zt得到是带注意力机制更新门的输出,将代入式(8)输出动态兴趣表示.
2.5 用户和项目特征提取模块
2.5.1 特征嵌入表示层 对于一个项目i∈I,其特征向量表示为Ai={v(c1),v(c2),···,v(cg)},v(cg)表示项目第g个特征的向量,cg表示第g个特征,例如项目的种类、价格等.
2.5.2 平凡注意力层 由于项目的特征是异构的,采用平凡注意力机制[14]赋予特征不同的权重,平凡注意力层定义如下:

其中,Wa是大小为dE×dE的矩阵,ba是dE维的向量,dE是特征向量的维度,将 αi乘Ai得到特征向量fi.
2.5.3 多头注意力机制 多头注意力机制允许模型在不同的表示子空间里学习到相关信息,采用多头注意力机制对项目特征进行深层次学习.传统的注意力机制忽略了顺序输入的位置信息,添加位置向量p,p是大小为g×dE的矩阵.在平凡注意力层,得到项目i∈I的特征向量表示fi,于是用户的总体特征表示为f={f1,f2,···,fg},将特征向量表示f与位置向量p相加得到:

注意力机制(Scaled Dot-product Attention)[27]定义如下:
其中,Q、K和V相当于F进行线性变化.将F线性变化,通过缩放点积输出:
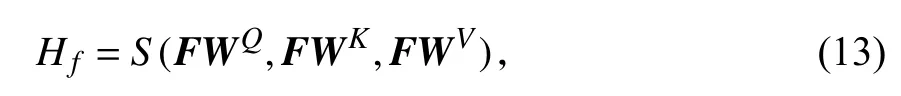
其中,WQ、WK、WV是大小为dE×dE的可学习参数矩阵.多头注意力机制定义如下:
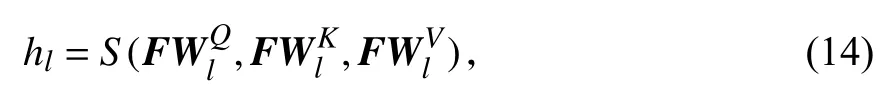
其中,hl是第l头输出,是dE×dE可学习参数,l是多头注意力机制的头数.通过将多头的输出拼接经过线性层输出Lf:

残差连接具有改善梯度消失爆炸的作用[28],所以本文在多头注意力机制后添加残差连接:

以ReLU 为激活函数的全连接层,克服梯度爆炸问题,在多层网络结构下梯度实现线性传递[29],定义如下:

其中,W1、W2、b1、b2是模型可学习的参数,Of是项目特征的输出表示.
每一层的参数在更新过程中,会改变下一层输入的分布,神经网络层数越多,表现得越明显,采用归一化层来保持一致[30].

将从开始输入F,到最后输出Of,这个过程定义为:

叠加q层多头注意力层表示为:

2.5.4 用户特征提取 同理,采用上述相同方式对用户特征提取.对于一个用户的特征,通过特征编码和平凡注意力机制后,与位置向量相加输出K,K等同于项目特征提取中的F,经过多头注意力机制输出项目的特征表示,定义如下:

