
基于卷积神经网络的文档列表排序学习算法
2022-08-10 08:21曹军梅马乐荣
计算机应用与软件 2022年7期
曹军梅 马乐荣
(延安大学数学与计算机科学学院 陕西 延安 716000)
0 引 言
排序问题已被广泛应用于信息检索、协同过滤和数据挖掘[1-3]等领域,是对检索到的样本根据其相关性进行排序。在文档检索中,排序描述为给定一个查询样本,通过对比待检索样本和这个查询样本的相似度,可以得到一系列相关的样本,再对这些样本根据其相关性借助一个排序函数来进行打分,然后按降序排列文档,即可得到一组相关由高到低样本。传统排序算法通过人工调整排序中所涉及的一些参数来构建排序函数,然而不断增加的文档特征数量,使得手工构建排序函数变得更加困难。
近年兴起的机器学习方法在排序问题上显示出其优越性,即排序学习[4]。这种方法的目的仍是构造一个排序函数,但它是通过最小化度量真实打分和预测打分之间差距的损失函数来实现。真实打分值来自于表示每个文档相关性的数据标注,而预测打分是通过排序函数得到。
排序学习方法根据输入数据颗粒度的不同,分为单文档[5]、文档对[6]和文档列表[7]方法。单文档方法直接采用分类或回归来解决排序问题,其中典型的包括Prank[5]和McRank[8]。文档对方法将检索到的文档中的任意两个文档构造成文档对,作为正样本或负样本进行训练,然后直接采用二分类的方法进行排序学习,常见的方法有Ranksvm[6]、Rankboost[9]和Ranknet[10]。虽然上述两种方法可对检索到的文档的相关性做出判别,但它们并不是直接解决排序问题,没有考虑文档列表中文档之间的全序关系。
研究表明[11],文档列表方法效果要优于单文档、文档对方法,它是将整个文档序列看作是一个训练样本,意图获得整个序列的排序情况,是在排序过程中最自然的结果展示方法,在排序任务中表现出了最好的性能,代表性的算法包括ListNet[7]、ListMLE[11]和ListCCE[12]。然而,这些代表性的文档列表方法只是利用一般的反向传播神经网络算法进行训练,没有考虑从每个文档中提取的特征之间的关系。事实上,这些特征之间是局部相关或冗余的。为进一步提高排序性能,需要对这些特征的性质进行深入考虑。因此,借助多通道深度卷积神经网络对文档的多模态特征进行重提取,进而进行排序学习。该方法过程可以分为训练和测试两个阶段。在训练阶段,利用训练数据进行学习和构建排序函数,排序函数是根据不断优化损失函数得到的。随后,将学习得到的排序函数在测试集上进行测试。
本文针对文档列表排序学习方法构建了一个多通道深度卷积神经网络架构,即ListCNN,它描述了如何重新提取多模态特征,从而对文档列表方法发挥其作用。而后通过实验验证本文提出的方法,实验结果表明该方法性能超过现有典型的文档列表方法。
1 文档列表排序学习分析
1.1 排序学习
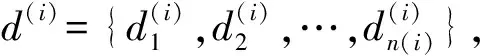
(1)
式中:m是查询的数量;f(x(i))和y(i)都是文档列表级的向量。因此,损失函数在列表颗粒度上度量真实值和预测值的相似性。
1.2 文档特征分析
在每个查询中,每个文档被提取为46维特征向量,并表示为1维向量。其中前40个特征与文本内容相关,即文档内容在多大程度上与查询相关,它们被分为八组,分别是词频率TF、逆文档频率IDF、TF×IDF所得到的值TF-IDF、DL(文档长度)、BM25、LMIR.ABS、LMIR.DIR和LMIR.JM[13],是从正文、锚文本、标题、URL和整个文档这五个域中提取得到,后6维特征与重要度相关,分别PageRank、入度、出度、URL中的斜线数、URL长度和子网页数量,反映了文档在互联网络中的重要度(如PageRank根据网页之间相互的链接关系来计算网页的排名,是Google用来标识网页的重要性的一种方法。其级别从1到10级,PageRank值越大说明该网页越受欢迎即重要度越高,通常能够从更多地方到达的网页更为重要,因此具有更高的PageRank值。)。所有这些特征都组成多模态特征。从五个域中提取的前40维特征分为五个领域,存在局部相关性,而且可能有冗余。如果利用多通道深度卷积神经网络从中重提取并得到新的表征特征,可以提高文档列表方法的性能。此外,对于后6个特征,同样进行重新提取。由于它们是多模态特征,所以本文设计一个在空间上并行的卷积神经网络进行提取。最后,所有这些重提取得到的表征特征将被聚合。