2.6 多层感知机输出模块经上文研究,得到动态兴趣建模表示、项目特征表示和用户特征表示,将其拼接表示,经过多层感知机和softmax函数,最终输出Pout:
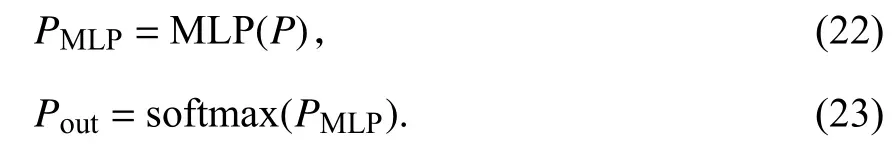
因多层感知机具有简单高效的特点[31],运用它进行深层次拼接输出,最后用softmax函数以概率的形式输出结果.
2.7 网络模型的训练这里采用二元交叉熵损失作为目标项目的优化目标函数,最终的损失函数为目标项目损失Ltarget与辅助损失Laux相结合:
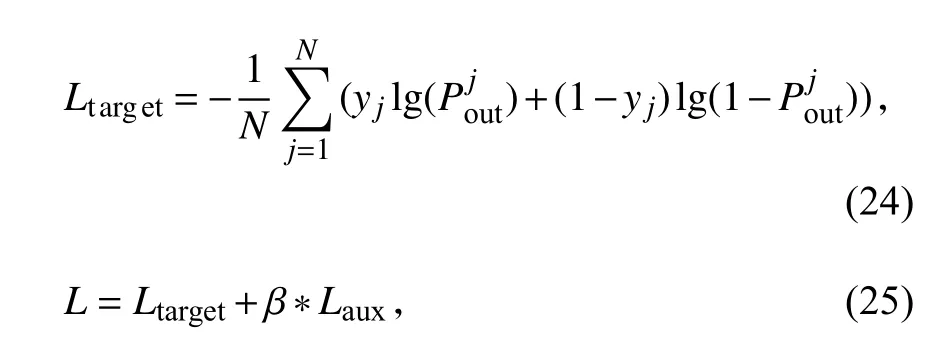
其中,N是训练样本的数量;y∈[0,1],y为1 时,表示用户和项目有交互,y为0 时,则相反;Pout是模型的输出,表示用户和目标项目交互的概率;β是一个超参数,用于平衡目标项目损失和辅助损失.
3 实验及分析
3.1 数据集本文使用 MovieLens-1M[32]和 Yelp两个公开数据集验证模型性能.MovieLens-1M 是个性化电影数据集.该数据集包含用户id、项目id、用户对项目交互的评分、时间戳、用户特征和项目特征.Yelp 是美国最大的点评网站公开的内部数据集,其涵盖商户、点评和用户数据,也包含用户和商户的特征信息.在本文实验中Yelp 和MovieLens-1M 特征选取如表2 所示.

表2 MovieLens-1M 和 Yelp 特征选取Tab.2 Feature selection of MovieLens-1M and Yelp
使用时间戳来确定交互顺序,由于用户的交互的次数是不固定的,本文采用长度分别为50、40对应MovieLens-1M 和Yelp 数据集上进行实验,如果用户交互次数少于定义的次数,在序列的左侧填充0;如果用户交互次数多于定义的次数,采用时间为近期的交互序列.截取 MovieLens-1M 和 Yelp的数据进行过滤,实验数据统计如表3 所示.