2 实现方法
考虑到前40维特征和后6维特征是跨模态的,模型中建立了两组并排的卷积神经网络,它们在空间上是并行的,包括所有卷积层和池化层。它们的输出被聚合并输入到全连接层中,然后使用前面提到文档列表损失函数进行训练。网络结构示意如图1所示。

图1 多通道卷积神经网络结构图
2.1 输入层
为了使训练集适应卷积神经网络,需要考虑输入层的数据格式。训练集中的每个文档被提取得到46维多模态特征,将这些特征按模态分开来考虑,即分别考虑前40个和后6个。由于前40个特征可以被卷积,因此将它们从1维向量变形为2维矩阵。具体做法是,把它们放在矩阵的边界位置,剩下位于中心的空白处以零值填充。这样,训练数据就可以容易地输入到卷积神经网络中。变形后的特征向量如图2所示。

图2 变形后的输入向量
2.2 卷积层
卷积操作的目的是为了实现权值共享。因此不管有多少网络节点来自输入层,需要维护权重参数数量只依赖于卷积核的大小和通道的数量,即所有的连接节点共享同样的连接权重。卷积核可以看作是一组权重,可以通过增加卷积核的数量从而得到多组权重,这可以增强网络的非线性建模能力。具体而言,对于前40个特征,设置了两个卷积层。第一层是一个通道大小为33的卷积核,第二层将池化后的第一层卷积操作结果扩展为11通道,卷积核大小是2×2。对于后6维原始特征,同样为了提高模型拟合能力,但由于这里没有局部相关性,本文模型设置了两个卷积层,卷积核大小都是1×1,但没有任何池化层,而且第一个卷积层设置为一个通道,第二个卷积层设置为三个通道。在这些卷积操作之后,输入数据将被传输并流入池化层或其他操作,如聚合等。为了得到一个非线性模型,在所有卷积运算的后面设置激活函数,和BP神经网络中一样,最常见的激活函数为sigmoid、tanh、和ReLU,它们会影响收敛速度。一般来情况下选择ReLU,但由于在本文中输入数据的特征相差不显著及ReLU在训练的过程中出现了神经元死亡、权重无法更新的情况,因此本文选用sigmoid作为激活函数。
2.3 池化层
在卷积操作之后,输出张量的维度仍然很高。为了降维,在这些卷积层之后必要地补充池化层。对于前40个特性,在每个卷积之后使用2×2大小的池化窗口进行平均池化操作。然而,对于后6维特性,由于没有局部相关性,因此没有池化操作。
2.4 输出层和全连接层

无论是哪种神经网络,在反向传播过程中,用于更新权重的梯度值可以被抽象地表示为:
(2)
本文提出的基于多通道卷积神经网络的文档列表排序学习方法主要过程见算法1。
算法1ListCNN
fort= 1 toTdo
fori = 1 tomdo
2. 利用式(2)计算所有梯度变化值Δω;
3. 更新所有权重ω=ω-Δω·η;
end for
利用式(1)计算损失函数值;
end for
3 实验与结果分析
为了验证本文方法的有效性,通过Tensorflow 1.10.0实现了本文方法。在实验中,采用CNN架构的文档列表方法作为实验组,并设置两个采用普通BP神经网络的对照组。其中一组是含有一个隐藏层的三层BP神经网络,另一层是更深的BP(Deeper-BP)神经网络,其每层的层数和神经元数与本文的CNN架构一样。这样设置的原因是,通常情况下,Deeper-BP神经网络可能表现得更好。然而,有时较深的BP神经网络能很好地拟合训练集,但过拟合可能会发生。因此,需要验证本文的方法是否与其他节点数相同的BP神经网络在过拟合时仍然能保持较好的性能。
3.1 数据集
本文采用Letor4.0数据集[14]中的两个数据集MQ2007和MQ2008进行实验,表1给出了它们的介绍信息。
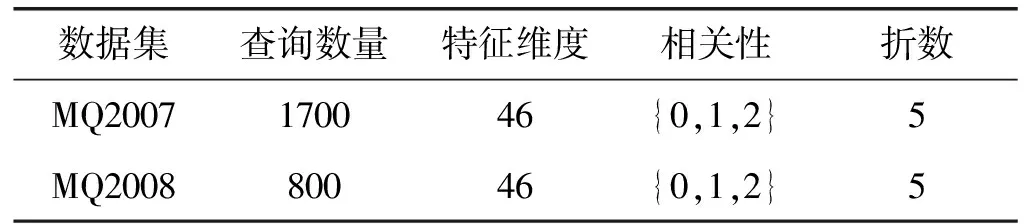
表1 MQ2007和MQ2008数据集介绍
MQ2007和MQ2008的查询使用了从TREC中产生的Gov2网页集合。数据格式为:
label qid:id feaid:feavalue feaid:feavalue ...