表3 MovieLens-1M 和Yelp 数据集数据统计情况Tab.3 Data statistics of MovieLens-1M and Yelp data sets
最后,将数据集划分为比例为0.8、0.1、0.1 的训练集、验证集和测试集.
3.2 评价指标曲线下面积(Area Under Curve,AUC)是一种衡量学习优劣的性能指标,本文采用其作为模型的评价指标.
3.3 基线模型和参数设置
3.3.1 基线模型 为了验证本文模型的性能,选取若干个模型作为对比模型.
BERT4Rec[6]:该模型将BERT 运用到序列推荐中,训练过程中使用掩盖任务对用户行为序列进行训练,用 “掩盖”增强后的向量作为预测用户下一时刻交互项目.
FDSA[14]:该模型运用平凡注意机制和多头注意力机制提取用户的兴趣和项目特征进行序列推荐,但是忽略了用户特征.
DIEN[9]:运用改进的辅助损失函数监督用户的兴趣转移,同时将注意力机制和GRU 结合捕获用户兴趣的变化,但是该模型忽略了对用户和项目特征进行深层次的特征提取.
GRU4Rec[20]:该模型利用GRU 从用户的交互序列中获取顺序依赖关系.
GRU4RecF[33]:该模型在GRU4Rec 的基础上添加了项目的属性特征,提升推荐的性能.