具体如下:
2 qid:22 1:0.666 2:0.716 … 46:0.789 #docid=197041
1 qid:221:0.333 2:0.35… 46:0.83 #docid=277438
0 qid:22 1:0.166 2:0.179 … 46:0.844 #docid=93542
每行表示一个文档样本,label表示该样本和该查询请求的相关性,划分为强相关、弱相关、不相关,分别量化表示为2、1、0;qid是查询请求的id,相同的查询请求的文档样本的qid相同,上面就是三个对qid为“22”的查询;紧接其后是提取到的1-46维的文档特征,每一个特征都表示为“特征:特征值”,最后以“#”开头的是文档注释。
使用相同数量的查询将每个数据集划分为5个部分,分别表示为S1、S2、S3、S4和S5,用于五折交叉验证。在每个折叠中,使用三个部分进行训练,一个部分进行验证,一个部分进行测试,如表2所示。训练集用于学习排名模型。由于进行了五折交叉验证,因此排名方法的性能实际上是五次实验的平均性能。
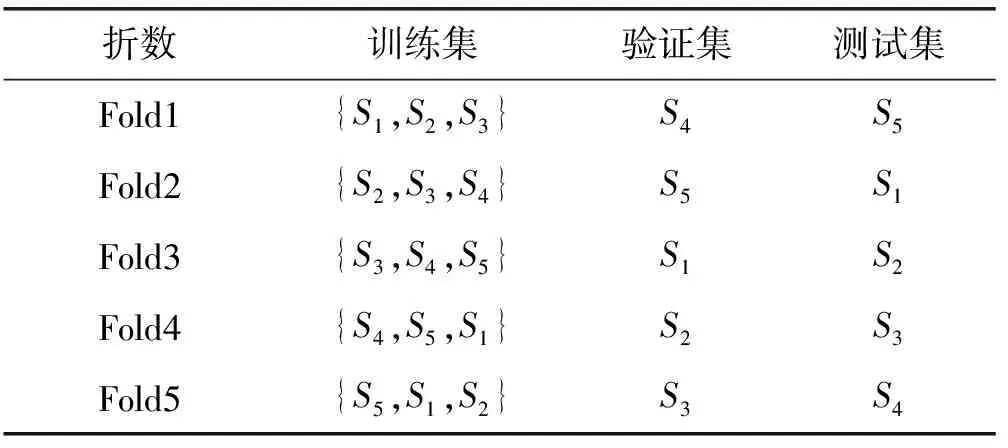
表2 五折交叉验证数据集划分
3.2 评价指标
使用信息检索中常用的两个排序性能指标NDCG@k(Normalized Discount Cumulative Gain)和MAP(Mean Average Precision)来衡量排序学习算法的性能的优劣,为对比实验设置五折交叉验证。
对于一个排好序的文档列表,NDCG的值可以表示为:
(3)