3.3.2 参数设置 本文在Pytorch 框架下验证模型性能,实验的操作系统为Windows 10,显卡为GTX1650Ti,CPU 型号为i5-10220H 处理器,Python版本为3.9,在Pycharm 集成环境下进行实验,具体参数设置如表4 所示.
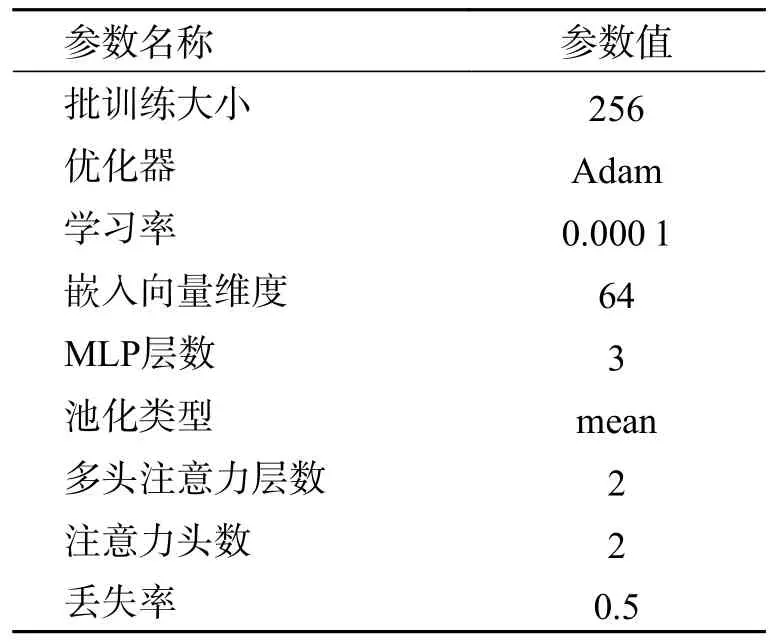
表4 本文实验参数设置Tab.4 Parameter settings of the model experiment
3.4 实验结果和分析在数据集Yelp 和 MovieLens-1M 上进行验证,本文提出的模型和基线模型对比如图2、3 所示.对图2、3 分析,可得出以下结论:通过在Yelp 和MovieLens-1M 数据集上进行实验,GRU4RecF 模型的效果始终优于GRU4Rec,二者的区别在于GRU4RecF 模型在GRU4Rec 的基础上融合了项目的特征信息.可见融合项目特征信息可以有效地提高模型的性能.
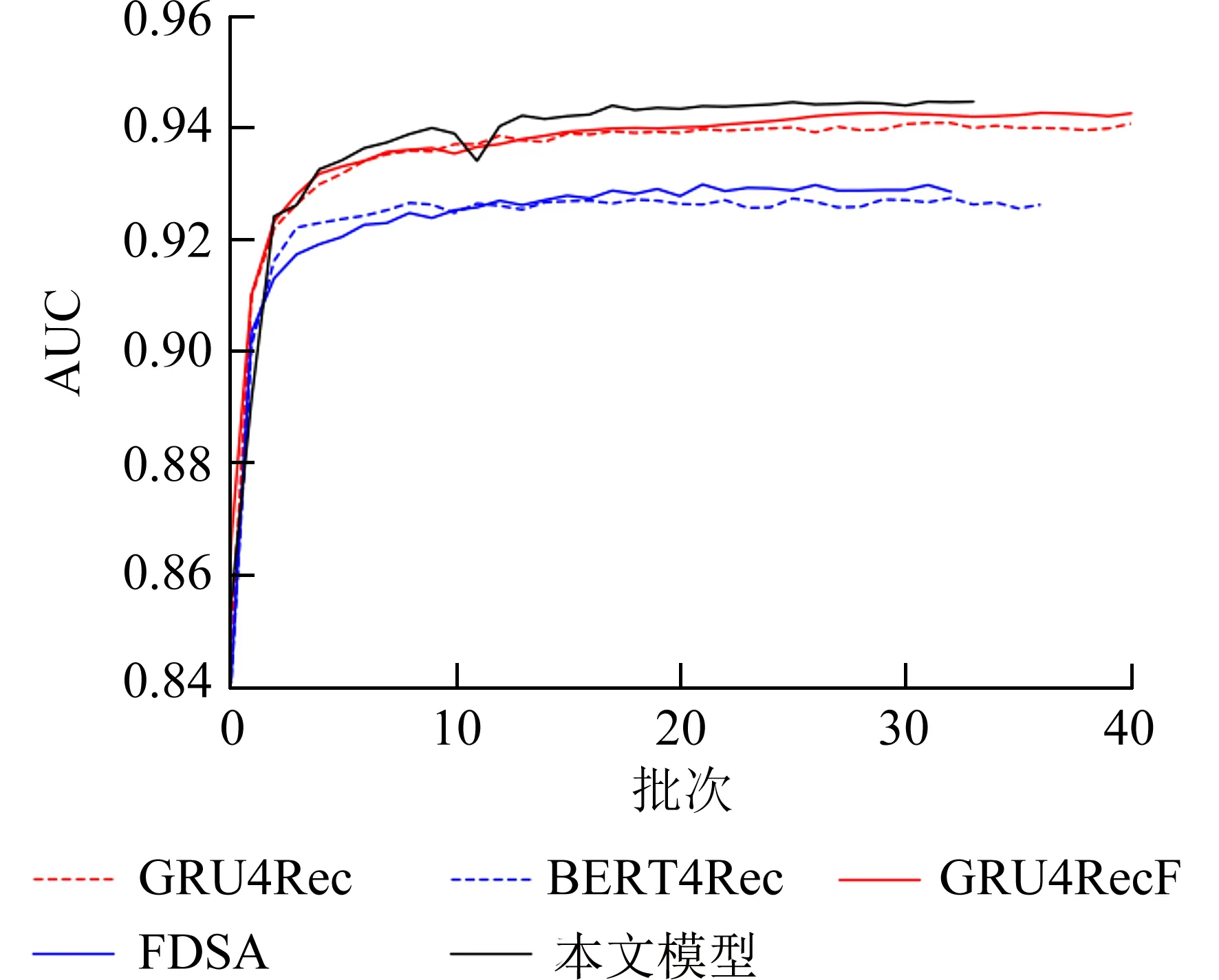
图2 MovieLens-1M 下各模型对比结果Fig.2 Comparison results of each model under MovieLens-1M

图3 Yelp 下各模型对比结果Fig.3 Comparison results of each model under Yelp
在两个数据集上,FDSA 模型的性能优于BERT4Rec 和GRU4Rec 模型.FDSA 模型采用平凡注意力机制提取用户的兴趣偏好和项目的特征信息,由实验可见平凡注意力机制和项目特征的融合更显优势.
通过对本文模型与GRU4RecF 和FDSA 模型比较,GRU4RecF 和FDSA 模型融合了项目的特征,但没有融合用户的特征信息.可见用户特征信息的融合可以有效提高模型的性能.
在MovieLens-1M 数据集上整体模型的性能比Yelp 的性能更高.原因可能是MovieLens-1M和Yelp 上性质不一样,MovieLens-1M 是电影影评数据集,Yelp 是类似大众点评的数据集;MovieLens-1M 用户和项目的平均行为数量分别为165、269,同时Yelp 过滤之后用户和项目的平均行为数量为12、10,可见过滤后MovieLens-1M 数据集的平均行为数量远超于Yelp.
本文通过运用带注意机制的GRU 和辅助损失函数对用户的动态兴趣建模,然后与用户特征融合.本文的模型只比BERT4Rec 模型性能高1.5%左右,可能是用户态兴趣建模的融合和多层感知机的加入,导致整个模型的层数太深,出现梯度消失的情况.
3.5 参数对模型的影响
3.5.1 不同长度交互序列影响 不同的交互长度也会对模型的性能造成影响.本文取长度为[20,30,40,50,60]进行实验,如图4 所示.在MovieLens-1M 集上,当序列长度为50,此时的模型性能最佳,为0.9426,可见在MovieLens-1M 集上取短时间的交互序列,相当于短期的兴趣建模,可以取得良好的效果.在Yelp 集上,当序列长度为40,此时的模型最佳,为0.912 0,可见对短期序列建模可以取得不错的效果.上述分析表明,当交互长度较大时,序列中的噪声增多,从而影响模型的性能.
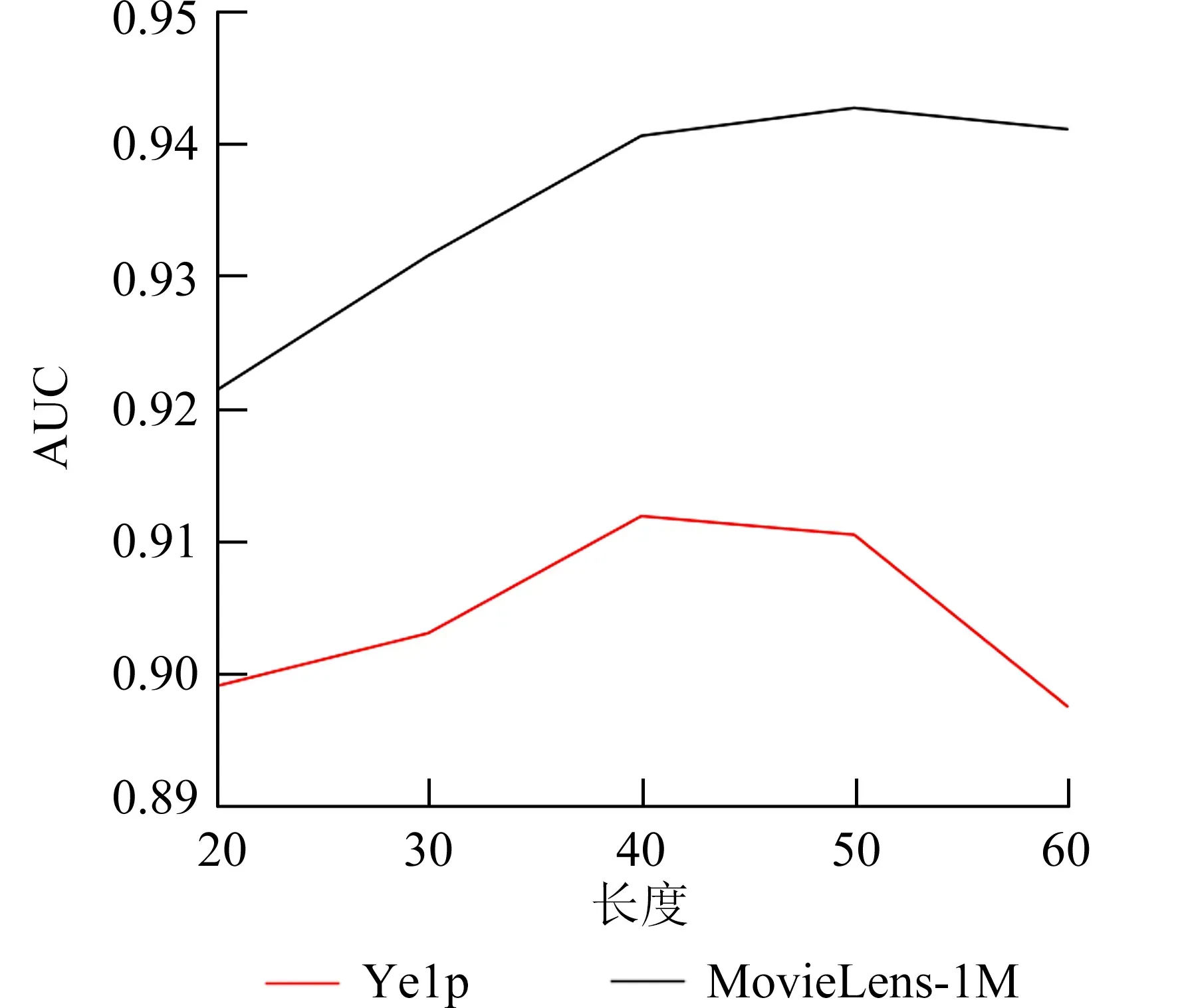
图4 本文模型在不同交互长度下对比实验Fig.4 Comparative experiments of the model in this paper under different interaction lengths
3.5.2 不同嵌入向量维度的影响 嵌入向量维度的大小影响模型的复杂程度,一定的维度大小能够充分实现模型的表达能力.本文采用[8,16,32,64,128]这5 个维度进行实验,如图5 所示.在MovieLens-1M 数据集上,当维度为128 时,模型的效果最好.在Yelp 数据集下,当维度为64 时,模型的效果最好;当维度为128 时,模型的效果出现下降,可见并不是嵌入向量越大,模型的效果越好.