式中:r(di)是第i个文档的相关性;Zk是归一化因子。NDCG的值越高,排序的结果越好。一般只考虑NDCG的前k个值,记为NDCG@k。
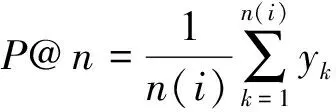
(4)
式中:m表示第m类查询;Crd表示相关文档的数。
3.3 结果分析
在指标NDCG上,由于只有前k个查询结果更有必要进行评估,通常采用NDCG@k来简化。具体而言,由于前10个结果更能得到关注[15],实验只取NDCG@1到NDCG@10的结果。图3展示了三个文档列表方法在Letor4.0数据集上的NDCG@1到NDCG@10的评价结果。可以发现在对照组中,只有ListNet在Deeper-BP神经网络上的表现超过普通的BP神经网络,而ListMLE[8]和ListCCE[9]由于过拟合,在Deeper-BP神经网络上的表现不好。然而,ListCNN的表现都能超过它们,即ListCNN达到了最优的性能,NDCG@1至NDCG@10的值在MQ2007上为0.59到0.68,在MQ2008上为0.64至0.79。
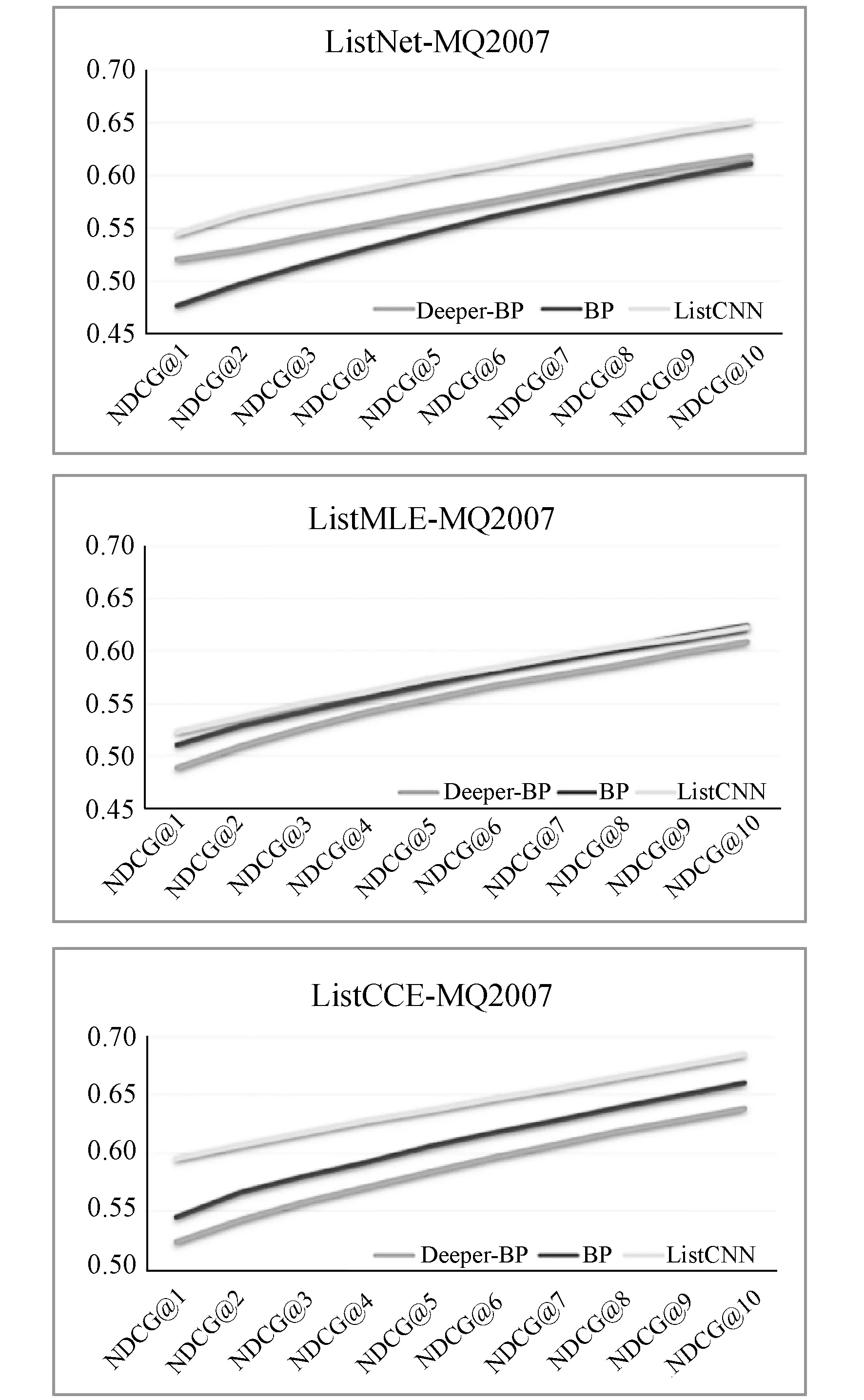

图3 数据集MQ2007和MQ2008的NDCG指标
表3和表4分别展示了算法在MQ2007和MQ2008数据集的MAP指标,其中ListNet[7]和ListCCE[9]的损失函数在ListCNN中的MAP指标上表现最好。只有ListMLE[8]的损失函数在ListCNN上表现略差于普通BP神经网络,这是由于过拟合造成。
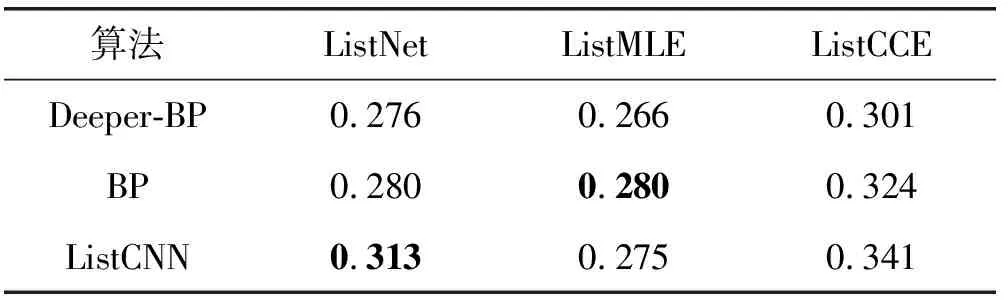
表3 数据集MQ2007的MAP指标
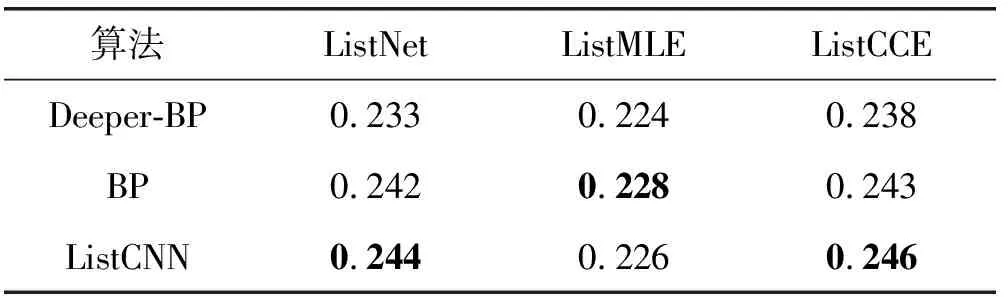
表4 数据集MQ2008的MAP指标
4 结 语
在研究排序效果最自然、效果较好的文档列表方法的基础上,通过分析文档多模态特征之间的关系,设计了多通道卷积神经网络来对文档的多模态特征进行重提取,从而得到更加有效的特征表示。为了验证本文文档列表排序学习ListCNN算法的优越性,用微软公开Letor4.0数据集中的MQ 2007和MQ 2008进行实验,并用NDCG值、MAP值的对比证实了ListCNN算法在排序过程中取得了较好的实验效果。由此表明本文提出的排序学习方法能够有效地提高排序学习算法的性能。下一步工作将继续挖掘影响排序性能的因素并加以改进,同时与深度学习相融合以增强排序模型在动态环境中的适用性。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
汽车工程师(2021年12期)2022-01-17
名家名作(2021年4期)2021-05-12
课堂内外(初中版)(2020年5期)2020-06-19
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
成长·读写月刊(2018年8期)2018-08-30
中学生数理化·教与学(2017年4期)2017-04-22
中学生数理化·中考版(2015年10期)2015-09-10
电影新作(2014年1期)2014-02-27