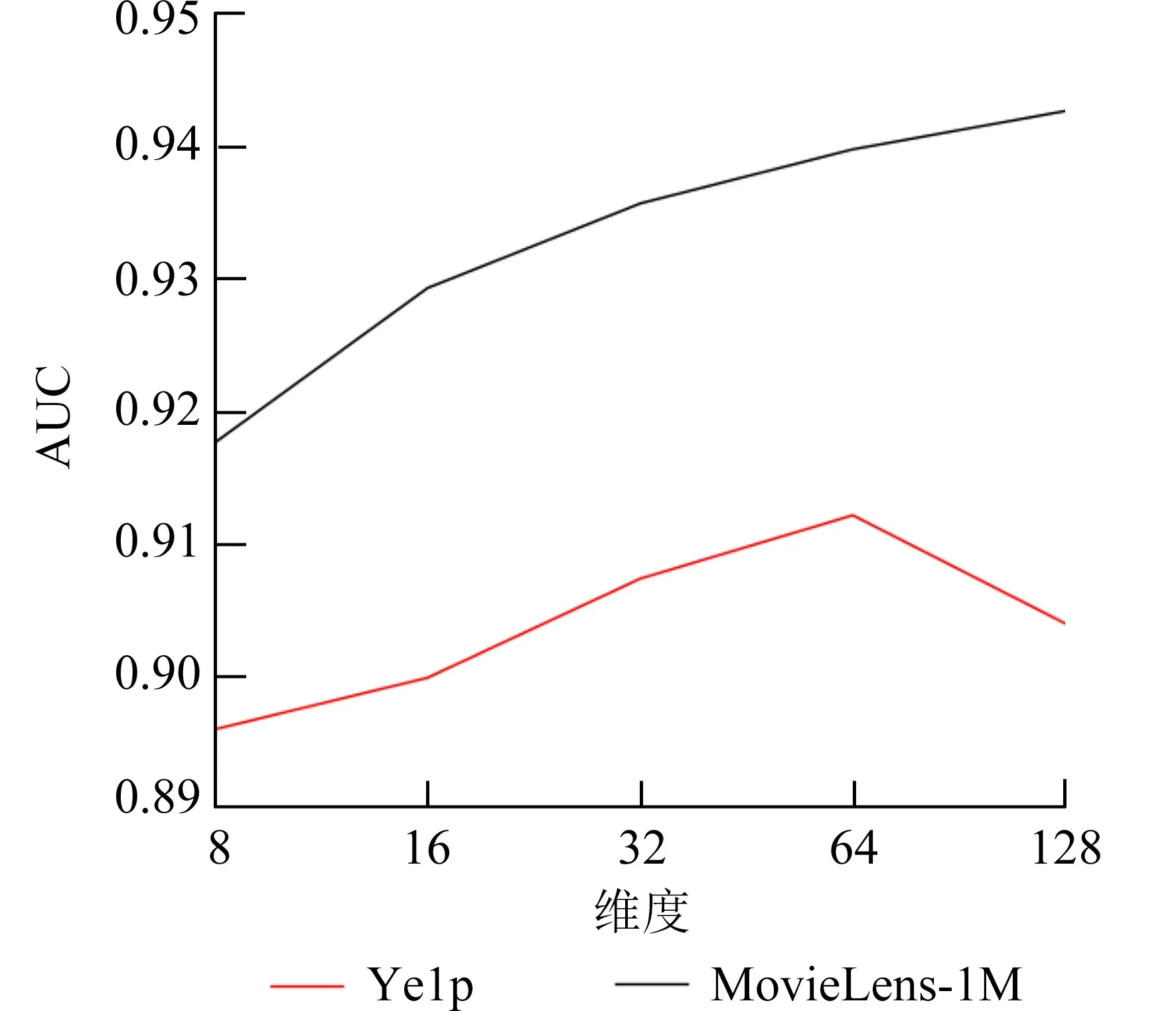
图5 本文模型在不同嵌入向量维度下对比实验Fig.5 Comparative experiments of the model in this paper under different embedding dimensions
3.6 消融实验表5 是去除各种影响因素后消融对比实验结果.去除用户和项目特征,模型的性能在MovieLens-1M 和Yelp 上分别下降0.87%、0.62%,由此验证了融合用户和项目特征的重要性.去除辅助损失函数,模型的性能在两个数据集上分别下降0.48%、0.31%,可见应用下一个行为来监督上一个隐藏兴趣状态的学习可以提高模型的性能.

表5 去除各种影响因素后不同模型消融对比实验结果Tab.5 Comparative experiment results of ablation of different models after removing various influencing factors
4 结论
本文提出了一种融合动态兴趣偏好与特征信息的序列推荐模型,通过对比实验,本文模型在两个数据集的实验结果优于其他基线模型;通过消融实验,验证了特征信息和动态兴趣建模在序列推荐中的重要性.然而本文通过融合动态兴趣建模和多层感知机的加入,导致模型的层数较深,使本文的性能略高于其他模型.未来的工作将从两个方面进行优化.首先,简化模型的层数,让模型更加简单高效;其次,将对用户的动态兴趣进行增强建模,将用户的长期兴趣和短期兴趣相结合,从而提高推荐的性能.
猜你喜欢
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
小雪花·成长指南(2022年1期)2022-04-09
数理化解题研究·综合版(2021年11期)2021-12-22
小学教学研究(2021年5期)2021-09-29
课程教育研究(2021年27期)2021-04-13
初中生世界·九年级(2020年2期)2020-04-10
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
第二课堂(课外活动版)(2016年2期)2016-10-21
阅读(中年级)(2009年11期)2009-04-14
